Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
実践的!FPGA開発セミナー vol.7
Search
株式会社フィックスターズ
August 09, 2022
Programming
870
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
実践的!FPGA開発セミナー vol.7
2022年2月24日実施の「実践的!FPGA開発セミナー vol.7」の当日資料です。
株式会社フィックスターズ
August 09, 2022
More Decks by 株式会社フィックスターズ
See All by 株式会社フィックスターズ
コンピュータービジョンセミナー5 / 3次元復元アルゴリズム Multi-View Stereo の CUDA高速化
fixstars
0
1.2k
Kaggle_スコアアップセミナー_DFL-Bundesliga_Data_Shootout編/Kaggle_fixstars_corporation_20230509
fixstars
1
1.2k
実践的!FPGA開発セミナーvol.21 / FPGA_seminar_21_fixstars_corporation_20230426
fixstars
0
1.6k
量子コンピュータ時代のプログラミングセミナー / 20230413_Amplify_seminar_shift_optimization
fixstars
0
1.2k
実践的!FPGA開発セミナーvol.18 / FPGA_seminar_18_fixstars_corporation_20230125
fixstars
0
1k
実践的!FPGA開発セミナーvol.19 / FPGA_seminar_19_fixstars_corporation_20230222
fixstars
0
1.1k
実践的!FPGA開発セミナーvol.20 / FPGA_seminar_20_fixstars_corporation_20230329
fixstars
0
950
量子コンピュータ時代のプログラミングセミナー / 20230316_Amplify_seminar _route_planning_optimization
fixstars
0
920
量子コンピュータ時代のプログラミングセミナー / 20230216_Amplify_seminar _production_planning_optimization
fixstars
0
800
Other Decks in Programming
See All in Programming
壊れたパーサから始める関数型設計と構成的なパーサ #fp_matsuri
raiga0310
2
250
【やさしく解説 設計編・中級 #1】一つの車に、運転手は一人 ~ある倉庫システムの事例から~
panda728
PRO
0
180
『コードを書く以外の』エンジニアリング〜課金基盤移行プロジェクト推進のためのTips4選
yuriko1211
0
500
1年で人数1.5倍、PR数5.5倍増。 品質とアウトカムはどうなったか、 何が効いたか
ike002jp
0
140
Welcome to the "Parametricity" 🏙️ − Generic だけど Specific な世界 −
guvalif
PRO
1
170
Even G2とAWSで推しのエージェントを召喚しよう!
har1101
1
170
音楽のための関数型プログラミング言語mimiumにおける多段階計算の活用
tomoyanonymous
1
330
言語を使う側から、作る側へ。 自作 Lisp で得た新たな気づき。
andpad
0
130
吝嗇家のためのAI活用 / AI development for miser - ChatGPT + Issue Driven Development
tooppoo
0
190
はてなアカウント基盤 State of the Union
cockscomb
1
1.3k
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
140
PHP初心者セッション2026 〜生成AIでは見えない裏側を知る:今だからLAMPを通して仕組みを学ぶ〜
kashioka
0
490
Featured
See All Featured
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
310
The agentic SEO stack - context over prompts
schlessera
0
850
SEO for Brand Visibility & Recognition
aleyda
0
4.6k
Lightning Talk: Beautiful Slides for Beginners
inesmontani
PRO
2
610
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
Tell your own story through comics
letsgokoyo
1
1k
The SEO Collaboration Effect
kristinabergwall1
1
510
