Oblivious Memories David Evans University of Virginia www.cs.virginia.edu/evans oblivc.org Theory and Practice of Secure Multiparty Computation 2016 Aarhus University 1 June 2016
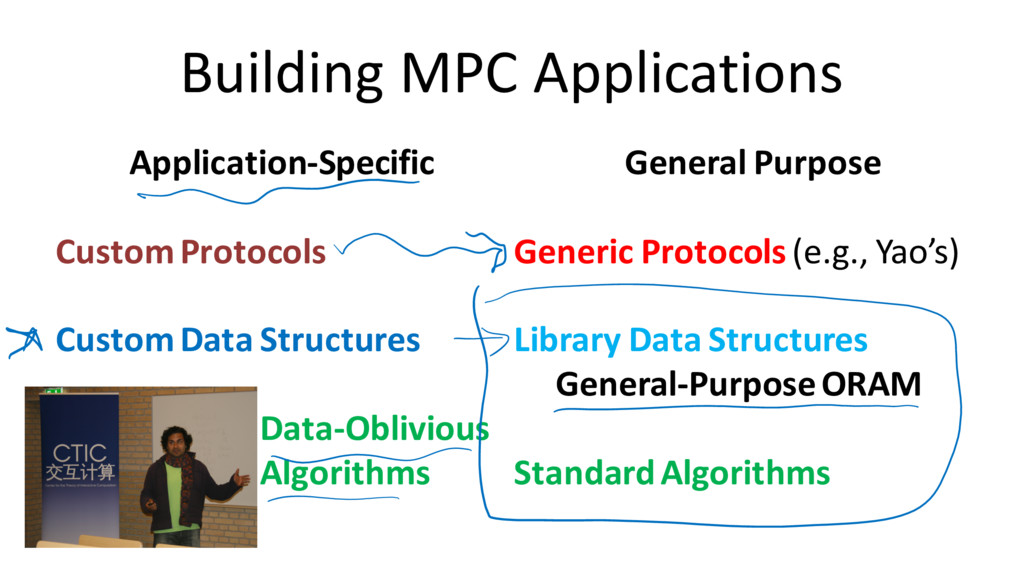
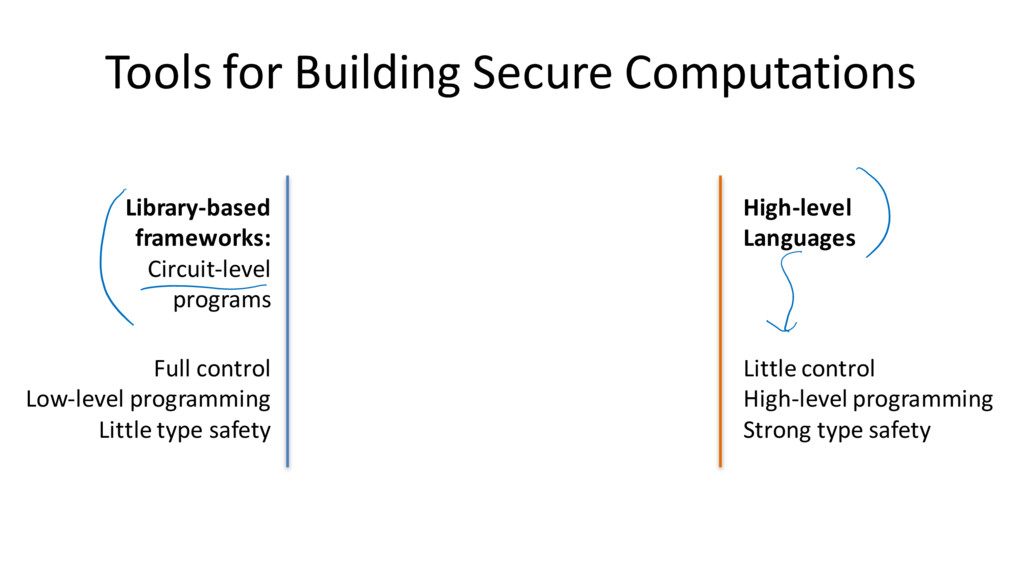
safety High-level Languages Little control High-level programming Strong type safety High-level programming Low-level customizability Helpful, escapabletype checking Tools for Building Secure Computations
regardless of oblivious condition var is Boolean: oblivious condition Programmer has control! But, not security risk: all private data is still encrypted
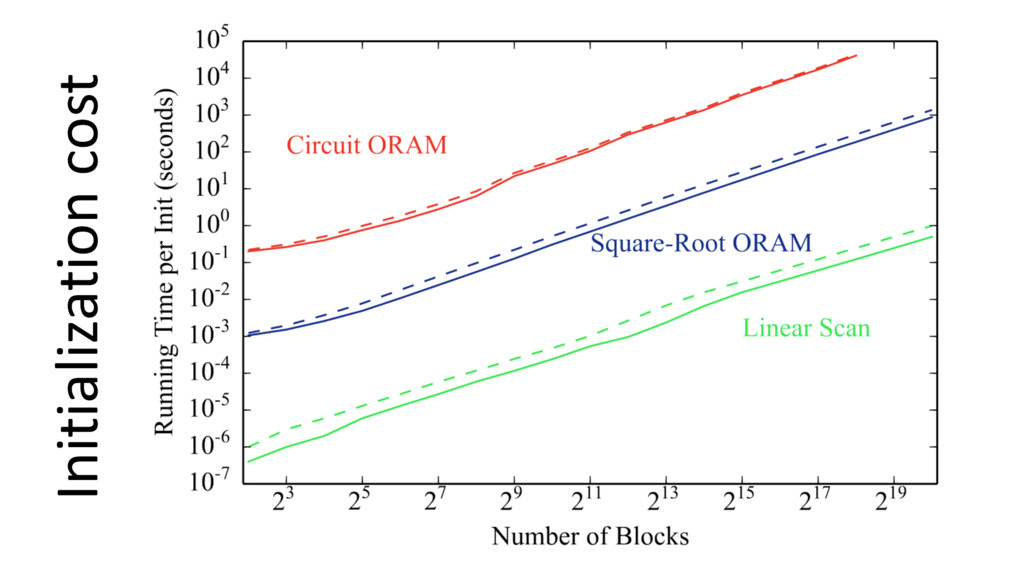
