la cual aprendemos cuando llegamos a este campo (a golpe de tutoriales y la documentación propia del sdk) se basa en Actividades, posteriormente Actividades y Fragments, y en ir extendiéndolas, así como usando una (o usando Fragments) por cada pantalla de nuestras aplicaciones. Esto nos lleva al problema de que nuestras Actividades empiezan a crecer y crecer de forma acelerada por cada nueva funcionalidad que les incluimos. O lo que se conoce como God Activity (Activity Dios u omnipresente), que carga con todo el peso de cada pantalla de nuestras aplicaciones, tales como: trabajo de presentación (UI), lógica, hilos, red, y todo lo que se nos ocurra. Arquitectura clásica I
aplicaciones con gran cantidad de funcionalidades y/o mantenimiento, dado que trae tantos problemas como todas y cada una de las cosas que mezclamos en estas clases omnipresentes: complejidad, dificultad de debugging, spaghetti code, casi imposibilidad de testeo, entre otras muchas. Partiendo de esta base tan endeble y a pesar de conseguir quizás (y no estoy muy seguro a día de hoy) un ritmo de desarrollo más acelerado solo estaremos cavando nuestro camino hacia la desesperación a hora de añadir nuevas características o realizar cualquier tipo de mantenimiento. Problemática I
bajo esta arquitectura? - Cargas de red en el hilo principal - Leaks de memoria - Evidente incumplmiento de los principios solid - Código nada testeable - Spaghetti code por doquier - Dificultad de debugging - Dificultad de extensibilidad y mantenimiento - ... Problemática II
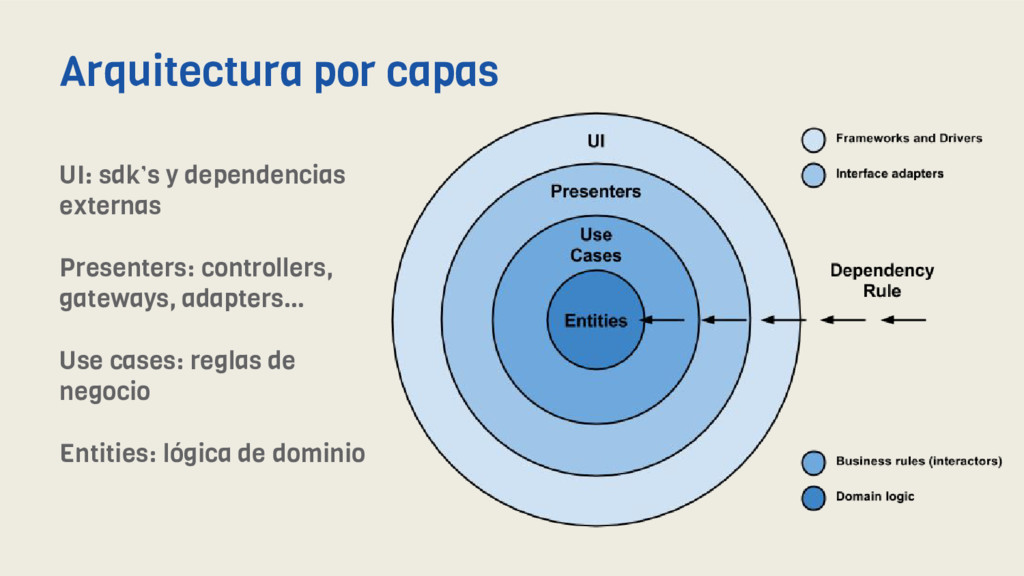
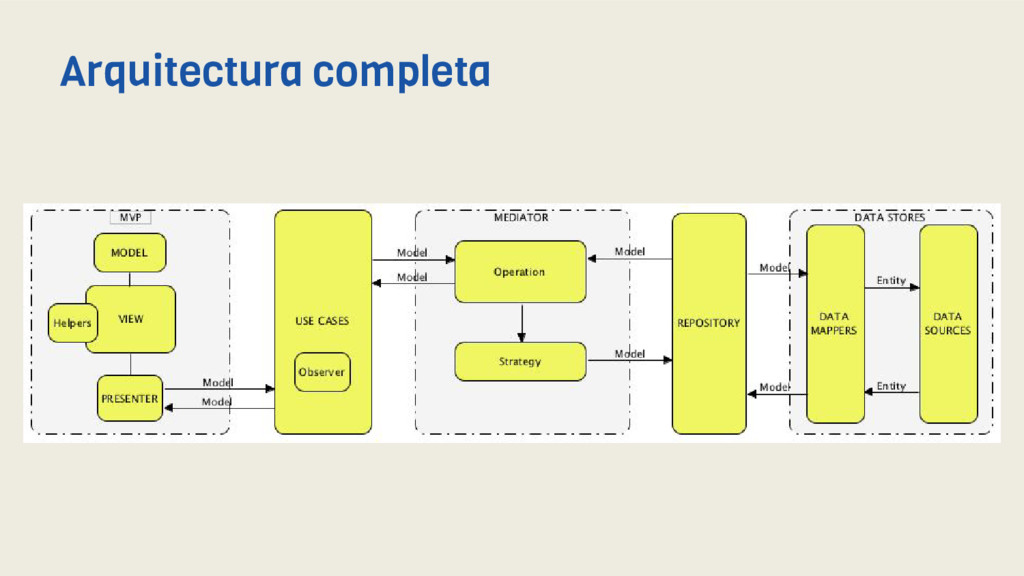
serían una serie de condiciones que debe cumplir nuestro software para que pueda ser considerado limpio, más que una arquitectura en sí puesto que no es cerrada y está abierta a interpretaciones. ¿En qué se basa? Clean Architecture nos muestra una serie de capas en las que separa el código de nuestra aplicación siguiendo una simple regla de dependencia de forma que: las dependencias sólo pueden apuntar hacia adentro y nada en un círculo interno puede saber nada en absoluto sobre algo en un círculo exterior. Introducción para noobs
