by Henry Yuchi, Chun Yui Wong, with further edits made by Ashley Scillitoe. We are grateful to Paul Constantine — for without him, this deck wouldn’t exist. FOLKS WHO HAVE CONTRIBUTED
are inevitable and unavoidable. Thankfully, equadratures has a few utilities that may be useful. But before delving into them, it will be useful to talk about ideas like principal components analysis (PCA) and more generally the singular value decomposition. A FEW WORDS
have a matrix of measurements (say CMM data). Wish to determine which modes of manufacturing variability are the greatest. We create a covariance matrix using the observed data and then find its eigendecompostion. A FEW WORDS eigenvectors eigenvalues Observations Dimensions
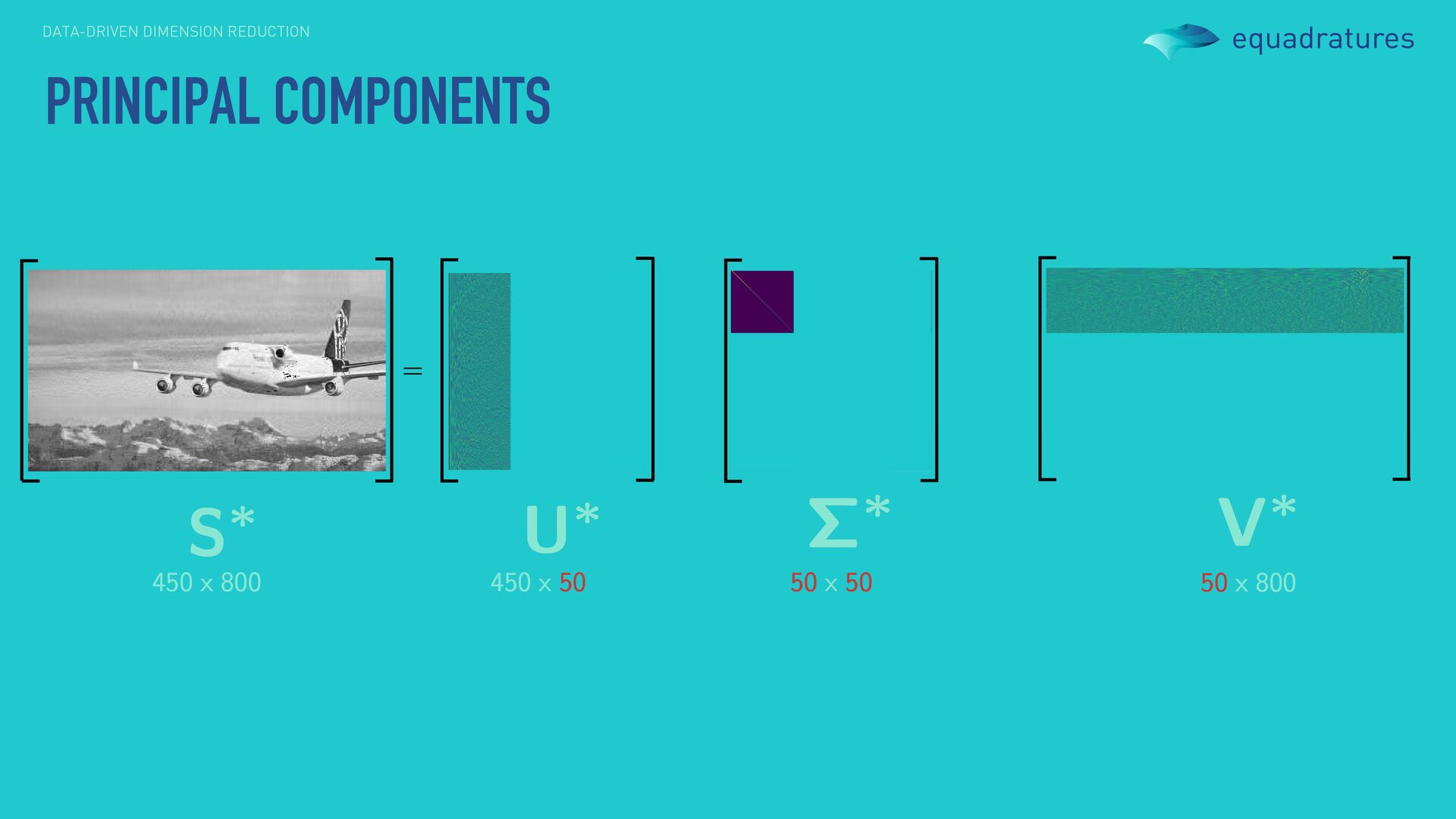
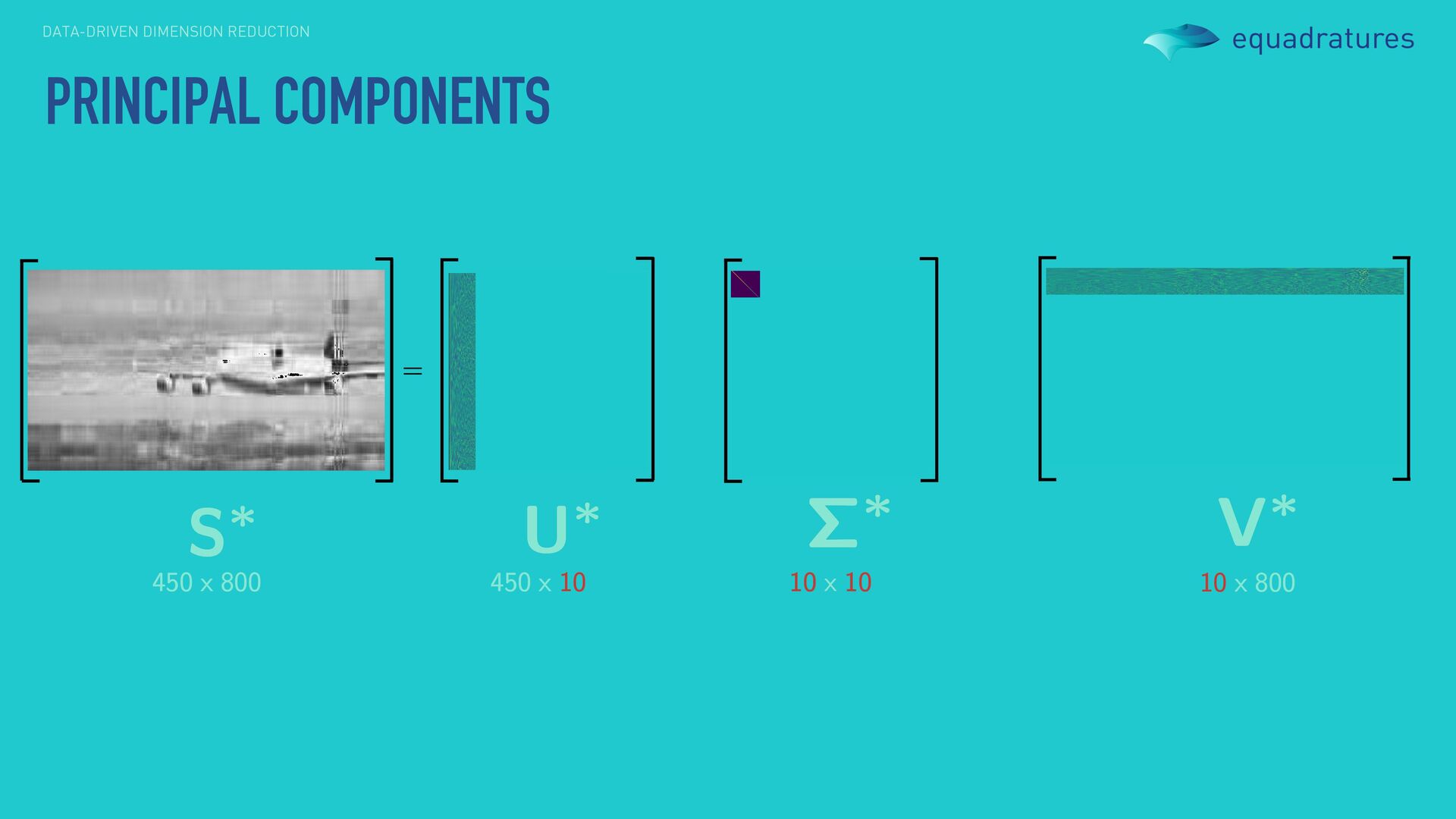
Wright (2011) Robust principal component analysis? J. ACM. *Schölkopf, Smola, Müller (1997) Kernel principal component analysis. Springer. Rather than apply principal components to a single image, we can apply it to numerous images to find dominant linear directions across all the images. Utility is not restricted to images and videos, but to any matrix / vector database. More robust and nonlinear variants also exist. However, we can’t really use this if we are interested in input-output pairs. For instance, computer experiments are usually carried out via a uniform design of experiment. Naïvely applying PCA to the inputs does not facilitate output-driven dimension reduction.