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
A better future with KSS
kneath
240
18k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.4k
Java REST API Framework Comparison - PWX 2021
mraible
34
9.5k
Transcript
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group 実践的!FPGA開発セミナー vol.7 2022/02/24 18:00~
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group AI Engine を用いた アプリケーション開発
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Who I am
3 写真 Yuki MATSUDA 松田 裕貴 ソリューション第一事業部 リードエンジニア
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group 自己紹介 4 •
松田 裕貴 • FPGA エンジニア • 主に Xilinx FPGA を使用 • 略歴 • 2016年 4月 フィックスターズ入社 • FPGA による高解像度の画像処理 • ネットワーク処理のオフロード • AIE を用いた画像処理の高速化 • などを着手
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group 本日のセミナーの内容 5 •
Versal で新しく追加された AI Engine アーキテクチャの概説 • 本セミナーでは、通常の AI Engine (not AI Engine-ML) について取り扱います • サンプルアプリケーションとして FIR Filter の作り方を紹介し、 また、AI Engine の性能を引き出すためのチューニング方法も紹介
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Agenda 6 •
AIE のアーキテクチャ • AIE のプログラミング方法 • AIE を使ったサンプルアプリ: FIR Filter • naive な実装 • チューニング後の実装 • まとめ
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Versal ACAPとは 7
• Xilinx の新しいアーキテクチャのチップ • 従来の FPGA に以下のアップデートを実施 • チップ内に NoC(Network on Chip)の追加 → 配線効率上昇 • AI Engine の追加 / DSP の更新 (DSP58) → 演算効率向上 • DDR, CMAC, PCIe 等の ハードマクロ化 → PL リソースの削減 • その他色々 https://japan.xilinx.com/products/silicon-devices/acap/versal-ai-core.html
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Why AI Engine?
8 • FPGA を計算用のデバイスとして見た場合、 GPU 等の他チップと比べると次のようなメリット /デメリット • メリット • I/O との密結合 => 低レイテンシ • カスタムなパイプラインを組むことでの処理効率の向上 • デメリット • 再構成可能であるが故のロジック集積効率の悪さ • 特に演算器 (DSP) の集積率が低く、総演算性能が低い • DNN 等、最近は演算負荷が高い処理が増えている傾向 → 演算器を高密度に集約した AI Engine が FPGA に追加された https://japan.xilinx.com/support/documentation/white_papers/j_wp506-ai-engine.pdf
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AI Engine とは
9 • チップ上に搭載された新たな計算用エンジン • PL の開発とは異なり、C言語ベースの SW でプログラミングを行う • 複数のコアをメッシュ状に繋いだメニーコア • 各コアは VLIW の SIMD プロセッサ • 各コアに隣接したローカルメモリによる高帯域なメモリアクセス • キャッシュなどはなし => 演算器の密度を向上させられる • PL (Programmable Logic) と AXI4-Stream IF で密結合 → I/O とも PL を介して密結合が可能 → FPGA のメリットを維持しつつ、高い演算性能を達成 https://japan.xilinx.com/products/silicon-devices/acap/versal-ai-core.html
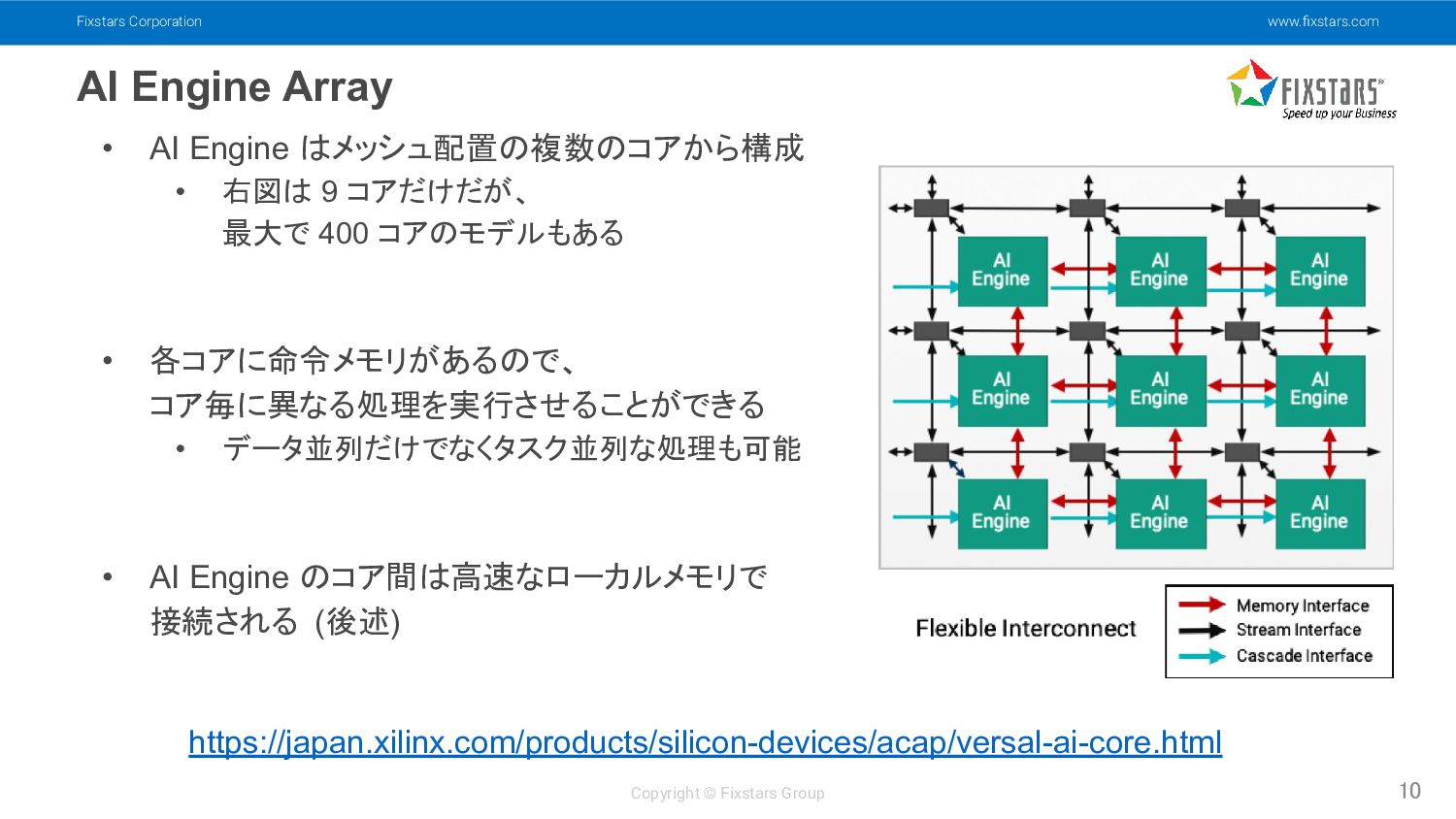
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AI Engine Array
