Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
CUDA高速化セミナーvol.3 ~ソフトウェア高速化と深層学習~
Search
株式会社フィックスターズ
July 29, 2022
Programming
490
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
CUDA高速化セミナーvol.3 ~ソフトウェア高速化と深層学習~
2022年7月28日に開催された「CUDA高速化セミナーvol.3 ~ソフトウェア高速化と深層学習~」の当日資料です。
株式会社フィックスターズ
July 29, 2022
More Decks by 株式会社フィックスターズ
See All by 株式会社フィックスターズ
コンピュータービジョンセミナー5 / 3次元復元アルゴリズム Multi-View Stereo の CUDA高速化
fixstars
0
1.2k
Kaggle_スコアアップセミナー_DFL-Bundesliga_Data_Shootout編/Kaggle_fixstars_corporation_20230509
fixstars
1
1.2k
実践的!FPGA開発セミナーvol.21 / FPGA_seminar_21_fixstars_corporation_20230426
fixstars
0
1.6k
量子コンピュータ時代のプログラミングセミナー / 20230413_Amplify_seminar_shift_optimization
fixstars
0
1.2k
実践的!FPGA開発セミナーvol.18 / FPGA_seminar_18_fixstars_corporation_20230125
fixstars
0
1k
実践的!FPGA開発セミナーvol.19 / FPGA_seminar_19_fixstars_corporation_20230222
fixstars
0
1.1k
実践的!FPGA開発セミナーvol.20 / FPGA_seminar_20_fixstars_corporation_20230329
fixstars
0
950
量子コンピュータ時代のプログラミングセミナー / 20230316_Amplify_seminar _route_planning_optimization
fixstars
0
920
量子コンピュータ時代のプログラミングセミナー / 20230216_Amplify_seminar _production_planning_optimization
fixstars
0
800
Other Decks in Programming
See All in Programming
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
500
エンジニアにデザインハーネスを 〜デザインプロセスを規定するためのハーネス〜 / Design harness from an engineer's perspective
rkaga
2
1.5k
そのテスト、説明できますか?~LWテスト戦略FW~のご紹介
nakahara
0
210
なぜ関数型プログラミングで「型」と「証明」が語られるのか #fp_matsuri
kajitack
3
950
Generative UI & AI-Assistants for Your Angular Solutions
manfredsteyer
PRO
0
110
「正の参照」と 「負の導出」で組む ハーネスエンジニアリング
cottpan
1
140
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
180
OSINT for SRE: 学術論文とポストモーテムから探る システム障害の共通パターン / SRE NEXT 2026
tomoyk
1
3.8k
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
170
【やさしく解説 設計編 #1】「ドメイン駆動」と「実装駆動」ってなに? 〜設計の考え方を、たとえ話で学ぼう〜
panda728
PRO
1
120
関数型プログラミングのメリットって何だろう?
wanko_it
0
180
PHP Application における Kubernetes 内 gRPC 通信
ganchiku
0
490
Featured
See All Featured
