Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Pyspark - produtividade e poder de processamento
Search
Felipe cruz
November 10, 2015
Technology
76
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Pyspark - produtividade e poder de processamento
Felipe cruz
November 10, 2015
More Decks by Felipe cruz
See All by Felipe cruz
Recomendação - Algoritmos de Filtragem Colaborativa
felipecruz
0
450
Coleta Massiva de Dados
felipecruz
2
140
TDC 2014 - Machine Learning Guerrilha
felipecruz
0
290
Python & C - Formas de Integração
felipecruz
0
140
Other Decks in Technology
See All in Technology
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction
spatial_ai_network
0
120
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.5k
AI Driven AI Governance
pict3
0
340
個人開発で育てる「大規模設計の苗床」 - AI時代の1人開発から始める業務への知識接続 / The Seedbed for Large-Scale Design - From AI-Era Solo Projects to Professional Knowledge
bitkey
PRO
0
170
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
2.7k
AIレビューはどこまで任せられるのか?自動化と人が背負うレビューの境界
sansantech
PRO
2
770
AI時代の EM への処方箋
staka121
PRO
0
140
しくみを学んで使いこなそう GitHub Copilot app
torumakabe
2
240
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
670
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
Featured
See All Featured
SEO Brein meetup: CTRL+C is not how to scale international SEO
lindahogenes
1
2.8k
4 Signs Your Business is Dying
shpigford
187
22k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
Everyday Curiosity
cassininazir
0
250
The Straight Up "How To Draw Better" Workshop
denniskardys
239
140k
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
690
AI: The stuff that nobody shows you
jnunemaker
PRO
8
820
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
From π to Pie charts
rasagy
0
230
Transcript
PySpark PySpark Produtividade e poder de processamento
Quem? Quem? github.com/felipecruz github.com/felipecruz @ @felipe felipej jcruz cruz
Agenda Agenda Map-Reduce Pyspark
Maior oferta feita em Maior oferta feita em uma semana
na uma semana na BOVESPA? BOVESPA?
Motivação Motivação highest_offer = max(offers)
None
None
? ?
? ?
highest_offers_1 = max(offers_partition1) highest_offers_2 = max(offers_partition2)
highest_offers_1 = max(offers_partition1) highest_offers_2 = max(offers_partition2) max(highest_offers_1, highest_offers_2)
calma... calma...
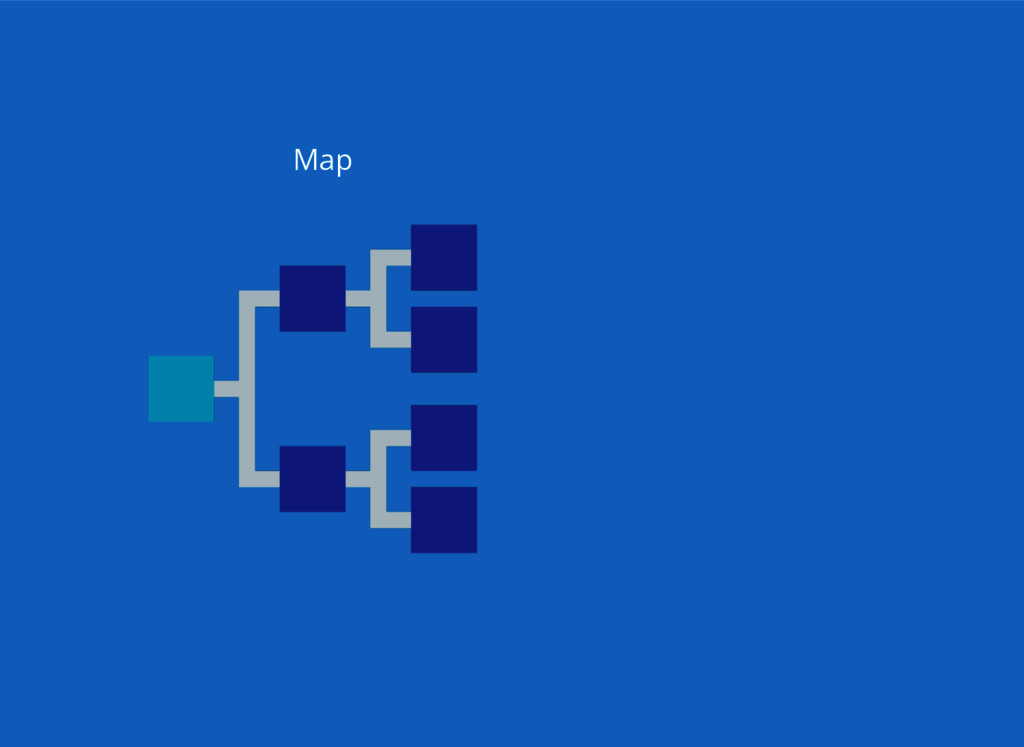
Map