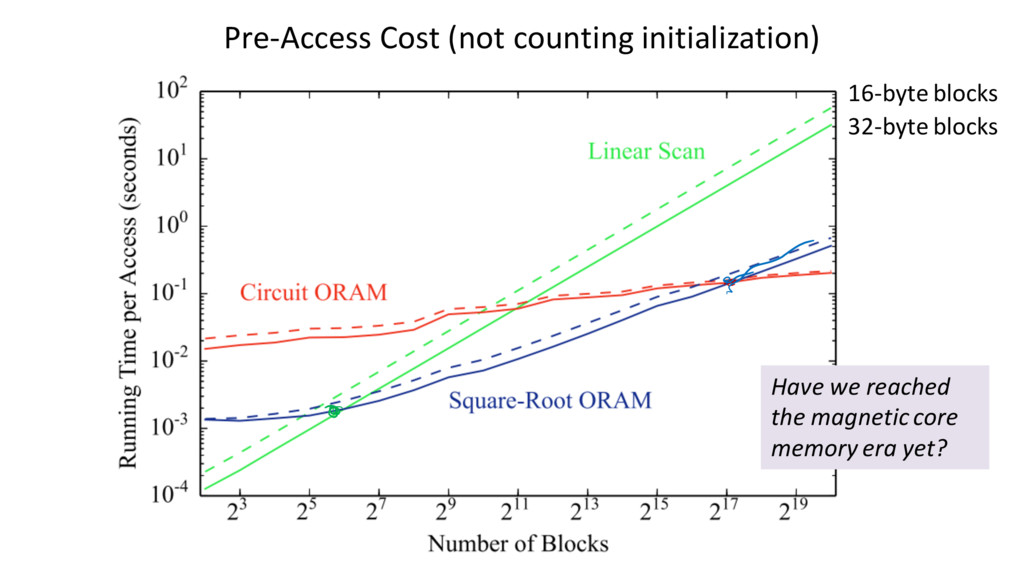
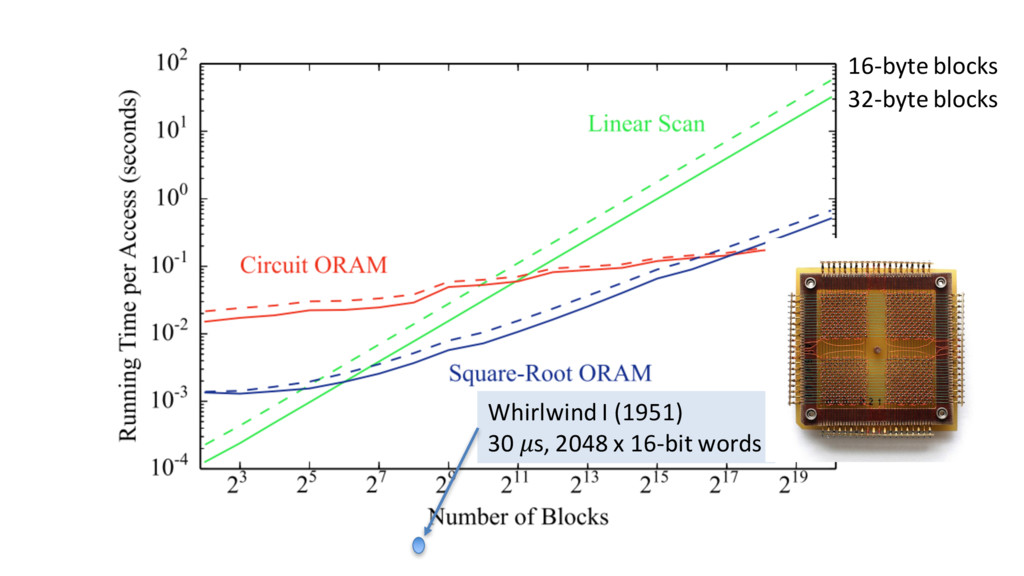
logic gates Raw Yao’s performance ≈ 3M gates per second Write speed ≈ 100,000 elements per second (not hiding access pattern) For hiding access pattern, N = 217 elements requires > 1 second per access
initialization and access sequences of the same length are indistinguishable to server. Sublinear client-side state Linear server-side encrypted state Initialize Access
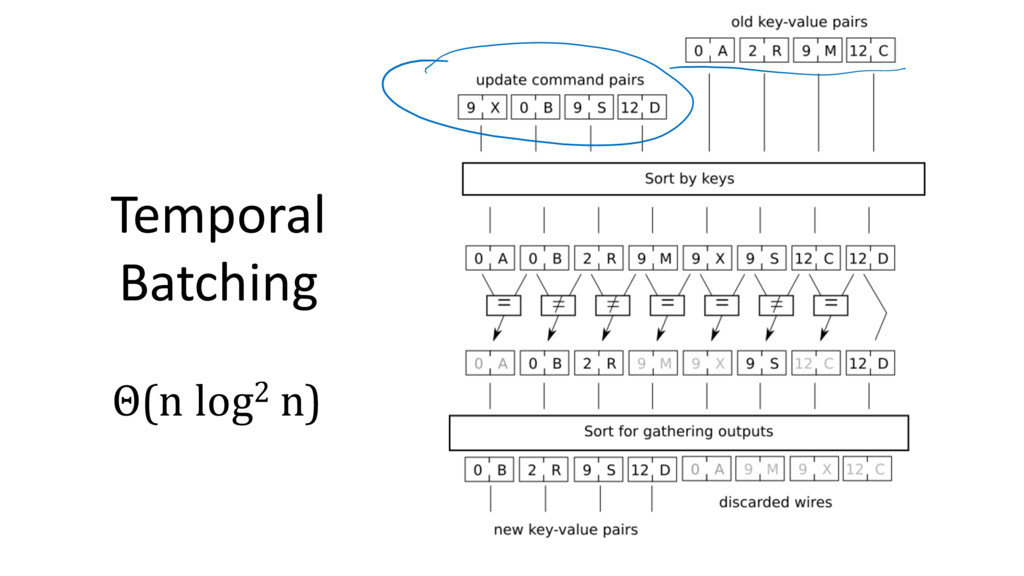
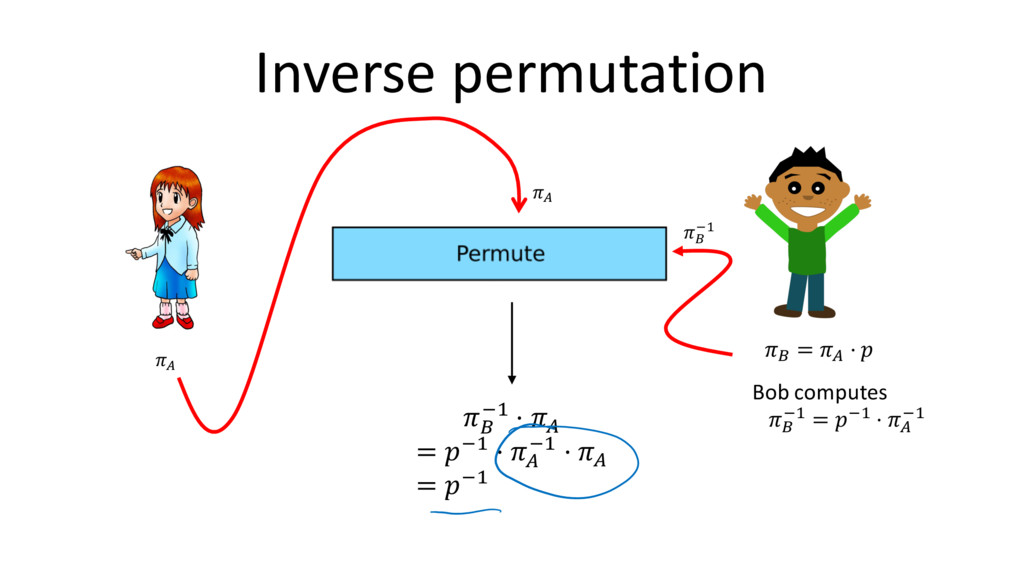
ORAM access – PRF is a big circuit in MPC • Initialization requires PRF evaluations • Requires oblivious sort twice: – Shuffling