ONNXのカスタムオペレータとして出力 35 @parse_args('v', 'v', 'i', 'f', 'f') def symbolic_efficient_nms_standard(g, boxes, scores, num_boxes, score_threshold, iou_threshold): num_detections, detection_boxes, detection_scores, detection_classes = g.op('tensorrt::EfficientNMS_TRT', boxes, scores, outputs=4, score_threshold_f=score_threshold, iou_threshold_f=iou_threshold, max_output_boxes_i=num_boxes, background_class_i=-1, score_activation_i=0, box_coding_i=0, ) return num_detections, detection_boxes, detection_scores, detection_classes def forward(self, input): … torch.ops.load_library('custom_ops.so') return torch.ops.custom_ops.efficient_nms_standard(transformed_anchors, confs, num_boxes, self.threshold, self.iou_threshold) register_custom_op_symbolic('custom_ops::efficient_nms_standard‘, symbolic_efficient_nms_standard, 11) 「ドメイン名::プラグイン名」で ONNXのカスタムオペレータ出力 PyTorchの推論(ONNXエクスポート)時 はカスタムオペレータのDLLを呼び出す
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
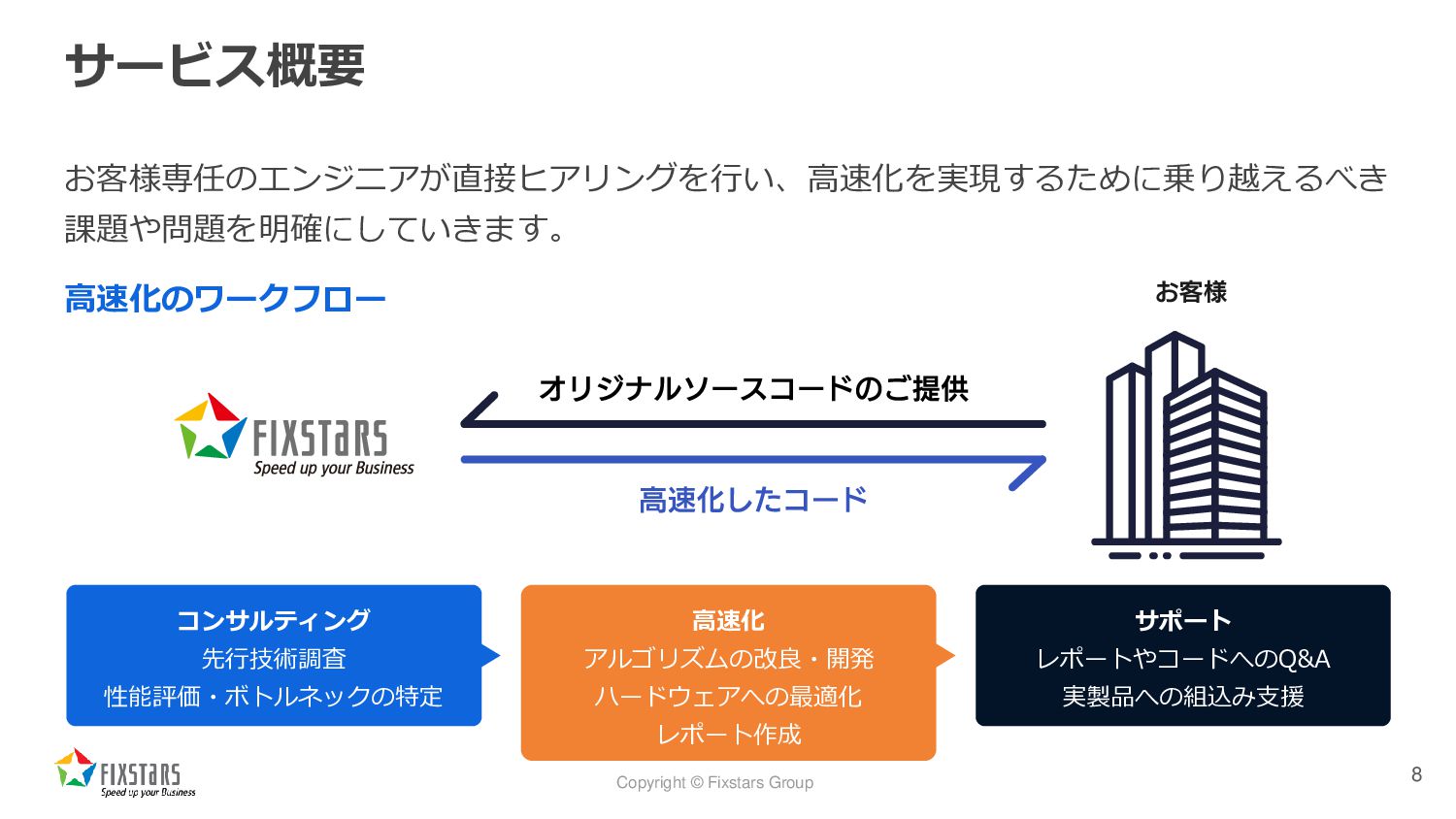{kind=link}
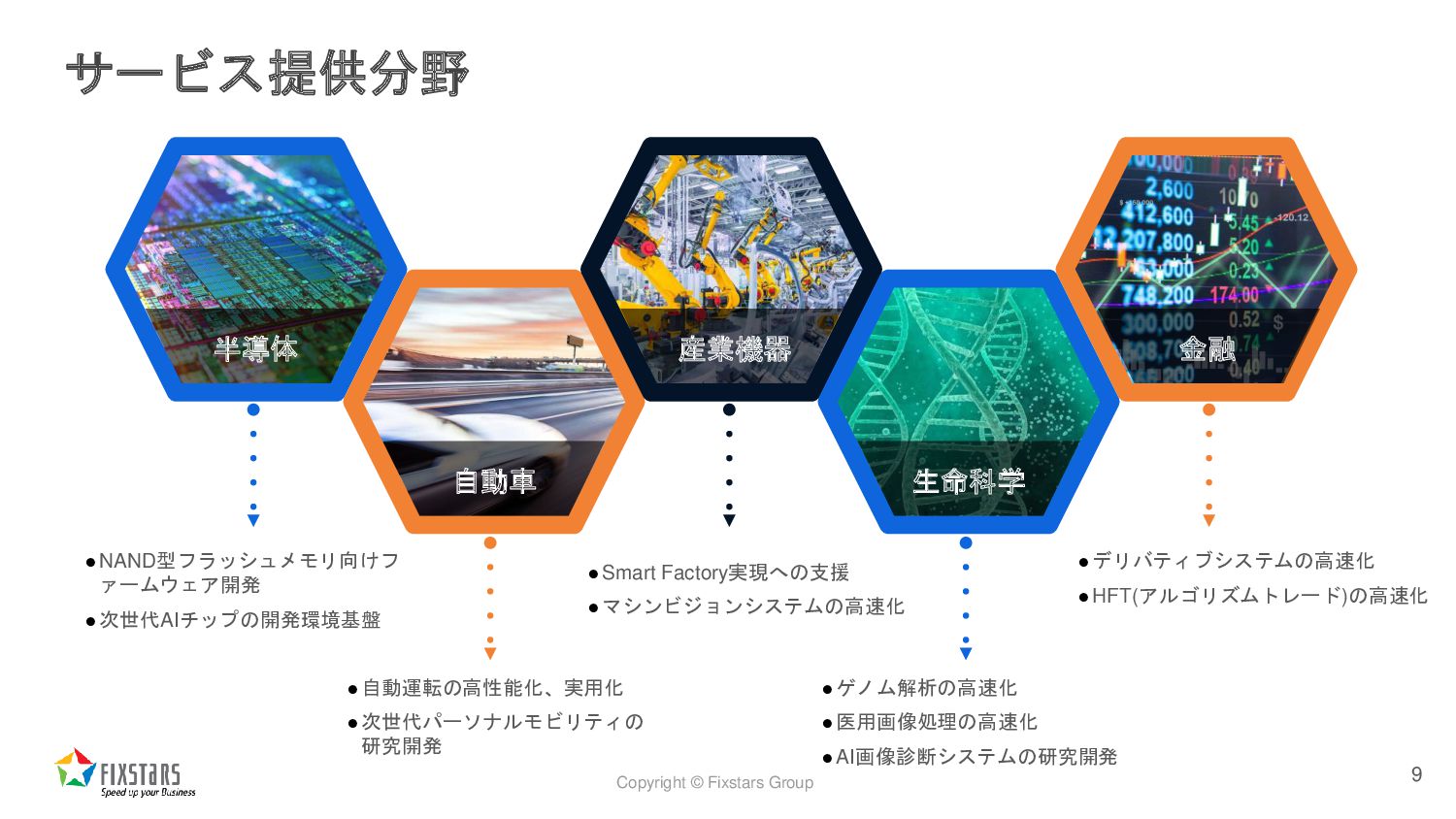{kind=link}
{kind=link}
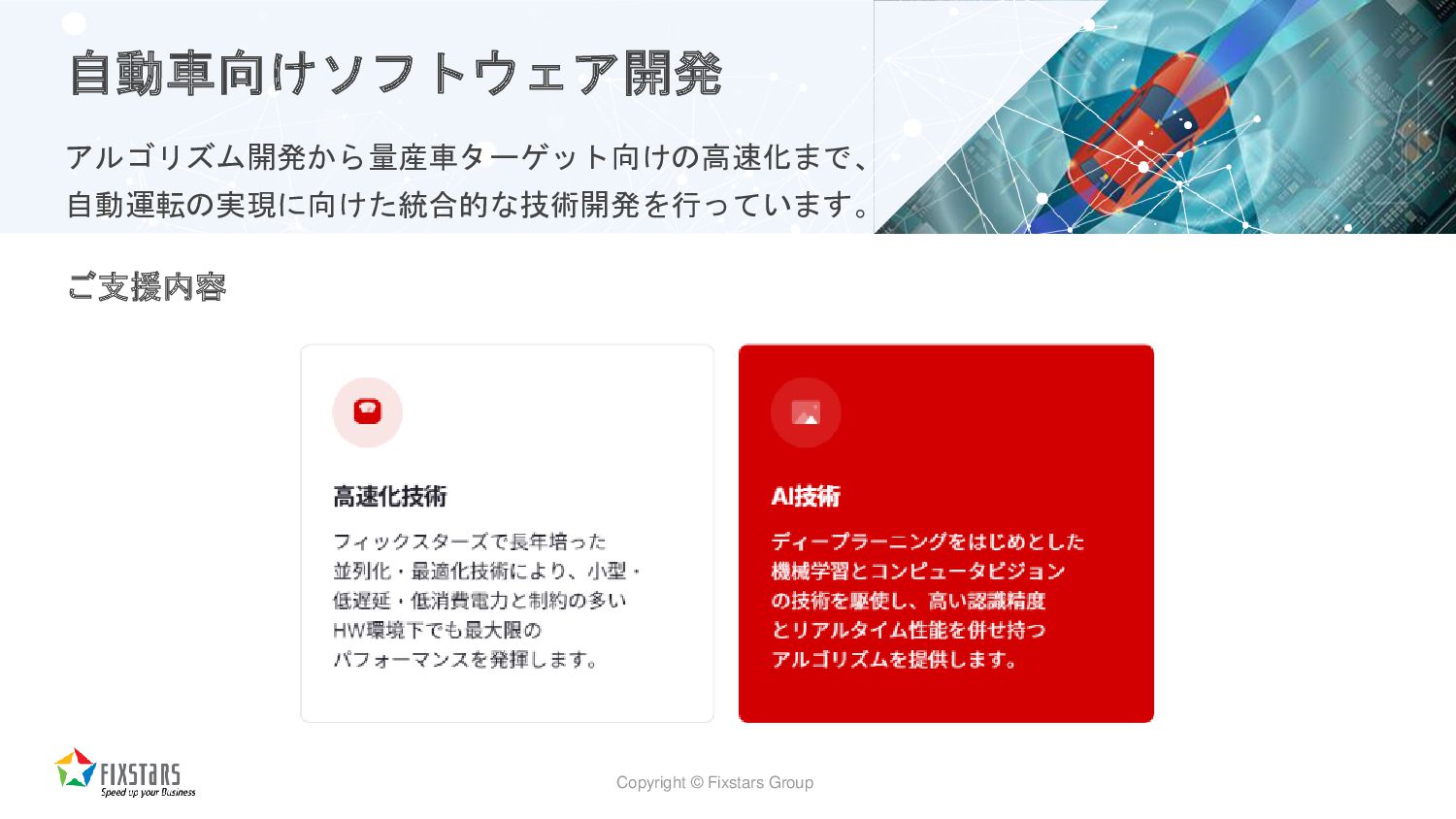{kind=link}
