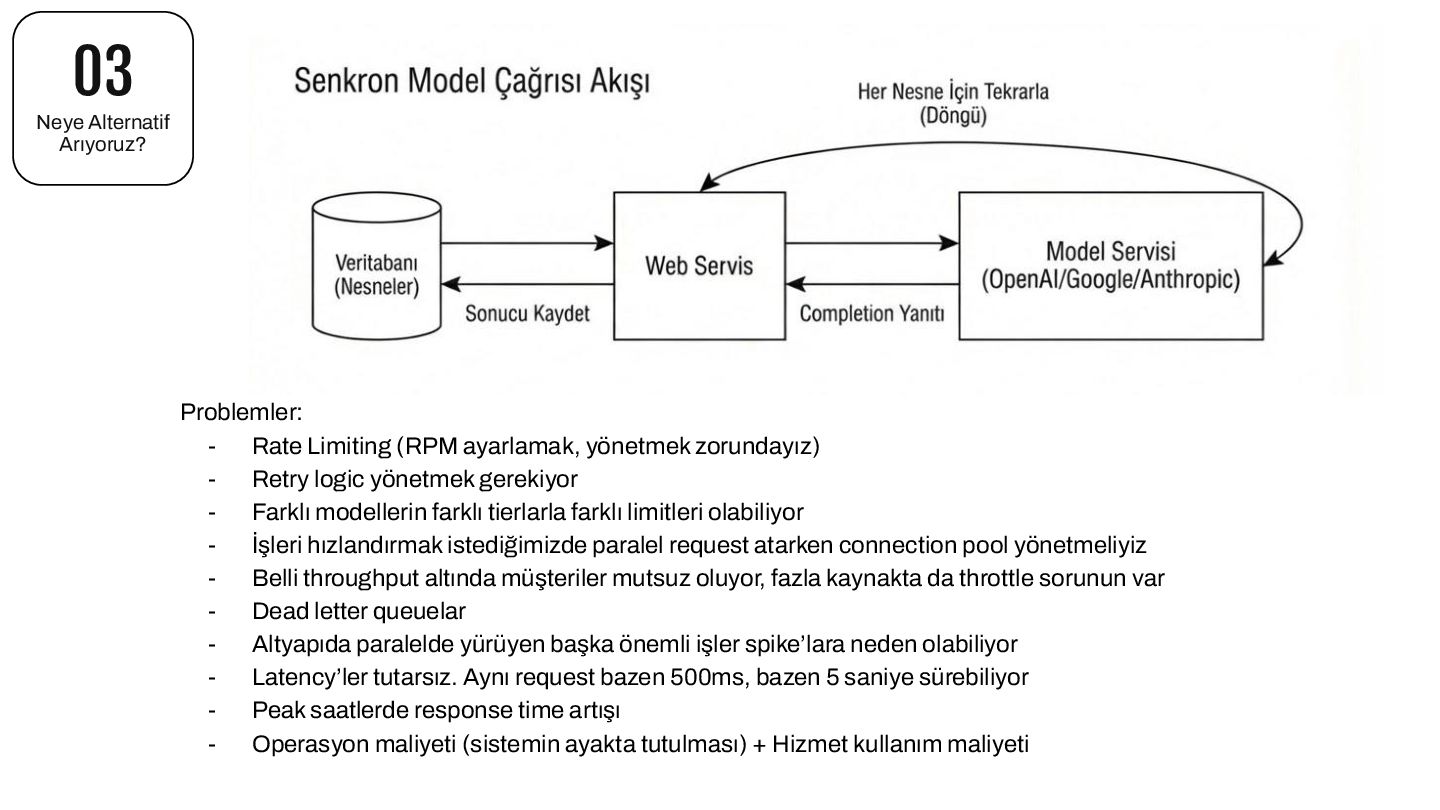
yönetmek zorundayız) - Retry logic yönetmek gerekiyor - Farklı modellerin farklı tierlarla farklı limitleri olabiliyor - İşleri hızlandırmak istediğimizde paralel request atarken connection pool yönetmeliyiz - Belli throughput altında müşteriler mutsuz oluyor, fazla kaynakta da throttle sorunun var - Dead letter queuelar - Altyapıda paralelde yürüyen başka önemli işler spike’lara neden olabiliyor - Latency’ler tutarsız. Aynı request bazen 500ms, bazen 5 saniye sürebiliyor - Peak saatlerde response time artışı - Operasyon maliyeti (sistemin ayakta tutulması) + Hizmet kullanım maliyeti