10 • AI Engine はメッシュ配置の複数のコアから構成 • 右図は 9 コアだけだが、 最大で 400 コアのモデルもある • 各コアに命令メモリがあるので、 コア毎に異なる処理を実行させることができる • データ並列だけでなくタスク並列な処理も可能 • AI Engine のコア間は高速なローカルメモリで 接続される (後述) https://japan.xilinx.com/products/silicon-devices/acap/versal-ai-core.html
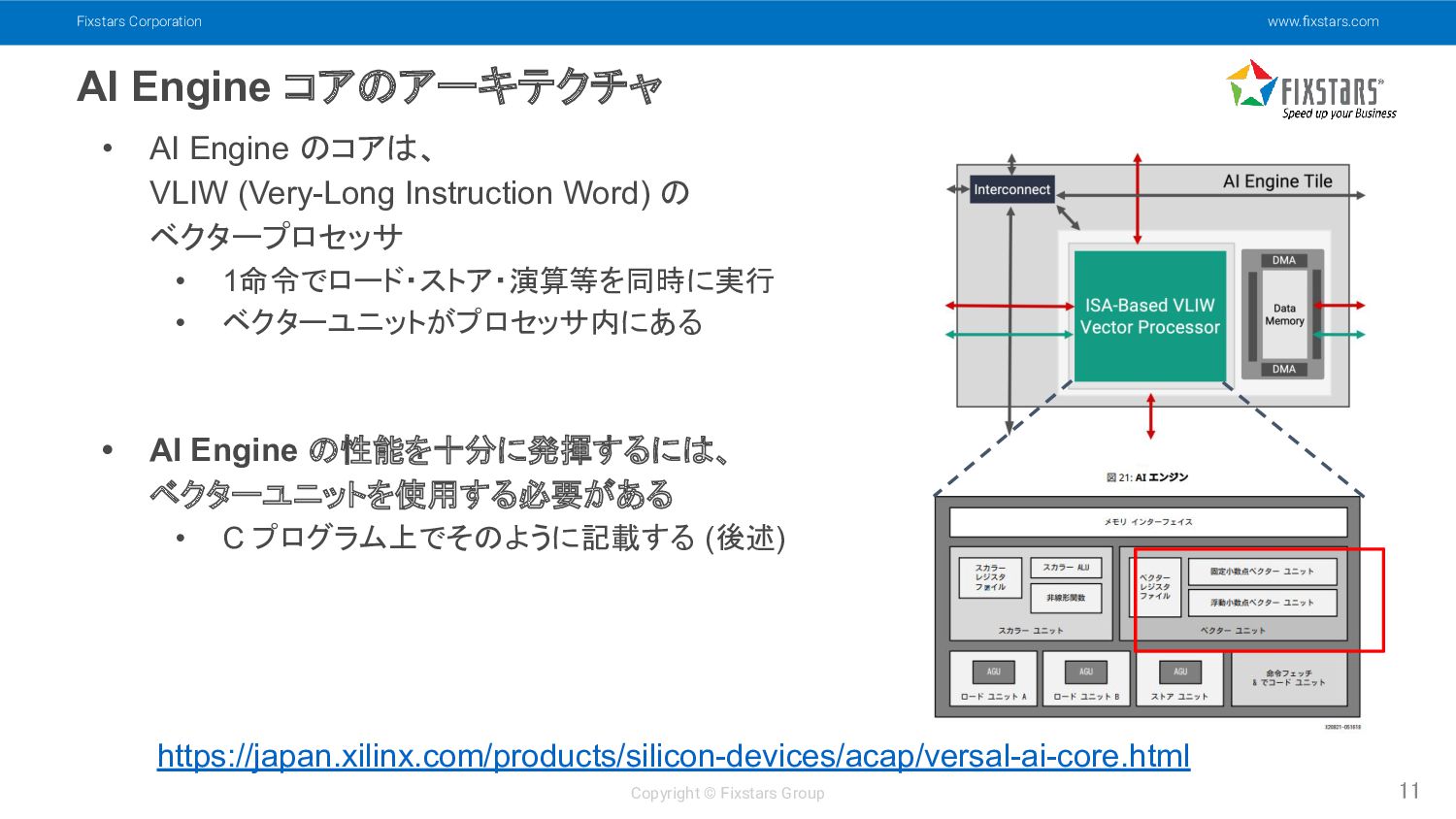
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AI Engine コアのアーキテクチャ
11 • AI Engine のコアは、 VLIW (Very-Long Instruction Word) の ベクタープロセッサ • 1命令でロード・ストア・演算等を同時に実行 • ベクターユニットがプロセッサ内にある • AI Engine の性能を十分に発揮するには、 ベクターユニットを使用する必要がある • C プログラム上でそのように記載する (後述) https://japan.xilinx.com/products/silicon-devices/acap/versal-ai-core.html
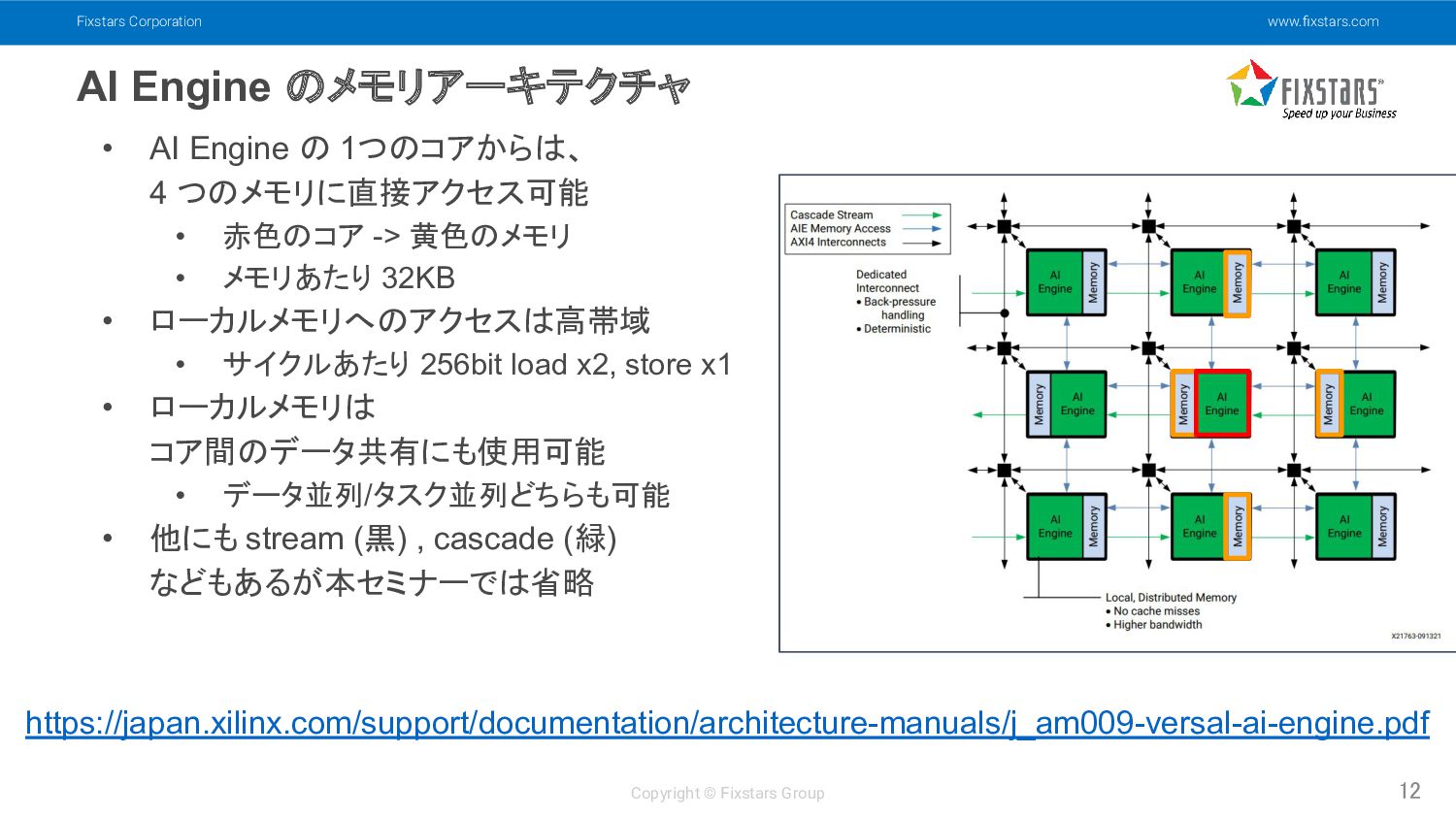
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AI Engine のメモリアーキテクチャ
12 • AI Engine の 1つのコアからは、 4 つのメモリに直接アクセス可能 • 赤色のコア -> 黄色のメモリ • メモリあたり 32KB • ローカルメモリへのアクセスは高帯域 • サイクルあたり 256bit load x2, store x1 • ローカルメモリは コア間のデータ共有にも使用可能 • データ並列/タスク並列どちらも可能 • 他にも stream (黒) , cascade (緑) などもあるが本セミナーでは省略 https://japan.xilinx.com/support/documentation/architecture-manuals/j_am009-versal-ai-engine.pdf
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AI Engine と外部とのインターフェース
13 • AI Engine へのインターフェース は以下の 2つ • GMIO: to/from DDR (NoC 経由) • PLIO: to/from PL (AXI4-Stream) • GMIO ではDDR へのブロックアクセスが可能 • ホストからアドレス, サイズを指定して転送する • PLIO では任意の PL Kernel とやり取りが可能 • プロトコルは AXIS 32bit/64bit/128bit • PL 上でデータを整形 (eg: 転置) し、 AIE には計算だけさせるような分担も可能 https://japan.xilinx.com/support/documentation/architecture-manuals/j_am009-versal-ai-engine.pdf
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Agenda 14 •
AIE のアーキテクチャ • AIE のプログラミング方法 • AIE を使ったサンプルアプリ: FIR Filter • naive な実装 • チューニング後の実装 • まとめ
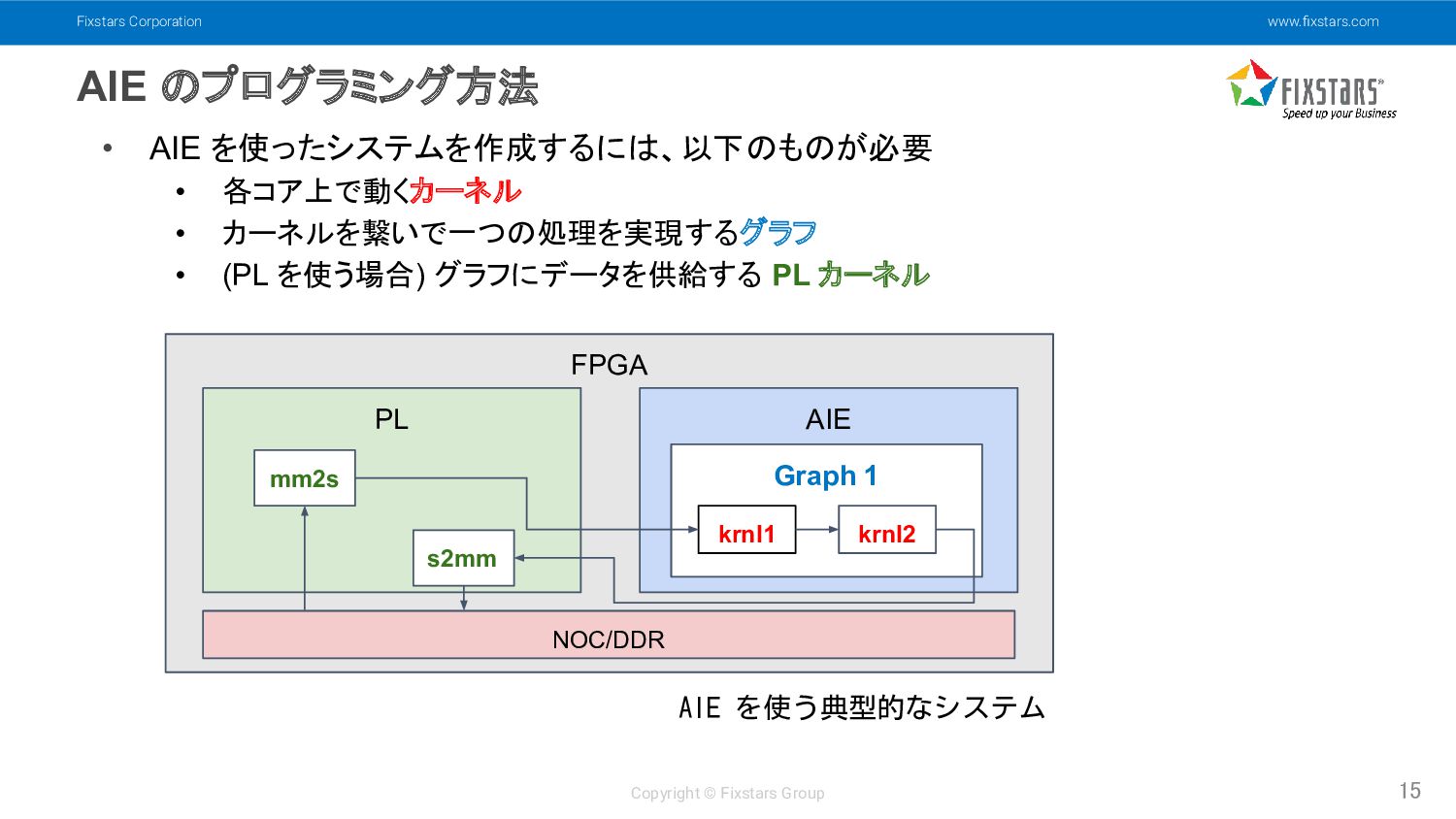
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AIE のプログラミング方法 15
• AIE を使ったシステムを作成するには、以下のものが必要 • 各コア上で動くカーネル • カーネルを繋いで一つの処理を実現するグラフ • (PL を使う場合) グラフにデータを供給する PL カーネル FPGA PL AIE NOC/DDR mm2s s2mm Graph 1 krnl1 krnl2 AIE を使う典型的なシステム
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group カーネル / グラフの作成
16 AIE Graph 1 krnl1 krnl2 カーネルの定義 入出力が特殊な以外は普通の C コード window は隣接したローカルメモリを表す グラフの定義 - adf::kernel::create でカーネル定義 - adf::connect でカーネル間/入出力を繋ぐ
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group カーネル / グラフの作成
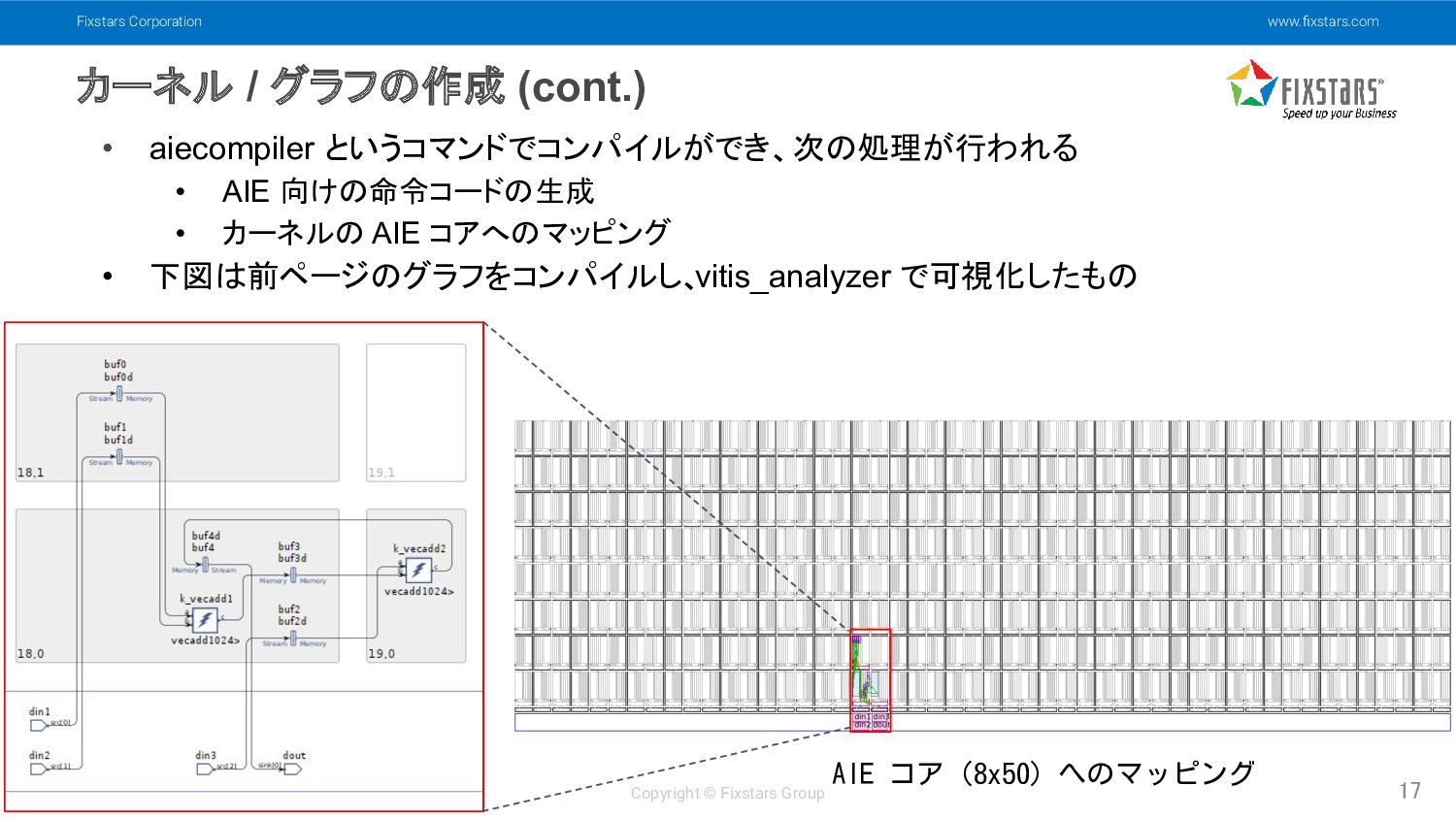
