Is observability a buzzword or a real thing? • Observability challenges in serverless • Observability Driven Development • How/When to test serverless applications • What to check to monitor serverless stack • Troubleshooting serverless applications
in which the cloud provider runs the server, and dynamically manages the allocation of machine resources. Pricing is based on the actual amount of resources consumed by an application, rather than on pre-purchased units of capacity. Wikipedia: https://en.wikipedia.org/wiki/Serverless_computing
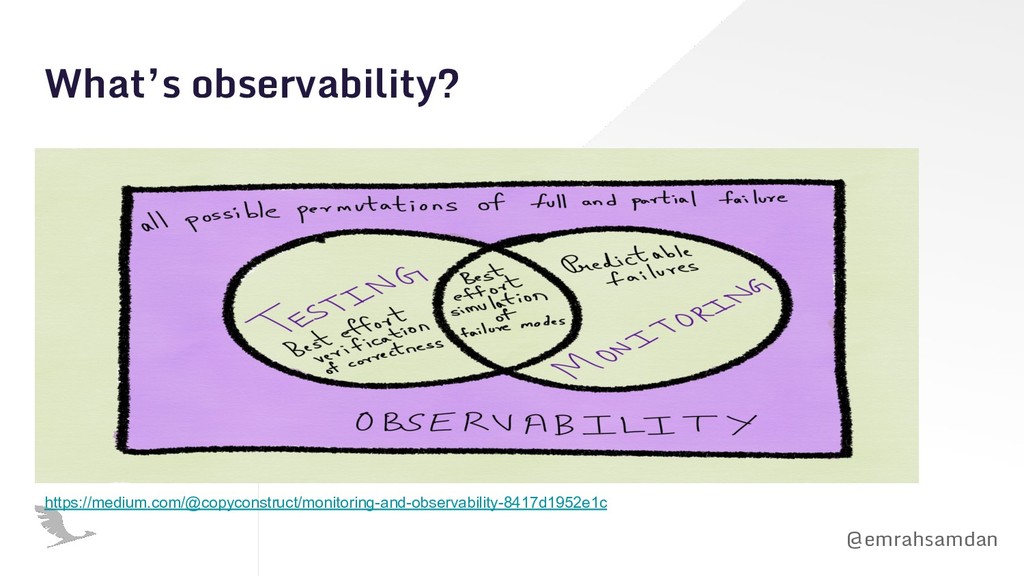
that we understand and we are aware of. Follow the metric charts. Known unknowns Things that we are aware of but don’t understand at a glance. Yes, there is a peak over there. Let me dig the traces and logs. Unknown knowns Things that we can understand but we are not aware of. I would have fixed this if I had that that metric chart :( Unknown unknowns Things we neither understand nor aware of. That things are broken and I have no freaking idea with what I have.
infrastructure • You either take whatever cloud vendor provides or accept that there will be an overhead. • Overhead? ◦ Gathering intelligence (should be acceptable) ◦ Transporting it to where necessary (you only have invocation life time to take the data out) • Everything is event-driven and distributed.
you need to when you have to troubleshoot a unknown-unknown? • Can an observability tool know your unknowns? • If you don’t know what to know what can you do? Known knowns Things that we understand and we are aware of. Follow the metric charts. Known unknowns Things that we are aware of but don’t understand at a glance. Yes, there is a peak over there. Let me dig the traces and logs. Unknown knowns Things that we can understand but we are not aware of. I would have fixed this if I had that that metric chart :( Unknown unknowns Things we neither understand nor aware of. That things are kaputt and I have no freaking idea with what I have.
