Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
【論文紹介】Deep Inside Convolutional Networks Visual...
Search
fhiyo
September 03, 2018
Science
1.6k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
【論文紹介】Deep Inside Convolutional Networks Visualising Image Classification Models and Saliency Maps -- Simonyan Vedaldi Zisserman 2013 in ArXiv.pdf
fhiyo
September 03, 2018
More Decks by fhiyo
See All by fhiyo
Security_Engineering___Third_Edition_Chapter.20.pdf
fhiyo
0
34
Security_Engineering___Third_Edition_Chapter.21.pdf
fhiyo
0
35
Git再入門
fhiyo
0
160
効果検証入門1章
fhiyo
1
550
言語処理のための機械学習入門 1.1〜1.4
fhiyo
0
96
オプトにおける自然言語生成の応用事例
fhiyo
6
790
【論文紹介】Forecasting at Scale
fhiyo
1
720
統計的因果探索に入門してみた
fhiyo
0
560
Other Decks in Science
See All in Science
機械学習 - SVM
trycycle
PRO
2
1.2k
AkarengaLT vol.41
hashimoto_kei
1
150
フィードフォワードニューラルネットワークを用いた記号入出力制御系に対する制御器設計 / Controller Design for Augmented Systems with Symbolic Inputs and Outputs Using Feedforward Neural Network
konakalab
0
160
Kritische evaluatie van GenAI-output voor literatuuronderzoek
voginip
0
190
水耕栽培を始める前に知っておきたい植物の科学
grow_design_lab
0
280
