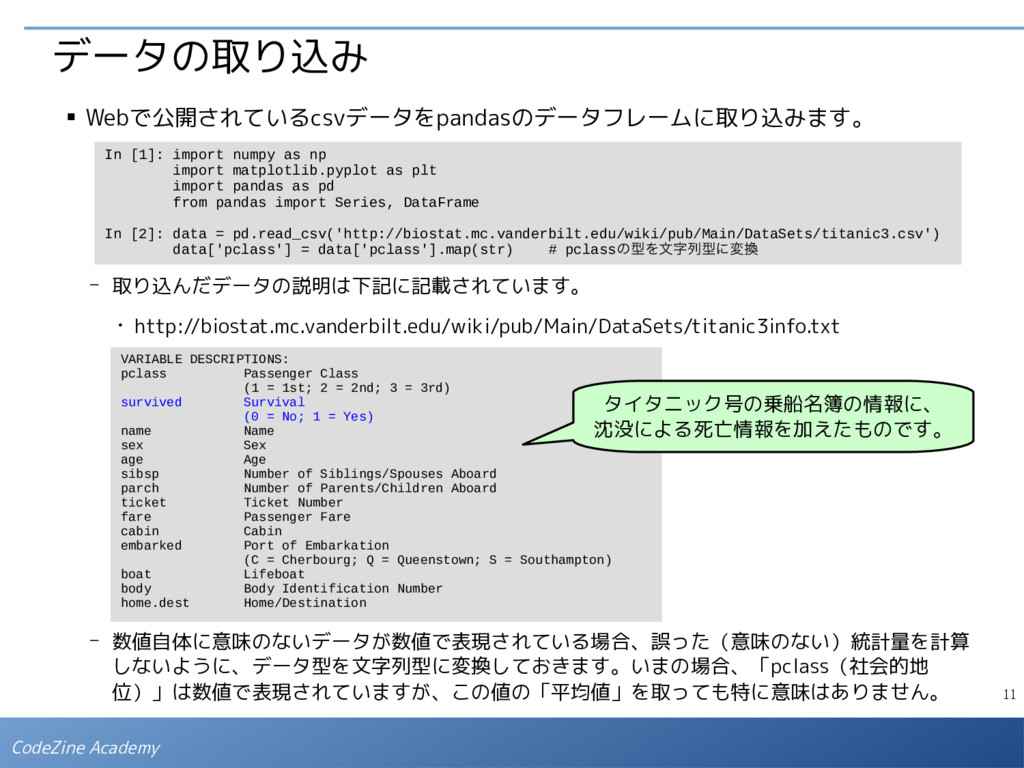
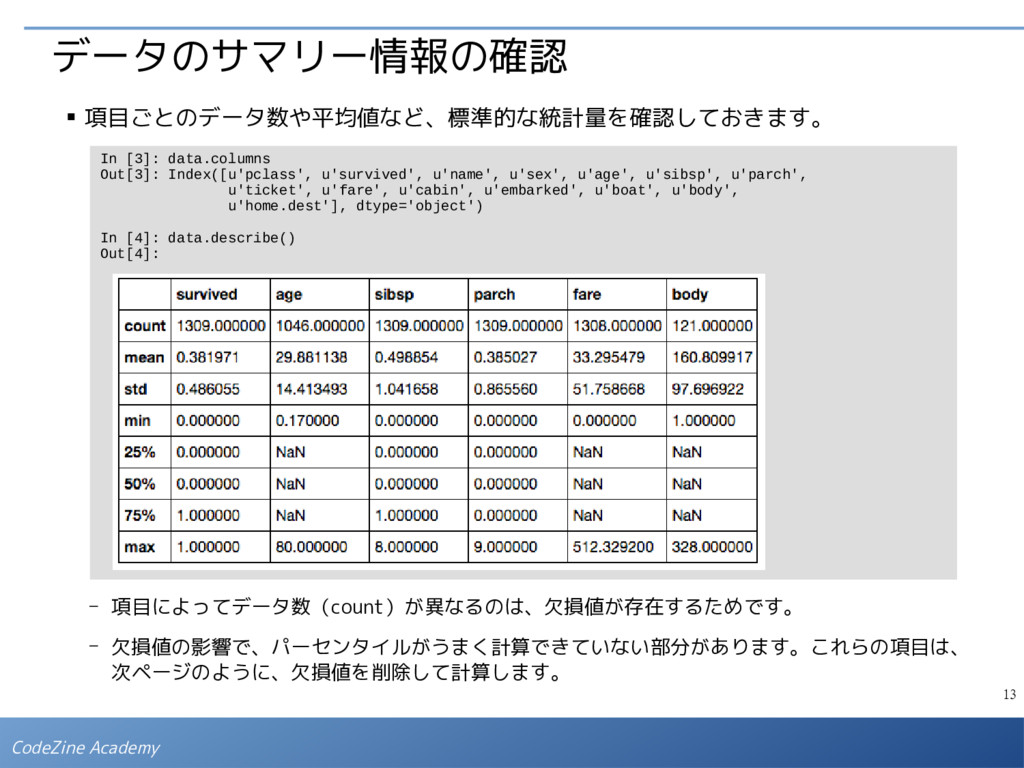
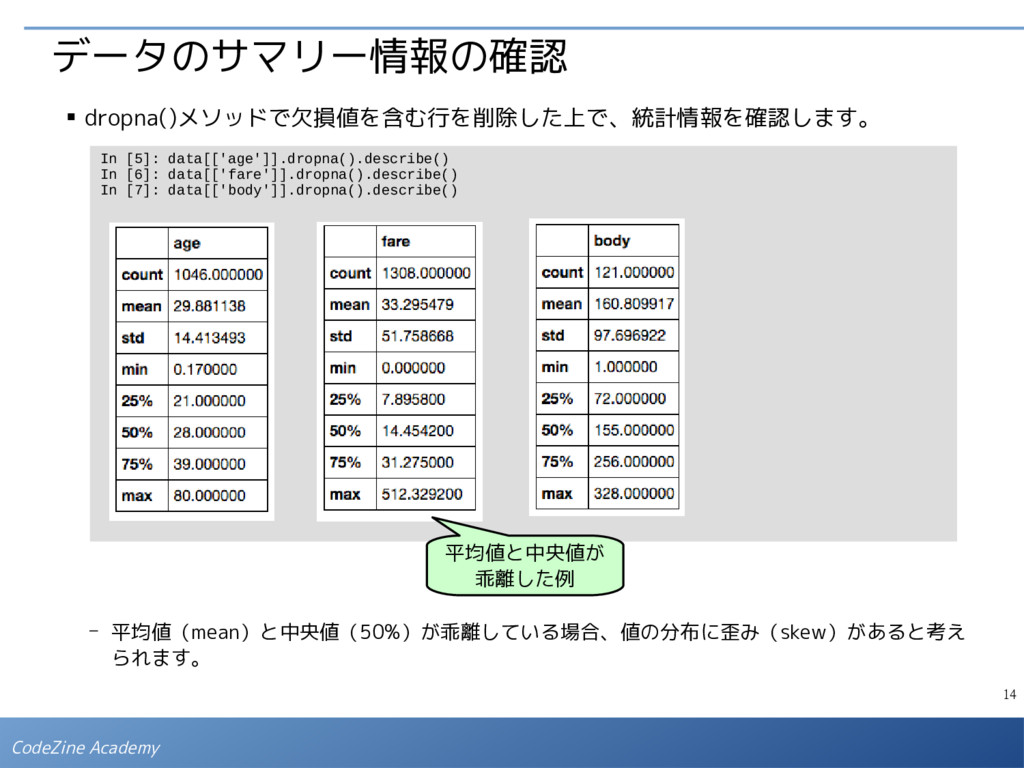
- 数値自体に意味のないデータが数値で表現されている場合、誤った(意味のない)統計量を計算 しないように、データ型を文字列型に変換しておきます。いまの場合、「pclass(社会的地 位)」は数値で表現されていますが、この値の「平均値」を取っても特に意味はありません。 In [1]: import numpy as np import matplotlib.pyplot as plt import pandas as pd from pandas import Series, DataFrame In [2]: data = pd.read_csv('http://biostat.mc.vanderbilt.edu/wiki/pub/Main/DataSets/titanic3.csv') data['pclass'] = data['pclass'].map(str) # pclassの型を文字列型に変換 VARIABLE DESCRIPTIONS: pclass Passenger Class (1 = 1st; 2 = 2nd; 3 = 3rd) survived Survival (0 = No; 1 = Yes) name Name sex Sex age Age sibsp Number of Siblings/Spouses Aboard parch Number of Parents/Children Aboard ticket Ticket Number fare Passenger Fare cabin Cabin embarked Port of Embarkation (C = Cherbourg; Q = Queenstown; S = Southampton) boat Lifeboat body Body Identification Number home.dest Home/Destination タイタニック号の乗船名簿の情報に、 沈没による死亡情報を加えたものです。
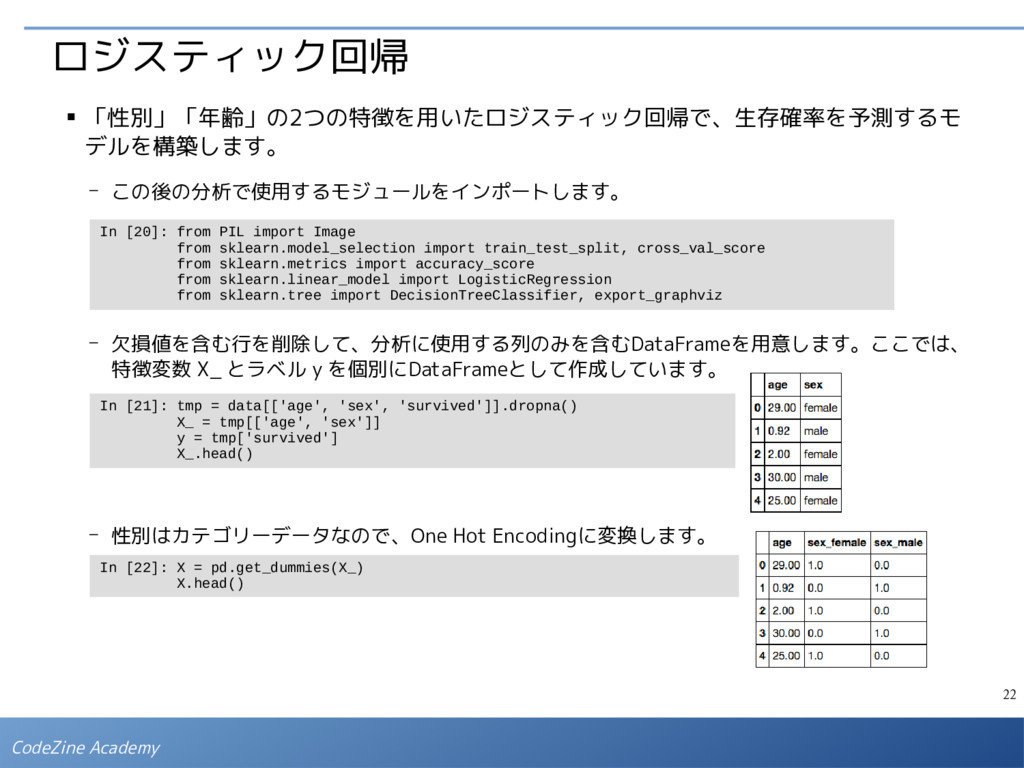
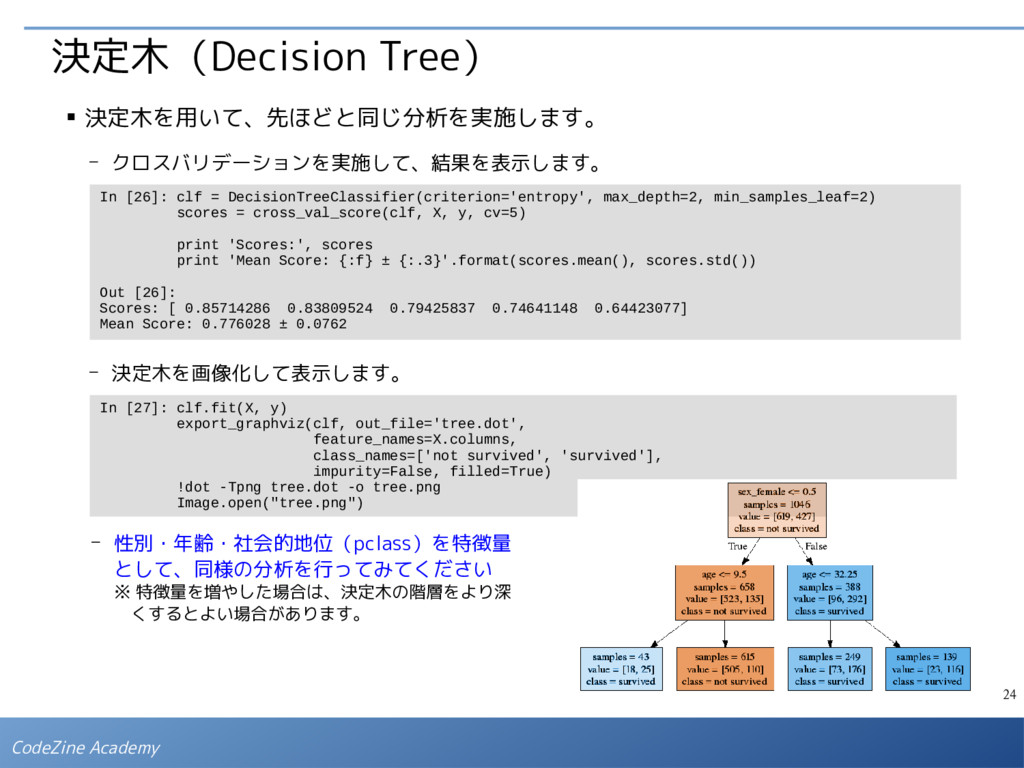
欠損値を含む行を削除して、分析に使用する列のみを含むDataFrameを用意します。ここでは、 特徴変数 X_ とラベル y を個別にDataFrameとして作成しています。 - 性別はカテゴリーデータなので、One Hot Encodingに変換します。 