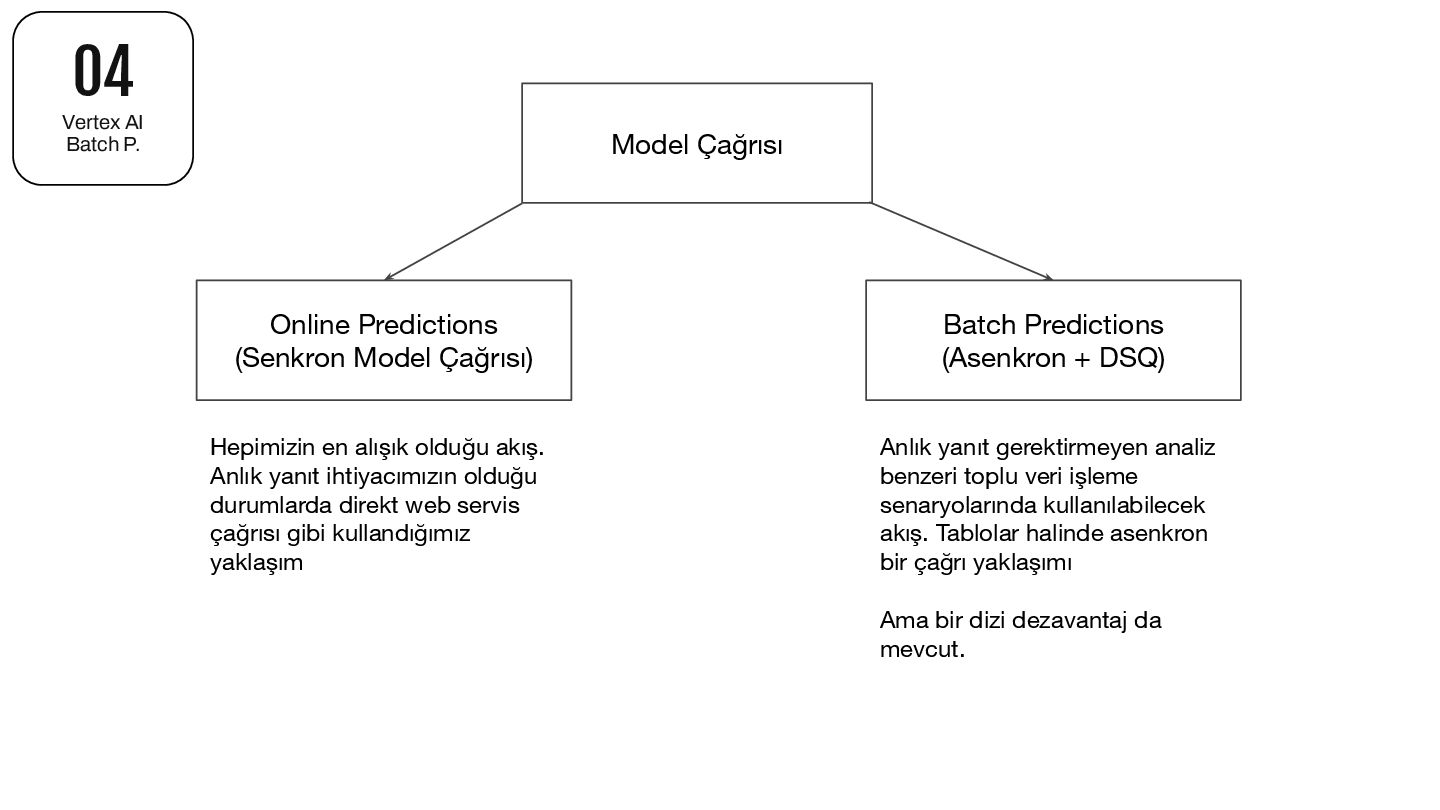
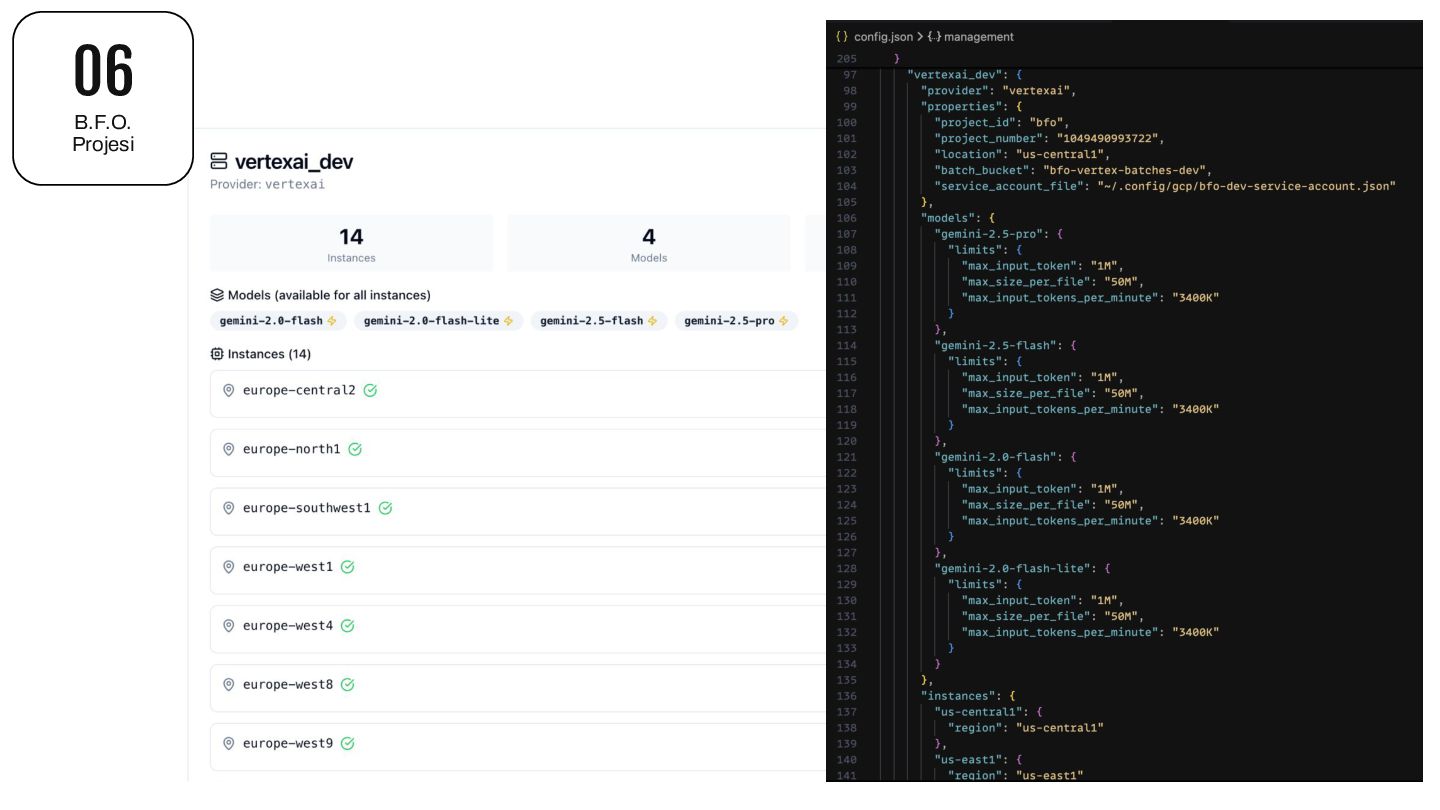
direkt web servis çağrısı gibi kullandığımız yaklaşım 04 Vertex AI Batch P. Model Çağrısı Online Predictions (Senkron Model Çağrısı) Batch Predictions (Asenkron + DSQ) Anlık yanıt gerektirmeyen analiz benzeri toplu veri işleme senaryolarında kullanılabilecek akış. Tablolar halinde asenkron bir çağrı yaklaşımı Ama bir dizi dezavantaj da mevcut.
birim maliyet. Yüksek hacimli işlemlerde bu fark ciddi bütçe tasarrufu sağlıyor. Rate Limit Sorunu Yok (Dynamic Shared Quota) Online API'lerde RPM/TPM limitlerine takılmak yerine, yüz binlerce kaydı tek job olarak submit edebiliyoruz. Implementasyon Basitliği Retry mekanizması, error handling ve job scheduling Google tarafından yönetiliyor. Kendi queue sistemimizi yazmamıza gerek kalmadı. Kaynak Verimliliği Kendi sunucularımızda connection pool, concurrent request yönetimi gibi karmaşıklıklarla uğraşmıyoruz. Ölçeklenebilirlik Veri hacmi arttıkça infrastructure tarafında değişiklik yapmadan aynı pipeline'ı kullanmaya devam edebiliyoruz. BigQuery Entegrasyonu Input/output doğrudan BigQuery tablolarından okunup yazılabiliyor. ETL süreçleriyle doğal bir uyum sağlayabiliyor. 04 Vertex AI Batch P.