memory according to PRF – Removing dummy blocks Solution strategy: use random permutation instead of PRF
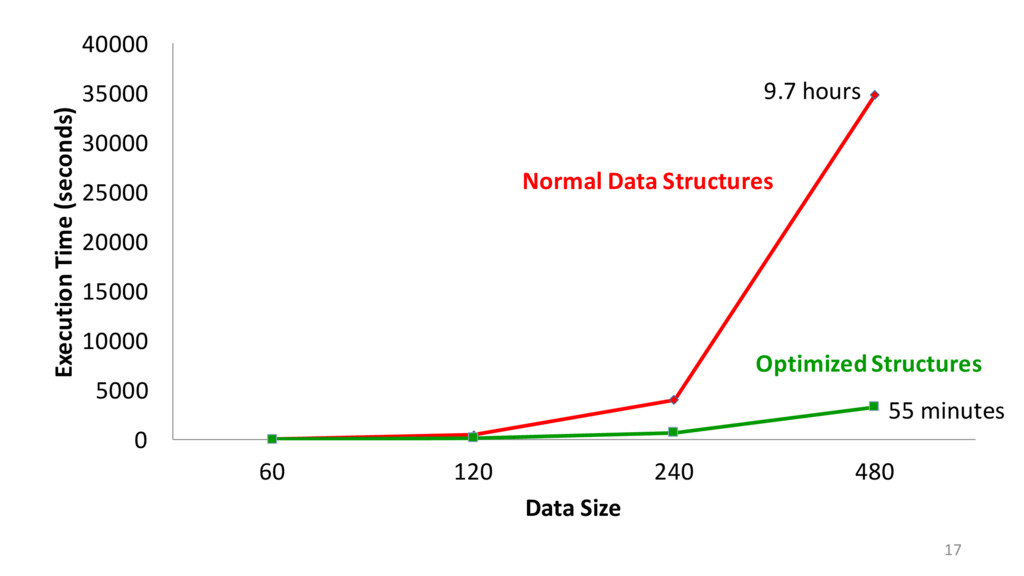
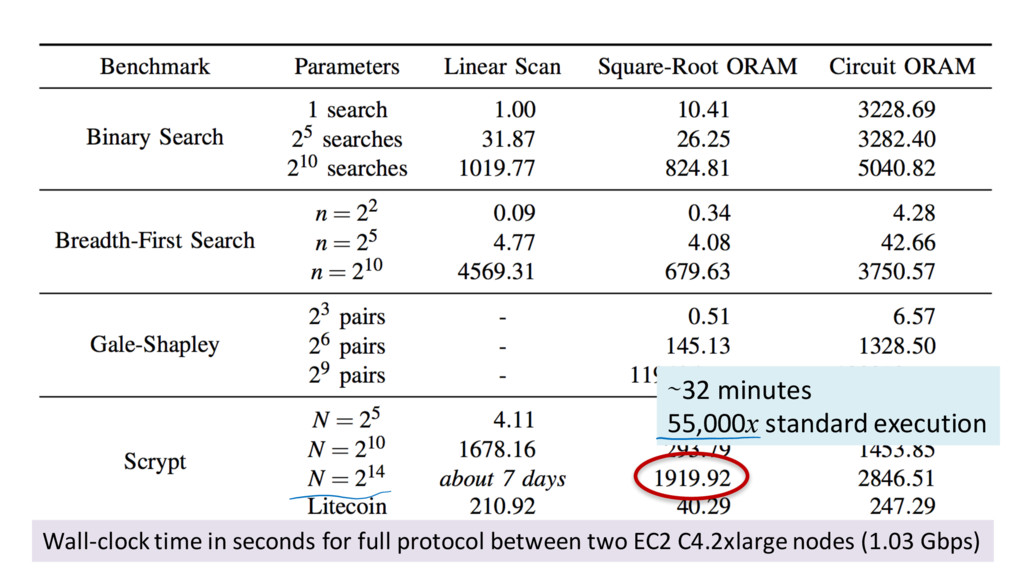
optimization: using custom data structures when memory access predictable • Stronger security models: active security – All results are semi-honest model • Establishing Meaningful Trust 64 KB memory 1 s access (∼2000x improvement)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Crazy Things in Typical Code 5 a[i] = x](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_4.jpg){kind=link}
![Circuit for Array Update 6 i == 0 a[0] x](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_5.jpg){kind=link}