(cont.) 17 • aiecompiler というコマンドでコンパイルができ、次の処理が行われる • AIE 向けの命令コードの生成 • カーネルの AIE コアへのマッピング • 下図は前ページのグラフをコンパイルし、 vitis_analyzer で可視化したもの AIE コア (8x50) へのマッピング
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AIE と PL
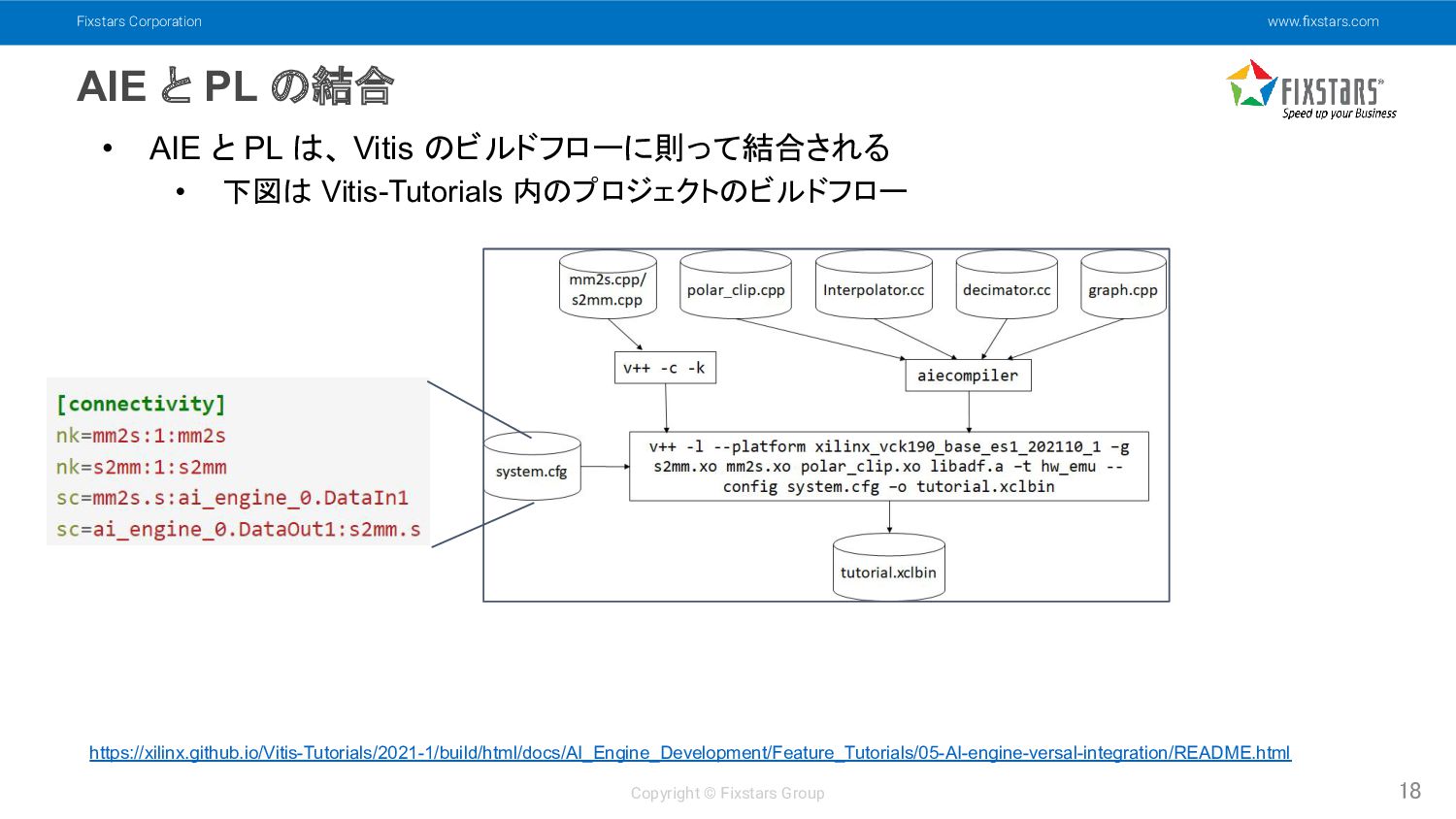
の結合 18 • AIE と PL は、 Vitis のビルドフローに則って結合される • 下図は Vitis-Tutorials 内のプロジェクトのビルドフロー https://xilinx.github.io/Vitis-Tutorials/2021-1/build/html/docs/AI_Engine_Development/Feature_Tutorials/05-AI-engine-versal-integration/README.html
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AIE と PL
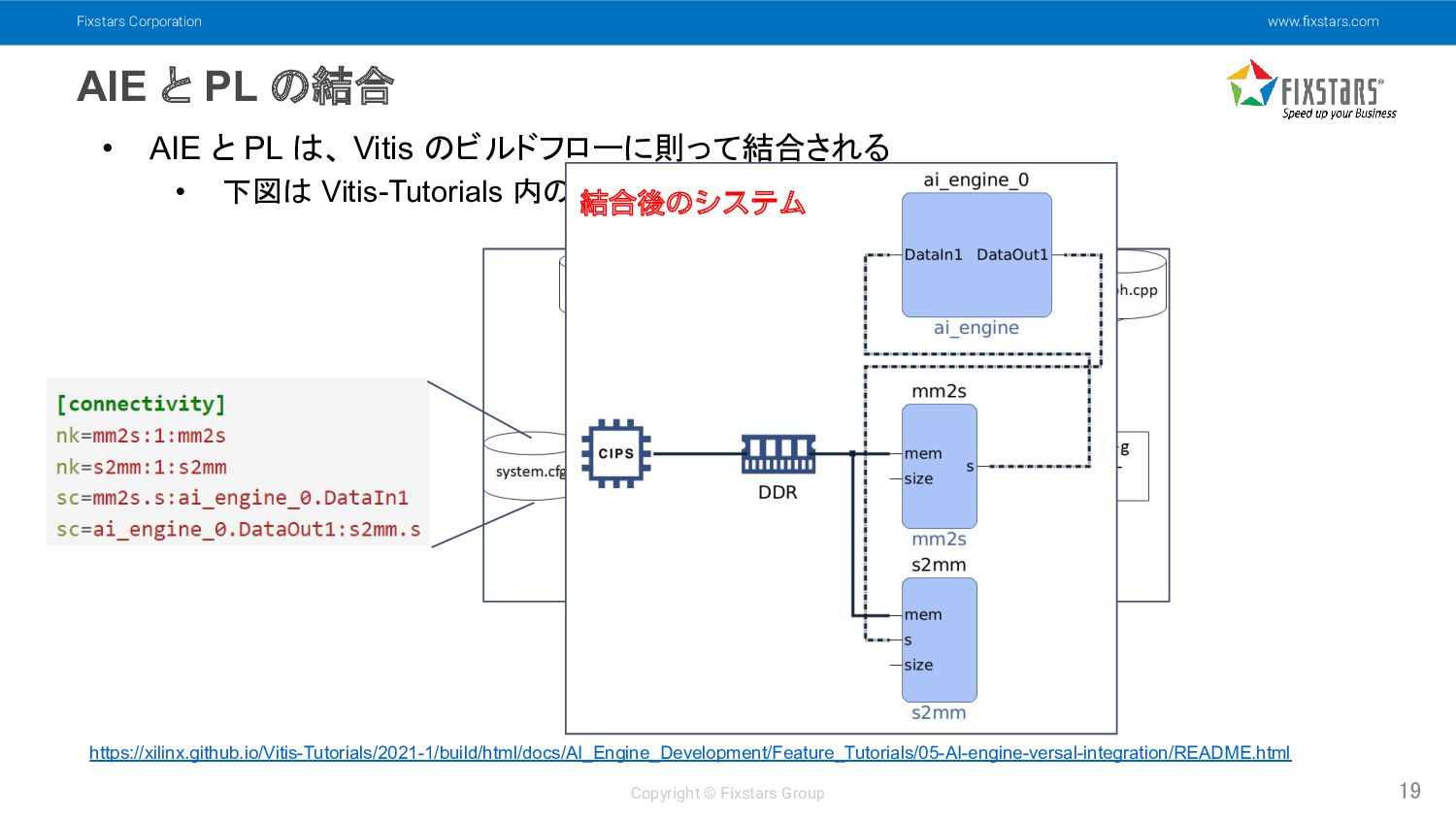
の結合 19 • AIE と PL は、 Vitis のビルドフローに則って結合される • 下図は Vitis-Tutorials 内のプロジェクトのビルドフロー https://xilinx.github.io/Vitis-Tutorials/2021-1/build/html/docs/AI_Engine_Development/Feature_Tutorials/05-AI-engine-versal-integration/README.html 結合後のシステム
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Agenda 20 •
AIE のアーキテクチャ • AIE のプログラミング方法 • AIE を使ったサンプルアプリ: FIR Filter • naive な実装 • チューニング後の実装 • まとめ
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FIR Filter on
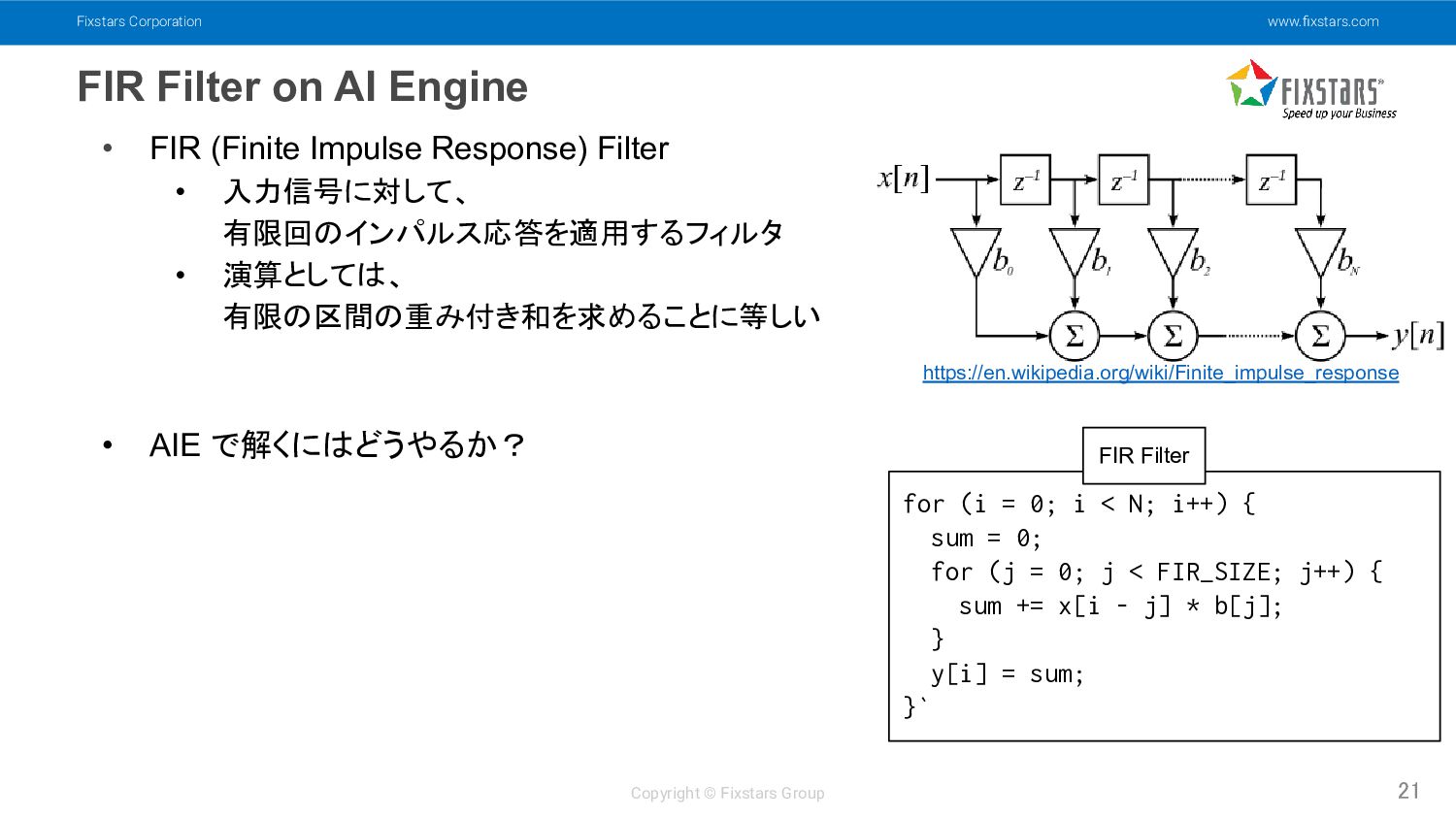
AI Engine 21 • FIR (Finite Impulse Response) Filter • 入力信号に対して、 有限回のインパルス応答を適用するフィルタ • 演算としては、 有限の区間の重み付き和を求めることに等しい • AIE で解くにはどうやるか? for (i = 0; i < N; i++) { sum = 0; for (j = 0; j < FIR_SIZE; j++) { sum += x[i - j] * b[j]; } y[i] = sum; }` FIR Filter https://en.wikipedia.org/wiki/Finite_impulse_response
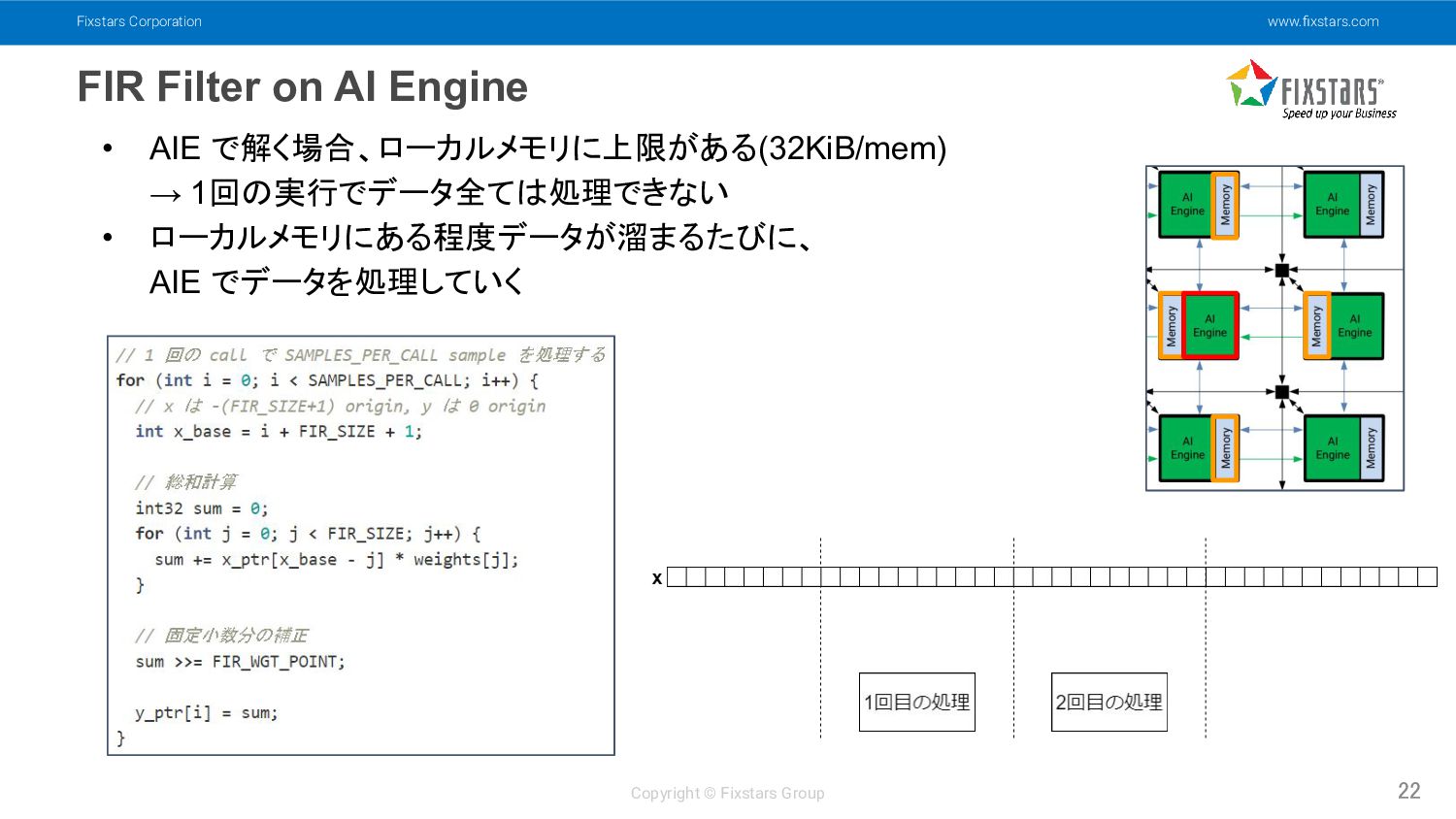
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FIR Filter on
AI Engine 22 • AIE で解く場合、ローカルメモリに上限がある (32KiB/mem) → 1回の実行でデータ全ては処理できない • ローカルメモリにある程度データが溜まるたびに、 AIE でデータを処理していく
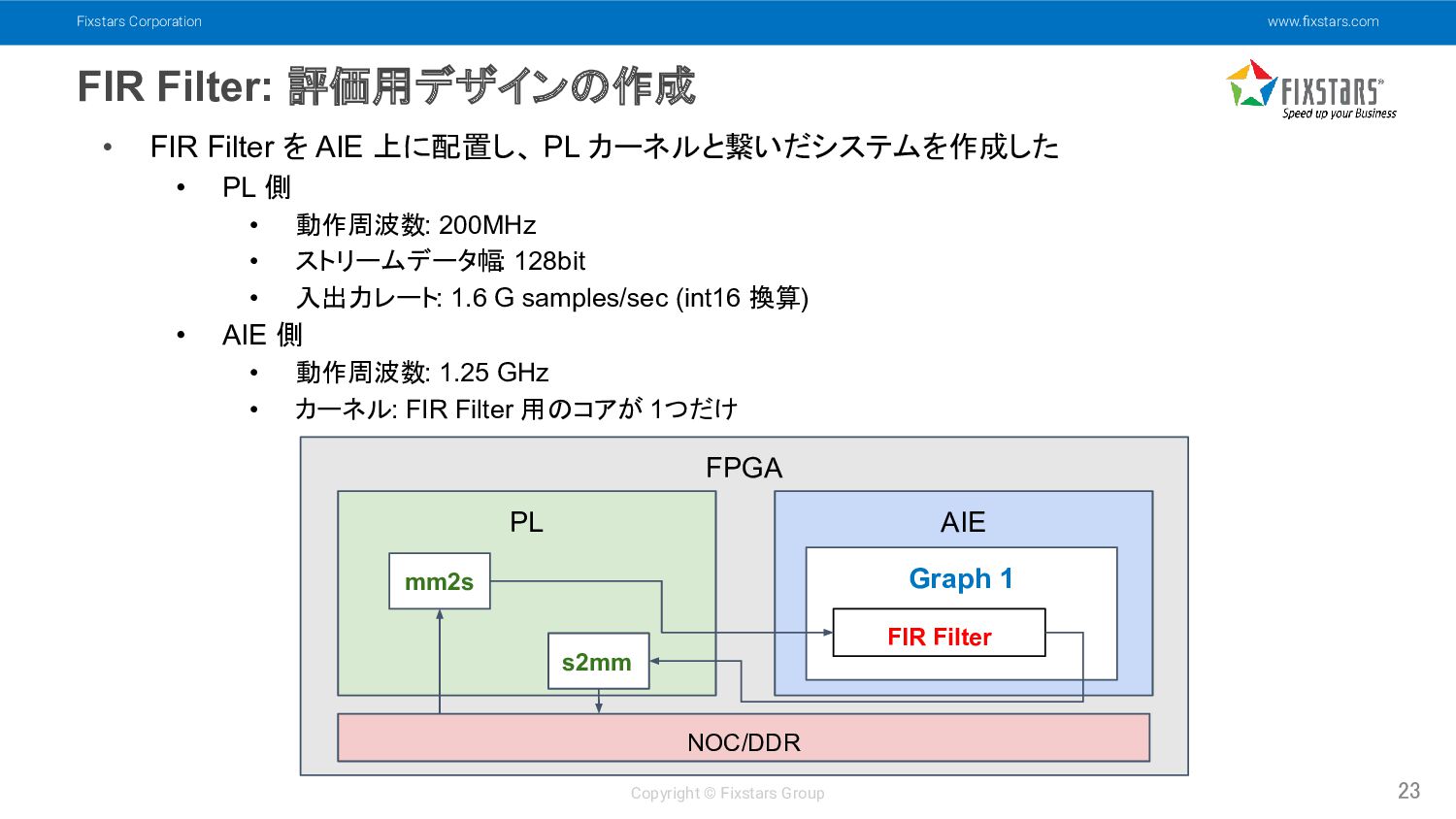
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FIR Filter: 評価用デザインの作成
23 • FIR Filter を AIE 上に配置し、 PL カーネルと繋いだシステムを作成した • PL 側 • 動作周波数: 200MHz • ストリームデータ幅: 128bit • 入出力レート: 1.6 G samples/sec (int16 換算) • AIE 側 • 動作周波数: 1.25 GHz • カーネル: FIR Filter 用のコアが 1つだけ FPGA PL AIE NOC/DDR mm2s s2mm Graph 1 FIR Filter
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FIR Filter: 実機での実行結果
24 • 以下のパラメータで FIR (Finite Impulse Response) Filter を実行した • 入力: 4M samples / int16 • 出力: 4M samples / int16 • フィルタサイズ: 63 • 実行結果 • AIE は naive な実装だと全然速くないので、 SIMD 化が重要になる 実装 実行時間 処理レート (samples/sec) 処理レート (cycles/sample) naive 実装 1888.16 ms 2.22 Msamples / sec 562.71
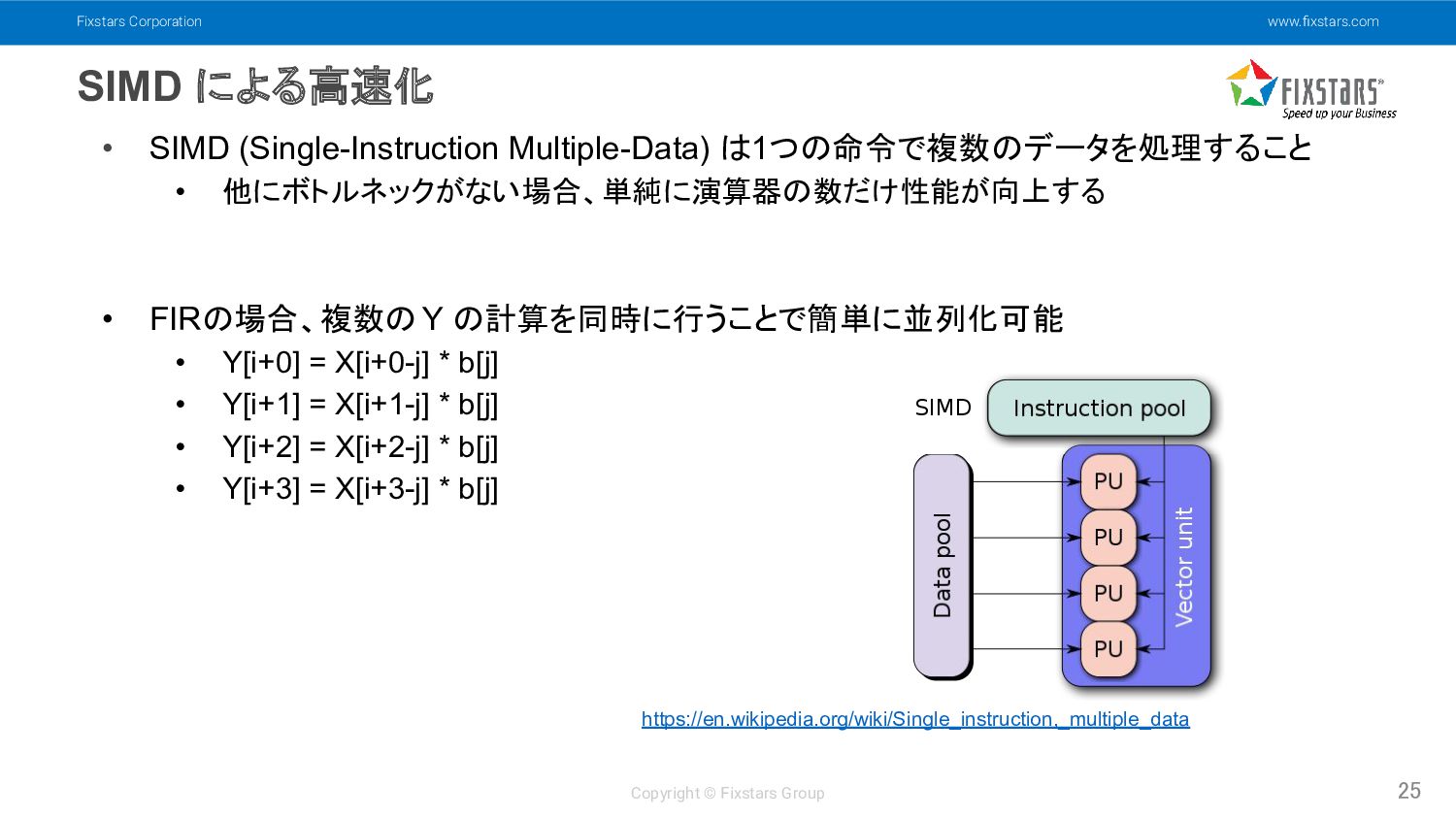
