18 [1] 山田健太, 青田雅輝 (2024). マルチモーダルな深層学習手法を用いた政治資金収支報告書の判読 の試み. 2024年度日本選挙学会総会・研究会. [2] 大村和正, 白井穂乃, 石原祥太郎, 澤紀彦 (2023). 極性と重要度を考慮した決算短信からの業績要 因文の抽出. 言語処理学会第29回年次大会発表論文集. [3] Shotaro Ishihara, Hiromu Takahashi, and Hono Shirai (2023). Quantifying Diachronic Language Change via Word Embeddings: Analysis of Social Events using 11 Years News Articles in Japanese and English. 9th International Conference on Computational Social Science.
[7] • ユーザ入力画像を用いた記事推薦 [8] • 生成的推薦による人気バイアスの分析 [9] 提供:閲覧数以外も考慮した推薦システム 22 [7] Atom Sonoda, Fujio Toriumi, and Hiroto Nakajima (2024). User Experiments on the Effect of the Diversity of Consumption on News Services. IEEE Access. [8] Kota Tanabe, Shotaro Ishihara, Kenta Yamada, Masaki Aota, and Yasutsuna Matayoshi (2025). Making News Familiar: News Recommendation from Daily Scenery. Proceedings of the KES2025.
[10] Norihiko Sawa (2020). Test headlines on News Media by Multi-Armed Bandit: Case Study of Multi-Armed Bandit to raise CTR of Articles. Computation + Journalism Symposium 2020.
Models: A Survey. Proceedings of the TrustNLP 2023. コーパスの前処理,事前学習の工夫,モデルの後処理など[13] Defense: Training Defense: Pre-processing Defense: Post-processing data deduplication data sanitization regularization differential privacy filterling confidence masking knowledge distillation 50 どう対応するべき?
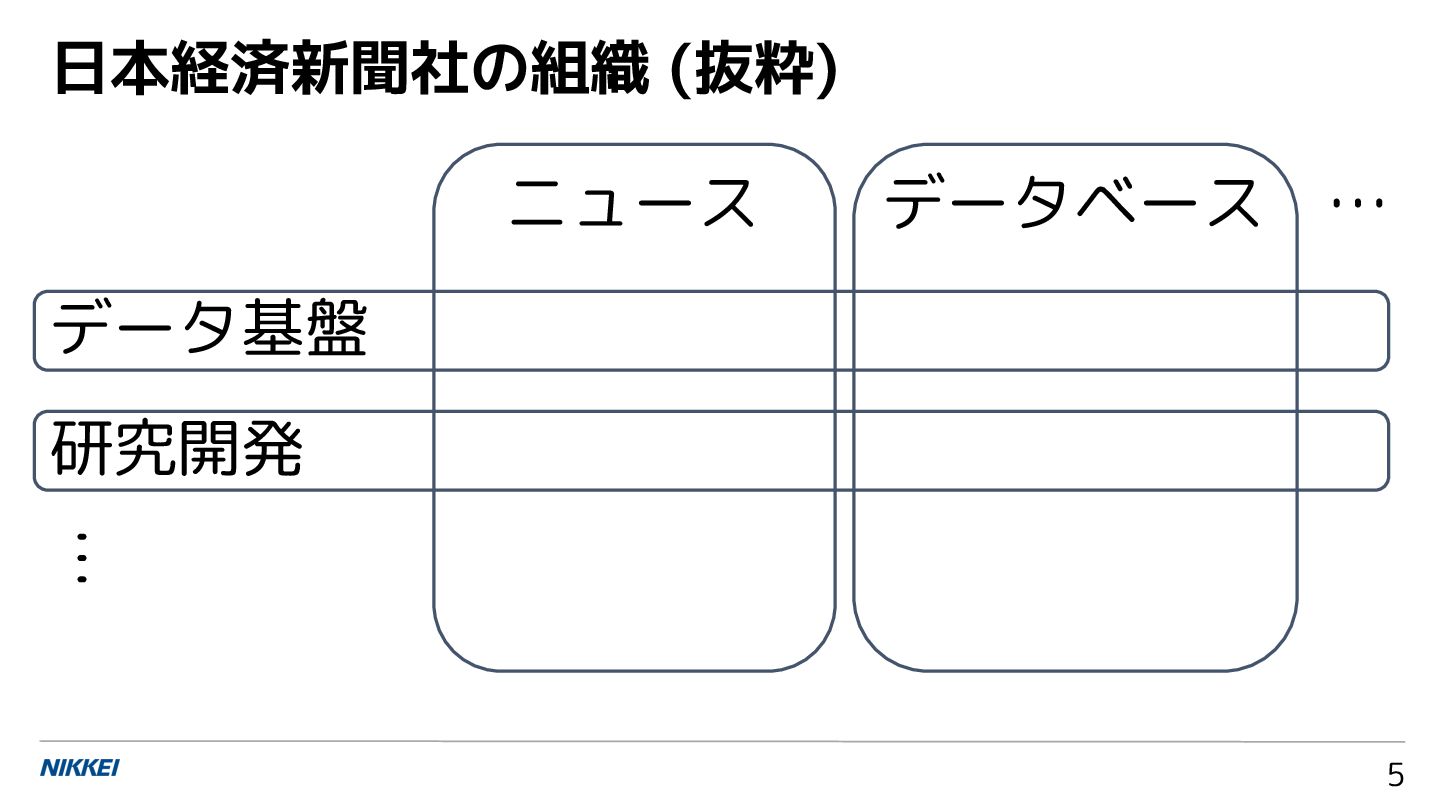