機械学習 - ニューラルネットワーク入門
trycycle
PRO
0
1.1k
Utiliser Bitcoin sans Internet
rlifchitz
0
300
俺たちは本当に分かり合えるのか? ~ PdMとスクラムチームの “ずれ” を科学する
bonotake
2
2.5k
Inside the Mind of an LLM
baggiponte
0
200
データベース11: 正規化(1/2) - 望ましくない関係スキーマ
trycycle
PRO
0
1.3k
Understanding CVP Waveforms: Interpretation and Clinical Implications in Anesthesiology
taka88
0
680
AkarengaLT vol.40
hashimoto_kei
0
120
Featured
See All Featured
Marketing to machines
jonoalderson
1
5.6k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
400
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
470
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Un-Boring Meetings
codingconduct
0
350
Docker and Python
trallard
47
4k
GitHub's CSS Performance
jonrohan
1033
470k
Making the Leap to Tech Lead
cromwellryan
135
10k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
[SF Ruby Conf 2025] Rails X
palkan
2
1.2k
Claude Code のすすめ
schroneko
67
230k
Transcript
【論文紹介】 Deep Inside Convolutional Networks: Visualising Image Classification Models and
Saliency Maps Simonyan, Vedaldi, Zisserman 2013 in ArXiv @fhiyo 1
自己紹介 @fhiyo データサイエンスエンジニア 統計解析、機械学習モデル作成 Python / Shell Script (bash) /
