This presentation introduces K-Means clustering, covering its core concepts, step-by-step process, real-world applications, and advantages and limitations. Designed for aspiring members of the Tencent Innovation Club, it highlights how K-Means can drive practical machine learning solutions and data-driven innovation.
{kind=link}
{kind=link}
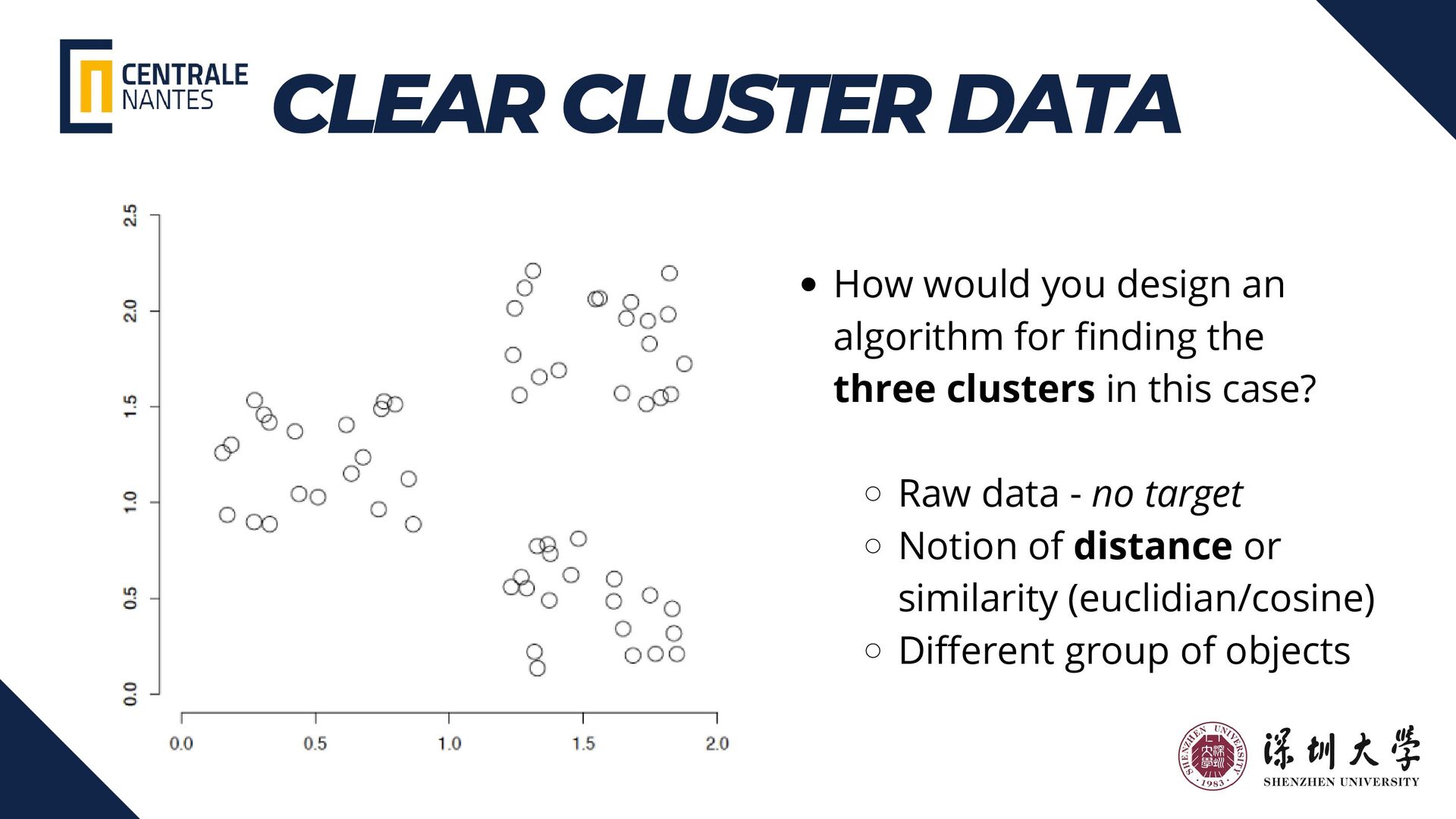{kind=link}
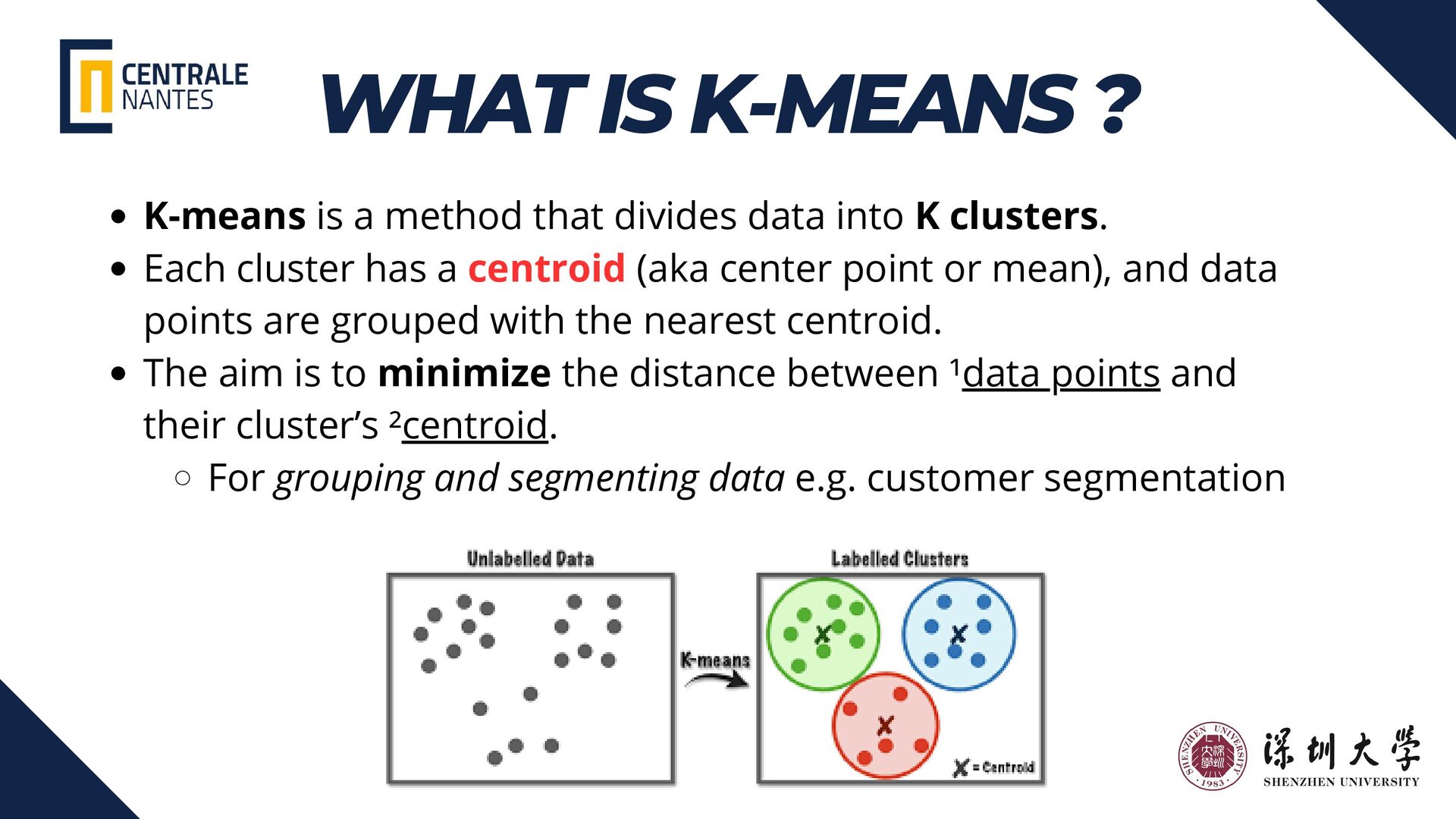{kind=link}