como vemos son: - Una separación de conceptos sencilla - Gran extensibilidad y flexibilidad - Cumplimiento de los principios SOLID - Código limpio, testeable y mantenible - Desacoplamiento e independencia de frameworks - Fácil integración de librerías u otros agentes externos - Centrado en la lógica de negocio y no en las herramientas - Abstracción entre capas, especialmente notable entre fuentes de datos CA: SOLID y clean code
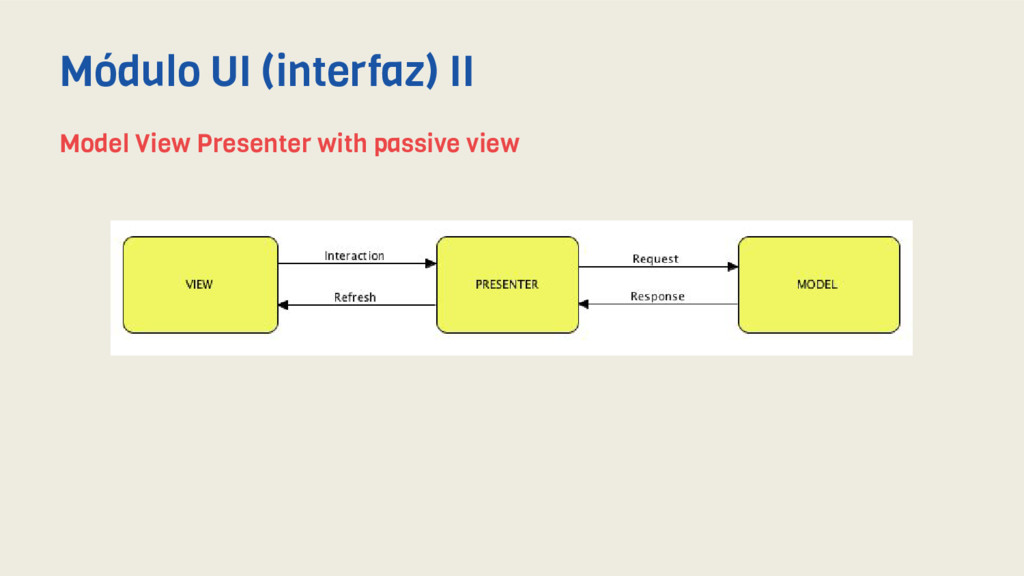
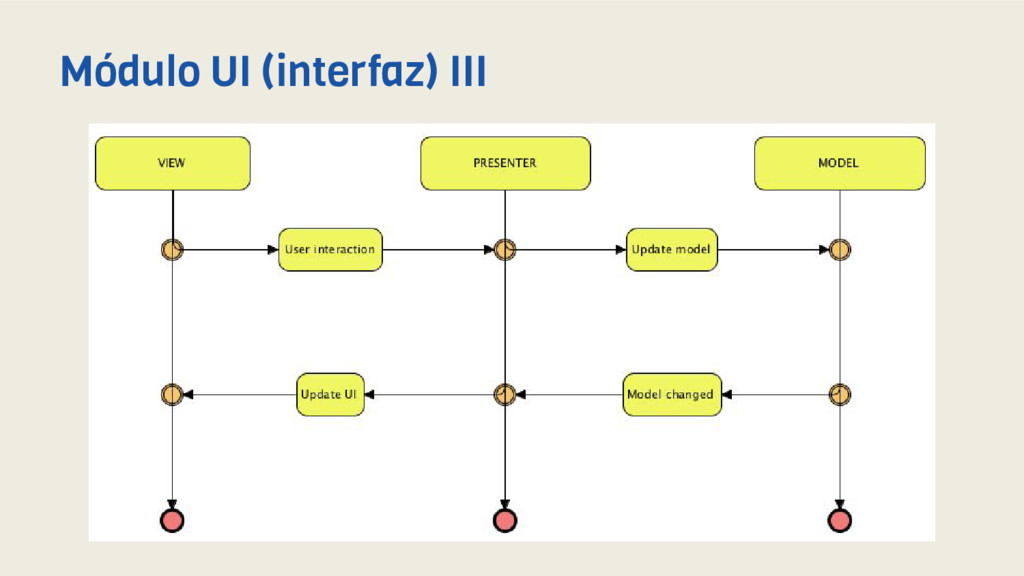
mas cercana posible la implementación clean en la capa de UI de nuestras aplicaciones. Para ello hemos empleado el patrón Modelo - Vista (pasiva) - Presentador (MVP) mediante un framework de creación propia (Meigic) y así separar la lógica de presentación de nuestras vistas, así como de nuestros modelos. Por otro lado hemos eliminado el uso de una interfaz para la implementación del Presentador puesto que no aporta mayor testabilidad ni desacoplamiento y en definitiva es una pérdida de tiempo. Además aplicamos activamente el concepto de Interface Driven Development, también llamado Diseño por contrato. Módulo UI (interfaz) I
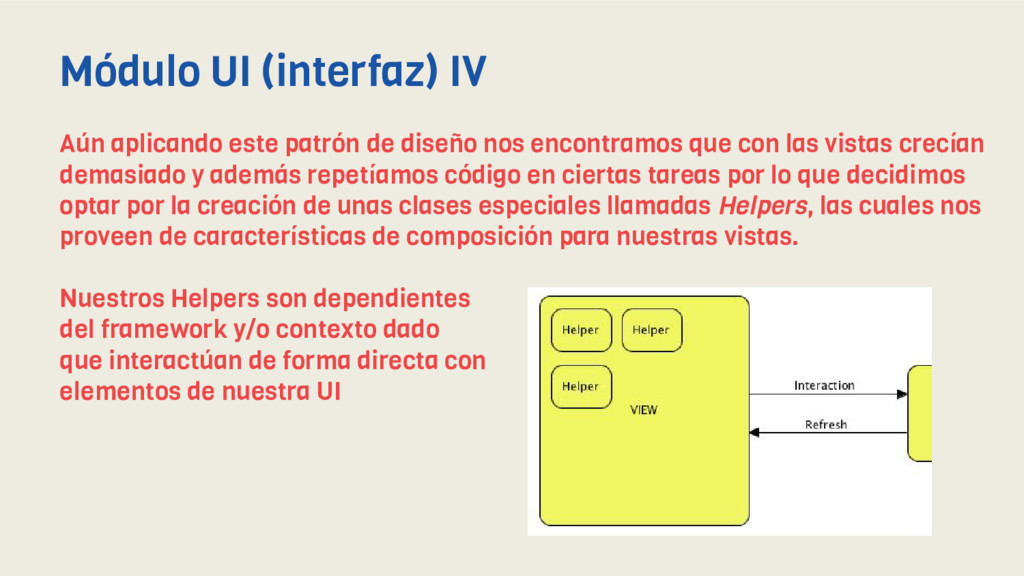