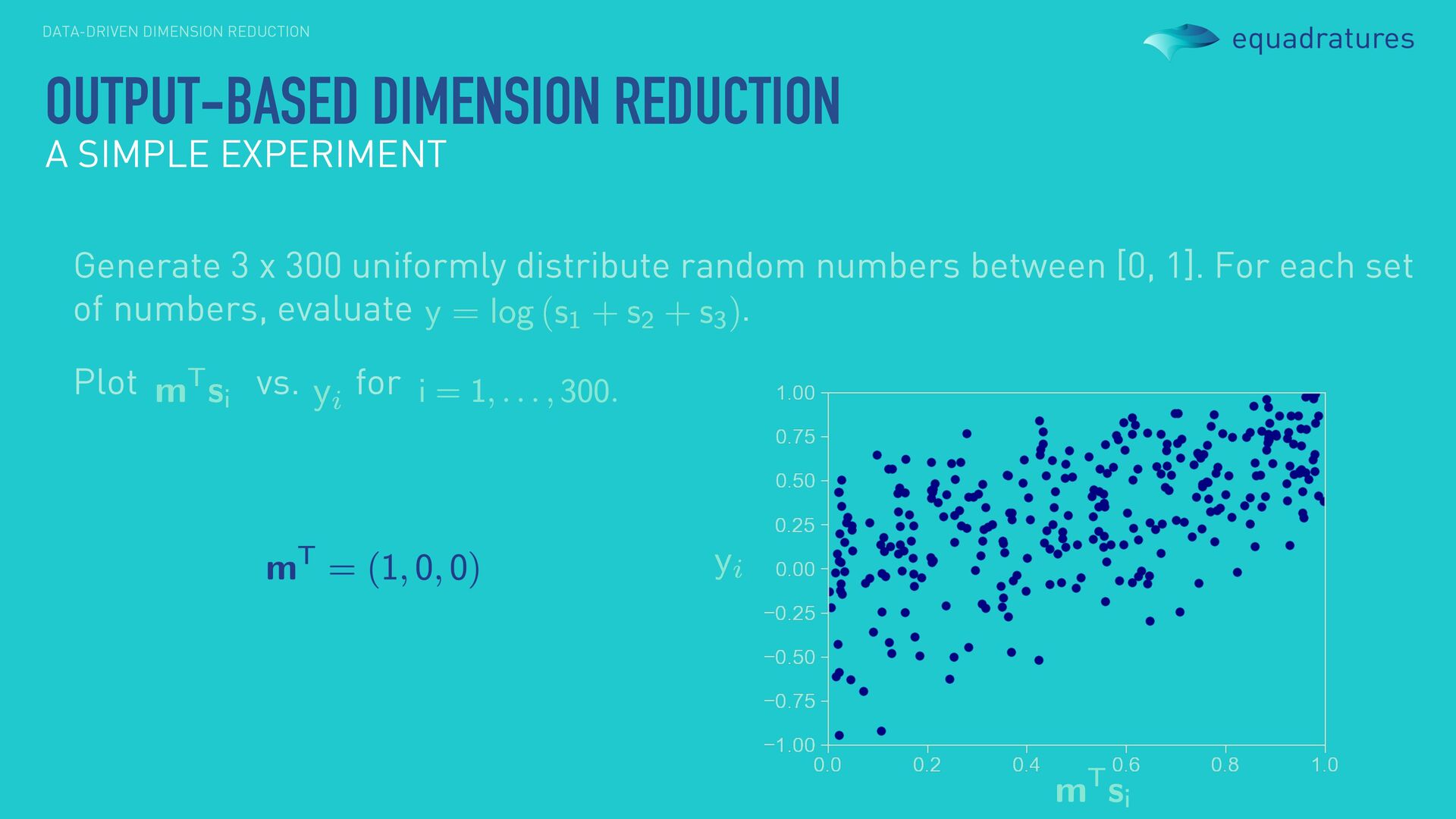
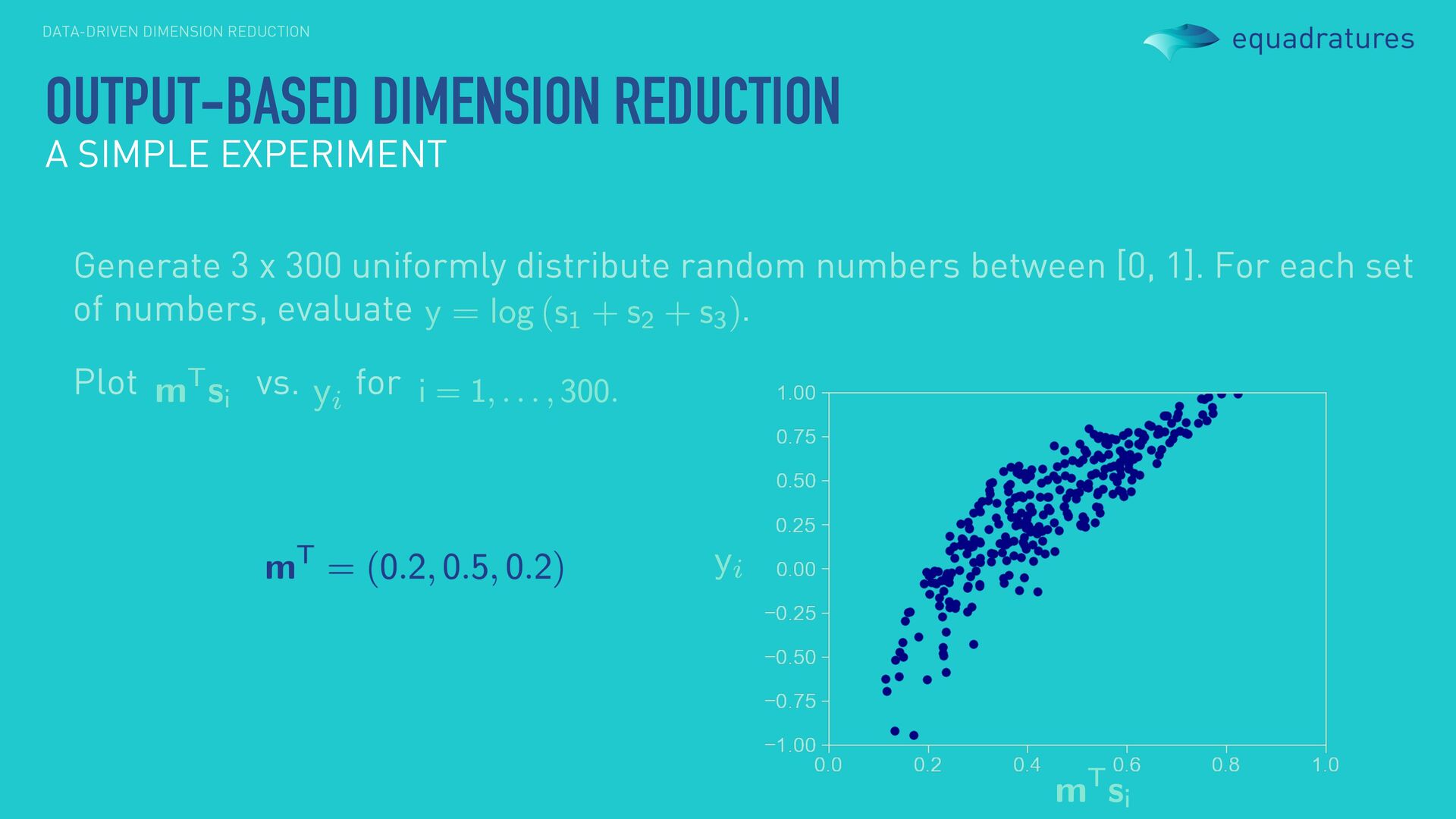
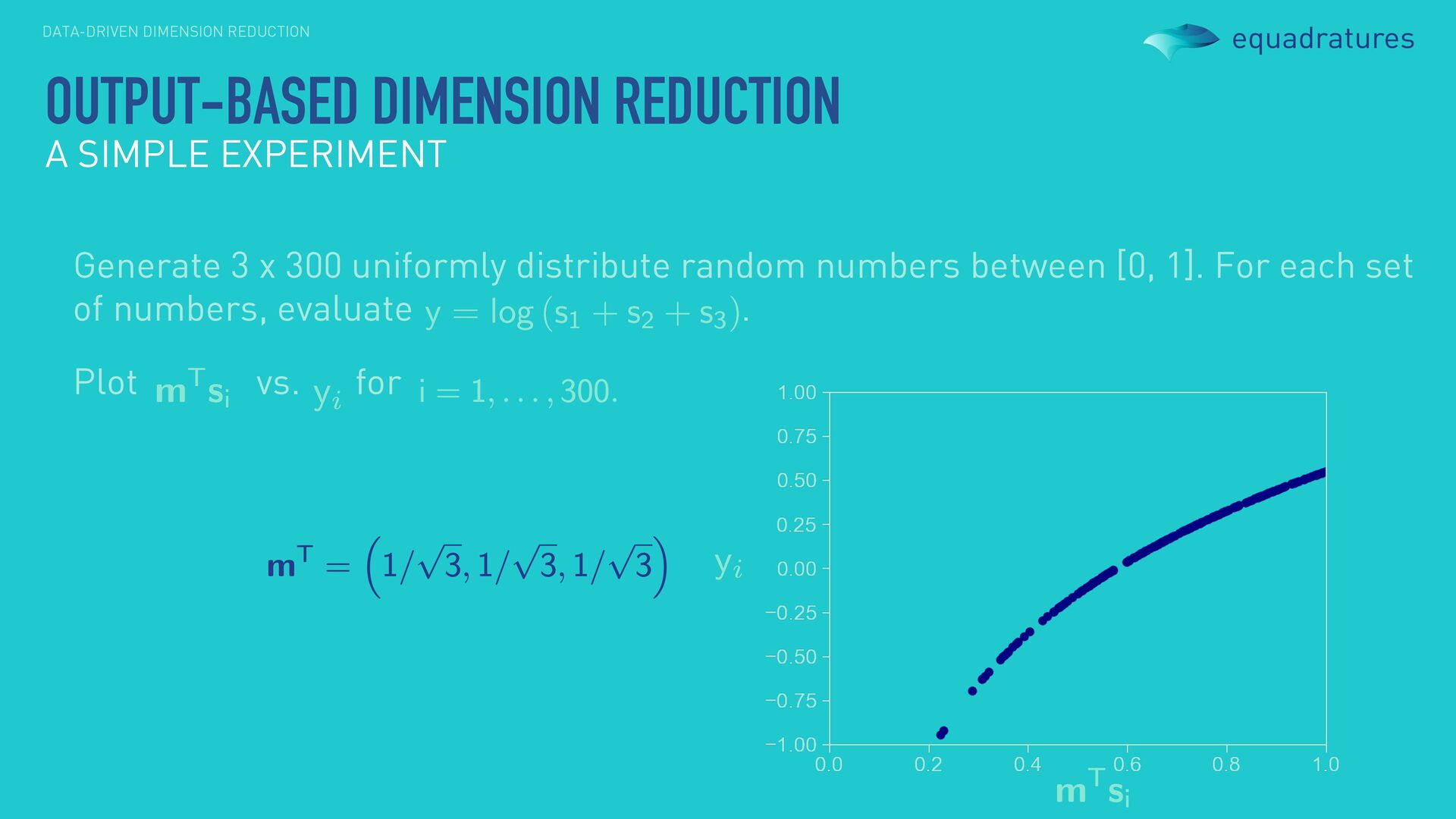
0.81 0.75 0.33 0.78 0.94 0.46 0.23 0.58 0.83 Generate 3 x 300 uniformly distribute random numbers between [0, 1]. For each set of numbers, evaluate . OUTPUT-BASED DIMENSION REDUCTION A SIMPLE EXPERIMENT
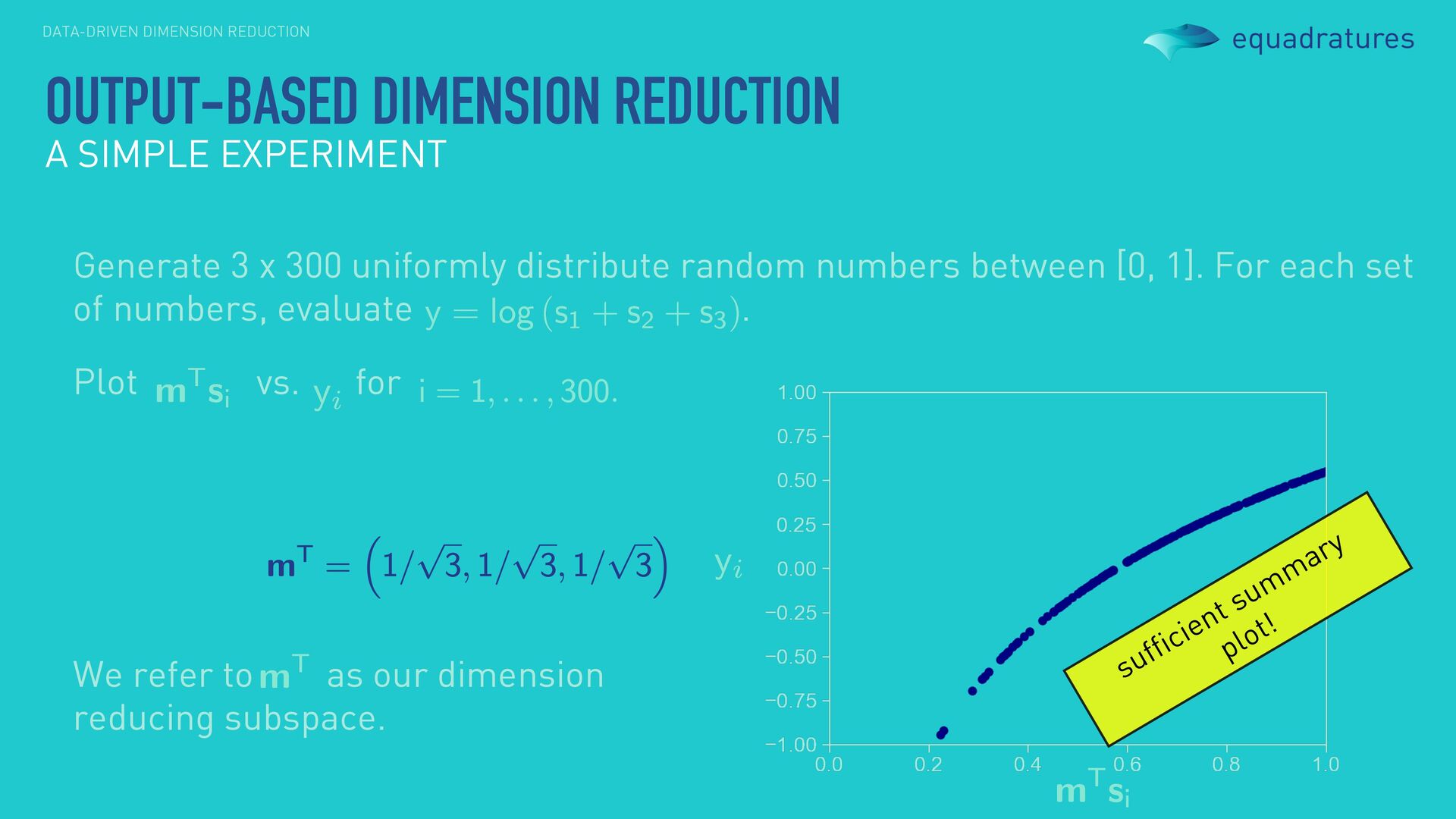
numbers between [0, 1]. For each set of numbers, evaluate . Plot vs. for OUTPUT-BASED DIMENSION REDUCTION A SIMPLE EXPERIMENT We refer to as our dimension reducing subspace. sufficient summary plot!