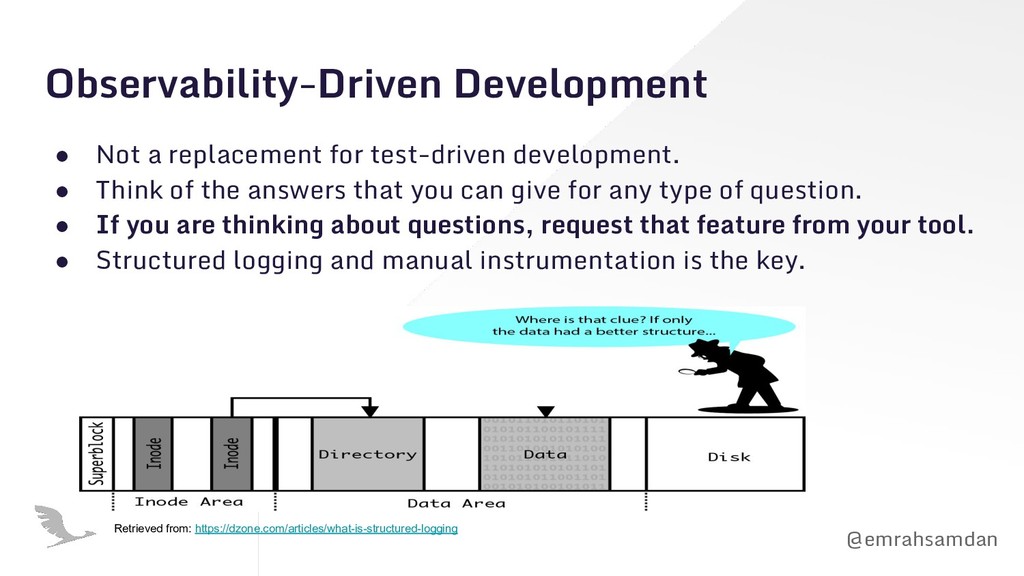
• Think of the answers that you can give for any type of question. • If you are thinking about questions, request that feature from your tool. • Structured logging and manual instrumentation is the key. Retrieved from: https://dzone.com/articles/what-is-structured-logging
pain. ◦ How to mock the cloud resources. Is it actually correct to mock them? ◦ How should you test the chain of many invocations? ◦ How to integrate it with CI/CD tools? • Integration testing with real resources is still the best effort but again how?
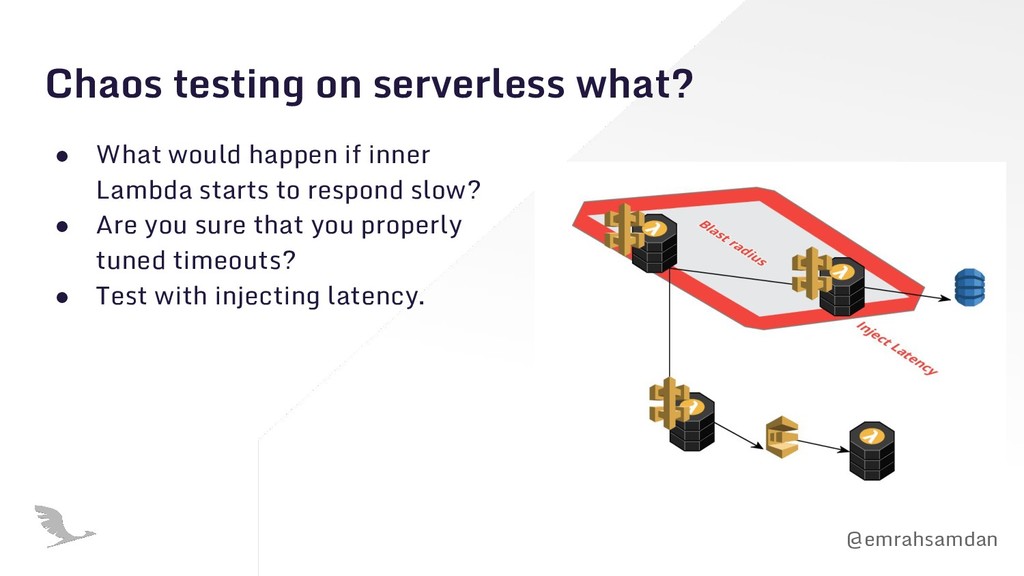
business logic against the resources. • See how your messages being transformed in the flow. • Async events can cause problems that you can never guess.