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
Embracing the Ebb and Flow
colly
88
5.1k
Navigating Weather and Climate Data
rabernat
0
370
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
530
職位にかかわらず全員がリーダーシップを発揮するチーム作り / Building a team where everyone can demonstrate leadership regardless of position
madoxten
64
56k
We Are The Robots
honzajavorek
0
280
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Making Projects Easy
brettharned
120
6.7k
The Psychology of Web Performance [Beyond Tellerrand 2023]
tammyeverts
49
3.5k
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
340
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Transcript
Copyright © Fixstars Group CUDA 高速化セミナー vol.3 ソフトウェア高速化と深層学習
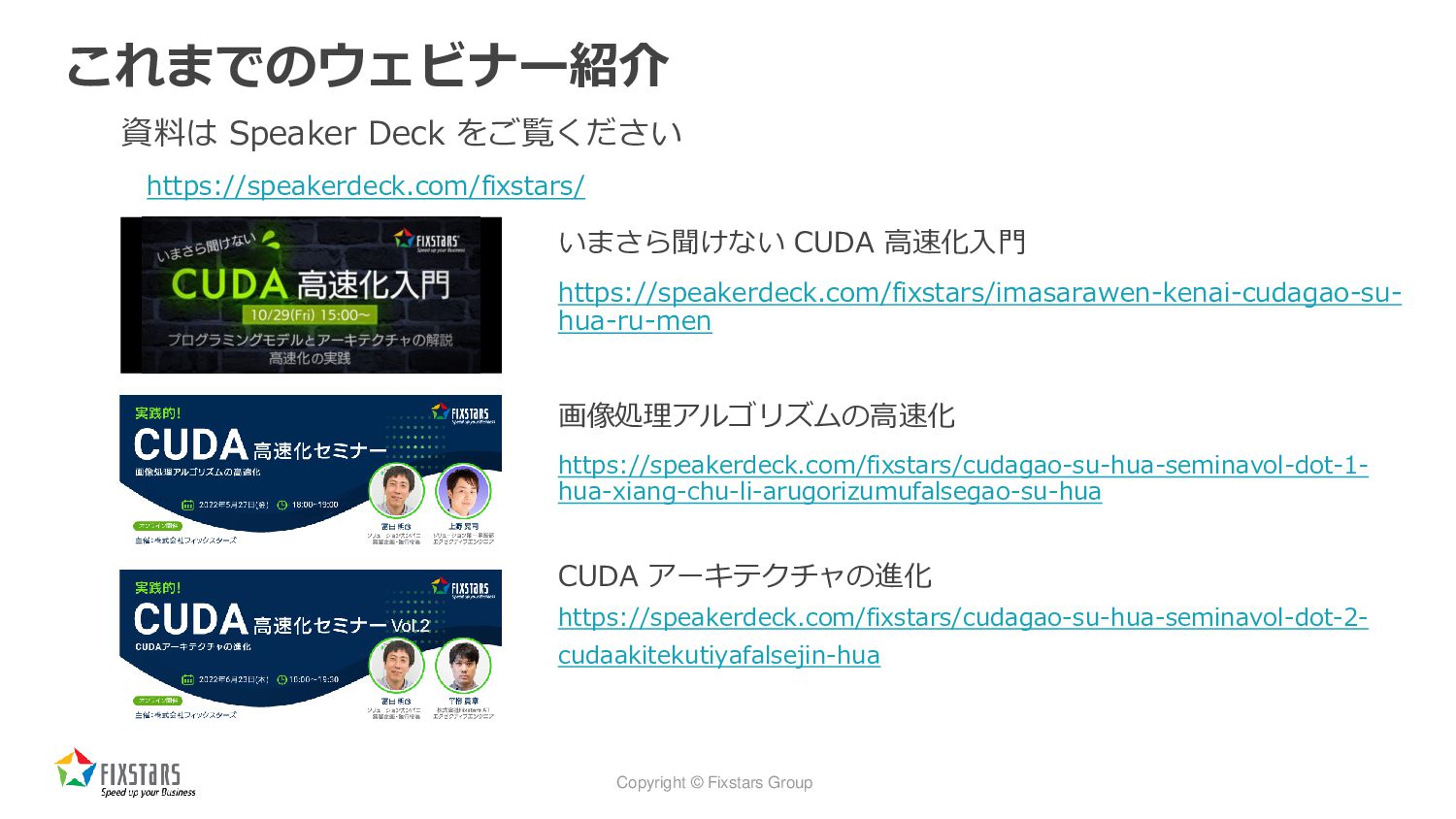
Copyright © Fixstars Group これまでのウェビナー紹介 いまさら聞けない CUDA 高速化入門 https://speakerdeck.com/fixstars/imasarawen-kenai-cudagao-su- hua-ru-men
画像処理アルゴリズムの高速化 https://speakerdeck.com/fixstars/cudagao-su-hua-seminavol-dot-1- hua-xiang-chu-li-arugorizumufalsegao-su-hua CUDA アーキテクチャの進化 https://speakerdeck.com/fixstars/cudagao-su-hua-seminavol-dot-2- cudaakitekutiyafalsejin-hua 資料は Speaker Deck をご覧ください https://speakerdeck.com/fixstars/
Copyright © Fixstars Group 本日のAgenda • フィックスターズのご紹介 (15分) • ソフトウェア高速化と深層学習(60分)
◦ ソフトウェア高速化 ◦ 深層学習 ◦ GPUと高速化 • Q&A • 告知 3
Copyright © Fixstars Group 発表者紹介 冨田 明彦 ソリューションカンパニー 執行役員 前職では組込み向けCPUのデジタル設計に携わ
る。2008年にフィックスターズへ入社。金融、 医療業界において、ソフトウェア高速化業務に 携わる。その後、新規事業企画、半導体業界の 事業を担当し、現職。 4 二木 紀行 ソリューション第一事業部 エグゼクティブエンジニア 理化学研究所でスーパーコンピュータを利用した バイオ系の研究に10年以上携わる。2010年にフ ィックスターズへ入社。GPUプログラムの高速化、 分散並列処理、深層学習のアーキテクチャ開発ま で、幅広く業務を担当。SC06でゴードン・ベル 賞を受賞。博士(薬学)、薬剤師。
Copyright © Fixstars Group フィックスターズの ご紹介
Copyright © Fixstars Group フィックスターズの強み コンピュータの性能を最大限に引き出す、ソフトウェア高速化のエキスパート集団 ハードウェアの知見 アルゴリズム実装力 各産業・研究分野の知見 6
目的の製品に最適なハードウェアを見抜き、 その性能をフル活用するソフトウェアを開 発します。 ハードウェアの特徴と製品要求仕様に合わ せて、アルゴリズムを改良して高速化を実 現します。 開発したい製品に使える技術を見抜き、実 際に動作する実装までトータルにサポート します。
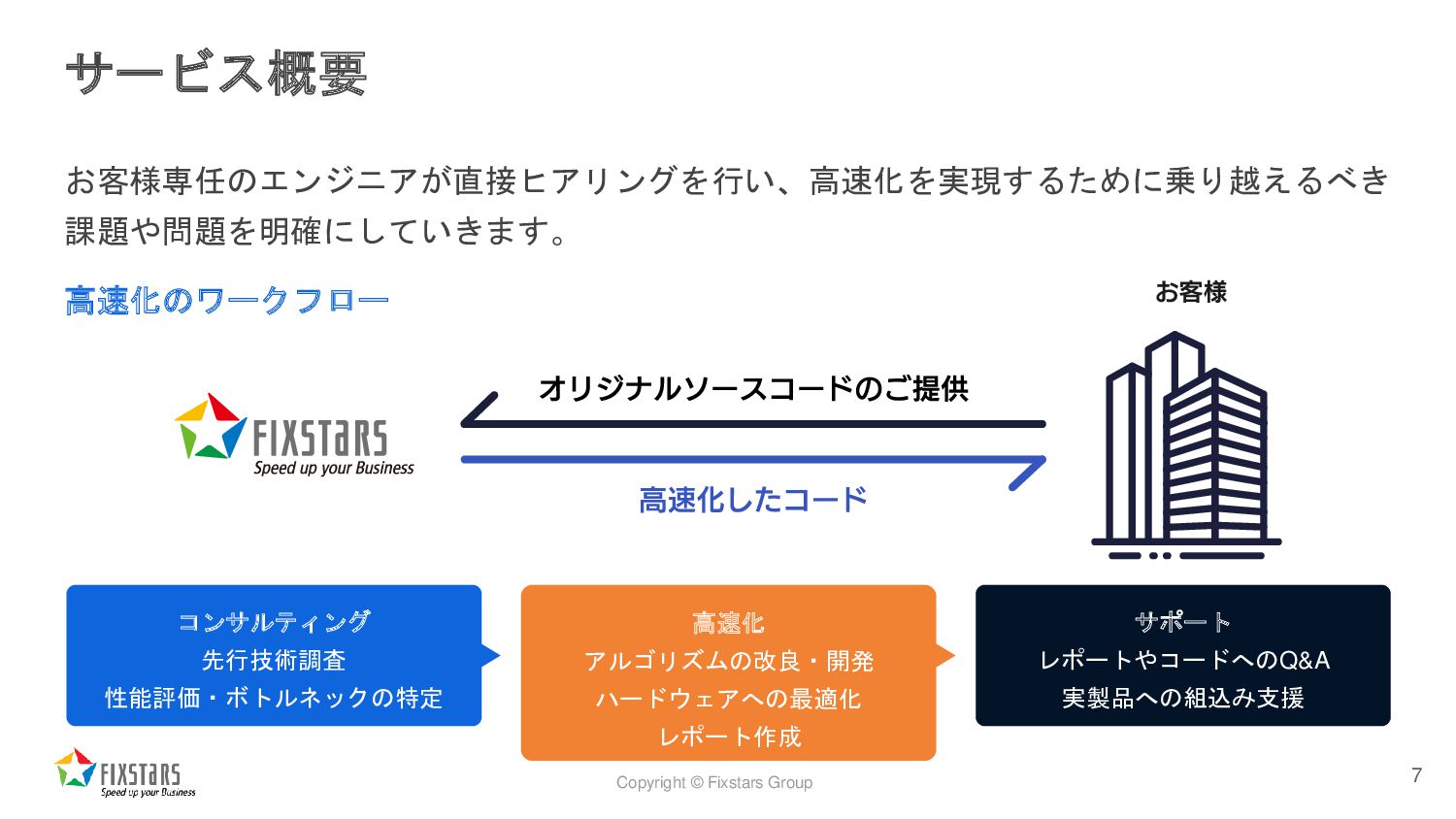