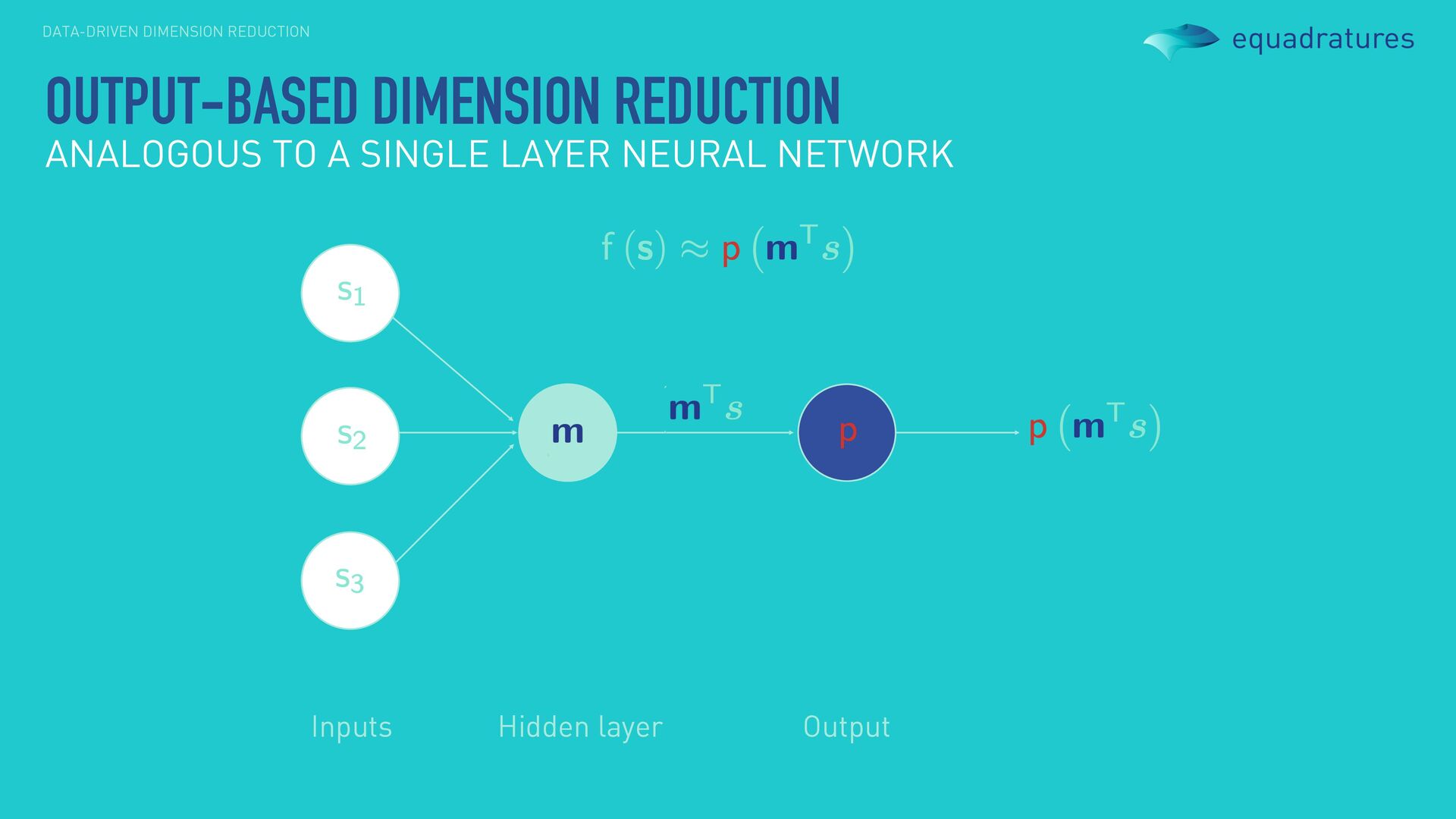
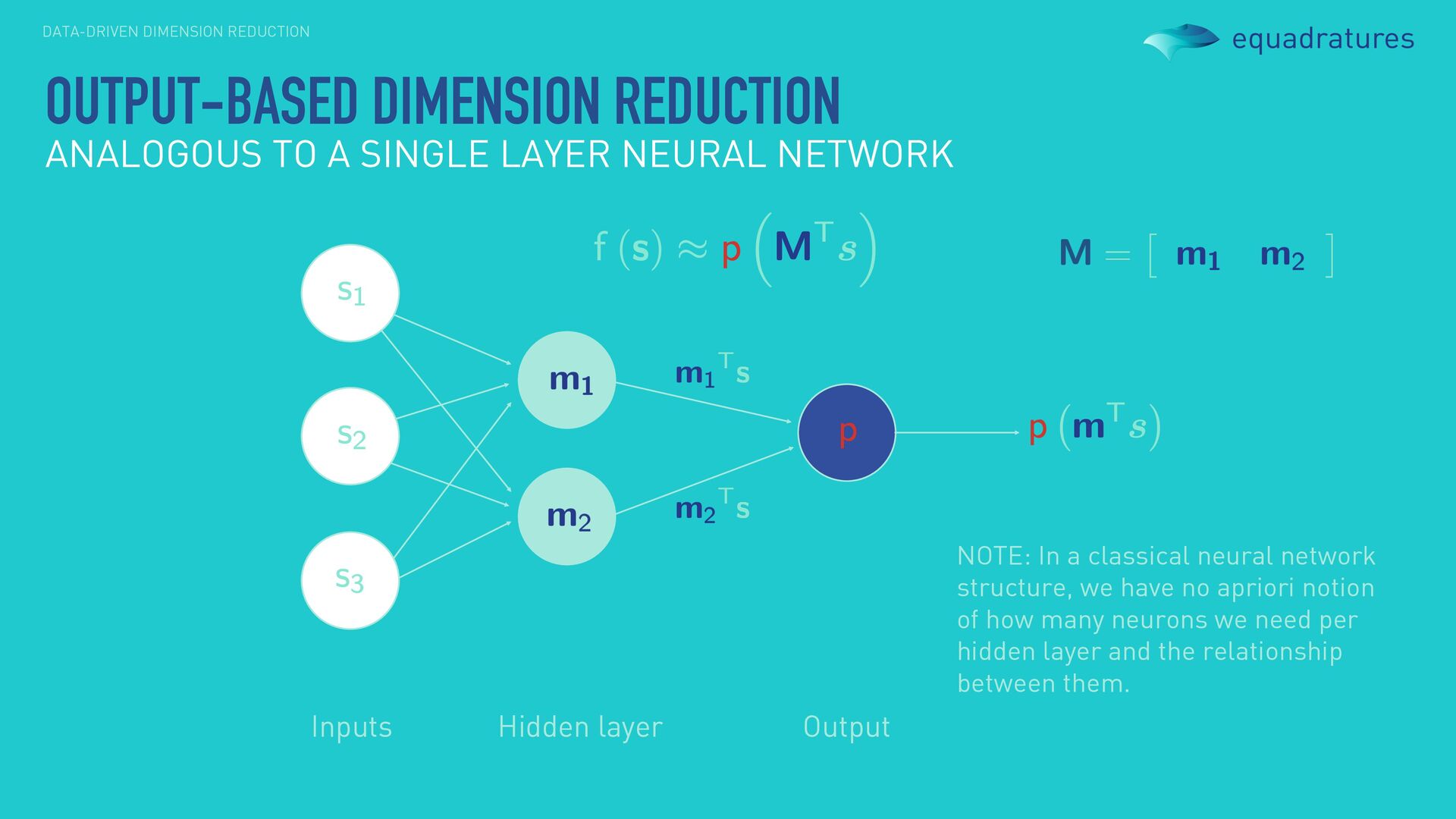
LAYER NEURAL NETWORK Hidden layer Inputs Output NOTE: In a classical neural network structure, we have no apriori notion of how many neurons we need per hidden layer and the relationship between them.
A 3D object. Shadow A 2D projection of a 3D object. Consider the projection of a cube on a plane, it can either be a square or hexagon. Be aware: understanding high- dimensional spaces is very important!
