Traditional keyword-based search is dying. Users expect Google-quality search that understands intent, handles typos gracefully, and finds semantically similar content even when exact keywords don't match. Thanks to embeddings and vector databases, you can now build this level of search sophistication in your PHP applications?and it's easier than you think.
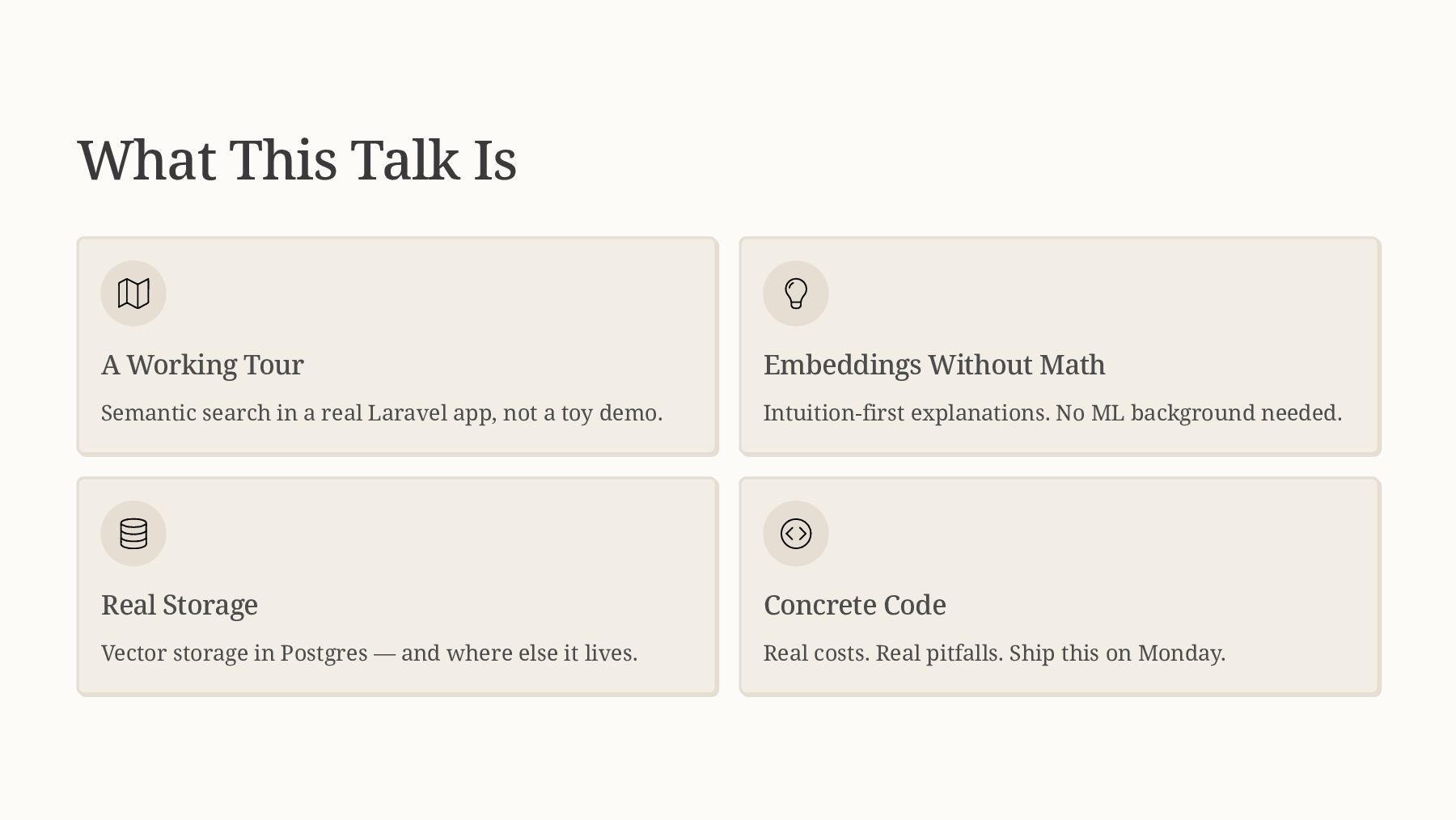
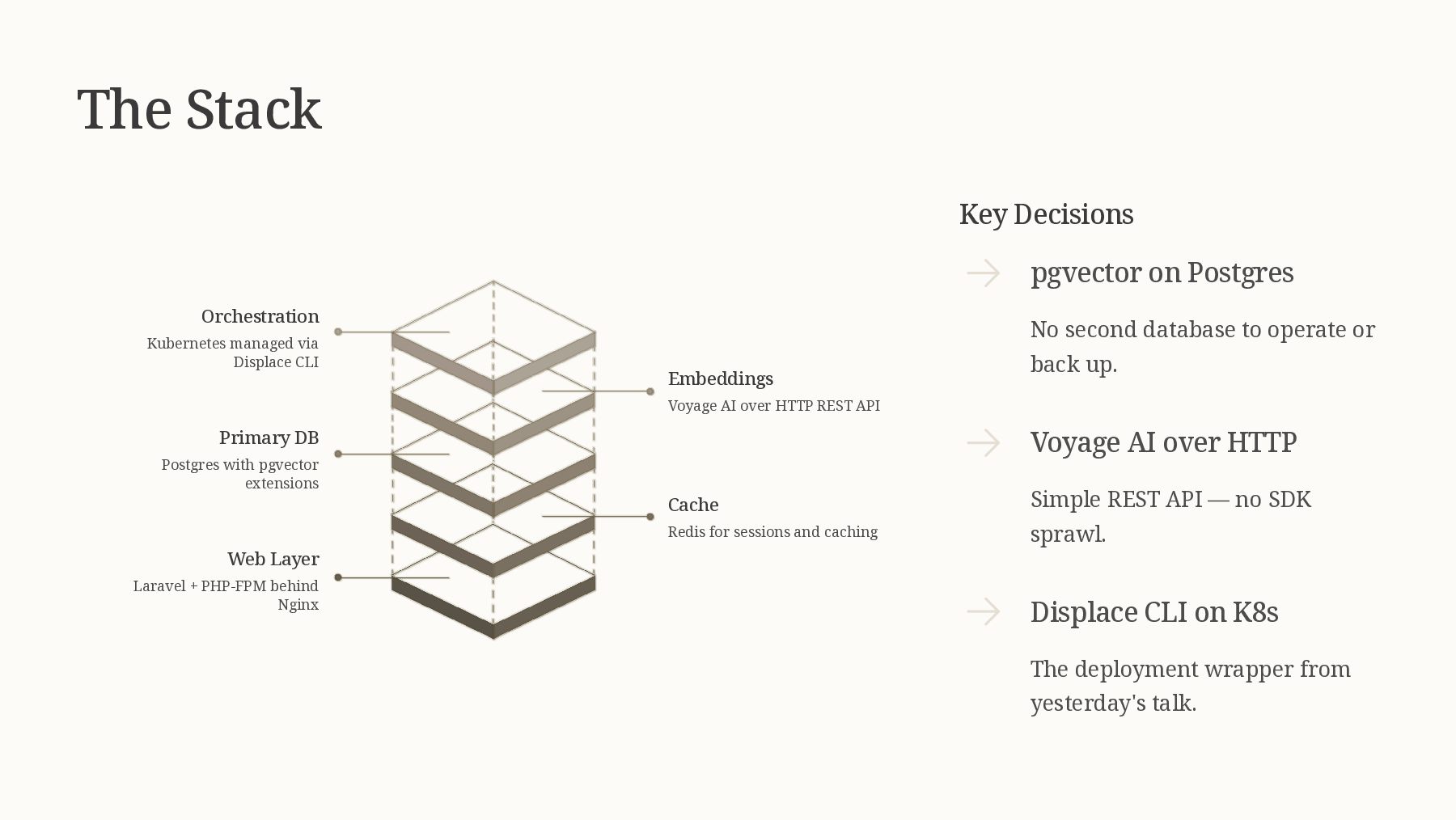
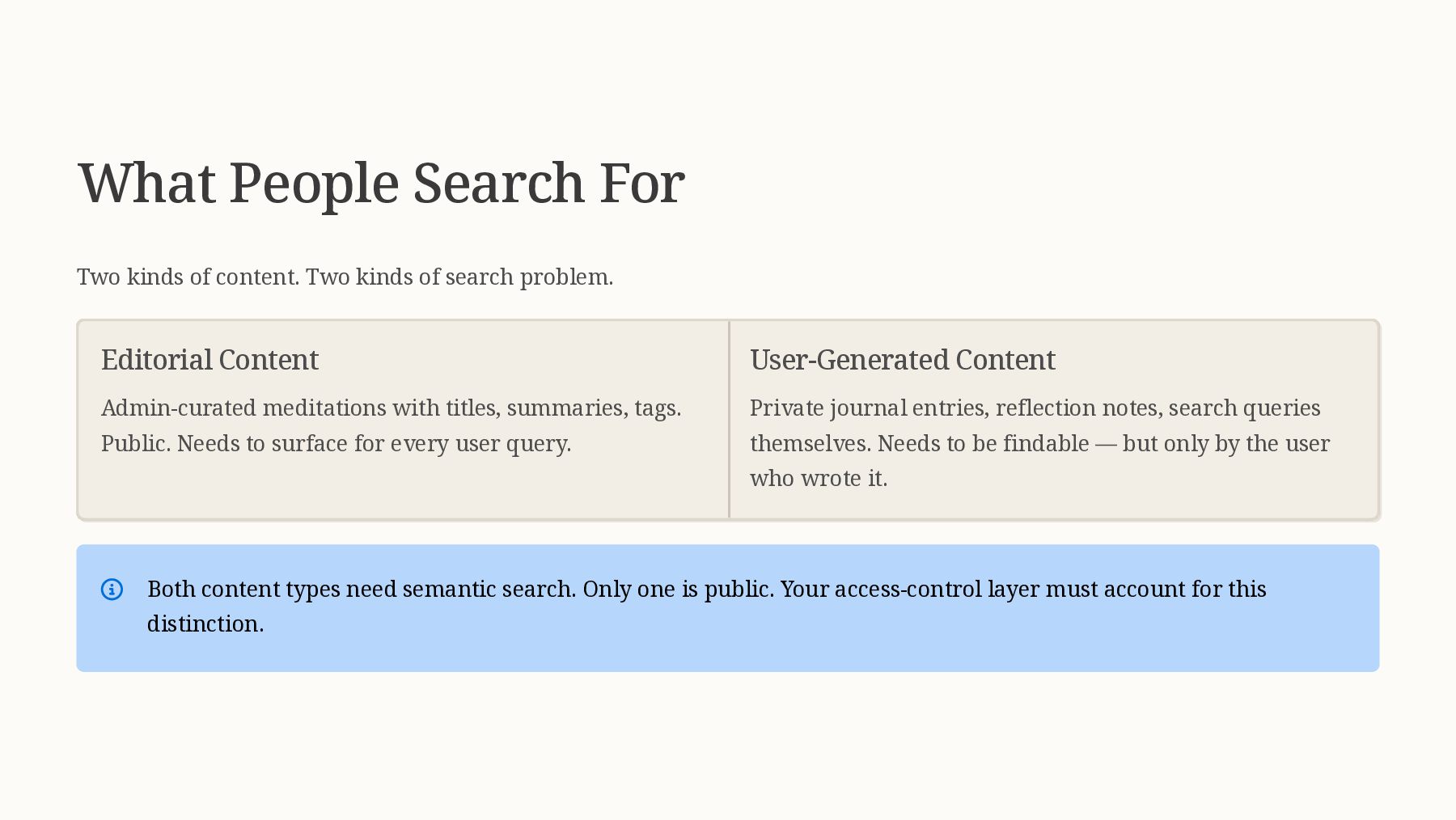
This talk demystifies semantic search by showing you how to transform your existing PHP search implementation into an intelligent, meaning-aware system. You'll learn how embeddings work (without needing a PhD in machine learning), how to integrate vector databases into your PHP stack, and practical strategies for implementing hybrid search that combines the best of keyword and semantic approaches.
