Artificielle: panorama • Les grands cas d’usage de l’IA • Les notions clés de l’IA 10h30 - 11h30 : Intelligence Artificielle: pour aller plus loin • Les grandes étapes d’un projet IA • Réussir sa campagne d’annotation • Les métriques d’évaluation des modèles 11h40 - 12h00 : Ateliers participatifs • Suis-je prêt à démarrer mon projet?
publique. • Apprentissage sur des données structurées ; • Apprentissage sur des données images ; • Apprentissage sur du langage naturel ; • Apprentissage sur des données de voix.
d’intérêt ; ◦ Prédire les prix de l’essence ; • Classification automatique ; ◦ Prédire si une entreprise va embaucher ou non dans les trois prochains mois ; • Segmentation automatique ◦ Regrouper automatiquement les bâtiments avec les mêmes profils de consommation énergétiques.
: prédire une défaillance d’entreprises à partir de données de type URSSAF (cotisations, effectifs, dettes) ou DIRECCTE (demande d’activité partielle, etc) ; • Il s’agit d’un problème de classification : on prédit une défaillance dans les 12 prochains mois ; • L’algorithme produit un classement qui permet de prioriser les visites en fonction de la probabilité défaillance.
potentiel solaire des toits en France ? • Classification des toits en quatre catégories : • Nord-Sud, Est-Ouest, plat, autres • Annotation humaine via une interface (45 000 bâtiments) ; • Généralisation avec un modèle de classification automatique. • https://www.data.gouv.fr/fr/organizatio ns/opensolarmap/
modèles de voitures pour limiter les erreurs dans les procès verbaux ? (ANTAI) • Deux étapes : • Détection de la voiture dans l’image • Classification du modèle de voiture • https://iaflash.fr/testapi/matchvec
détecter les occupations irrégulières du sol dans les zones à risque (DDTM Hérault) • Deux étapes : • Annotation d’images aériennes pour détecter les caravanes, les mobil-homes, les navires, les constructions en dur • Entraînement d’un modèle permettant de généraliser
automatique d’informations ; • Reconnaître les noms des personnes dans un texte ; • Classification automatique de documents ; • Classifier automatiquement les emails ; • Questions/réponses ou conversations automatisées ; • Répondre automatiquement à des questions ouvertes.
pseudonymiser automatiquement les décisions de justice ? (Cour de cassation et Conseil d’Etat) ; • Détecter automatiquement les prénoms, les adresses, les dates de naissance ; • Deux étapes : • Annotation de décisions ; • Entraînement d’un modèle qui généralise pour l’ensemble des décisions. • https://pseudo.etalab.studio/
Datajust : extraction automatique d’informations sur les préjudices corporels dans la jurisprudence • Projet Ebers (CHU Toulouse) : extraction automatique d’infomations dans les compte-rendus médicaux • Projet Siance (Autorité de sûreté nucléaire) : extraction automatique d’information dans les lettres de suite des inspections
• Pour répondre aux questions des usagers sur le chèque emploi associatif, l’ACOSS a développé un voicebot qui permet de répondre aux questions simples ; • Détecter les “intentions” des questions pour trouver la bonne réponse ; • Distinguer 72 intentions différentes parmi les questions pour trouver la bonne réponse.