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group SIMD による高速化 25
• SIMD (Single-Instruction Multiple-Data) は1つの命令で複数のデータを処理すること • 他にボトルネックがない場合、単純に演算器の数だけ性能が向上する • FIRの場合、複数の Y の計算を同時に行うことで簡単に並列化可能 • Y[i+0] = X[i+0-j] * b[j] • Y[i+1] = X[i+1-j] * b[j] • Y[i+2] = X[i+2-j] * b[j] • Y[i+3] = X[i+3-j] * b[j] https://en.wikipedia.org/wiki/Single_instruction,_multiple_data
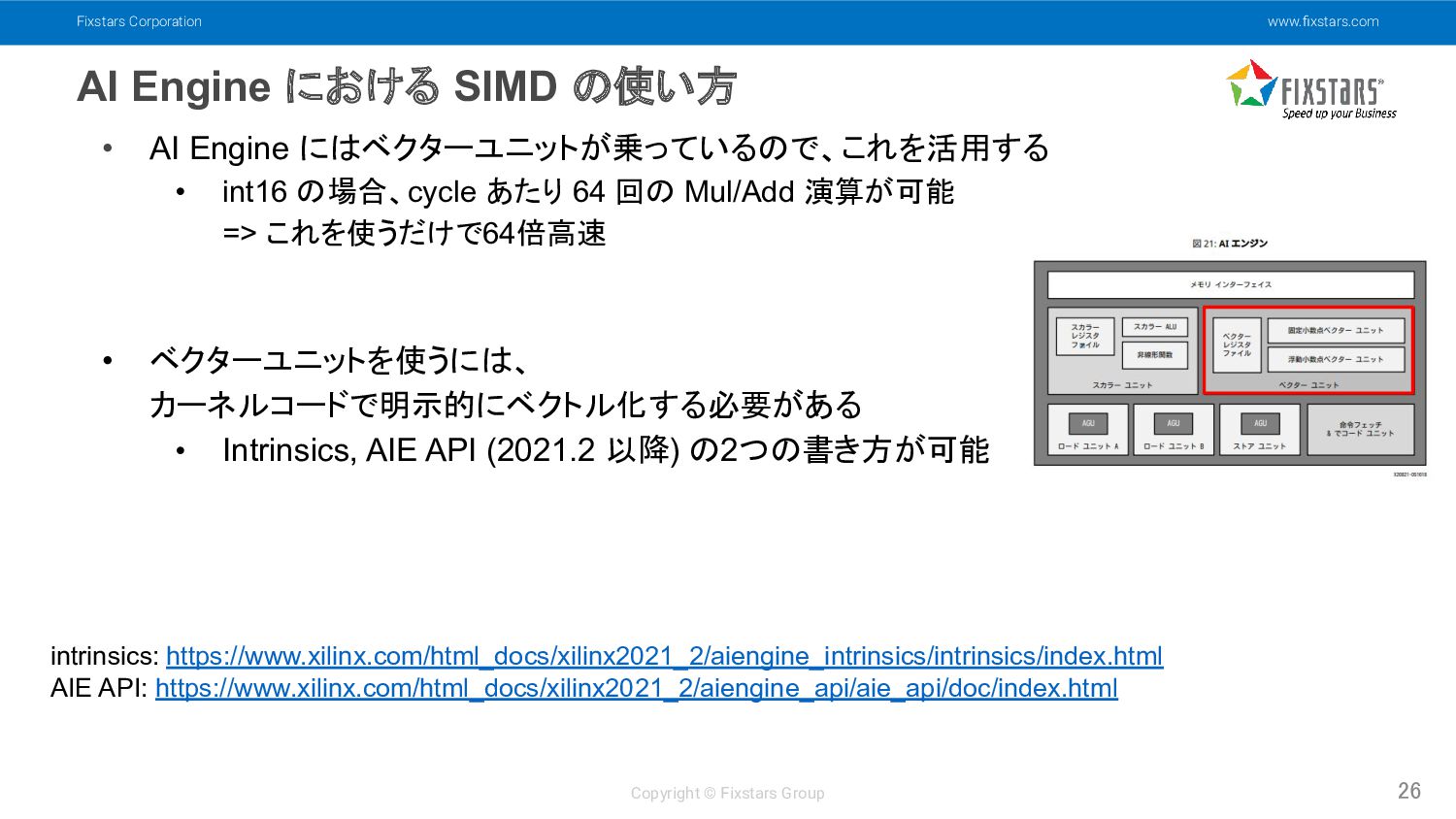
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group AI Engine における
SIMD の使い方 26 • AI Engine にはベクターユニットが乗っているので、これを活用する • int16 の場合、cycle あたり 64 回の Mul/Add 演算が可能 => これを使うだけで64倍高速 • ベクターユニットを使うには、 カーネルコードで明示的にベクトル化する必要がある • Intrinsics, AIE API (2021.2 以降) の2つの書き方が可能 intrinsics: https://www.xilinx.com/html_docs/xilinx2021_2/aiengine_intrinsics/intrinsics/index.html AIE API: https://www.xilinx.com/html_docs/xilinx2021_2/aiengine_api/aie_api/doc/index.html
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FIR Filter on
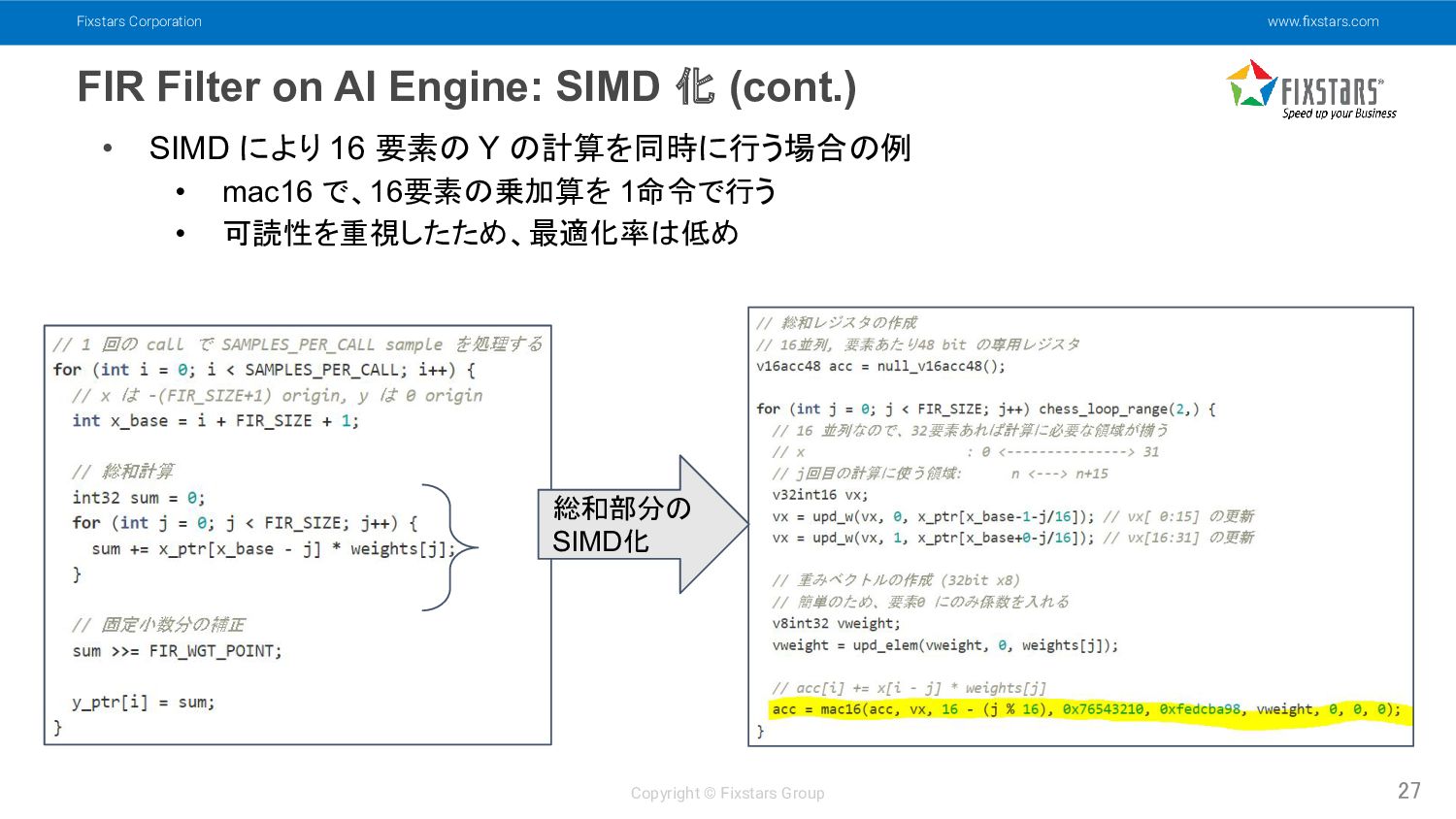
AI Engine: SIMD 化 (cont.) 27 • SIMD により 16 要素の Y の計算を同時に行う場合の例 • mac16 で、16要素の乗加算を 1命令で行う • 可読性を重視したため、最適化率は低め 総和部分の SIMD化
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FIR Filter on
AI Engine: SIMD 化 (cont.) 28 • SIMD 化後の処理性能 • 8倍弱程度の性能向上 • 演算器の性能としては SIMD の あり/なしで 64倍ほど性能が変わるので、 ちゃんとチューニングすればもう 8倍くらいは達成の余地あり • SIMD の あり / なしで劇的に性能が変わるため、 ちゃんと適用していくことが大事 実装 実行時間 処理レート (samples/sec) 処理レート (cycles/sample) naive 実装 1888.16 ms 2.22 Msamples / sec 562.71 SIMD 版 254.609 ms 16.47 Msamples / sec 75.90
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FIR Filter on
AI Engine: その他チューニング 29 • 今回は 1 コアしか使っていないが、AIE はコア数が膨大なため、 複数コアを使うと当然性能は向上する • 今回は複数コアまでは行えず • データ並列、タスク並列性などを抽出していくのが大事 • とはいっても、カーネル毎のチューニングとか 複数コアに載せるとか一からやっていくのは大変 ... → Xilinx 提供のライブラリを使いましょう
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Xilinx 提供のライブラリ 30
• AI (DNN) 処理 • Vitis-AI で DPU が提供されている • https://github.com/Xilinx/Vitis-AI • AI 処理以外 • Vitis Libraries にいくつかのライブラリが提供されている • https://xilinx.github.io/Vitis_Libraries/ • DSP / Vision のライブラリが現在提供されている • 今回実装した FIR も Vitis Libraries 内にあります
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group まとめ 31 •
AI Engine は FPGA のいいところを残しつつ 演算性能を強化できる面白いアーキテクチャ • PL との密結合 • VLIW SIMD プロセッサで構成されるメニーコア • AI Engine の性能を十分に引き出すには、 AI Engine 側のプログラムのチューニングがかなり重要 • SIMD の使用 • 複数コアの使用 • データ並列 • タスク並列 • PL 側で AIE が処理しやすいような形に整形するのも大事 • AI Engine のチューニングは大変なので Vitis Libraries 等を活用していくのも大事
