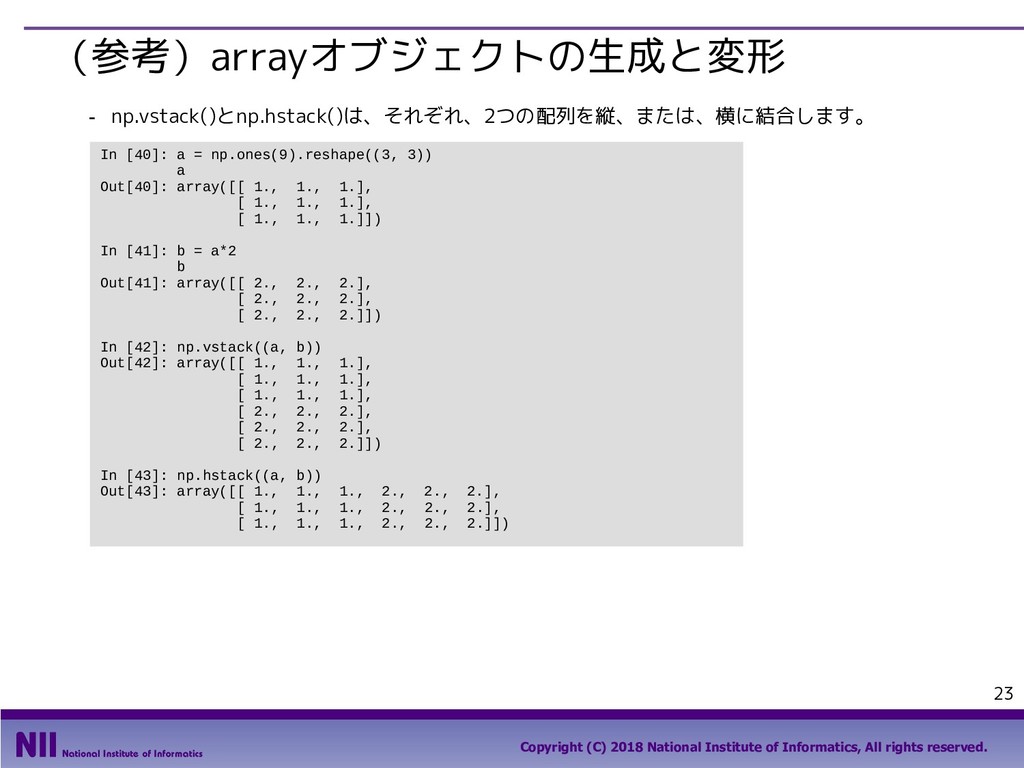
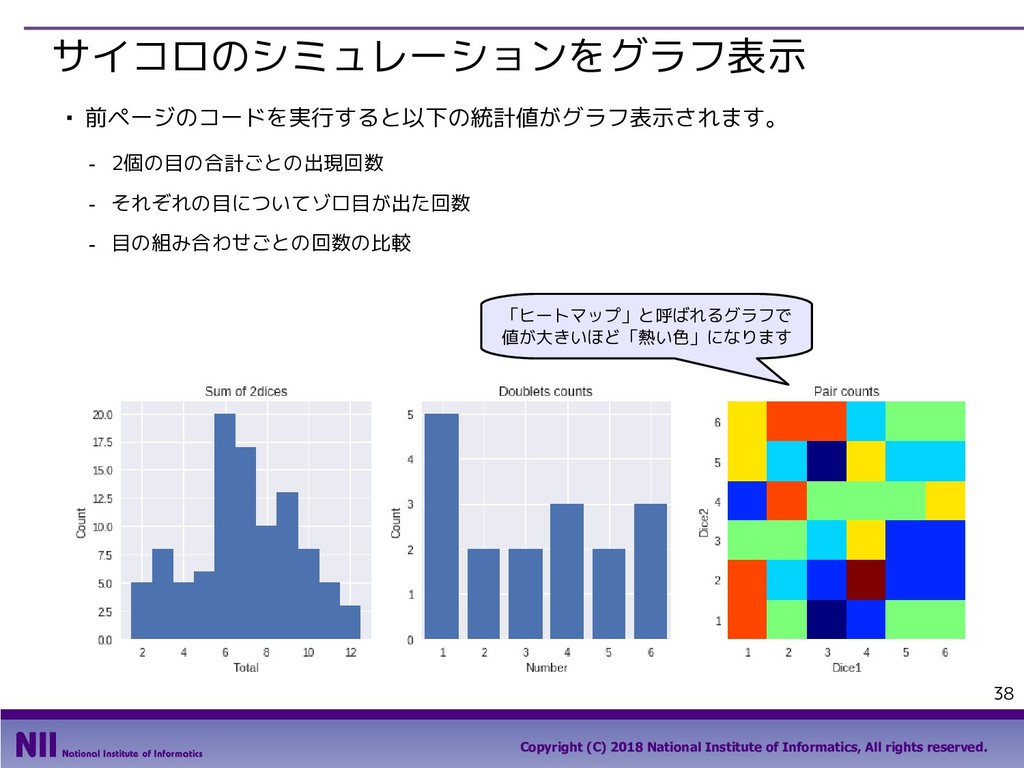
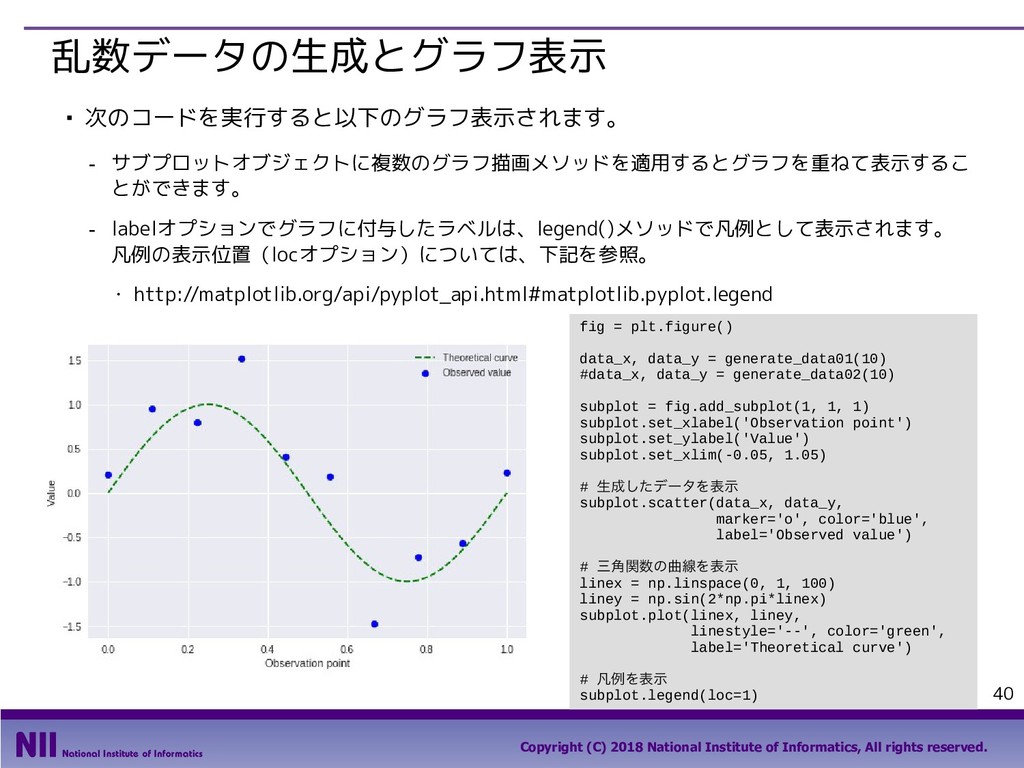
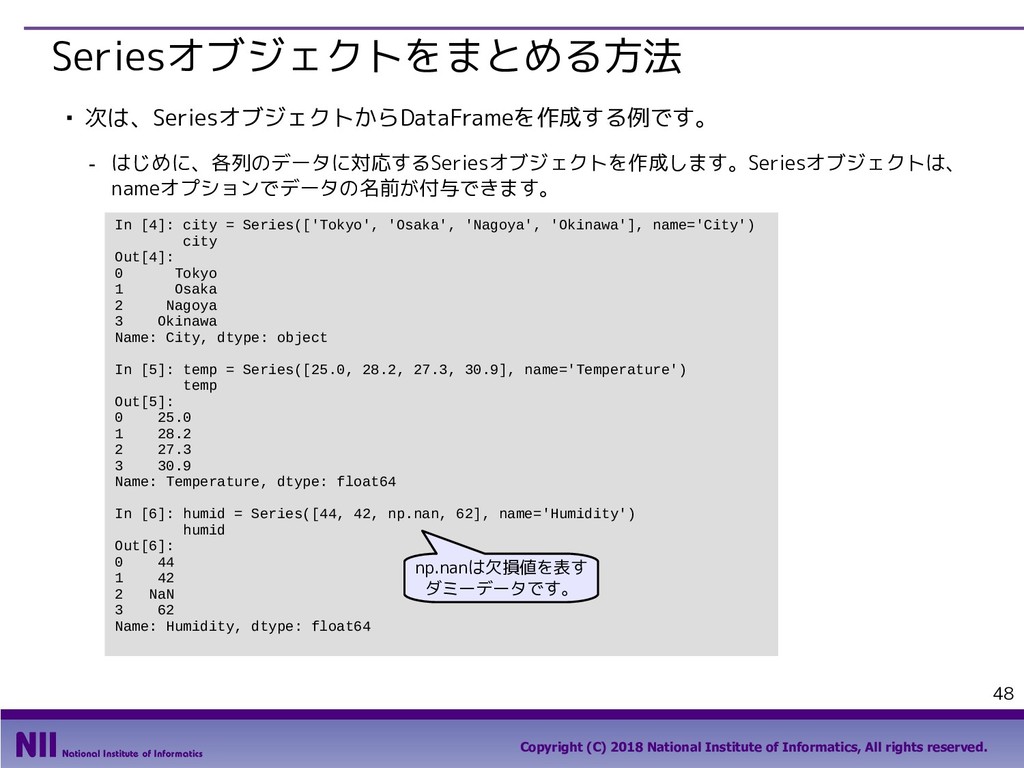
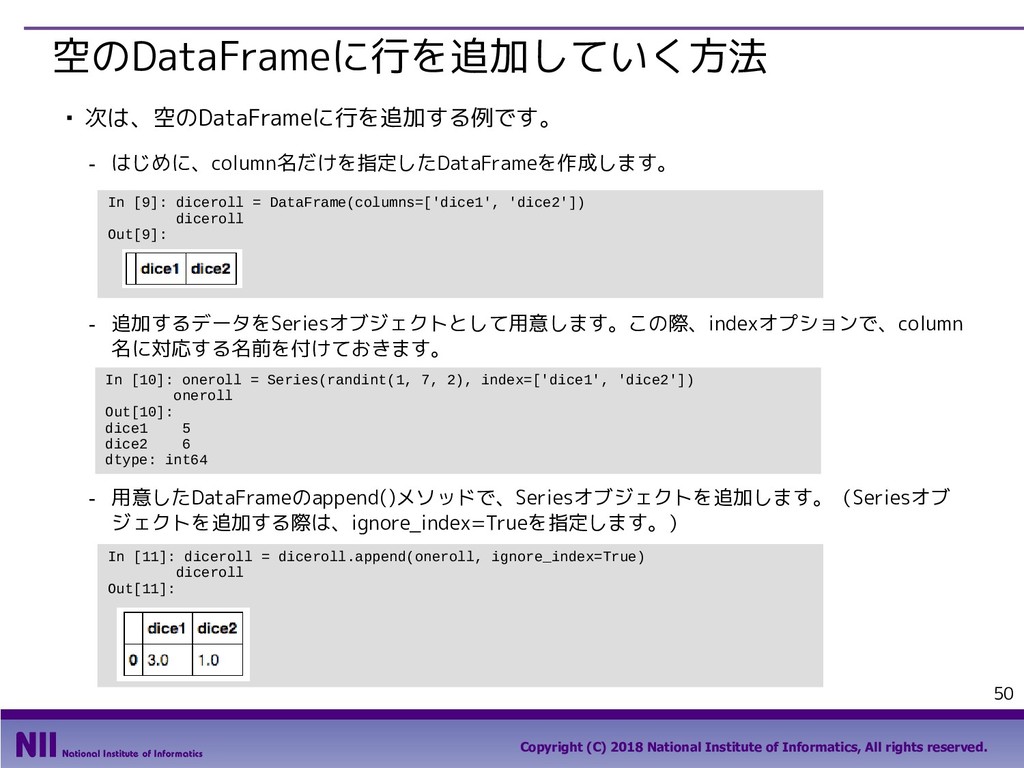