{kind=link}
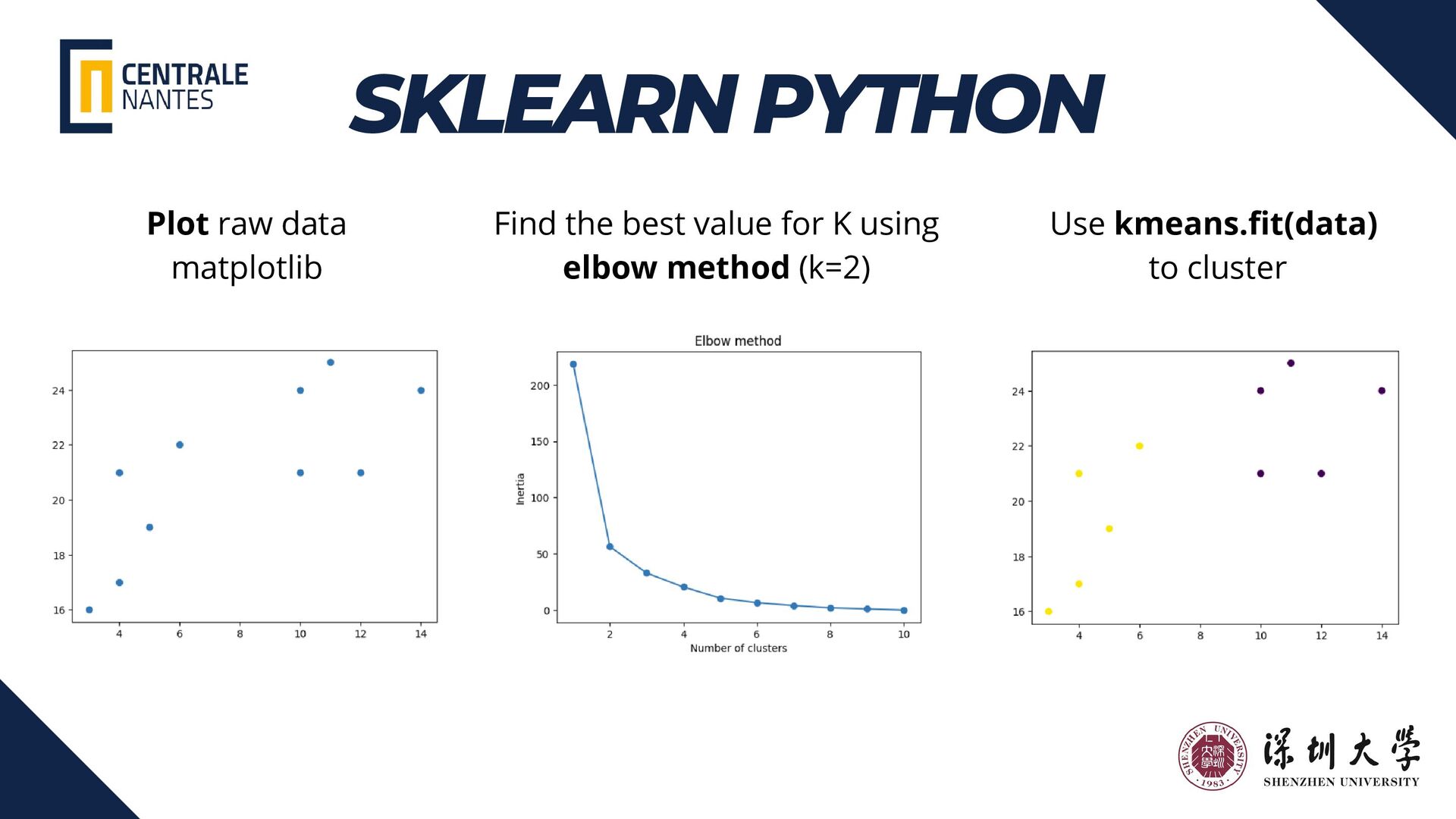{kind=link}
{kind=link}
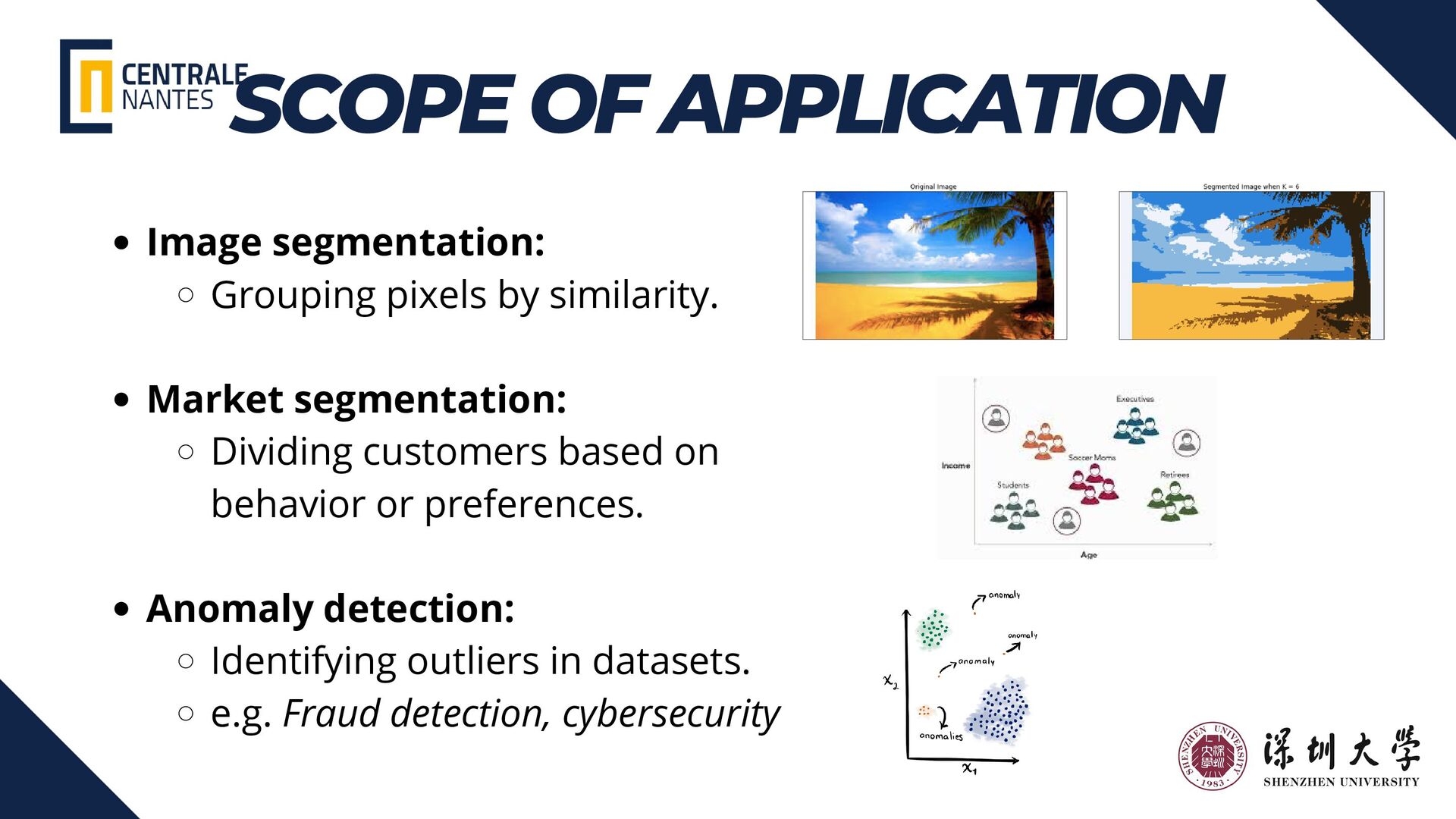{kind=link}
{kind=link}