In [20]: from PIL import Image from sklearn.model_selection import train_test_split, cross_val_score from sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier, export_graphviz In [22]: X = pd.get_dummies(X_) X.head() In [21]: tmp = data[['age', 'sex', 'survived']].dropna() X_ = tmp[['age', 'sex']] y = tmp['survived'] X_.head()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
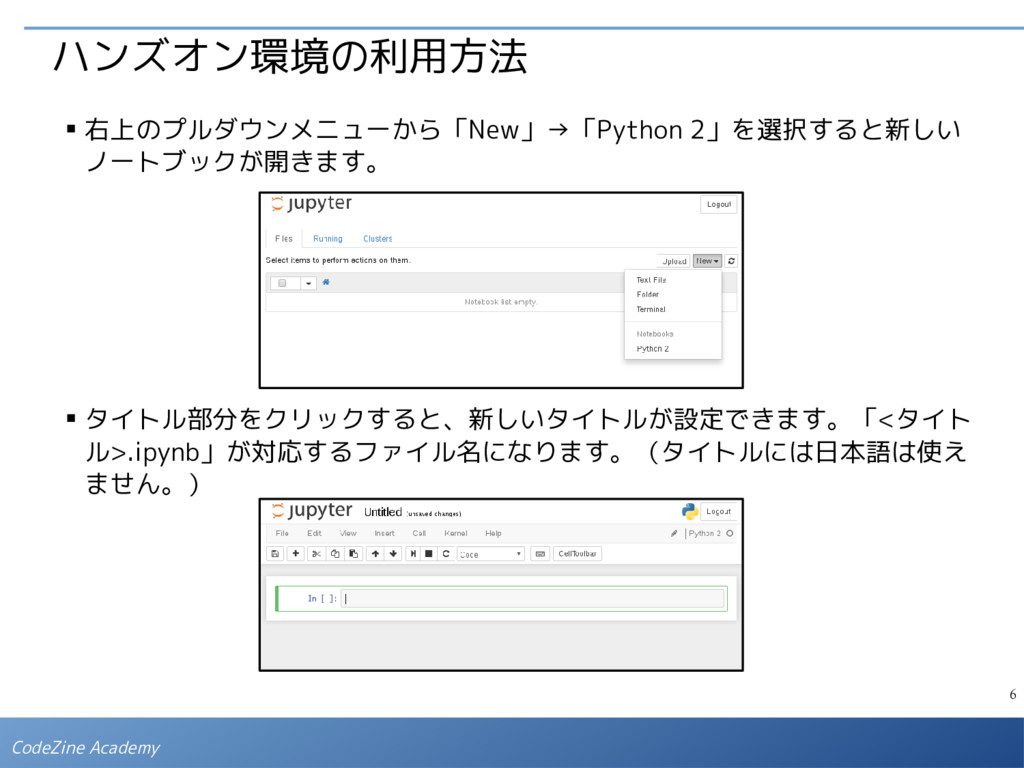{kind=link}
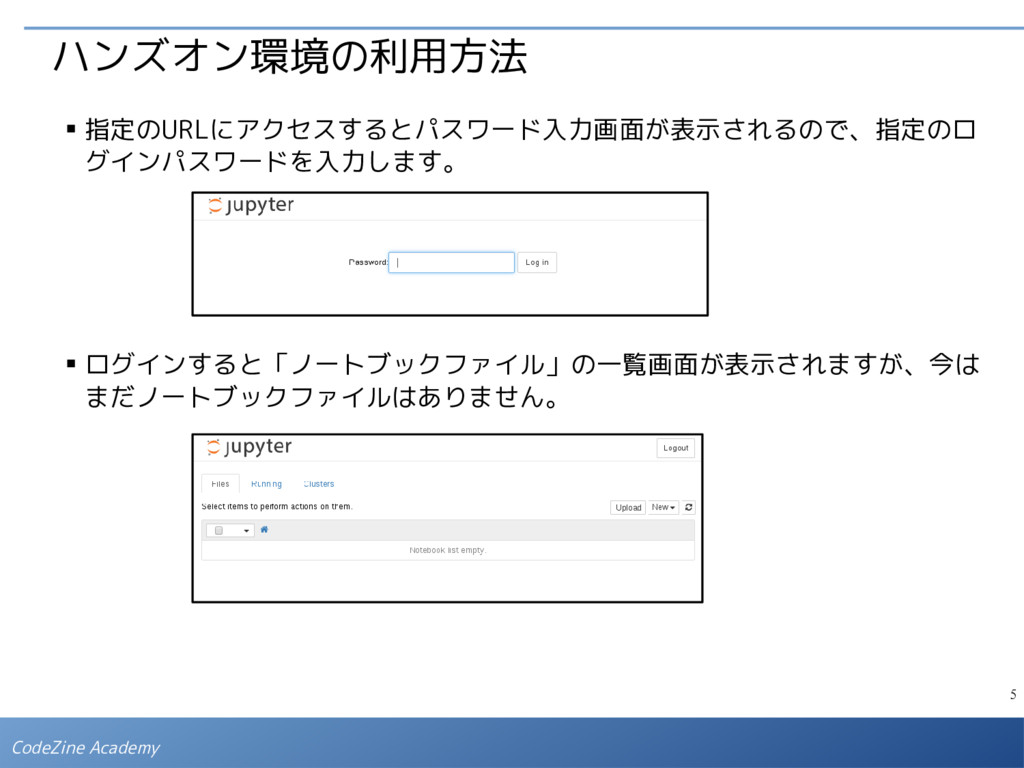