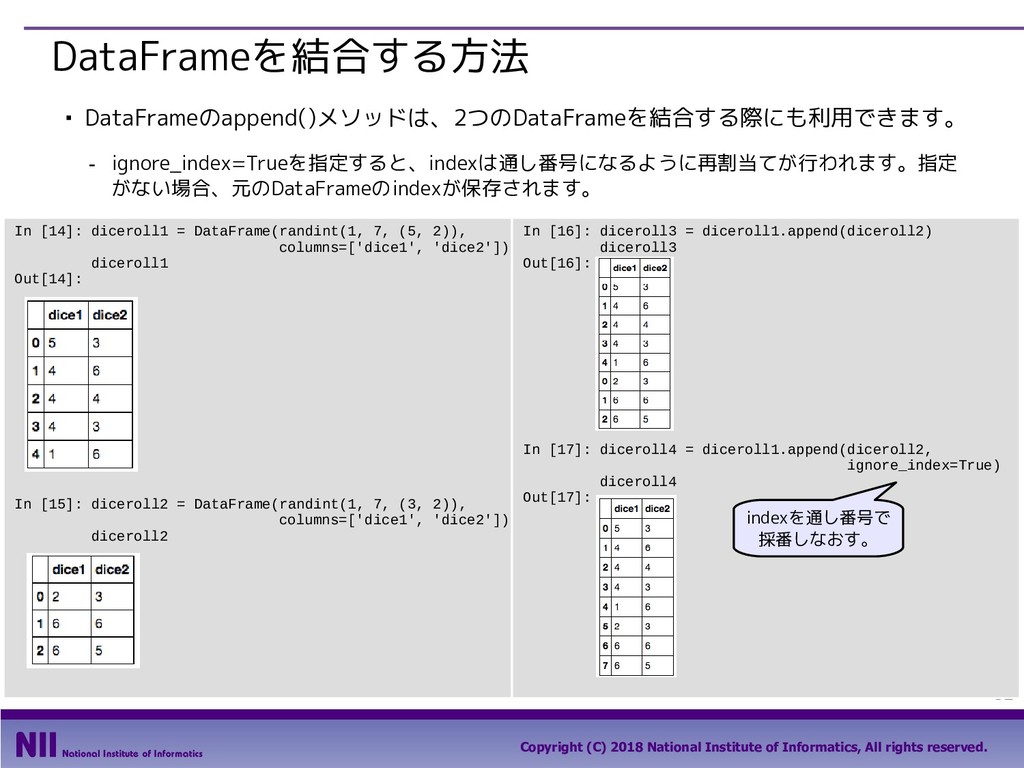
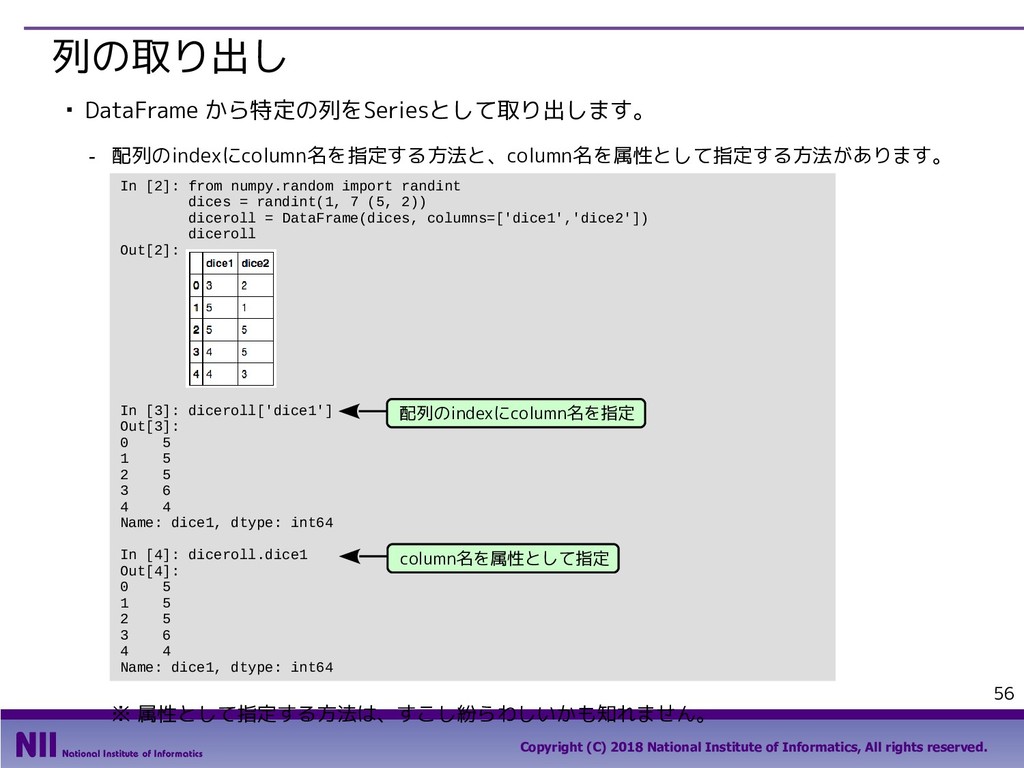
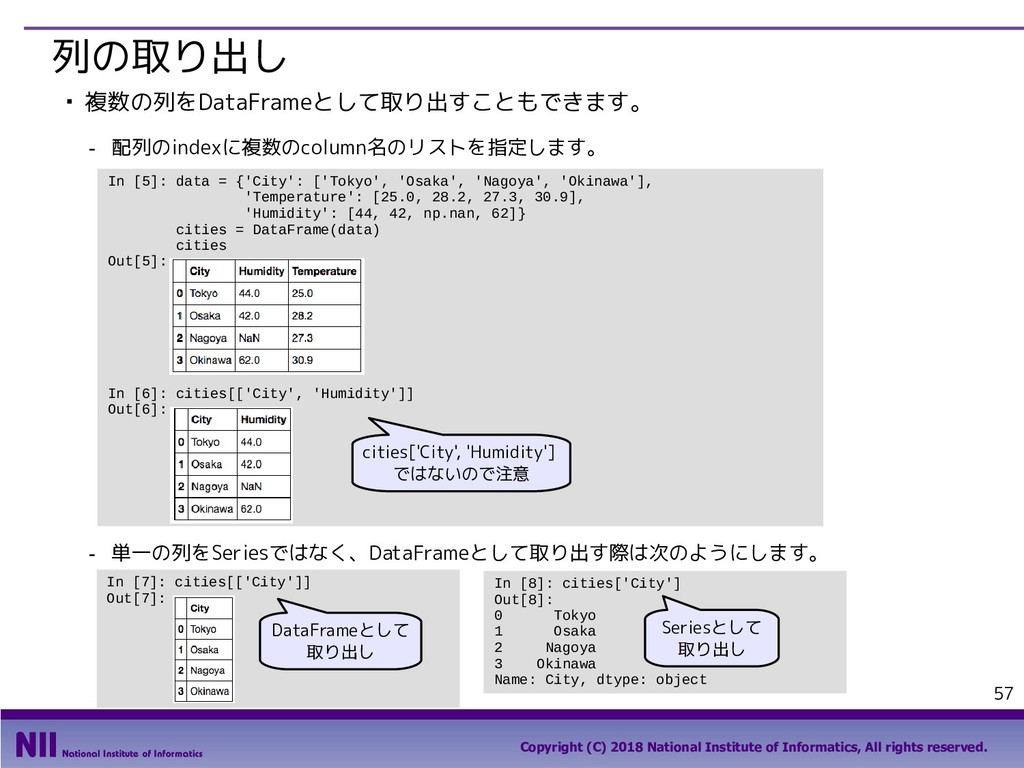
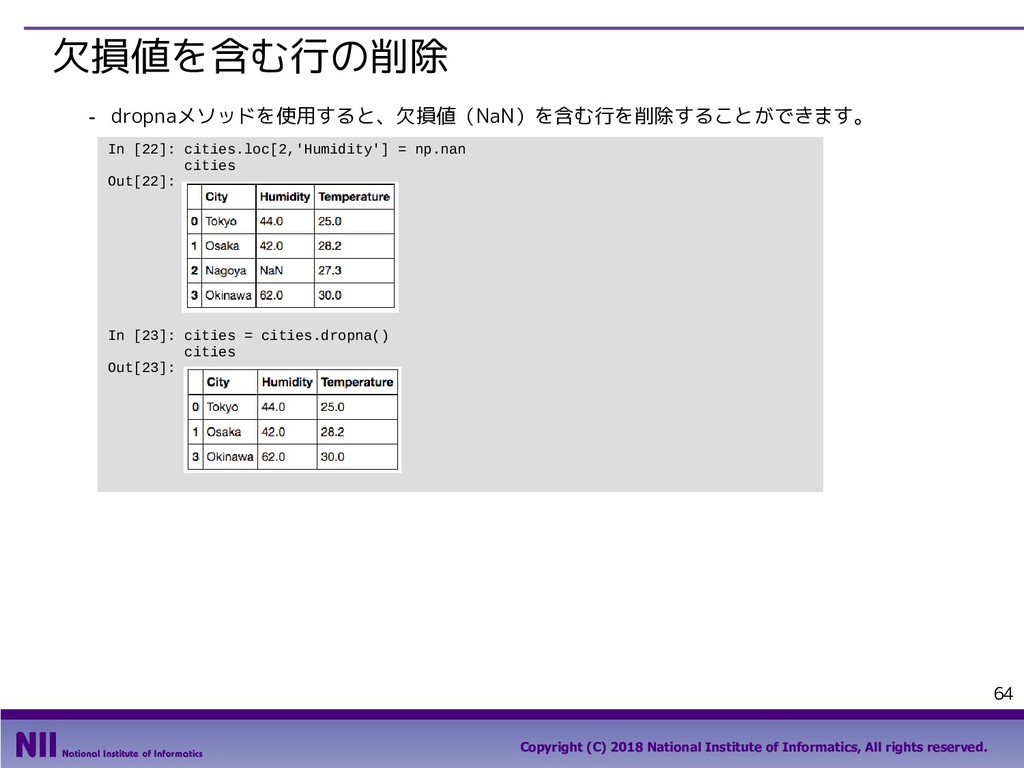
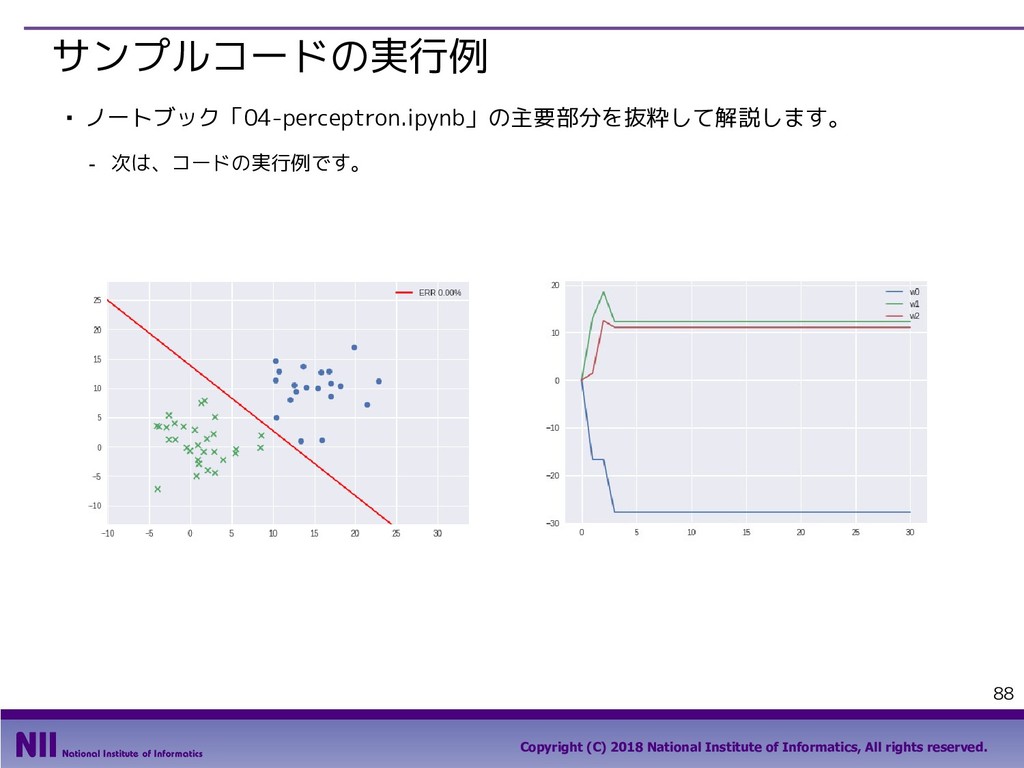
