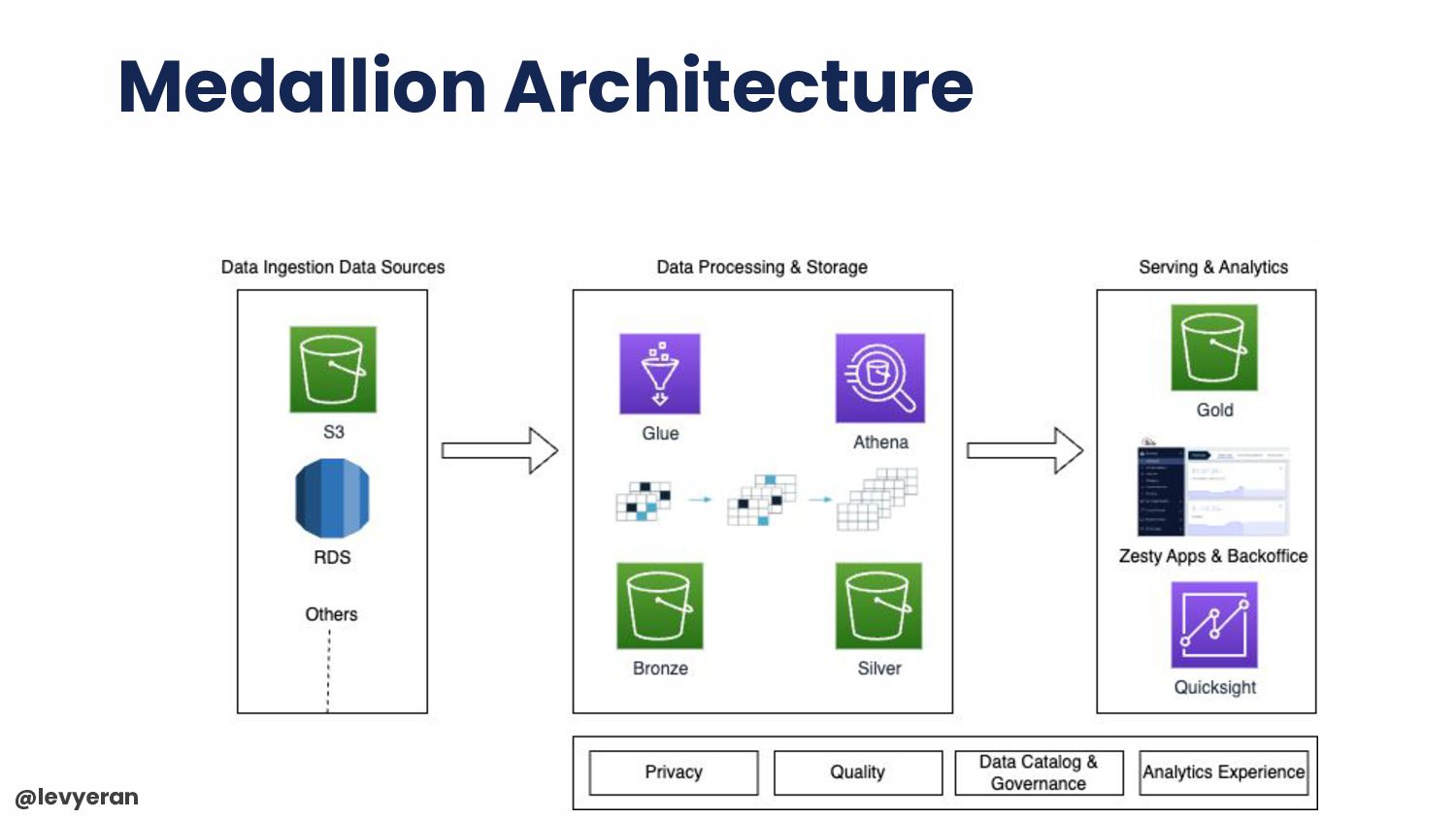
table format widely adopted and integrates well with AWS ecosystem (Glue catalog, Athena, etc). - Table evolution - Mainly schema and partitioning layout (particularly hidden partitioning). - Integrating well with many processing engines - supports our long term strategy in leveraging the right technologies to their needs.
