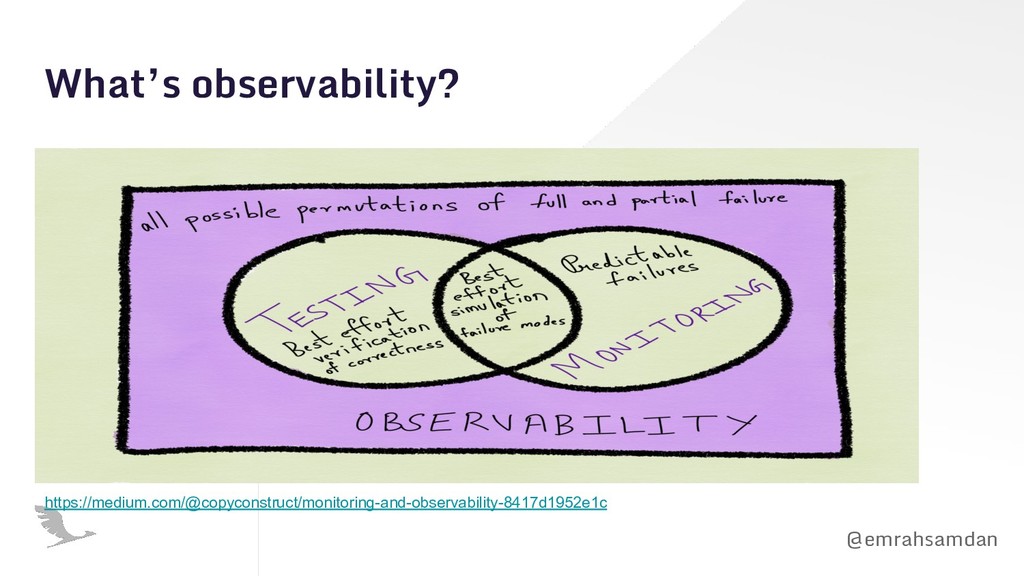
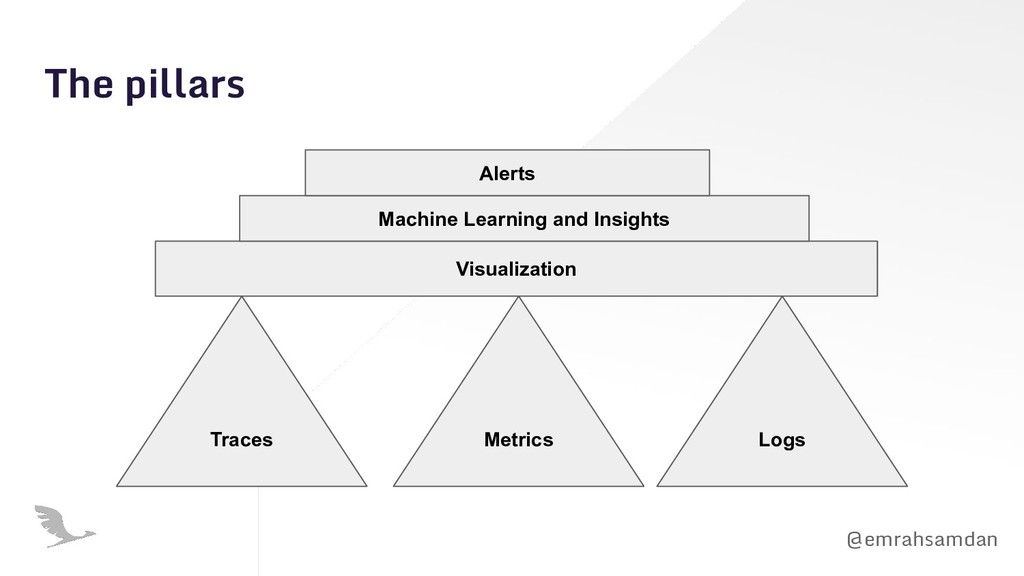
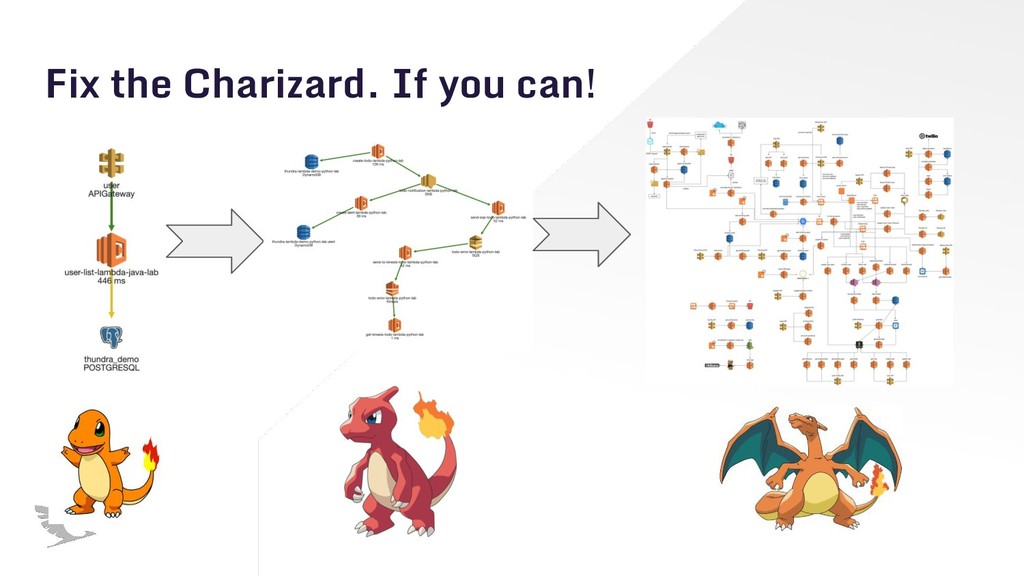
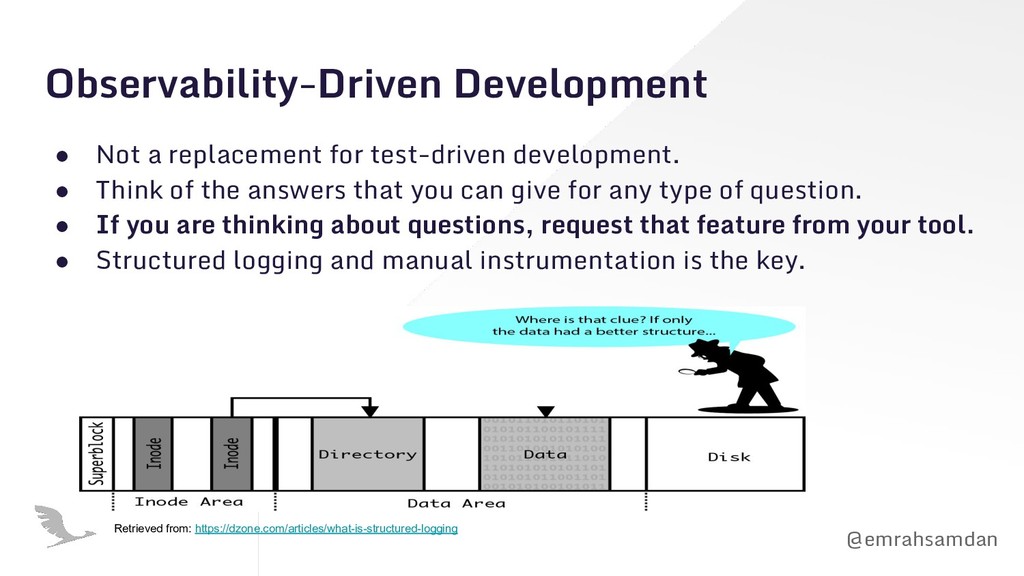
Observability is different than monitoring because it's a state for your software system rather than an action to keep