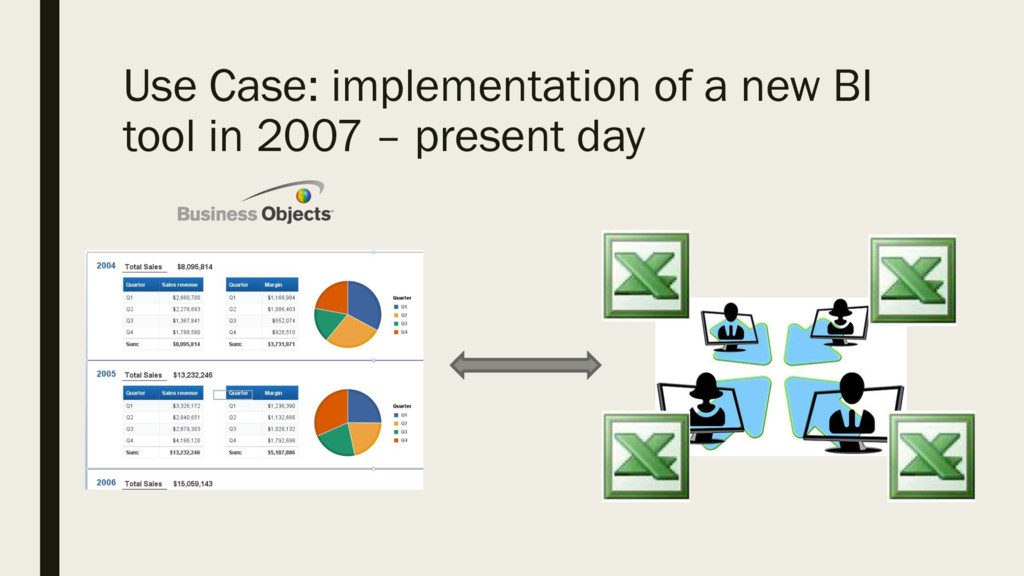
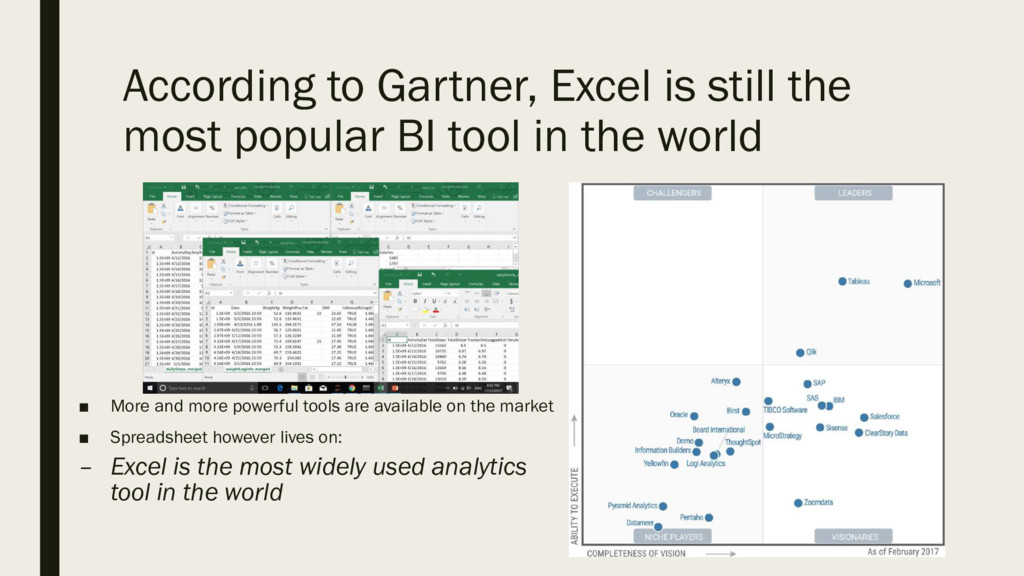
The spreadsheet lives on, especially in sectors slow to adopt new technology, such as medicine and nance. Not only data is frequently stored and passed around in the
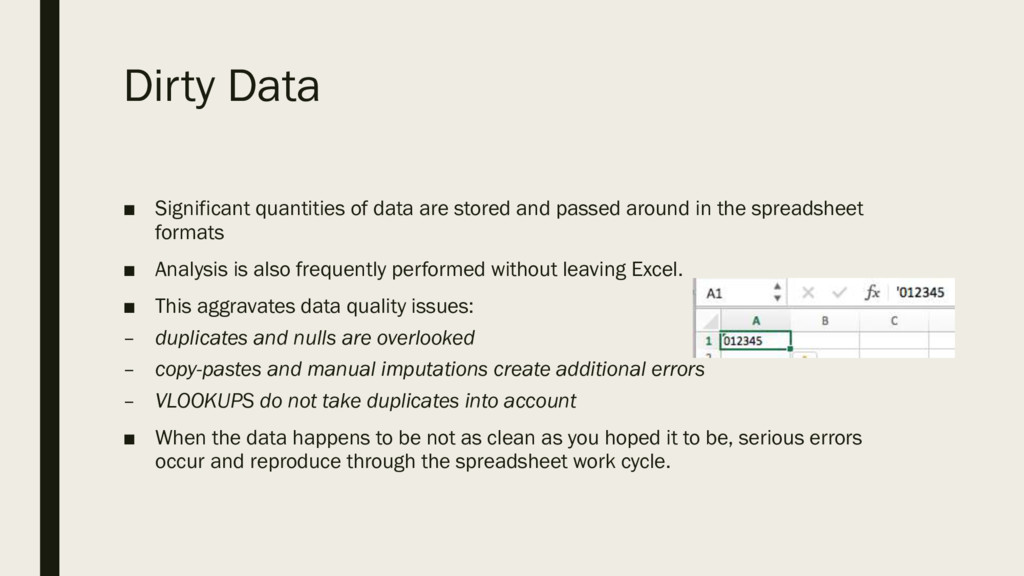
spreadsheet formats, analysis is also frequently performed without leaving Excel. And when the data happens to be not as clean as you hoped it to be, serious errors occur and
reproduce through the spreadsheet workcycle. Data quality issues such as duplicates and nulls, common practices such as copy-pastes, VLOOKUPS, and manual imputations as