Glue catalog and Athena engine version 3 (preferably a dedicated WorkGroup). - Parquet with ZSTD compression - this is the data format we adopted across our data lake. - Snapshot age - 2 days (default is 5 days). Athena allows predefined key-value TBLPROPERTIES only. Glue catalog - Metadata tracking
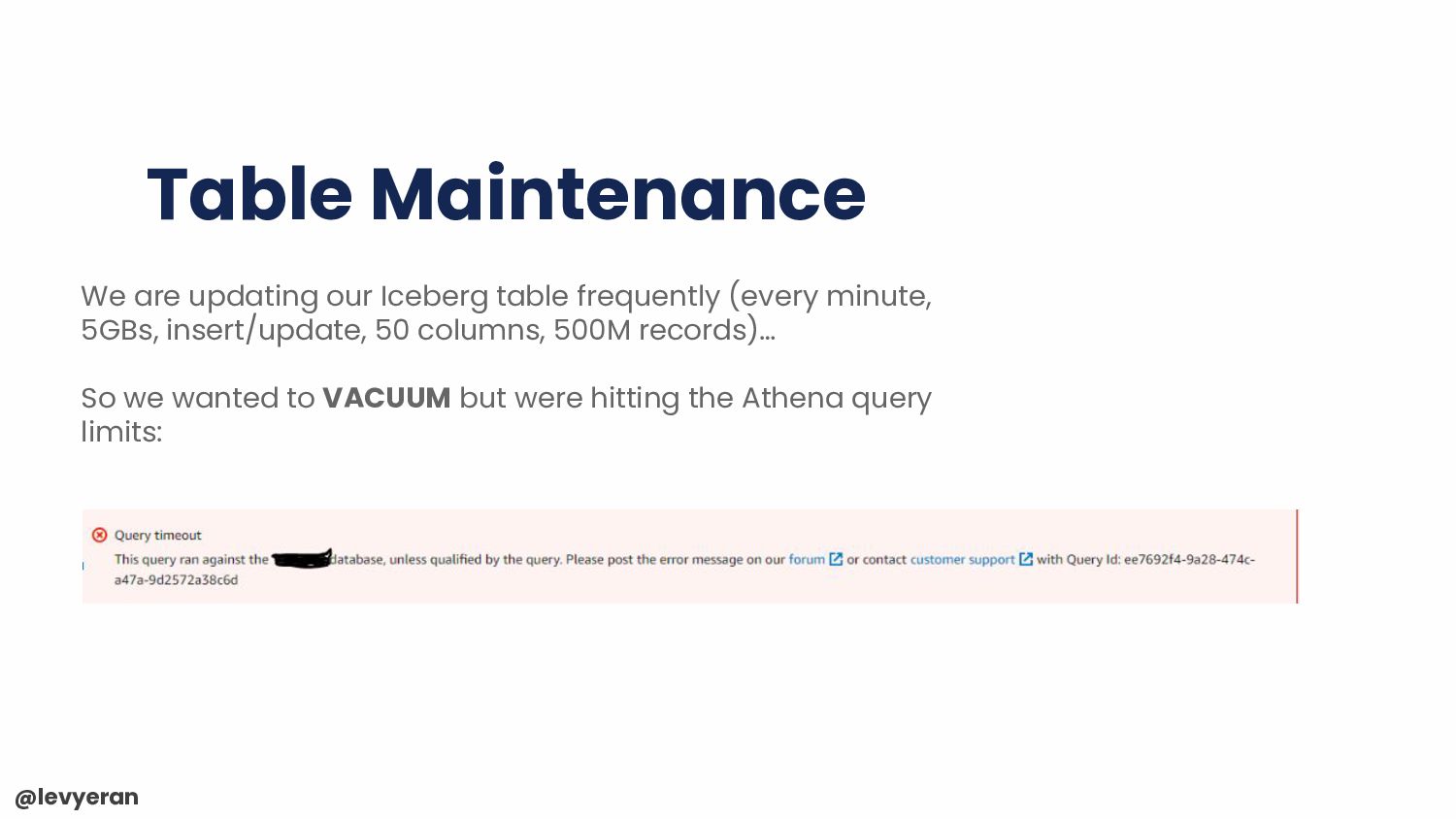
we were hitting another : ICEBERG_VACUUM_MORE_RUNS_NEEDED: Removed 1000 files in this round of vacuum, but there are more files remaining. Please run another VACUUM command to process the remaining files You can try overcome it by running AWS Step Functions in a