C++ / Java 広く浅く、科学なら割となんでも好き 2
Outline - 論文: https://arxiv.org/abs/1312.6034 - deep Convolutional Networks (ConvNet) の可視化の研究
- 目的変数についての各画素の重要度を saliency map (顕著性マップ) として出力することで、弱教 師あり物体認識 (weakly supervised object segmentation) のタスクを解いている - 本論文の可視化手法は、逆畳み込みネットワーク (deconvolutional network) による可視化の 一般化である (今回はあまり触れない ) 3
用語解説 4
Saliency Map (顕著性マップ) 人が画像をみたときに注目しやすい場所を推定したヒートマップのこと。 登場してから歴史が長く、様々なモデルが提案されている。 5 Hou, X., & Zhang,
L. (2007). Saliency Detection : A Spectral Residual Approach, 2(800) 人が左の画像を見るとき、木や芝よりも人がいるところを注目している Saliency Mapの実装例: https://www.kaggle.com/ernie55ernie/mnist-with-keras-visualization-and-saliency-map
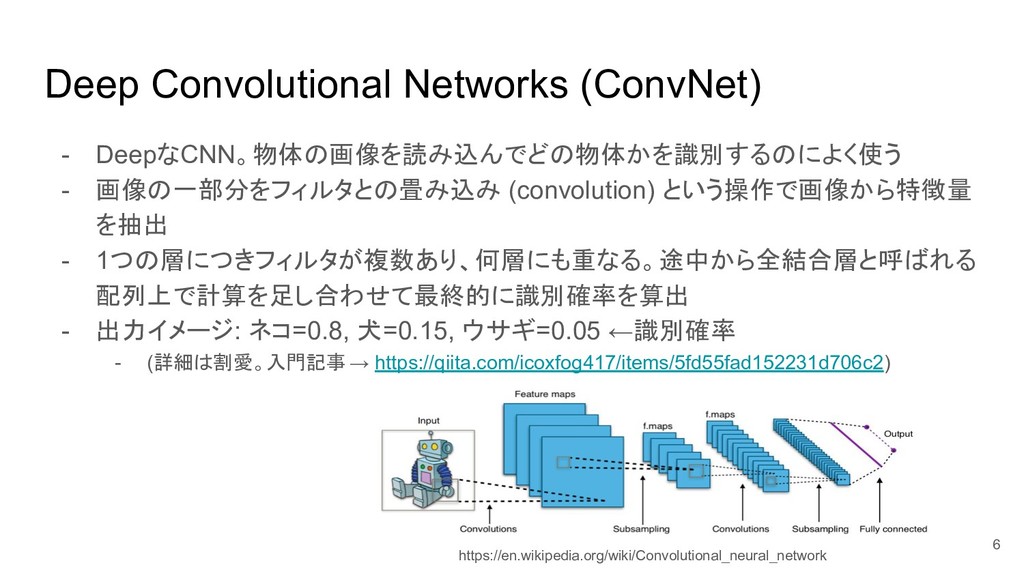
Deep Convolutional Networks (ConvNet) - DeepなCNN。物体の画像を読み込んでどの物体かを識別するのによく使う - 画像の一部分をフィルタとの畳み込み (convolution) という操作で画像から特徴量
を抽出 - 1つの層につきフィルタが複数あり、何層にも重なる。途中から全結合層と呼ばれる 配列上で計算を足し合わせて最終的に識別確率を算出 - 出力イメージ: ネコ=0.8, 犬=0.15, ウサギ=0.05 ←識別確率 - (詳細は割愛。入門記事 → https://qiita.com/icoxfog417/items/5fd55fad152231d706c2) https://en.wikipedia.org/wiki/Convolutional_neural_network 6
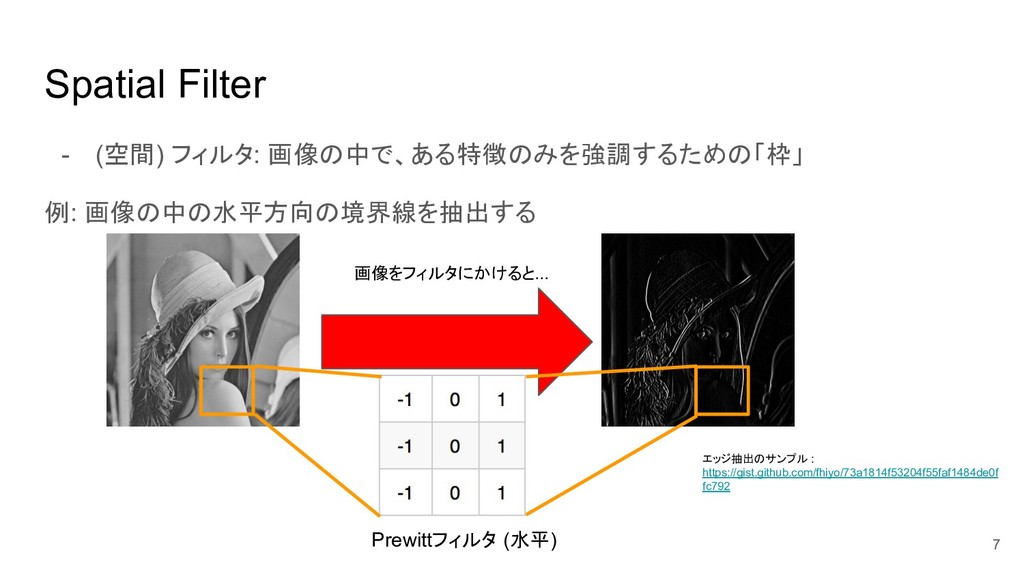
