Kleinen wie im Großen Suche kann auch bei klassischen Anwendungsfällen unterstützen Was wollen wir in diesem Vortrag zeigen http://www.morguefile.com/archive/display/861760
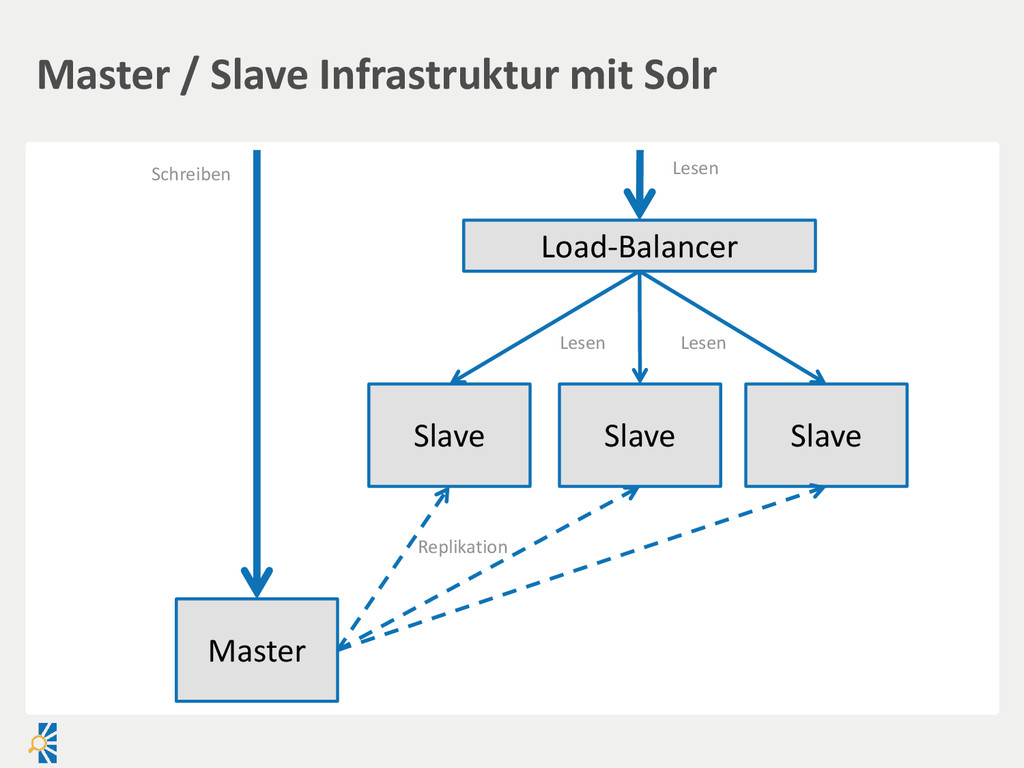
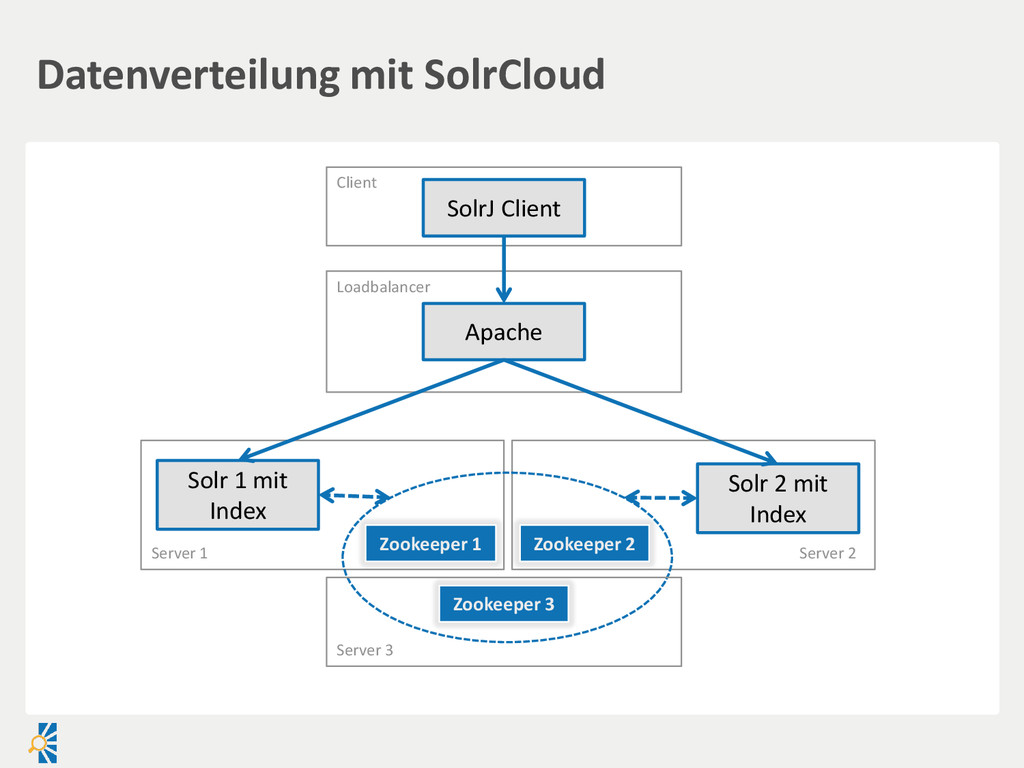
Neue Knoten können einfach hinzugefügt werden Nachteile Daten stehen erst verzögert auf