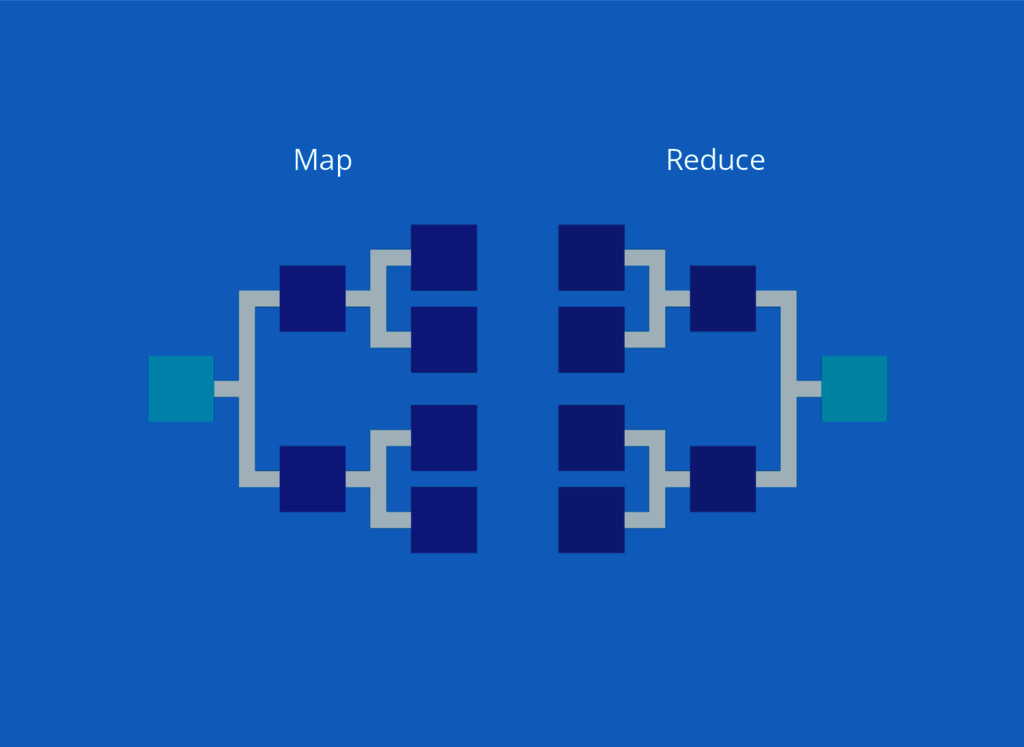
Map Reduce
Map-Reduce Map-Reduce não é divisão e conquista (que pode ser
implementada com map-reduce)
Aplicações Aplicações Filtragem Distintos Top K Por valor Sumarização Índice
invertido Contagem de palavras Estruturação Ordenação Particionamento Embaralhamento Join Inner join Produto cartesiano nosso exemplo K = 1
PySpark PySpark
Funcionalidades centrais Funcionalidades centrais Map-Reduce RDD, DataFrames & SQL MLlib
Streaming GraphX
Map Map & Reduce & Reduce >>> prices = sc.textFile('s3n://prognoos-pyspark/*.gz')
\ ... .filter(lambda x: x.count(';') > 14) \ ... .map(lambda x: [s.strip() for s in x.split(';')]) \ ... .map(lambda x: (x[1], x[8], x[15])) ... >>> prices.take(2) [(u'ABEVA70', u'000000000000.350000', u'000000000000008300'), (u'ABEVA70', u'000000000000.350000', u'000000000000007100')]
Map & Map & Reduce Reduce >>> prices = sc.textFile('ftp://*.gz')
\ ... .filter(lambda x: x.count(';') > 14) \ ... .map(lambda x: [s.strip() for s in x.split(';')]) \ ... .map(lambda x: (x[1], float(x[8]), x[15])) ... >>> sum_all = prices.map(lambda x: x[2])\ ... .reduce(lambda x, y: x + y) ... >>> sum_all 1532623750.0
from datetime import datetime strpt = lambda x: datetime.strptime(x, '%H:%M:%S.%f')
f = float negs = sc.textFile('s3n://prognoos-pyspark/NEG/*.gz') \ .filter(lambda x: x.count(';') > 14) \ .map(lambda x: [s.strip() for s in x.split(';')]) \ .map(lambda x: (strpt(x[5]), 'NEG', x[1], f(x[3]), f(x[16]), x[17])) buys = sc.textFile('s3n://prognoos-pyspark/CPA/*.gz') \ .filter(lambda x: x.count(';') > 14) \ .map(lambda x: [s.strip() for s in x.split(';')]) \ .map(lambda x: (strpt(x[6]), 'CPA', x[1], f(x[8]), x[15], None)) sell = sc.textFile('s3n://prognoos-pyspark/VDA/*.gz') \ .filter(lambda x: x.count(';') > 14) \ .map(lambda x: [s.strip() for s in x.split(';')]) \ .map(lambda x: (strpt(x[6]), 'VDA', x[1], f(x[8]), None, x[15])) all_operations = negs.union(buys).union(sell) total = all_operations.count() # total = 52980676
... nem tudo são ... nem tudo são flores flores
data = sc.parallelize(['aa', 'bb', 'ab', 'bc']) def _filter(data): sts =
['a', 'b'] rets = [] for st in sts: rets.append((st, data.filter(lambda x: x.startswith(st)))) return rets rdds = _filter(data) for st, rdd in rdds: print((st, rdd.collect())) # ('a', ['bb', 'bc']) # ('b', ['bb', 'bc']) Python - Anti-pattern - não faça!!