Copyright © Fixstars Group サービス概要 お客様専任のエンジニアが直接ヒアリングを行い、高速化を実現するために乗り越えるべき 課題や問題を明確にしていきます。 高速化のワークフロー コンサルティング 先行技術調査
性能評価・ボトルネックの特定 高速化 アルゴリズムの改良・開発 ハードウェアへの最適化 レポート作成 サポート レポートやコードへのQ&A 実製品への組込み支援 7
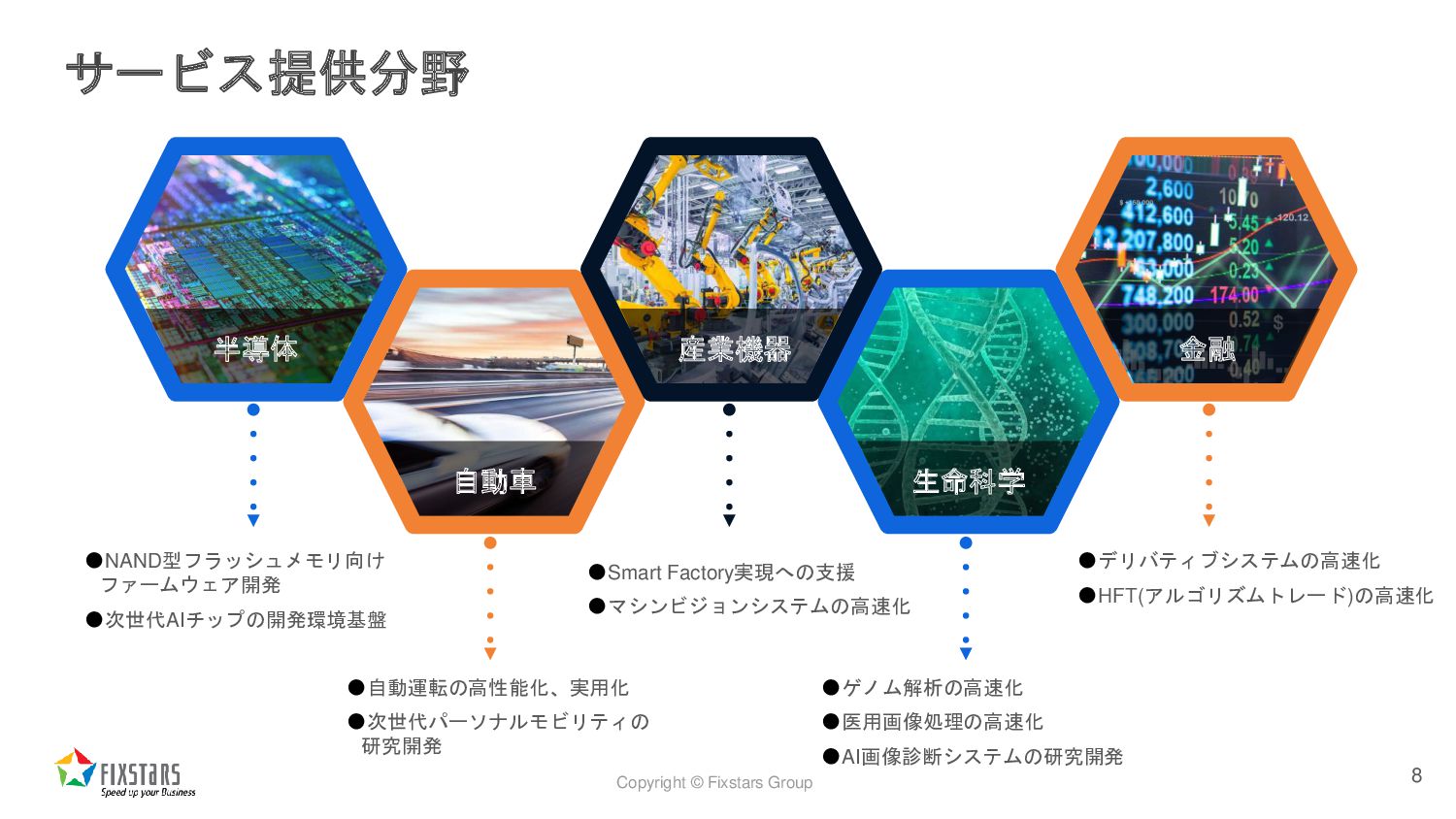
Copyright © Fixstars Group サービス提供分野 8 半導体 自動車 産業機器 生命科学
金融 •NAND型フラッシュメモリ向け ファームウェア開発 •次世代AIチップの開発環境基盤 •自動運転の高性能化、実用化 •次世代パーソナルモビリティの 研究開発 •Smart Factory実現への支援 •マシンビジョンシステムの高速化 •ゲノム解析の高速化 •医用画像処理の高速化 •AI画像診断システムの研究開発 •デリバティブシステムの高速化 •HFT(アルゴリズムトレード)の高速化
Copyright © Fixstars Group サービス領域 様々な領域でソフトウェア高速化サービスを提供しています。大量データの高速処理は、 お客様の製品競争力の源泉となっています。 9 組込み高速化 画像処理・アルゴリズム
開発 分散並列システム開発 GPU向け高速化 FPGAを活用した システム開発 量子コンピューティング AI・深層学習 自動車向け ソフトウェア開発 フラッシュメモリ向けフ ァームウェア開発
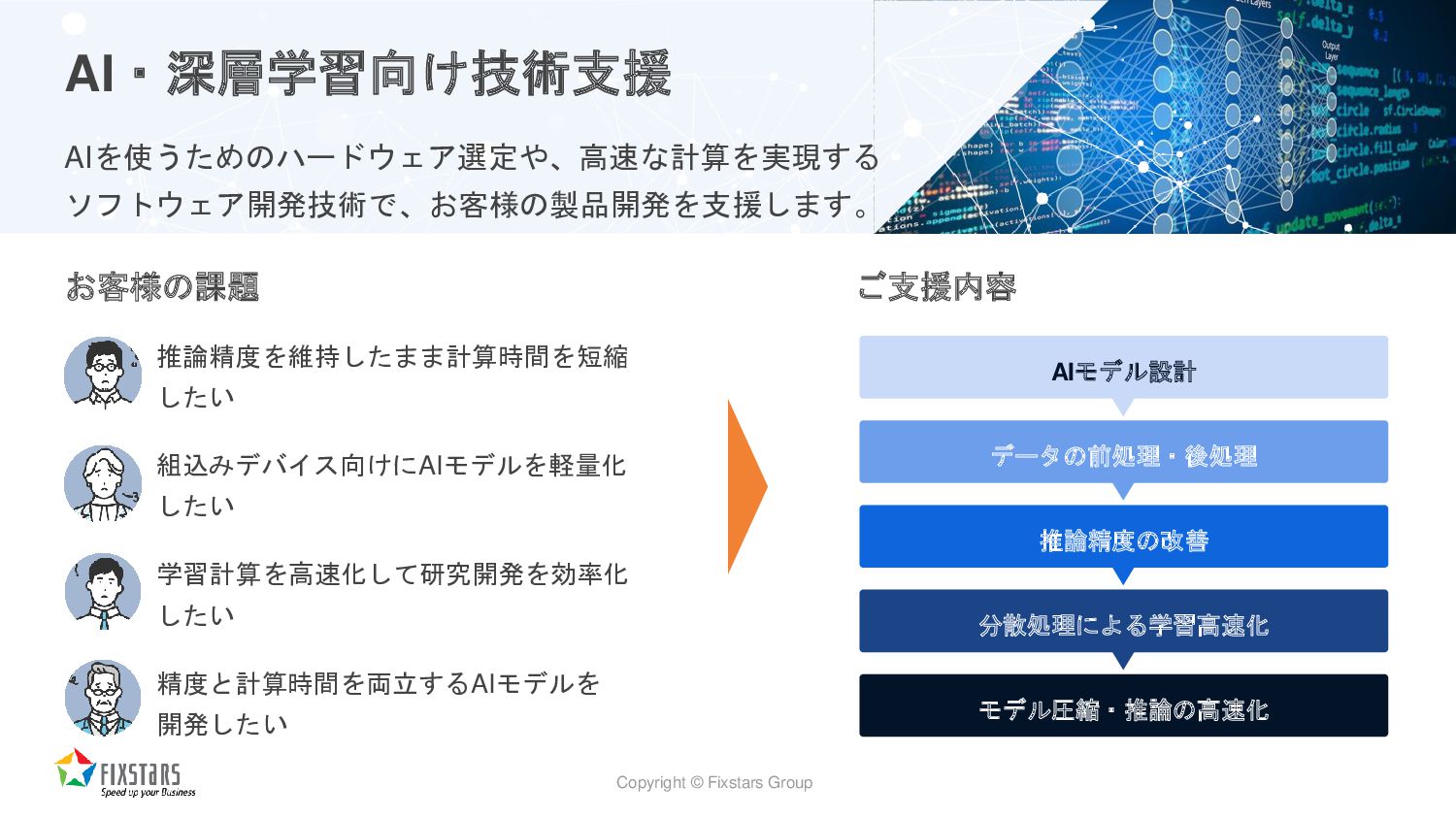
Copyright © Fixstars Group AI・深層学習向け技術支援 AIを使うためのハードウェア選定や、高速な計算を実現する ソフトウェア開発技術で、お客様の製品開発を支援します。 お客様の課題 推論精度を維持したまま計算時間を短縮 したい
組込みデバイス向けにAIモデルを軽量化 したい ご支援内容 AIモデル設計 データの前処理・後処理 推論精度の改善 分散処理による学習高速化 モデル圧縮・推論の高速化 学習計算を高速化して研究開発を効率化 したい 精度と計算時間を両立するAIモデルを 開発したい
Copyright © Fixstars Group 画像処理アルゴリズム開発 高速な画像処理需要に対して、経験豊富なエンジニアが 責任を持って製品開発をご支援します。 お客様の課題 高度な画像処理や深層学習等のアルゴリズム を開発できる人材が社内に限られている
機能要件は満たせそうだが、ターゲット機器 上で性能要件までクリアできるか不安 製品化に結びつくような研究ができていない ご支援内容 深層学習ネットワーク精度の改善 様々な手法を駆使して深層学習ネットワークの精度を改善 論文調査・改善活動 論文調査から最先端の手法の探索 性能向上に向けた改善活動を継続 アルゴリズム調査・改変 課題に合ったアルゴリズム・実装手法を調査 製品実装に向けて適切な改変を実施
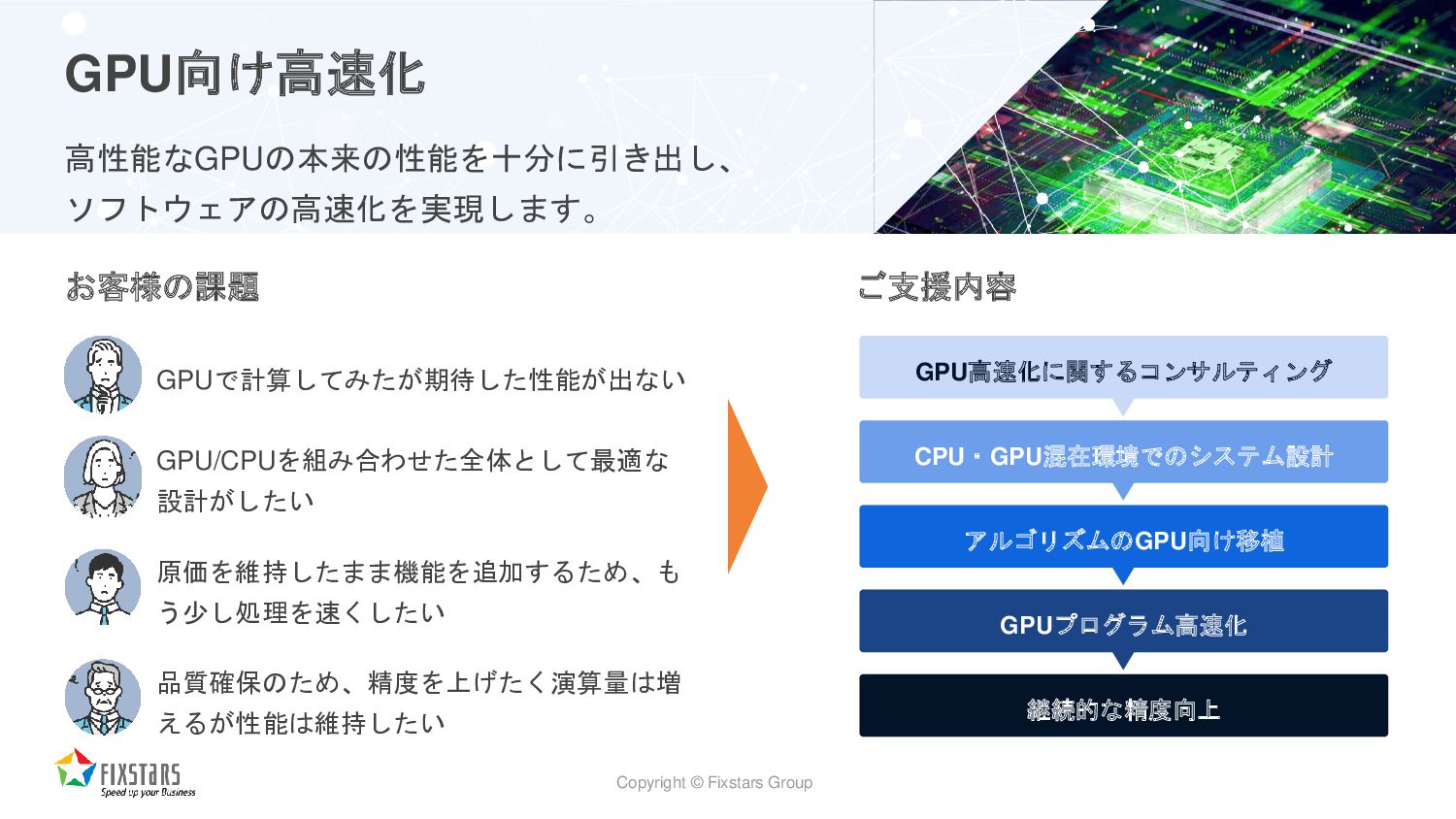
Copyright © Fixstars Group GPU向け高速化 高性能なGPUの本来の性能を十分に引き出し、 ソフトウェアの高速化を実現します。 お客様の課題 GPUで計算してみたが期待した性能が出ない GPU/CPUを組み合わせた全体として最適な
設計がしたい ご支援内容 GPU高速化に関するコンサルティング CPU・GPU混在環境でのシステム設計 アルゴリズムのGPU向け移植 GPUプログラム高速化 継続的な精度向上 原価を維持したまま機能を追加するため、も う少し処理を速くしたい 品質確保のため、精度を上げたく演算量は増 えるが性能は維持したい
Copyright © Fixstars Group 深層学習適用時の課題と本講演でのアプローチ 1. 学習・推論に時間がかかりすぎる! 13 2. 学習・推論の処理を速くするには?
◦ GPU を使う? ◦ なぜ処理を速くできる? 3. 深層学習の高速化に向けて基礎技術を おさえよう! ◦ ソフトウェアの高速化技術 ◦ 深層学習の仕組み
Copyright © Fixstars Group ソフトウェア高速化と深層学習
Copyright © Fixstars Group アジェンダ • ソフトウェア高速化 ◦ ソフトウェア高速化とは何か? ◦
