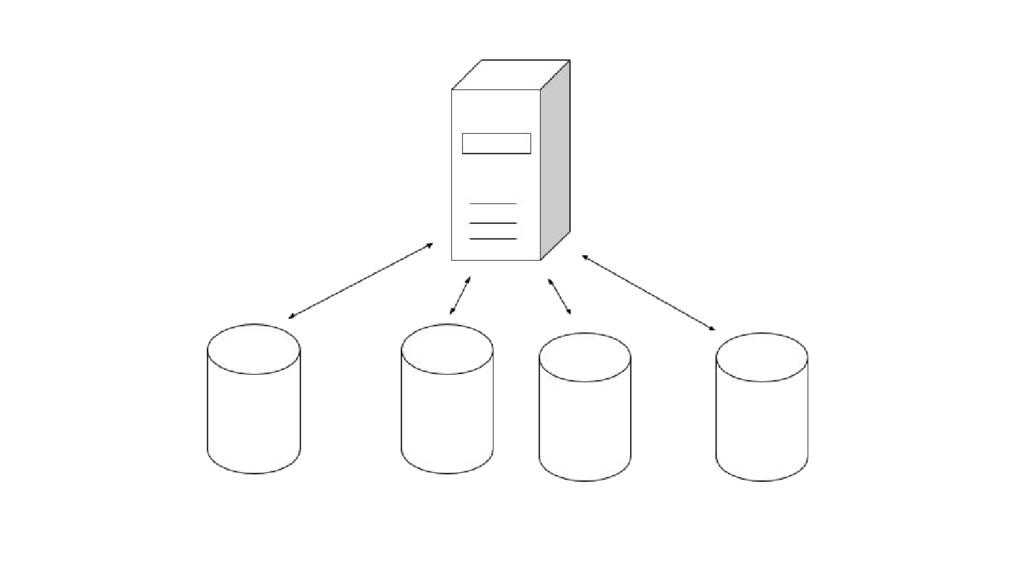
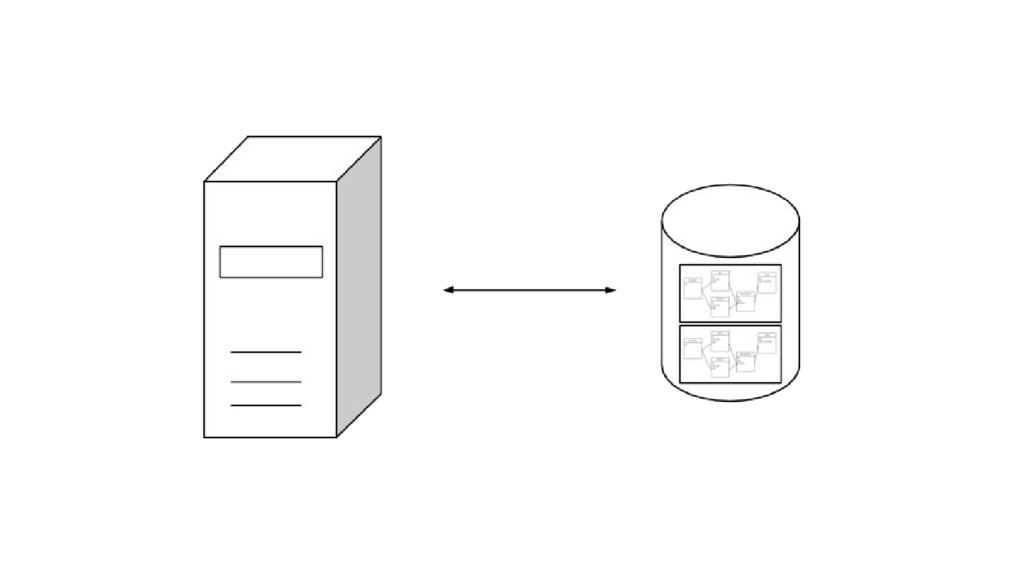
Applications often need multitenancy at some level. The most common scenario is to keep data isolated among clients. One way to achieve this is to have multiple database instances and connect to each according to the user accessing the system. Another approach is to have a single database and model relationships so it's possible to query data separately. The last common way is again to have a single database instance, but this time there are multiple separate schemas. I'll go over each of these approaches. For each, you will learn about the architecture, understand how to build it using Django, see examples on how to make queries and learn what tools can help on the job. By the end, you will understand key differences and be able to choose the approach that better suits your next application.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Single Shared Schema [or how the big guys do it]](https://files.speakerdeck.com/presentations/3dd956bf73844daca44c3e8994c7d5cc/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