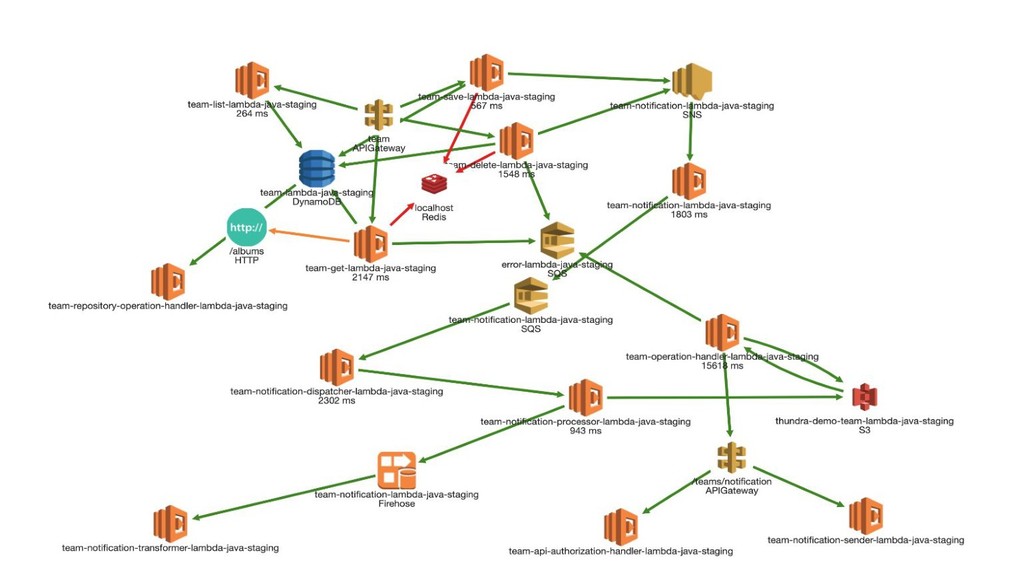
engineering greatly because ◦ Distributed ◦ Lots of possibilities of failures in async environment ◦ Event-driven (So poisonous events) ◦ Roles and permissions are so granular that access can slip away.
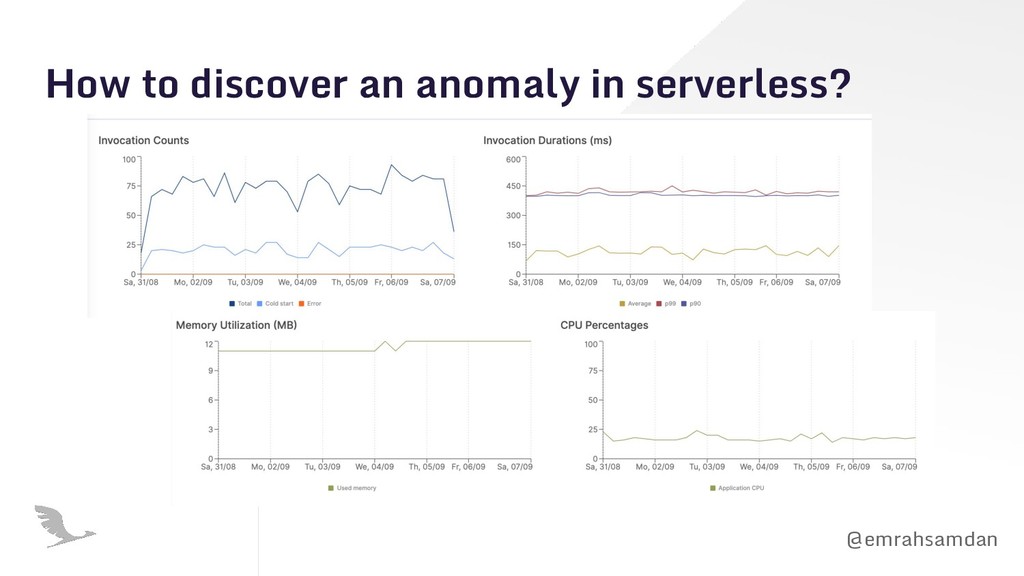
