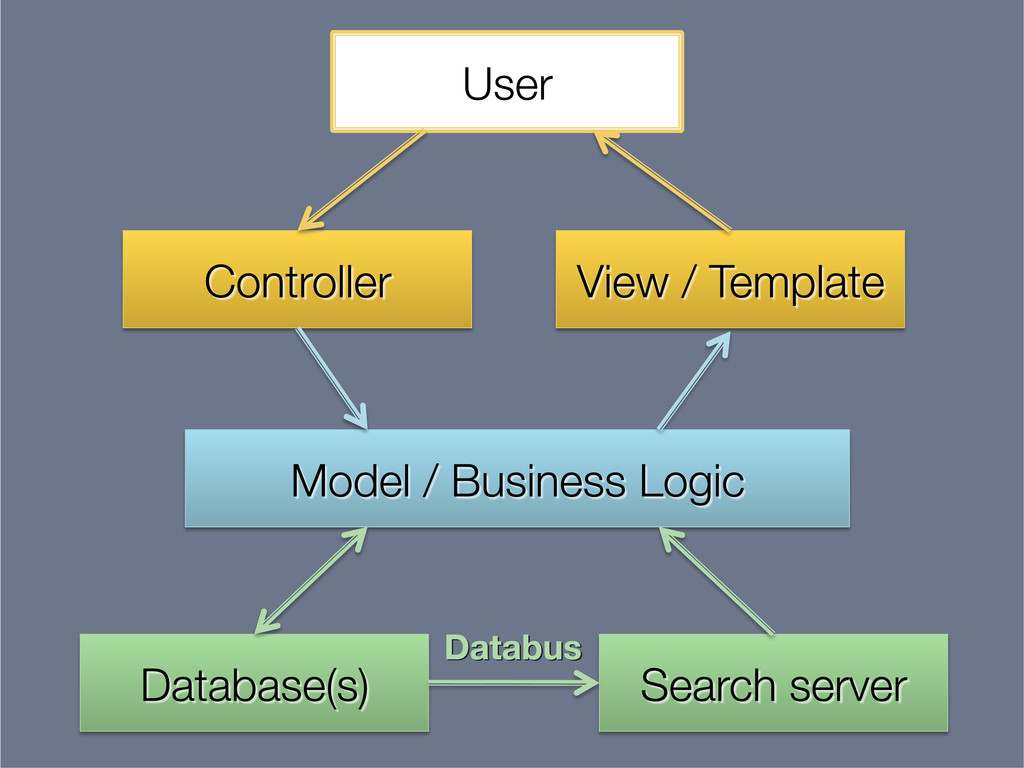
While building Rapportive, we learnt a few things about dealing with data — especially data in large volumes, with complex structure, that is constantly changing. And we've developed some patterns for thinking