GaussianKernelSimple(単純移植 カーネル) • ループが完全にアンロールされて いる • フィルタの値が命令の即値になっ ている ld.global.u8 %rs6, [%rd8]; cvt.rn.f32.u16 %f11, %rs6; fma.rn.f32 %f12, %f11, 0f3C5A024A, %f10; ld.global.u8 %rs7, [%rd8+1]; cvt.rn.f32.u16 %f13, %rs7; fma.rn.f32 %f14, %f13, 0f3D744317, %f12; ld.global.u8 %rs8, [%rd8+2]; cvt.rn.f32.u16 %f15, %rs8; fma.rn.f32 %f16, %f15, 0f3DC95C2B, %f14; ld.global.u8 %rs9, [%rd8+3]; cvt.rn.f32.u16 %f17, %rs9; fma.rn.f32 %f18, %f17, 0f3D744317, %f16; ld.global.u8 %rs10, [%rd8+4]; cvt.rn.f32.u16 %f19, %rs10; fma.rn.f32 %f20, %f19, 0f3C5A024A, %f18; add.s32 %r15, %r2, 2; mad.lo.s32 %r16, %r15, %r3, %r1; cvt.s64.s32 %rd9, %r16; add.s64 %rd10, %rd3, %rd9; GaussianKernelSimple(単純移植) PTXの一部 45
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
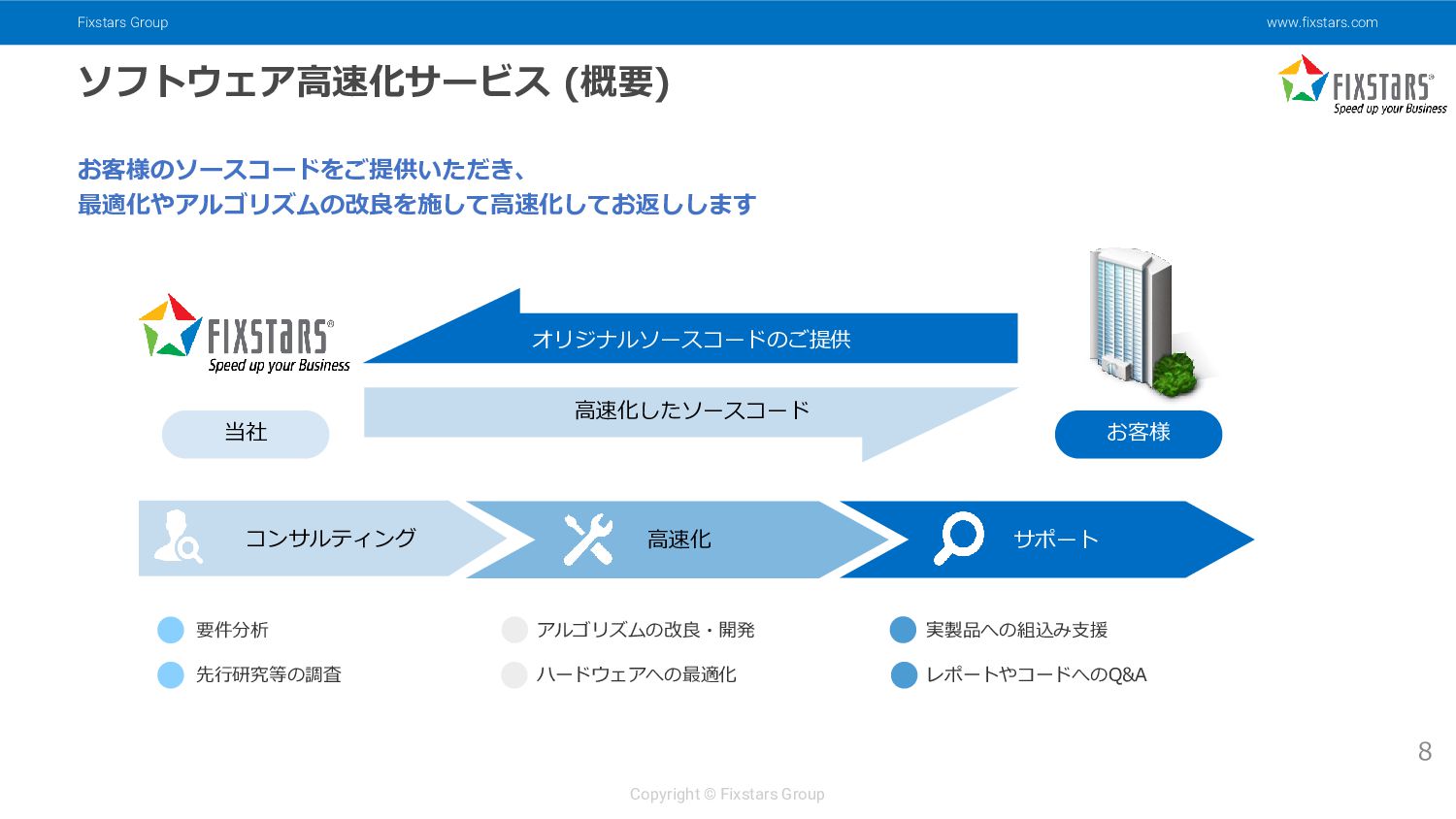{kind=link}
{kind=link}
{kind=link}