{kind=link}
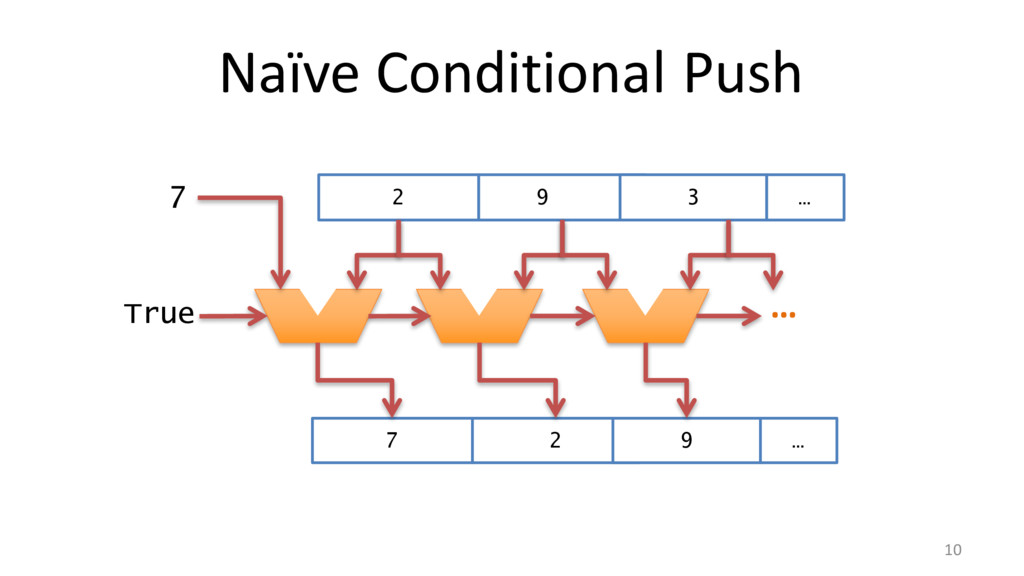
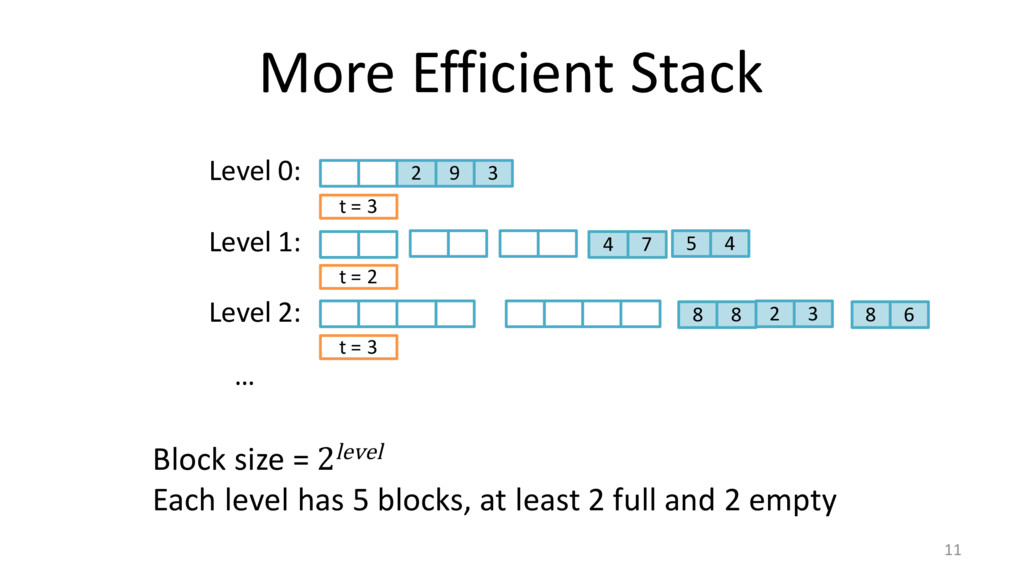
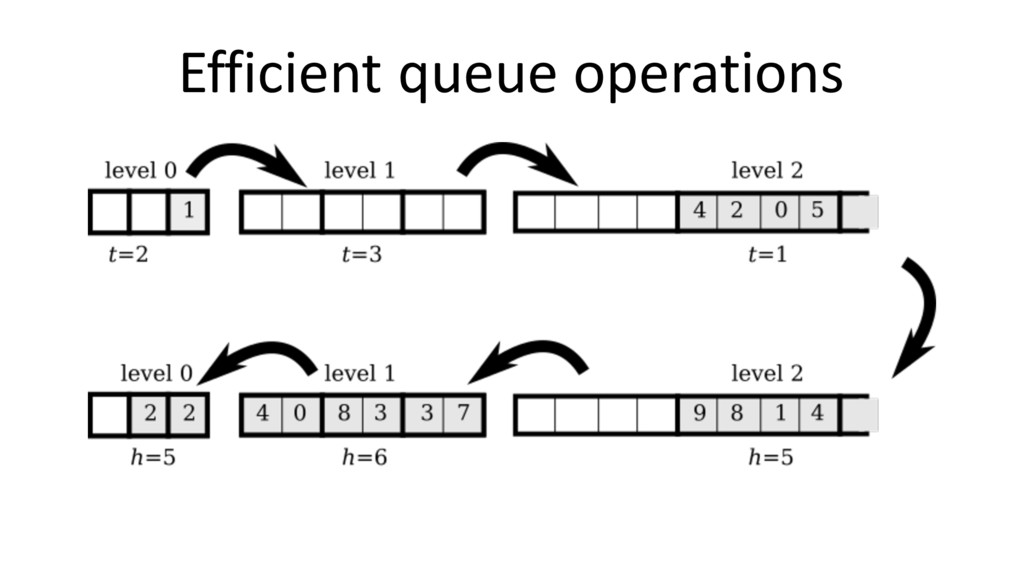
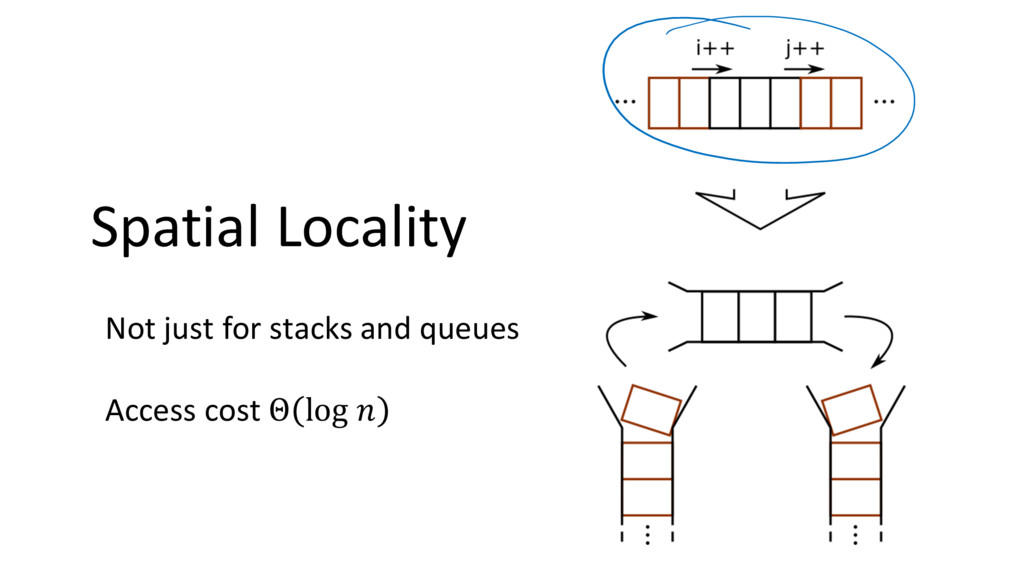
![Locality: Stacks and Queues 8 if (x != 0) a[i]](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_7.jpg){kind=link}
![Naïve Conditional Push 9 … p x a[0] a[1] a[2]](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obliv-C #include <million.h> int main (int argc, char ∗argv[]) {](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
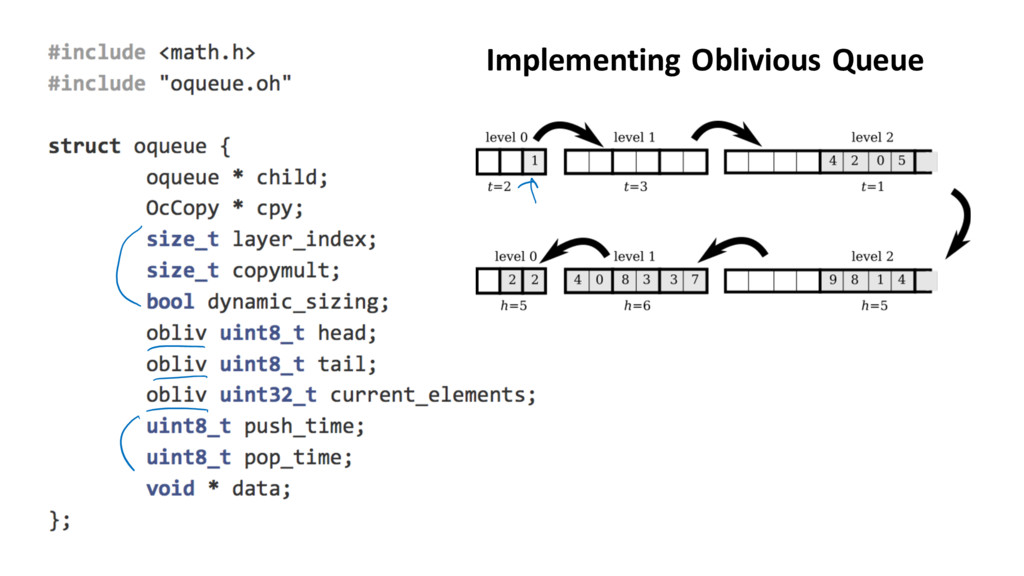{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