about data and processing in ways that keeps us sane.
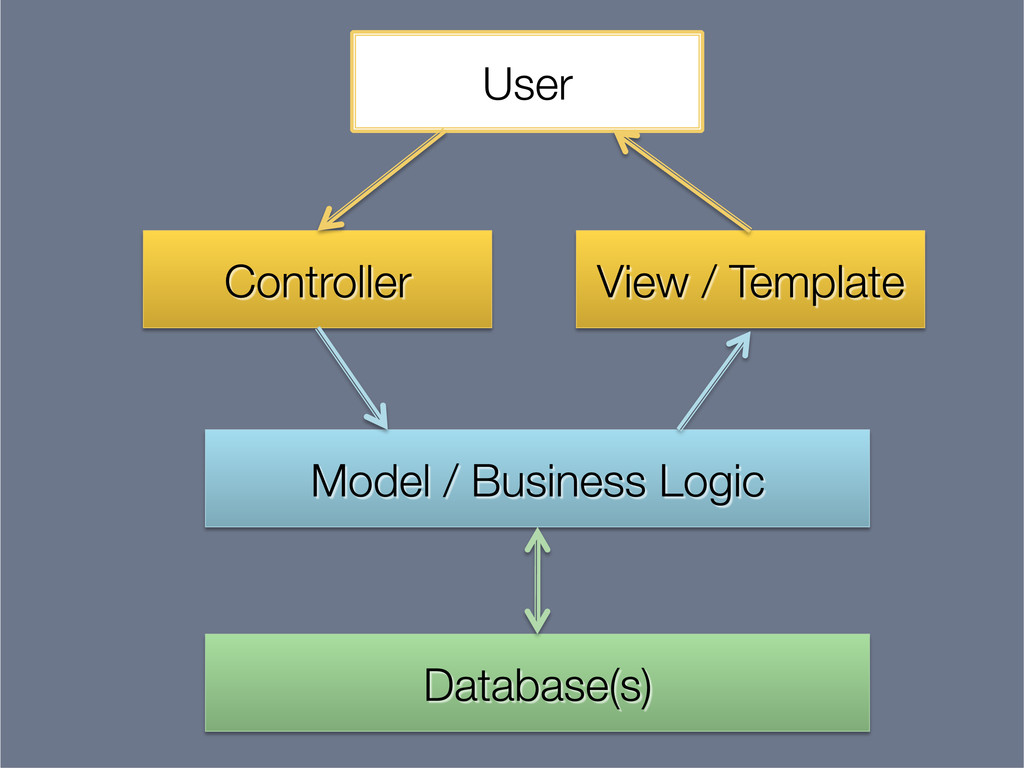
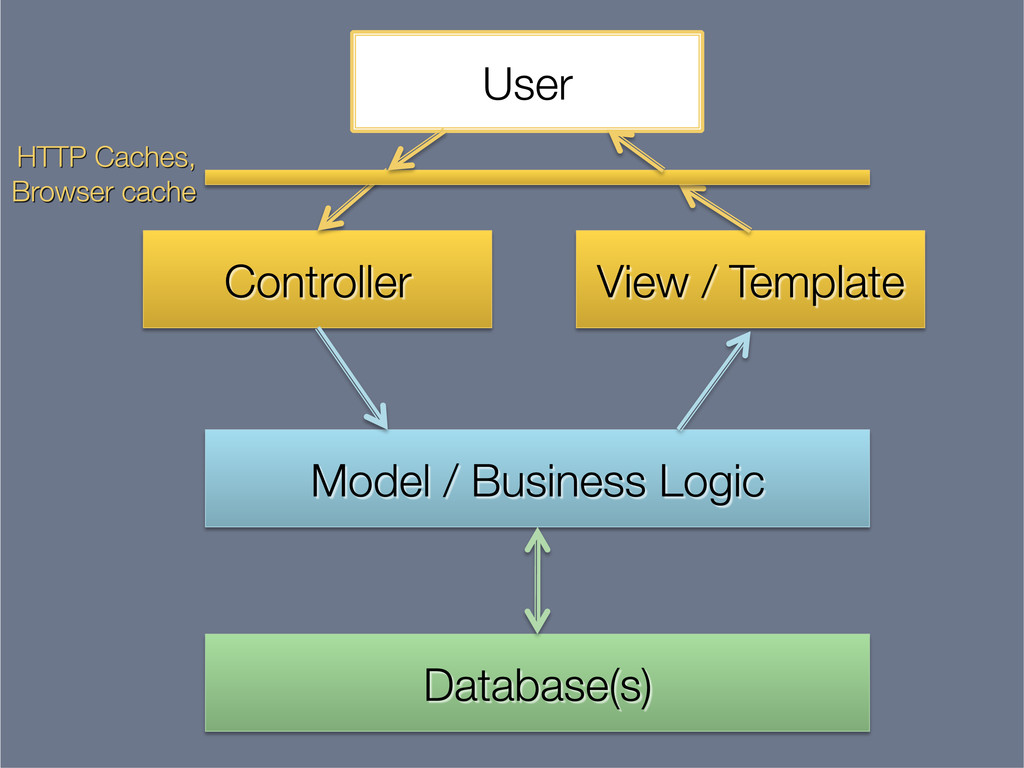
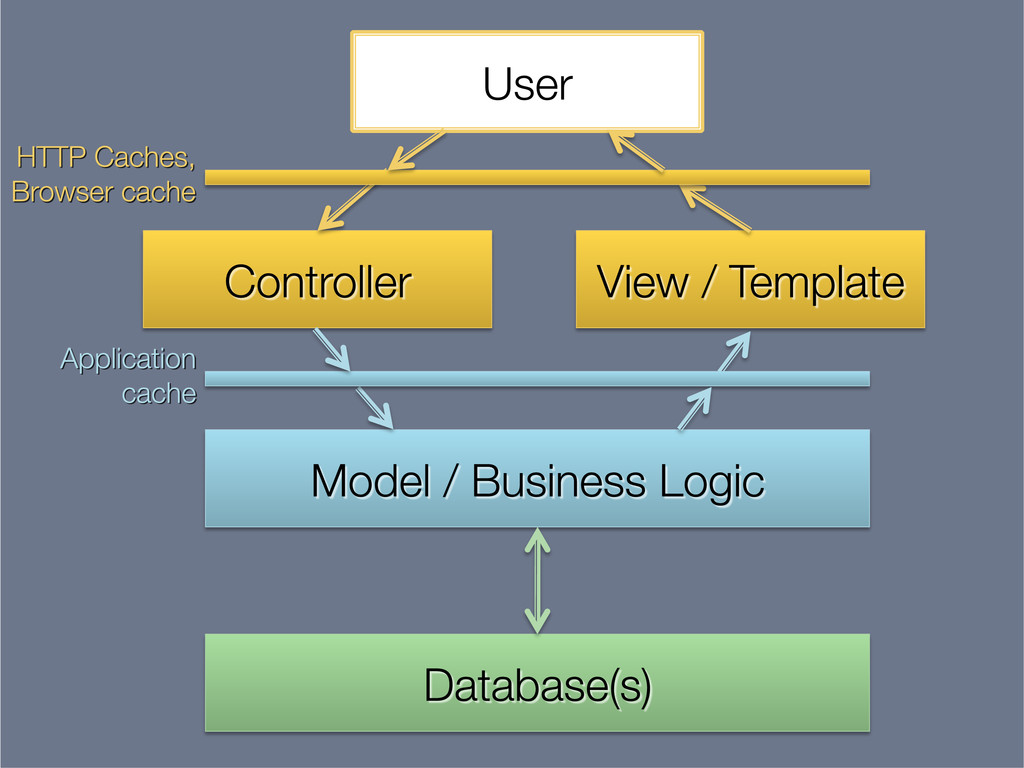
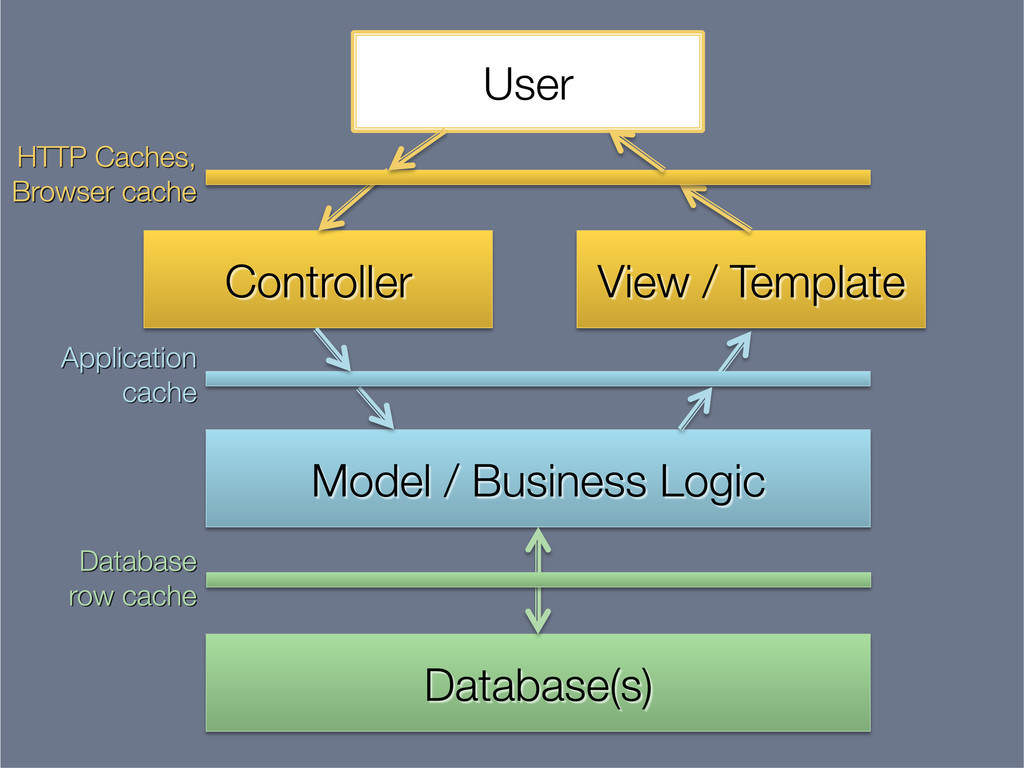
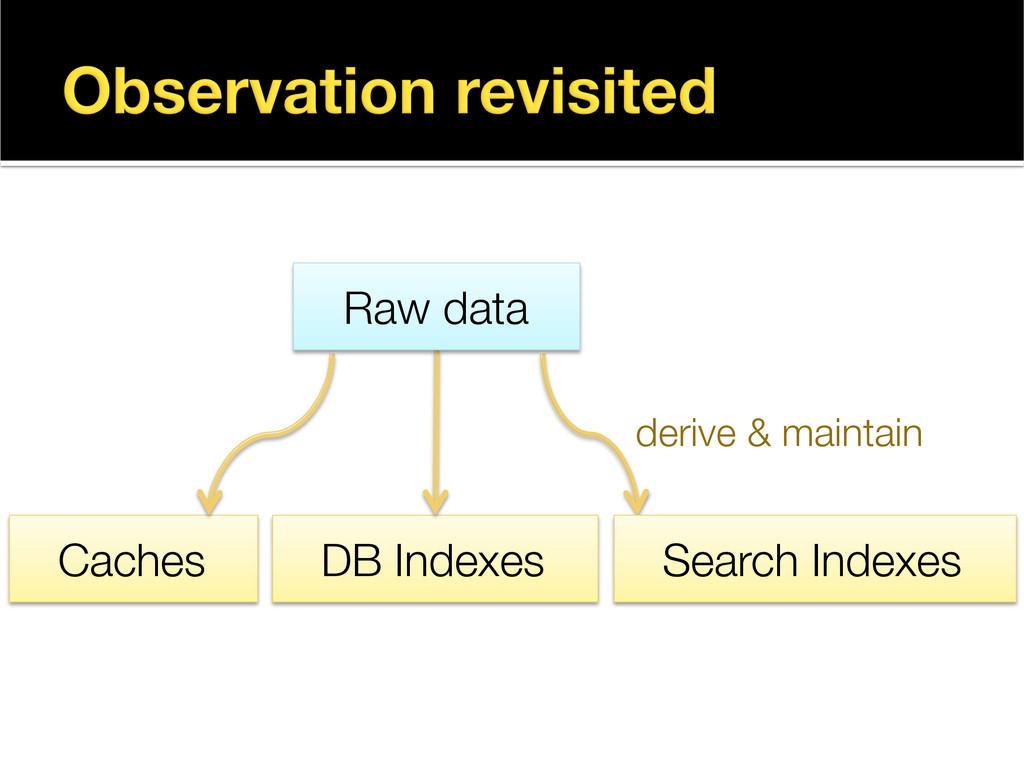