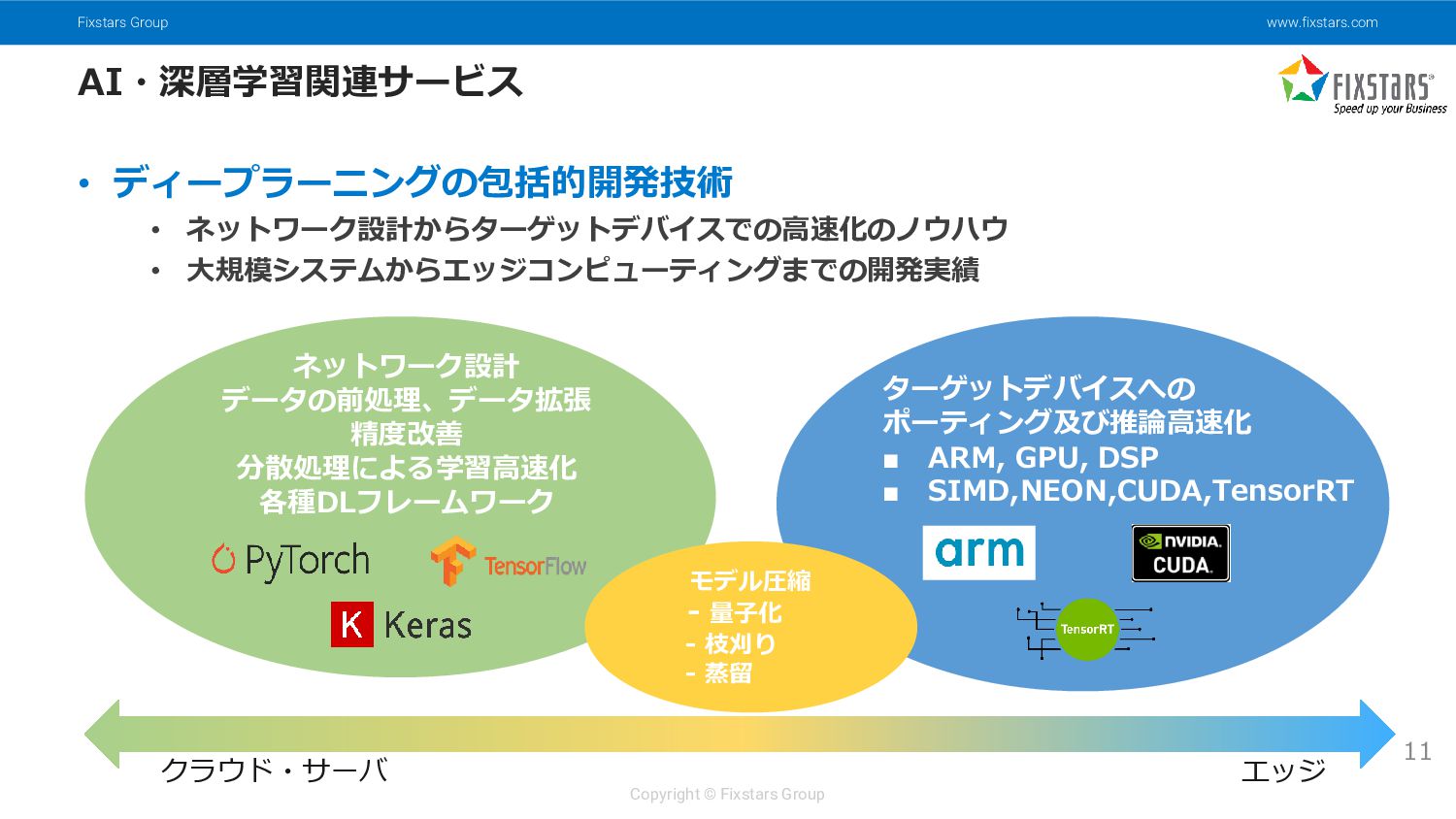{kind=link}
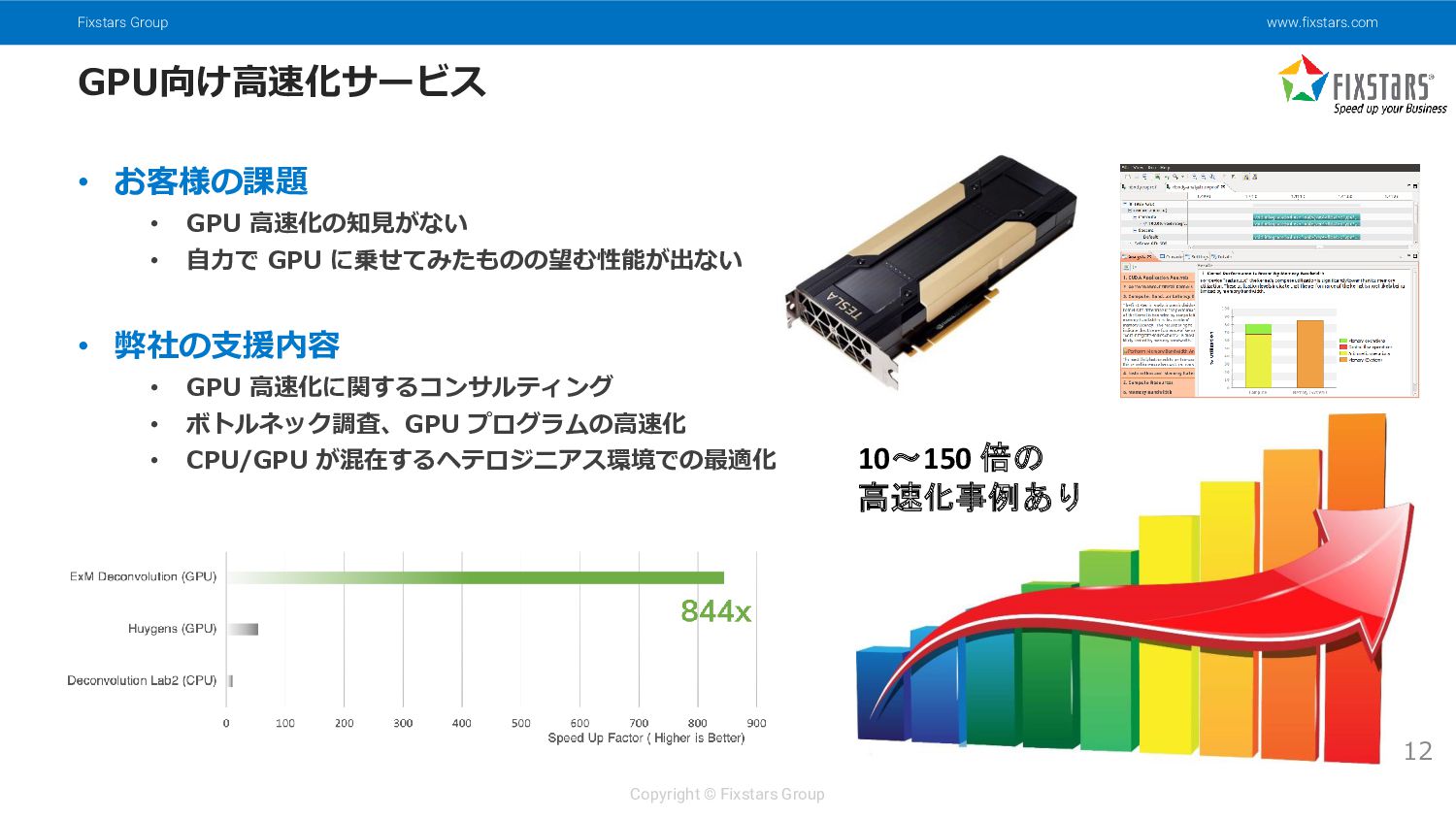{kind=link}
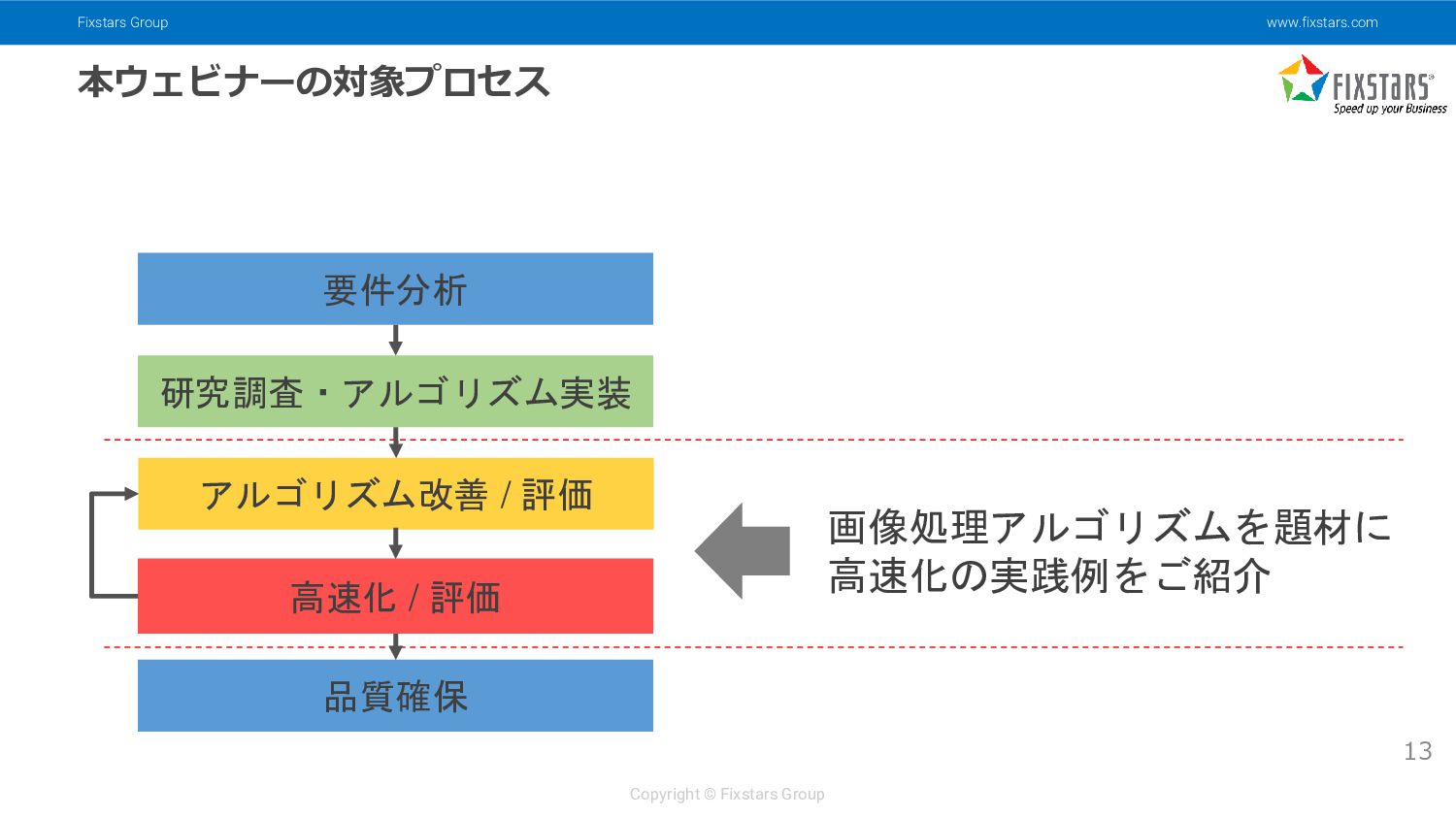{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
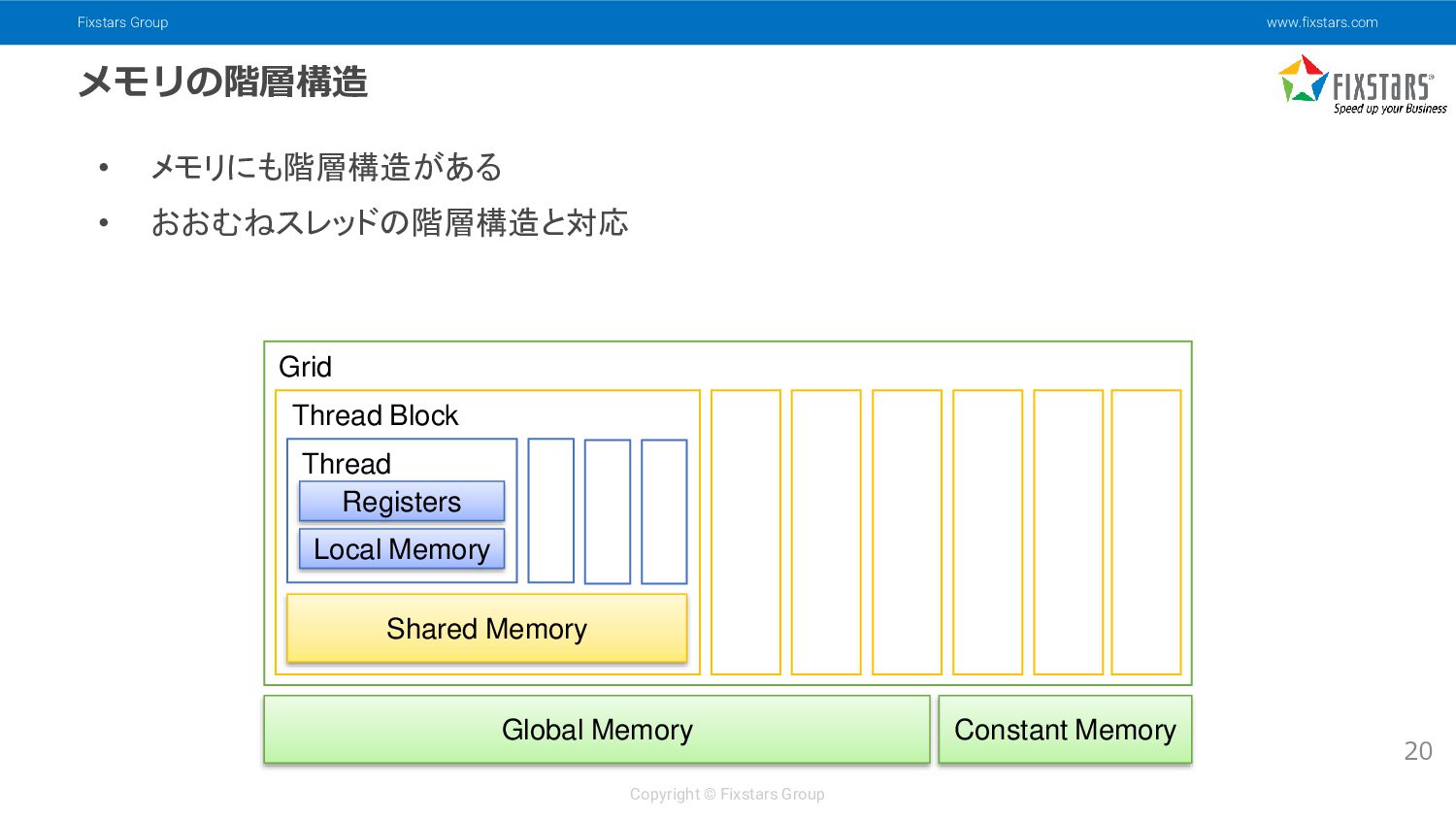{kind=link}
{kind=link}
{kind=link}