速度×電力×場所 ◦ 高速化を行うためのハードウェア ◦ 高速化の手段 • 深層学習 ◦ 深層学習と高速化 ◦ ニューラルネットワーク ◦ 「推論」と「学習」 ◦ 畳み込みニューラルネットワーク(CNN) ◦ 誤差逆伝播法 ◦ バッチ処理 ◦ 行列計算 • GPUと高速化 ◦ 分散並列化 ◦ さらなる高速化 15
Copyright © Fixstars Group ソフトウェア高速化とは何か? • プログラムを速くすること • 例えば、あるリストを昇順に並び替えるプログラムが遅いので速くしたい ◦
速いアルゴリズムを使用 ▪ 遅い: 隣接する値を比較して入れ替えていくバブルソート ▪ 速い: ある基準値未満と以上の2グループに分割して処理していくクイックソート ◦ 既存のライブラリやフレームワークを使用 ◦ 速いコンピュータを使用 ◦ 既にソート済みの数列を使用 • 目的を達成できればOK ◦ 条件と制約 – 高速化をするにあたり検討 16
Copyright © Fixstars Group 速度×電力×場所 17 どれだけ速くする 必要があるのか? どのくらい電力を 使えるのか?
どれだけの場所を 用意できるのか?
Copyright © Fixstars Group 速度 • 速度は高速化の主目的 • 必要な速度 ◦
実行される関数の速度 ◦ システム全体の速度 • 目的と手段 ◦ 目的を明確にする ◦ 取りえる手段を確認 18
Copyright © Fixstars Group 電力 • 高速化の対象となるコンピュータ ◦ 車載デバイス ◦
スマートフォン ◦ PC ◦ クラウドコンピュータ ◦ スーパーコンピュータ • 電力とコスト ◦ どれだけの電力が利用できるか? ◦ 高速化による利益よりも電力のコストが上回っていない か? 19
Copyright © Fixstars Group 場所 • 利用場所は様々 ◦ オフィスのデスク ◦
サーバルーム ◦ データセンター ◦ 自動車 ◦ クラウドサービス • PC内のスペース ◦ GPUのボードは何枚搭載可能か? • セキュリティ ◦ ネットワーク利用の有無 20
Copyright © Fixstars Group 高速化を行うためのハードウェア • CPU • GPU •
FPGAとASIC • クラウドコンピューティング • エッジデバイス • 高性能コンピューティング(HPC) • 量子コンピュータ 21
Copyright © Fixstars Group CPU • 一般的なPCに搭載され、プログラムを実行・ 処理 ◦ 高性能あればより高速に動作
• アセンブリに近い低レベルでのコードにより CPU の機能や特性を活用した高速化が可能 • 1つのCPU内に複数のコアを搭載 ◦ マルチコア・メニーコア ◦ 計算処理をそれぞれのコアで分担した並列処理によ る性能向上が可能 22
Copyright © Fixstars Group GPU • グラフィックス演算処理装置 ◦ 画像処理に特化した演算装置 •
画像処理以外の用途に利用 • GPUに搭載された数千個のコアを利用するこ とで大規模な並列計算が可能 • 大規模な並列計算や浮動小数点数演算が得意 ◦ 深層学習による演算処理と親和性が高い ◦ さまざまな深層学習系ライブラリを提供 ◦ 学習・推論時の高速演算に利用 23
Copyright © Fixstars Group FPGAとASIC • FPGA (Field Programmable Gate
Array) ◦ プログラミング可能な集積回路 ◦ 作成した集積回路は後から書き換え可能 ▪ 目的に合わせた処理が可能 • ASIC(Application Specific Integrated Circuit) ◦ 設計後の変更が困難 ◦ 初期投資に費用がかかる ◦ 消費電力が低い ◦ 動作が高速 ◦ 大量に生産する場合に単価が安い • 集積回路の設計には、Verilog HDLやVHDLなどの ハードウェア記述言語を利用 24
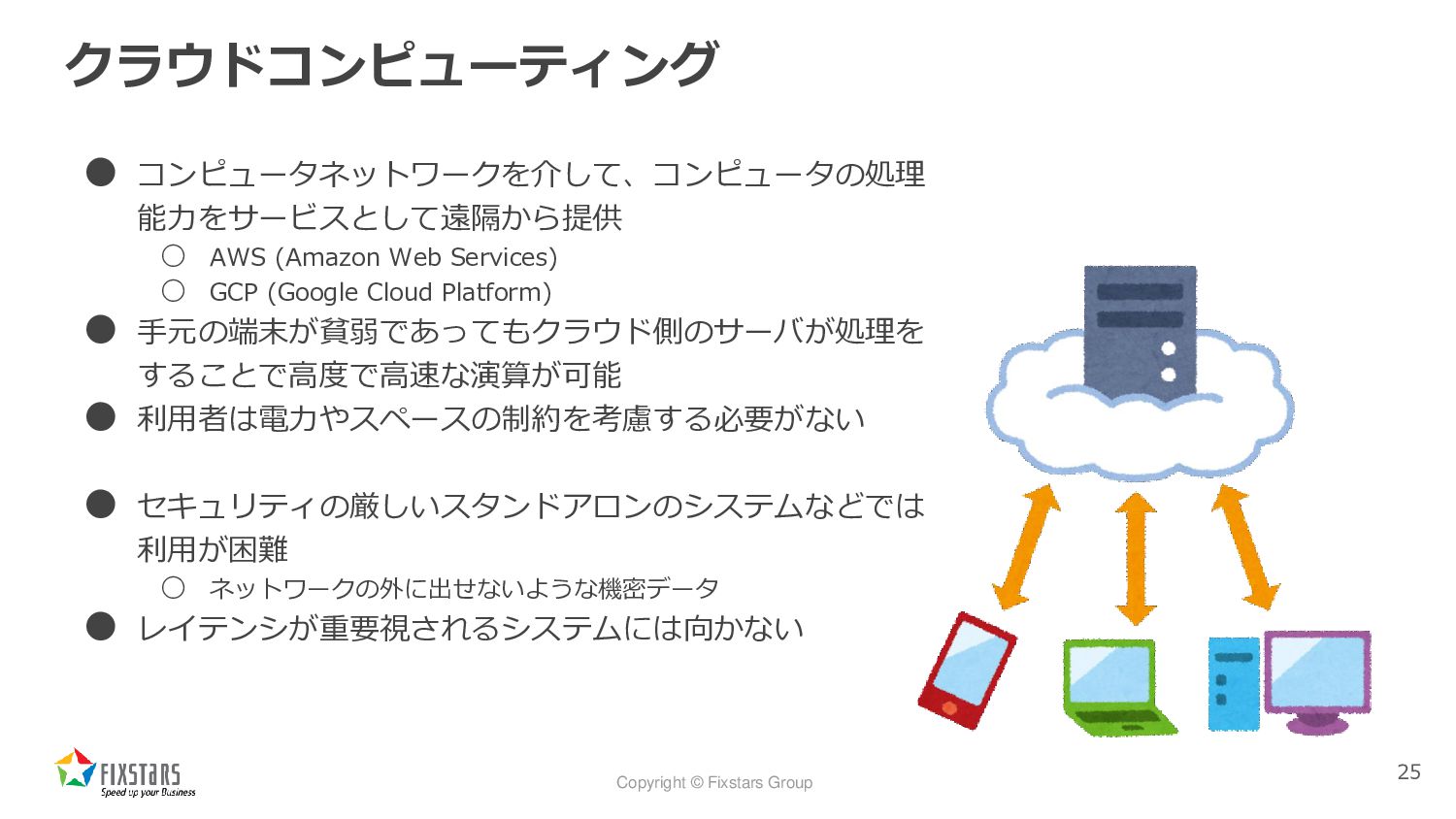
Copyright © Fixstars Group クラウドコンピューティング • コンピュータネットワークを介して、コンピュータの処理 能力をサービスとして遠隔から提供 ◦ AWS
(Amazon Web Services) ◦ GCP (Google Cloud Platform) • 手元の端末が貧弱であってもクラウド側のサーバが処理を することで高度で高速な演算が可能 • 利用者は電力やスペースの制約を考慮する必要がない • セキュリティの厳しいスタンドアロンのシステムなどでは 利用が困難 ◦ ネットワークの外に出せないような機密データ • レイテンシが重要視されるシステムには向かない 25