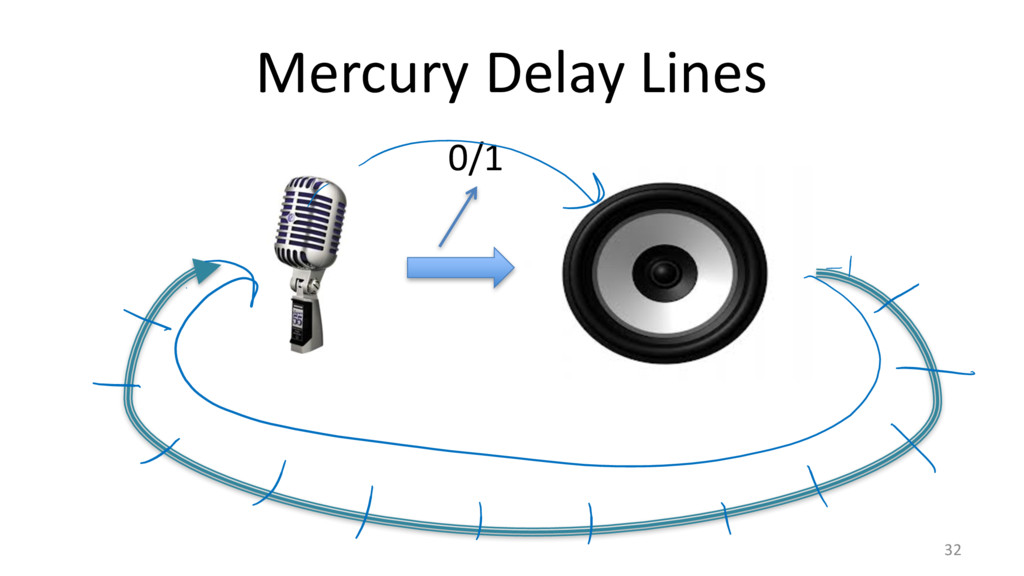{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Traditional ORAM Client Untrusted Server [Goldreich 1987] Security property: all](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_38.jpg){kind=link}
![RAM-SC [Gordon, Katz, Kolesnikov, Krell, Malkin, Raykova, Vahlis 2012] Alice](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_39.jpg){kind=link}
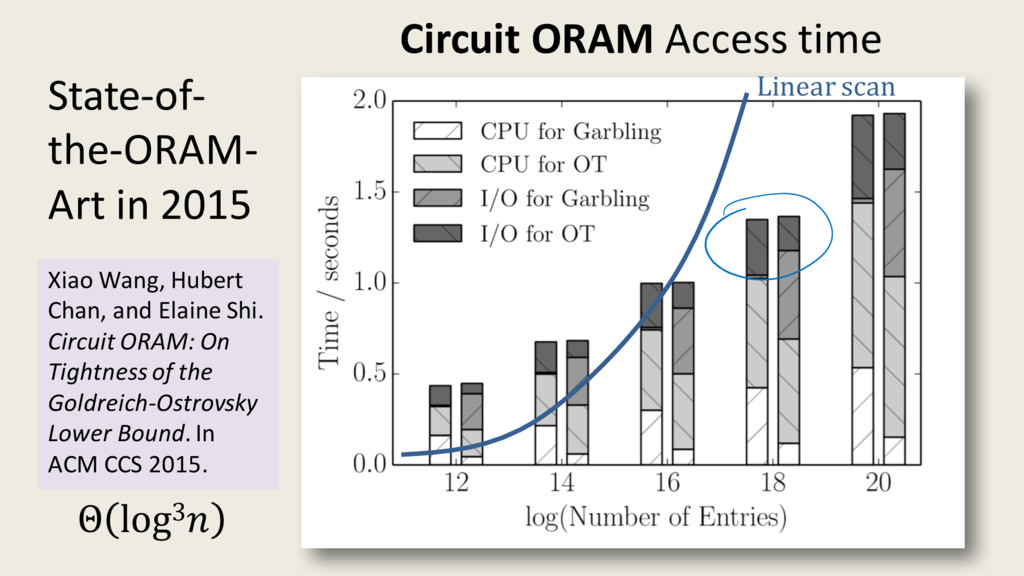{kind=link}
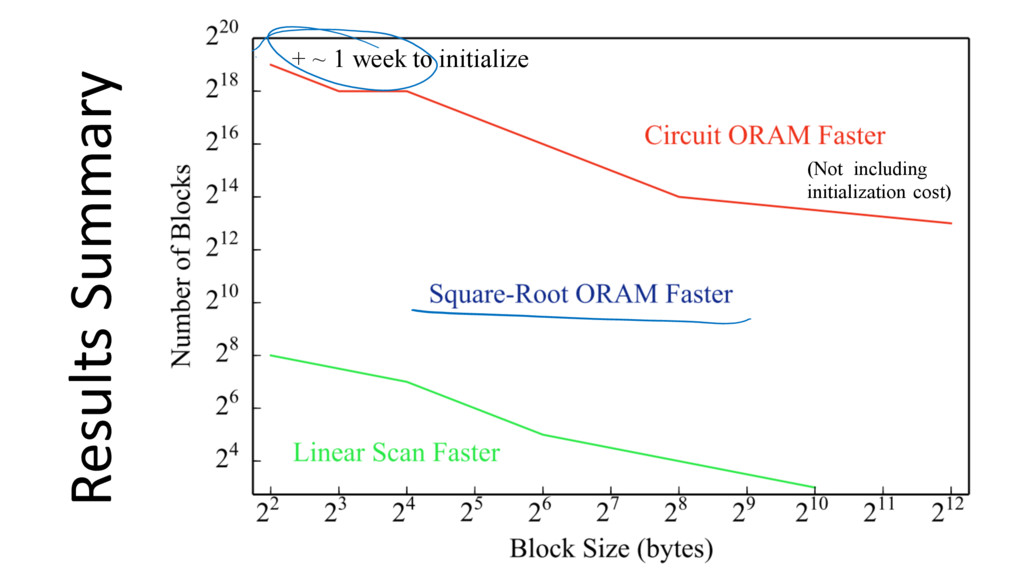{kind=link}
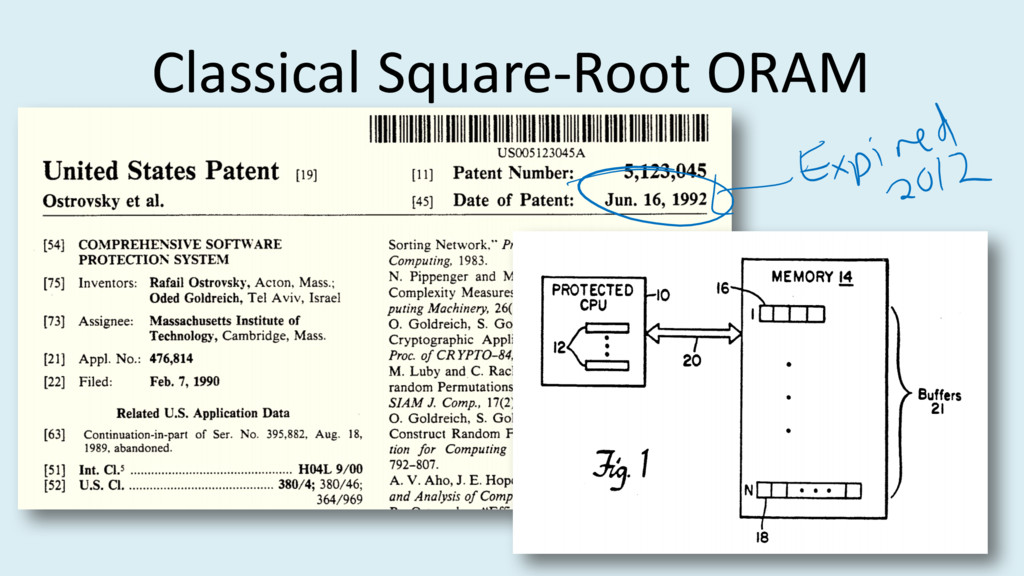{kind=link}
{kind=link}
![Shuffling Network [Waksman 1968] Cost per shuffle: 5B](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_44.jpg){kind=link}