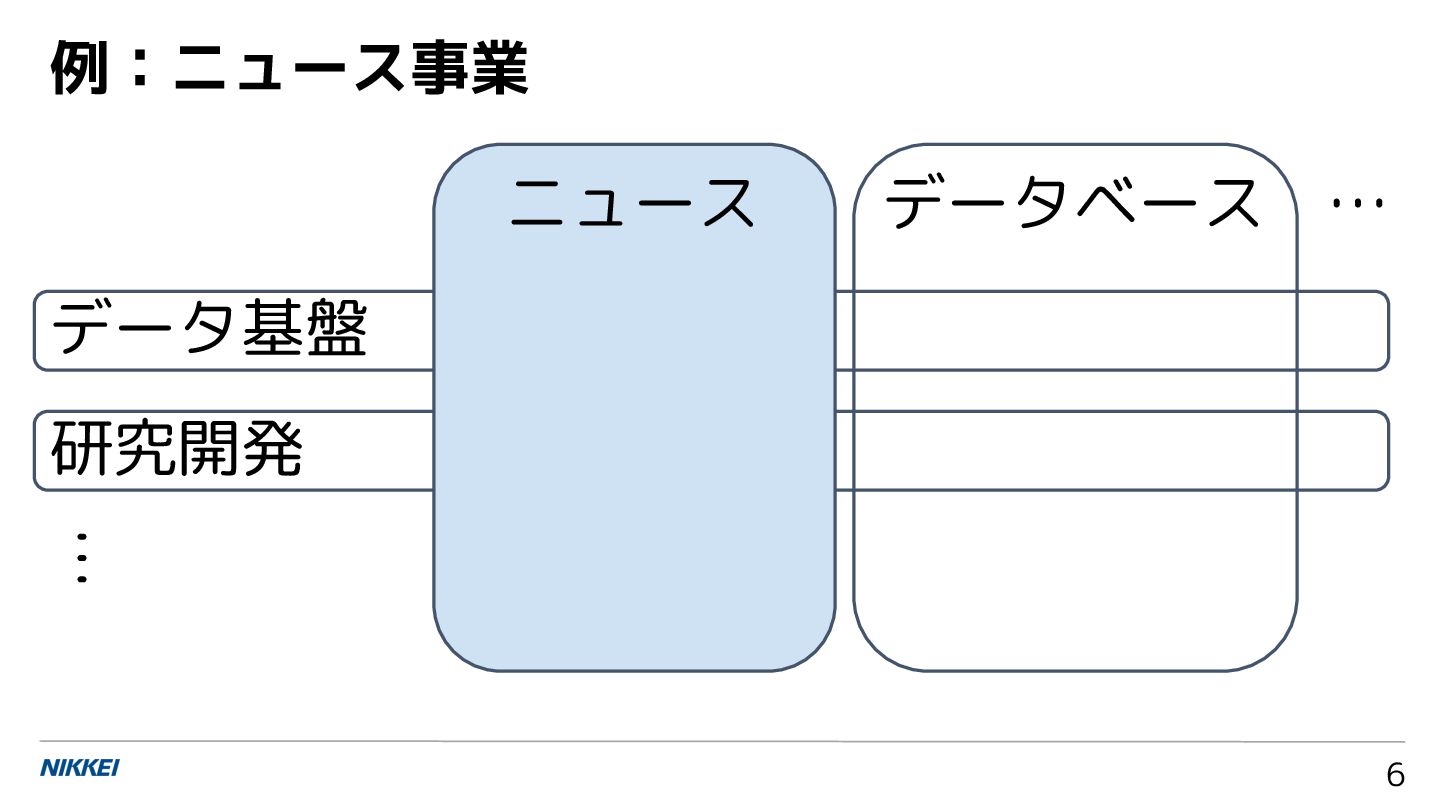
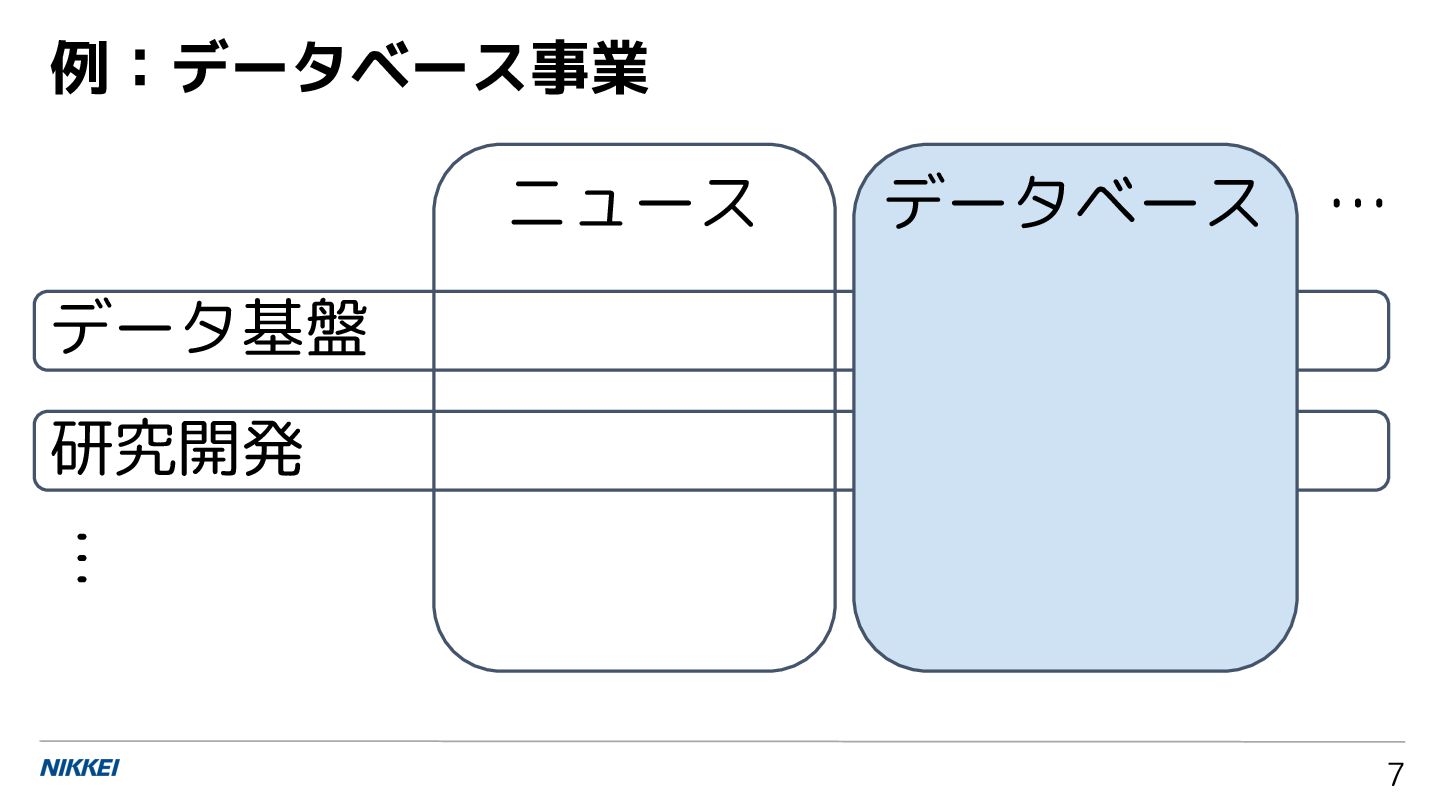
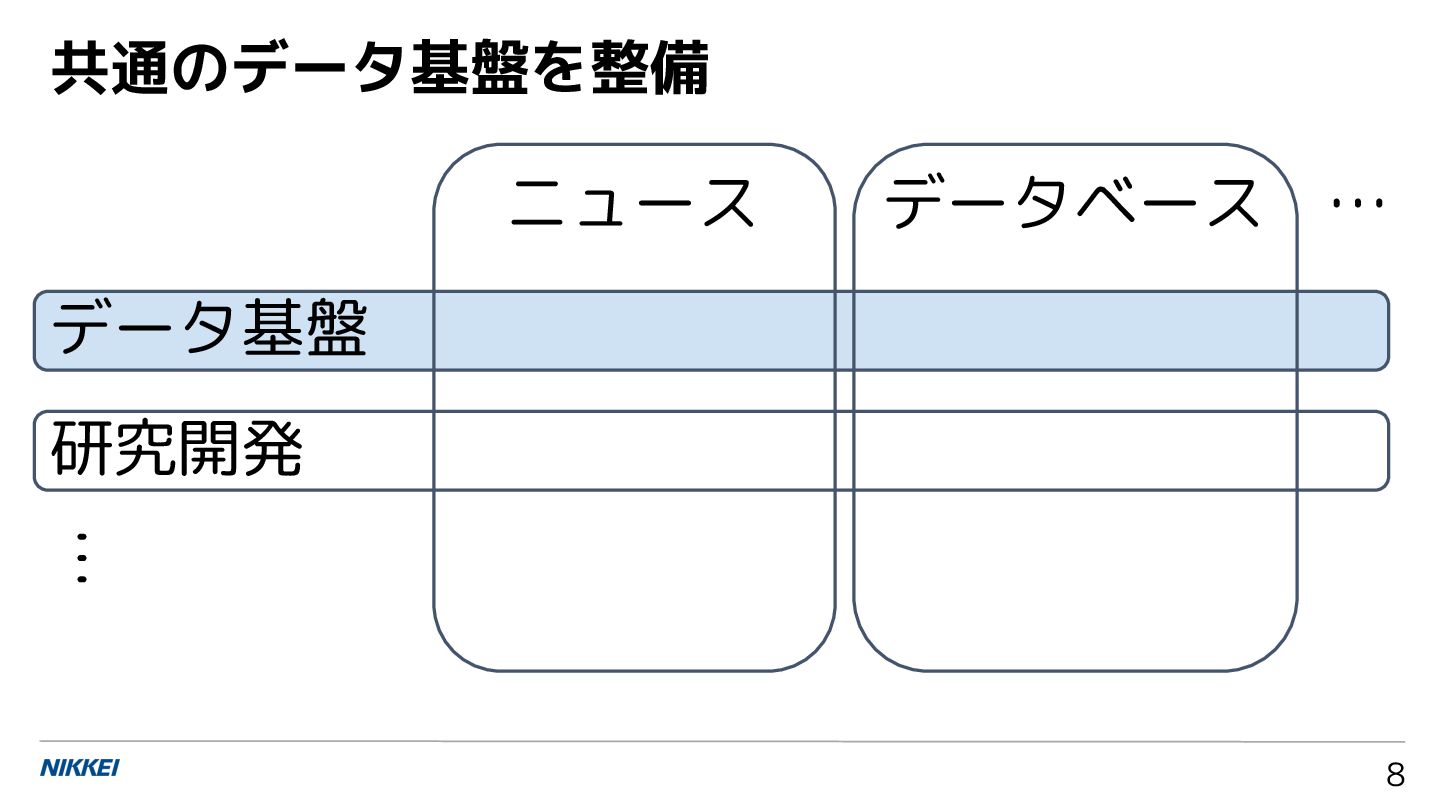
![情報技術の社会実装に向けた 応用と課題:ニュースメディ アの事例から 石原祥太郎 [email protected] 日本経済新聞社 日経イノベーション・ラボ 上級研究員 第 9](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
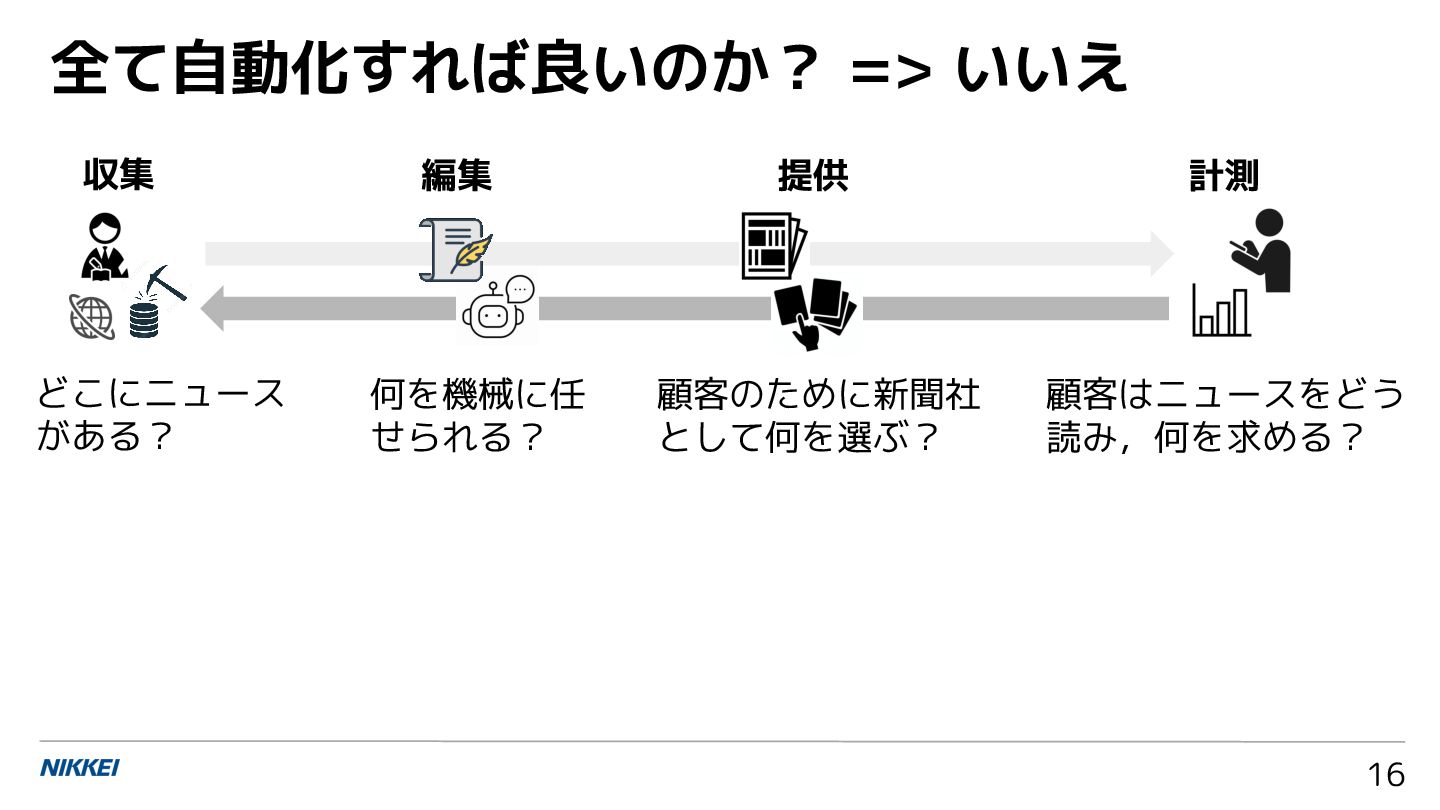
![• 政治資金収支報告書の画像からの数値情報抽出 [1] • 決算短信からの業績要因文の抽出 [2] • 新聞記事を対象とした単語の意味変化の分析 [3] 収集:収集対象や方法を工夫する勘所が必要](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_17.jpg){kind=link}