it up. You can resolve the issues in your architecture only if your system is truly observable. Observability is particularly important in serverless because serverless embraces asynchronous communication of distributed tiny resources. In such a system, it's very hard to track the issues with a classical monitoring approach. In this presentation, we are showing how observability can be critical for serverless applications during different phases of software development lifecycle.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
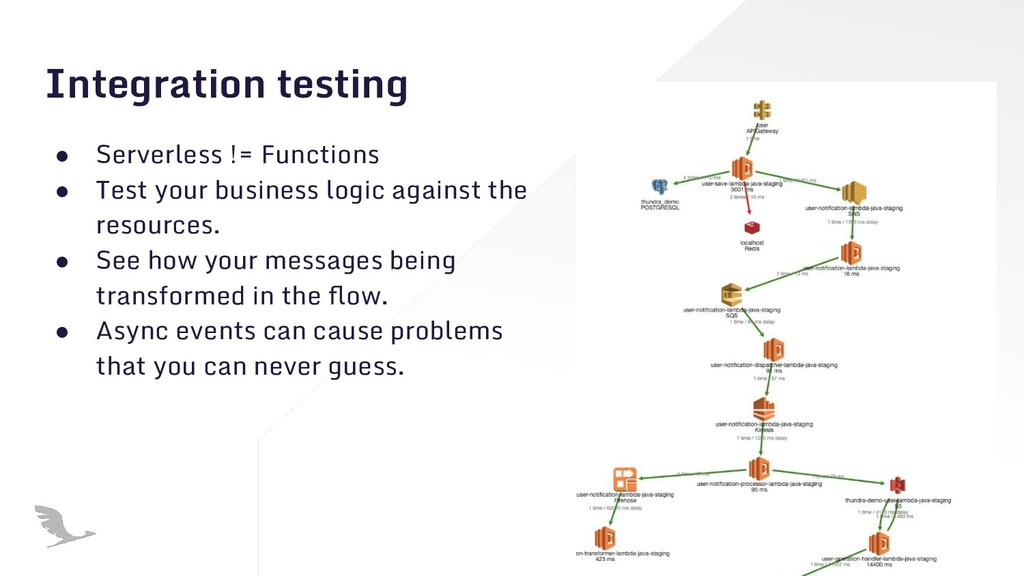{kind=link}