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group Alveo!でLinuxを動かす
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Who I am
33 写真 Kenta IDA 井田 健太 ソリューション第一事業部 シニアエンジニア
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group FPGA上でLinuxを動かす(再掲) 34 •
Linuxで動作する豊富なソフトウェア資産を使いたい • e.g. ドライバ、ネットワークスタック、ライブラリ • 現実的には、各FPGAベンダーのCPU内蔵FPGA製品を使う • Xilinx: Zynq等, Intel: Cyclone V SoC等 • CPU内蔵ではないFPGAの場合 • 各社が提供するソフトCPUコアを使う • Xilinx: Microblaze (MMU構成) • Intel: Nios II/f • ベンダが提供する方法に従えば、比較的簡単に動作する
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group ベンダ提供ツールが用意してくれるもの(再掲) 35 •
ベンダ提供のLinux環境構築ツールは様々なものを自動的に用意してくれる • ハードウェア構成を表すデバイスツリー • ファームウェアをロードして実行するブートローダー • デバイスツリーに基づいて 基本的なハードウェアの初期化を行うファームウェアやセカンドブートローダー • 対象のハードウェア上で動作するように設定されたLinuxカーネルイメージ • システムの動作に必要なものが含まれているルートファイルシステムイメージ • 上記のものに含まれるプログラムをコンパイルするための クロスコンパイル用ツールチェイン • ターゲット上のプログラムをデバッグするためのデバッガ • ベンダはYocto Projectや YoctoをカスタマイズしたものをLinux環境構築ツールとして提供 • Xilinx: PetaLinux
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group RISC-VのCPUコア(再掲) 36 •
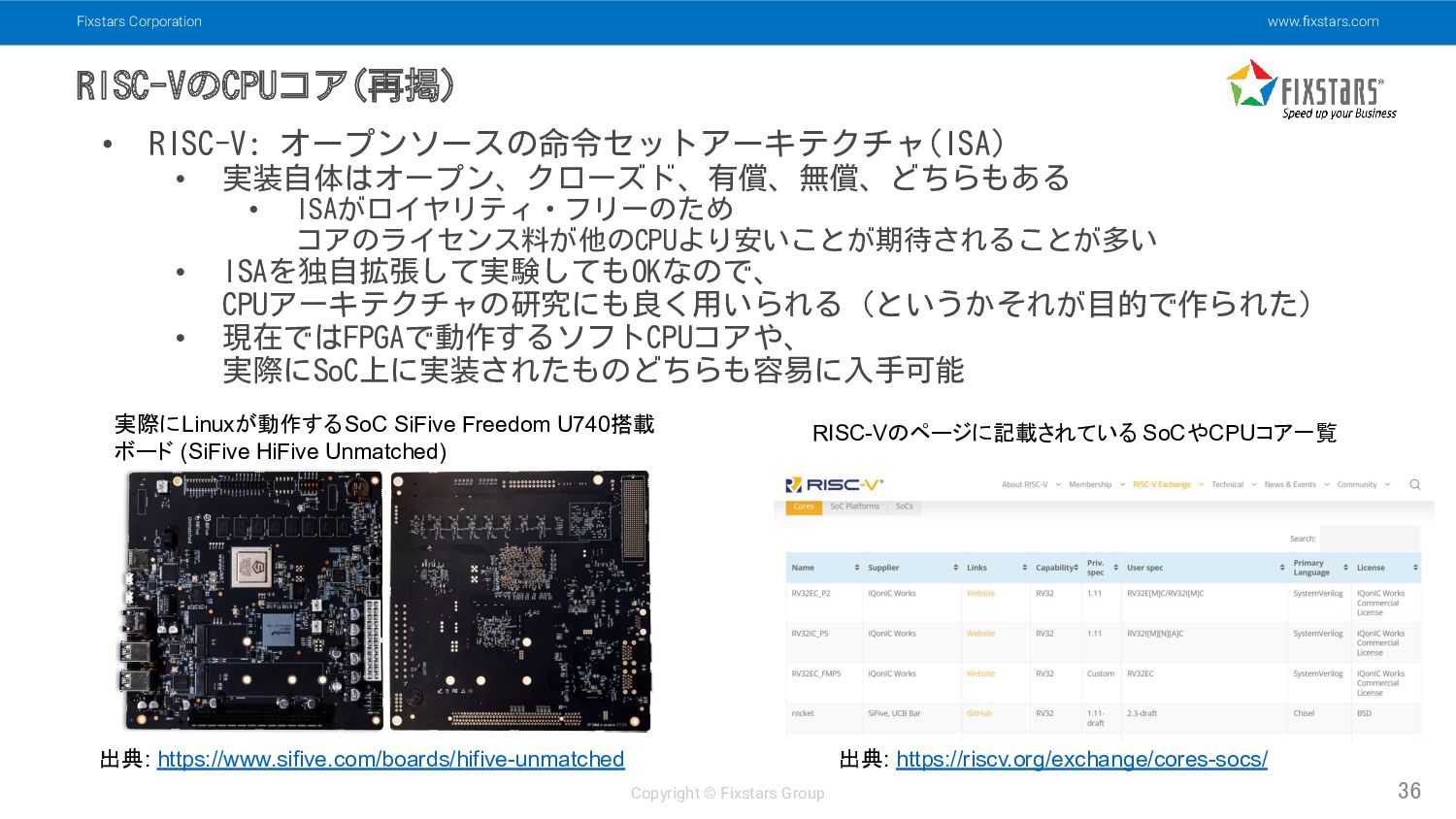
RISC-V: オープンソースの命令セットアーキテクチャ(ISA) • 実装自体はオープン、クローズド、有償、無償、どちらもある • ISAがロイヤリティ・フリーのため コアのライセンス料が他のCPUより安いことが期待されることが多い • ISAを独自拡張して実験してもOKなので、 CPUアーキテクチャの研究にも良く用いられる (というかそれが目的で作られた) • 現在ではFPGAで動作するソフトCPUコアや、 実際にSoC上に実装されたものどちらも容易に入手可能 出典: https://www.sifive.com/boards/hifive-unmatched 実際にLinuxが動作するSoC SiFive Freedom U740搭載 ボード (SiFive HiFive Unmatched) RISC-Vのページに記載されている SoCやCPUコア一覧 出典: https://riscv.org/exchange/cores-socs/
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Linuxの動作に必要な機能 (再掲) 37
• 最低限の命令セットサポート • RISC-V 32bitの基本命令 (I) • 乗算命令 (M) • アトミック命令 (A) • 圧縮命令 (C) は必須ではない (カーネルの設定で無効化可能) • MMUによる仮想メモリのサポート • 厳密にはMMU無しの構成も可能だが、実用性に欠く • タイマーによる時刻取得と指定時刻での割り込み • スケジューリングに必要
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Linuxの動作に必須ではないがほしい機能 (再掲) 38
• コンソール入出力 • フレームバッファによるコンソール出力、キーボードによる入力 • シリアル(UART)通信による入出力 • デバッガ接続機能 • トラブルシューティングにデバッガが無いとかなりキビシイ • FPGAなので内部信号の観測ロジックなどを埋め込め無くはないが非効率的 • 比較的高速なOSイメージの転送手段 • ルートファイルシステムやカーネルのイメージを何度も更新するので
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VexRiscv (再掲) 39
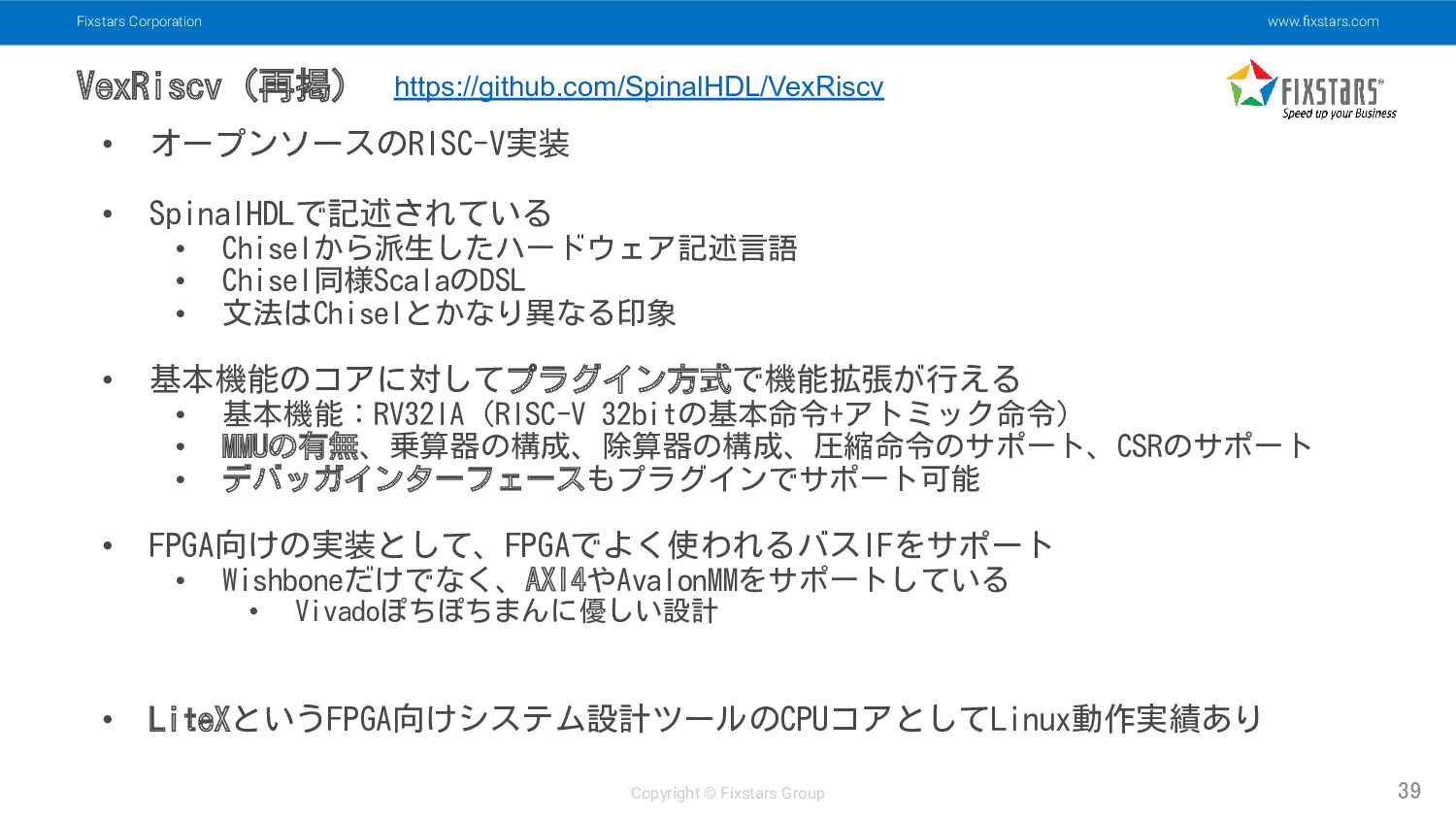