Copyright © Fixstars Group エッジデバイス • インターネットに接続された装置のこと ◦ スマートフォン ◦
インターネット家電 • クラウドコンピューティングにより情報を高速に処 理可能 • エッジデバイス側で高度な処理を行うエッジコンピ ューティング ◦ ネットワークの遅延やサーバの負荷を低減し、高性能演算を 可能に ◦ エッジデバイスにおける高速化はシステム全体へ大きく寄与 26
Copyright © Fixstars Group 高性能コンピューティング(HPC) • HPCとは、科学技術計算などを主とした非常に 処理性能が高い計算処理のこと ◦ 多数のCPUコアと超高速のネットワークシステムを搭載
◦ ネットワーク上に存在する複数のコンピュータシステム と連携し分散処理 27
Copyright © Fixstars Group 量子コンピュータ • 従来のコンピュータでは現実的な時間で解くことが困難な問 題に対して、量子力学的な現象を利用して効率的に解くため のコンピュータ •
量子力学的な現象 ◦ 2つ以上の状態を同時に取り得る事象 ◦ 「量子ビット」で表現 ◦ 複数の状態を表現できる量子ビットに対して量子力学的な操作を行い、 それらを観測することで結果を得る • まだ開発途上の技術 ◦ 一般的に利用できるようになるまでにはしばらくかかる見込み ◦ 組合せ最適化問題に特化している量子アニーリングマシン ◦ NISQと呼ばれる誤り訂正機能のない量子コンピュータ 28
Copyright © Fixstars Group 高速化の手段 • 定数倍高速化 • アルゴリズムの改善 •
ライブラリの利用 29
Copyright © Fixstars Group 定数倍高速化 • コンピュータによる計算処理を改良・改善する ことにより計算量のオーダーを変えずに高速化 すること ◦
計算負荷の高い除算を減らす ◦ キャッシュを効率的に利用 ◦ コンパイラのオプションを調整して最適化 • 本質的な計算アルゴリズムを変更せずに高速に 処理されるような改変全般が対象 30
Copyright © Fixstars Group アルゴリズムの改善 • 低レイヤを最適化の対象とした定数倍高速化に対 して、アルゴリズムの改善による高速化は極めて 効果を期待できる場合がある ◦
高速なアルゴリズム ◦ 近似アルゴリズム ◦ 並列化アルゴリズム • 計算量オーダーのレベルで高速化 ◦ バブルソート(𝑂 𝑛2 )とクイックソート(𝑂 𝑛 log 𝑛 ) 31
Copyright © Fixstars Group ライブラリの利用 • 最適化されたライブラリやフレームワークの使用して高速化 • GPUを利用した汎用深層学習ライブラリ ◦
PyTorch ◦ TensorFlow • NVIDIA GPUによる深層学習用ライブラリcuDNN ◦ 深層学習ライブラリのコア技術として組み込まれる • 推論の実行に関しては、複数レイヤにまたがる処理に対してメモ リ使用量の削減やカーネルの最適化を行うTensorRT • 数値演算の高速化 ◦ Intel CPU用のMKL (Math Kernel Library) ◦ NVIDIA GPU用のcuBLAS 32
Copyright © Fixstars Group 高速化を行う前に • 調査・分析・検証 ◦ 対象を調べて必要なことを見つける •
プロファイリング ◦ 対象を調べる方法の一つであり、各関数の実行 時間や呼び出し回数などがわかる • ボトルネック ◦ 最も時間のかかる場所のことであり、そこを改 善することにより全体の性能が顕著に向上 • リファクタリング ◦ 直接の性能を向上させるものではなく、改善や 改良を行う際に高い作業効率が期待できる 33
Copyright © Fixstars Group 深層学習と高速化 • 深層学習について ◦ 単純なニューラルネットワークから始まり、複雑な CNNやRNNなどの様々なアーキテクチャが存在する
◦ 「学習」によりニューラルネットワークモデルを作り、 そのモデルを使って「推論」を行う • 高速化の必要性 ◦ 深層学習のアーキテクチャのほとんどは膨大な計算を 行う必要がある ◦ 深層学習を行う対象や環境は様々であり、それぞれに 適した処理能力が必須となる • 速度と精度 ◦ 深層学習を利用する上で精度は最も重要 ◦ 環境や目的に合わせて判断する必要がある 34