{kind=link}
{kind=link}
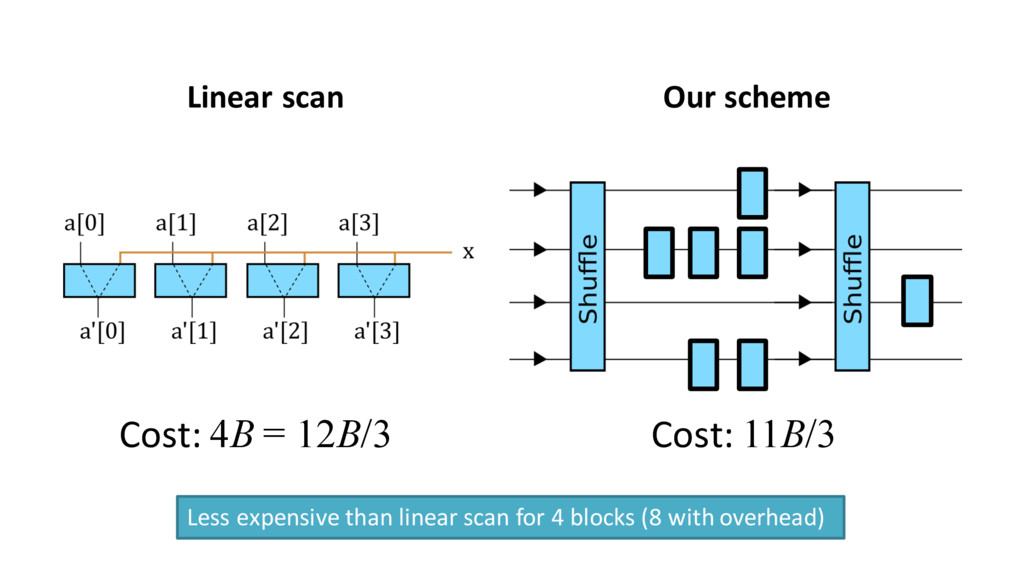{kind=link}
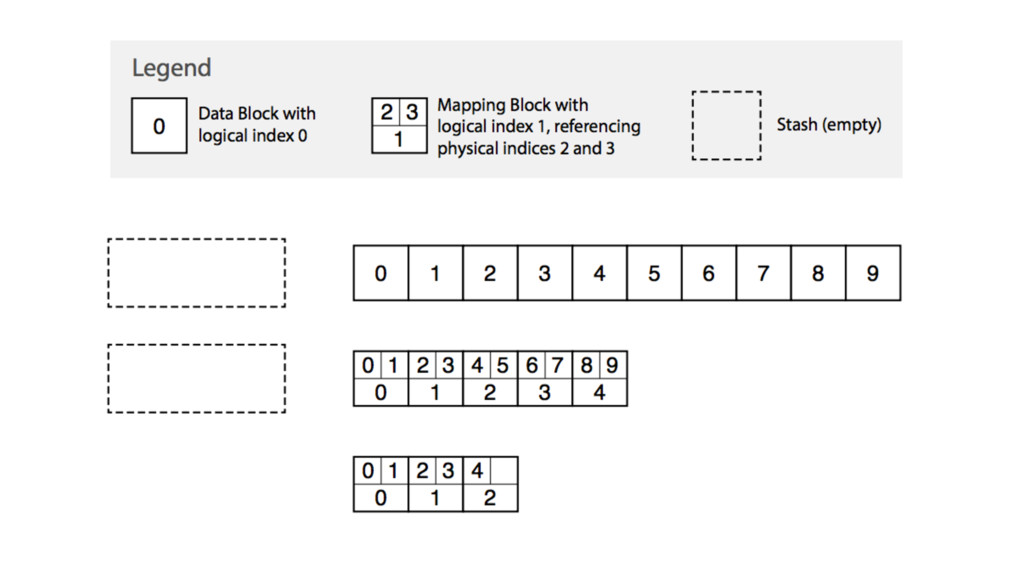{kind=link}
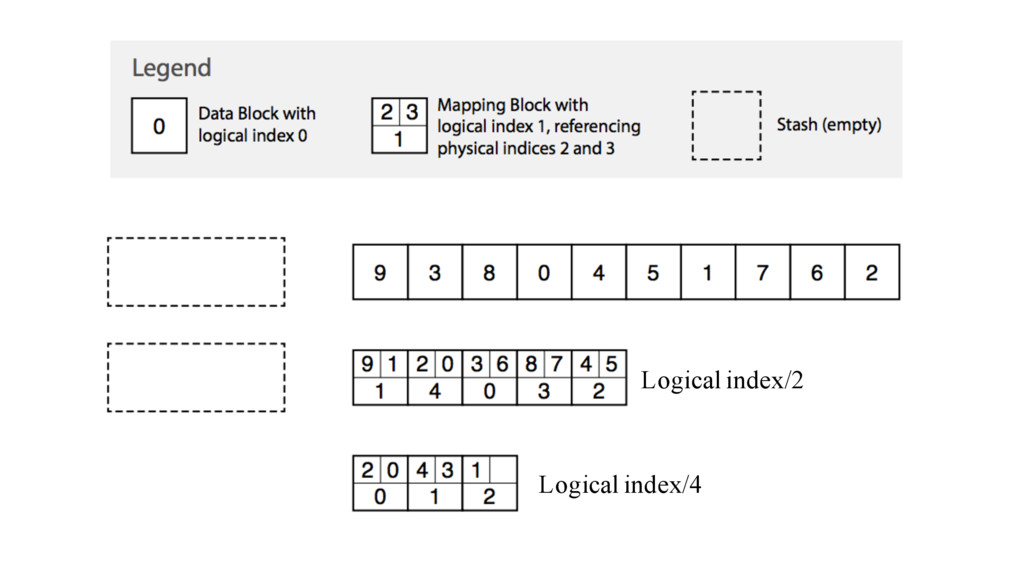{kind=link}
![Logical index/4 Logical index/2 read a[8] First Access](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_50.jpg){kind=link}
![Logical index/4 Logical index/2 read a[8] First Access](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_51.jpg){kind=link}
![Logical index/4 Logical index/2 read a[8] First Access](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_52.jpg){kind=link}