DataFrames & SQL DataFrames & SQL
DataFrame DataFrame A distributed collection of data grouped into named
columns http://spark.apache.org/docs/latest/api/python/pyspark.sql.html#pyspark.sql.DataFrame
events = negs.union(buys).union(sell).toDF() # API de DataFrame total = events.count()
# Salva pra uso posterior events.write.save('s3n://prognoos/events/', format='parquet', mode='Overwrite')
SparkSQL SparkSQL http://spark.apache.org/docs/latest/api/python/pyspark.sql.html >>> path = 's3n://prognoos-test/events' >>> table_name =
'bovespa_events' >>> events = sqlContext.read.parquet(path) >>> events.registerTempTable(table_name) >>> total_events = sqlContext.sql(''' select count(*) from bovespa_events ''')
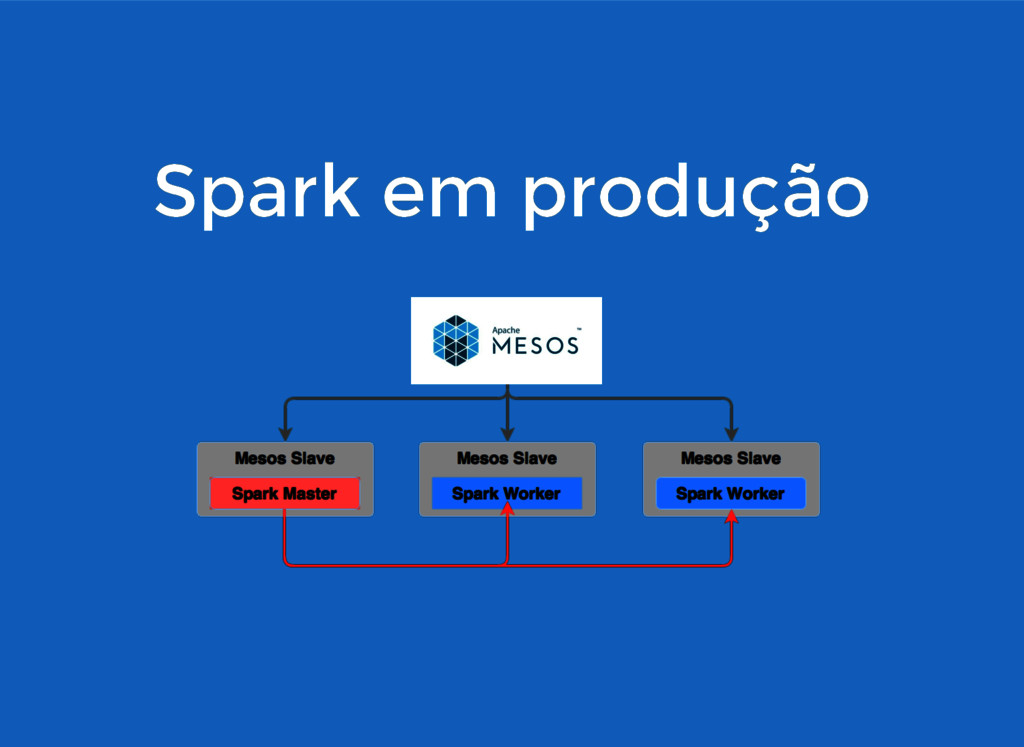
Spark em produção Spark em produção Standalone Hadoop/Yarn Mesos
Spark em produção Spark em produção
Dúvidas? Dúvidas? @felipejcruz @felipejcruz github.com/felipecruz github.com/felipecruz
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data = sc.parallelize(['aa', 'bb', 'ab', 'bc']) def _filter(data): sts =](https://files.speakerdeck.com/presentations/3214d864dfab40bc87465d71e5e911f4/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}