un rôle moteur dans la contribution à l’atteinte des Objectifs de Développement Durable (ODD). • Un angle mort de l’architecture financière internationale. • Plusieurs études menées afin de mesurer la contribution des financements de ces banques aux ODD avec des méthodes variées mais peu d’analyse sur le narratif des banques.
afin d’alimenter les chercheurs et le grand public à la fois • sur les données financières : Total des actifs, Capitaux propres, etc. • sur l’alignement des banques de développement sur les ODD dans leur narratif Contraintes • Délais courts: La base doit être présentée au Sommet « Finance in Common » qui se tient en Novembre 2020. • Ressources restreintes => Automatisation au maximum des processus.
chaque année un rapport annuel (RA) présentant leurs activités et leur états financiers. • Récupération de plus de 3000 Rapports Annuels des BPD datant de 1966 à 2020. Construction de 2 algorithmes • Un algorithme basé sur des techniques de NLP pour collecter les éléments financiers présentés dans les RA • Un algorithme de machine learning (XGBoost) pour qualifier l’importance des ODD dans le narratif des BPDs.
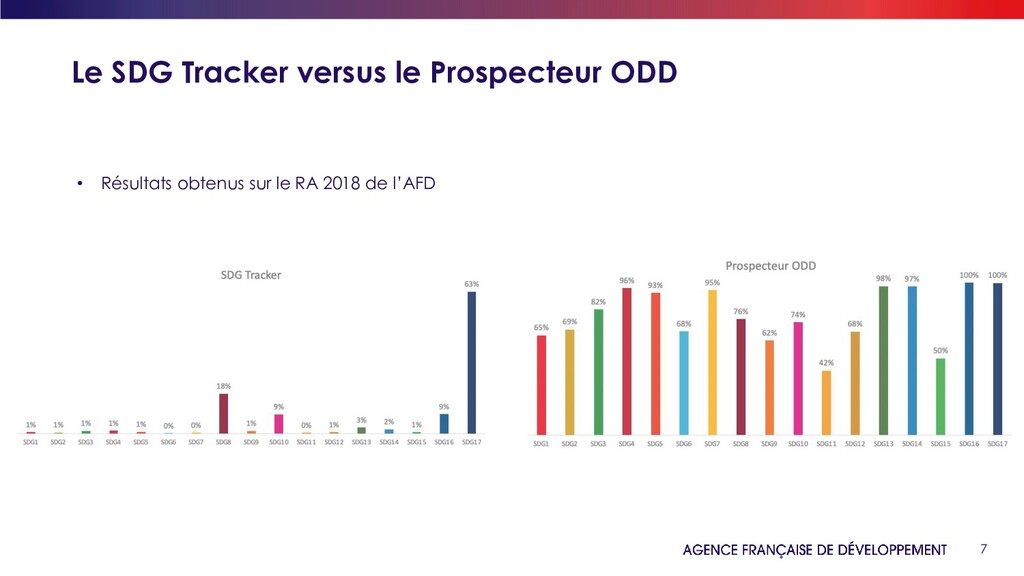
du SDG Financing Lab de l’OCDE • Algorithme de Machine Learning (XGBoost) développé par l’OCDE • Premiers travaux concluants • Base d’apprentissage déjà faite Application du SDG Tracker sur les Rapports Annuels des banques de développements Limites de l’algorithme SDG Tracker • L’algorithme de l’OCDE est construit pour analyser des textes courts alors qu’un RA contient entre plusieurs centaines de pages => Temps de calcul trop long sur de longs textes. • L’algorithme de l’OCDE présente les résultats sous forme de fréquences relatives. Le total des 17 ODD est toujours égal à 100 ce qui lie les ODD les uns aux autres… => Nécessité de modifier et adapter l’algorithme de l’OCDE
des longs textes • Remplacement de Tika par Xpdf pour la convertion des PDF en texte • Suppression des étapes de pré-traitements non nécessaires • Remplacement de XgBoost par LGBM • Parrallélisation des traitements sur 8 cœurs. • Utilisation de l’approche des fenêtres glissantes de 20 lignes, au lieu d’une analyse phrase par phrase. Résultats plus robustes • Conservation de la probabilité maximale des fenêtres glissantes pour chaque ODD qui ressort Résultats directement sous forme de pourcentage exploitables Indépendant de la taille du document Le Prospecteur ODD, une adaptation du SDG Tracker de l’OCDE Obtention d’un algorithme qui tourne sur 3000 documents (plus de 100 pages chacun) en 30 minutes.
résultats directement exploitables https://afdshiny.shinyapps.io/developmentbanksdatabase/ Merci à DreamRs pour le développement de cette Data Visualisation en R Shiny !
rapports annuels datant de 2008 à 2018 Le site https://afdshiny.shinyapps.io/developmentbanksdatabase présentant • Une vision financière sur les principaux éléments financiers • Une vision ODD pour une analyse par groupe de banques • Une vision banque avec la possibilité de comparer les banques entre elles et identifier leur spécificités • Une possibilité de téléchargement des données mise en open data • Un historique disponible sur 10 ans pour certaines banques • Et plein d’autres surprises !!! Rendez vous en Septembre 2021 pour la publication des millésimes 2019 et 2020 !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Merci afd.fr Bruce Olivaux [email protected] @OlivauxB](https://files.speakerdeck.com/presentations/68fa32d9584349bd83ee89ab2c9f732d/slide_9.jpg){kind=link}