well as failure to properly understand and clean the data prior to making conclusions frequently lead to signi cant errors.
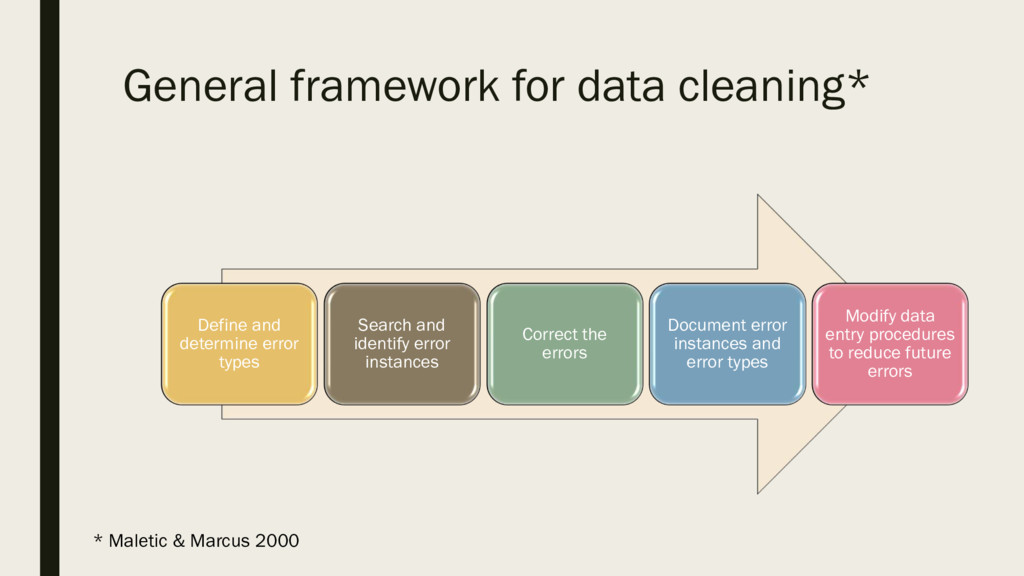
Pandas library provides a powerful tool of ingesting, cleaning, transforming, and visualizing spreadsheet data that are either lacking in Excel or are very painful to implement
given the number of worksheets required for a task. This talk will demonstrate several frequently occurring data issues and show how they can be dealt with in Pandas. We will
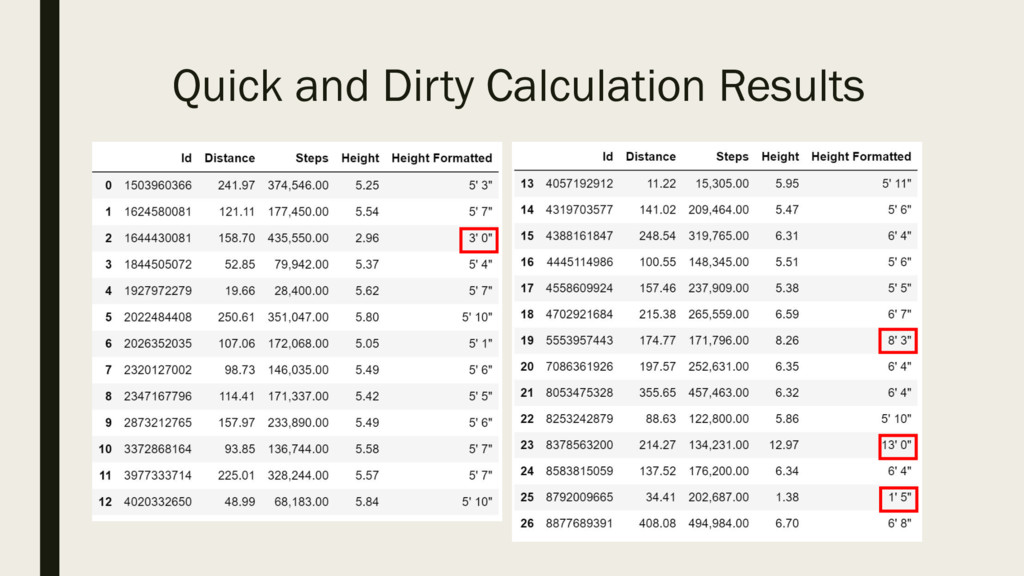
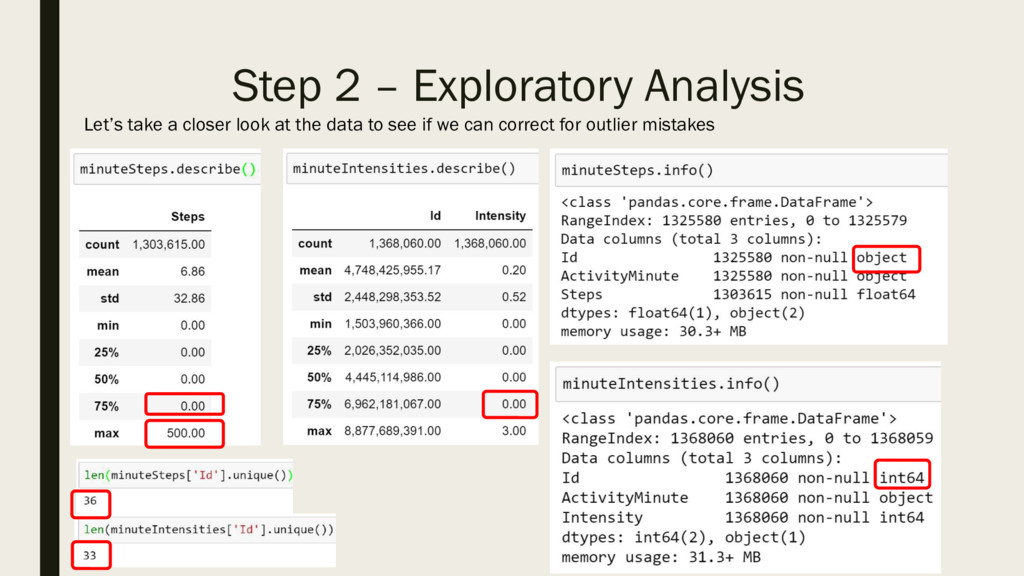
start with an example of an analysis performed in an Excel spreadsheet and will perform step by step invalidation of its conclusions. For this talk we will use a synthetic dataset
that artificially combines multiple data issues encountered in real life and provides a good illustration of common data pitfalls.
Co-presented with Tanya Yarmola
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks! Feyzi Bagirov, [email protected], @FeyziBagirov Tanya Yarmola, [email protected], @TanyaYarmola GitHub:](https://files.speakerdeck.com/presentations/bfa4f67f904342f09acdedccf50ca14b/slide_50.jpg){kind=link}