• オープンソースのRISC-V実装 • SpinalHDLで記述されている • Chiselから派生したハードウェア記述言語 • Chisel同様ScalaのDSL • 文法はChiselとかなり異なる印象 • 基本機能のコアに対してプラグイン方式で機能拡張が行える • 基本機能:RV32IA (RISC-V 32bitの基本命令+アトミック命令) • MMUの有無、乗算器の構成、除算器の構成、圧縮命令のサポート、CSRのサポート • デバッガインターフェースもプラグインでサポート可能 • FPGA向けの実装として、FPGAでよく使われるバスIFをサポート • Wishboneだけでなく、AXI4やAvalonMMをサポートしている • Vivadoぽちぽちまんに優しい設計 • LiteXというFPGA向けシステム設計ツールのCPUコアとしてLinux動作実績あり https://github.com/SpinalHDL/VexRiscv
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group 対象のボード 40 •
Alveo U50 (今回はちゃんとAlveo U50!) • PCIe Gen3x16 or Gen4x8接続のアクセラレータカード • QSFP28スロットを1つ搭載 (写真はES品なのでSFP-DD2つになっている) • 100GbEが使える • 標準でVitisによる開発フローをサポート • HBM 8[GiB]搭載 • 4[GiB]のブロック x2 • LUT 872J, FF 1743K, DSP 5952 • (参考)前回使ってたボード↓ • LiteFury (https://github.com/RHSResearchLLC/NiteFury-and-LiteFury) • Artix-7 XC7A100T-L2FGG484EとDDR3 256[MiB]搭載したFPGAボード • M.2 2280 M key形状 • PCIe Gen2 x4接続可能 出典: https://github.com/RHSResearchLLC/NiteFury-and-LiteFury
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group システム構成 41 •
前回LiteFuryに入れた時と同じ • クロックだけ125[MHz]→300[MHz] • ターゲット • CPUコア:VexRiscv@300[MHz] MMUあり構成 • メモリ :HBM (256[MiB]) • タイマー:ACLINTのうちタイマー機能を最低限実装 (IPIはなし) • UART: Xilinx AXI UART 16550 • デバッグ • JTAG信号生成:AXI GPIO (ホストCPU制御) • UART: Xilinx AXI UART 16550 • ホストインターフェース • XDMA (Vitis Platform Shell側)
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Alveo向けデザインの開発フロー 42 •
2つの開発フローをサポート • Vivadoフロー • Vitisフロー • Vivadoフロー • 従来の、RTLやIP Integratorを用いたIPベース設計によるフロー • フルカスタムの設計が可能 • Vitisフローに比べて手間がかかる (ということになっている) • ホストとの通信機能の実装など • Vitisフロー • Vitisを用いたHLSを軸としたアクセラレータ開発フロー • ボードごとに用意されたシェル上で、目的とする演算を行うカーネルをHLSで開発 • ホストからカーネルをPCIe経由で書き換える機能が標準で提供される • カーネルへのデータ転送などはシェル側の機能で行う • XRTと呼ばれるホスト側のランタイム環境が標準で提供される • カーネルの起動やデータ転送はXRTの関数を呼べば実行できる
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Vitisフローの利点 43 •
開発が楽になるかどうか…は内容によるので置いておく • PCIe経由での安全なコンフィグレーション機能が便利 • PCIeを扱うデザインの開発時… • 誤操作でPCIeコアがハングアップ、そのままホストも一緒にフリーズ • リモートワーク中だと、誰かに再起動をお願いすることに… • Vitis (というかXRT) の場合 • PCIeコア自体はユーザーが開発する部分の外側にある • Xilinxが提供するシェルと呼ばれるデザインに含まれている • ユーザーのカーネルはシェルのPRリージョンにPRでコンフィグレーションされる • PCIeコア周辺にAXI Firewall等のハングアップ対策コアが入っている • AXI FIrewall: スレーブ側が応答を返さないなどの場合、 タイムアウトしてダミー応答を返すIP • XRT管理コマンド経由でカーネルのリセットをアサートしたりできる • 復帰する仕組みが初めから用意されている
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VexRiscvはVitisフローでうごかせるのか? 44 •