Slaves zur Verfügung Keine Lösung für Index-Splitting Ausfallsicherheit für schreibende Zugriffe Replizierung
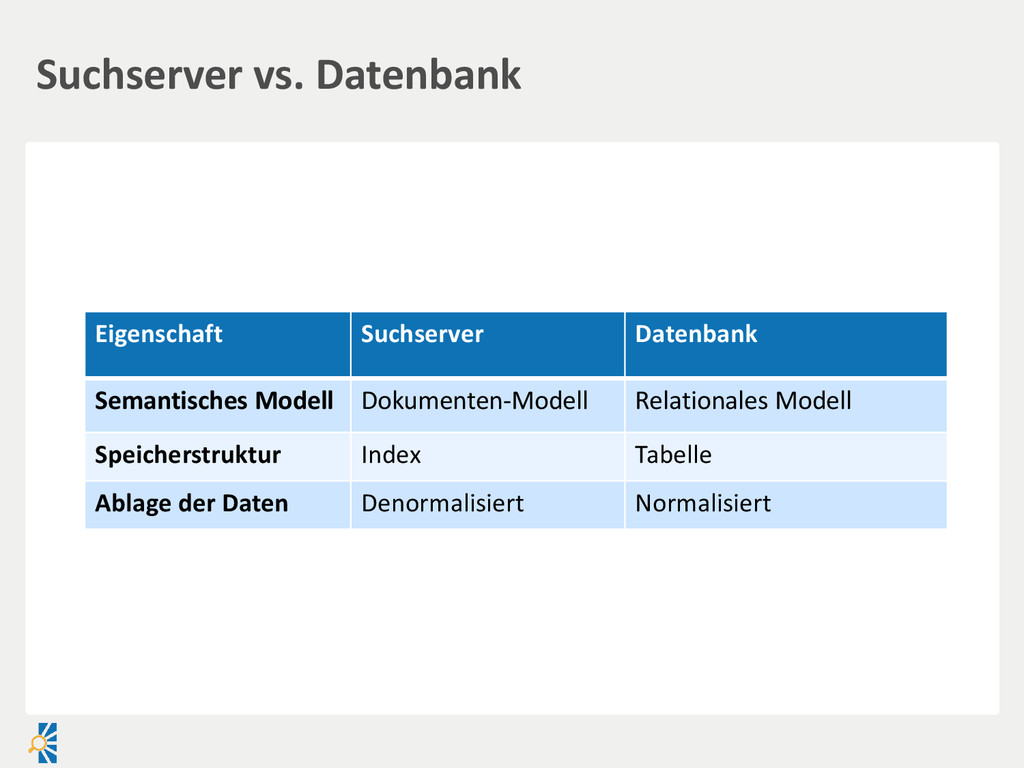