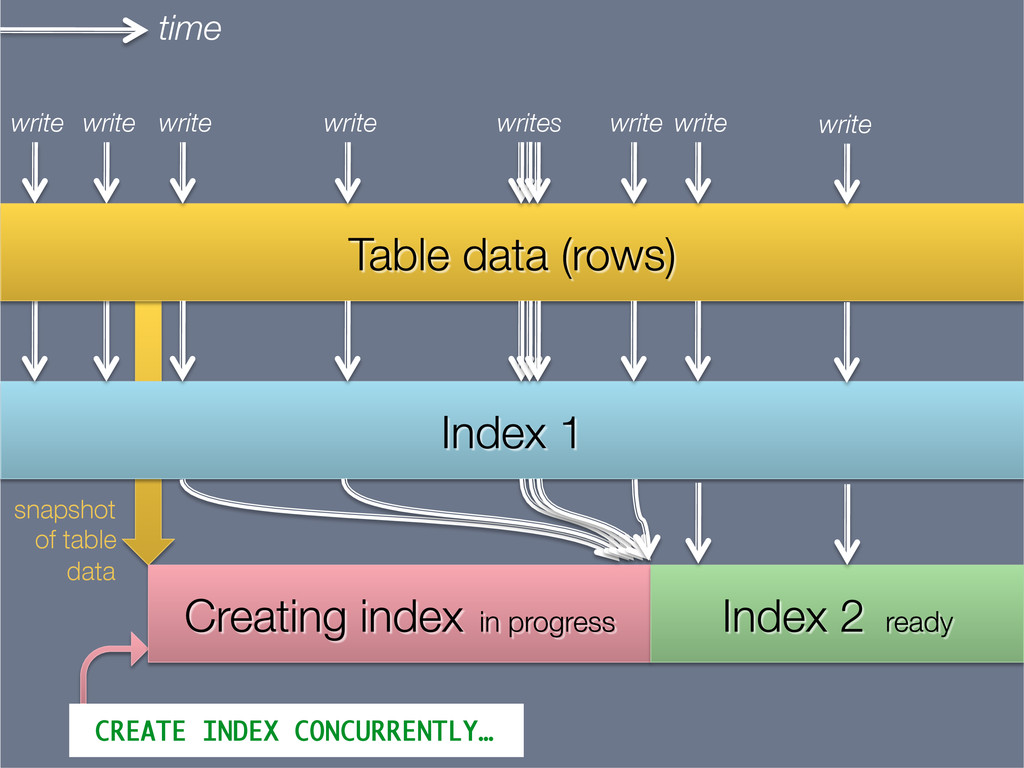
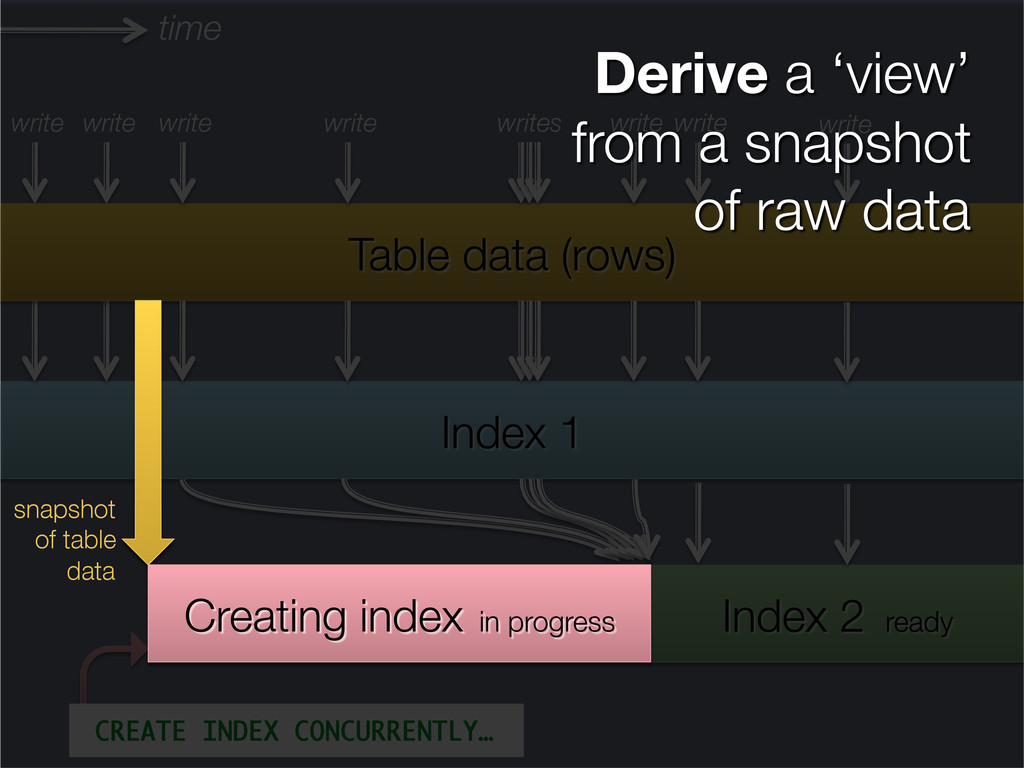
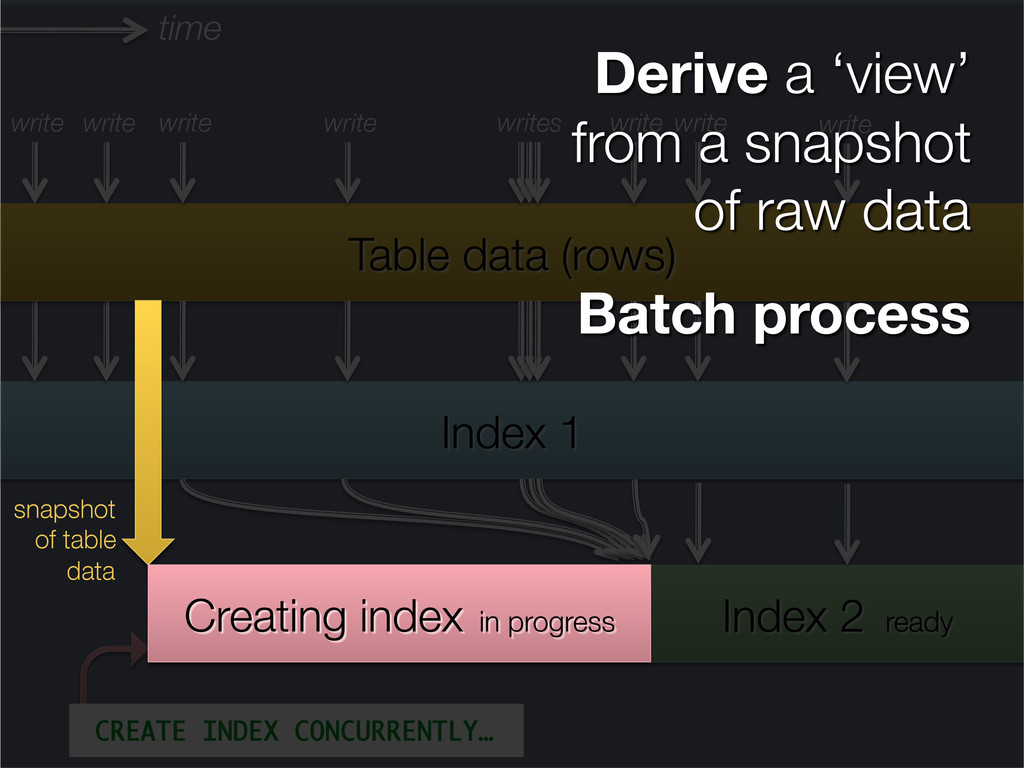
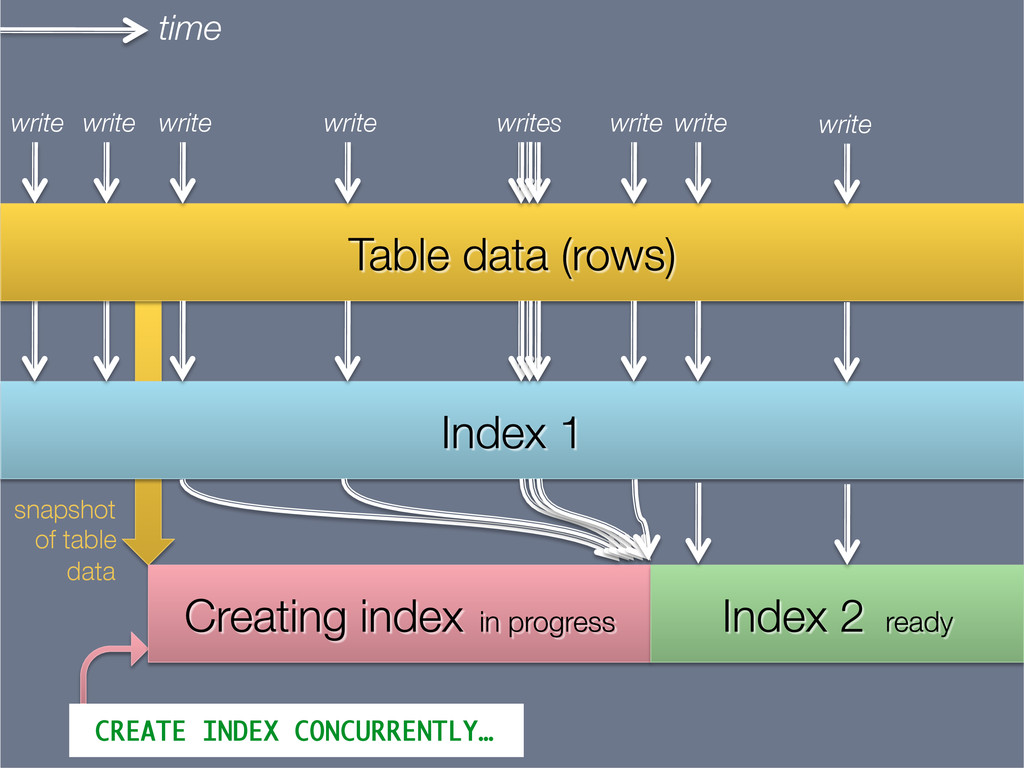
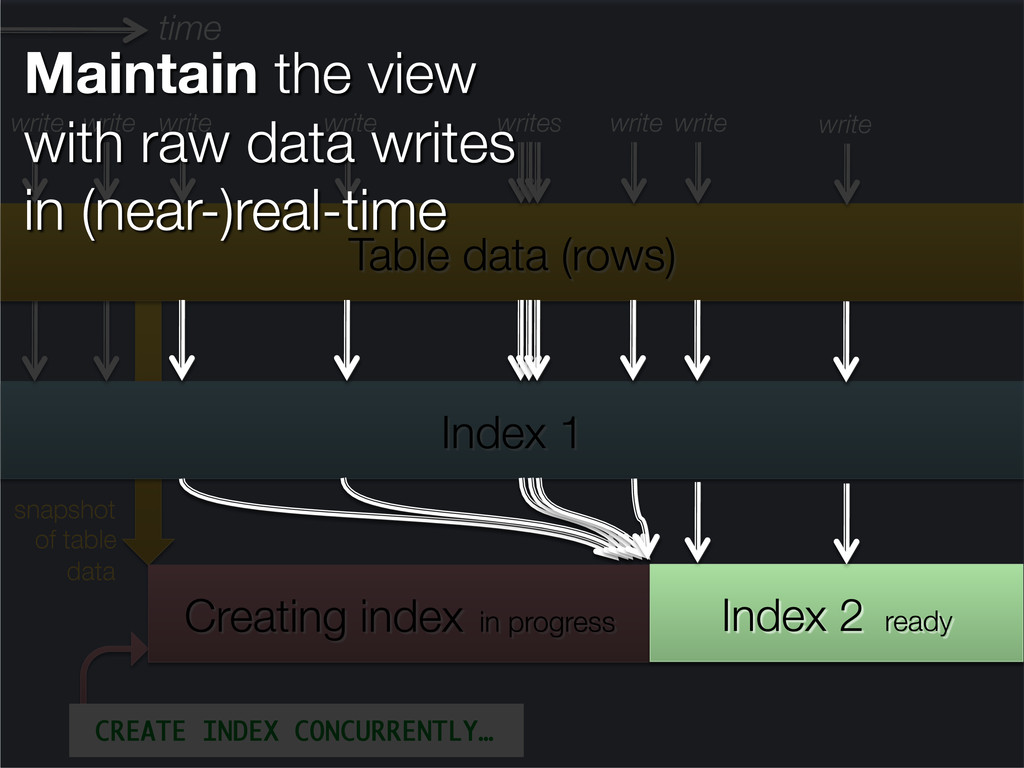
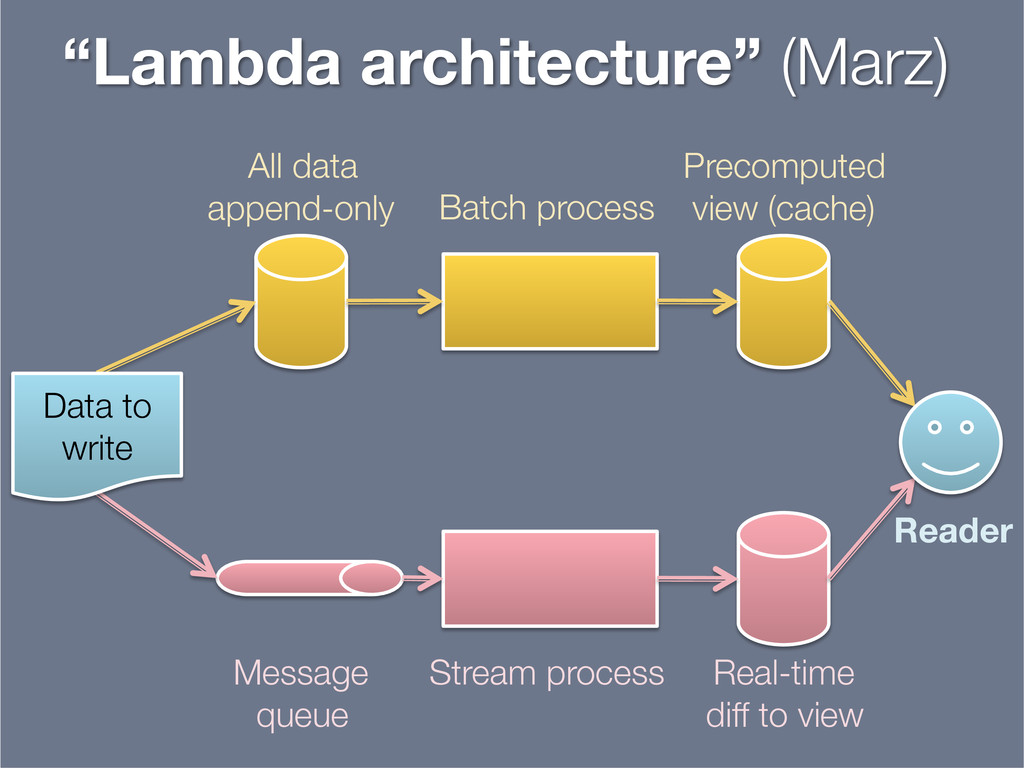