![Logical index/4 Logical index/2 read a[8] First Access](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_53.jpg){kind=link}
![Logical index/4 Logical index/2 read a[8] First Access](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_54.jpg){kind=link}
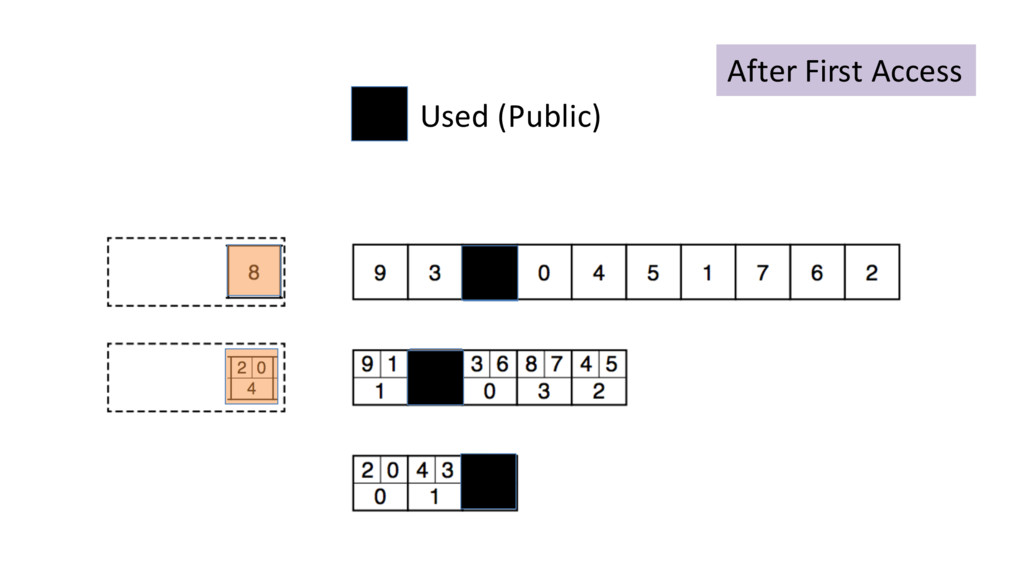{kind=link}
![Second Access read a[9]](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_56.jpg){kind=link}
![Second Access read a[9] Randomly select unused element](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_57.jpg){kind=link}
![Second Access read a[9] Randomly select unused element Randomly select](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_58.jpg){kind=link}