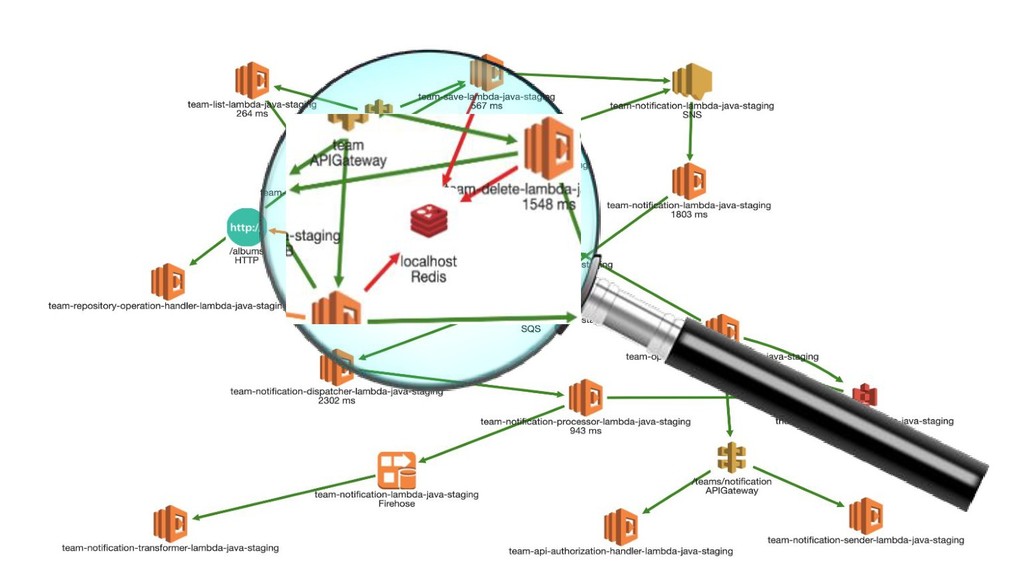
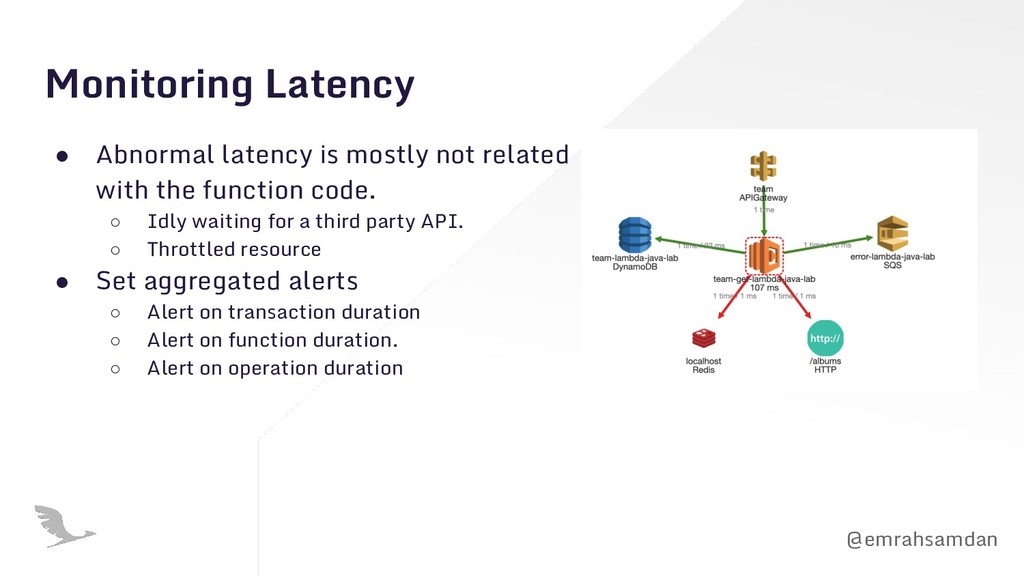
Issues can stay local before you notice them. • It is slow. Why? ◦ API slowdown? ◦ Throttle on any resource? ◦ Bad coding practice? • Invocation counts go crazy. ◦ Seasonal peak? ◦ Successful product? ◦ Retry storms?