![7 CodeZine Academy ハンズオン環境の利用方法 ▪ ノートブック上では、セルにプログラムコードを入力して、「▶」ボタン、も しくは [Ctrl] + [Enter]](https://files.speakerdeck.com/presentations/bb647d6ed3734a6b9ca71bf4be66f679/slide_6.jpg){kind=link}
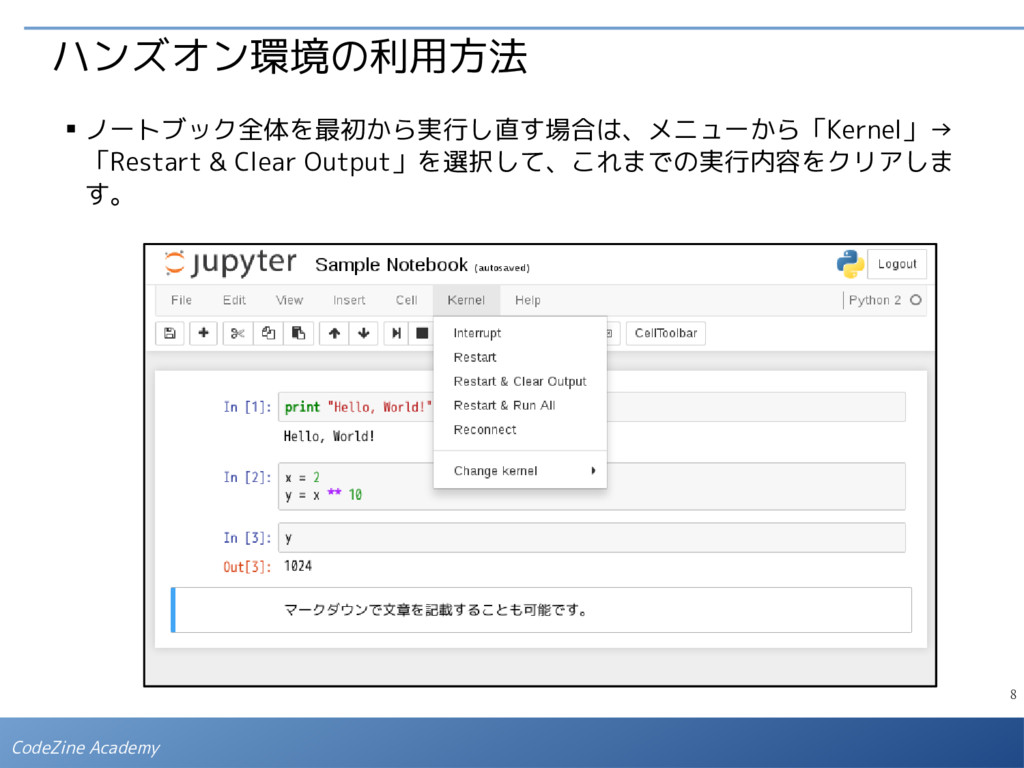{kind=link}
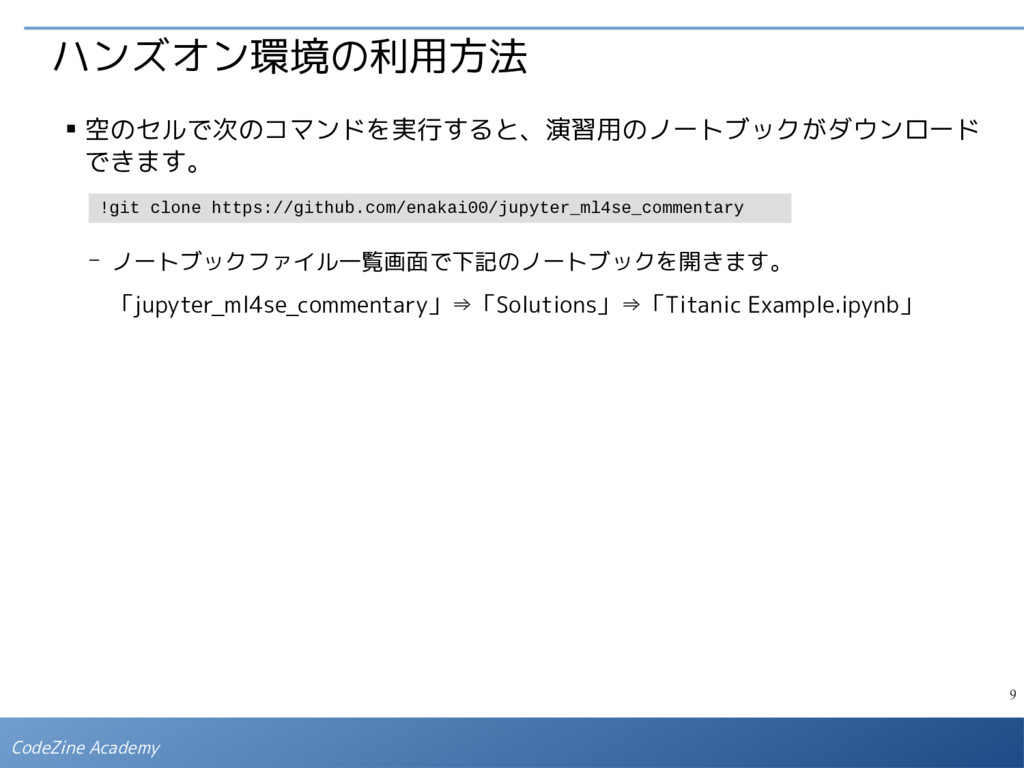{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![17 CodeZine Academy 数値データの相関の可視化 ▪ 2つの数値データの関係性を見るときは、散布図で可視化します。 - 例として、年齢(age)と料金(fare)の関係を散布図で表示します。 In [10]:](https://files.speakerdeck.com/presentations/bb647d6ed3734a6b9ca71bf4be66f679/slide_16.jpg){kind=link}
![18 CodeZine Academy カテゴリーデータと数値データの相関の可視化 ▪ カテゴリーデータと数値データの関係性を見るときは、箱ひげ図で可視化します。 - 例として、社会的地位(pclass)と料金(fare)の関係を箱ひげ図で表示します。 In [11]:](https://files.speakerdeck.com/presentations/bb647d6ed3734a6b9ca71bf4be66f679/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}