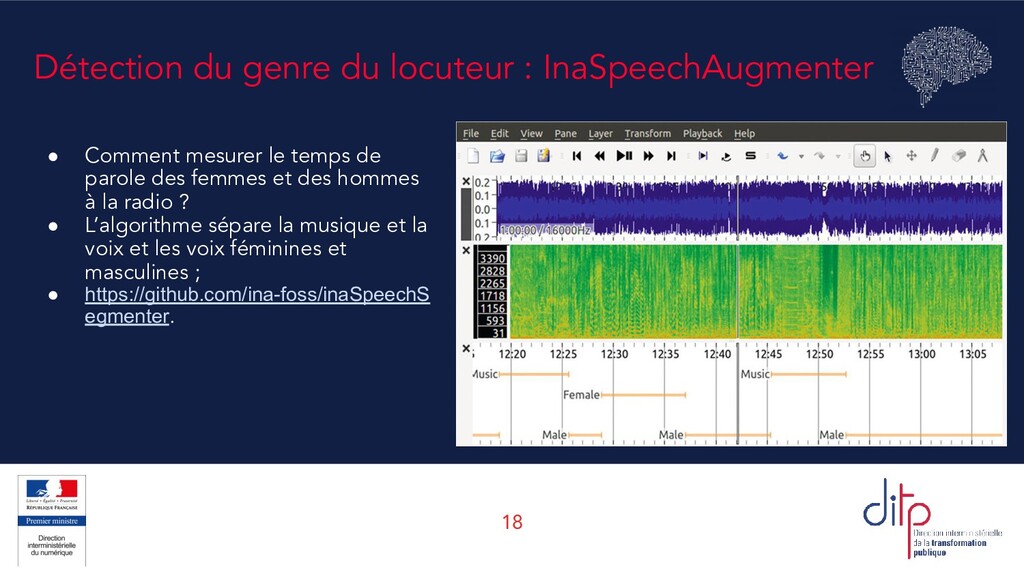
mesurer le temps de parole des femmes et des hommes à la radio ? • L’algorithme sépare la musique et la voix et les voix féminines et masculines ; • https://github.com/ina-foss/inaSpeechS egmenter.
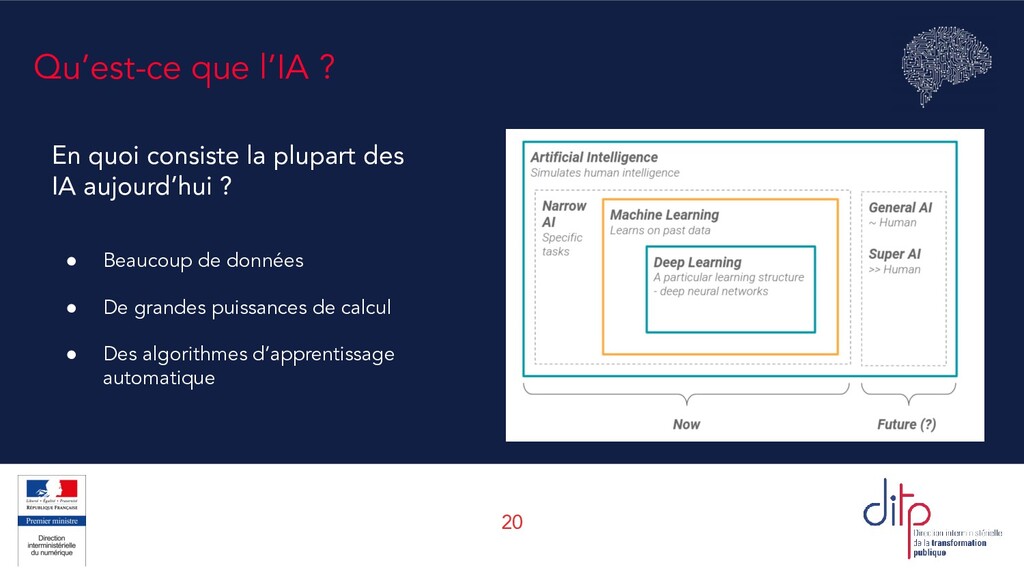
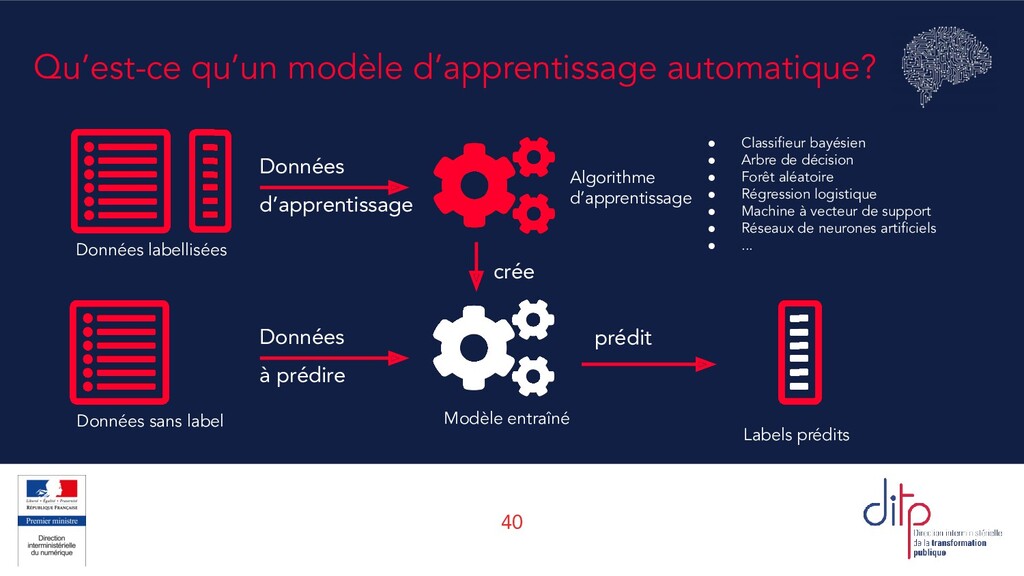
l’IA Qu’est-ce que l’Intelligence Artificielle ? Qu’est-ce qu’un algorithme ? Différence entre apprentissage supervisé et non supervisé Focus sur le supervisé : un exemple simple, la régression linéaire Différence entre statistique et machine learning : décrire ou prédire ? Pourquoi prédire n’est pas comprendre ?
calculs) finie et non ambiguë d'opérations ou d'instructions permettant de résoudre une classe de problèmes. Exemples: une addition, le système de calcul des impôts Cas d’un algorithme d’apprentissage automatique Suite d’opérations (de calculs) pour trouver