loop like this suggested solution Missing several runs and you will face another challenge as increasing Athena query limits won’t help you much this time…
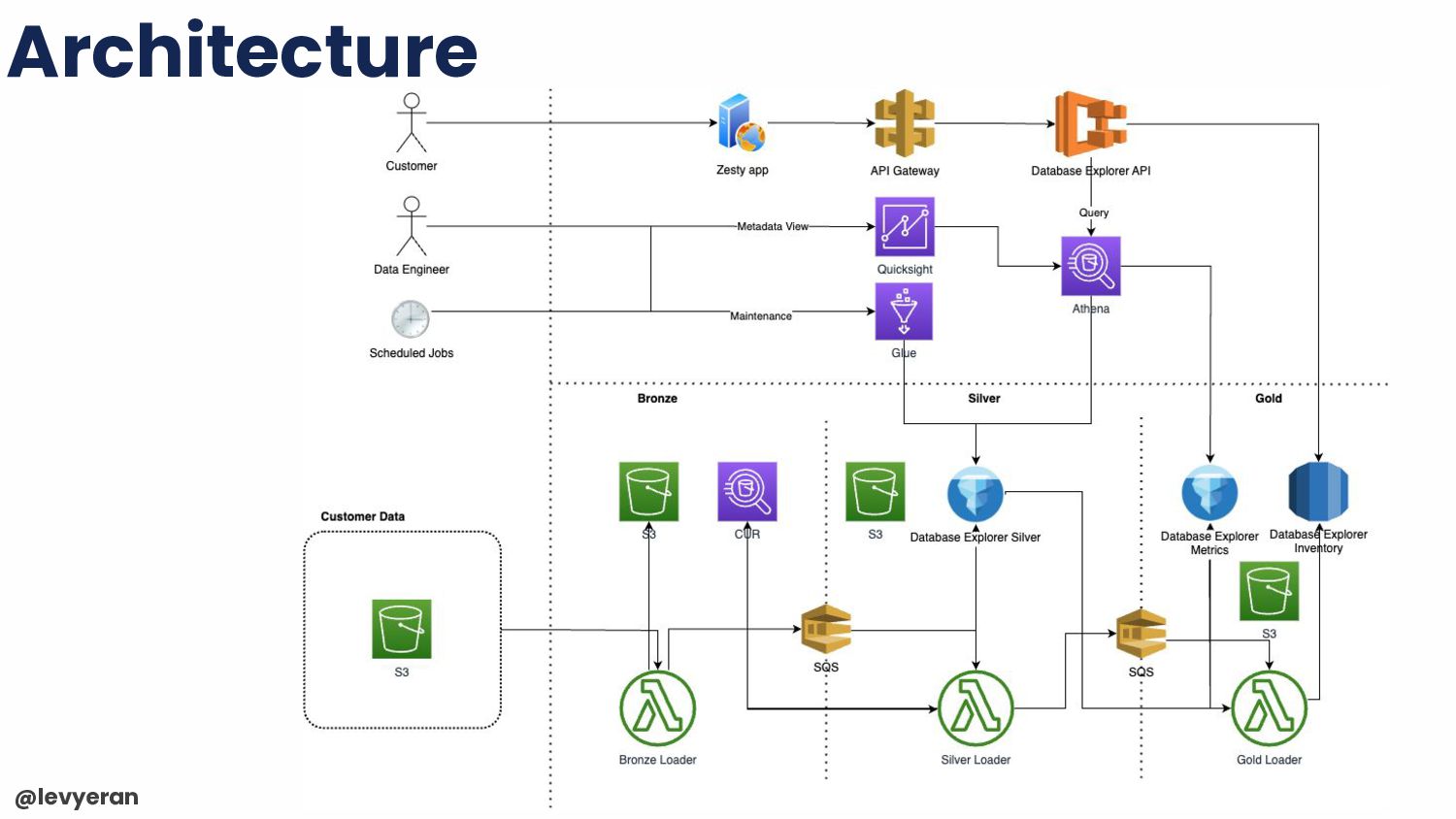
for the long run, we decided to utilize the Iceberg Spark procedures in order to perform our maintenance jobs: - Glue 3.0 and later supports Iceberg integration out of the box - Ad-hoc & built-in scheduler - Integrated with CI/CD pipeline using AWS SDKs Nice AWS blog and an AWS Glue Developer Guide are available
to perform are: - Register the Iceberg connector for AWS Glue (Not required for Glue 4.0) - Create