Spatial Filter - (空間) フィルタ: 画像の中で、ある特徴のみを強調するための「枠」 例: 画像の中の水平方向の境界線を抽出する 7 Prewittフィルタ
(水平) 画像をフィルタにかけると... エッジ抽出のサンプル : https://gist.github.com/fhiyo/73a1814f53204f55faf1484de0f fc792
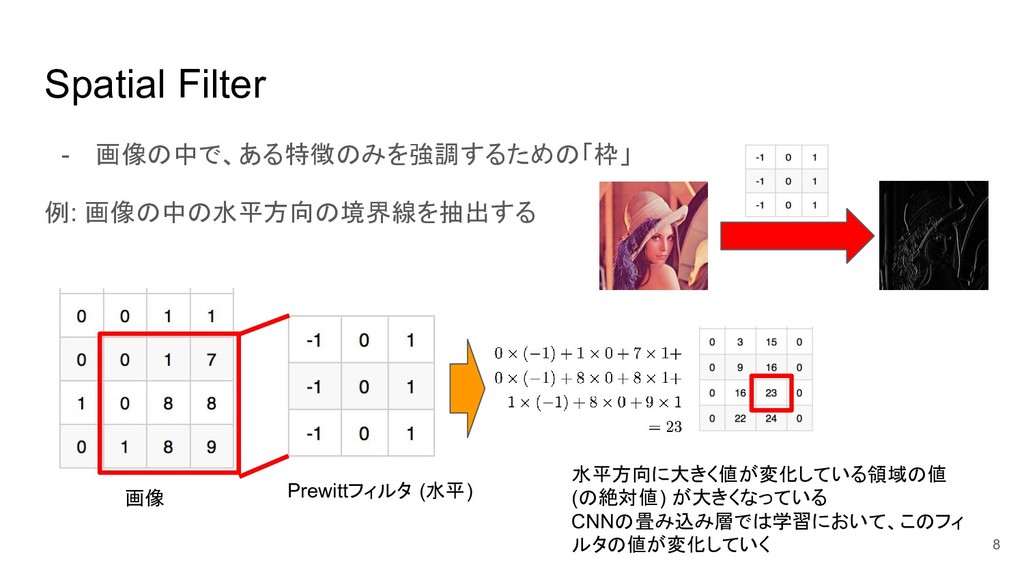
Spatial Filter - 画像の中で、ある特徴のみを強調するための「枠」 例: 画像の中の水平方向の境界線を抽出する 8 Prewittフィルタ (水平) 水平方向に大きく値が変化している領域の値
(の絶対値) が大きくなっている CNNの畳み込み層では学習において、このフィ ルタの値が変化していく 画像
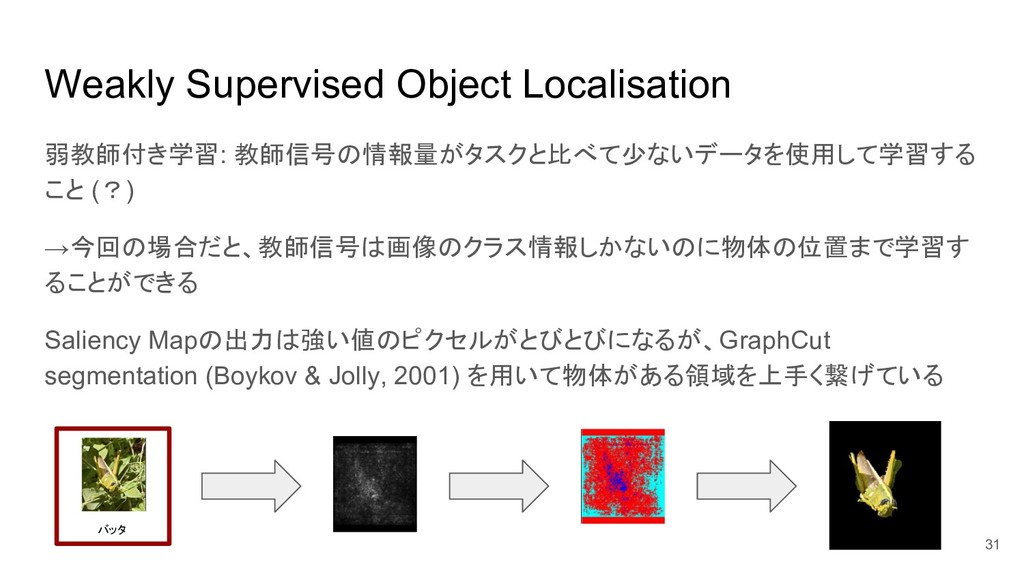
Weakly Supervised Object Localisation 弱教師付き学習: 教師信号の情報量がタスクと比べて少ないデータを使用して学習する こと (?) →今回の場合だと、教師信号は画像のクラス情報しかないのに物体の位置まで学習す ることができる
9 バッタ 入力画像とラベルの 情報のみから物体が ある位置を抽出してい る
Research Background - ConvNetによる物体認識は精度は高いが解釈性が悪い - ネコだと認識したのはわかるし精度もすごいんだけど、画像のどこを見て、どう計算してネコと判定 したのか? - 先行研究 -
ある層のあるフィルタに着目して、その活性化関数を最大化するような入力パターンを最適化を行 うことで発見する (Erhan et al., 2009) - 上の研究ではどのような画像がフィルタに反応するかはわかるが、入力画像のどの部分が識別結 果に寄与しているのかは不明 10 i番目の層のj個目のフィルタの出力を最大化する入 力画像x*を求める
Contribution - どのような画像がフィルタに強く反応するのかを調べた (ConvNetに対して計算し たのは始めて) - Saliency mapを出力することで、画像のどの部分が識別結果に寄与したのかを可 視化することに成功→ConvNetの解釈性を向上させた -
本論文で使われている勾配法による可視化は、逆畳み込みネットワークによる可 視化の一般化であることを示した 11
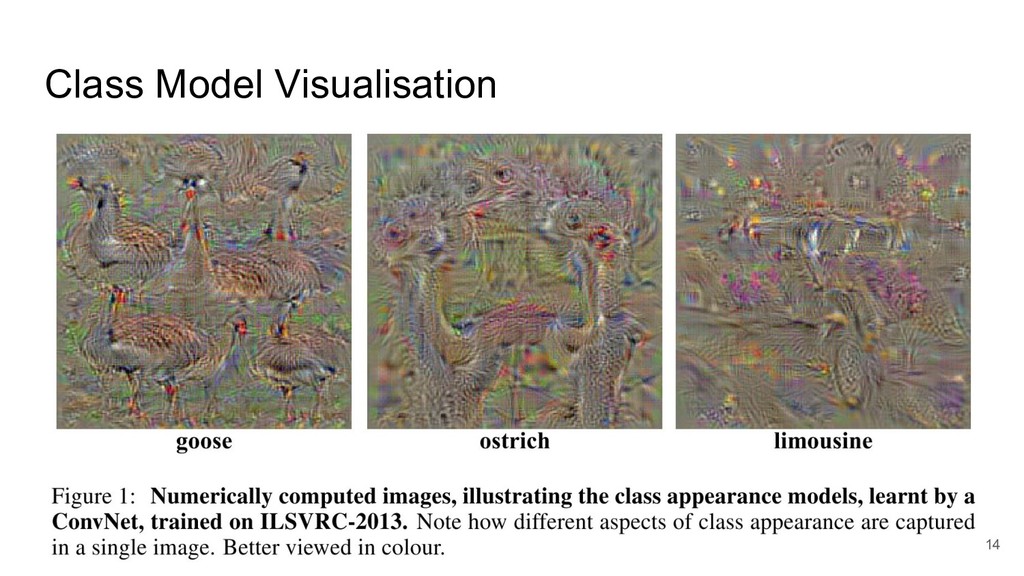