le modèle le plus performant possible au vue d’un certain critère (la fonction de coût) Dans ce cas, les paramètres de l’algorithme ne sont pas déterminés explicitements mais sont “ajustés” au fur et à mesure de façon automatique Conclusion: les algorithmes sont omniprésents dans les systèmes informatiques. Ils ne correspondent pas nécessairement à de l’IA.
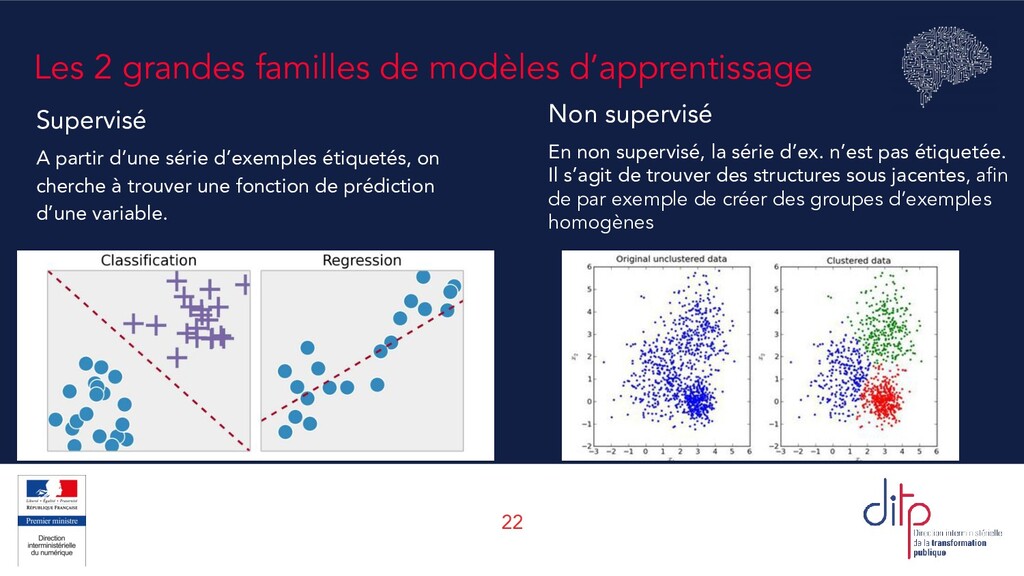
partir d’une série d’exemples étiquetés, on cherche à trouver une fonction de prédiction d’une variable. Non supervisé En non supervisé, la série d’ex. n’est pas étiquetée. Il s’agit de trouver des structures sous jacentes, afin de par exemple de créer des groupes d’exemples homogènes
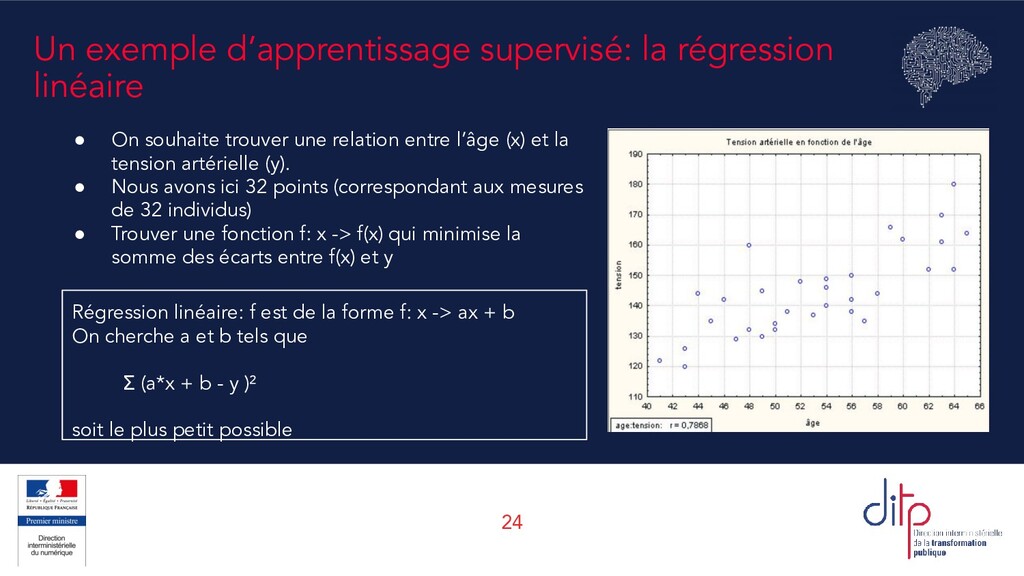
souhaite trouver une relation entre l’âge (x) et la tension artérielle (y). • Nous avons ici 32 points (correspondant aux mesures de 32 individus) • Trouver une fonction