![Routing - ibm.spinnertracking.com def tenant_middleware(get_response): def middleware(request): host = request.get_host().split(':')[0]](https://files.speakerdeck.com/presentations/3dd956bf73844daca44c3e8994c7d5cc/slide_18.jpg){kind=link}
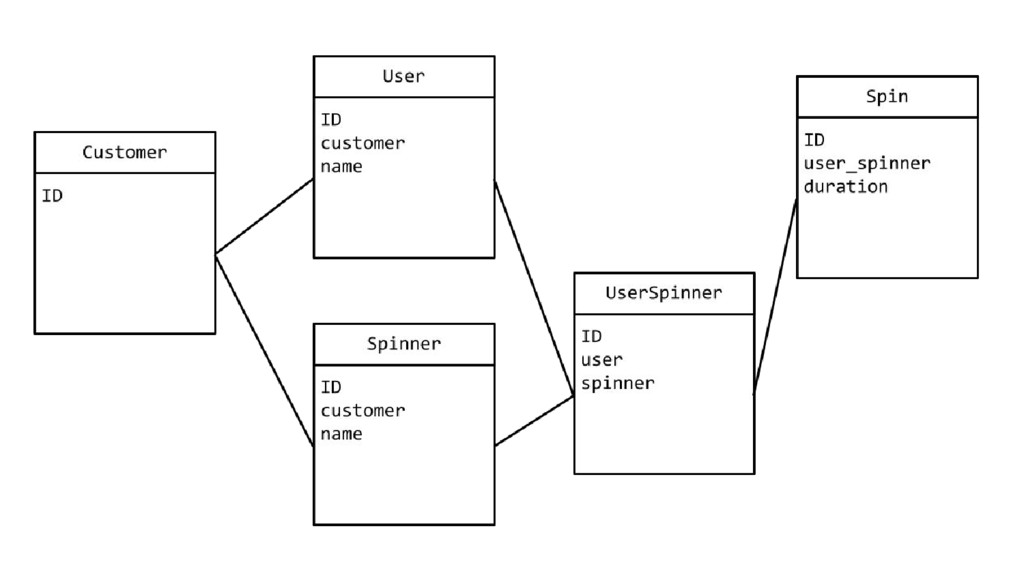
![Querying avg_duration = ( Spin.objects .filter(user_spinner__user__customer=request.customer) .aggregate(avg=Avg('duration')))['avg']](https://files.speakerdeck.com/presentations/3dd956bf73844daca44c3e8994c7d5cc/slide_19.jpg){kind=link}
{kind=link}
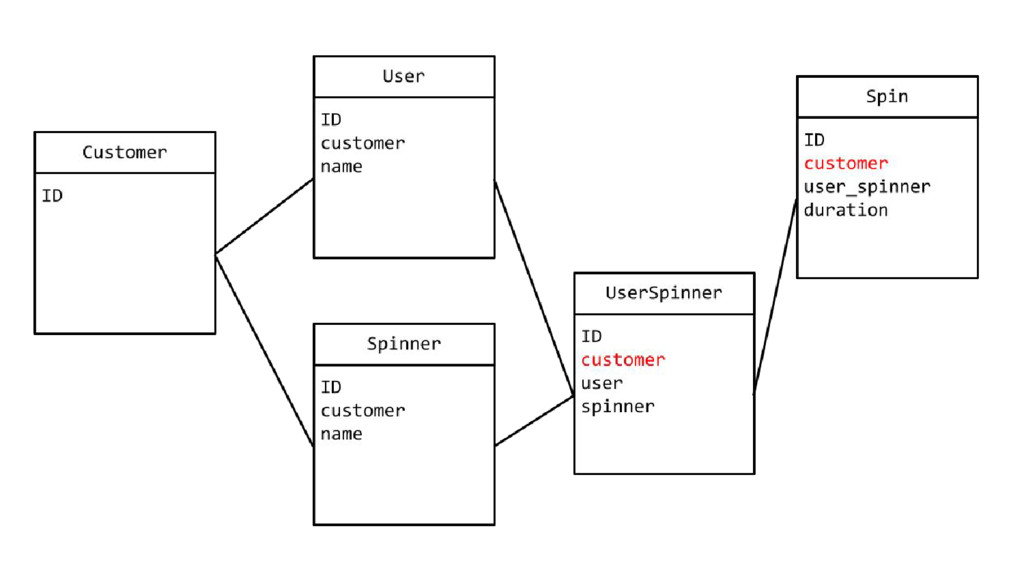
![Simpler querying avg_duration = ( Spin.objects .filter(customer=request.customer) .aggregate(avg=Avg('duration')))['avg']](https://files.speakerdeck.com/presentations/3dd956bf73844daca44c3e8994c7d5cc/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Routing - settings MIDDLEWARE_CLASSES = [ 'tenant_schemas.middleware.TenantMiddleware', # … ]](https://files.speakerdeck.com/presentations/3dd956bf73844daca44c3e8994c7d5cc/slide_39.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigado! http://bit.ly/vinta2017 Newsletter: vinta.com.br/blog/ twitter.com/@xima github.com/filipeximenes [email protected]](https://files.speakerdeck.com/presentations/3dd956bf73844daca44c3e8994c7d5cc/slide_49.jpg){kind=link}