Class Model Visualisation 12
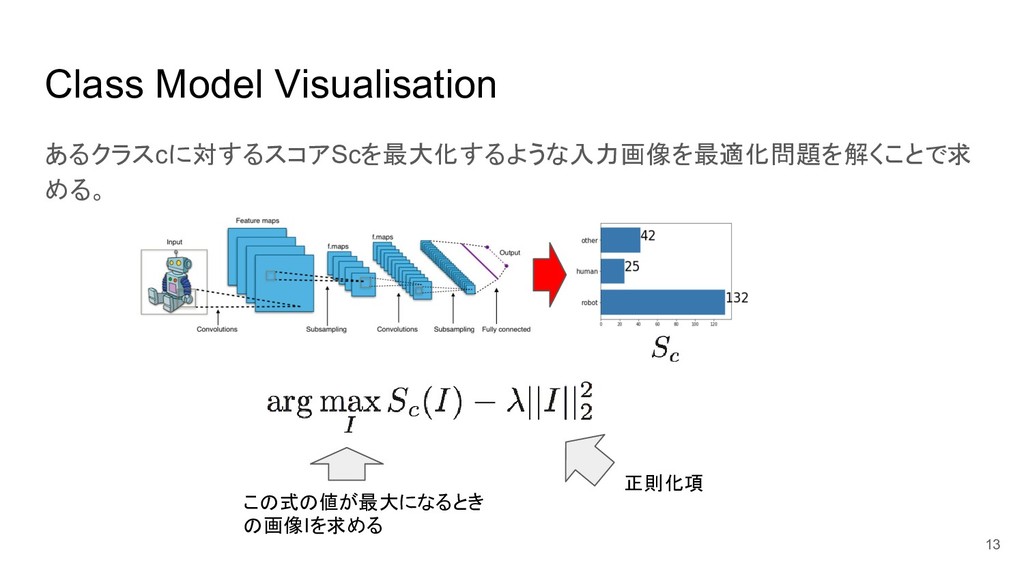
Class Model Visualisation あるクラスcに対するスコアScを最大化するような入力画像を最適化問題を解くことで求 める。 13 この式の値が最大になるとき の画像Iを求める 正則化項
Class Model Visualisation 14
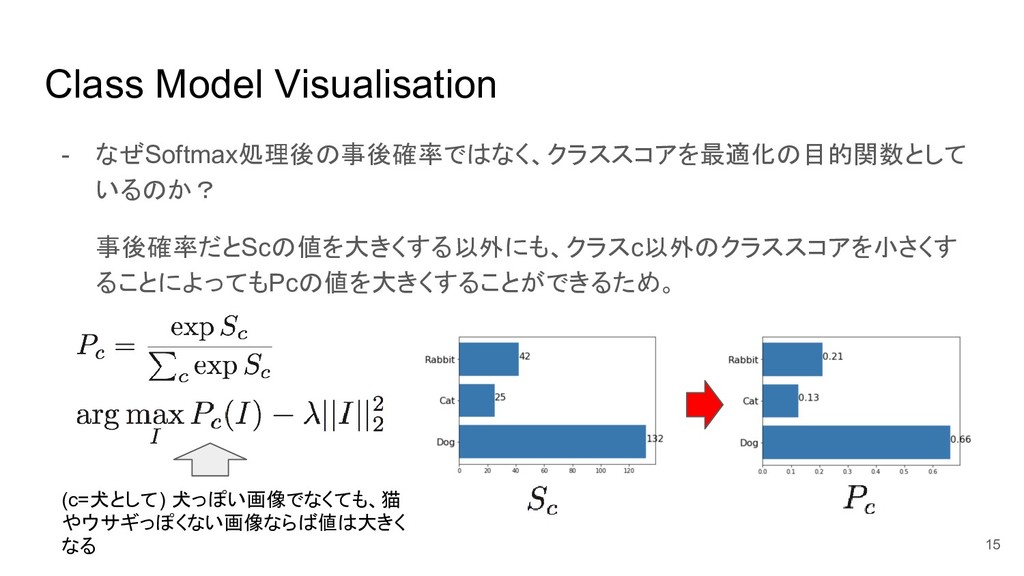
Class Model Visualisation - なぜSoftmax処理後の事後確率ではなく、クラススコアを最適化の目的関数として いるのか? 事後確率だとScの値を大きくする以外にも、クラスc以外のクラススコアを小さくす ることによってもPcの値を大きくすることができるため。 15 (c=犬として)
犬っぽい画像でなくても、猫 やウサギっぽくない画像ならば値は大きく なる
Image-Specific Class Saliency Visualisation 16
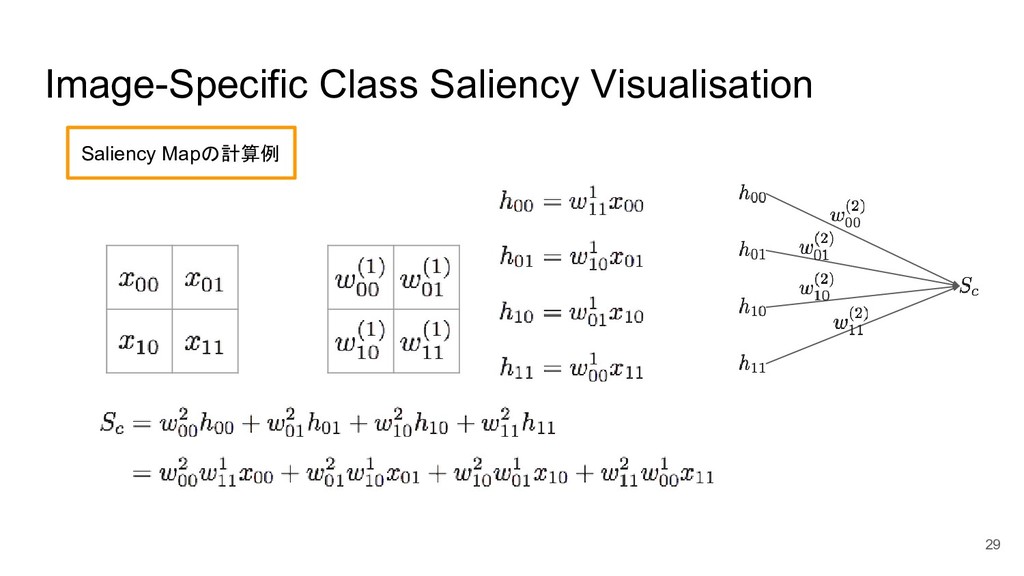
Image-Specific Class Saliency Visualisation ConvNetに対してfirst-order Taylor expansionを用いて近似することで各ピクセルの重 要度を算出する。 クラス分類において重要なピクセルは、直感的にはオブジェクトが存在しているところと 考えることができる。実験したところ実際にそうなっていることを確認した
17 I: 入力画像, S: クラススコア, c: クラスラベル, b: 定数項 このwを画像の形に配列し直したものが本研究における Saliency Map
Image-Specific Class Saliency Visualisation 18
[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。
19 https://en.wikipedia.org/wiki/Taylor_series テイラー展開の次数を上げることによって元の 関数にfittingする (左) (式: y = e^x) 収束半径内では次数を上げることで元の関数に 近づくが、収束半径外 (x > 1) では次数を上げる ことで発散していく (右) (式: y = log(1 + x)) ref: http://eman-physics.net/math/taylor.html