error conditional expectation active subspace Poincaré constant In practice, for computing the active subspace we require gradient evaluations (or approximations thereof) —> not always feasible.
with a polynomial expansion, i.e., solving This can be done via least squares. One can consider solving this in other norms, leading to solutions via compressed sensing, or some combination thereof. where
gradient estimates (e.g., adjoints). •May require many model evaluations. •The “reduced” dimension is easy to gauge based on eigenvalue decay. active subspaces •Does not require gradients or gradient estimates (e.g., adjoints). •Requires # of model evaluations based on “reduced” dimension. •The “reduced” dimension may need to be estimated.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DATA-DRIVEN DIMENSION REDUCTION PROJECTIONS & ZONOTOPES SUBSPACE-BASED [LINEAR] PROJECTIONS Consider](https://files.speakerdeck.com/presentations/39b3cbf85dfc4274b0fdf2fdd23dbdc5/slide_23.jpg){kind=link}
![DATA-DRIVEN DIMENSION REDUCTION PROJECTIONS & ZONOTOPES SUBSPACE-BASED [LINEAR] PROJECTIONS Human](https://files.speakerdeck.com/presentations/39b3cbf85dfc4274b0fdf2fdd23dbdc5/slide_24.jpg){kind=link}
![DATA-DRIVEN DIMENSION REDUCTION PROJECTIONS & ZONOTOPES SUBSPACE-BASED [LINEAR] PROJECTIONS Human](https://files.speakerdeck.com/presentations/39b3cbf85dfc4274b0fdf2fdd23dbdc5/slide_25.jpg){kind=link}
![DATA-DRIVEN DIMENSION REDUCTION PROJECTIONS & ZONOTOPES SUBSPACE-BASED [LINEAR] PROJECTIONS Generate](https://files.speakerdeck.com/presentations/39b3cbf85dfc4274b0fdf2fdd23dbdc5/slide_26.jpg){kind=link}
![DATA-DRIVEN DIMENSION REDUCTION PROJECTIONS & ZONOTOPES SUBSPACE-BASED [LINEAR] PROJECTIONS Generate](https://files.speakerdeck.com/presentations/39b3cbf85dfc4274b0fdf2fdd23dbdc5/slide_27.jpg){kind=link}
![DATA-DRIVEN DIMENSION REDUCTION PROJECTIONS & ZONOTOPES SUBSPACE-BASED [LINEAR] PROJECTIONS Generate](https://files.speakerdeck.com/presentations/39b3cbf85dfc4274b0fdf2fdd23dbdc5/slide_28.jpg){kind=link}
![DATA-DRIVEN DIMENSION REDUCTION PROJECTIONS & ZONOTOPES SUBSPACE-BASED [LINEAR] PROJECTIONS Generate](https://files.speakerdeck.com/presentations/39b3cbf85dfc4274b0fdf2fdd23dbdc5/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}