ETL Job or a Jupyter Notebook - Provide the necessary configuration to the Spark job/notebook such as: –datalake-formats and –conf NOTE: these actions automatically inject the Iceberg Spark SQL extension
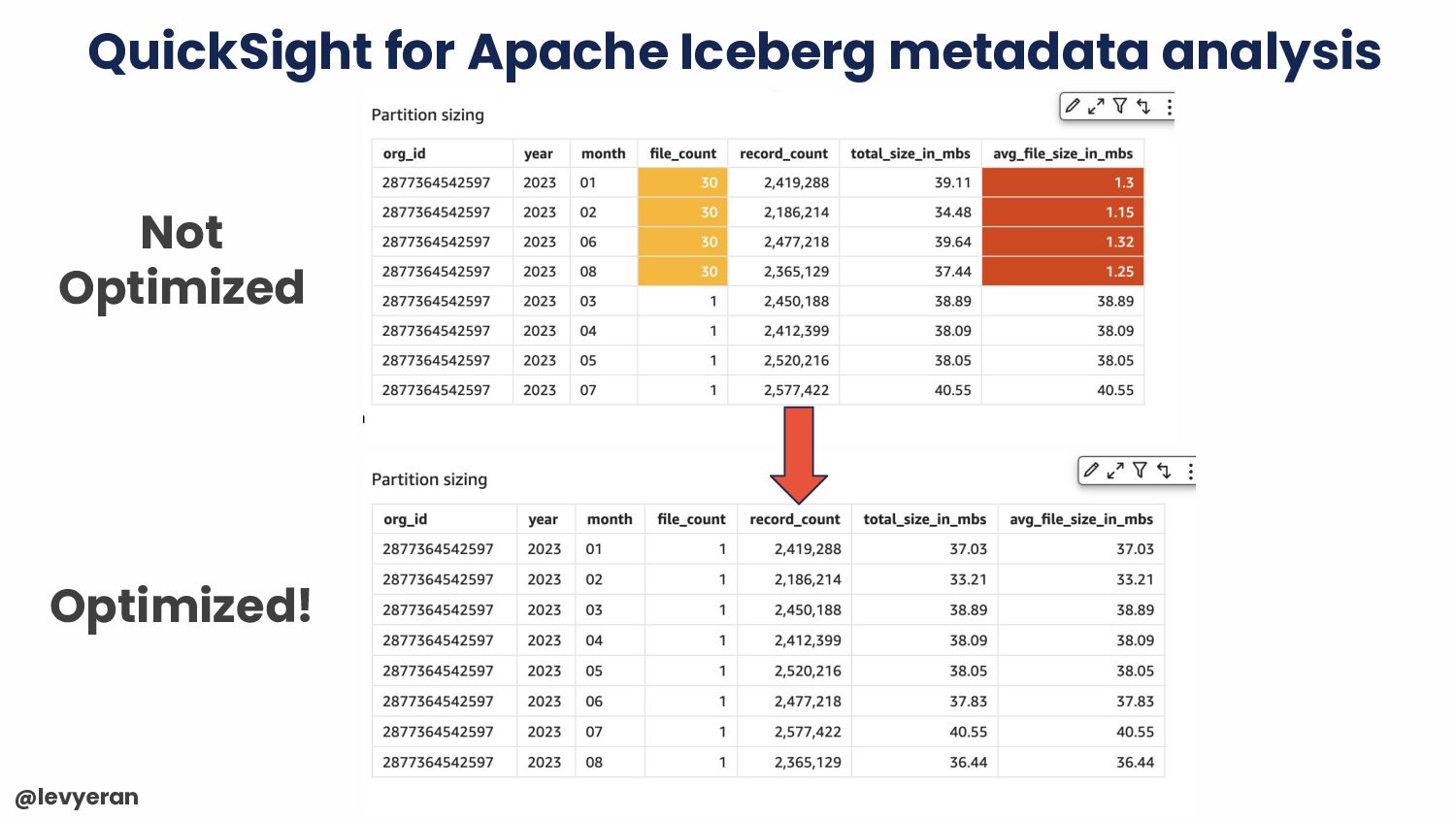
and specifically in the AWS ecosystem. • It's not persist & forget -> take Iceberg maintenance into consideration while choosing your architecture. • Keep monitoring -> your partitioning strategy might change, file size, query latencies, etc. as there are many moving parts that can impact your performance.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}