{kind=link}
![• 独自 T5 による要約生成 [4] • 記事の校正や校閲 [5] • 組合せ探索によるクロスワードパズル作成](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_19.jpg){kind=link}
{kind=link}
![[9] 石原祥太郎 (2025). 生成的推薦の人気バイアスの分析:暗記の観点から. 2025年度人工知能学会 全国大会発表論文集. • 推薦システムと多様性の分析 with 東大・鳥海研](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_21.jpg){kind=link}
{kind=link}
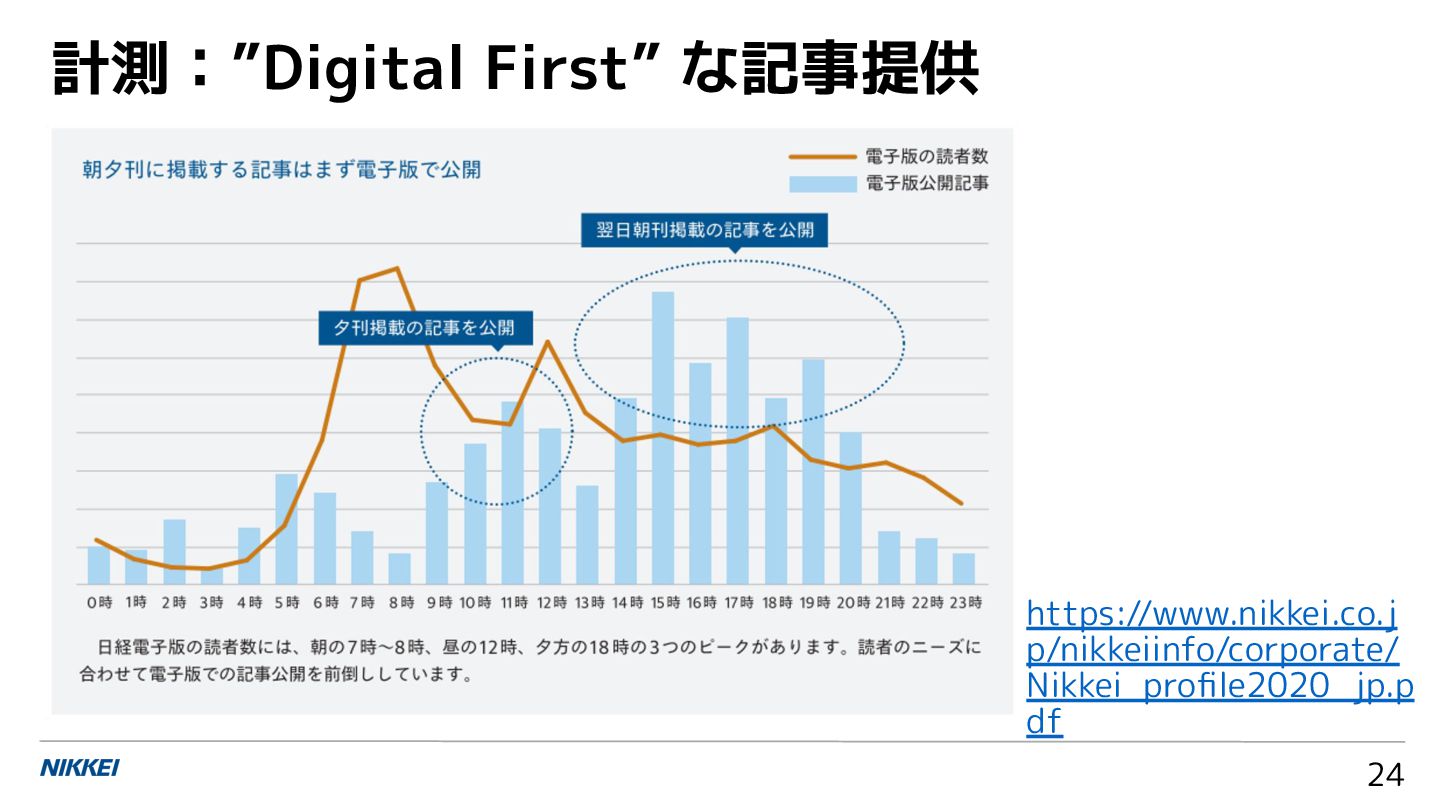{kind=link}