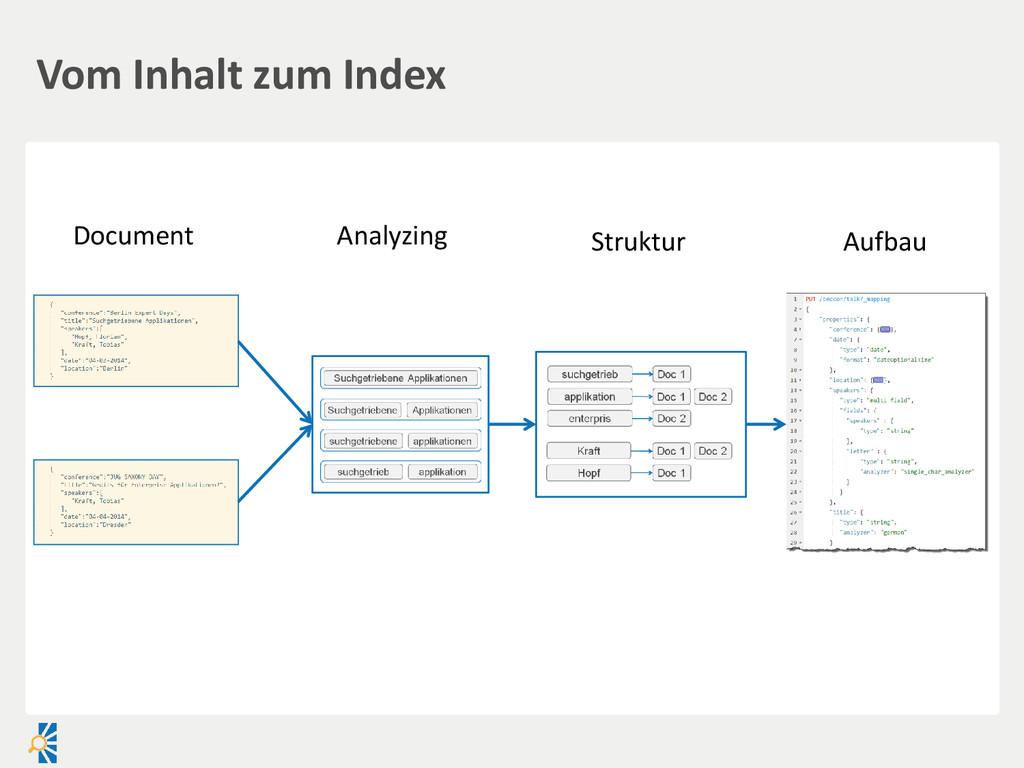
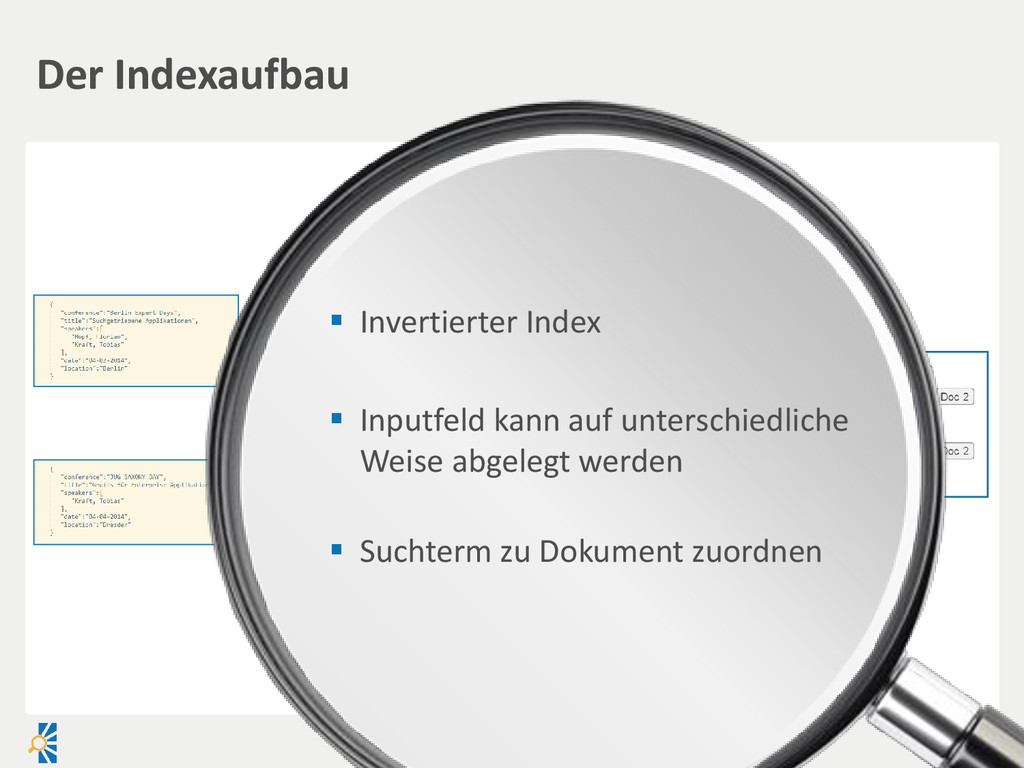
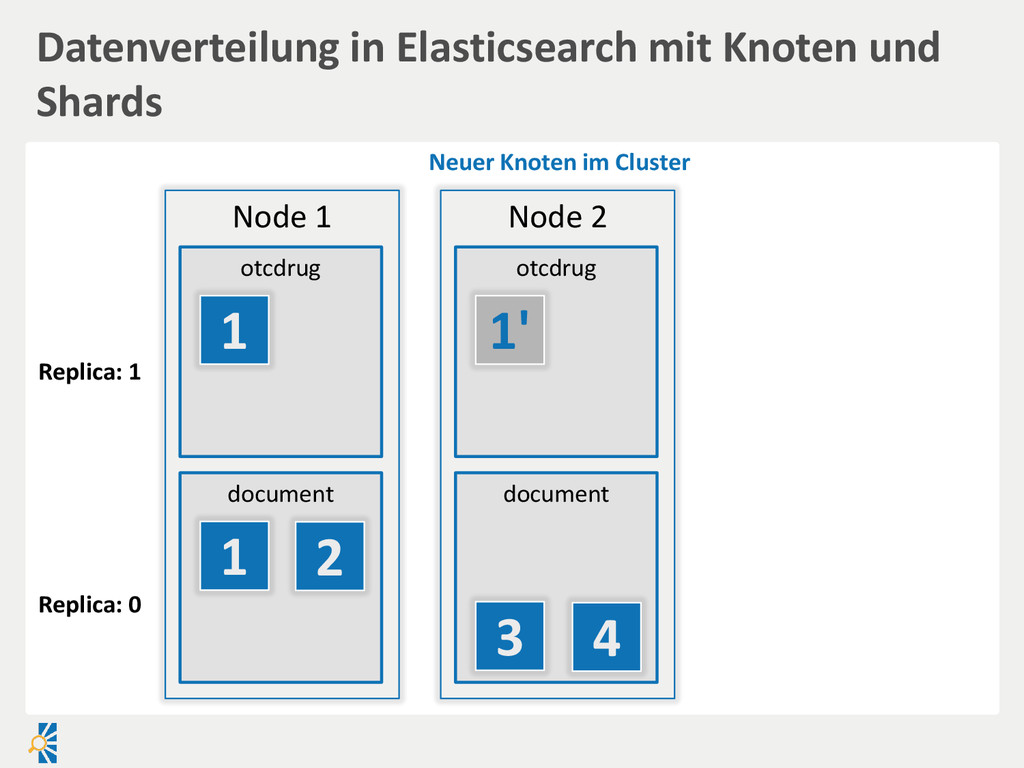
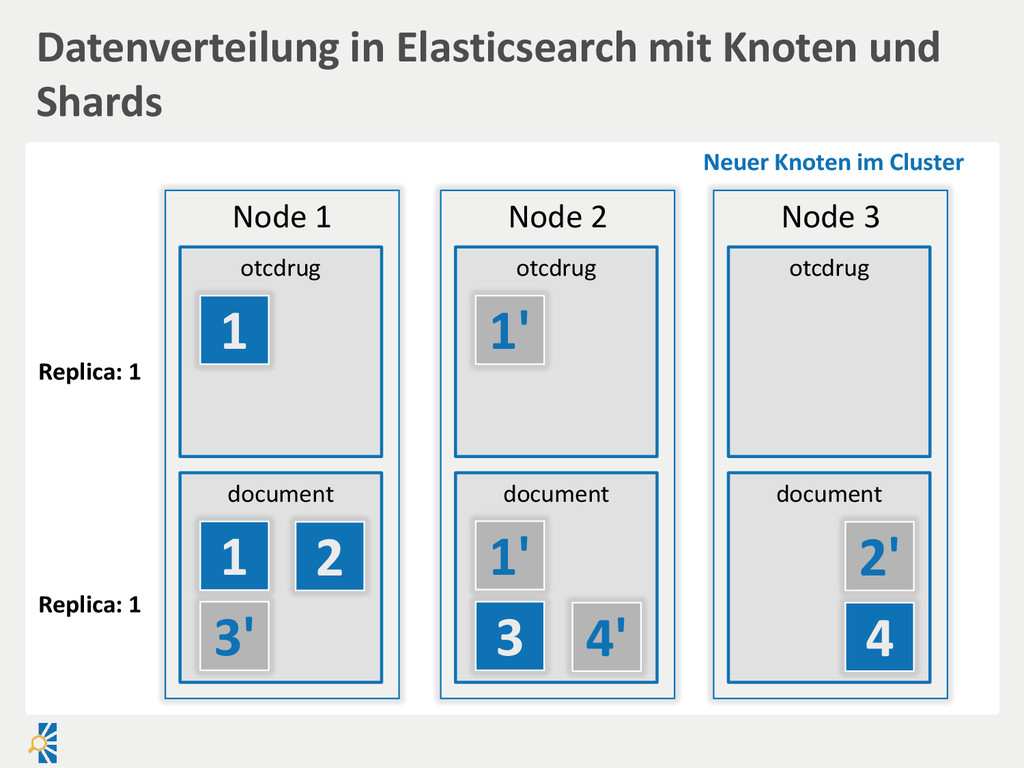
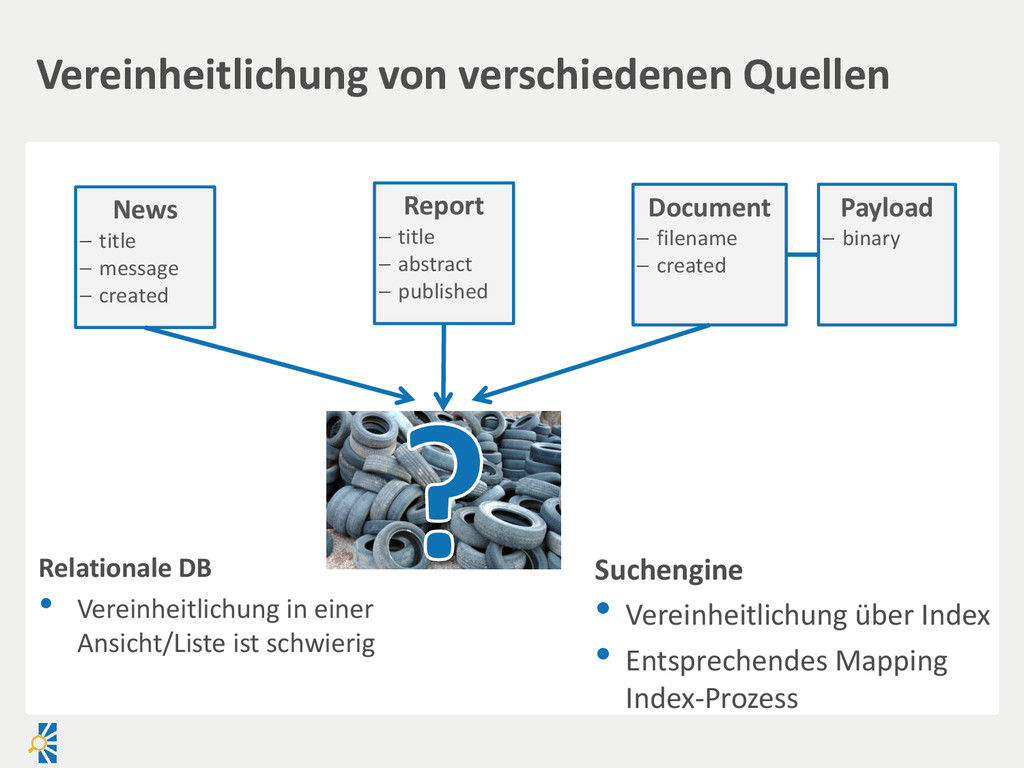
