TMPA-2017: Tools and Methods of Program Analysis
3-4 March, 2017, Hotel Holiday Inn Moscow Vinogradovo, Moscow
Live testing distributed system fault tolerance with fault injection techniques
Alexey Vasyukov (Inventa), Vadim Zherder (MOEX)
For video follow the link: https://youtu.be/mGLRH2gqZwc
Would like to know more?
Visit our website:
www.tmpaconf.org
www.exactprosystems.com/events/tmpa
Follow us:
https://www.linkedin.com/company/exactpro-systems-llc?trk=biz-companies-cym
https://twitter.com/exactpro
![[ ИМИДЖЕВОЕ ИЗОБРАЖЕНИЕ ] Live Testing of Distributed System Fault](https://files.speakerdeck.com/presentations/737f9e78b10b4026b8d92f9805acf66a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
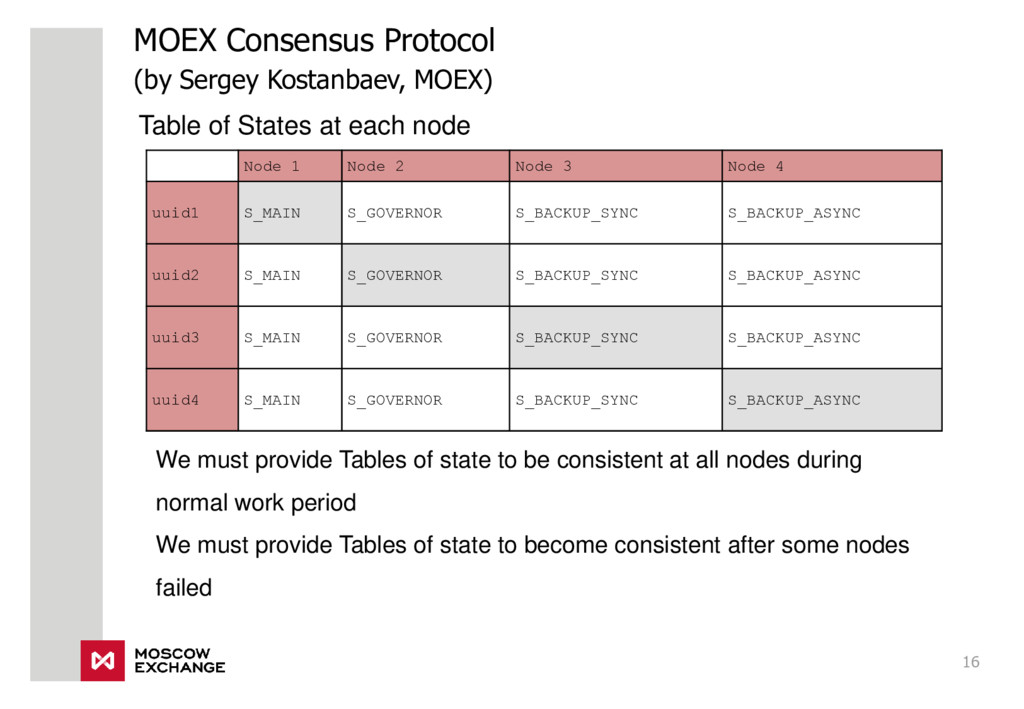{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
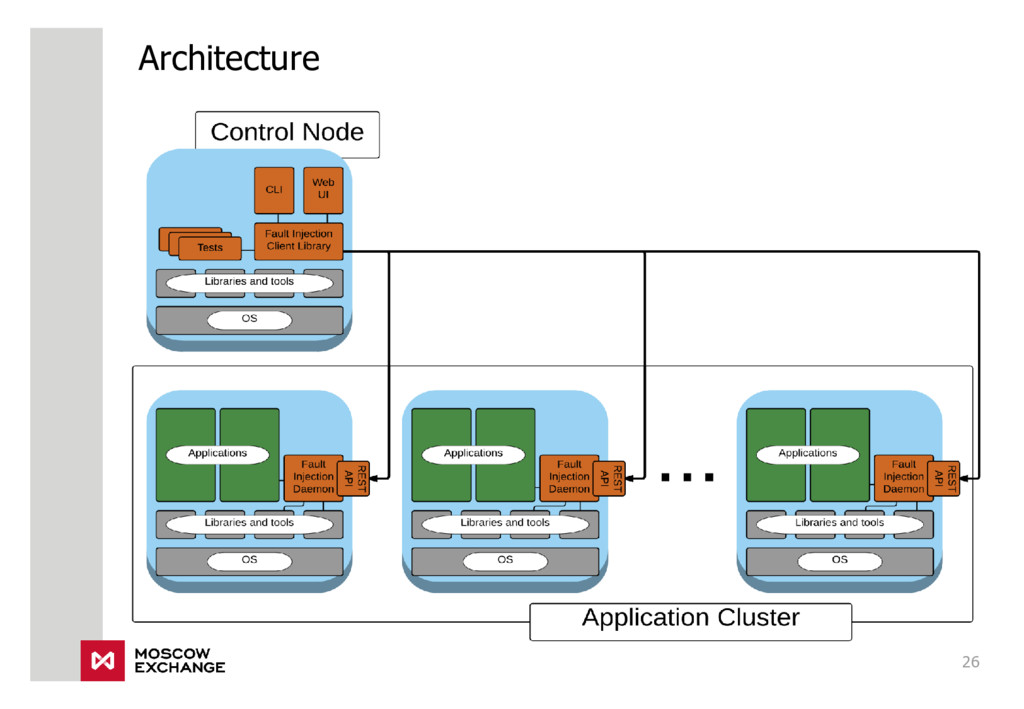{kind=link}
{kind=link}