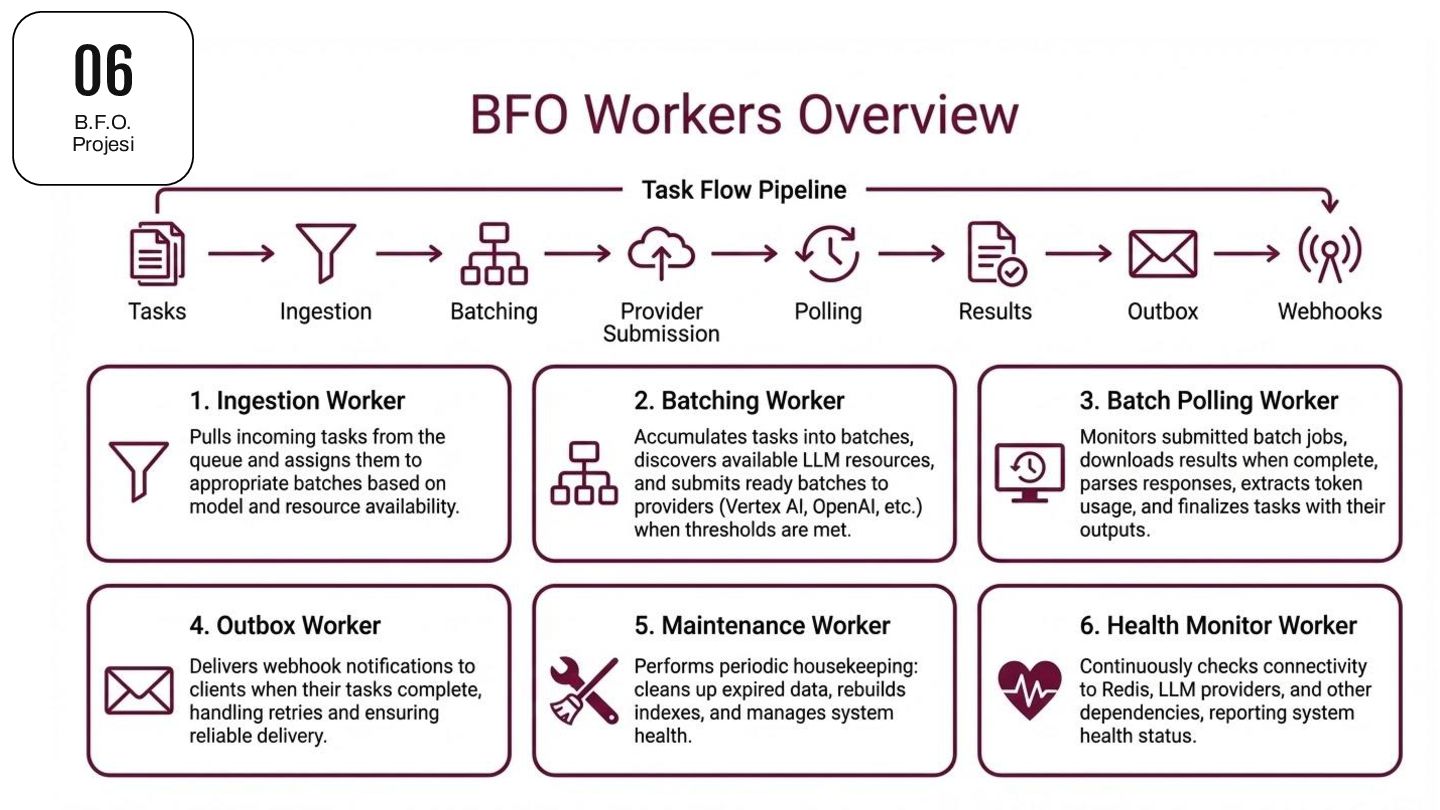
bin çağrı. Her analiz parametresi değiştiğinde (ki müşteri geri dönüşleriyle 3 - 4 faz olabiliyor) tekrar edilmesiyle ortalama 200 bin çağrı. Sosyal medyayı da dahil ettiğimizde… Son 30 günde 2.5 milyon çağrı. Input+Output 10 milyardan fazla token kullanımı. SLA Son kullanıcılara sunduğumuz bir hizmet var ve B2B modelimizde sözleşmelerle garanti altına alınıyor. Moda etkinliklerinin, sosyal medyada olan bitenin analizlerle platforma eklenmesi için müşterilerimize bir taahhüt veriyoruz. Bu taahhüt süreleri yaklaşınca batch’den online’a geri dönmemiz gerekebilir! İhtiyaç Startup denkleminde ~%50’e yakın maliyet avantajı olmazsa olmaz. Ancak “Batch” yapısının kendine has bir denklemi var. Buna adapte olabilecek ve yığın işlem de olsa elimizdeki veriyi son kullanıcıları en az bekleterek modellere işletebilecek bir çözüm gerekiyor. 05 Golang’in Resme Girişi
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}