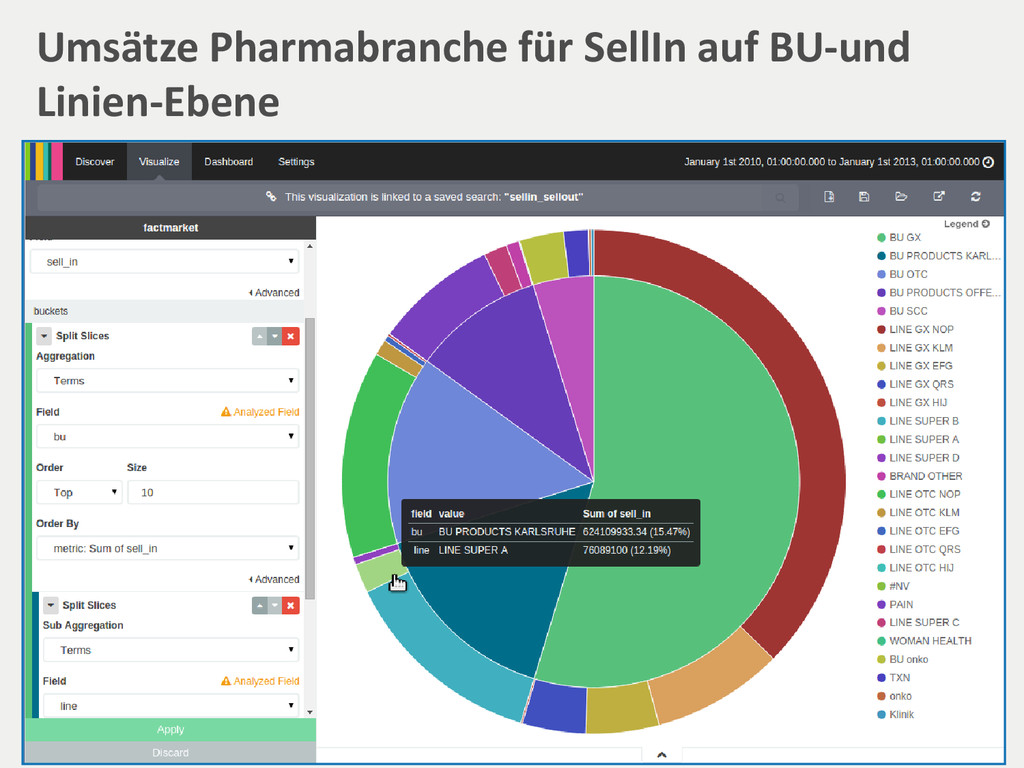
created Document filename created Payload binary Report title abstract published Suchengine • Vereinheitlichung über Index • Entsprechendes Mapping Index-Prozess Relationale DB • Vereinheitlichung in einer Ansicht/Liste ist schwierig
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}