![Second Access read a[9] Randomly select unused element Randomly select](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_59.jpg){kind=link}
![Second Access read a[9] Randomly select unused element Randomly select](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_60.jpg){kind=link}
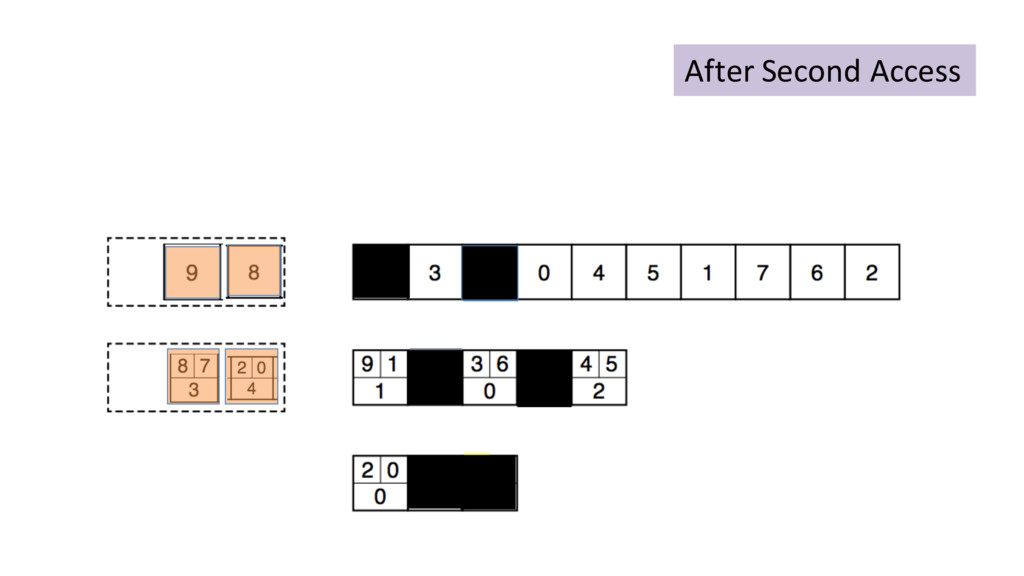{kind=link}
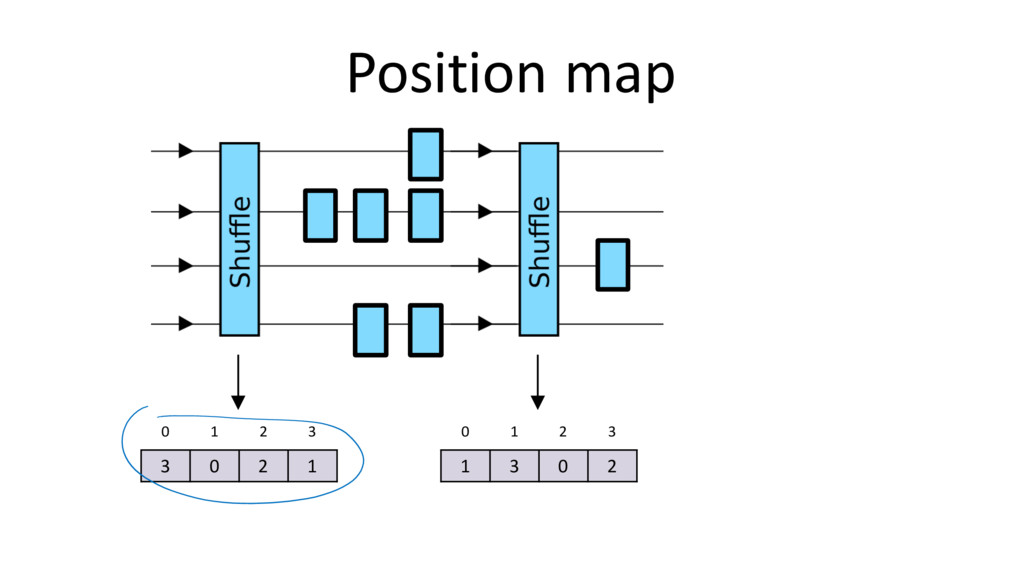{kind=link}
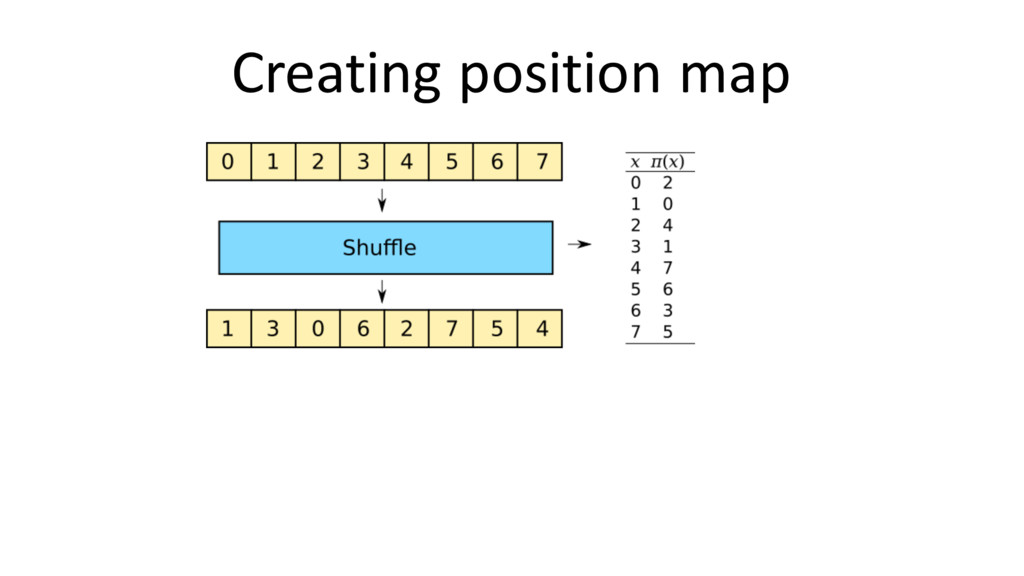{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![David Evans [email protected] www.cs.virginia.edu/evans OblivC.org mightBeEvil.org](https://files.speakerdeck.com/presentations/842b989ea55944eab157702bbb71a5fb/slide_77.jpg){kind=link}