encontramos que con las vistas crecían demasiado y además repetíamos código en ciertas tareas por lo que decidimos optar por la creación de unas clases especiales llamadas Helpers, las cuales nos proveen de características de composición para nuestras vistas. Nuestros Helpers son dependientes del framework y/o contexto dado que interactúan de forma directa con elementos de nuestra UI Módulo UI (interfaz) IV
podemos ver una implementación simple del patrón MVP usando Meigic. Además se ha añadido una clase Helper (ColorHelper) que obtiene el contexto y la vista donde va a aplicar los cambios.
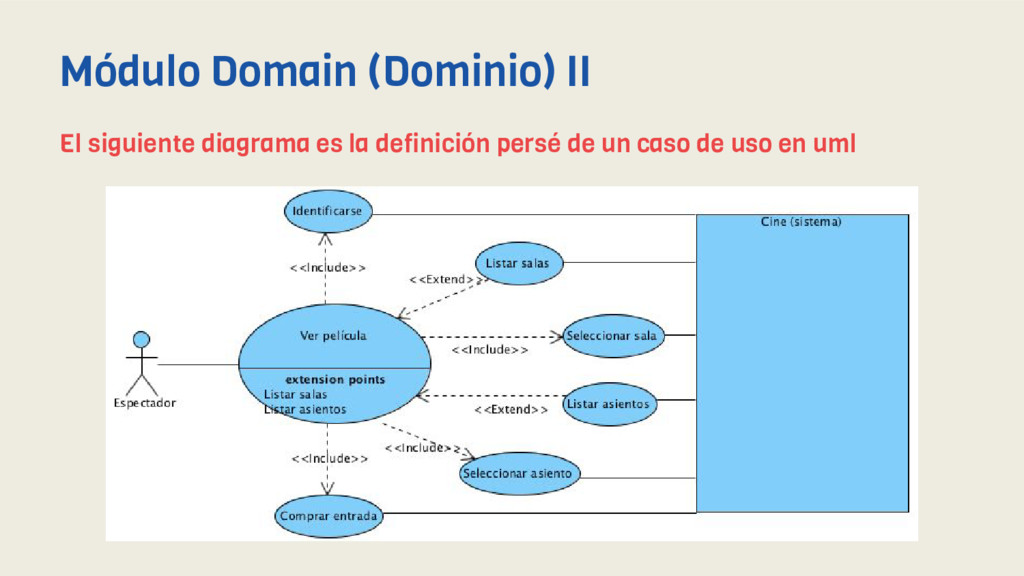
nuestra capa de dominio (negocio), por tanto tendremos nuestros Casos de Uso (también llamados Interactors) y nuestros Modelos de negocio propiamente dichos. Nuestra interpretación a la hora de implementar UseCase se basa en 3 cosas: - Fluent interfaces (patrón Api fluent) - RxJava (patrón Observer) - Patrón Command Por lo que tomamos ventaja de flexibilidad de modelado que nos ofrece RxJava a la hora de trabajar con datos y además dotamos de una interfaz fluida (y DSL) a nuestros casos de uso gracias a las Fluent interfaces. Módulo Domain (Dominio) I