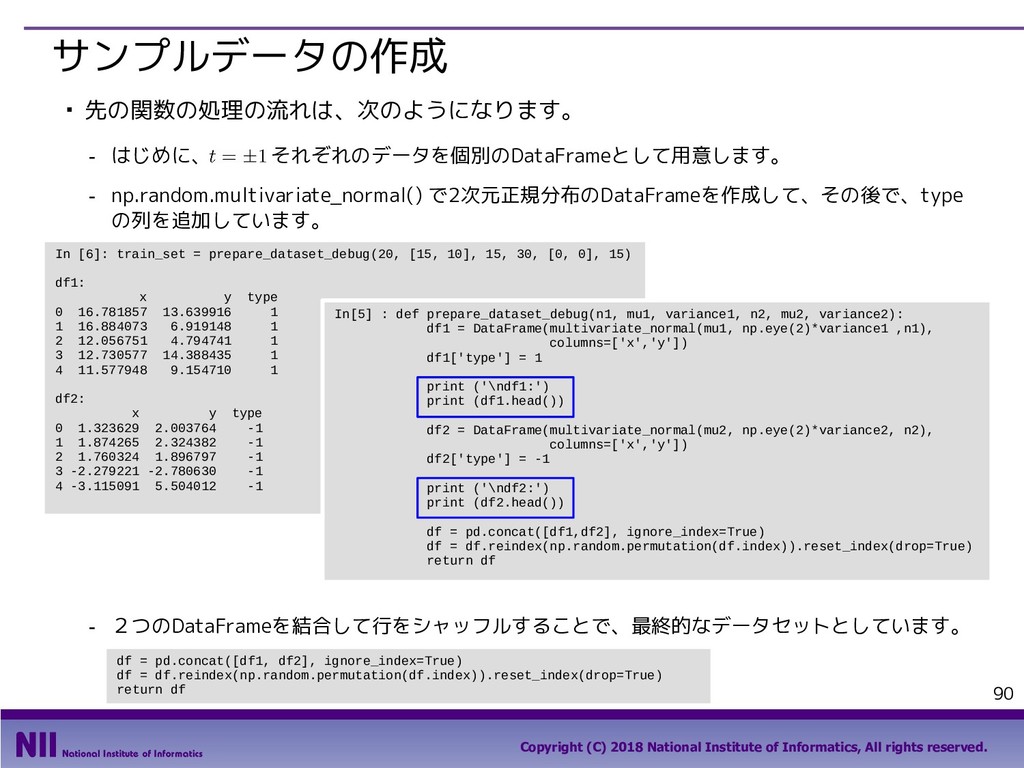
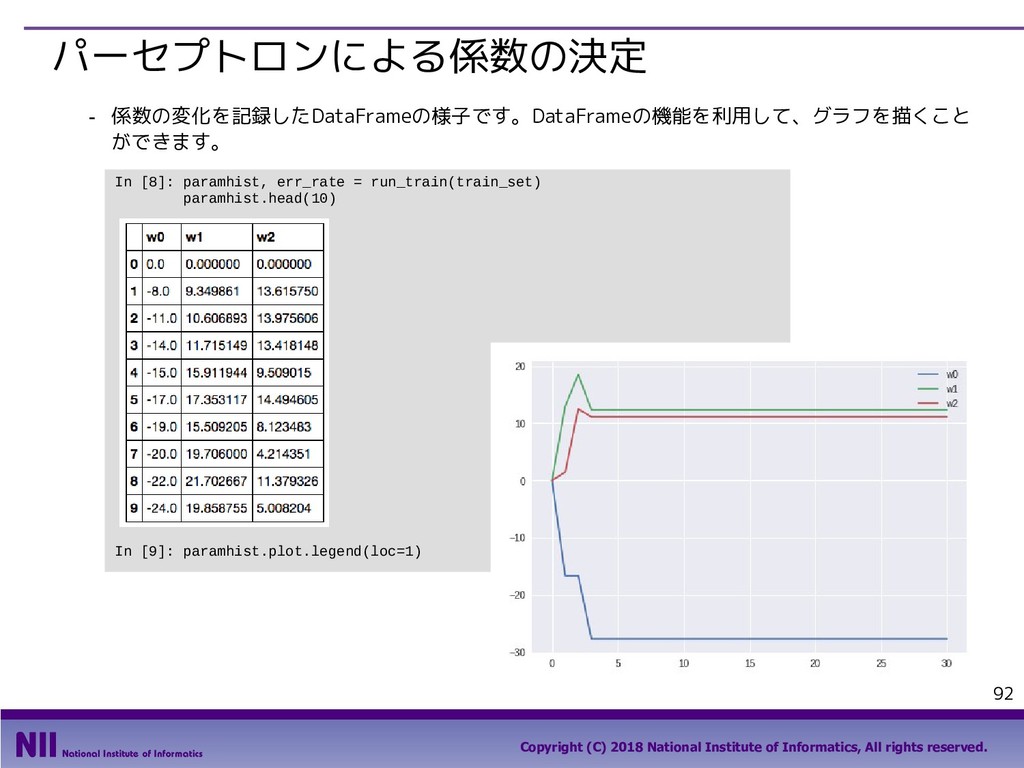
All rights reserved. 69 行のシャッフル ▪ トランプのカードを集めたDataFrameで、カードのシャッフルを行います。 - トランプのカードを集めたDataFrameを定義します。 - permutation()関数は、arrayの要素の順番をランダム入れ替えます。下記は、index属性で取り 出したindexの順番をシャッフルしています。 In [5]: face = ['king', 'queen', 'jack', 'ten', 'nine', 'eight', 'seven', 'six', 'five', 'four', 'three', 'two', 'ace'] suit = ['spades', 'clubs', 'diamonds', 'hearts'] value = range(13,0,-1) deck = DataFrame({'face': np.tile(face, 4), 'suit': np.repeat(suit, 13), 'value': np.tile(value, 4)}) deck.head() Out[5]: In [6]: np.random.permutation(deck.index) Out[6]: array([48, 33, 6, 49, 10, 28, 41, 18, 32, 36, 19, 14, 25, 46, 30, 51, 2, 31, 12, 5, 42, 4, 9, 40, 43, 13, 16, 35, 8, 1, 50, 20, 17, 22, 24, 11, 26, 47, 37, 27, 45, 29, 0, 3, 44, 34, 38, 39, 15, 21, 7, 23]) 先頭部分のデータだけを 取り出すメソッド
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
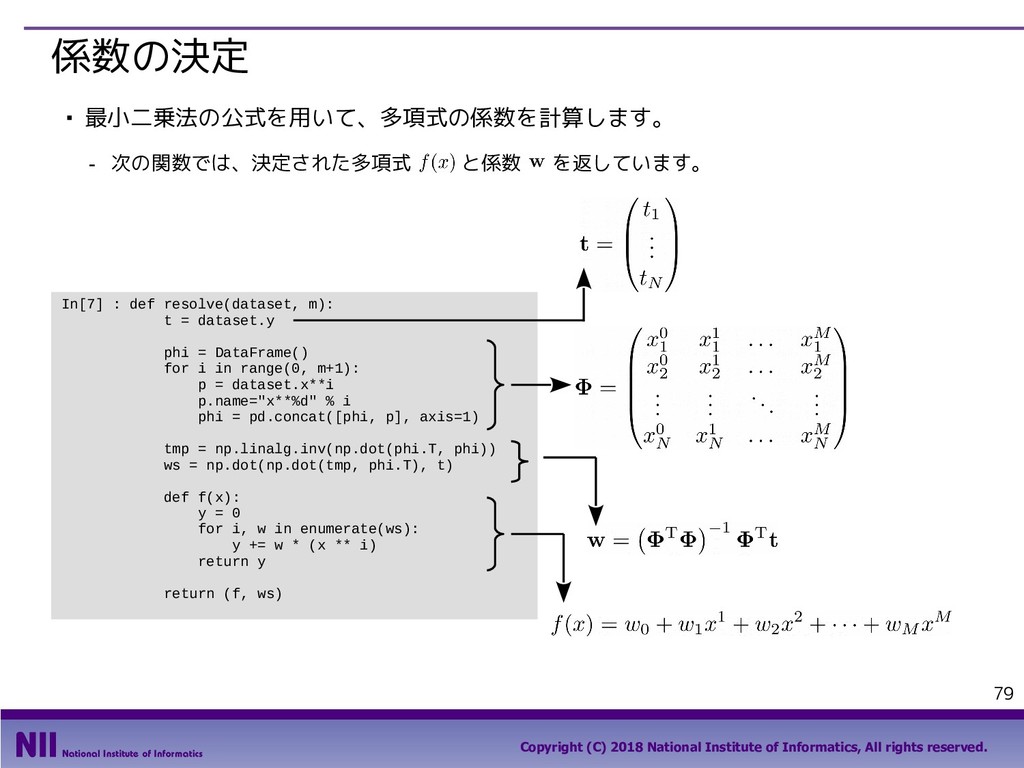{kind=link}
{kind=link}
{kind=link}
