df.columns df.values Out[152]: DatetimeIndex(['2013-01-01', '2013-01-02', '2013-01-03', '2013-01-04', '2013-01-05', '2013-01-06'], dtype='datetime64[ns]', freq='D') Out[153]: Index(['A', 'B', 'C', 'D'], dtype='object') Out[154]: array([[ 0.94251405, 0.45785949, 1.79680407, -0.1673346 ], [ 1.350054 , 0.37280432, 1.17952484, -1.49736159], [ 1.39631522, 1.66978288, 0.01449329, 0.0692628 ], [-1.51205691, -0.94297288, -0.14236803, -0.0421941 ], [-0.30273957, -1.61310536, 2.65031003, 1.2375204 ], [ 1.33817644, -0.3023708 , 0.90805789, 2.66969448]])
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
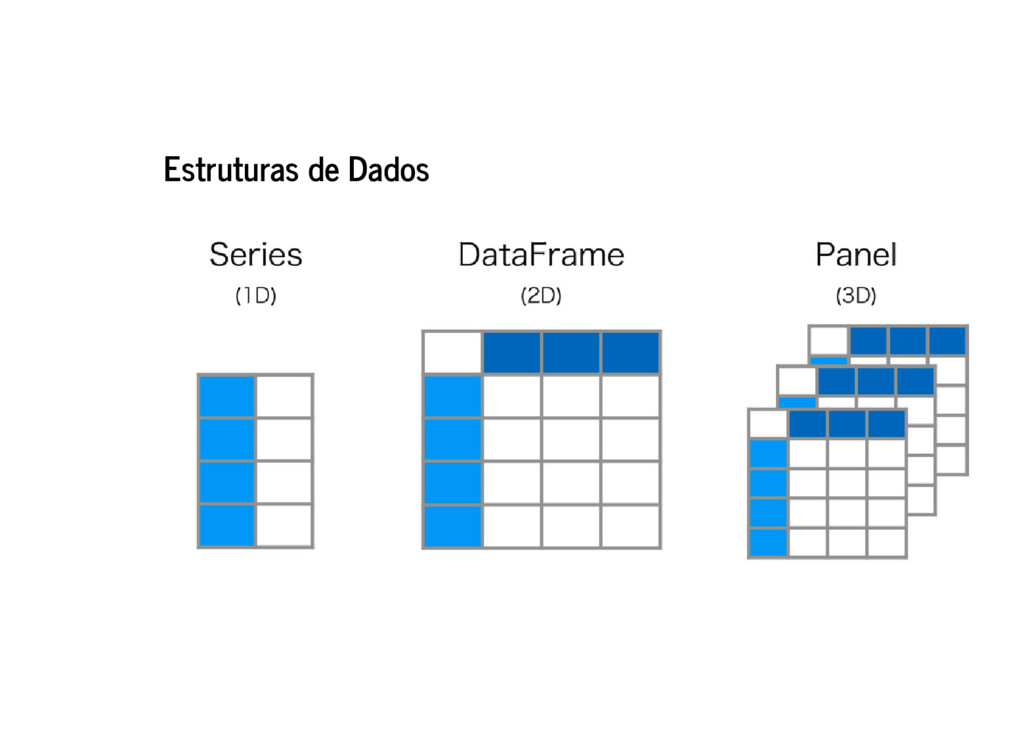
![Estruturas de Dados In [118]: import pandas as pd](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![Criando Series A partir de um np.ndarray In [119]: In](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_14.jpg){kind=link}
![Criando Series A partir de um dict In [122]: In](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_15.jpg){kind=link}
![Criando Series A partir de um valor In [124]: pd.Series(5.,](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_16.jpg){kind=link}
![Series são como np.ndarray In [125]: In [126]: In [127]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_17.jpg){kind=link}
![Series são como dict In [128]: In [129]: In [130]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_18.jpg){kind=link}
![Operações com Series In [133]: In [134]: In [135]: s](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_19.jpg){kind=link}
{kind=link}
![Criando DataFrames A partir de um dict In [136]: d](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_21.jpg){kind=link}
![Criando DataFrames A partir de um dict In [137]: In](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
![Operações com DataFrame Projeção In [141]: Adição In [142]: df['one']](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_25.jpg){kind=link}
![In [143]: df['foo'] = 'bar' df Out[143]: one two three](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_26.jpg){kind=link}
![Operações com DataFrame Exclusão In [144]: In [145]: del df['two']](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![Criando objetos In [146]: s = pd.Series([1,3,5,np.nan,6,8]) s Out[146]: 0](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_30.jpg){kind=link}
![Criando objetos In [147]: In [148]: dates = pd.date_range('20130101', periods=6)](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_31.jpg){kind=link}
![Criando objetos In [149]: df2 = pd.DataFrame({ 'A' : 1.,](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_32.jpg){kind=link}
![Entendendo os dados In [150]: In [151]: df.head() df.tail(3) Out[150]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_33.jpg){kind=link}
![Entendendo os dados In [152]: In [153]: In [154]: df.index](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_34.jpg){kind=link}
![Entendendo os dados In [155]: df.describe() Out[155]: A B C](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_35.jpg){kind=link}
![Entendendo os dados In [156]: df.info() <class 'pandas.core.frame.DataFrame'> DatetimeIndex: 6](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_36.jpg){kind=link}
![Manipulando os dados Obtendo a transposta In [157]: df.T Out[157]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_37.jpg){kind=link}
![Manipulando os dados Ordenando índices In [158]: df.sort_index(axis=1, ascending=False) Out[158]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_38.jpg){kind=link}
![Manipulando os dados Ordenando valores In [159]: df.sort_values(by='B') Out[159]: A](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_39.jpg){kind=link}
![Projetando os dados In [160]: df['A'] Out[160]: 2013-01-01 0.942514 2013-01-02](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_40.jpg){kind=link}
![Projetando os dados In [161]: In [162]: df[0:3] df['20130102':'20130104'] Out[161]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_41.jpg){kind=link}
![Projetando os dados Por rótulo In [163]: df.loc[dates[0]] Out[163]: A](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_42.jpg){kind=link}
![Projetando os dados Por rótulo In [164]: df.loc[:,['A','B']] Out[164]: A](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_43.jpg){kind=link}
![Projetando os dados Por rótulo In [165]: df.loc['20130102':'20130104',['A','B']] Out[165]: A](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_44.jpg){kind=link}
![Projetando os dados Por rótulo In [166]: In [167]: df.loc['20130102',['A','B']]](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_45.jpg){kind=link}
![Projetando os dados Por posição In [168]: In [169]: df.iloc[3]](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_46.jpg){kind=link}
![Projetando os dados Por posição In [170]: In [171]: df.iloc[[1,2,4],[0,2]]](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_47.jpg){kind=link}
![Projetando os dados Por posição In [172]: In [173]: df.iloc[:,1:3]](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_48.jpg){kind=link}