vemos como implementamos en caso de uso de identificación de un usuario en el sistema. En LoginUseCase implementamos una interefaz fluida para dotarlo de semántica (DSL) y nos valemos del patrón comand como finalizador de la acción, este devuelve la subscripción (RX) para que obtengamos el resultado en nuestro Presenter
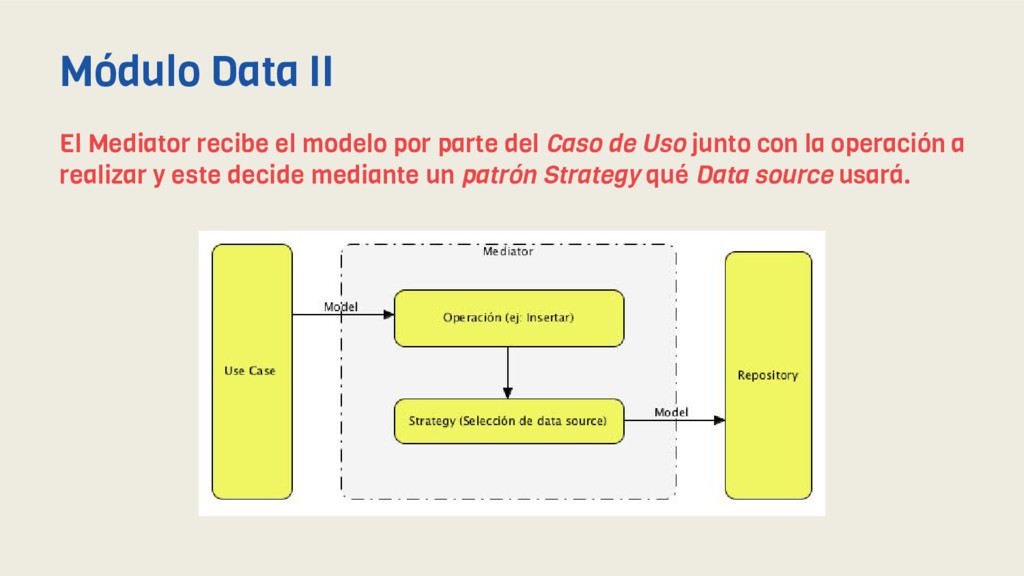
captado la interacción del usuario y hemos modelado una Request, por lo que nos queda: - Mediar sobre los repositorios (patrón Mediator) - Mapear la request (patrón Data mapper) - Seleccionar el repositorio (patrón Strategy) - Llamar al repo (patrón Repository) - Y por último mapear la respuesta (Response) y devolverla (Data mapper) De nuevo y como hemos visto hasta este punto, nos apoyamos en patrones para obtener un código limpio en cada capa. Módulo Data I
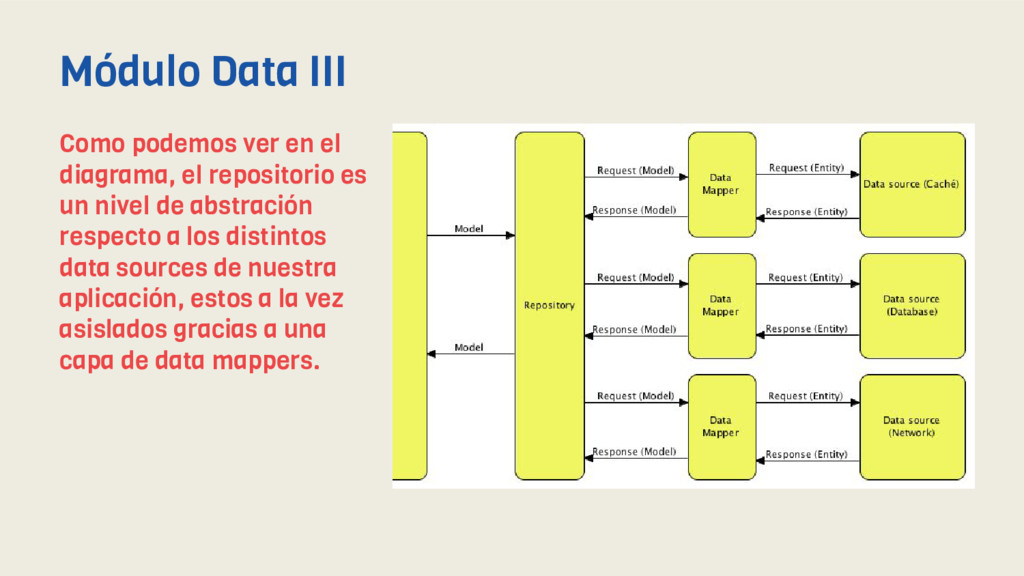
repositorio es un nivel de abstración respecto a los distintos data sources de nuestra aplicación, estos a la vez asislados gracias a una capa de data mappers. Módulo Data III
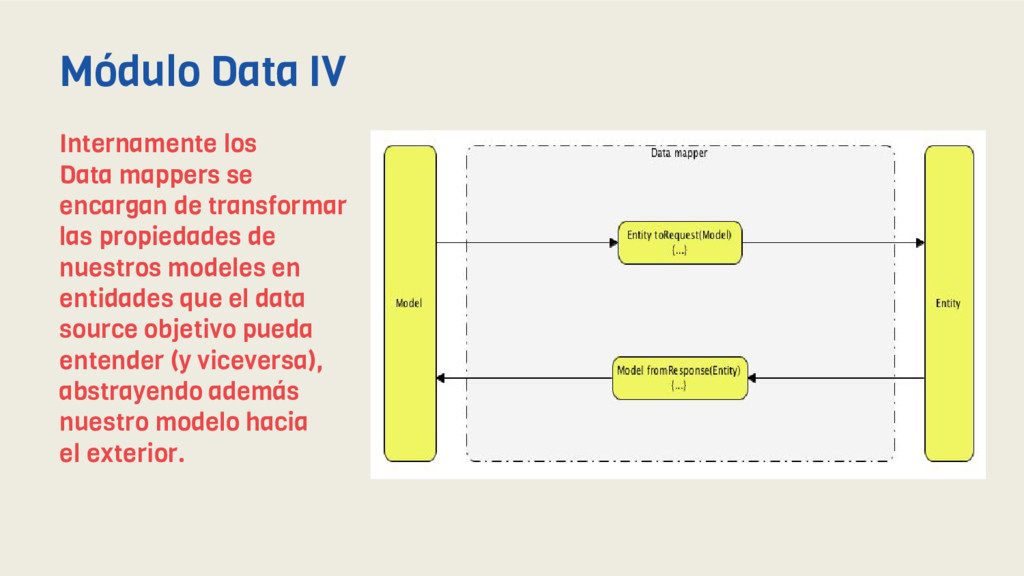
transformar las propiedades de nuestros modeles en entidades que el data source objetivo pueda entender (y viceversa), abstrayendo además nuestro modelo hacia el exterior. Módulo Data IV
Uso implementado en el módulo anterior, realizamos el login consultando primero nuestra Estratégia (caducidad de un token anterior) para decir como y donde loguearnos. Al elegir un repositorio externo, mapeamos nuestro modelo para adaptarlo a la endidad del repositorio y a la inversa con la respuesta.
planteado una problemática y explorado una solución, tomando las condiciones propuestas por Clean Architecture e implementándolas a golpe de patrónes de diseño de software. Con todo ello hemos obtenido una arquitectura sólida, limpia, testeable, facilmente mantenible, y además, facil de reconocer por aquellos que conozcan los patrones empleados. El esquema por capas que nos abstrae de implementaciones, el uso de fronteras mediante interfaces y data mappers que garantizan también una alta abstracción y extensión, facilitan en conjunto la adición de nuevas características y/o mantenimiento. Conclusión
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}