f: x -> f(x) qui minimise la somme des écarts entre f(x) et y Régression linéaire: f est de la forme f: x -> ax + b On cherche a et b tels que Σ (a*x + b - y )² soit le plus petit possible
et prédire Dans le premier cas, on l’utilise pour identifier des corrélation et tenter de décrire un phénomène La régression linéaire peut être à la fois un outil de statistique et de machine learning. Dans le second cas, on l’utilise pour prédire: on souhaite, à partir de l’âge d’une personne, estimer sa tension artérielle
: déduire des lois par généralisation des observations, en utilisant les corrélations entre variables. Remarque : la prédiction ne désigne pas nécessairement une estimation d’une valeur dans le futur Nécessité d’une intelligence humaine pour interpréter/ comprendre les résultats d’un modèle. Exemple : l’étude statistique de la localisation des balles sur les avions de guerre (cf. biais du survivant)
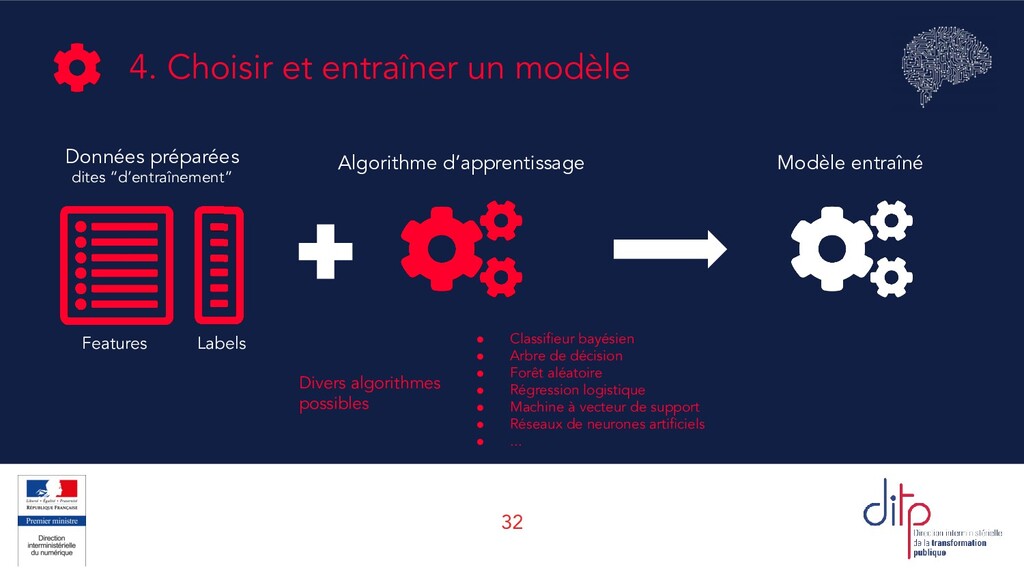
systèmes d’IA font appel des algorithmes supervisés Dans beaucoup de situations, les “labels” à prédire ne sont pas directement disponibles et il faut les créer “à la main” Pour que l’algorithme affiche de bonnes performances, il est essentiel que les labels soient de qualité Évaluer la qualité d’un modèle nécessite des labels dont on
rôle de chacun de ses membres • Un manager qui forme et s’assure de la qualité des annotations • Un ou plusieurs annotateurs Choisir un logiciel d’annotation • Solution existante ou • Développement d’une solution sur mesure? Bien définir les tâches à effectuer: • Faire un schéma synthétique d’annotation • Une documentation détaillée • Un FAQ • Un quizz Évaluer la qualité des annotations • Constitution d’un “gold data set” • Contrôle régulier de la qualité des annotations • Tests de cohérence automatique (optionnel)