{kind=link}
{kind=link}
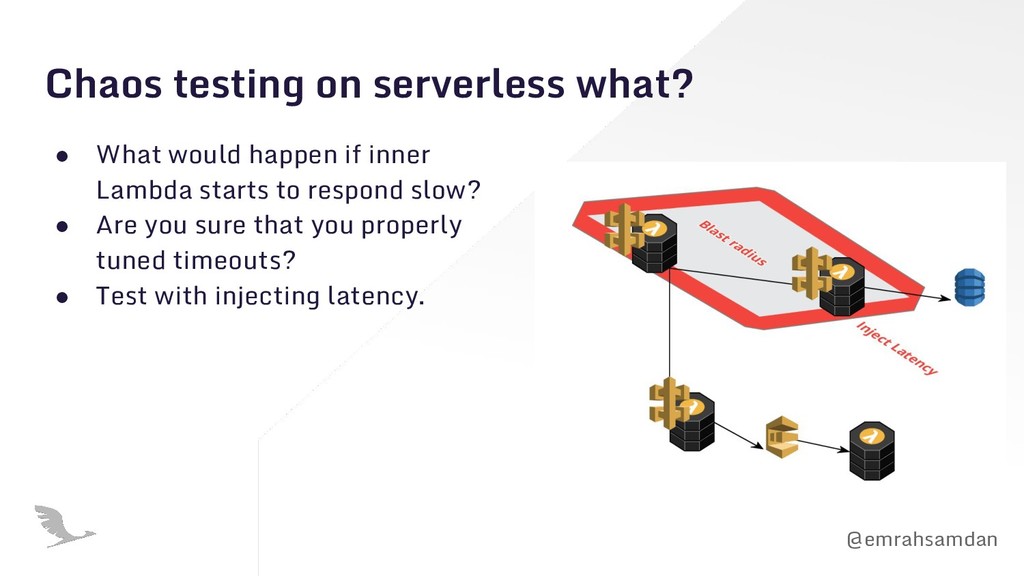{kind=link}
{kind=link}
{kind=link}
{kind=link}
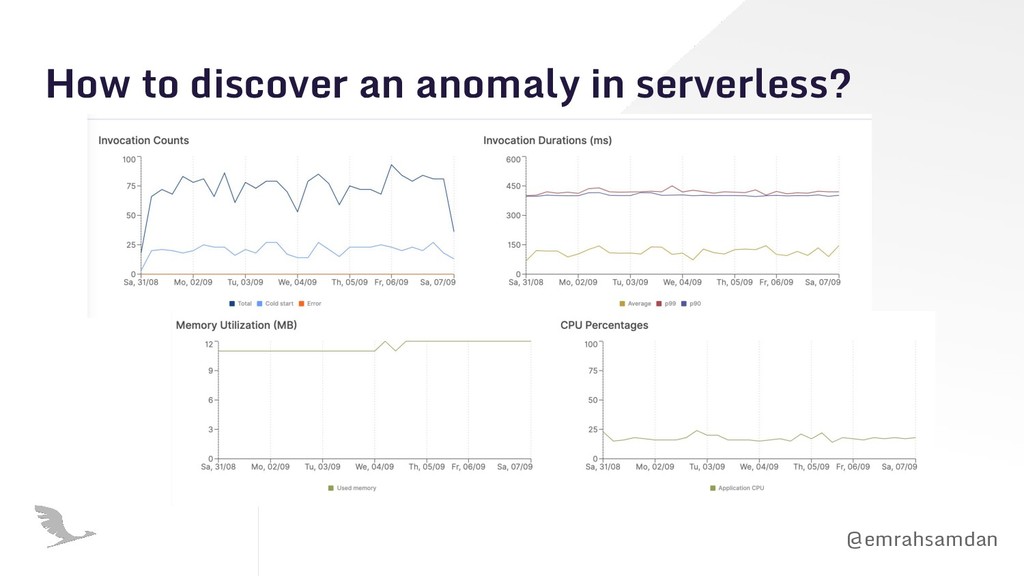{kind=link}
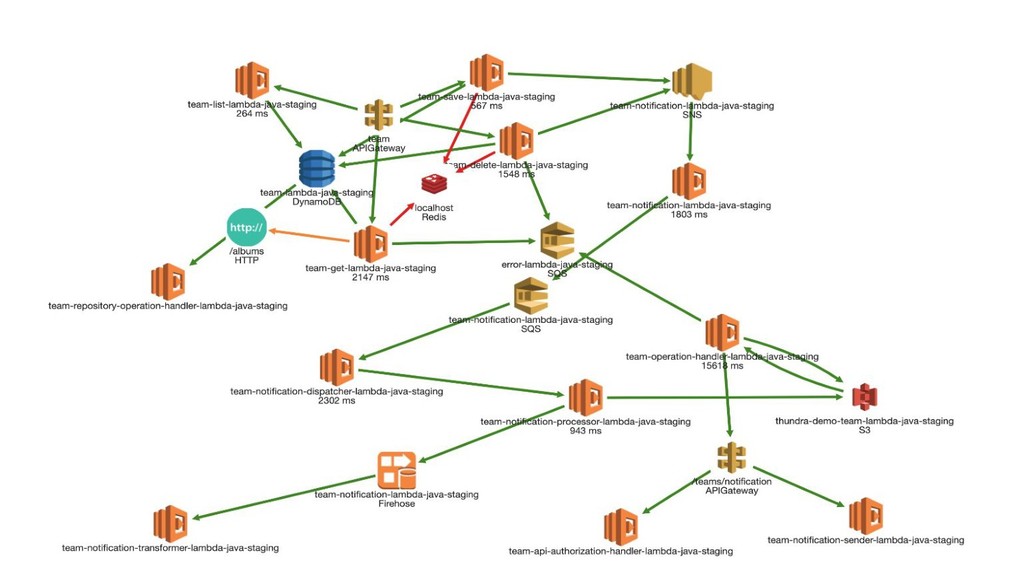{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}