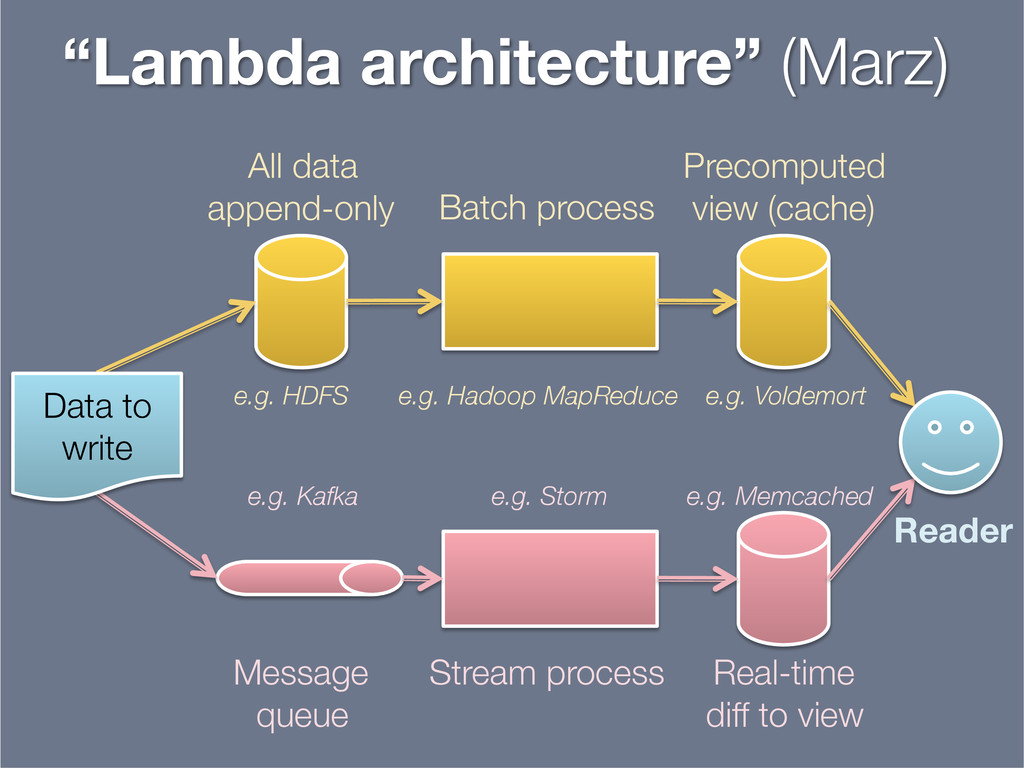
This presentation explores the idea of deriving secondary, read-optimised datasets from a primary, raw, write-optimised dataset. That idea is the common pattern behind caches, database indexes and full-text indexes.
