“Tina makes $18.00 an hour. If she works more than 8 hours per shift, she is eligible for overtime, which is paid by your hourly wage + ½ your hourly wage. If she works 10 hours every day for 5 days, how much money does she make?” 2. Guidance Adaptation • 汎用的な戦略を立てる: 「賃金と残業代のルールを理解し、体系的に計算する。」 3. Reasoning Structure Generation • 問題解決のための具体的な骨子の生成: 「1. 時給と残業代のルールを理解する。 2. 勤務シフトの数を決定する...」 4. Reasoning Path Generation • 最終的な解答を含む完全な推論パスを生成 5. フィルタリング • Ground Truthがある場合 → 正解ラベルを使ってフィルタリング • Ground Truthがない場合 → 多数決で正解を決める(Self-Consistency) 6. パスの再生成 • フィルタリングの結果、パスが残らなかったときは Guidance Adaptation、Reasoning Structure Generationのステップのみで正解を与えて再生成
• シードプロンプトの例(問題分割、ステップバイステップなど): › How can I break down this problem into smaller, more manageable parts? › Let’s make a step by step plan and implement it with good notation and explanation. • プロンプト: › Without working out the solution, adapt the following reasoning modules to be specific to our task Reasoning Module: {Seed Prompt 𝑝𝑗 𝑟𝑎𝑤} Task: {Instruction 𝑞𝑖𝑗 } • 出力例: › Make a list of ideas for understanding hourly wage and overtime rule and apply them one by one to accurately calculate wages.
Adaptationの結果をもとに、具体的な推論構造を立てる。 • プロンプト › Without working out the solution, create an actionable and concise reasoning structure step by step for the task using this adapted reasoning module: {Adapted Prompt 𝑝 (𝑖,𝑗) 𝑎𝑑𝑝 } Task: {Instruction 𝑞𝑖 } • 出力例: › 1. Understand the hourly wage and overtime rules. 2. Determine the number of shifts. 3. Calculate regular hours per day. 4. Calculate overtime hours per day. 5. Calculate total daily earnings. 6. Calculate total earnings for 5 days.
Structure Generationステップで生成した具体的な解決戦略をもと に推論パスを生成する • プロンプト › Using the following reasoning structure: {Reasoning Structure 𝑟(𝑖,𝑗) 𝑠 } Task:{Instruction 𝑞𝑖 } Solve this task step by step based on the above reasoning structure. • 出力例 › • 人手のFew-shotに依存せず、一つの問題に対して最大25通りの異なる アプローチの多様な学習データを生成できる。 Tina's regular hourly wage is $18.00 per hour. Tina works 10 hours every day, which exceeds the 8-hour limit, so she works 2 shifts (10 hours / 8 hours per shift). For each day, Tina works 8 regular hours. That's 8 * $18.00 = $144.00 per day. For each day, she works an additional 2 overtime hours. That's 2 * ($18.00 + $9.00) = $54.00 per day…
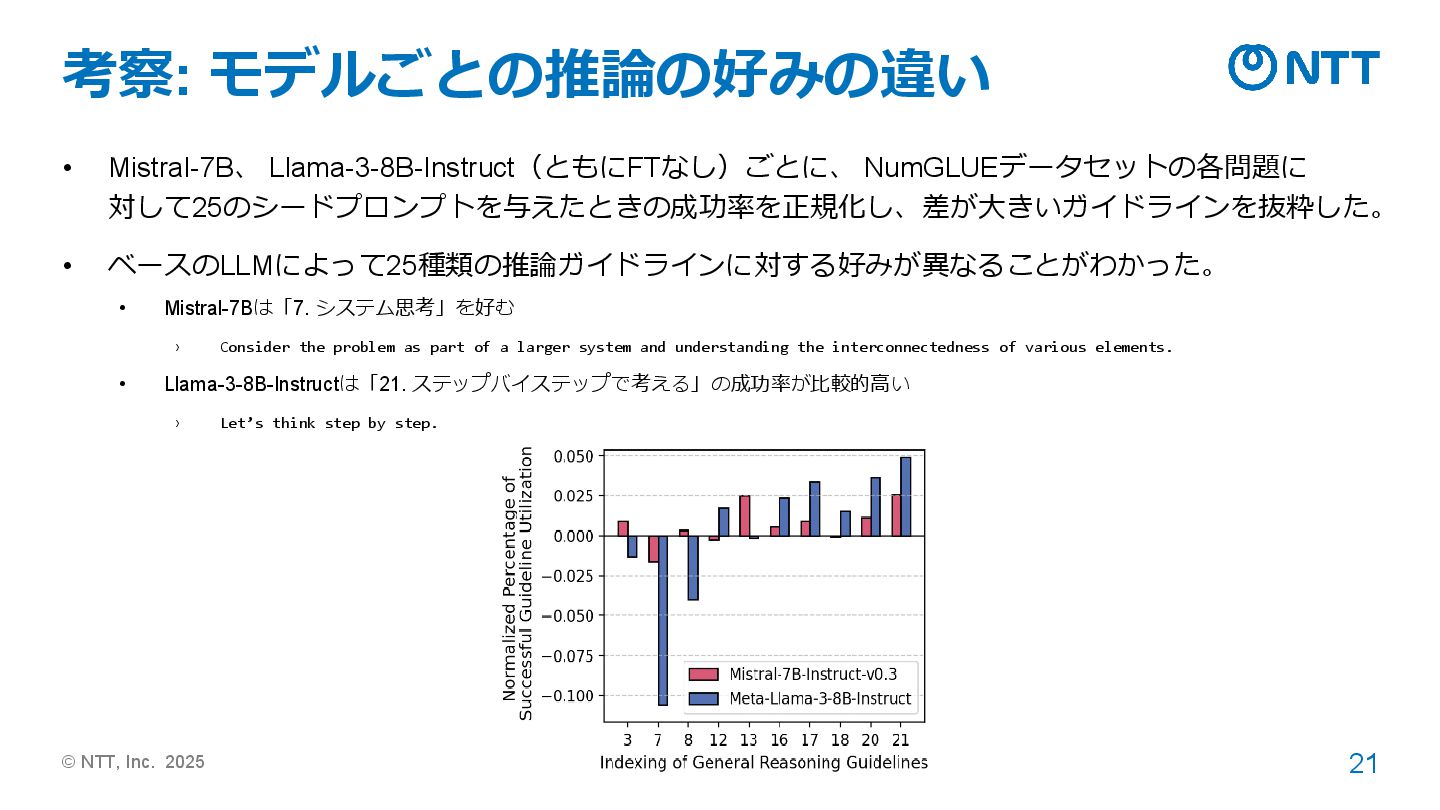
NumGLUEデータセットの各問題に 対して25のシードプロンプトを与えたときの成功率を正規化し、差が大きいガイドラインを抜粋した。 • ベースのLLMによって25種類の推論ガイドラインに対する好みが異なることがわかった。 • Mistral-7Bは「7. システム思考」を好む › Consider the problem as part of a larger system and understanding the interconnectedness of various elements. • Llama-3-8B-Instructは「21. ステップバイステップで考える」の成功率が比較的高い › Let’s think step by step.
クラスタ数が少なく、「直接計算」や「ステップバイステップ計算」といった 単純な推論戦略しか確認されなかった。 › Cluster 1: Direct Calculation and Simplification › Cluster 2: Algebraic and Formula-based Approaches › Cluster 3: Stoichiometry and Chemical Reactions › Cluster 4: Problem Decomposition and Step-by-Step Calculation › Cluster 5: Logical Reasoning and Pattern Recognition
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}