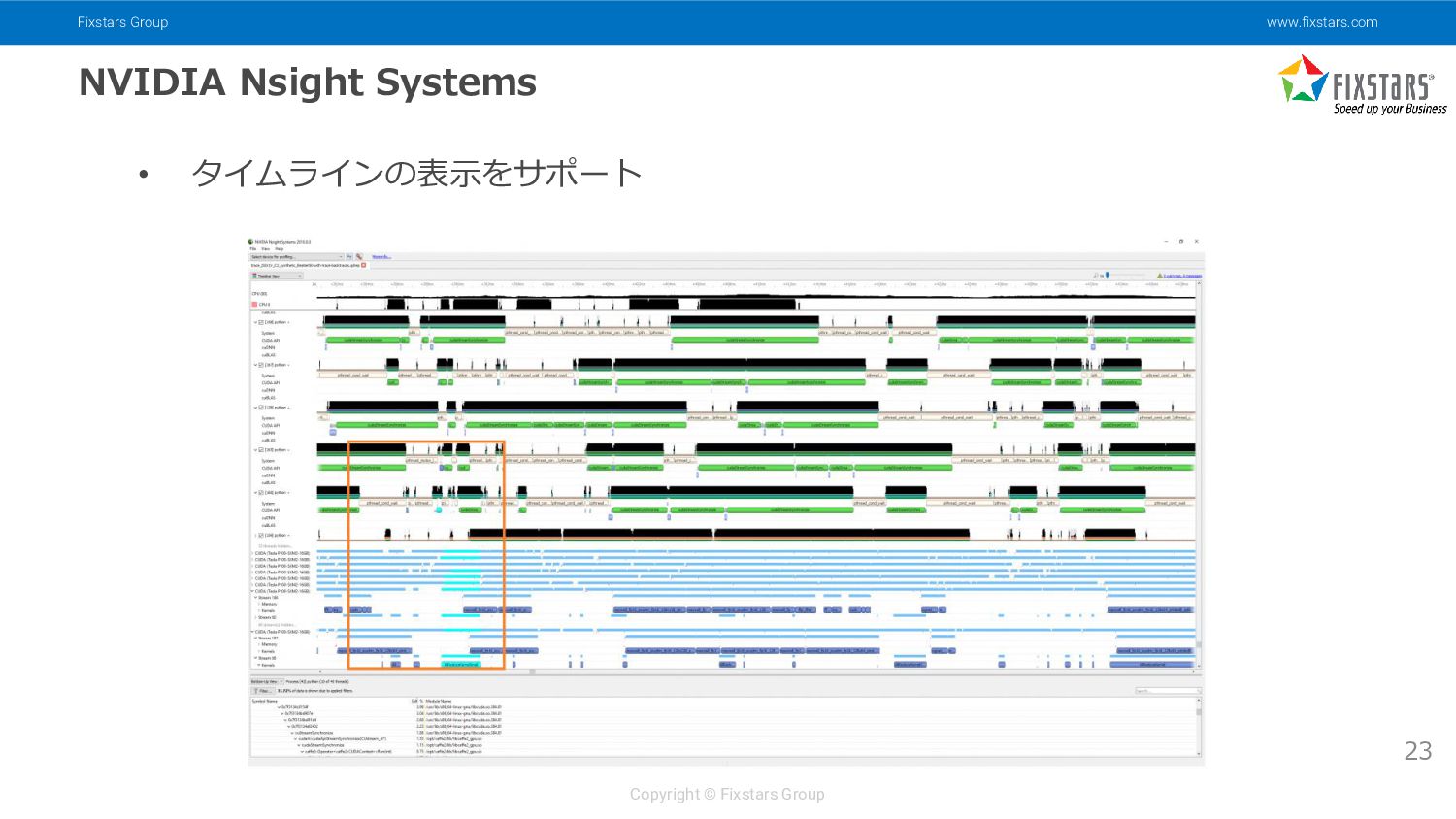{kind=link}
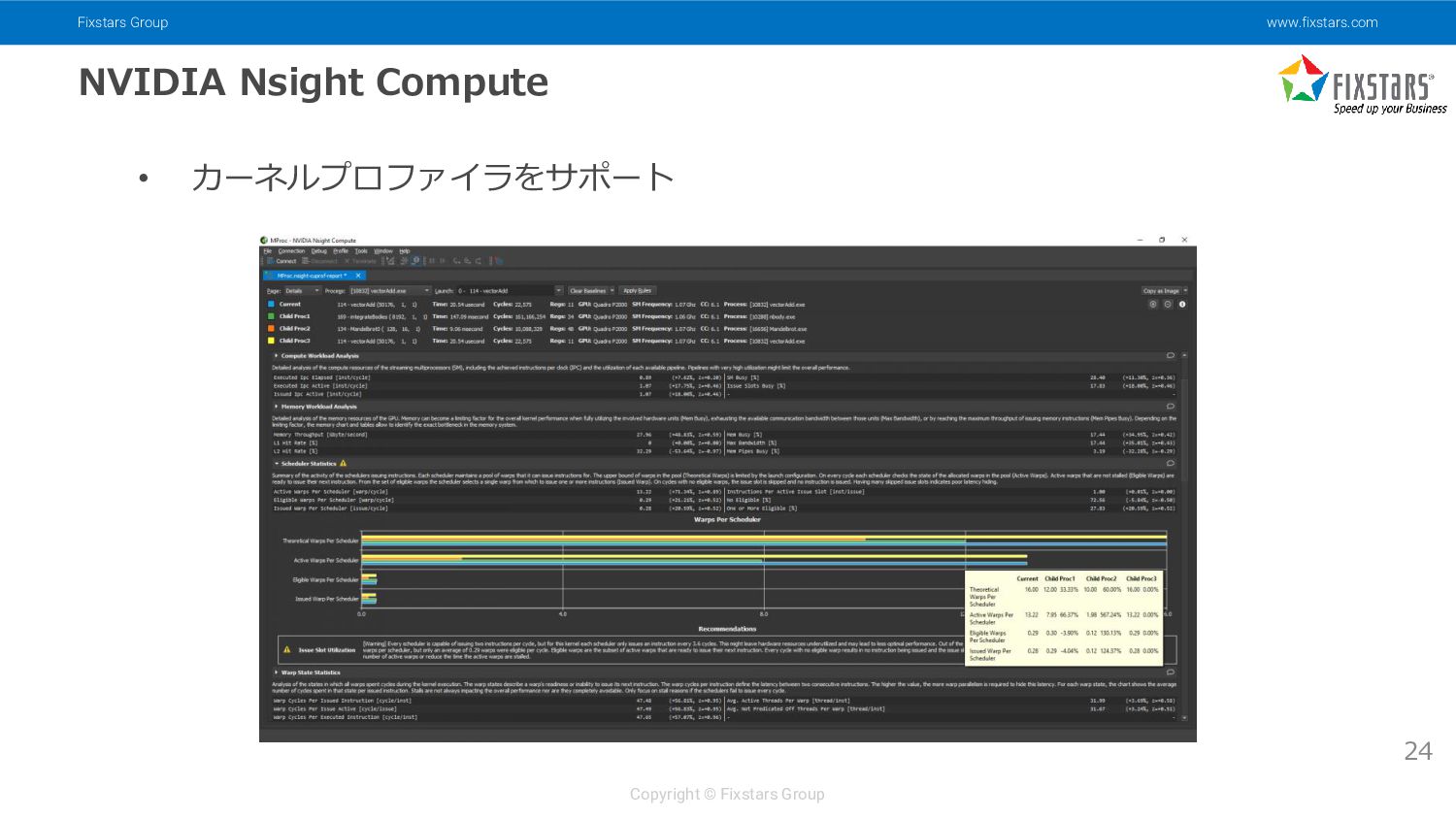{kind=link}
{kind=link}
{kind=link}
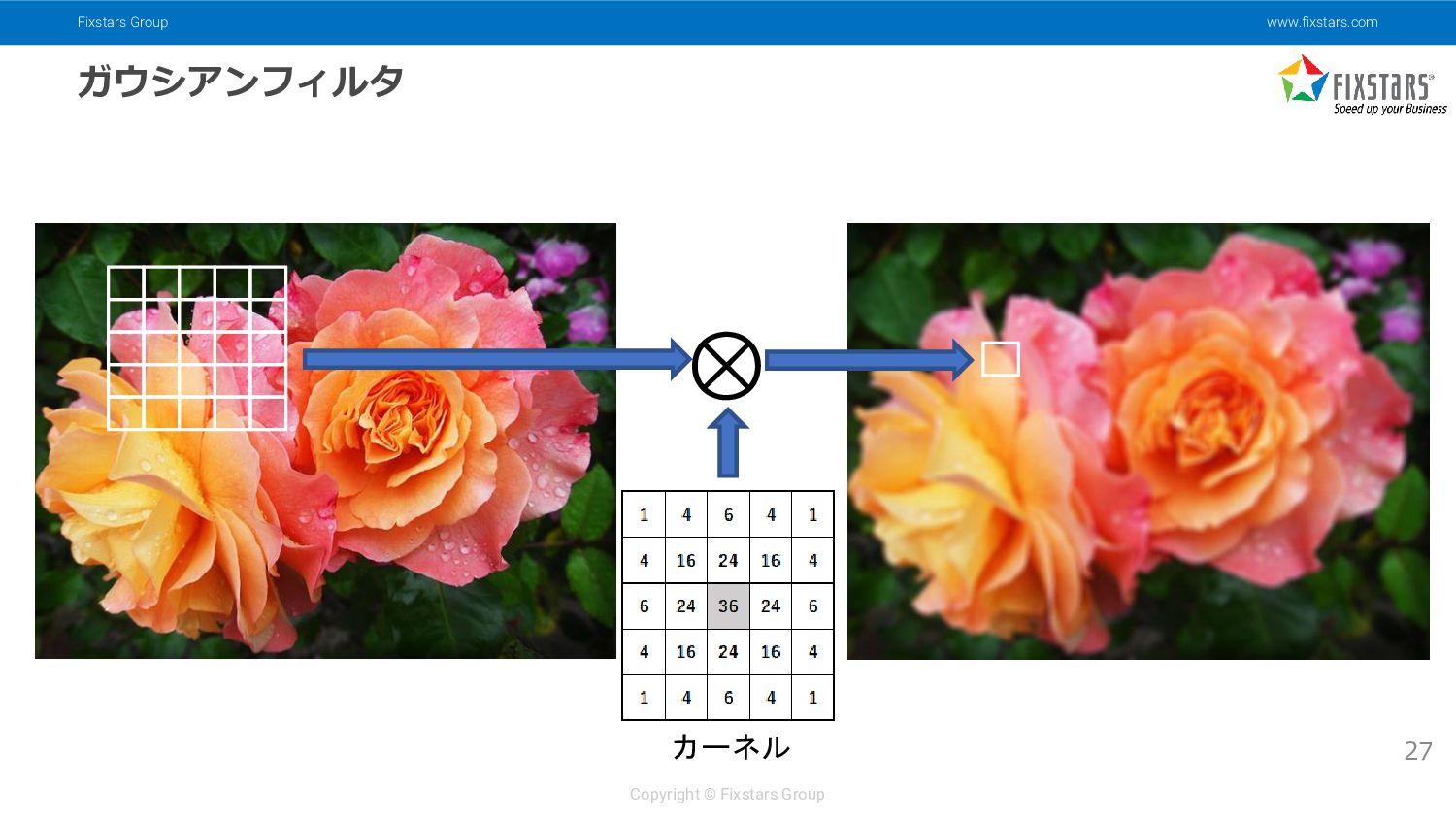{kind=link}
{kind=link}
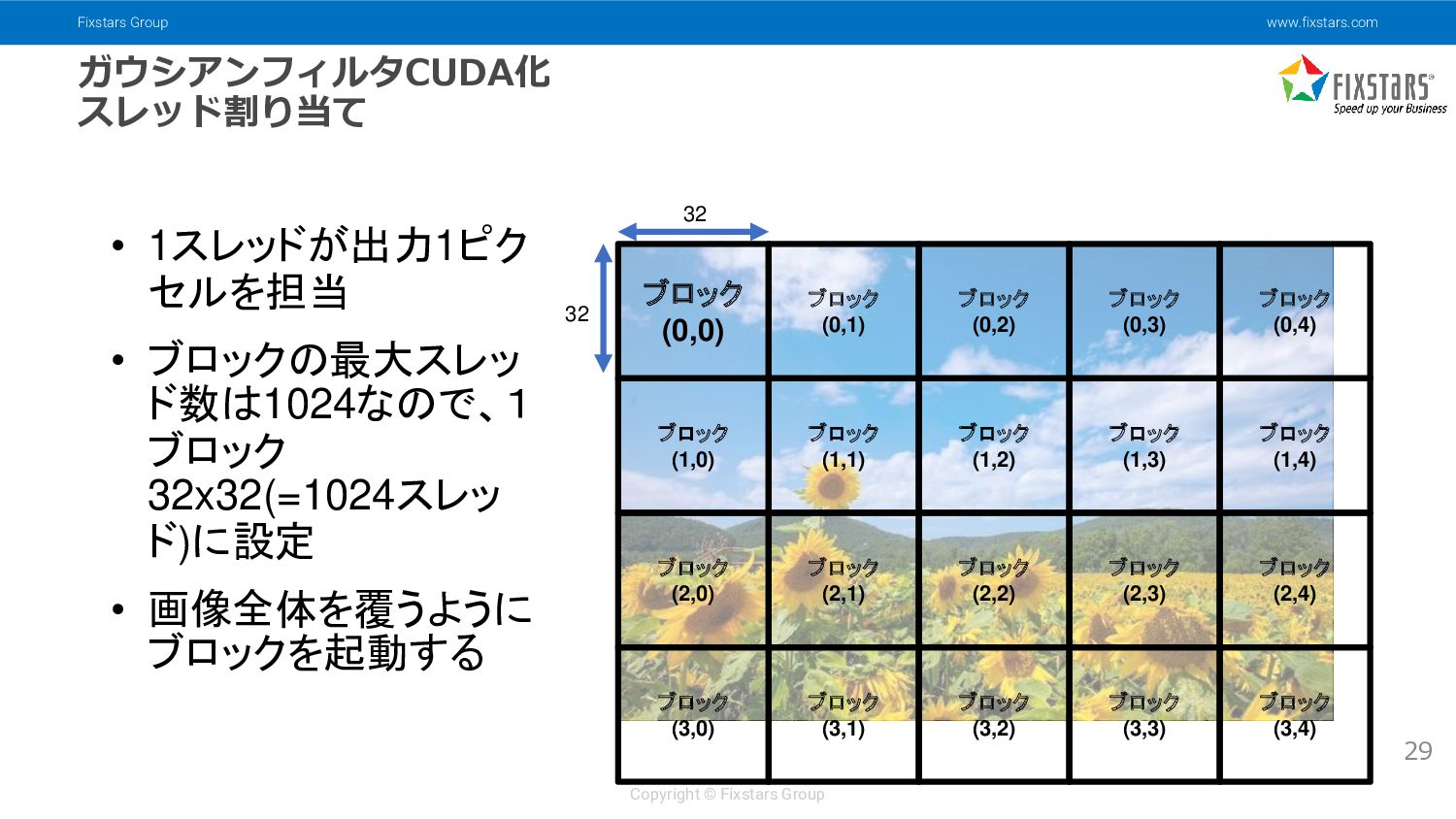{kind=link}
{kind=link}
{kind=link}
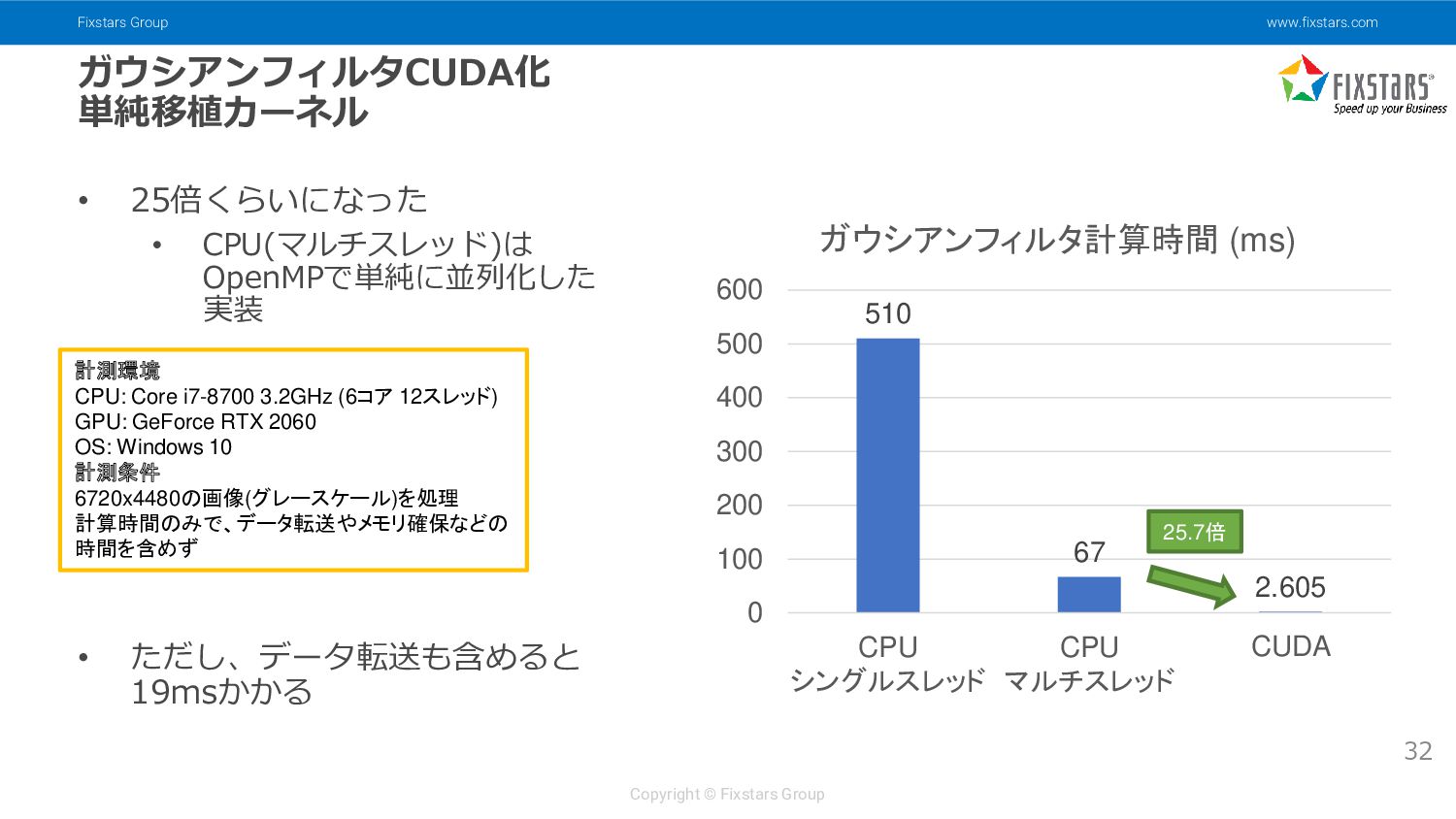{kind=link}