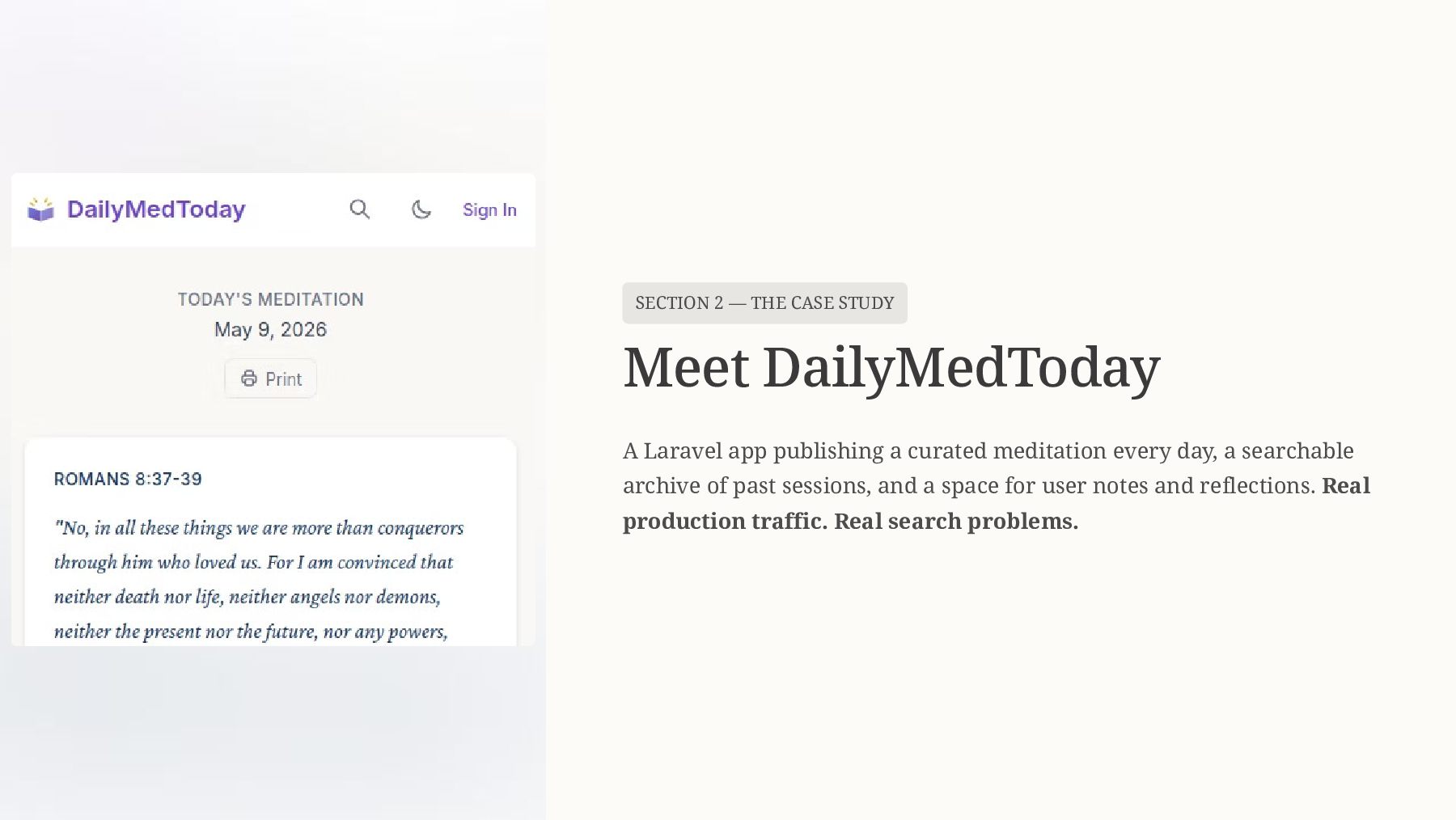
This talk includes live demonstrations of semantic search finding relevant results where traditional search fails, showing side-by-side comparisons