[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。
20 https://en.wikipedia.org/wiki/Taylor_series テイラー展開の次数を上げることによって元の 関数にfittingする (左) (式: y = e^x) 収束半径内では次数を上げることで元の関数に 近づくが、収束半径外 (x > 1) では次数を上げる ことで発散していく (右) (式: y = log(1 + x)) ref: http://eman-physics.net/math/taylor.html
[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。
21 https://en.wikipedia.org/wiki/Taylor_series テイラー展開の次数を上げることによって元の 関数にfittingする (左) (式: y = e^x) 収束半径内では次数を上げることで元の関数に 近づくが、収束半径外 (x > 1) では次数を上げる ことで発散していく (右) (式: y = log(1 + x)) ref: http://eman-physics.net/math/taylor.html
[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。
22 https://en.wikipedia.org/wiki/Taylor_series テイラー展開の次数を上げることによって元の 関数にfittingする (左) (式: y = e^x) 収束半径内では次数を上げることで元の関数に 近づくが、収束半径外 (x > 1) では次数を上げる ことで発散していく (右) (式: y = log(1 + x)) ref: http://eman-physics.net/math/taylor.html
[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。
23 https://en.wikipedia.org/wiki/Taylor_series テイラー展開の次数を上げることによって元の 関数にfittingする (左) (式: y = e^x) 収束半径内では次数を上げることで元の関数に 近づくが、収束半径外 (x > 1) では次数を上げる ことで発散していく (右) (式: y = log(1 + x)) ref: http://eman-physics.net/math/taylor.html