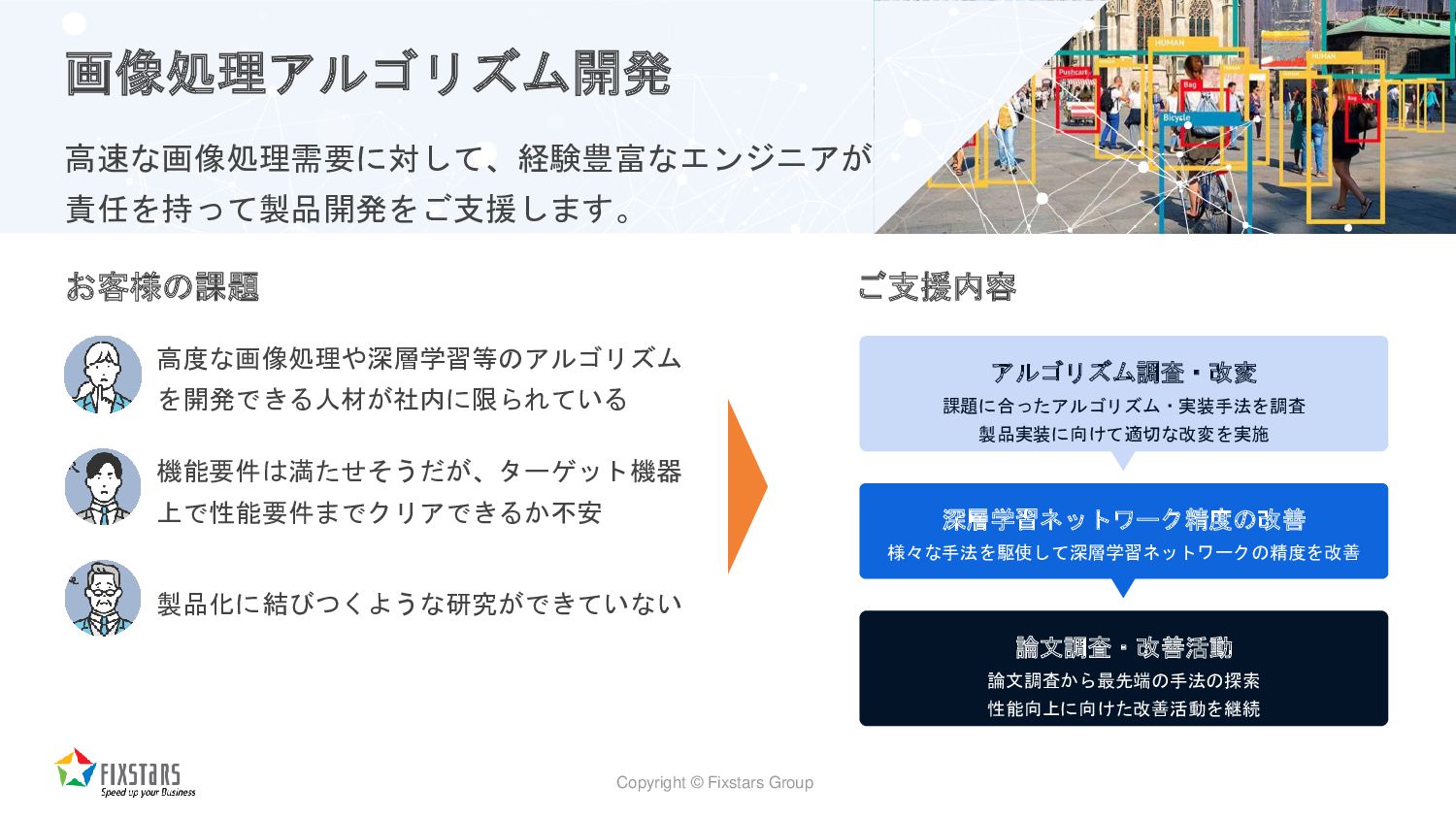{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Copyright © Fixstars Group 変換事例の概要(2) • 前処理 ◦ Float化、[0, 255]→[0.0,](https://files.speakerdeck.com/presentations/b1013a5d7ef349a5866b954ade8f3203/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
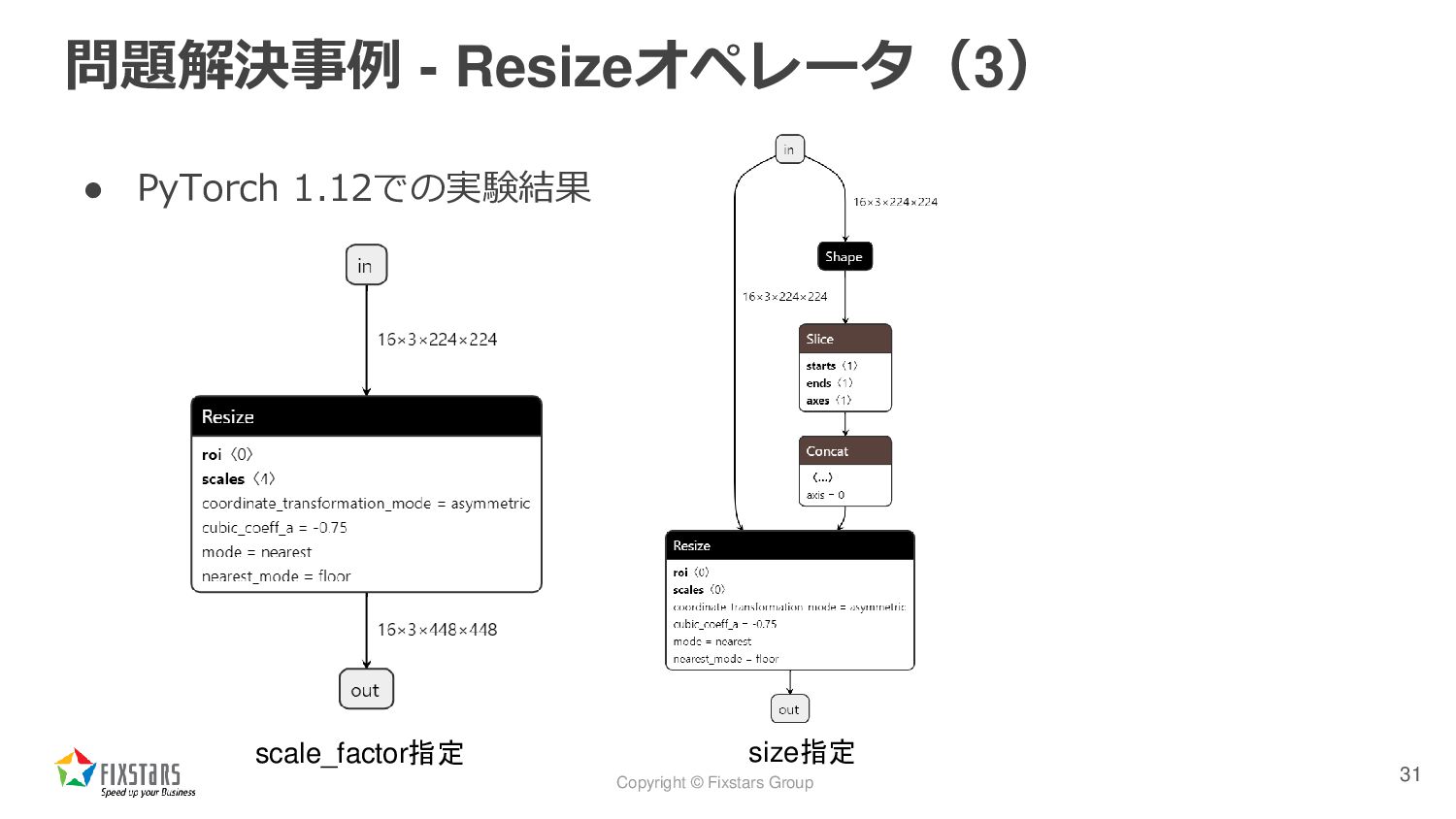{kind=link}