![Projetando os dados Por condição In [174]: In [175]: df[df.A](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_49.jpg){kind=link}
![Projetando os dados isin() In [176]: In [177]: df2 =](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_50.jpg){kind=link}
![Modi cando os dados Adicionando colunas In [178]: In [179]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_51.jpg){kind=link}
![Modi cando os dados Alterando valores In [180]: df Out[180]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_52.jpg){kind=link}
![Modi cando os dados Alterando valores In [181]: df.at[dates[0],'A'] =](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_53.jpg){kind=link}
![Modi cando os dados Alterando valores com condições In [182]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_54.jpg){kind=link}
![Modi cando os dados Alterando valores com condições In [183]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_55.jpg){kind=link}
![Tratando os dados In [184]: df1 = df.reindex(index=dates[0:4], columns=list(df.columns) +](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_56.jpg){kind=link}
![Tratando os dados In [185]: In [186]: df1 pd.isnull(df1) Out[185]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_57.jpg){kind=link}
![Tratando os dados In [187]: In [188]: df1.dropna(how='any') df1.fillna(value=5) Out[187]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_58.jpg){kind=link}
![Tratando os dados apply() In [189]: In [190]: df.apply(np.cumsum) df.apply(lambda](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_59.jpg){kind=link}
![Tratando os dados apply() In [191]: df.apply(lambda x: [max(1, y)](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_60.jpg){kind=link}
![Operando com os dados Estatísticas In [192]: df.mean() Out[192]: A](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_61.jpg){kind=link}
![Operando com os dados Estatísticas In [193]: df.mean(1) Out[193]: 2013-01-01](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_62.jpg){kind=link}
![Operando com os dados Estatísticas In [194]: In [195]: s](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_63.jpg){kind=link}
![Operando com os dados Strings In [196]: In [197]: s](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_64.jpg){kind=link}
![Mesclando dados Merge In [198]: df = pd.DataFrame(np.random.randn(10, 4)) df](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_65.jpg){kind=link}
![Mesclando dados Merge In [199]: pieces = [df[:3], df[3:7], df[7:]]](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_66.jpg){kind=link}
![Mesclando dados Join In [200]: In [201]: In [202]: left](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_67.jpg){kind=link}
![Mesclando dados Join In [203]: pd.merge(left, right, on='key') Out[203]: key](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_68.jpg){kind=link}
![Mesclando dados Append In [204]: df = pd.DataFrame(np.random.randn(8, 4), columns=['A','B','C','D'])](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_69.jpg){kind=link}
![Mesclando dados Append In [205]: s = df.iloc[3] s Out[205]:](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_70.jpg){kind=link}
![Mesclando dados Append In [206]: df.append(s, ignore_index=True) Out[206]: A B](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_71.jpg){kind=link}
![Agrupando dados In [207]: df = pd.DataFrame({'A' : ['foo', 'bar',](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_72.jpg){kind=link}
![Agrupando dados In [208]: df.groupby('A').sum() Out[208]: C D A bar](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_73.jpg){kind=link}
![Agrupando dados In [209]: df.groupby(['A','B']).sum() Out[209]: C D A B](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_74.jpg){kind=link}
![Integrações In [211]: import matplotlib.pyplot as plt](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_75.jpg){kind=link}
![Matplotlib In [212]: ts = pd.Series(np.random.randn(1000), index=pd.date_range('1/1/2000', periods=1 000)) ts](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_76.jpg){kind=link}
![Matplotlib In [213]: df = pd.DataFrame(np.random.randn(1000, 4), index=ts.index, columns=['A', 'B',](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_77.jpg){kind=link}
![CSV In [214]: In [215]: df.to_csv('data/foo.csv', index_label='date') df = pd.read_csv('data/foo.csv',](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_78.jpg){kind=link}
![HDF5 In [216]: In [217]: df.to_hdf('data/foo.h5','df') df = pd.read_hdf('data/foo.h5','df') df.head()](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_79.jpg){kind=link}
![Excel In [218]: In [219]: df.to_excel('data/foo.xlsx', index_label='date', sheet_name='Sheet1') df =](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_80.jpg){kind=link}
![Obrigado! Dúvidas? Felipe Pontes @felipemfp [email protected]](https://files.speakerdeck.com/presentations/8039e701743541239704e6cd0545bd77/slide_81.jpg){kind=link}
{kind=link}