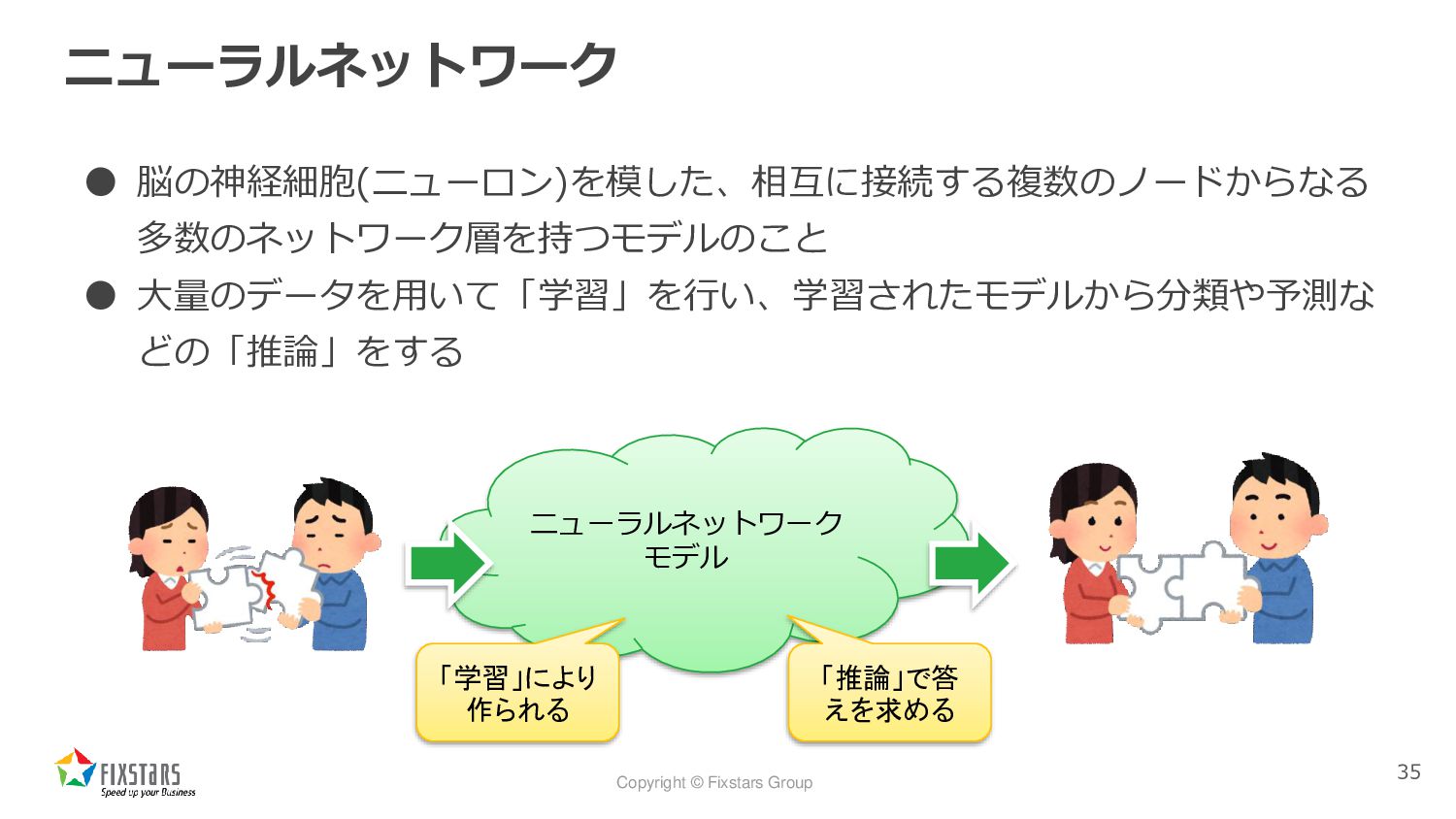
Copyright © Fixstars Group ニューラルネットワーク • 脳の神経細胞(ニューロン)を模した、相互に接続する複数のノードからなる 多数のネットワーク層を持つモデルのこと • 大量のデータを用いて「学習」を行い、学習されたモデルから分類や予測な
どの「推論」をする 35 ニューラルネットワーク モデル 「学習」により 作られる 「推論」で答 えを求める
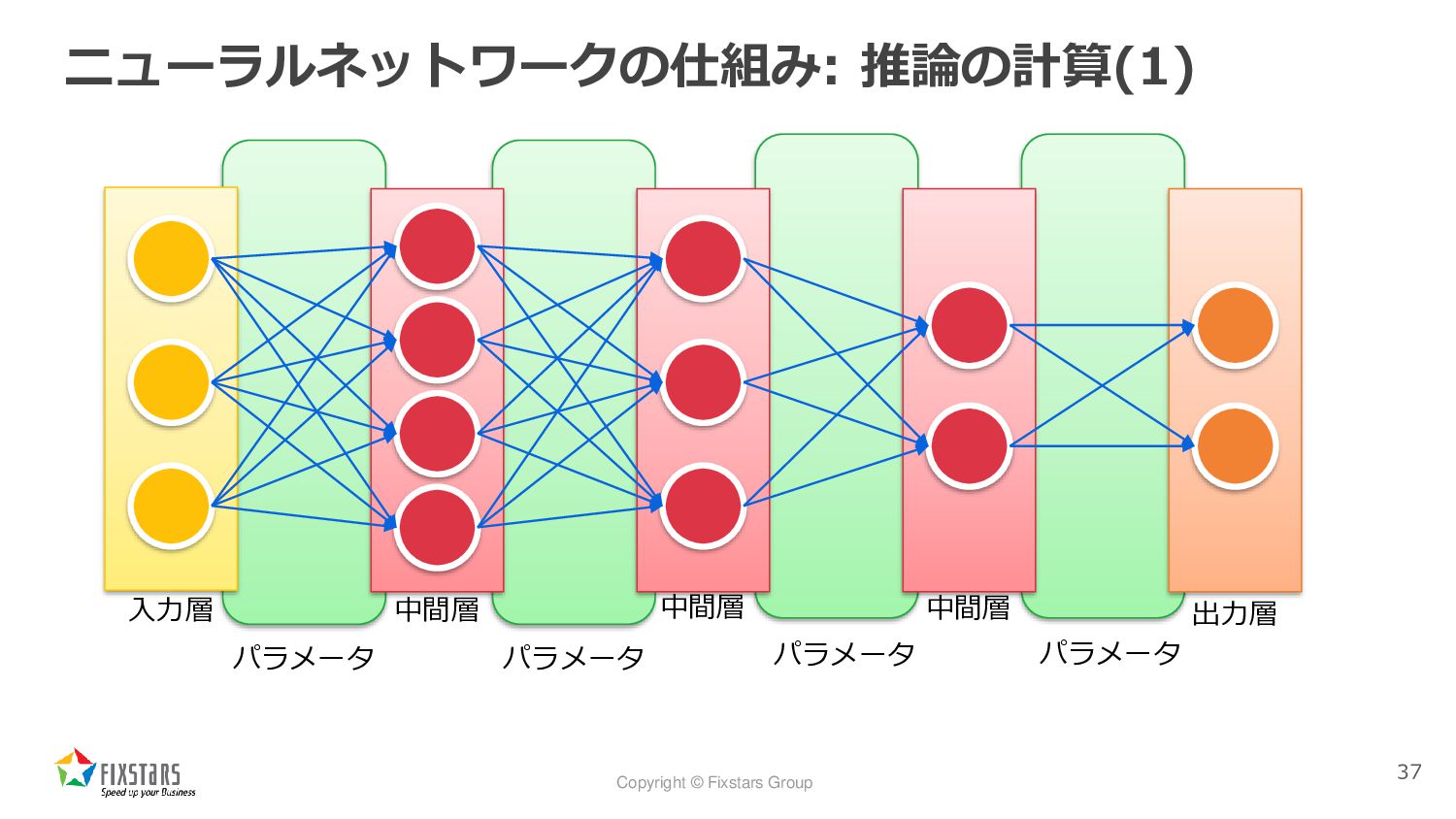
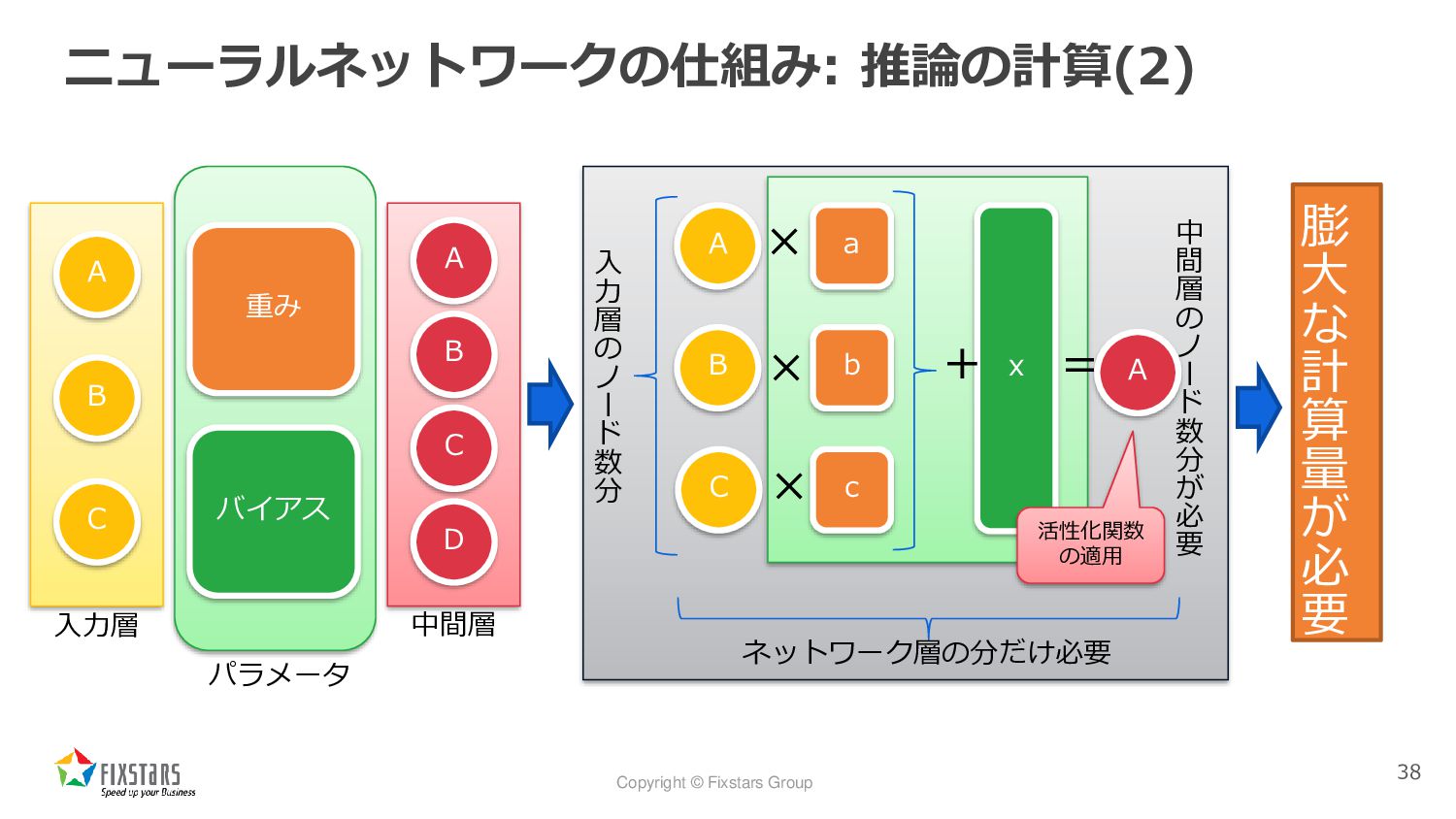
Copyright © Fixstars Group 「推論」と「学習」 • ニューラルネットワークモデル ◦ 計算に必要な複数のパラメータを持ち、多くの場合、それを多層で表現される •
推論とはモデルを使って結果を求めること ◦ 入力データに対して、モデルの持つパラメータを使って計算を行い、出力結果を得る • 学習とはモデルのパラメータを決定すること ◦ 学習データを使って、モデル内のパラメータを計算で決定する 36
Copyright © Fixstars Group ニューラルネットワークの仕組み: 推論の計算(1) 37 入力層 出力層 中間層
中間層 中間層 パラメータ パラメータ パラメータ パラメータ
Copyright © Fixstars Group ニューラルネットワークの仕組み: 推論の計算(2) 38 A B C
入力層 A B C D 中間層 パラメータ 重み バイアス A a x A b c B C × × × + = 入 力 層 の ノ ー ド 数 分 中 間 層 の ノ ー ド 数 分 が 必 要 ネットワーク層の分だけ必要 膨 大 な 計 算 量 が 必 要 活性化関数 の適用
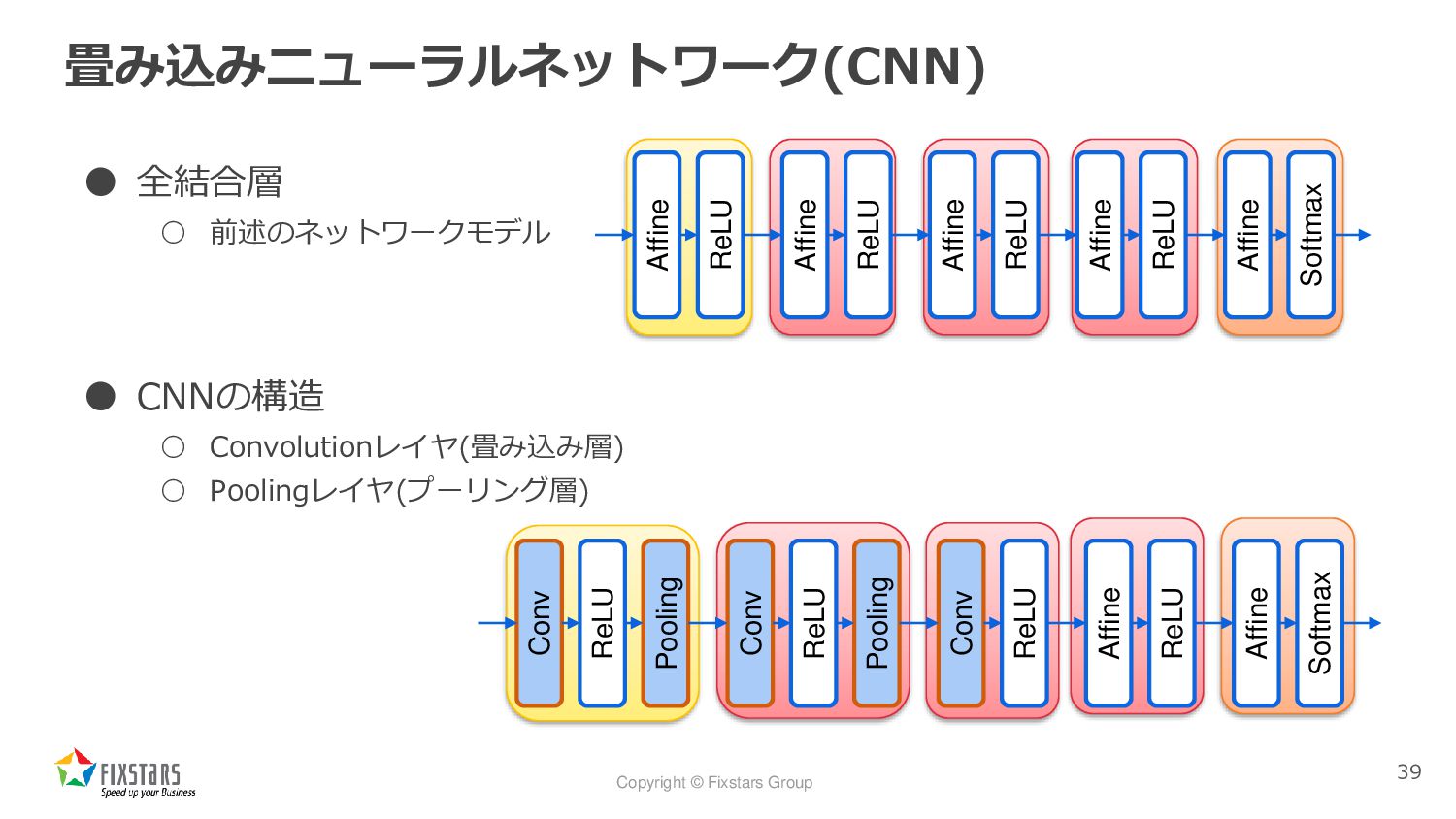
Copyright © Fixstars Group 畳み込みニューラルネットワーク(CNN) • 全結合層 ◦ 前述のネットワークモデル •
CNNの構造 ◦ Convolutionレイヤ(畳み込み層) ◦ Poolingレイヤ(プーリング層) 39 Affine ReLU Affine ReLU Affine ReLU Affine ReLU Affine Softmax Conv ReLU Pooling Conv ReLU Pooling Conv ReLU Affine ReLU Affine Softmax
Copyright © Fixstars Group 畳み込み層 • 各層を流れるデータは形状のあるデータ ◦ 3次元データなど ◦
画像は通常、縦・横・チャンネルの3次元形状 • 全結合層の問題点 ◦ データの形状が反映されない ◦ 全結合層の入力では1次元に変換が必要 ◦ 画像は3次元の形状で、これには空間的情報が含まれている • 畳み込み層は形状を維持する ◦ 畳み込み層の入出力データを特徴マップと呼ぶ 40
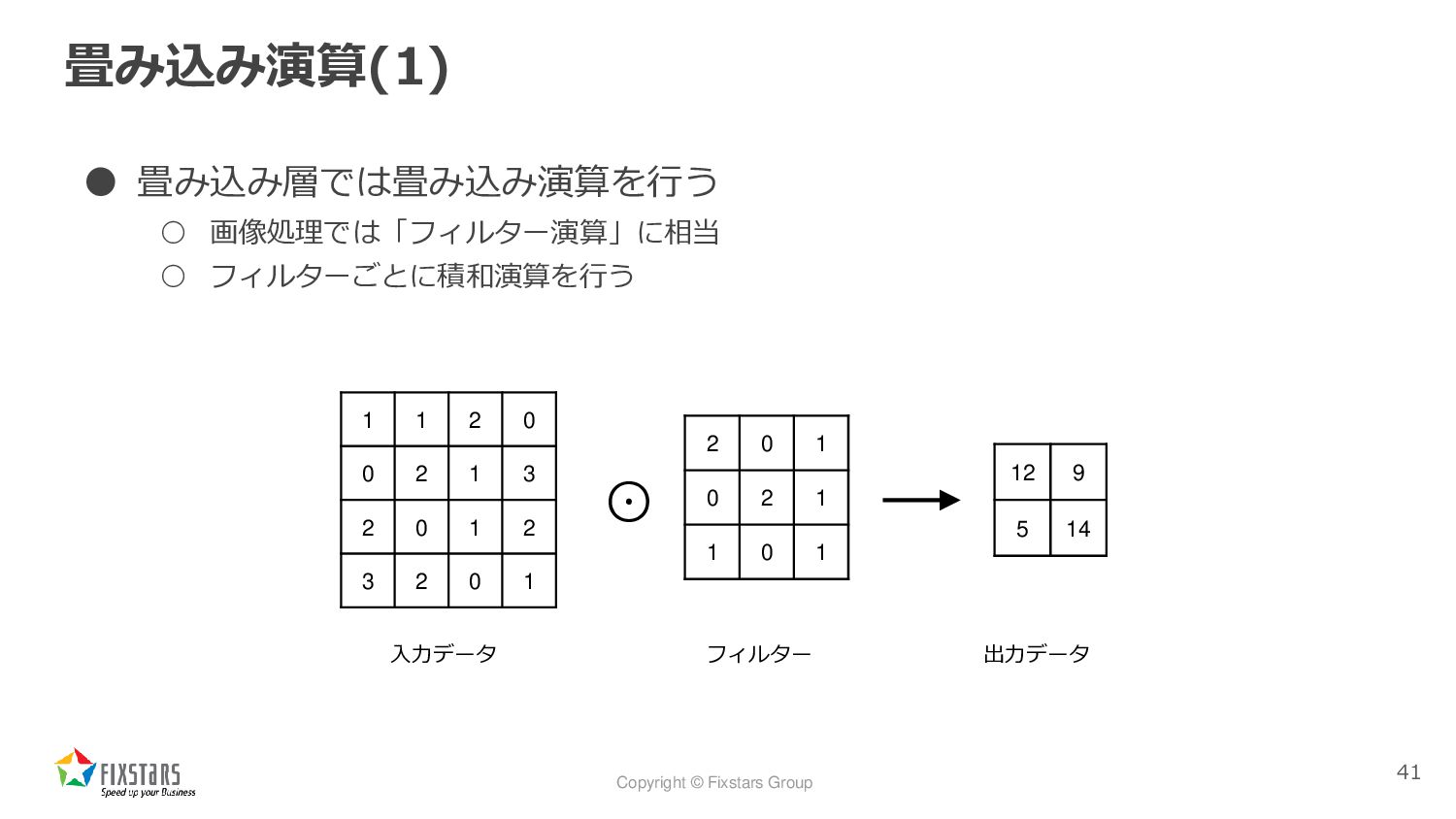
Copyright © Fixstars Group 畳み込み演算(1) • 畳み込み層では畳み込み演算を行う ◦ 画像処理では「フィルター演算」に相当 ◦
フィルターごとに積和演算を行う 41 1 1 2 0 0 2 1 3 2 0 1 2 3 2 0 1 2 0 1 0 2 1 1 0 1 12 9 5 14 ⊙ 入力データ フィルター 出力データ
Copyright © Fixstars Group 畳み込み演算(2) 42 1 1 2 0
0 2 1 3 2 0 1 2 3 2 0 1 2 0 1 0 2 1 1 0 1 12 ⊙ 1 1 2 0 0 2 1 3 2 0 1 2 3 2 0 1 2 0 1 0 2 1 1 0 1 12 9 ⊙
Copyright © Fixstars Group 畳み込み演算(3) 43 1 1 2 0
0 2 1 3 2 0 1 2 3 2 0 1 2 0 1 0 2 1 1 0 1 12 9 5 ⊙ 1 1 2 0 0 2 1 3 2 0 1 2 3 2 0 1 2 0 1 0 2 1 1 0 1 12 9 5 14 ⊙
Copyright © Fixstars Group 畳み込み演算(4) • 畳み込み演算のバイアス • つねにバイアスは一つだけ (1