d’annotation (extraire beaucoup d’informations) Simplicité/rapidité de la tâche d'annotation Gain de temps de développement avec un outil sur étagère Gain d'efficacité via le développement d'un outil custom Qualité/fiabilité des annotations Rapidité du travail d’annotation VS VS VS
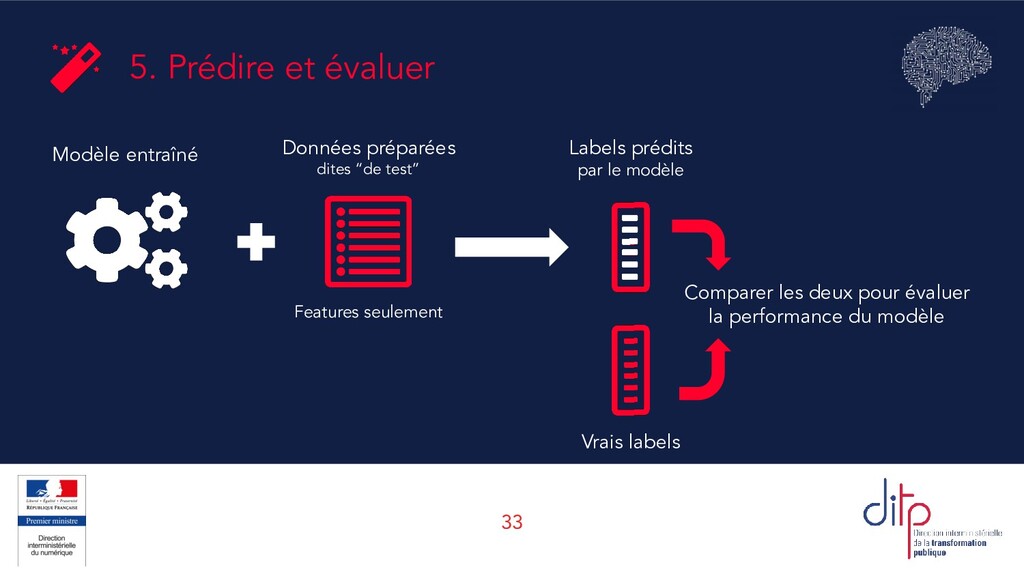
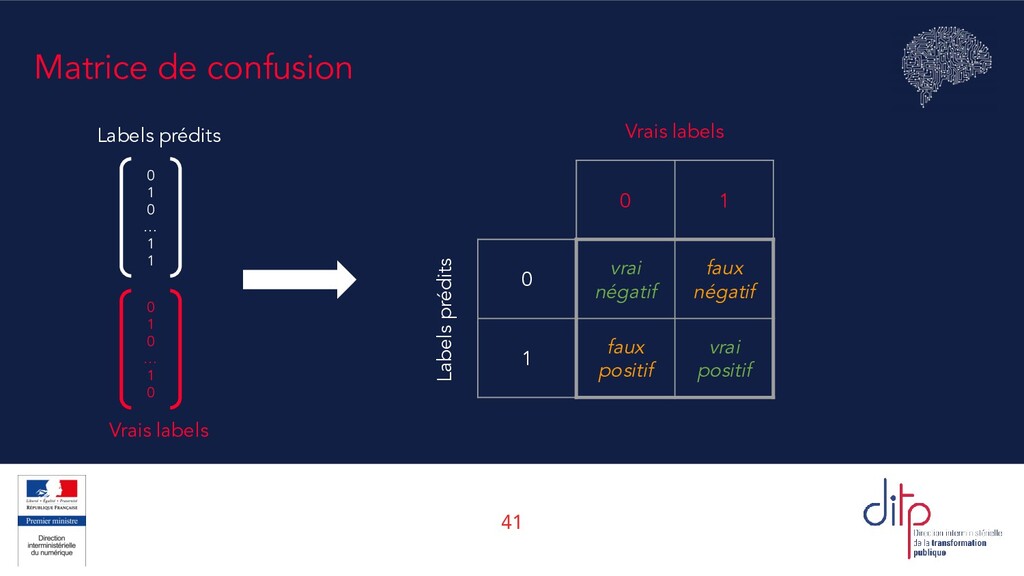
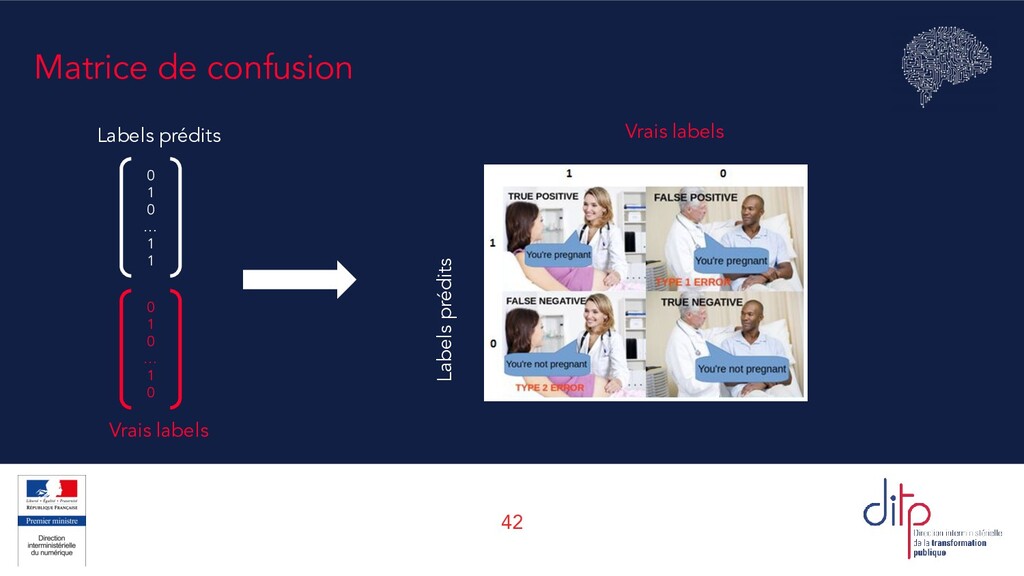
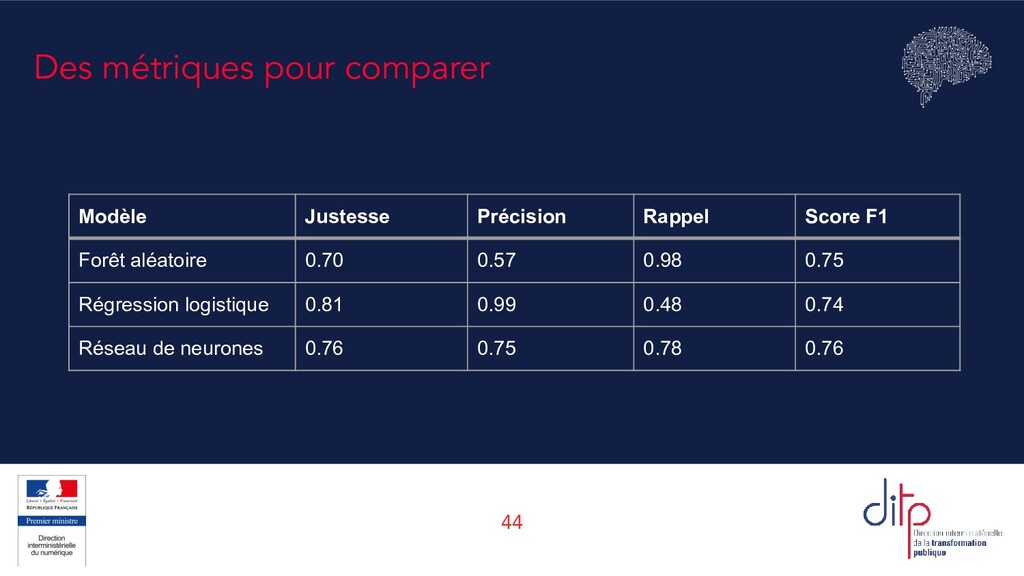
+ VN + FP + FN Une mesure simple : le taux de réponses correctes. Mais ne détaille pas où les erreurs sont commises, entre FP et FN. Précision VP VP + FP Parmi les observations classées positives, combien l’étaient vraiment ? Mesure la capacité à classer juste (qualité). Rappel (recall) VP VP + FN Parmi toutes les observations vraiment positives, combien ont été effectivement classées comme telles ? Mesure l’exhaustivité. Score F (ou score F1) 2 ⋅ précision ⋅ rappel précision + rappel La moyenne harmonique de la précision et du rappel, qui permet de prendre les deux en compte. Existe aussi le F2 score, F0.5, etc.
à mesurer “à quel point la courbe suit bien les points”. Mesure continue et non plus discrète pour chaque observation. Basée sur des mesures d’écart Exemples
l’objectif ? • Quel est le coût de “manquer” une observation positive • Quel est le coût de la vérifier à tort ? • Préférez vous en conséquence précision élevée ou rappel élevé ? • Doit-on toujours sacrifier l’un pour obtenir l’autre ? • Sur quoi peut-on à votre avis jouer pour augmenter l’un ou l’autre ?
ZG_faA/viewform?usp=sf_link Plus d’éléments sur “Comment préparer l’arrivée des prestataires?” ici: https://github.com/etalab-ia/ami-ia/blob/master/accueil-prestataire.md
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}