The content is related to my blog post on precomputed caches and data dependencies (http://martin.kleppmann.com/2012/10/01/rethinking-caching-in-web-apps.html), though approaching the topic from a different angle.
Talk given at Wonga, London, 11 January 2013.
![Martin Kleppmann • [email protected] • http://martinkl.com](https://files.speakerdeck.com/presentations/768ce7403e3801305d8c1231380e44fa/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
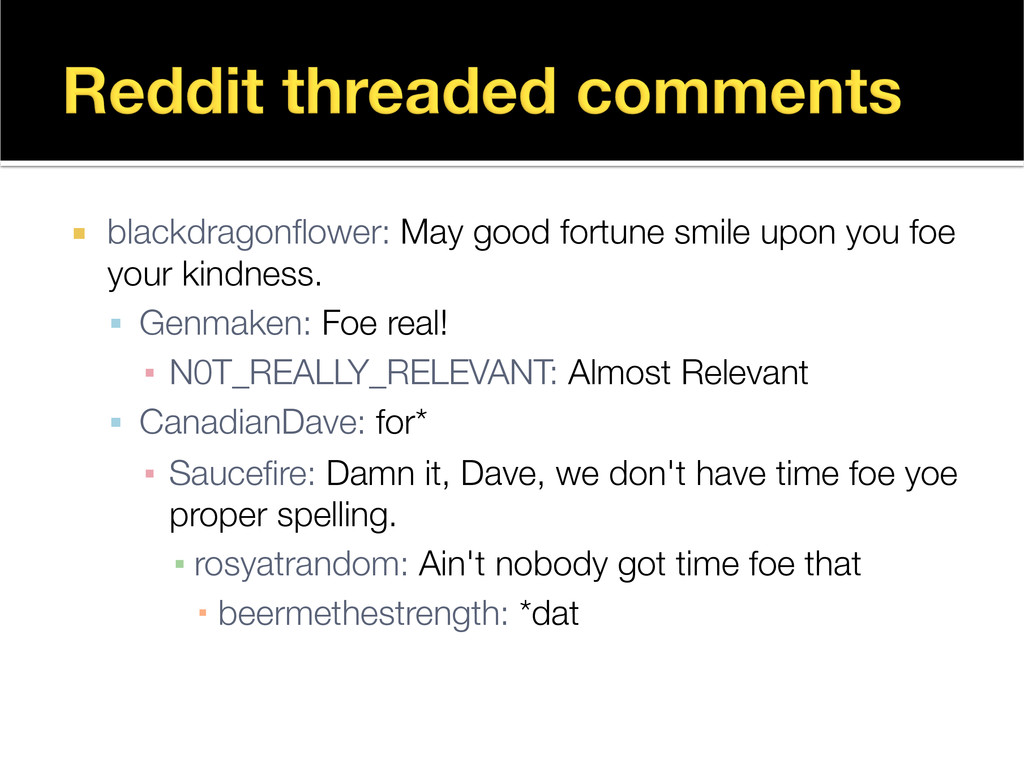{kind=link}
{kind=link}
{kind=link}
{kind=link}
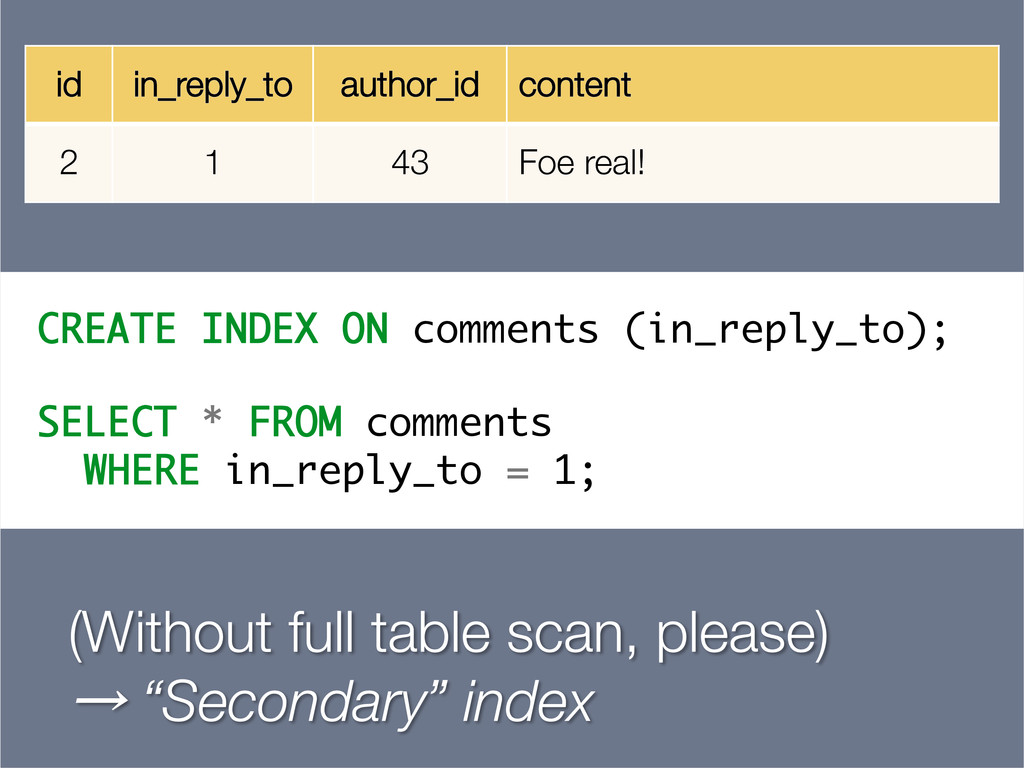{kind=link}
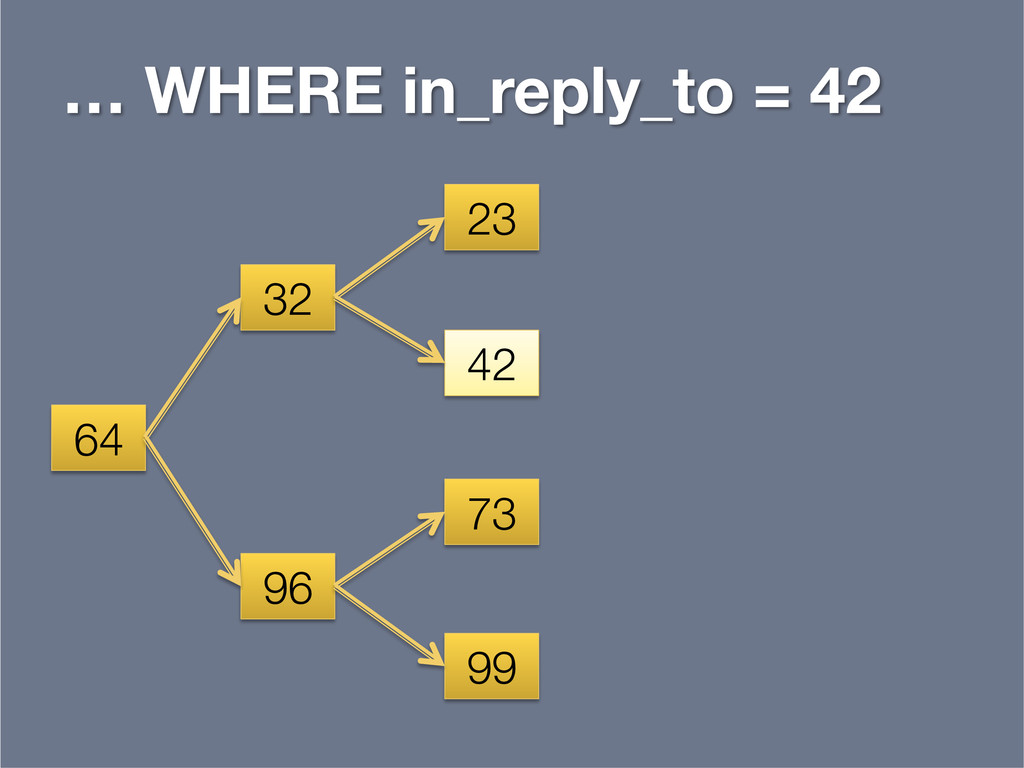{kind=link}