× 1) 44 1 1 2 0 0 2 1 3 2 0 1 2 3 2 0 1 2 0 1 0 2 1 1 0 1 12 9 5 14 ⊙ 入力データ フィルター 3 + 15 12 8 17 出力データ バイアス
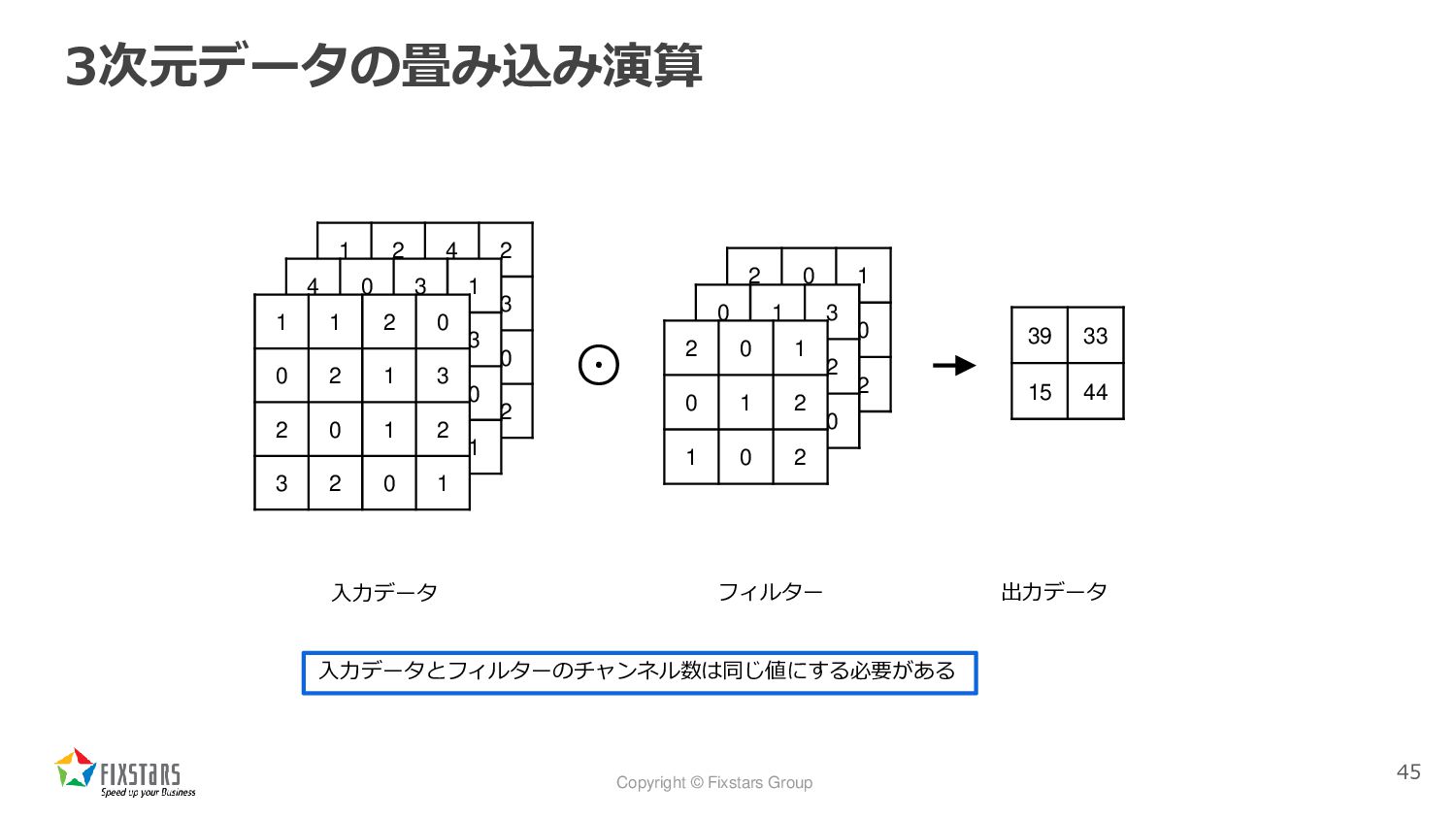
Copyright © Fixstars Group 3次元データの畳み込み演算 45 1 2 4 2
0 1 2 3 3 0 1 0 2 4 0 2 4 0 3 1 0 1 0 3 3 0 2 0 1 3 0 1 1 1 2 0 0 2 1 3 2 0 1 2 3 2 0 1 2 0 1 0 3 0 1 0 2 0 1 3 0 1 2 1 0 0 2 0 1 0 1 2 1 0 2 39 33 15 44 ⊙ 入力データ フィルター 出力データ 入力データとフィルターのチャンネル数は同じ値にする必要がある
Copyright © Fixstars Group プーリング層 • プーリング層は、縦・横方向の空間を小さくする演算 • Maxプーリングの例 ◦
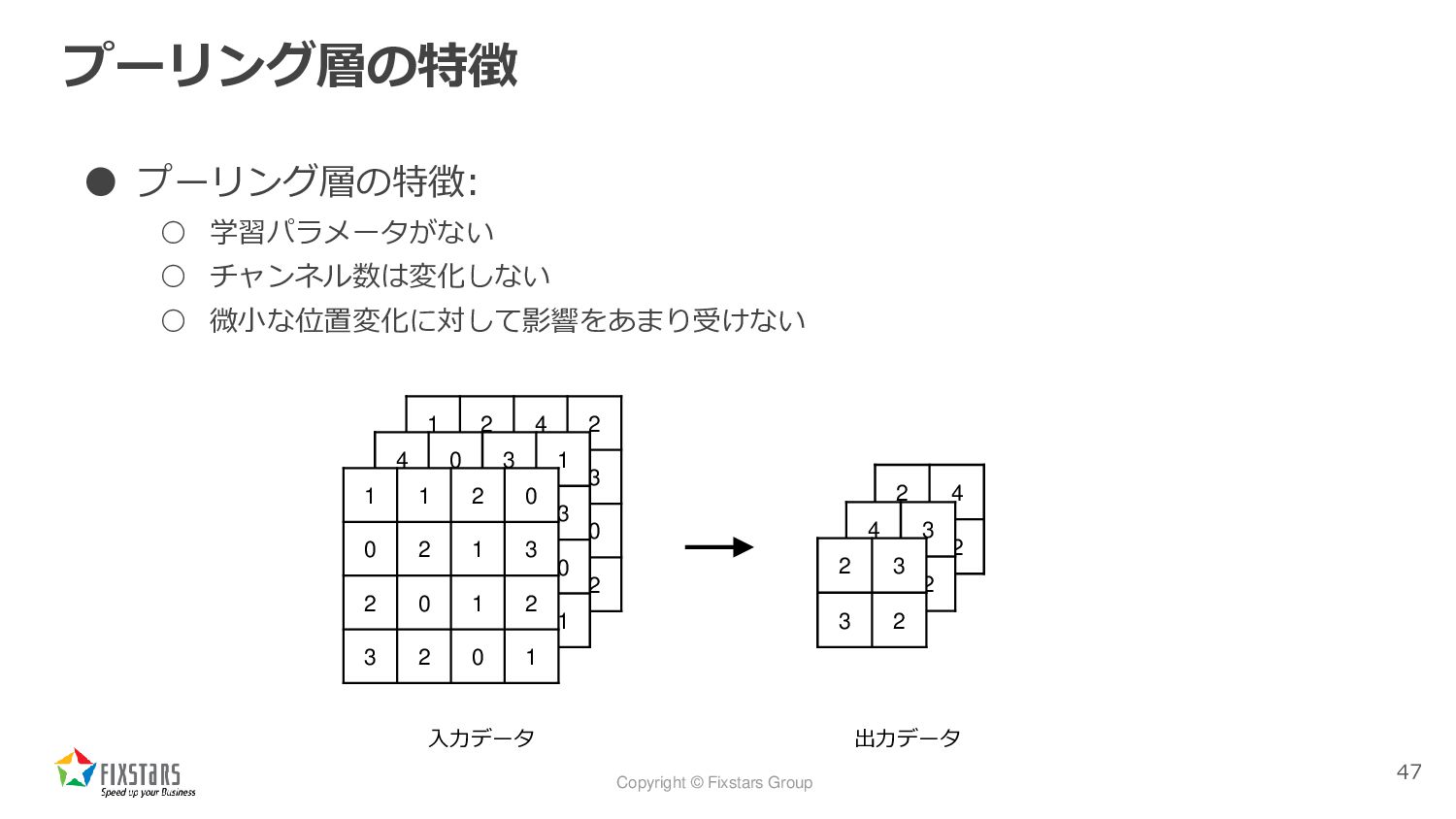
2×2のMaxプーリングをストライド2(2マスずらしながら計算)で行った場合 46 1 1 2 0 0 2 1 3 2 0 1 2 3 2 0 1 2 3 3 2
Copyright © Fixstars Group プーリング層の特徴 • プーリング層の特徴: ◦ 学習パラメータがない ◦
チャンネル数は変化しない ◦ 微小な位置変化に対して影響をあまり受けない 47 入力データ 出力データ 1 2 4 2 0 1 2 3 3 0 1 0 2 4 0 2 4 0 3 1 0 1 0 3 3 0 2 0 1 3 0 1 1 1 2 0 0 2 1 3 2 0 1 2 3 2 0 1 2 4 4 2 4 3 3 2 2 3 3 2
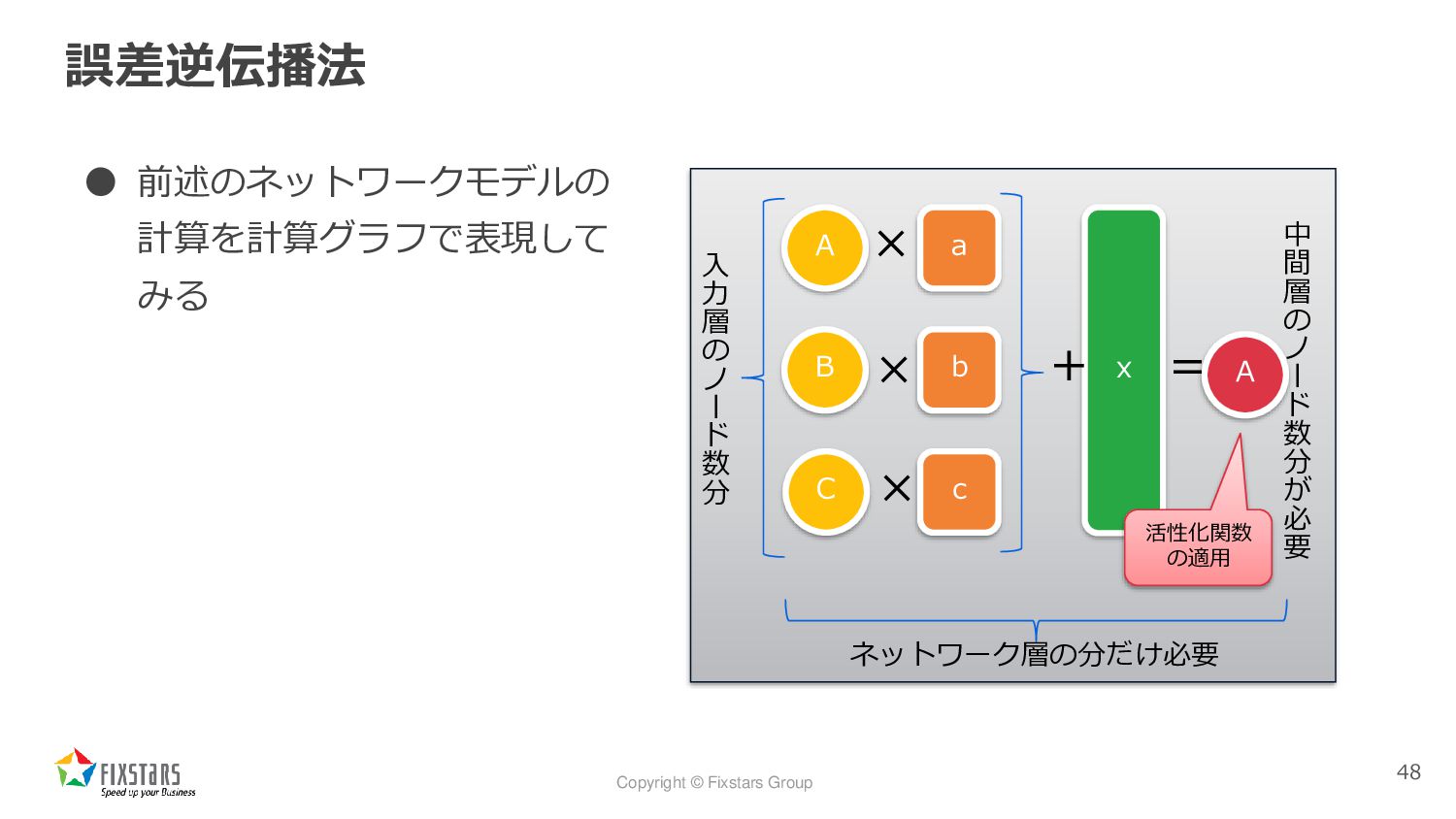
Copyright © Fixstars Group 誤差逆伝播法 • 前述のネットワークモデルの 計算を計算グラフで表現して みる 48
A a x A b c B C × × × + = 入 力 層 の ノ ー ド 数 分 中 間 層 の ノ ー ド 数 分 が 必 要 ネットワーク層の分だけ必要 活性化関数 の適用
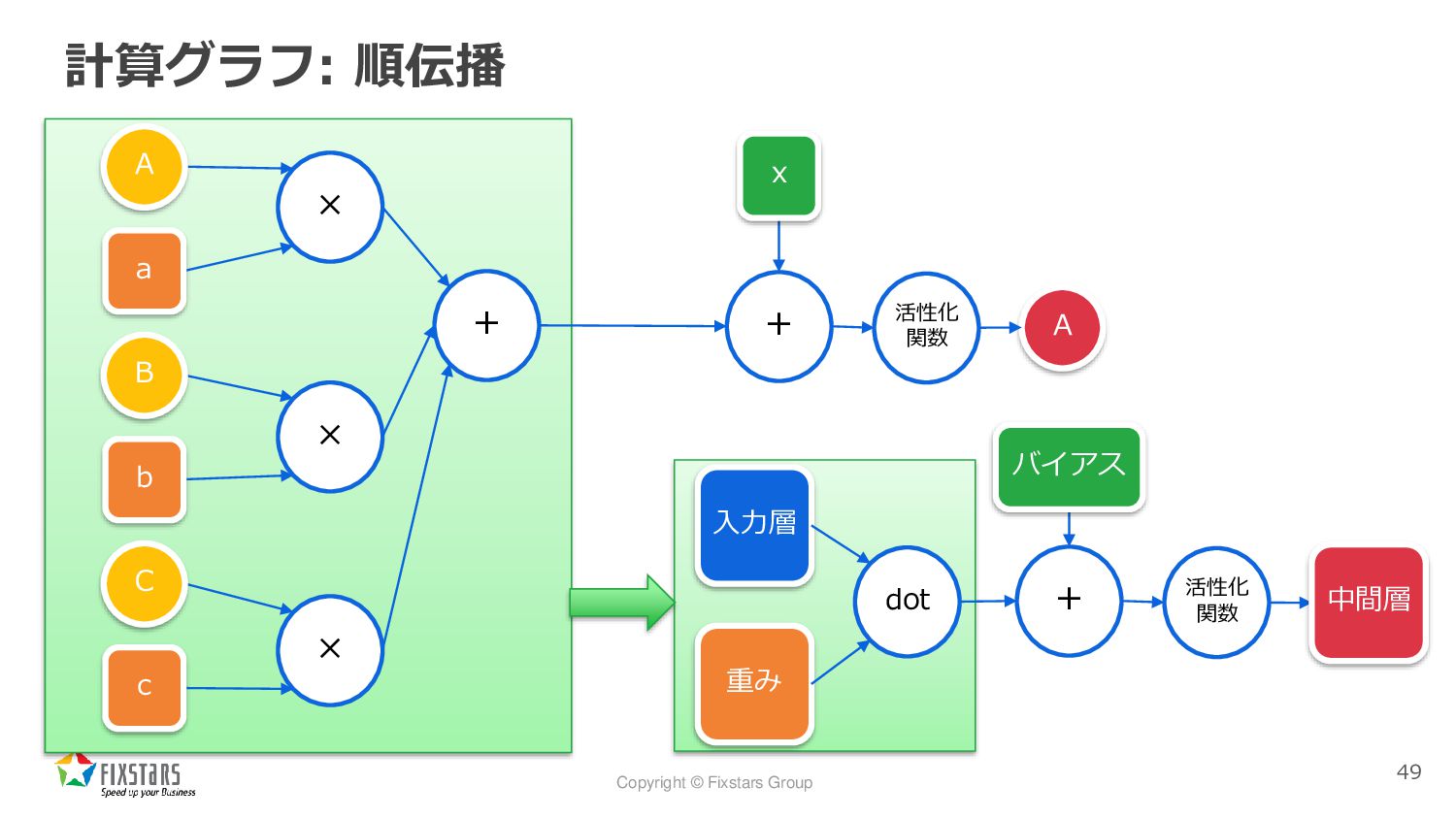
Copyright © Fixstars Group 計算グラフ: 順伝播 49 + + ×
× × A a x A b c B C 活性化 関数 重み 入力層 dot + バイアス 活性化 関数 中間層
Copyright © Fixstars Group 計算グラフ: 逆伝播 50 重み 入力層 dot
+ バイアス 活性化 関数 中間層 微分 微分 微分 微分 微分 パラメータ(重みとバイアス)に対して微 分によって求めた変化量分だけ値を修正 変化量がなくなるまで繰り返して最終的 なパラメータを求める → ネットワークモデルの完成 微分 出力された値 と正しい値の 差(loss)から 逆伝播 誤差逆伝播法
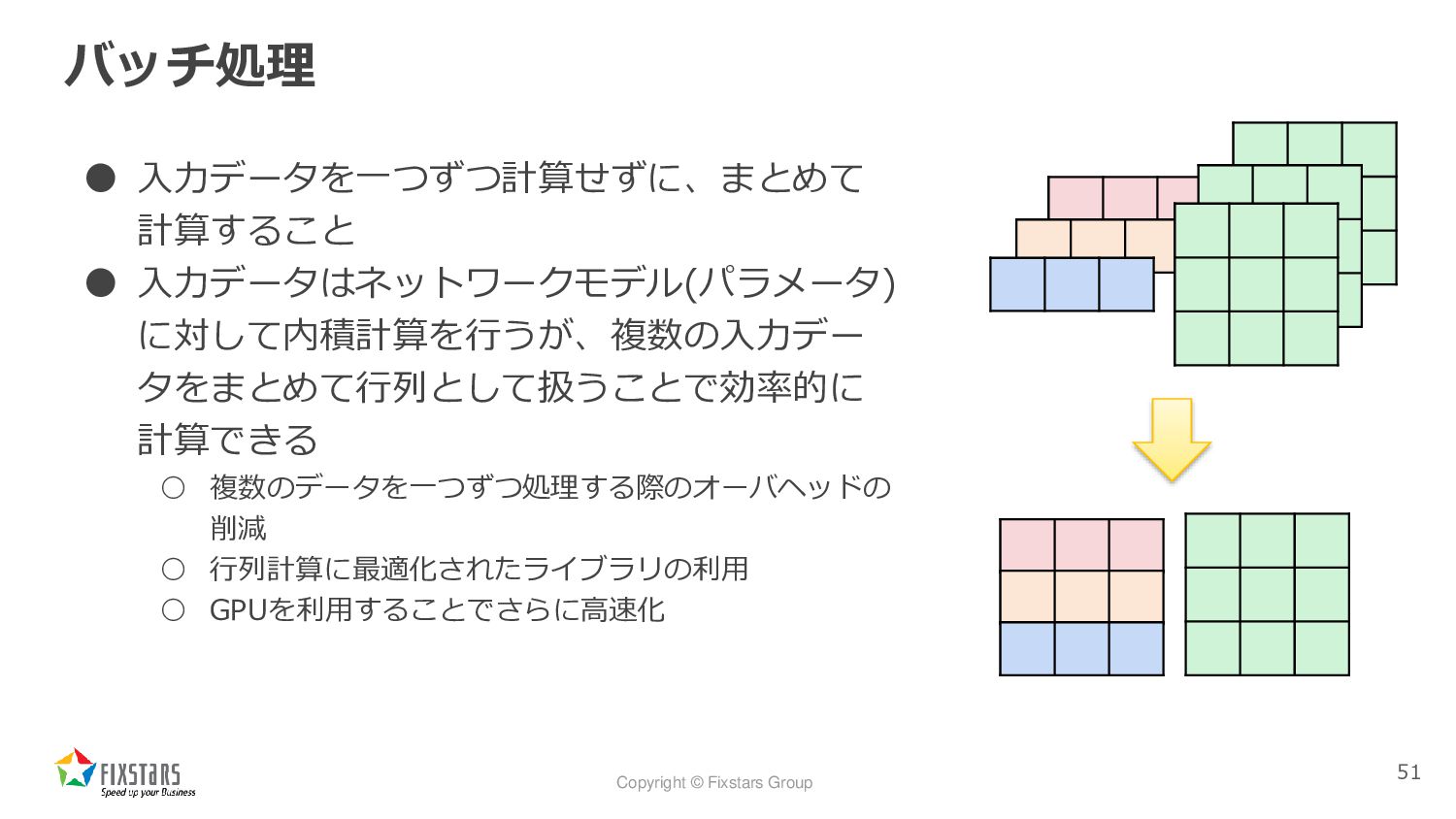
Copyright © Fixstars Group バッチ処理 • 入力データを一つずつ計算せずに、まとめて 計算すること • 入力データはネットワークモデル(パラメータ)
に対して内積計算を行うが、複数の入力デー タをまとめて行列として扱うことで効率的に 計算できる ◦ 複数のデータを一つずつ処理する際のオーバヘッドの 削減 ◦ 行列計算に最適化されたライブラリの利用 ◦ GPUを利用することでさらに高速化 51
Copyright © Fixstars Group 行列計算 • 行列計算はGPUによる高速化が可能 • CNN内の計算 ◦
畳み込み層やプーリング層では3次元以上のデータを扱う必要がある ▪ 例えば、高さ・横幅・チャンネル(RGBなど)・データ数(バッチ処理による)の4次元の データ ◦ 3次元以上のデータを2次元に変換 ▪ フィルターの適用領域が重なる場合、メモリ消費は大きくなる ◦ 入力データとフィルターを2次元に変換し内積を取る ◦ 最後に出力データの次元を変換すれば完了 • ループ処理のオーバヘッド削減や最適化された内積演算プログラムの利用に より高速化を期待できる 52
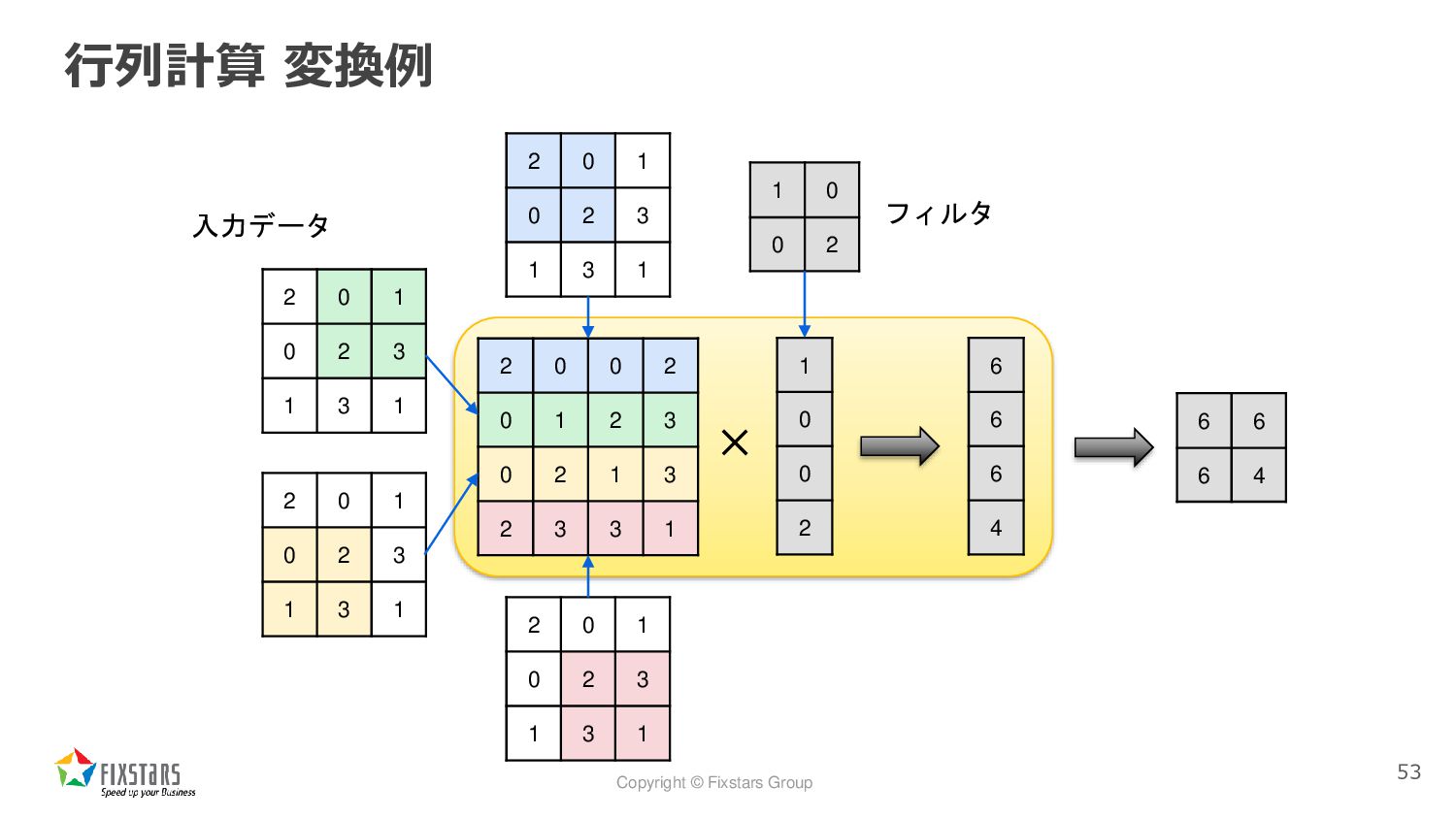
Copyright © Fixstars Group 行列計算 変換例 53 2 0 1