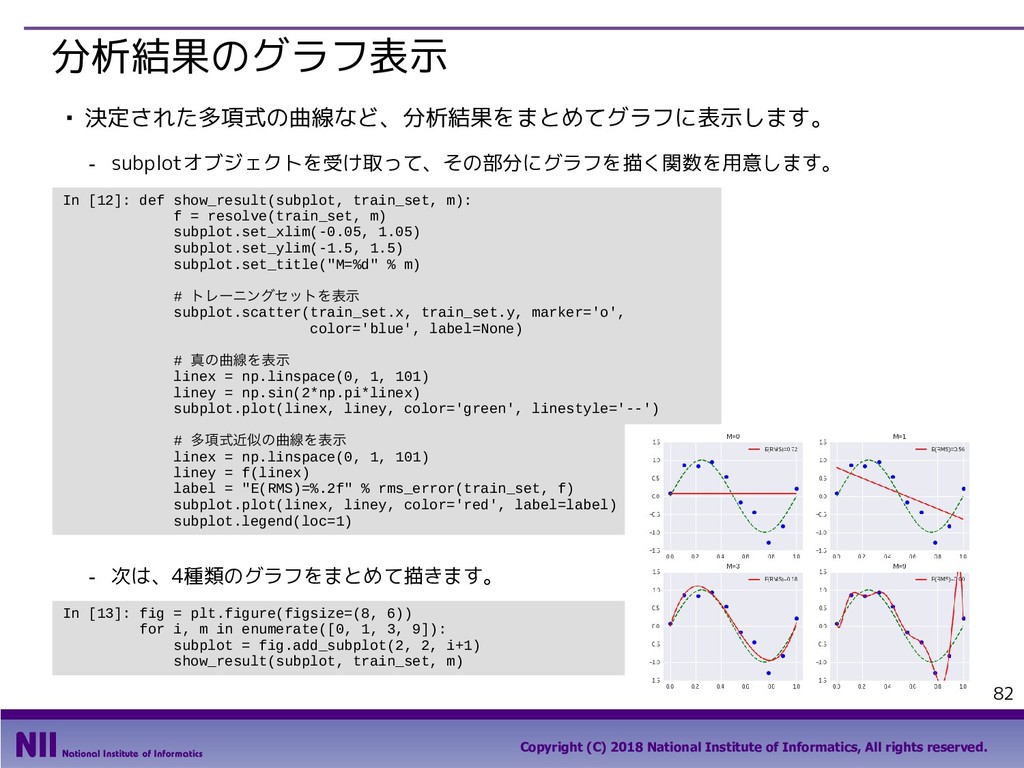{kind=link}
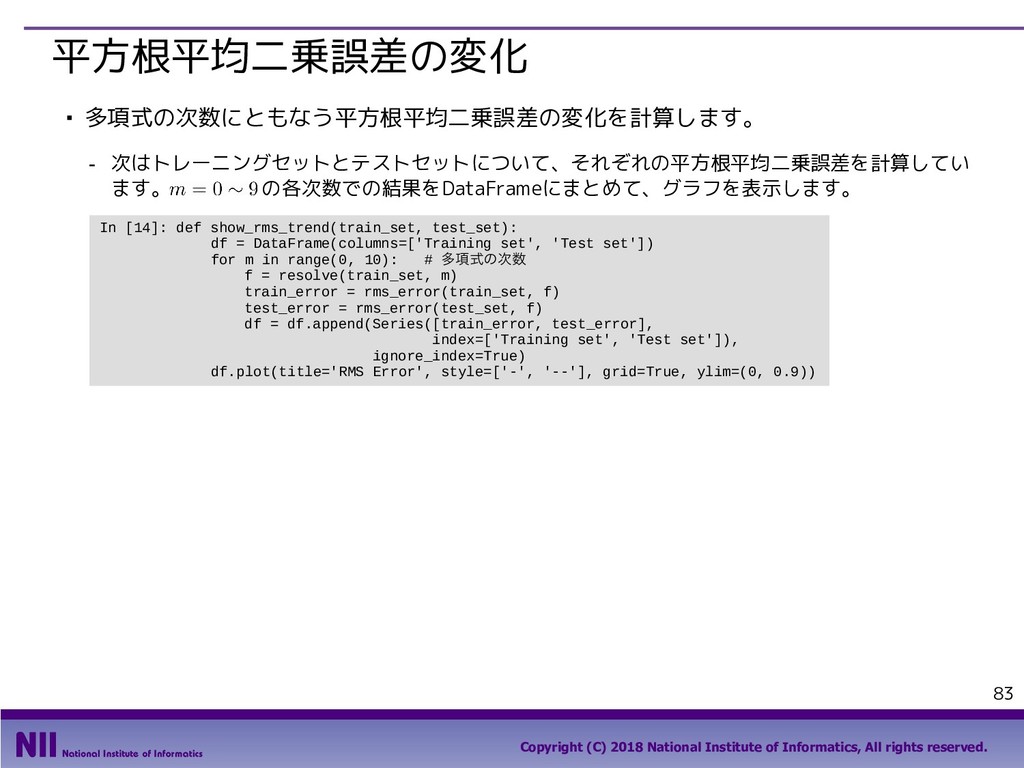{kind=link}
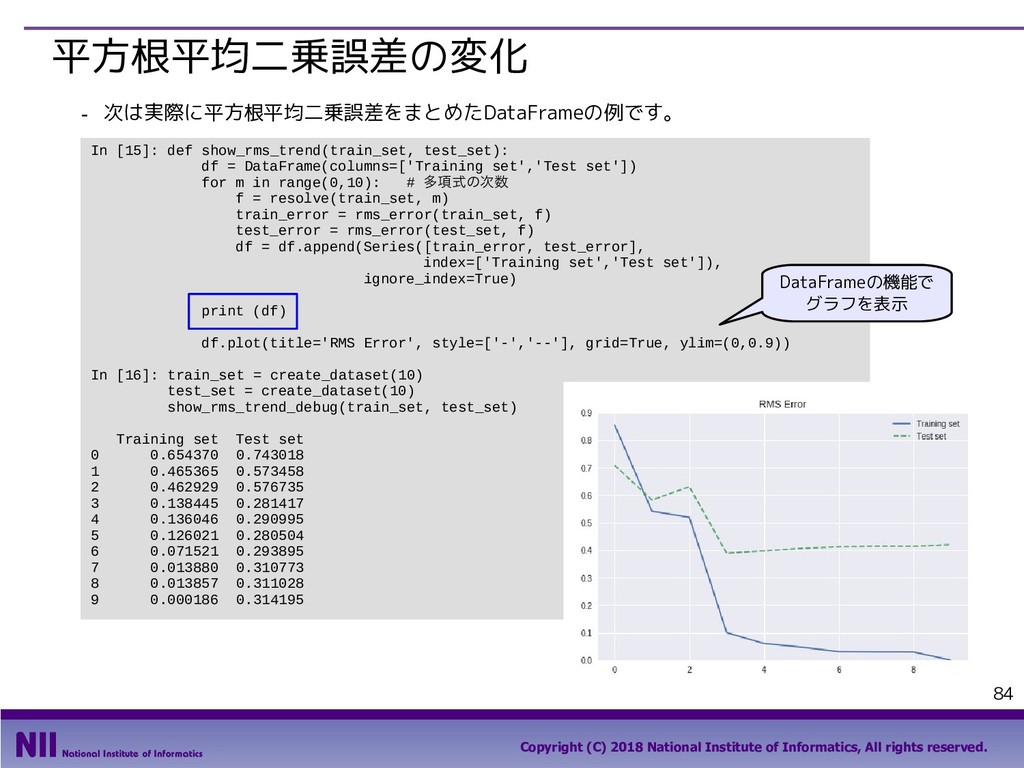{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}