{kind=link}
{kind=link}
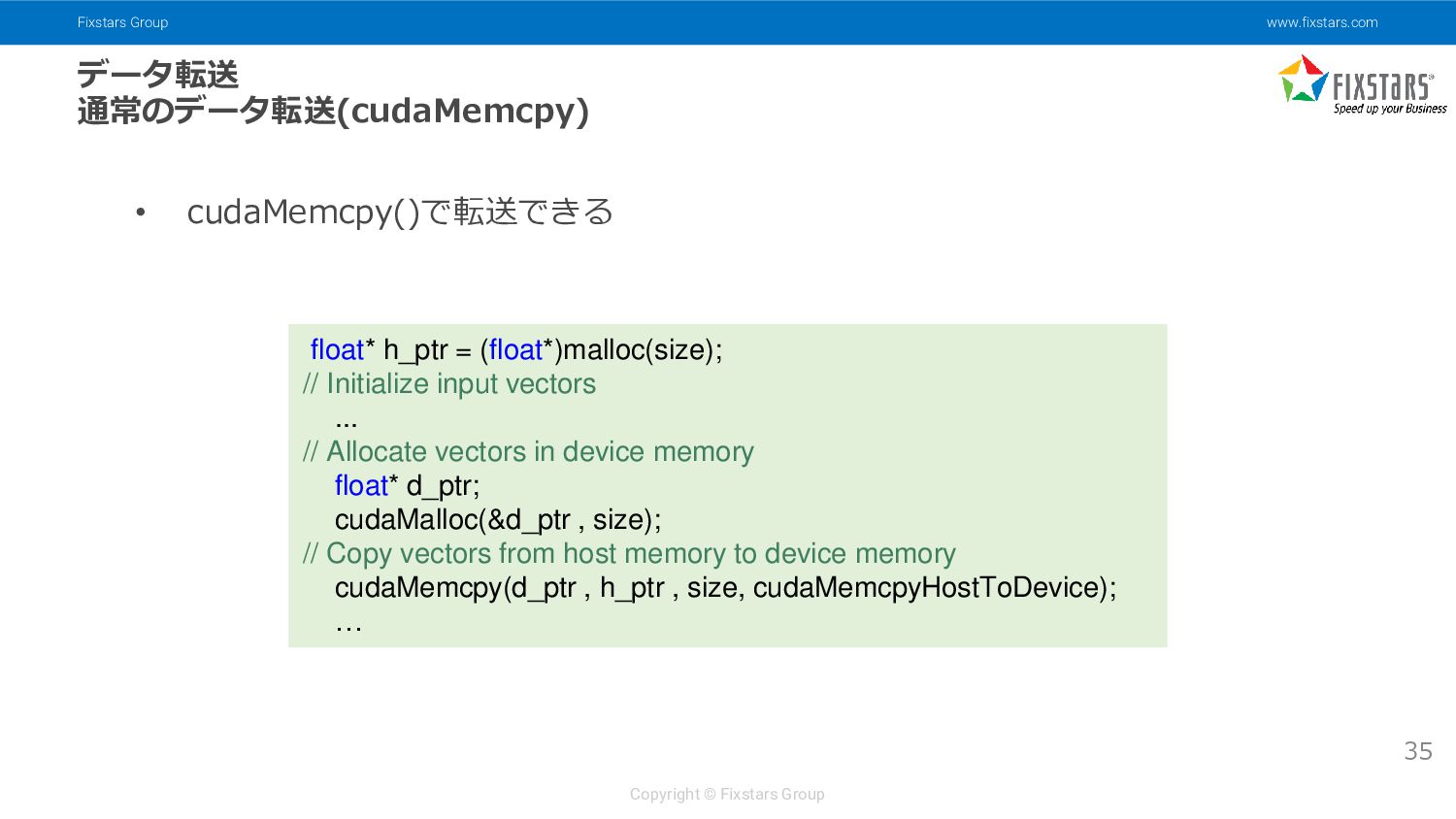{kind=link}
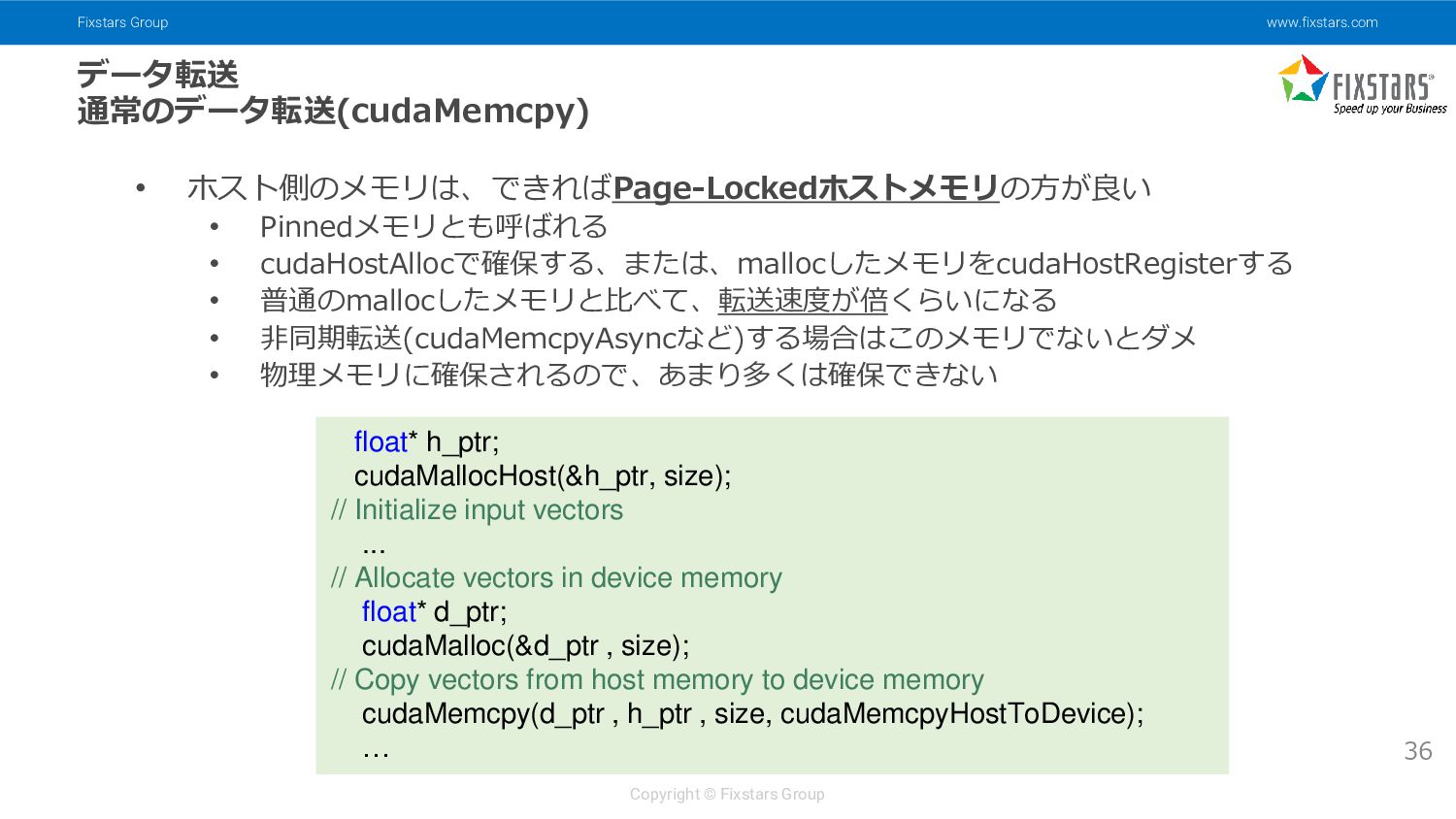{kind=link}
{kind=link}
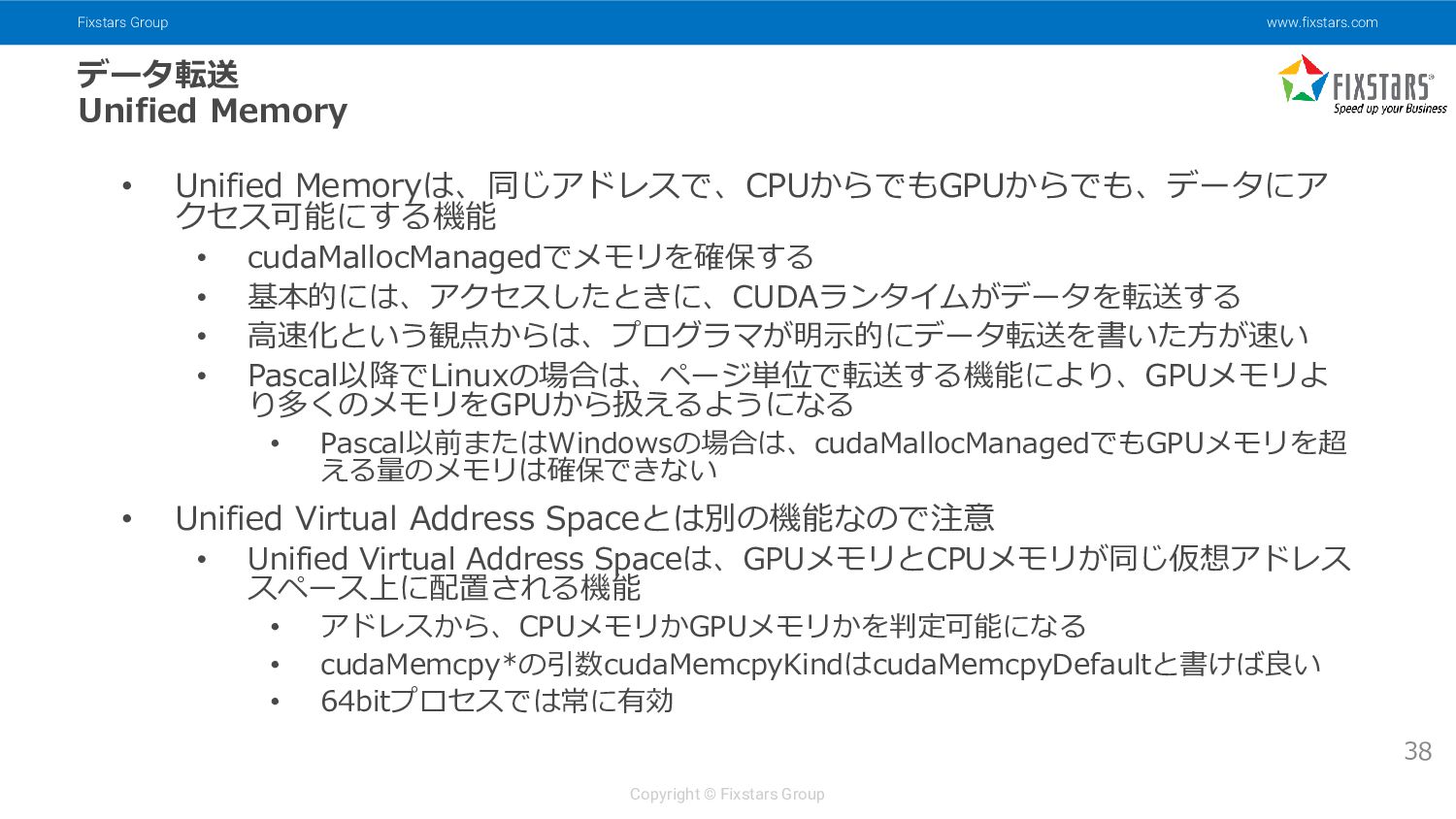{kind=link}
{kind=link}
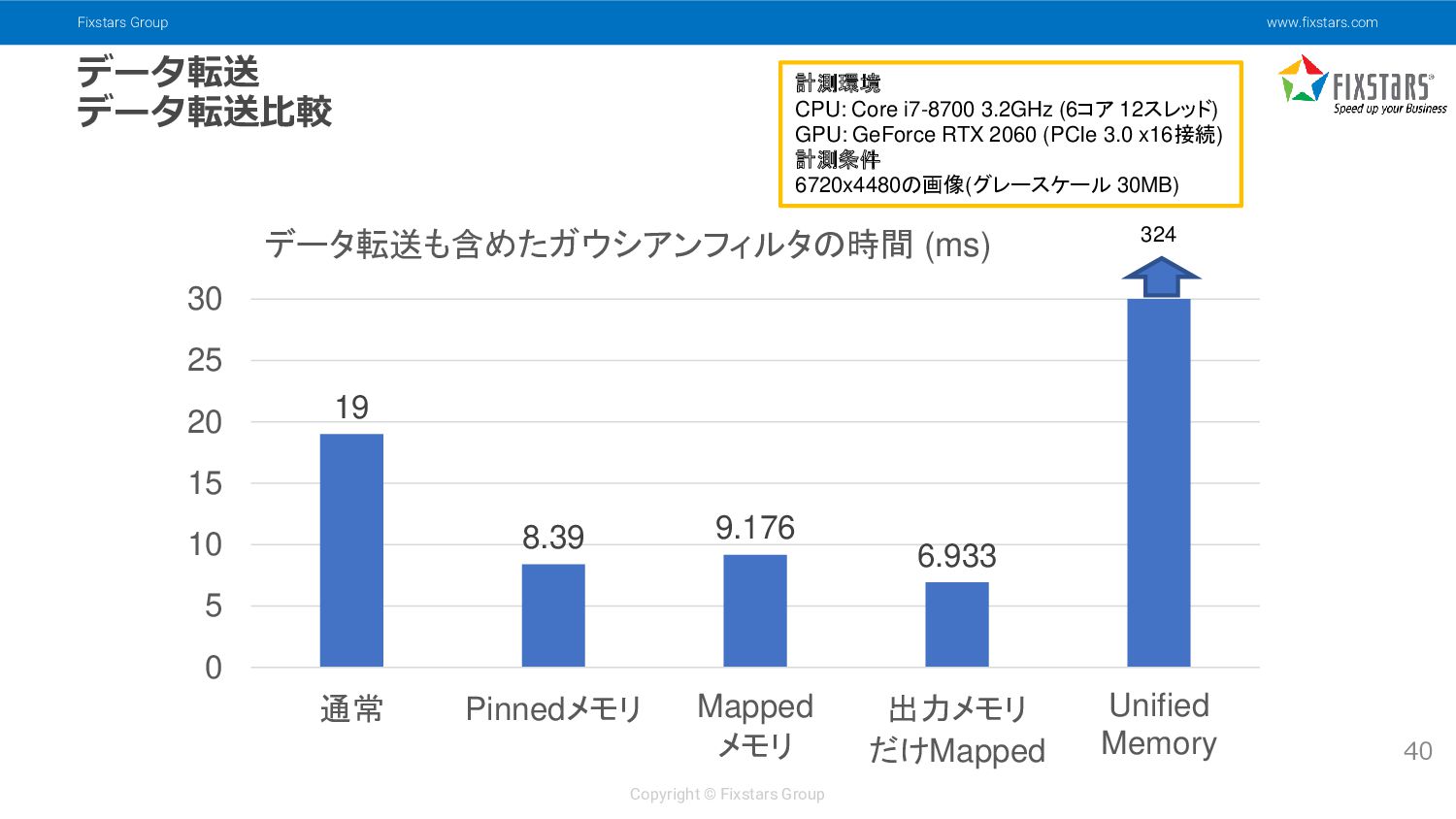{kind=link}
{kind=link}