{kind=link}
{kind=link}
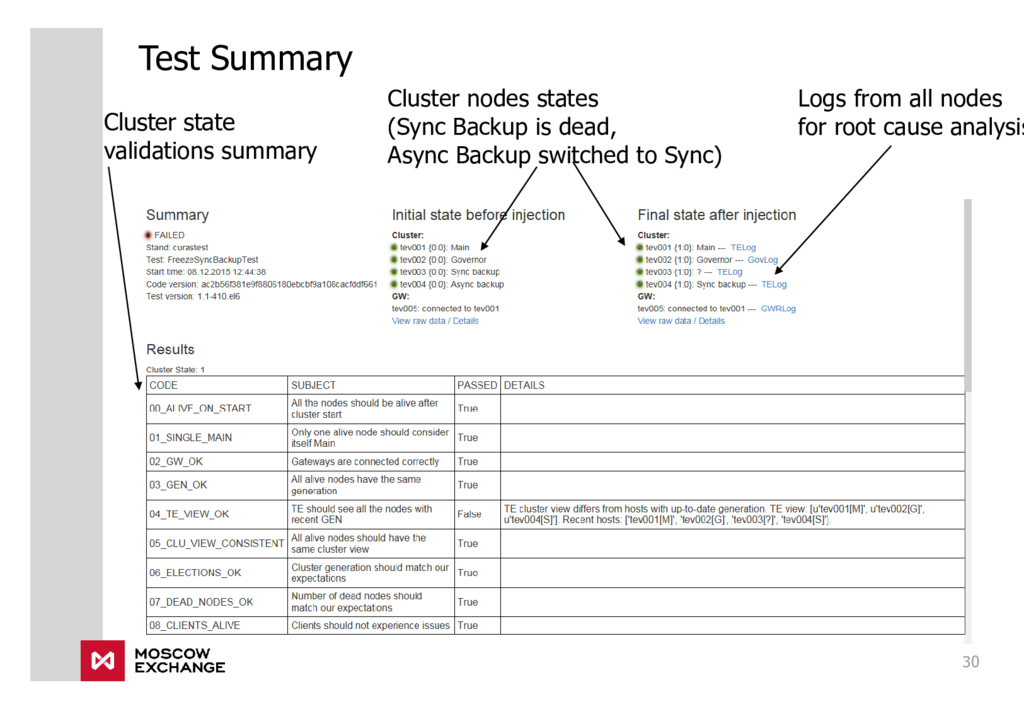{kind=link}
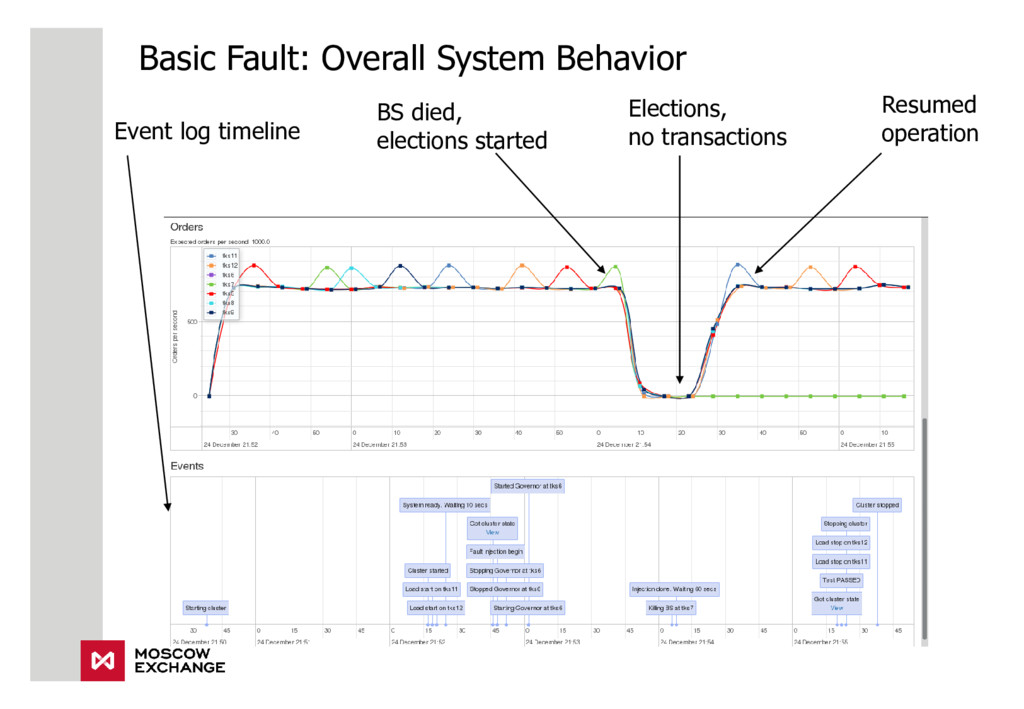{kind=link}
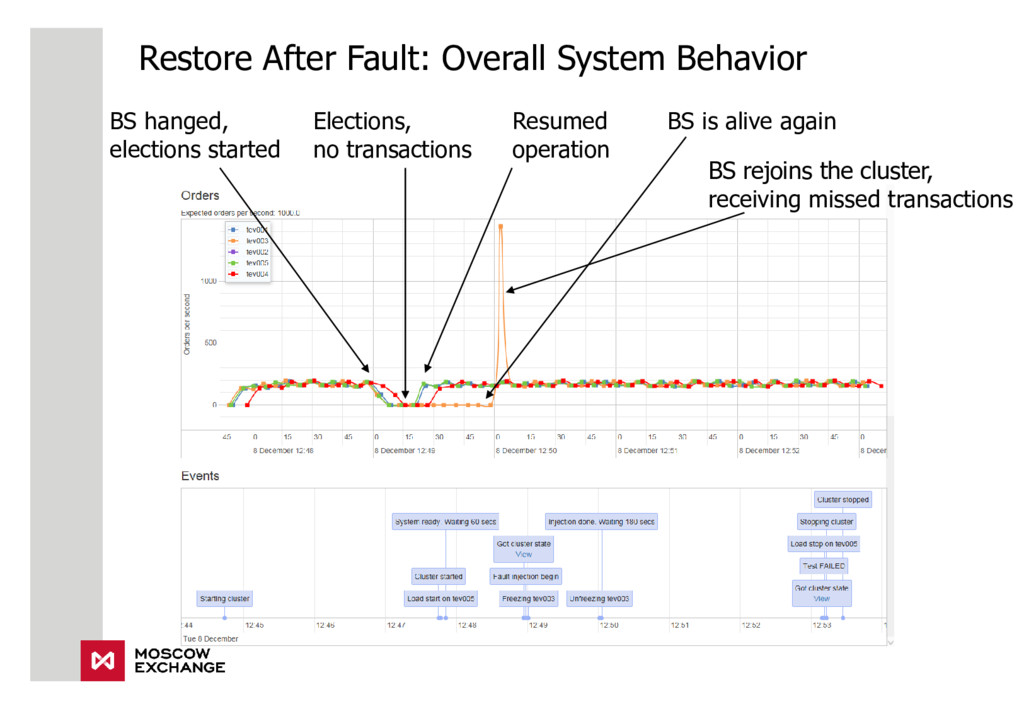{kind=link}
{kind=link}
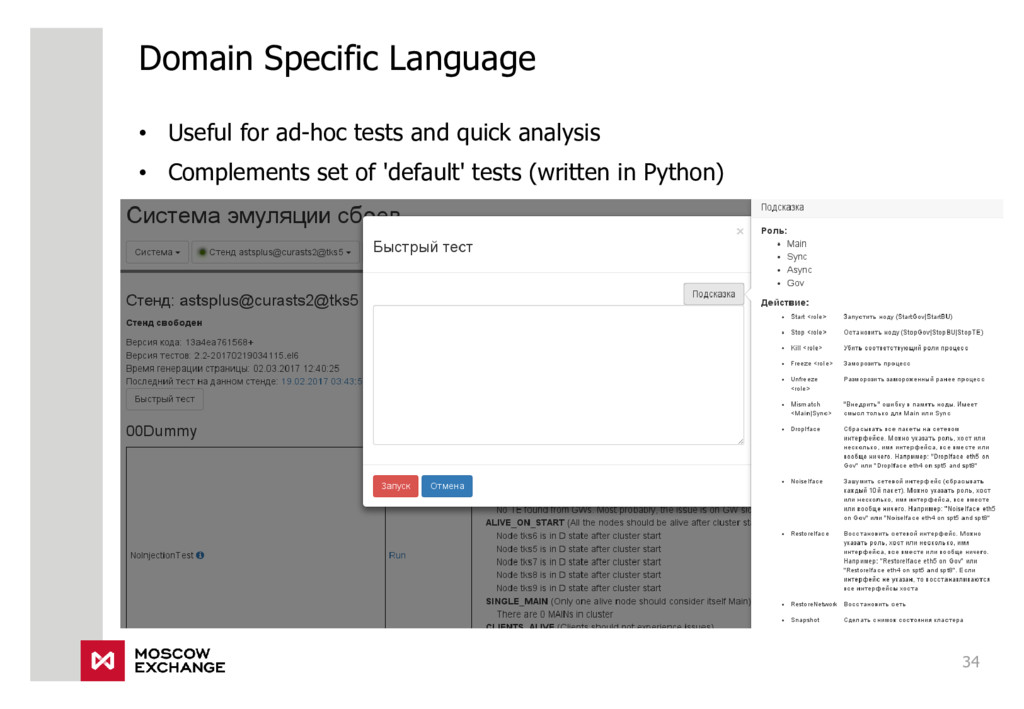{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}