![計測:A/B テストによる記事提供 [10] 25 クリック率: 3 % クリック率: 1 %](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
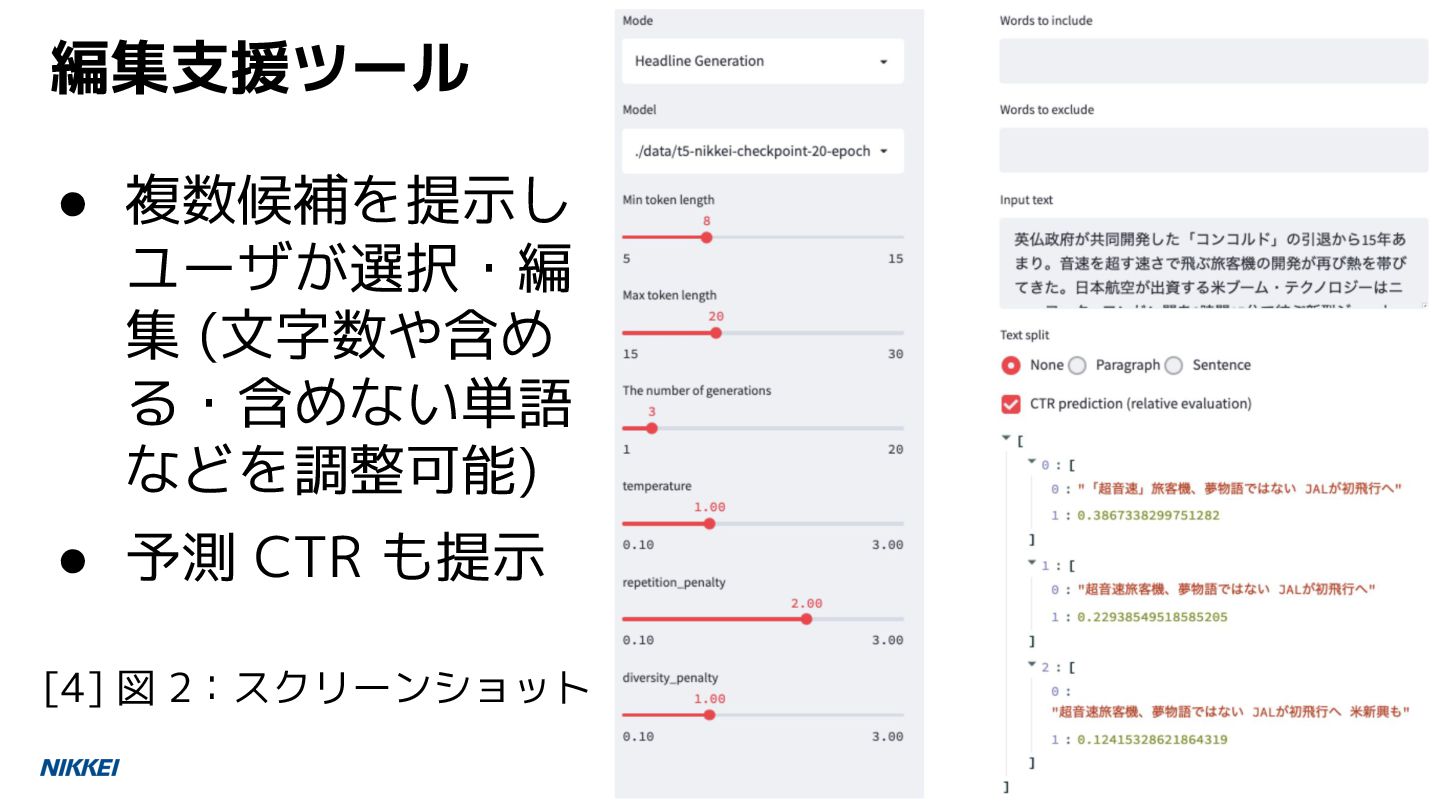
![編集者の見出し・3 行まとめとの一致度合いで評価 38 日経電子版 T5 で ROUGE が最良に [4] 表](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_37.jpg){kind=link}
{kind=link}
{kind=link}
![41 幻覚を含む場合,平均情報量が多い [4] 表 4:事前学習 済み T5 での幻覚の 有無の分析](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_40.jpg){kind=link}
![42 特徴的な幻覚の例 [4] 表 8:事前学習済み T5 での幻覚の例 事前学習コーパスに多い表現に引きずられる傾向](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_41.jpg){kind=link}
![43 カテゴリ別の詳細分析 [4] 図 5:カテゴリ別のデータセットを 使った分析](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_42.jpg){kind=link}
![44 カテゴリが一致するほど,幻覚が少ない [4] 表 9:カテゴリ別のデータセットを使った分析](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![48 [11] Shotaro Ishihara, Hiromu Takahashi (2024). Quantifying Memorization and](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_47.jpg){kind=link}
![ドメイン特化のコーパスほど,急速に暗記される 49 [12] Hiromu Takahashi, Shotaro Ishihara (2025). Quantifying Memorization](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_48.jpg){kind=link}
![[13] Shotaro Ishihara (2023). Training Data Extraction From Pre-trained Language](https://files.speakerdeck.com/presentations/25417b0439f744d3a1c3a4068f2b429d/slide_49.jpg){kind=link}
{kind=link}
{kind=link}