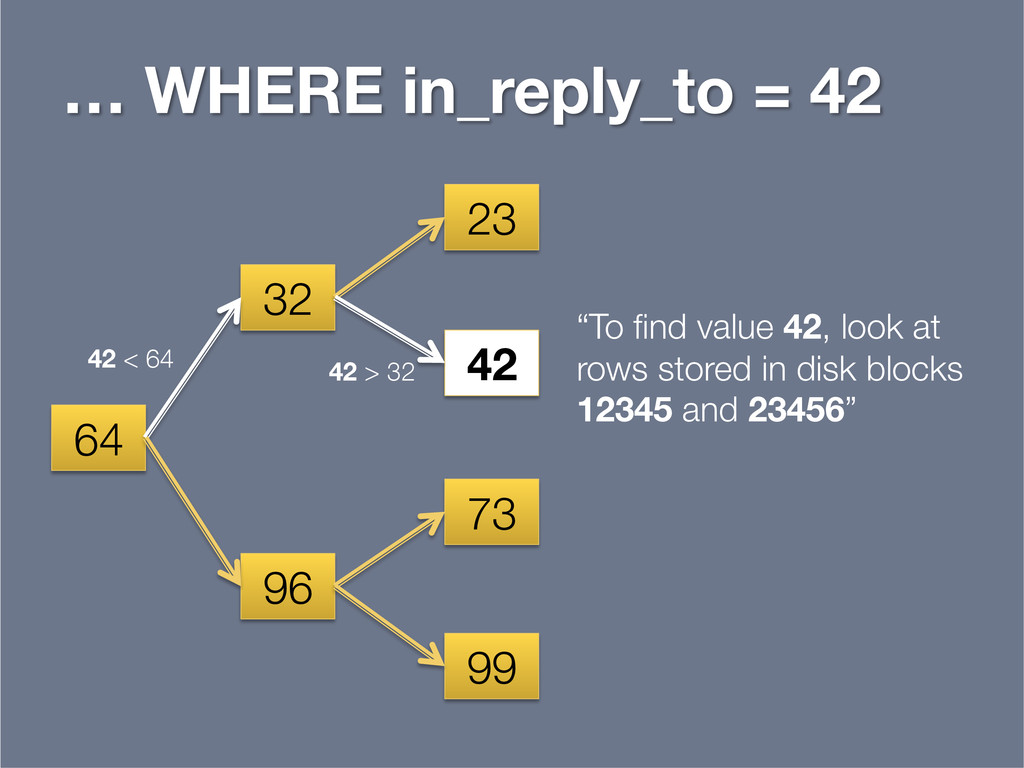{kind=link}
{kind=link}
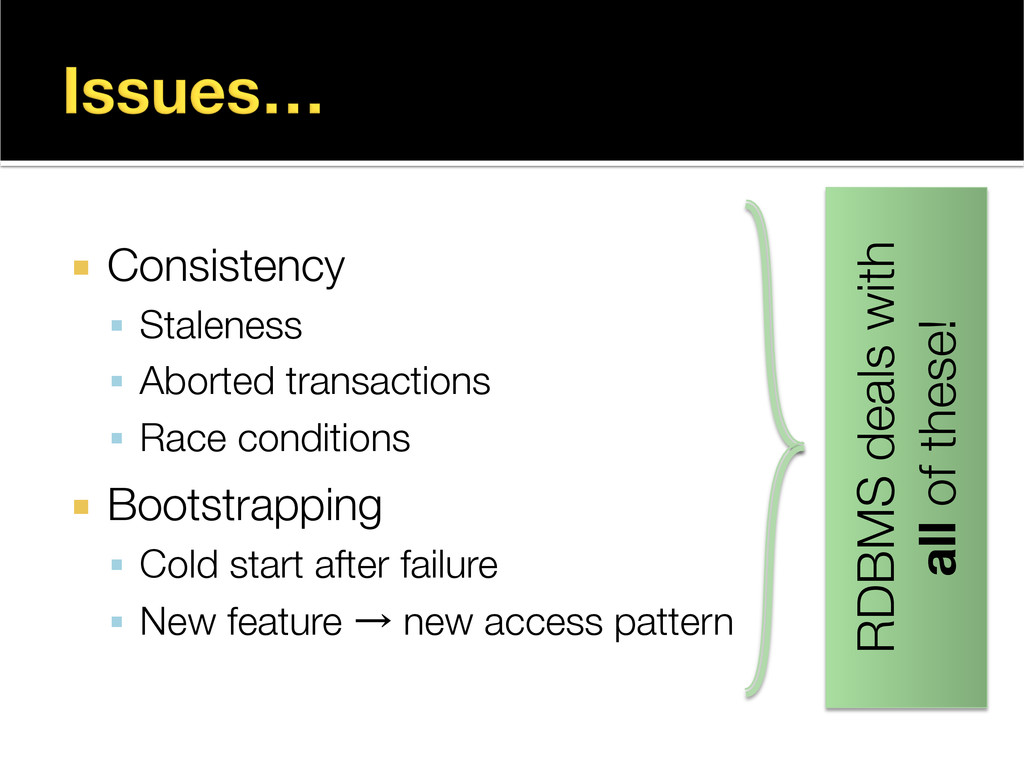{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
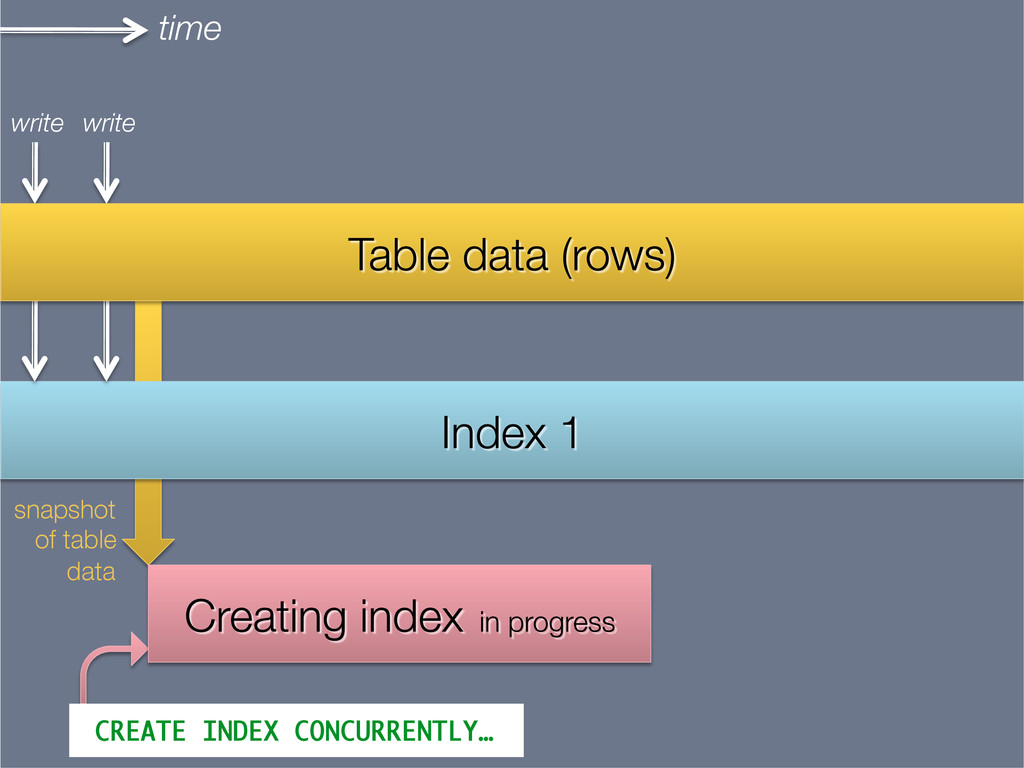{kind=link}
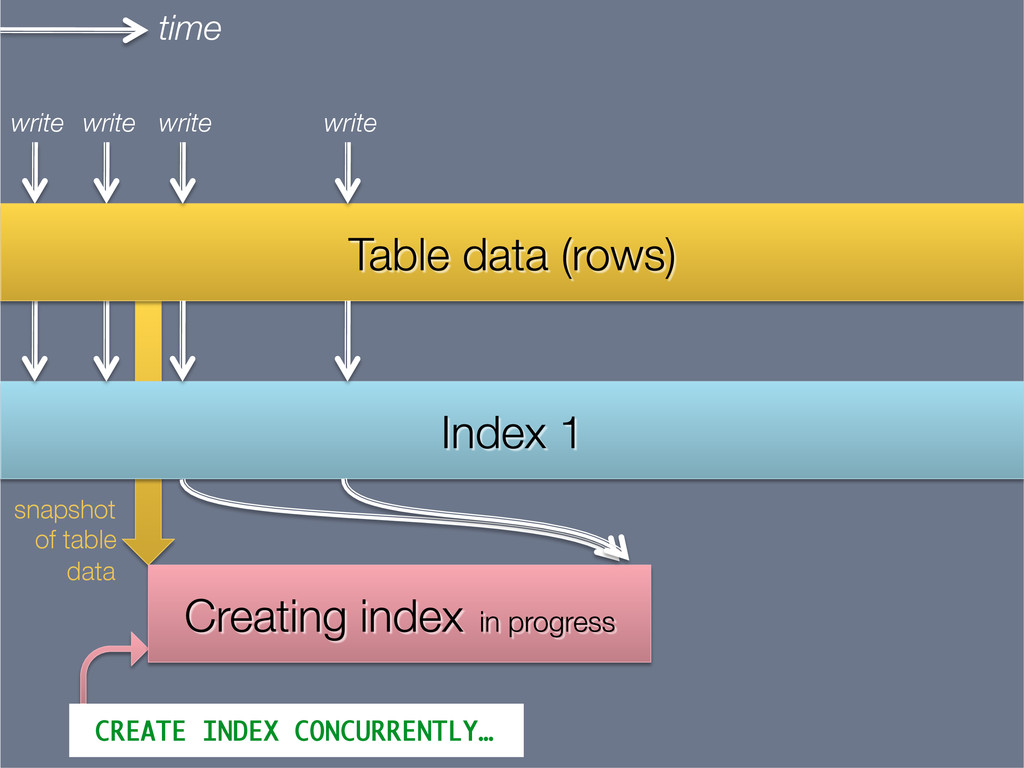{kind=link}
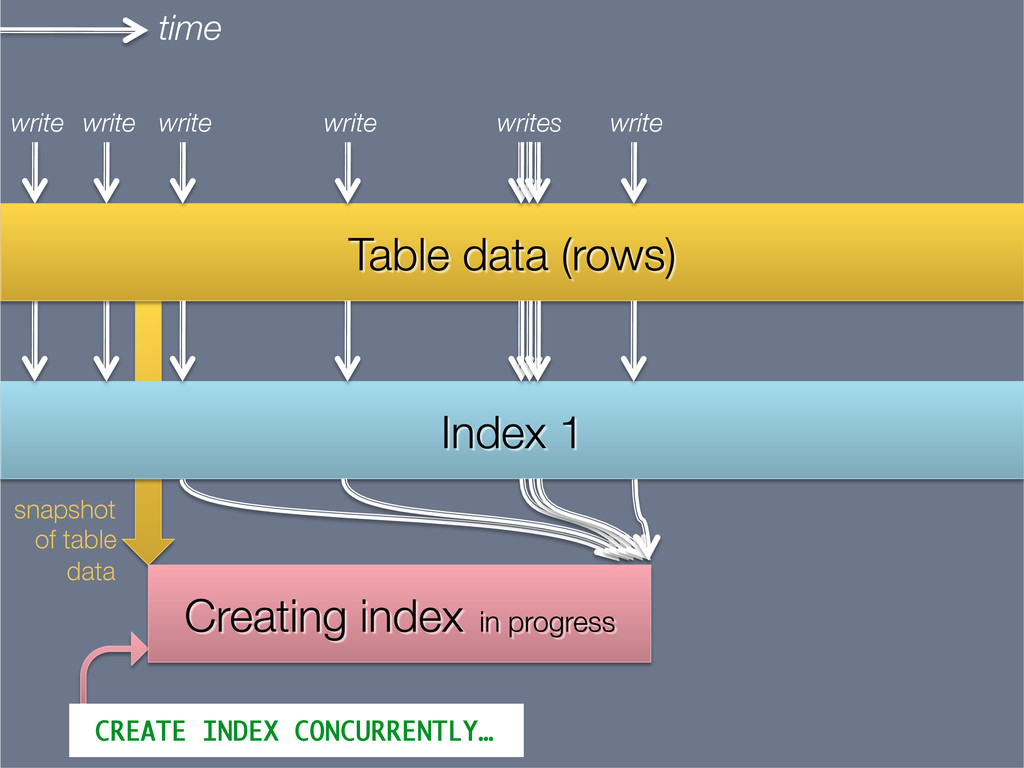{kind=link}
