Uma palestra que passa um pouco de algumas funções, exemplos e idéias para facilitar interessados no assunto a começar seus experimentos de forma mais estruturada e automatizada
mais fundamental ☞ Implementação Array N-dimensional ☞ Funções e operações sofisticadas ☞ Integração com C/C++ e Fortran ☞ Muitos outros pacote usam numpy por "baixo"
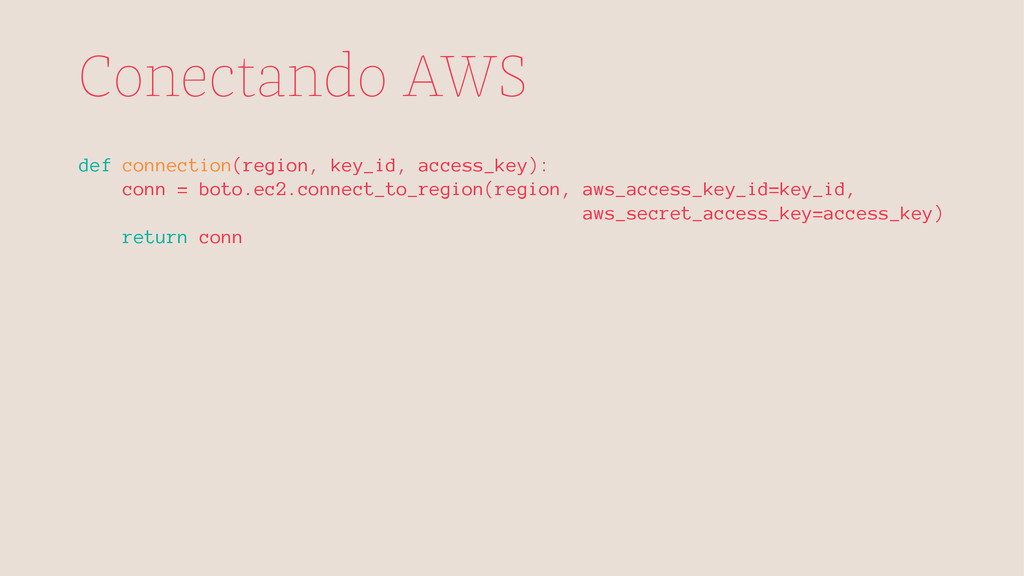
local ☞ Processamentos pesados na nuvem ☞ AWS e outros ☞ 0(zero) desperdício de tempo do servidor ☞ Não saturar processador local ☞ Alguns treinos podem levar horas, dias até.
criar o porgrama que realiza o treino enviar para nuvem para computação e terminar a instância. ☞ Resgatar o resultado na máquina local e montar um histórico para gerar um ranking. ☞ Buscar o máximo de automatização.
Sugestão: de preferência no mesmo serviço de computação para que eles sejam mais rapidamente transferidos ☞ S3 ou similares ☞ Como agregar dados de diversas fontes? ☞ Cada caso pode ter uma particularidade muito específica: analisar.
máquinas ao mesmo tempo trabalhando em paralelo ☞ Nenhum resultado deve ser jogado fora ☞ Podem ter insights/dicas importantes ☞ Montar um ranking ☞ HTML + JS + JSON
é considerado lento em alguns casos ☞ Python se integra com facilidade com projetos em C/C++ para machine learning ☞ As vezes é bom usar coisas que já são reconhecidamente boas de outras linguagens, como C/C++.
ser um diferencial. ☞ Dentro da área ML existem várias outras sub-áreas que usam técnicas diferentes. ☞ Tentar aprender muitas de uma vez pode atrasar resultados e confundir. ☞ Técnicas de visualização/exibição de dados são muito importantes.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Fim ☞ Perguntas ? ☞ Obrigado ☞ [email protected] ☞ @felipejcruz](https://files.speakerdeck.com/presentations/99773d9002fd01329b236236634e2996/slide_35.jpg){kind=link}