with the function code. ◦ Idly waiting for a third party API. ◦ Throttled resource • Set aggregated alerts ◦ Alert on transaction duration ◦ Alert on function duration. ◦ Alert on operation duration
fails for some reason, your function will retry several times. ◦ Sync events: You should control it. ◦ Async events: Different retry mechanisms. ◦ Stream based events: Risk of losing data. • Does this solve? • Check ◦ Iterator age ◦ Number of retries ◦ Number of errors ◦ Memory usage ◦ Cold starts
◦ Stacktrace ◦ Code line it caused ◦ Values of (Local variables) • Alert on latencies and timeout errors ◦ Slow API communications ◦ Slow DB interaction for bad queries
Issue may not be your code. • Check the third parties. • Check other metrics ◦ Iterator age of streams ◦ Throttles on resources • Have some runbooks ◦ Exponential backoffs to APIs, Alternative APIs ◦ Healthy on-call structures
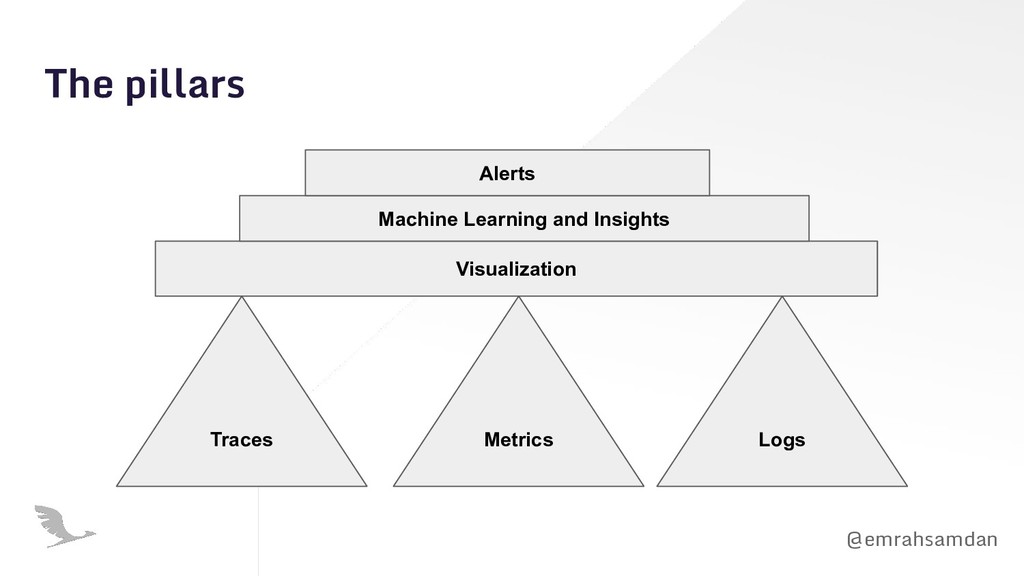
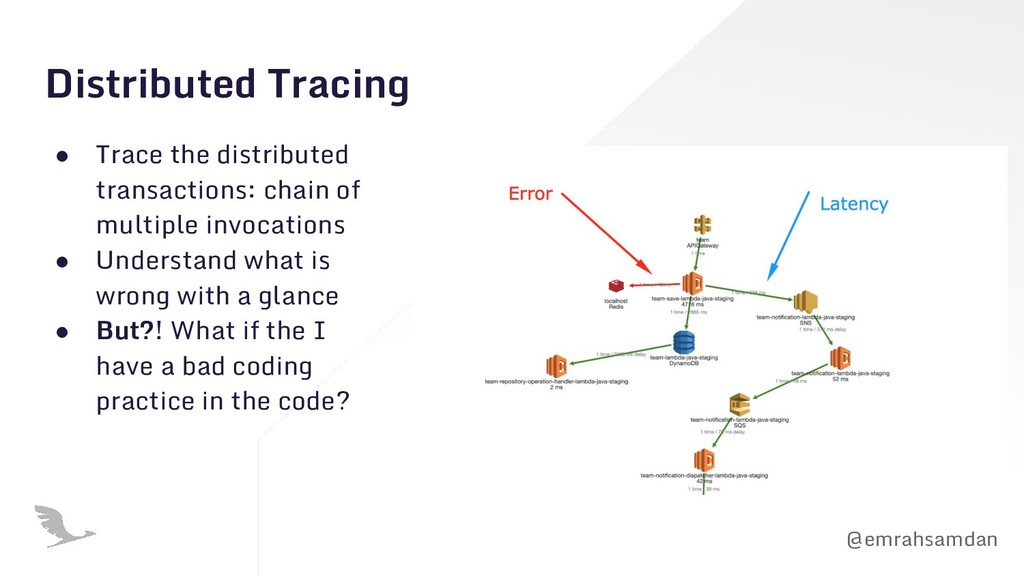
issue. • Observability with all three pillars aggregated is life-saving. • Automation is king! But, get yourself ready to ask questions with ODD. • Sadly, no testing scenario is sufficient in serverless. Step into chaos engineering before your engineering run into chaos! • Change the way you monitor your system. Look beyond functions and discover local bottlenecks with an architectural view! • Serverless transaction= A chain of invocations commuting between resources and APIs. Full tracing required! • Make your alerts actionable and start keeping runbooks for the issues that you can predict.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}