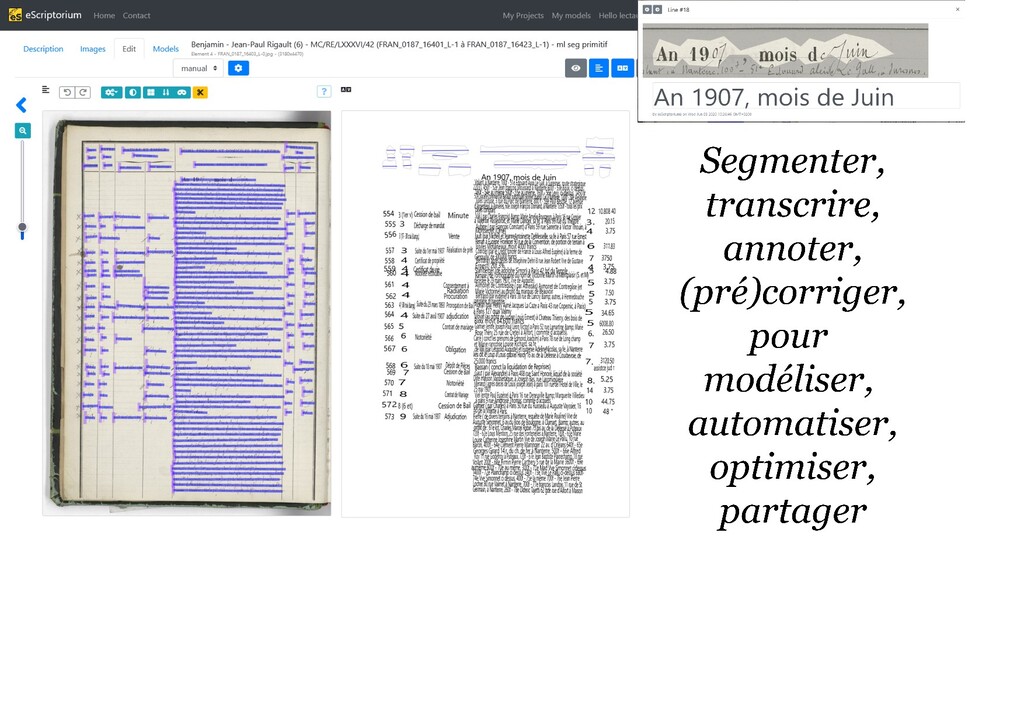
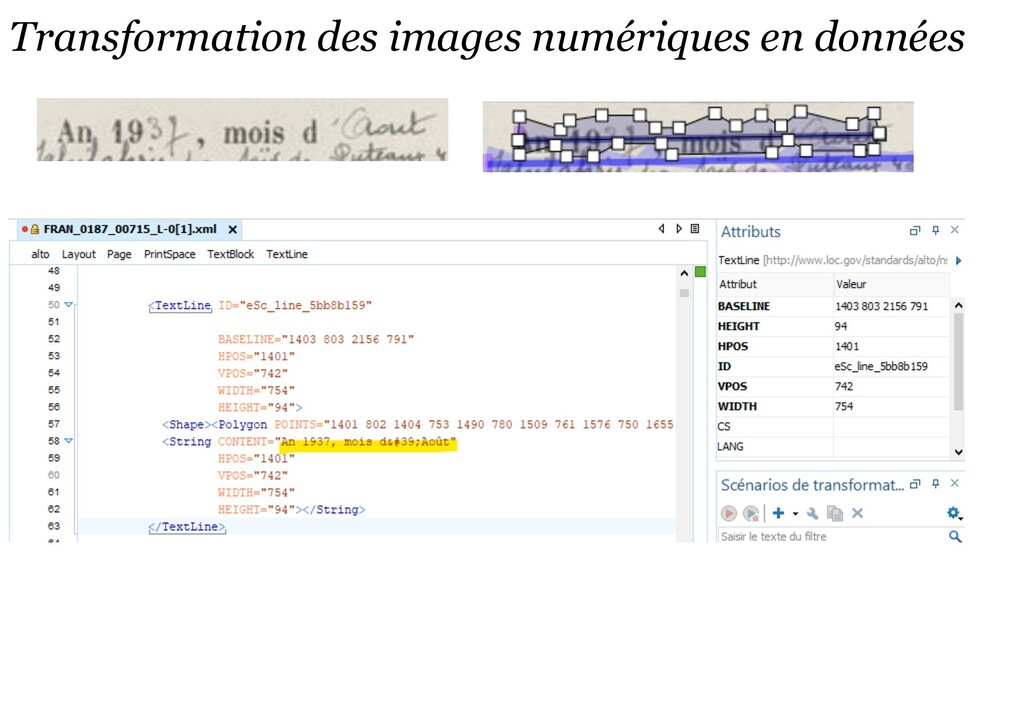
patrimoine écrit > mutualisation de données, modèles et méthodes documentés, produits avec un logiciel libre (Kraken/eScriptorium – projet Scripta-PSL) Convention-cadre Culture – Inria (DIN/SNUM)
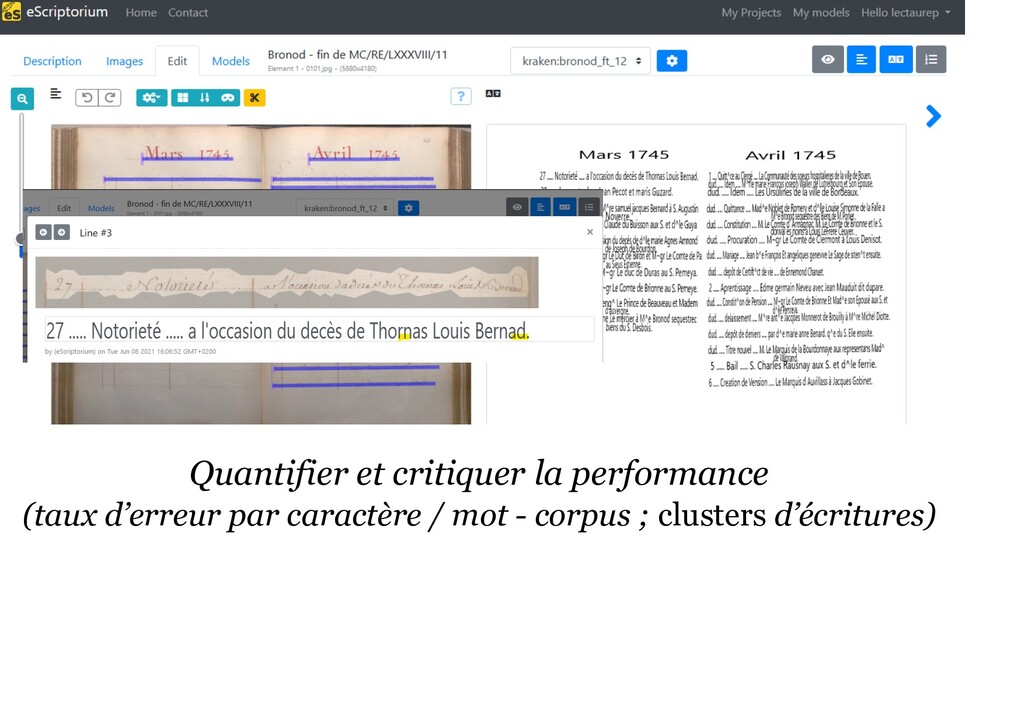
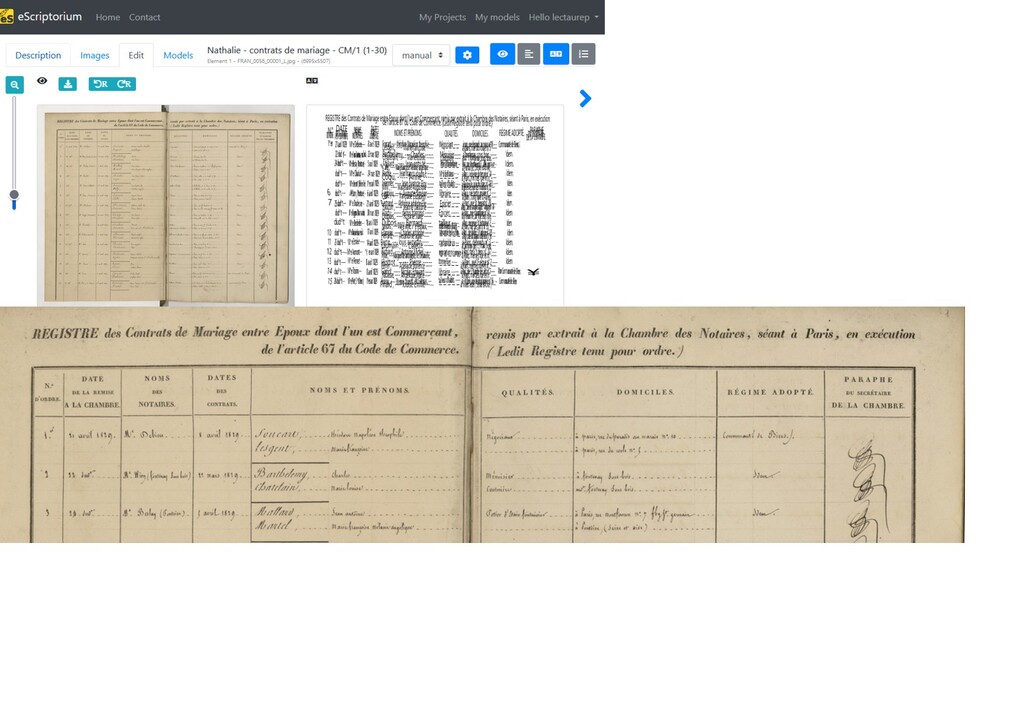
d’entraînement pour une nouvelle main (fond de sauce) * Golden set : 700 pages simples transcrites (10/15 mains, 1830/1836/1850/1901/1907, 6 notaires/2 études) * Random set : 600 pages simples transcrites (une centaine de mains) * Enregistrements de contrats de mariage, séparations, divorces : 144 doubles pages (une dizaine de mains) * Me Bronod (XVIIIe siècle) : 125 doubles pages (une main ; CER < 5 %)
la pseudonymisation des documents) > cf. investigation par le Lab IA d’un outil mutualisé d’OCR + extraction d’informations des documents administratifs
https://gitlab.com/scripta/escriptorium https://readcoop.eu/transkribus https://teklia.com/ > Christopher Kermorvant (Teklia) - Naoned, "Que peut l'intelligence artificielle pour les archives : un état de l'art", https://teklia.com/blog/202106-naoned/ (captation, Viméo, 30'57", 25 juin 2021) Futurs fantastiques - FF21: Fantastic Futures, 3rd International Conference on Artificial Intelligence for Librairies, Archives and Museums (AI4LAM), 9-10 décembre 2021, Paris, BnF https://easychair.org/cfp/FantasticFutures21 > Plusieurs projets d’HTR menés avec différents logiciels (libres ou pas) et différentes infrastructures seront présentés.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}