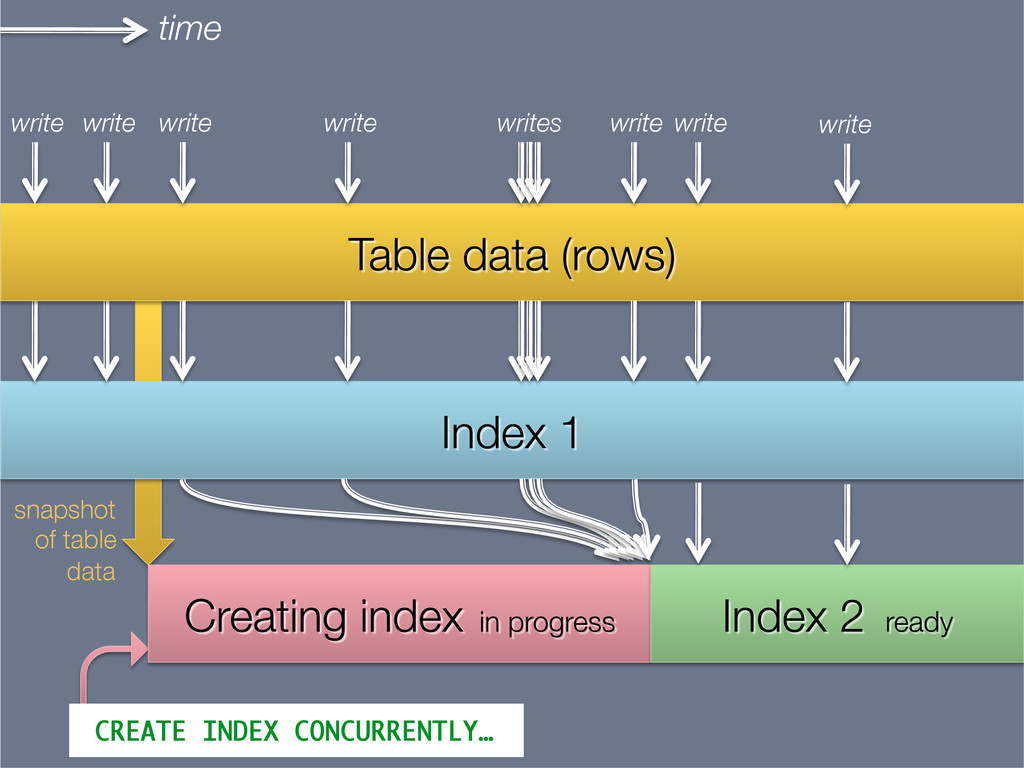{kind=link}
{kind=link}
{kind=link}
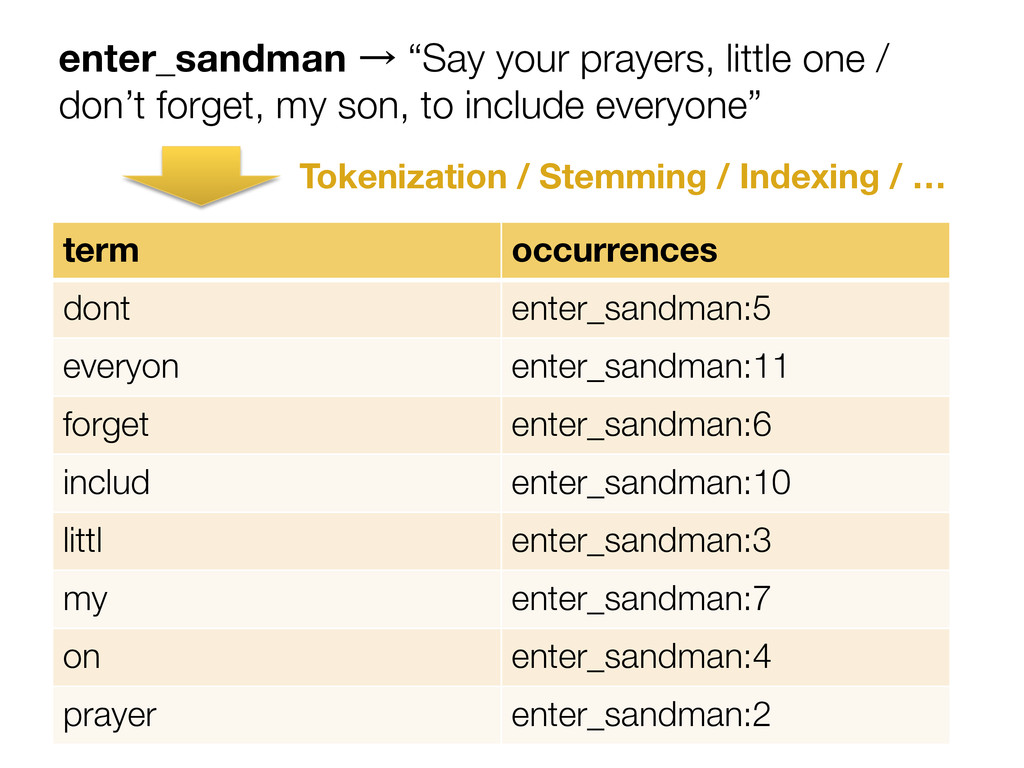{kind=link}
{kind=link}
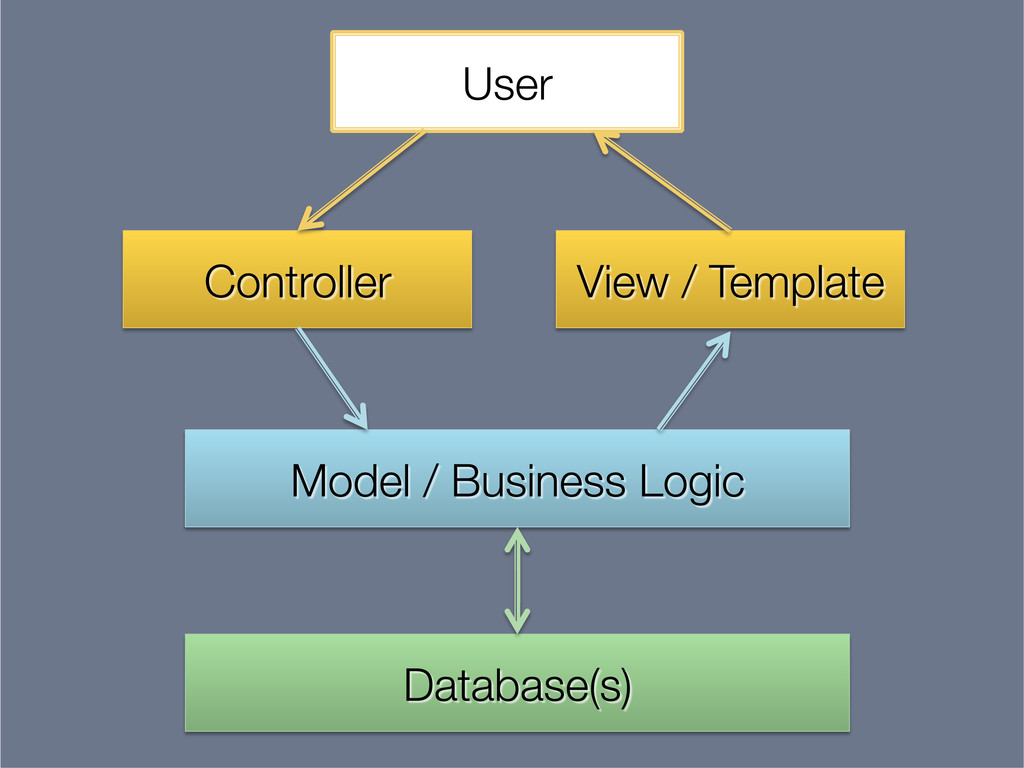{kind=link}
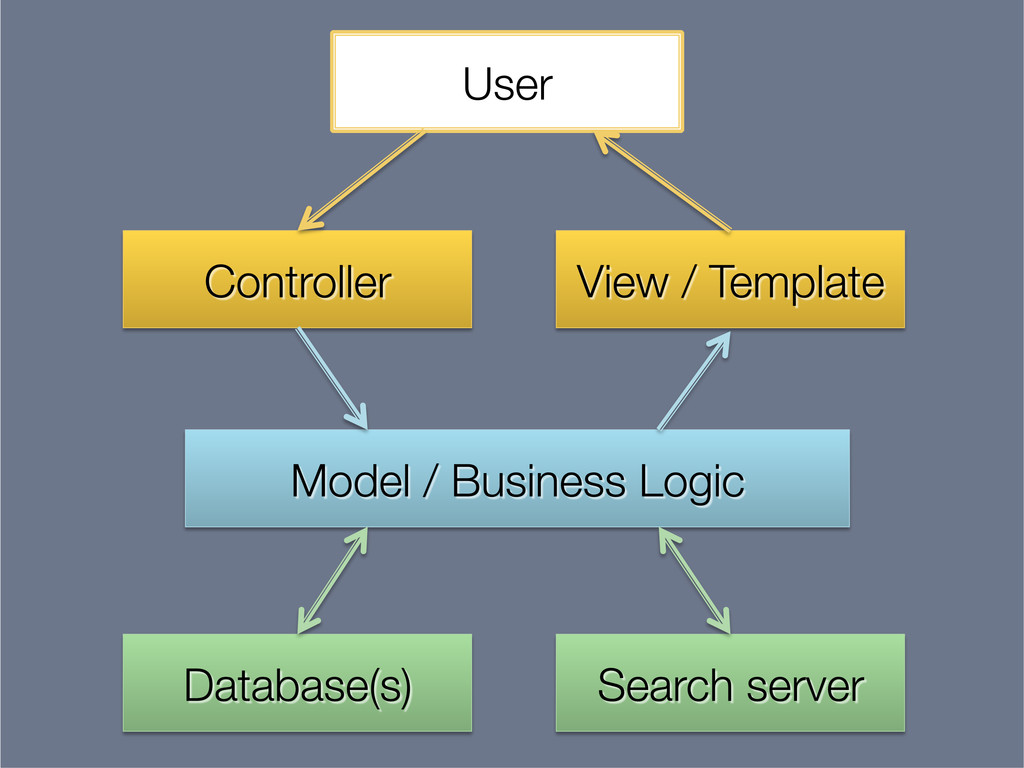{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}