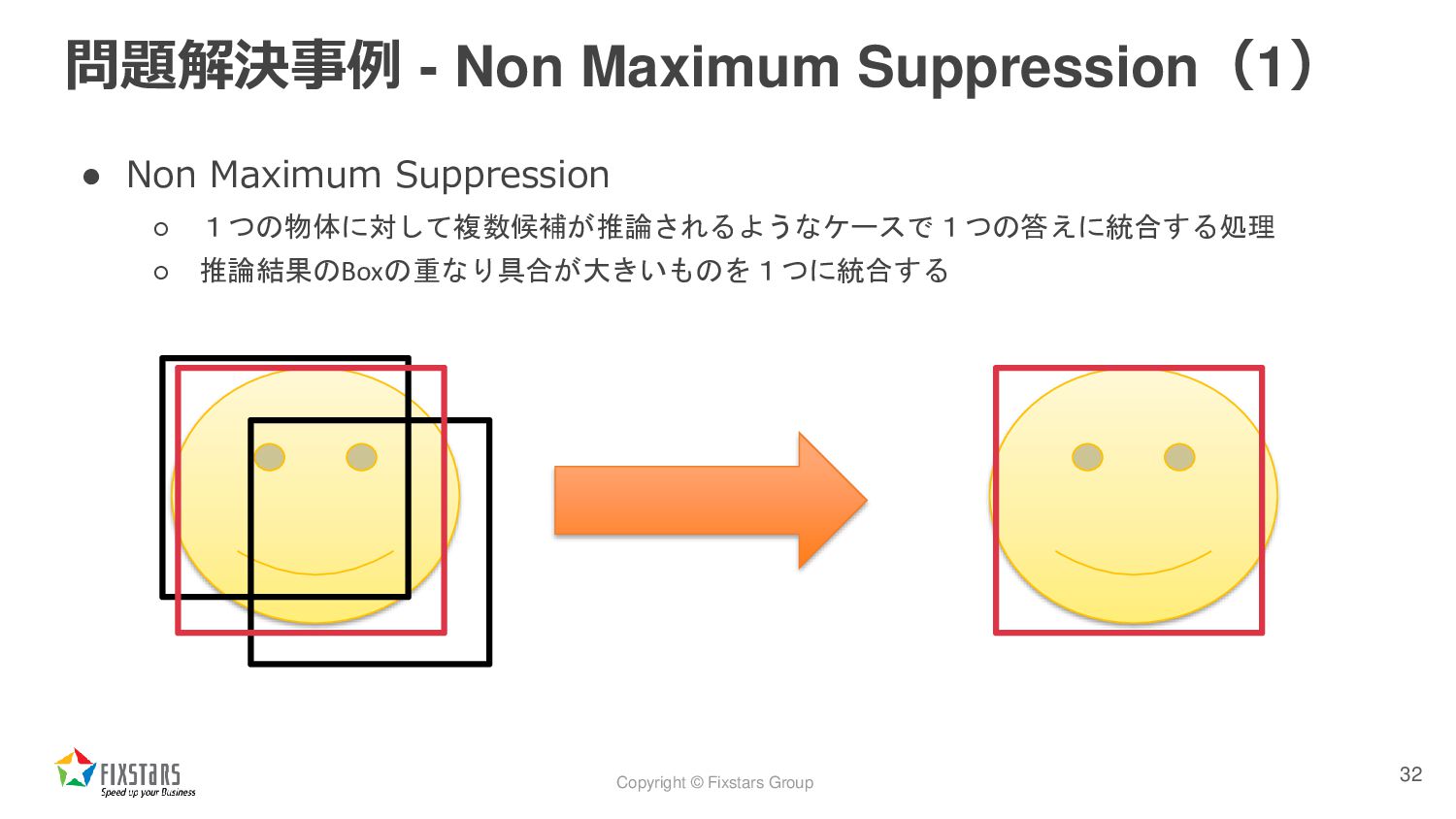{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Copyright © Fixstars Group Thank you! お問い合わせ窓口 : [email protected]](https://files.speakerdeck.com/presentations/b1013a5d7ef349a5866b954ade8f3203/slide_37.jpg){kind=link}