Share
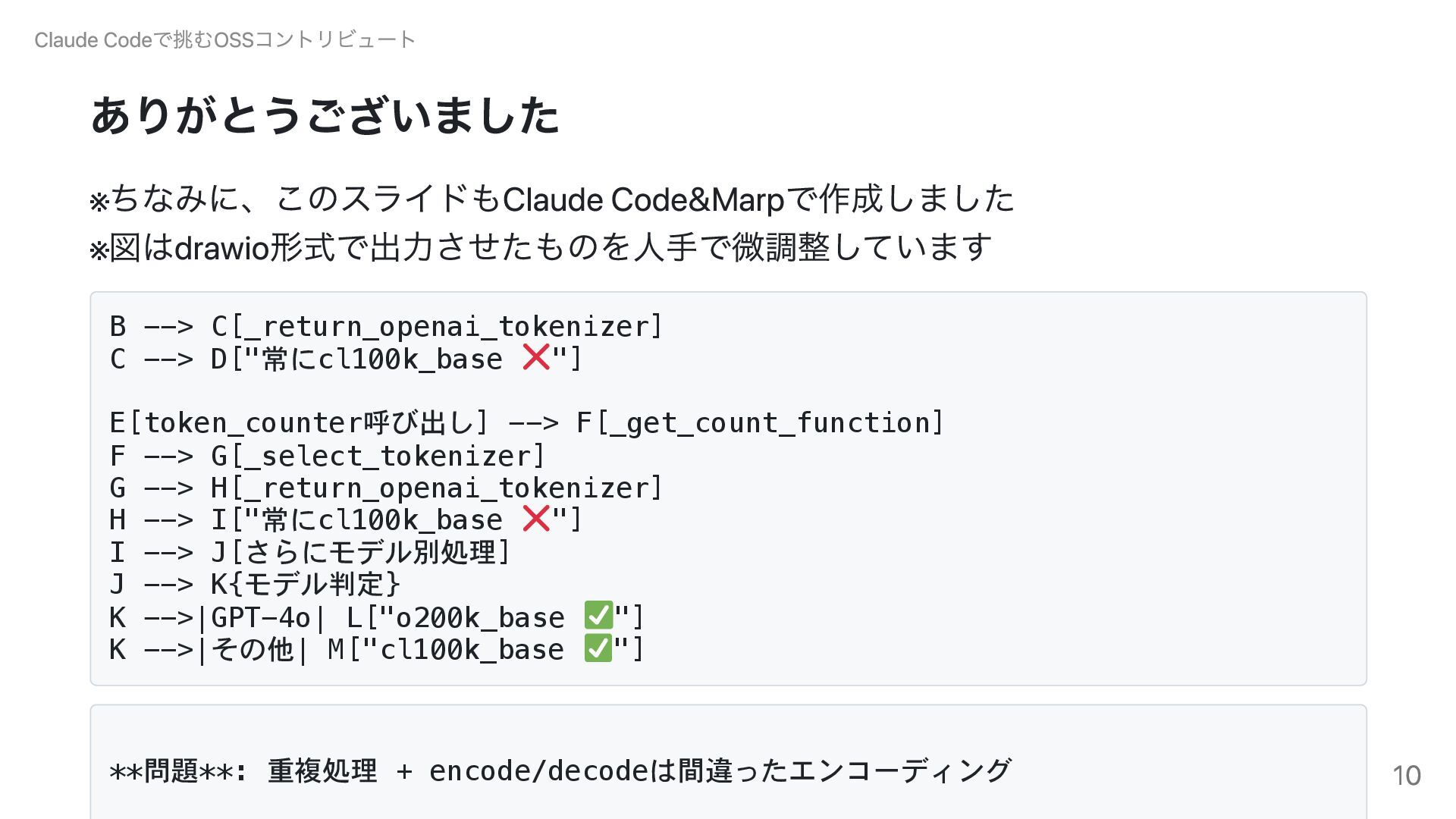
(第174回)Python mini Hack-a-thonで開発・発表したスライドです。 生成AIが得意な0からのデモアプリ作成ではなく、既存の大規模コードベースへのClaude Codeの適用例です。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}