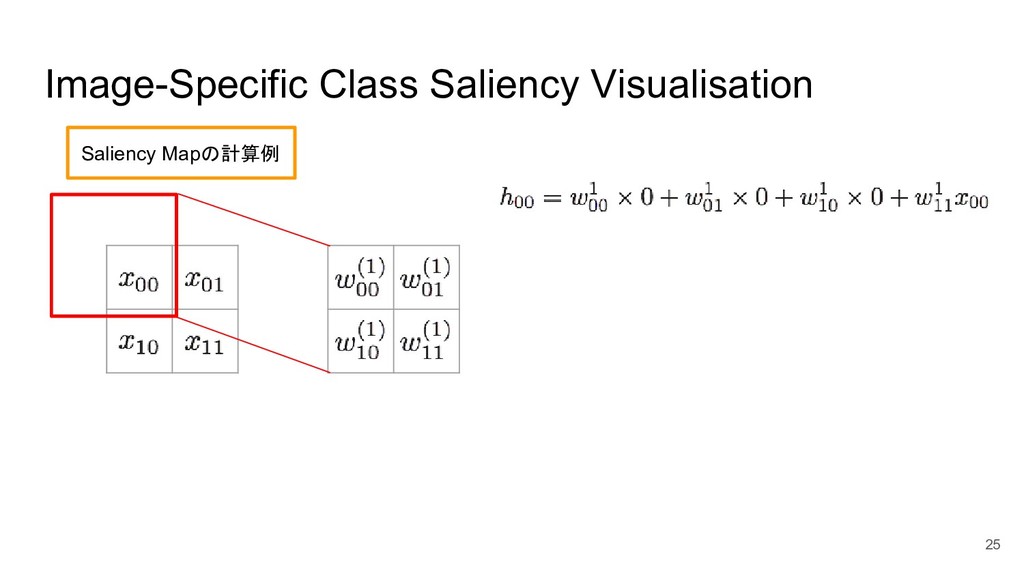
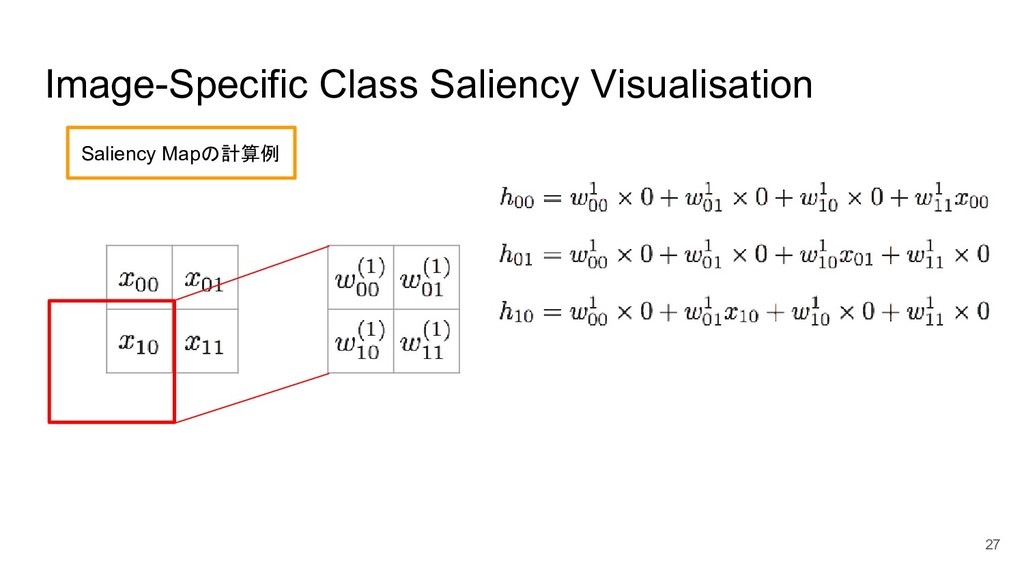
Image-Specific Class Saliency Visualisation 24 Saliency Mapの計算例 入力画像X 畳み込み層W 入力画像Xに対してフィルタWで畳み込んだ結果を全結合層
Hに格納し、そこ からNNの重みである と行列計算をすることによりクラススコア Scを出力す る、というモデルを考える。 全結合層H
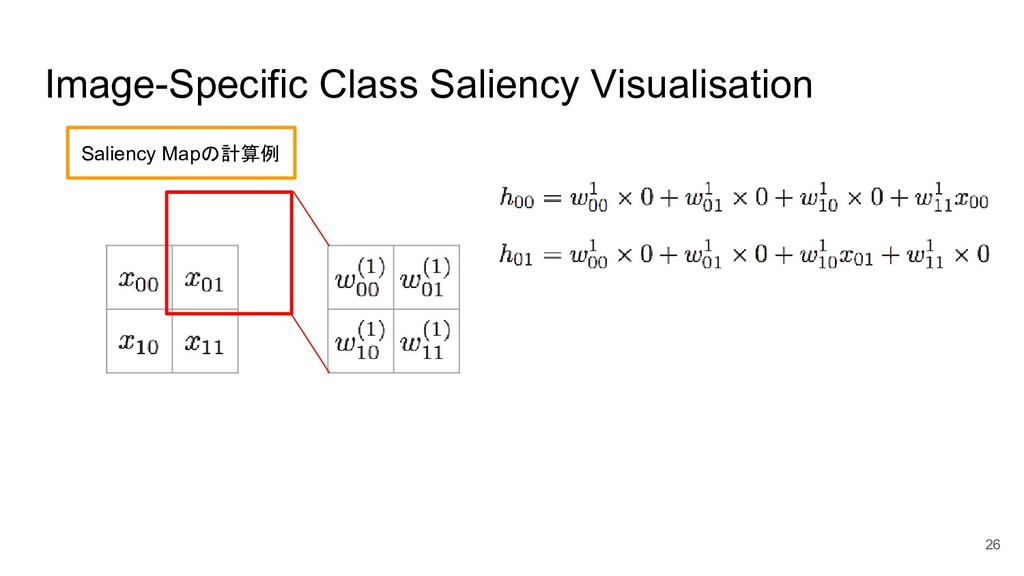
Image-Specific Class Saliency Visualisation 25 Saliency Mapの計算例
Image-Specific Class Saliency Visualisation 26 Saliency Mapの計算例
Image-Specific Class Saliency Visualisation 27 Saliency Mapの計算例
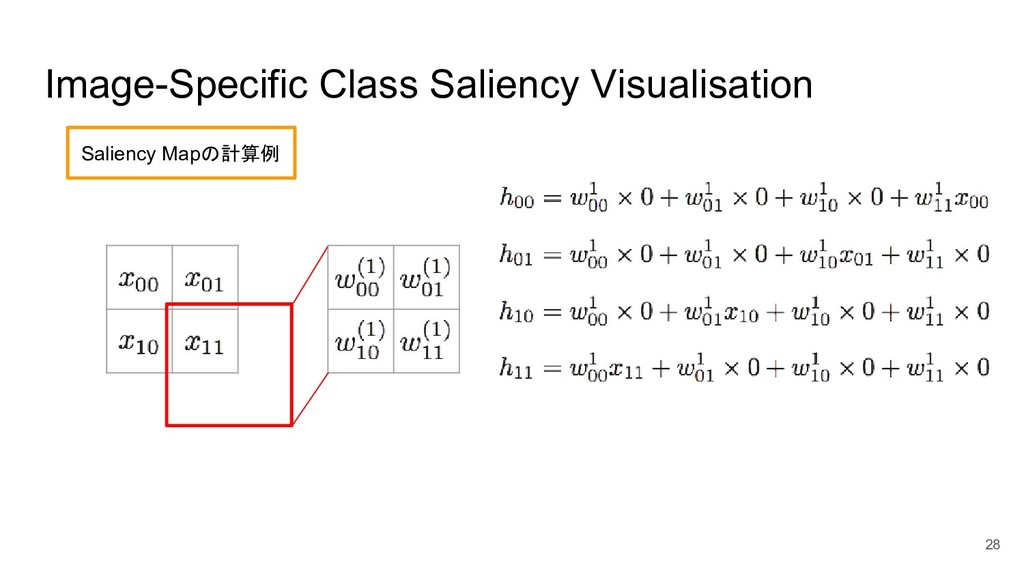
Image-Specific Class Saliency Visualisation 28 Saliency Mapの計算例
Image-Specific Class Saliency Visualisation 29 Saliency Mapの計算例
Image-Specific Class Saliency Visualisation 30 Saliency Mapの計算例 今回の例は単純なモデルのため入力に対して定 数になったが、中間層が増えれば Saliency
Map の各成分は入力画像の関数になる
Weakly Supervised Object Localisation 弱教師付き学習: 教師信号の情報量がタスクと比べて少ないデータを使用して学習する こと (?) →今回の場合だと、教師信号は画像のクラス情報しかないのに物体の位置まで学習す ることができる
Saliency Mapの出力は強い値のピクセルがとびとびになるが、GraphCut segmentation (Boykov & Jolly, 2001) を用いて物体がある領域を上手く繋げている 31 バッタ
Weakly Supervised Object Localisation 32