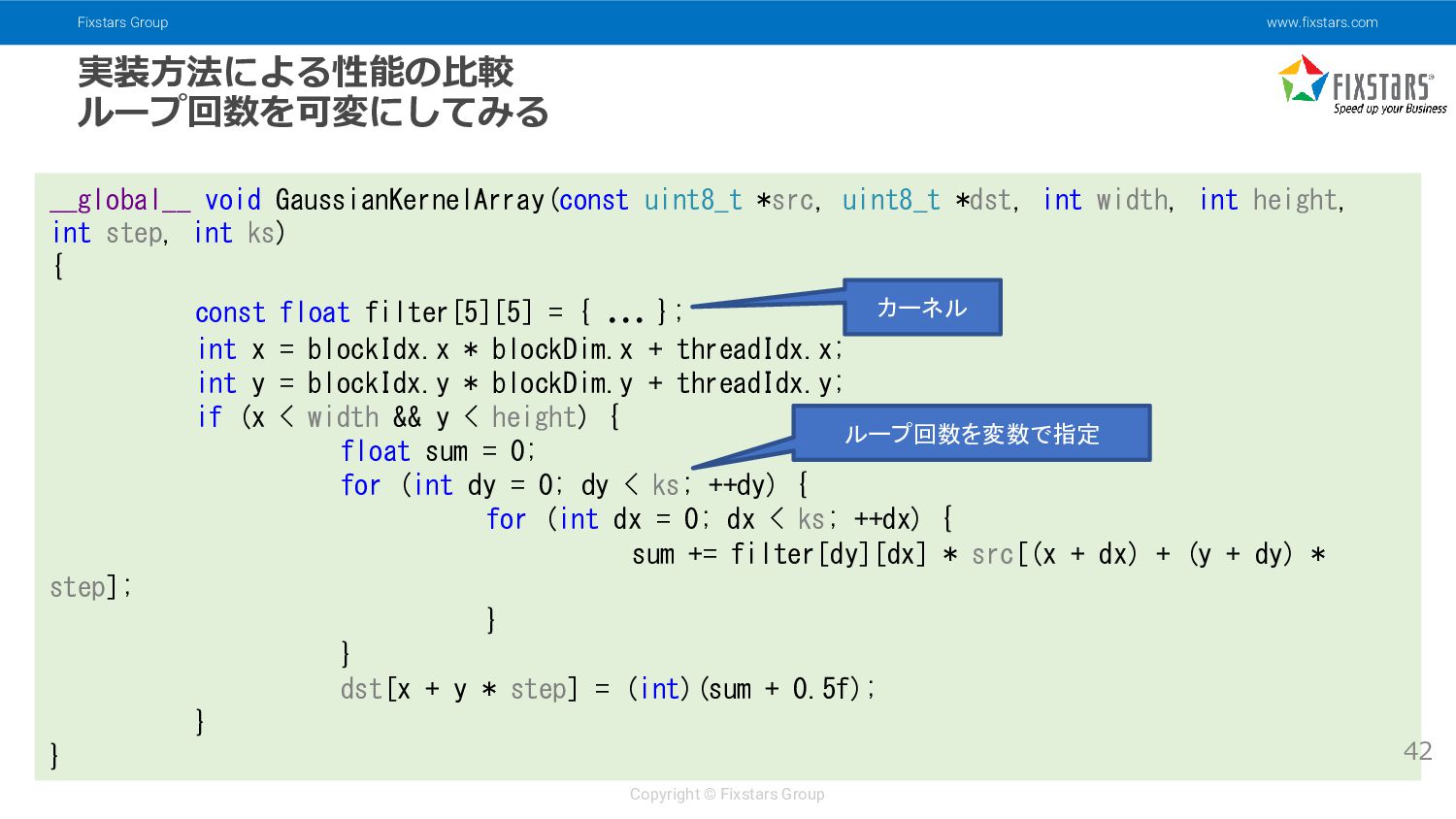{kind=link}
{kind=link}
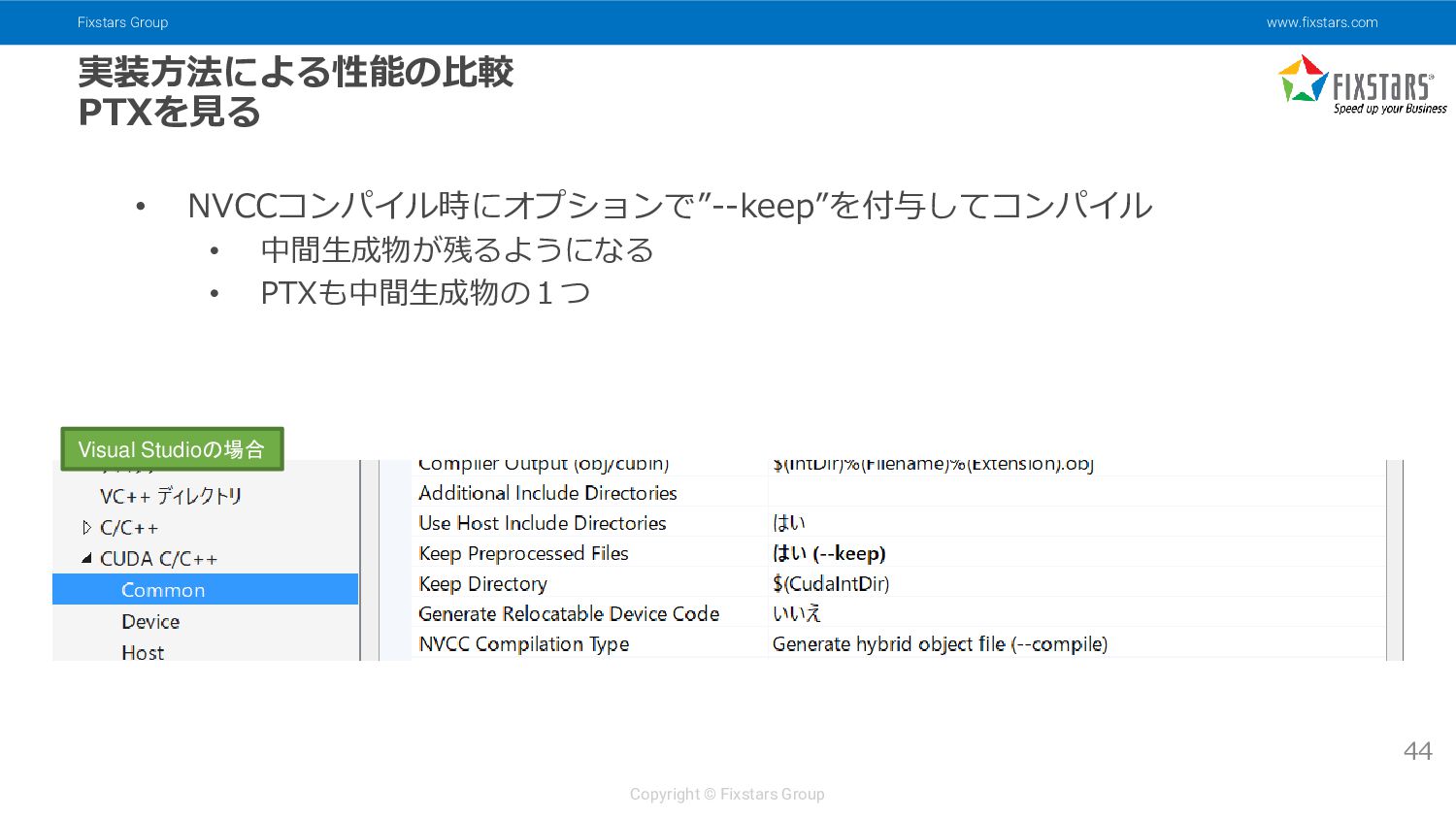{kind=link}
{kind=link}
{kind=link}
{kind=link}
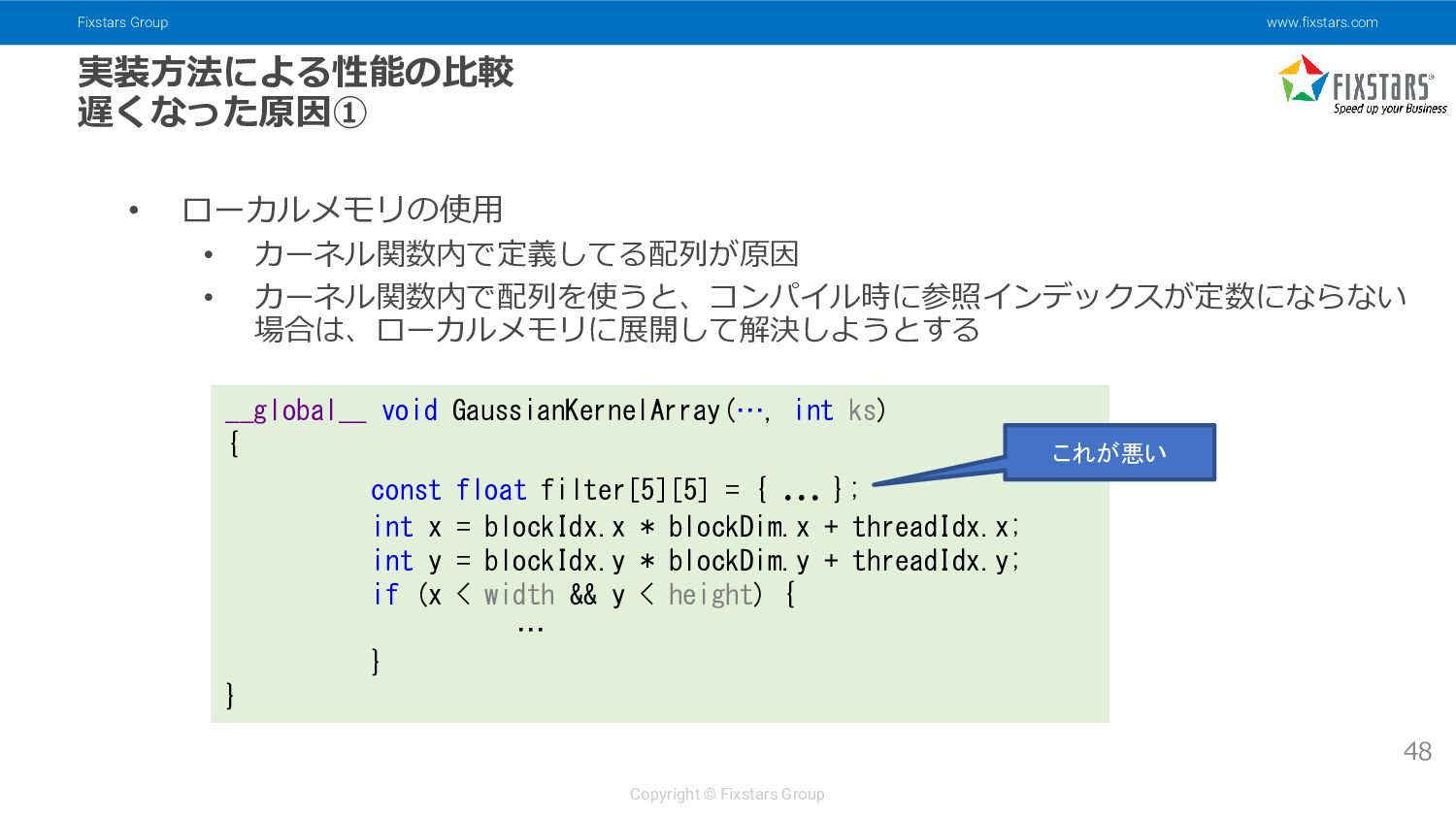{kind=link}
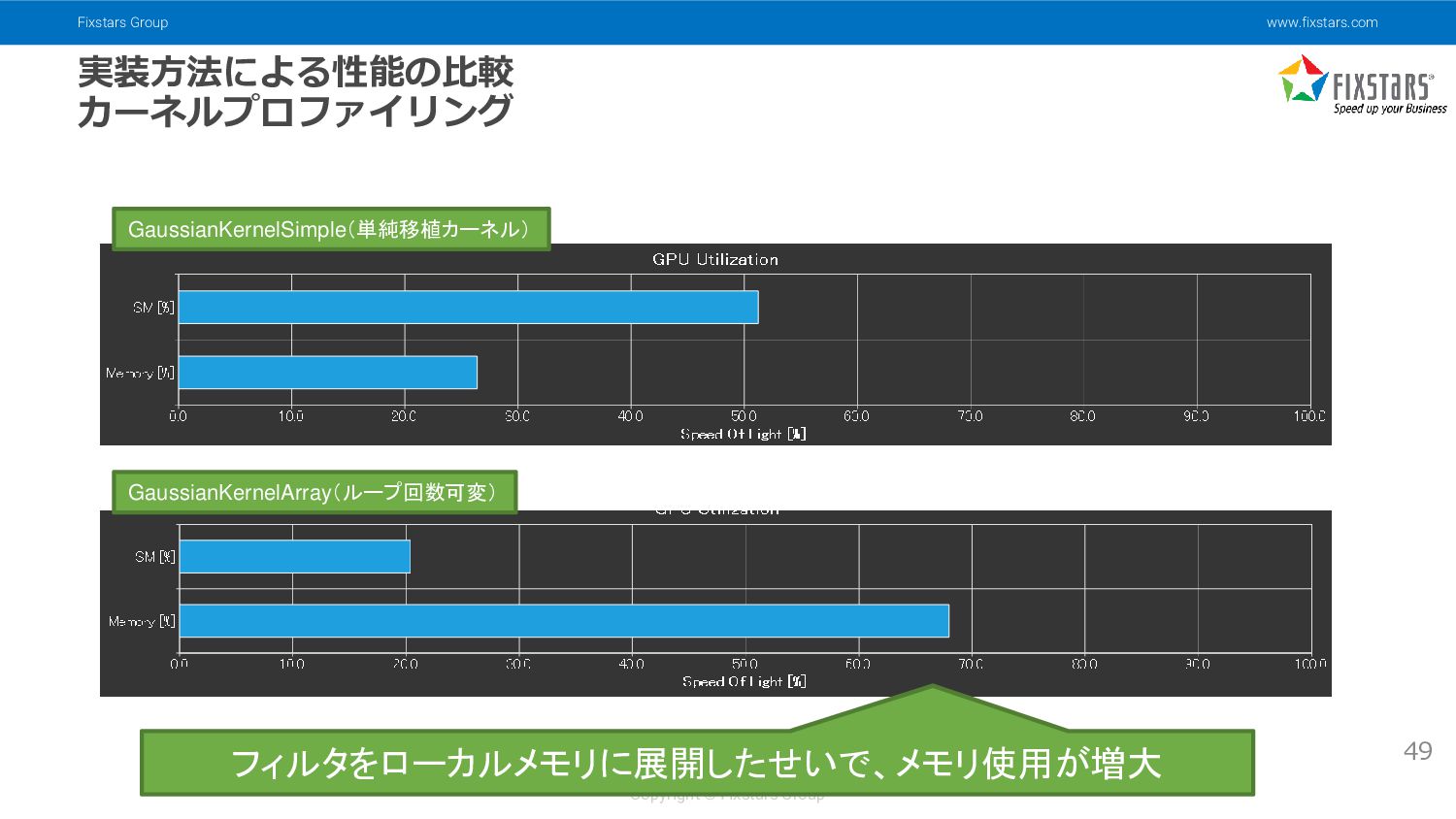{kind=link}
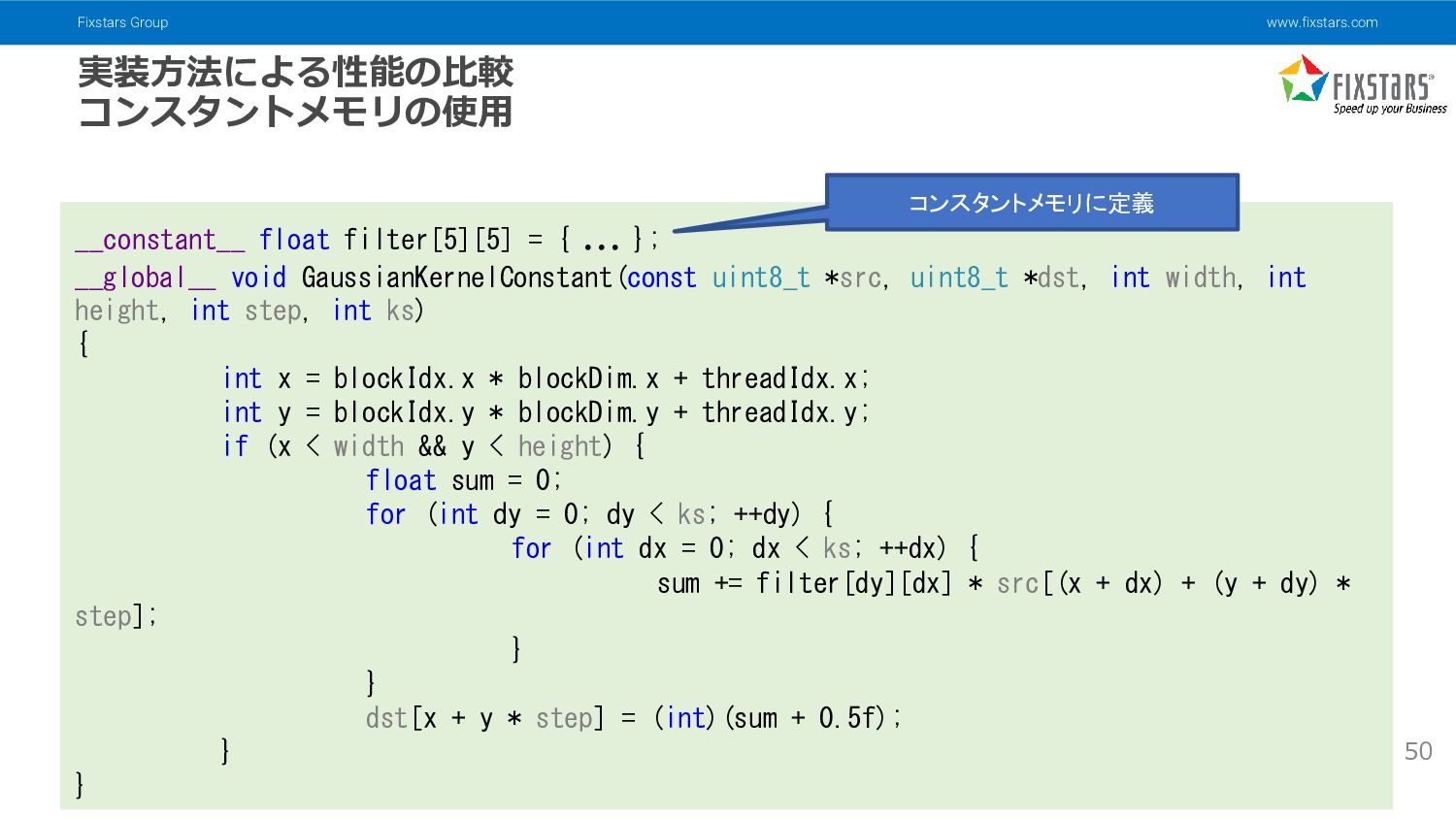{kind=link}