and actual code examples. You'll see how to retrofit semantic search into existing applications without a complete rewrite, making this immediately actionable for PHP developers.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
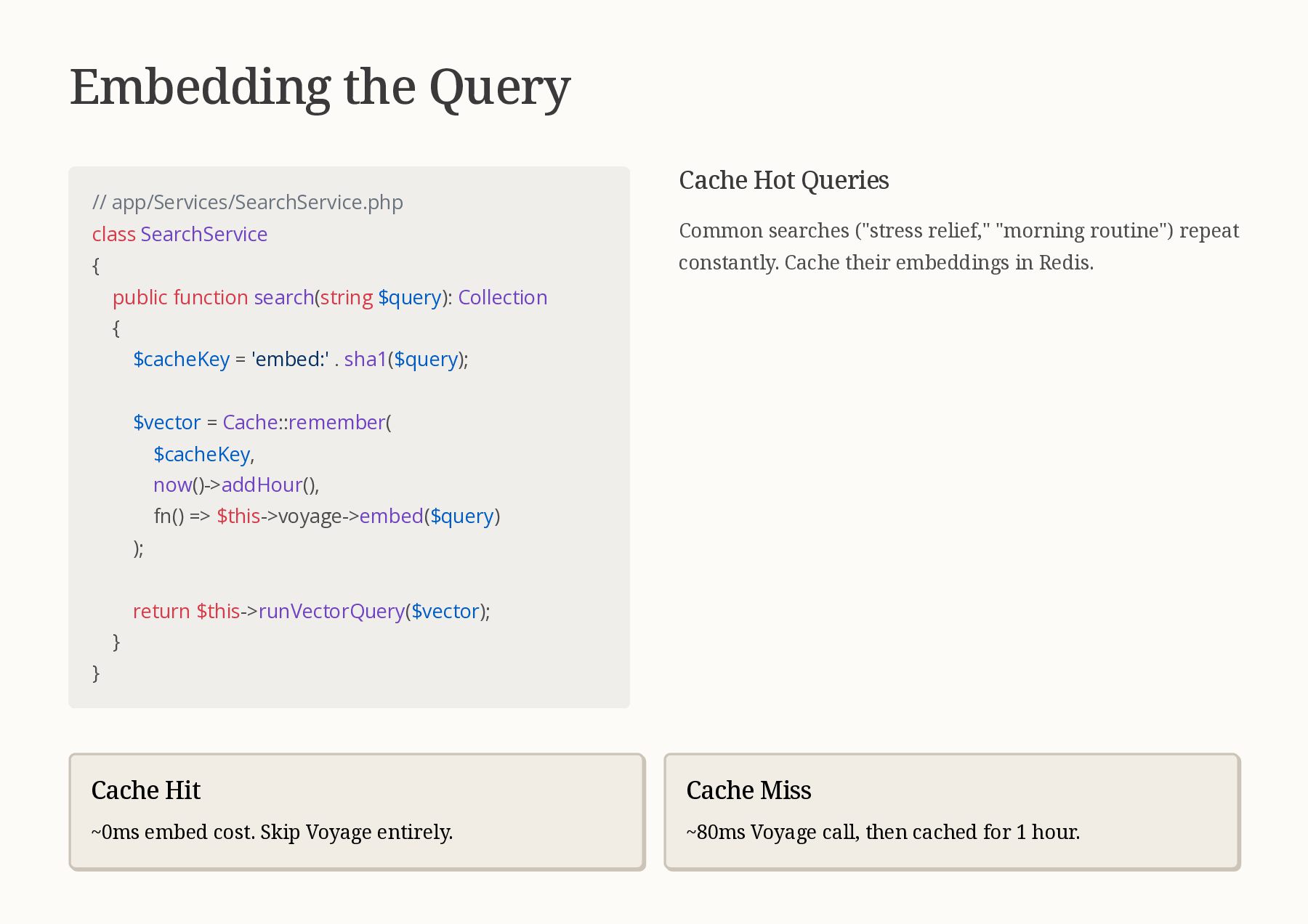{kind=link}
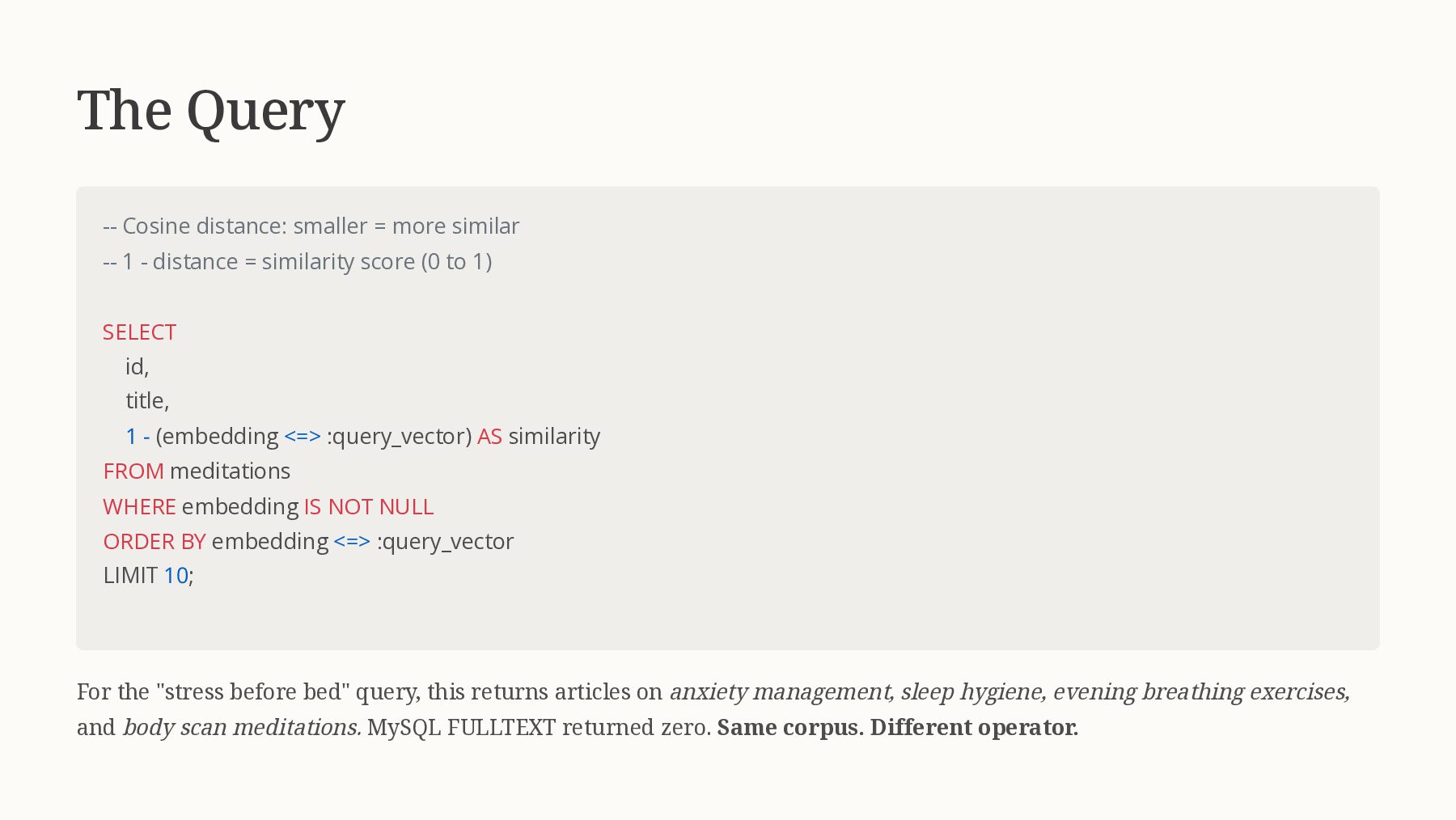{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}