Relation to Deconvolutional Networks 33
Relation to Deconvolutional Networks - 詳細は割愛 - 本手法はZeiler, Fergusによる畳み込み層の可視化の一般化になっている -
畳み込み層だけでなくプーリング層や全結合層などの他の層に関しても可視化が できる - 実際、Saliency Mapは全結合層のクラススコアを算出するニューロンに対する可 視化である。 34 https://arxiv.org/abs/1311.2901
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。](https://files.speakerdeck.com/presentations/354c66c2d3764044bb490cf92596e894/slide_18.jpg){kind=link}
![[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。](https://files.speakerdeck.com/presentations/354c66c2d3764044bb490cf92596e894/slide_19.jpg){kind=link}
![[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。](https://files.speakerdeck.com/presentations/354c66c2d3764044bb490cf92596e894/slide_20.jpg){kind=link}
![[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。](https://files.speakerdeck.com/presentations/354c66c2d3764044bb490cf92596e894/slide_21.jpg){kind=link}
![[復習] (finite) Taylor Series fが開区間Iにおいて、n回微分可能であるとする。 Iの点a を固定すると、各x ∈ Iに対して、 を満たすcがxとaの間に存在する。](https://files.speakerdeck.com/presentations/354c66c2d3764044bb490cf92596e894/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}