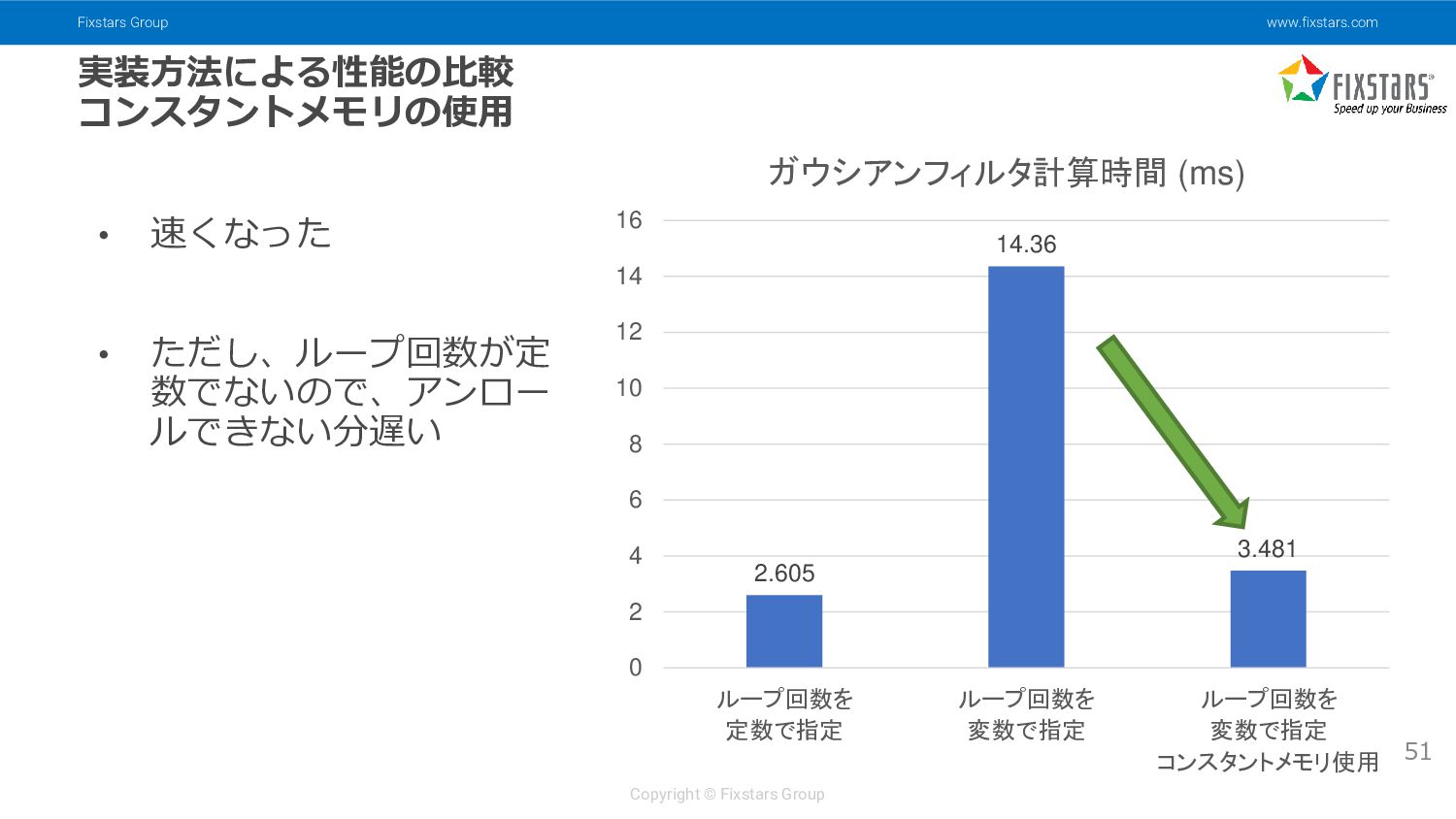{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
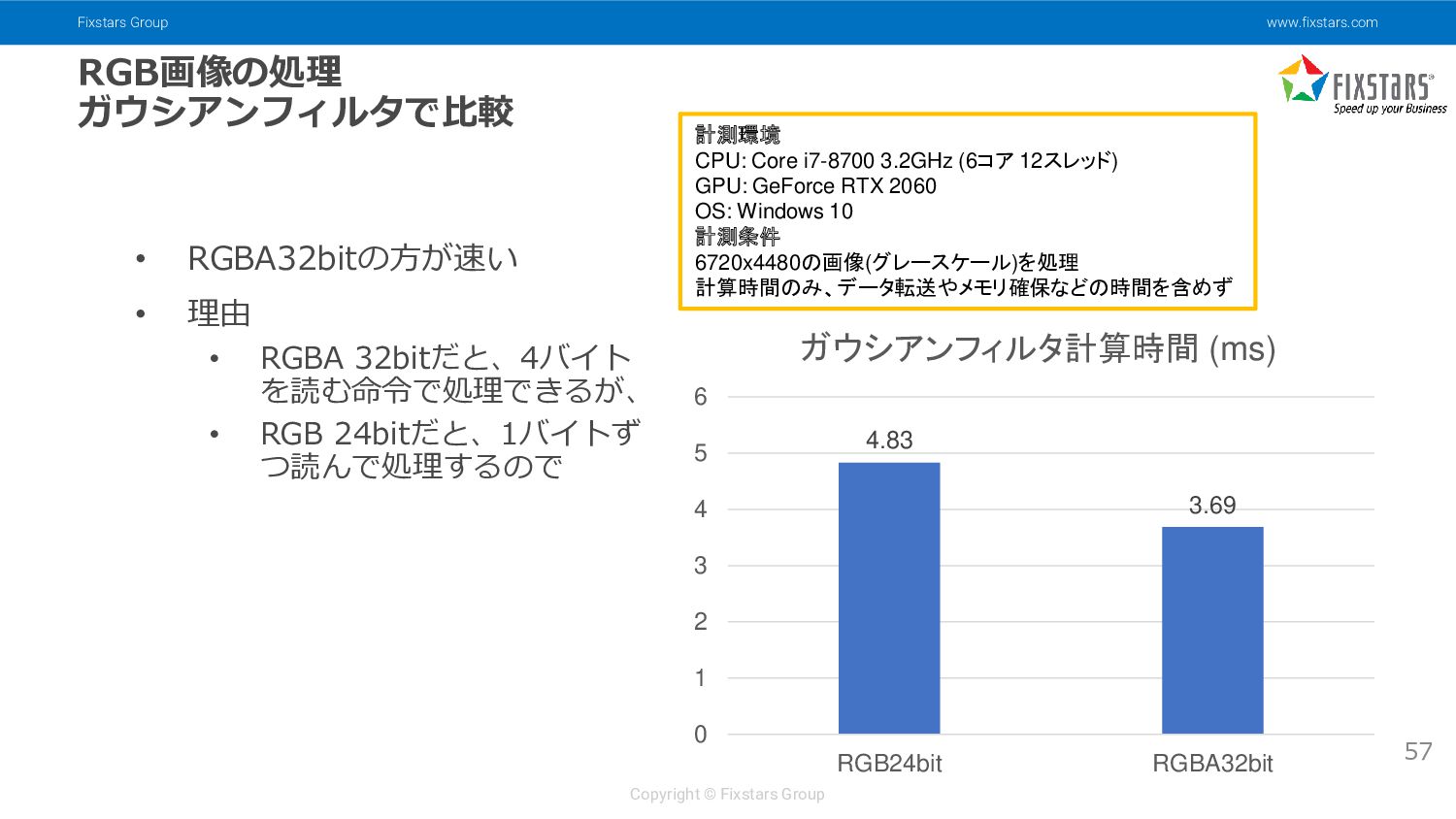{kind=link}
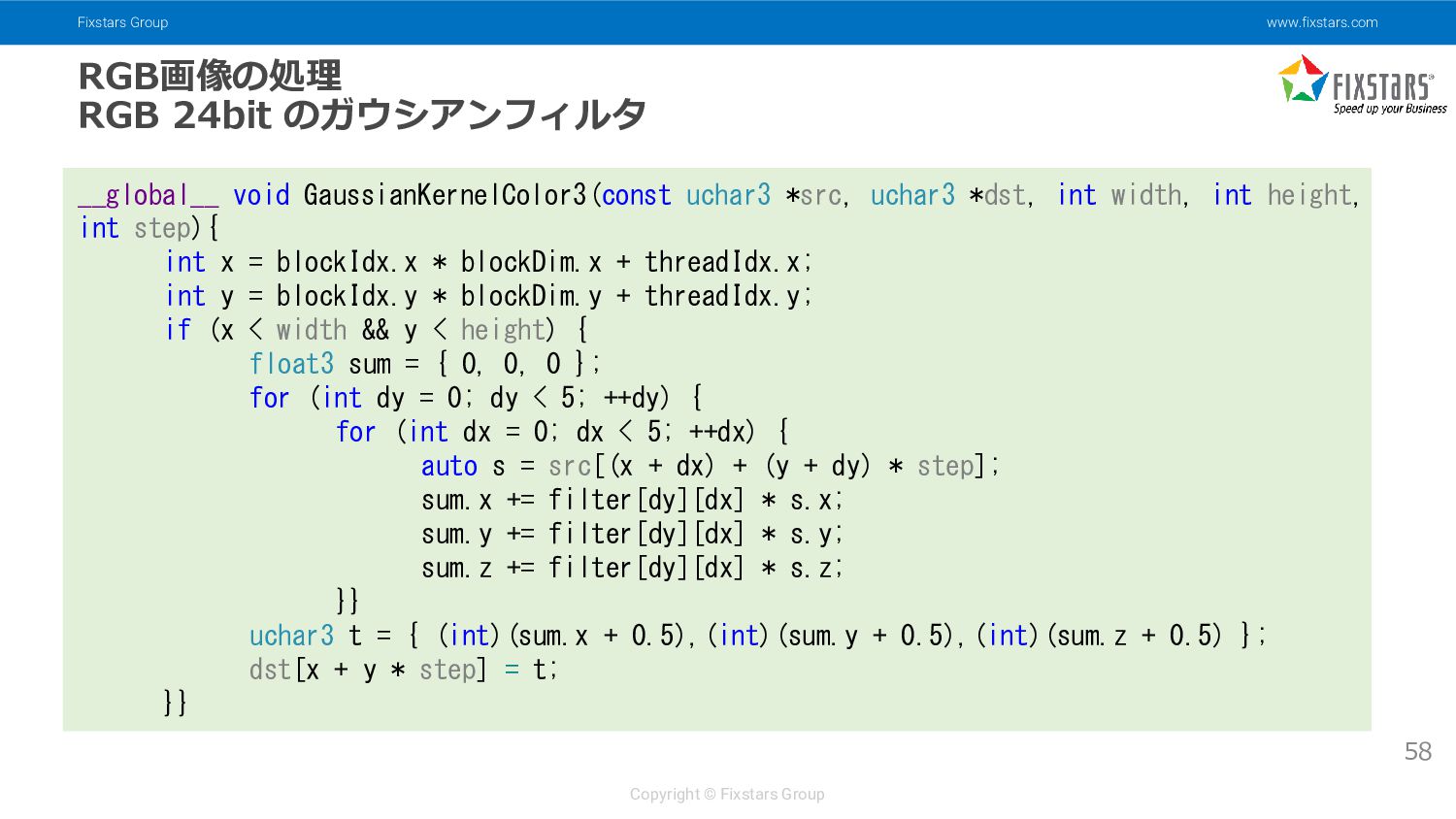{kind=link}
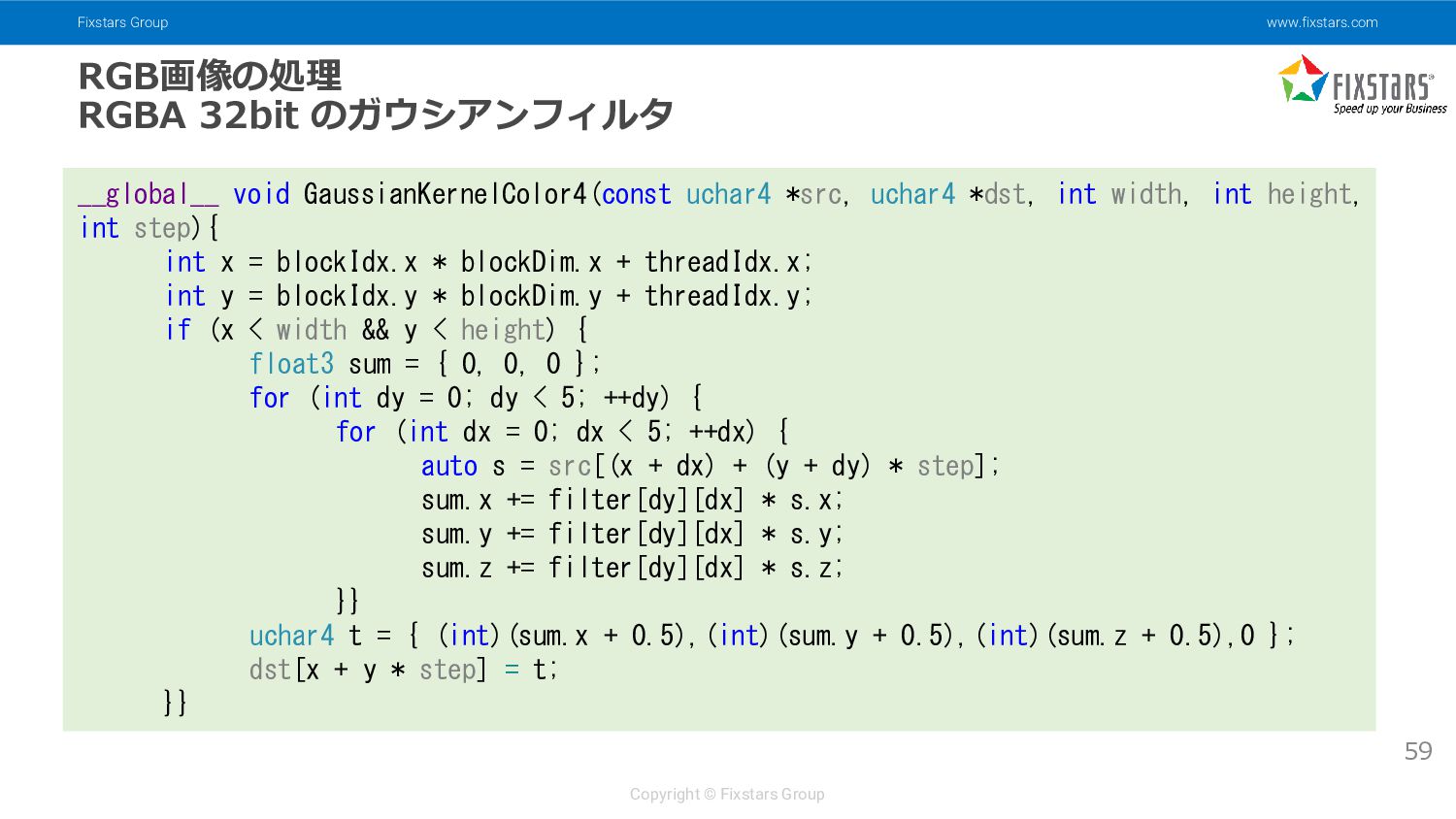{kind=link}
{kind=link}