0 2 3 1 3 1 2 0 1 0 2 3 1 3 1 1 0 0 2 2 0 1 0 2 3 1 3 1 2 0 1 0 2 3 1 3 1 2 0 0 2 0 1 2 3 0 2 1 3 2 3 3 1 1 0 0 2 × 6 6 6 4 入力データ フィルタ 6 6 6 4
Copyright © Fixstars Group GPUと高速化 • NVIDIAなどによるGPUデバイスでは深層学習に特化した最適化・高速化された ライブラリや深層学習フレームワークなどの利用 • 深層学習フレームワークで対応していなかったり、利用したい機能が実装されて
いるとは限らない • ライブラリの関数を直接利用する、デバイスに特化したコードを専用に記述する 必要がある • ライブラリにされていないような最新技術の利用や、対象のデータ構造を利用し た効率的なメモリアクセスを考慮するような最適化を行う場合なども独自に設 計・実装が必要 • PyTorchやTensorFlowなどの深層学習フレームワークのソースコードに対し、 必要なコードを追加・修正することで対応 54
Copyright © Fixstars Group 分散並列化 • 複数のコンピュータを使って計算を行う分散並列化による高速化 ◦ データ転送のためのネットワーク帯域がボトルネックになる可能性 ◦
物理的にネットワークを高速にしたり、データ転送を少なくするようなアルゴリズムを適用 • データ並列 ◦ 複数のプロセスそれぞれに同じニューラルネットワークモデルを複製して、それらに対して分割した入力デ ータを計算させる方法 ◦ 各データはそれぞれのプロセスで計算され、通常はパラメータの更新時に各プロセスを同期 • モデル並列 ◦ 1つのニューラルネットワークモデルに対し複数のプロセスを割り当てて計算させる方法 ◦ 1台のコンピュータでは扱いきれないような巨大なパラメータを持つモデルでも複数のコンピュータを使って 演算処理が可能 ◦ 実装が煩雑でプロセス間のデータ通信量がボトルネックになりやすいという欠点がある • 最近の深層学習フレームワークの多くが分散並列処理の機能を有している ◦ PyTorch ◦ TensorFlow 55
Copyright © Fixstars Group さらなる高速化 • 畳み込み演算の高速化 ◦ 高速フーリエ変換(FFT) ◦
Winogradアルゴリズム ◦ NVIDIA cuDNNライブラリで実装 • 枝刈り ◦ ネットワークモデルのパラメータが0に近いなど、計算結果に影響が小さいと判断される要素を省き疎行列にすること ◦ データサイズが小さくなることで計算量が少なくなり高速化が期待される • 量子化 ◦ 小さいビット数で表現することでデータサイズを小さくする ◦ 近年では16 ビットで表現される半精度浮動小数点演算を搭載したハードウェアが登場 ◦ 半精度浮動小数点演算ではデータサイズが通常の半分になることから消費メモリが少なく済み、半精度演算に特化した GPUの機能により高速演算が可能 • 二値化 ◦ 重みなどを1ビットとして扱うことで、使用メモリ量の削減と演算速度の高速化が期待 ◦ ハードウェア的にメモリ制約が厳しいFPGAやエッジデバイス上で顕著な効果が見込まれる 56
Copyright © Fixstars Group まとめ「高速化×深層学習×GPU」 • 高速化×深層学習 ◦ 高速化の目的や対象、環境などにより、様々な手段や方法がある ◦
深層学習は様々な状況で利用されており、高速化についても多様な方法がある ◦ 深層学習は現実的な時間で実行可能な方法を備えているが、それでも膨大な計算量を処理す るためにさらなる高速化が求められている • 深層学習×GPU ◦ GPUは深層学習に対する高速化に大きく寄与している ◦ GPUは深層学習に特化した複数の機能を組み込んでいる ◦ 目的とコストの観点からも、現状では深層学習の実用化に必須のデバイスとなっている 57
Copyright © Fixstars Group Thank you! お問い合わせ窓口 :
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Copyright © Fixstars Group Thank you! お問い合わせ窓口 : [email protected]](https://files.speakerdeck.com/presentations/9a41b43b29094e5a83e7efeccd328d1a/slide_57.jpg){kind=link}