動かせる • VitisにはHLSで記述したカーネルだけでなく、RTLで記述したカーネルもサポート • そのまま、RTLカーネルと呼ばれる • ただし、何でもRTLカーネルに出来るわけではなく、いくつかの制約がある • このあたりは UG1393 に記載されている • ポート (インターフェース) • クロック入力 • リセット入力 (Active Low) • 割り込み出力 (Active High) • AXI4 Lite Slave • ホストからのレジスタアクセス • AXI4 Master • FPGA上のメモリへのアクセス • AXI4 Stream (Master/Slave) • ホスト-カーネル間や、カーネル-カーネル間の通信 UG1393: https://docs.xilinx.com/r/en-US/ug1393-vitis-application-acceleration/RTL-Kernels
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Vitisにおけるカーネルの実行制御 45 •
AXI4 Lite Slaveの制御レジスタによる制御 • HLSで出てくる ap_ctrl_hs と同様 • Controlレジスタ(右図) での実行制御 • ap_startに1を書き込んで実行開始 • 0x10番地移行はカーネルのパラメータ用に使用 • カーネルのAXI Masterが使用するFPGA側メモリのアドレス指定にも利用 • void kernel(const uint32_t* in, uint32_t* out); とすれば in と out のFPGA上メモリのアドレスがレジスタに設定される • …という約束を守る以外にも、 User Managed RTL Kernel というものがある UG1393: https://docs.xilinx.com/r/en-US/ug1393-vitis-application-acceleration/RTL-Kernels
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group User Managed RTL
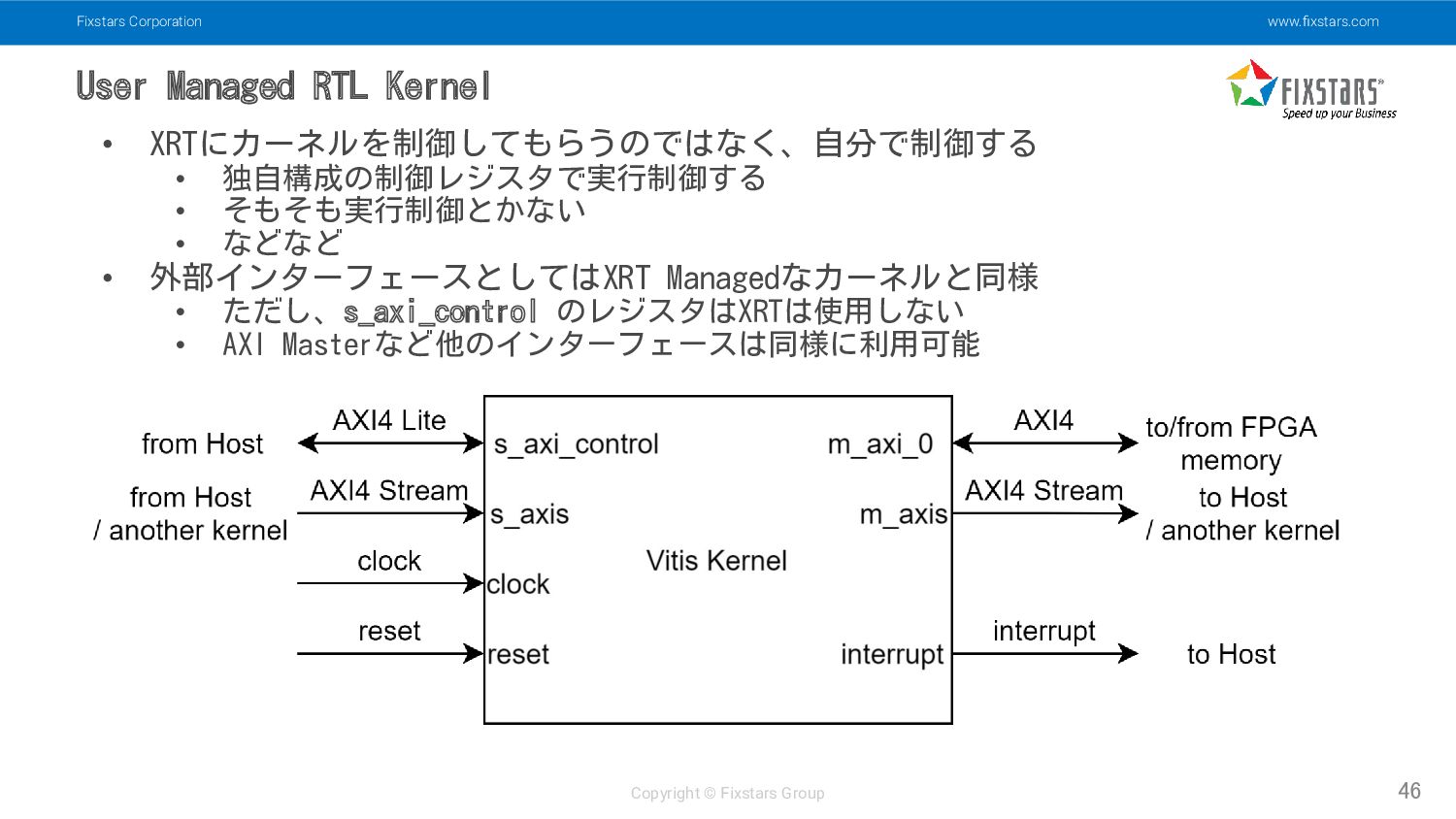
Kernel 46 • XRTにカーネルを制御してもらうのではなく、自分で制御する • 独自構成の制御レジスタで実行制御する • そもそも実行制御とかない • などなど • 外部インターフェースとしてはXRT Managedなカーネルと同様 • ただし、s_axi_control のレジスタはXRTは使用しない • AXI Masterなど他のインターフェースは同様に利用可能
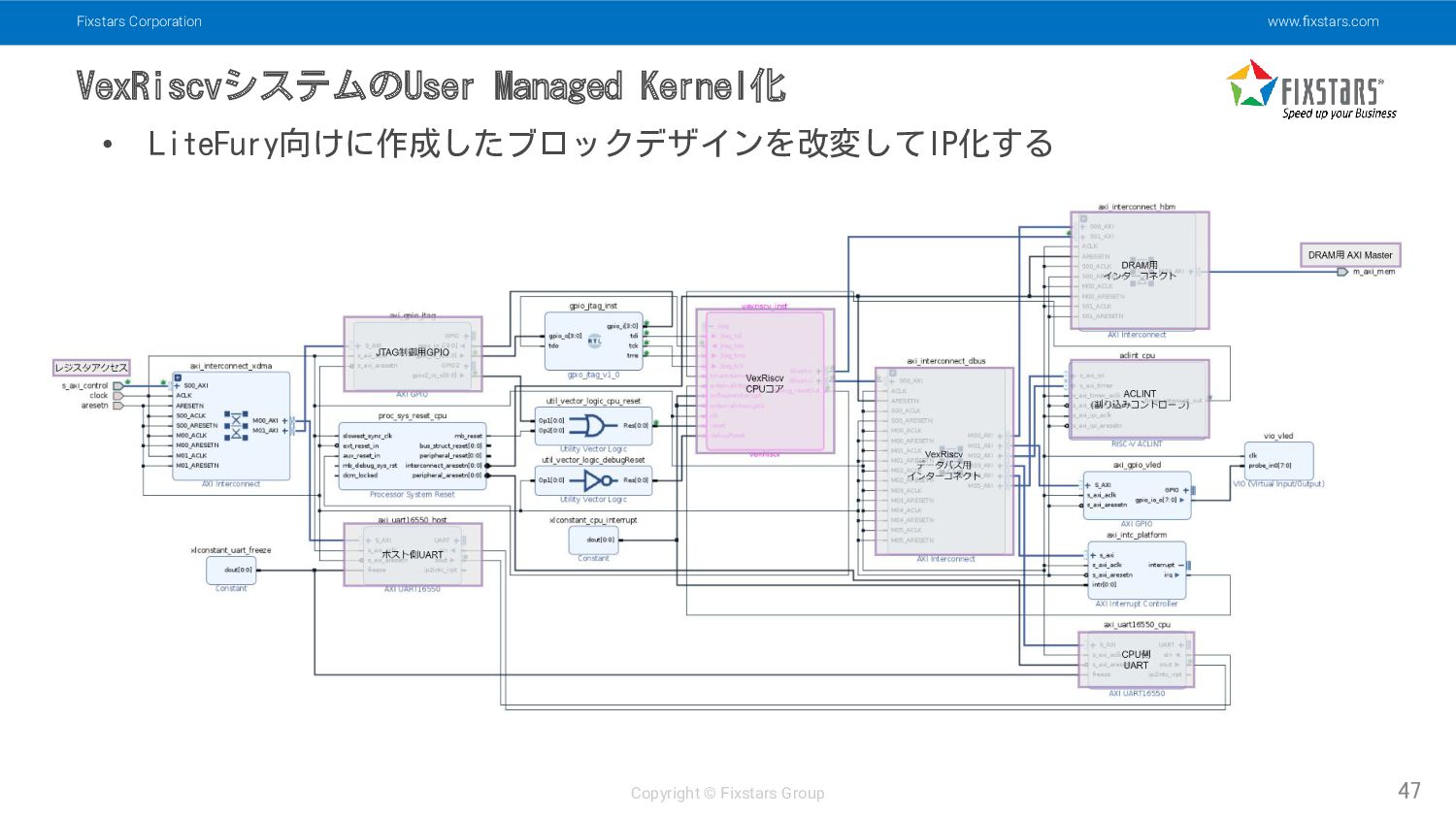
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VexRiscvシステムのUser Managed Kernel化
47 • LiteFury向けに作成したブロックデザインを改変してIP化する
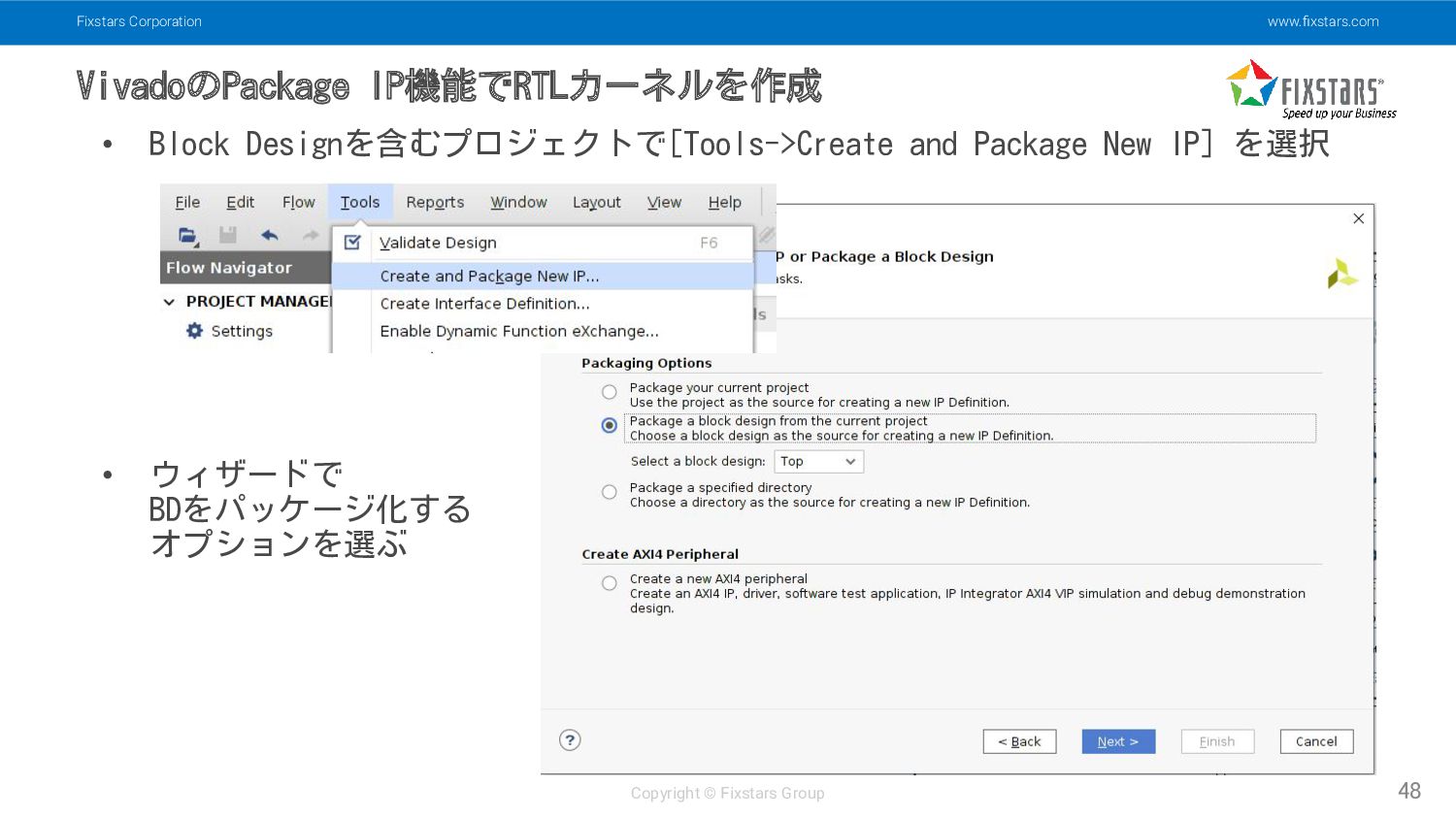
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VivadoのPackage IP機能でRTLカーネルを作成 48
• Block Designを含むプロジェクトで[Tools->Create and Package New IP] を選択 • ウィザードで BDをパッケージ化する オプションを選ぶ
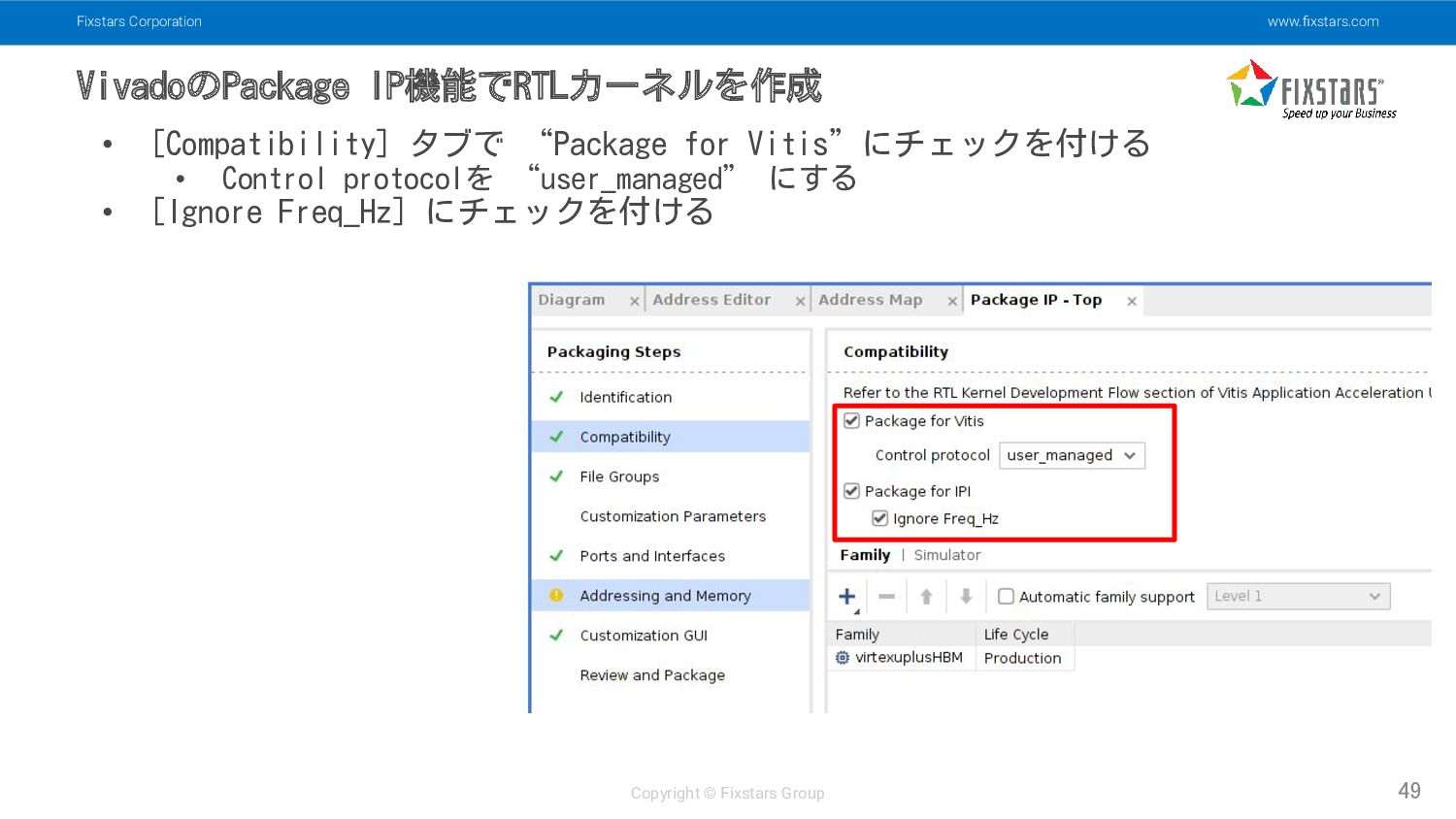
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VivadoのPackage IP機能でRTLカーネルを作成 49
• [Compatibility] タブで “Package for Vitis”にチェックを付ける • Control protocolを “user_managed” にする • [Ignore Freq_Hz] にチェックを付ける
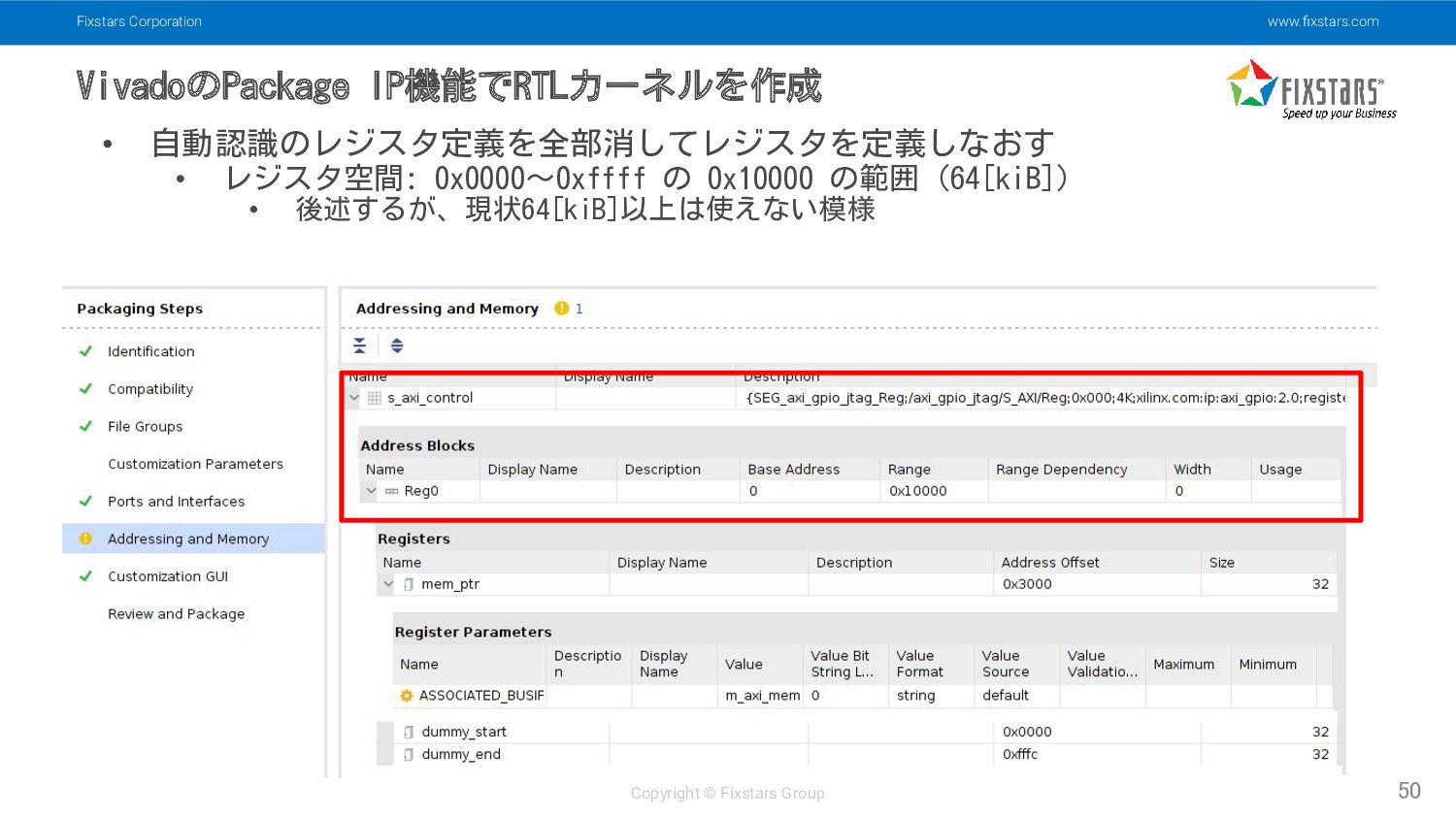
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VivadoのPackage IP機能でRTLカーネルを作成 50
• 自動認識のレジスタ定義を全部消してレジスタを定義しなおす • レジスタ空間: 0x0000~0xffff の 0x10000 の範囲 (64[kiB]) • 後述するが、現状64[kiB]以上は使えない模様
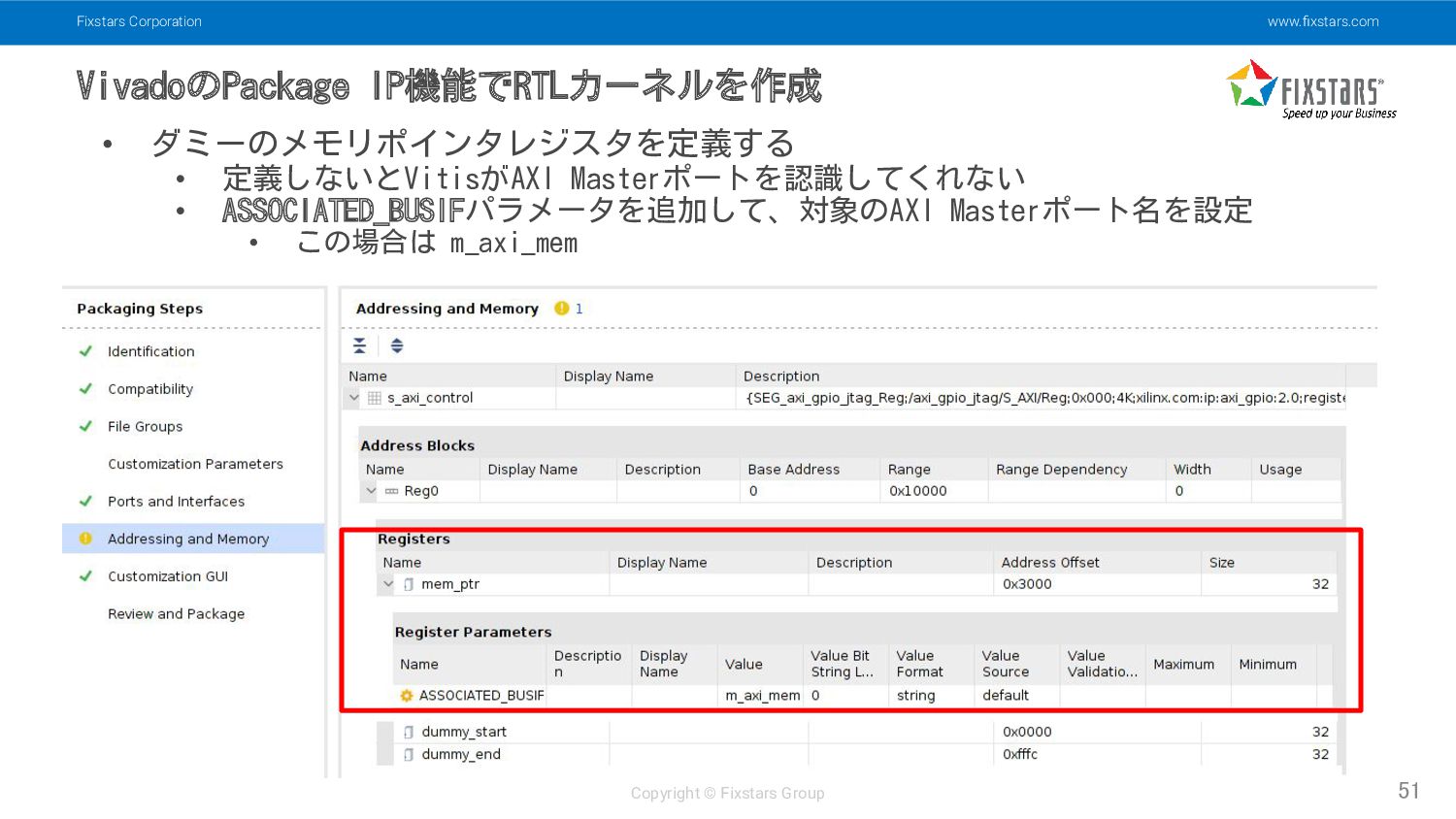
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VivadoのPackage IP機能でRTLカーネルを作成 51
• ダミーのメモリポインタレジスタを定義する • 定義しないとVitisがAXI Masterポートを認識してくれない • ASSOCIATED_BUSIFパラメータを追加して、対象のAXI Masterポート名を設定 • この場合は m_axi_mem
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group VivadoのPackage IP機能でRTLカーネルを作成 52
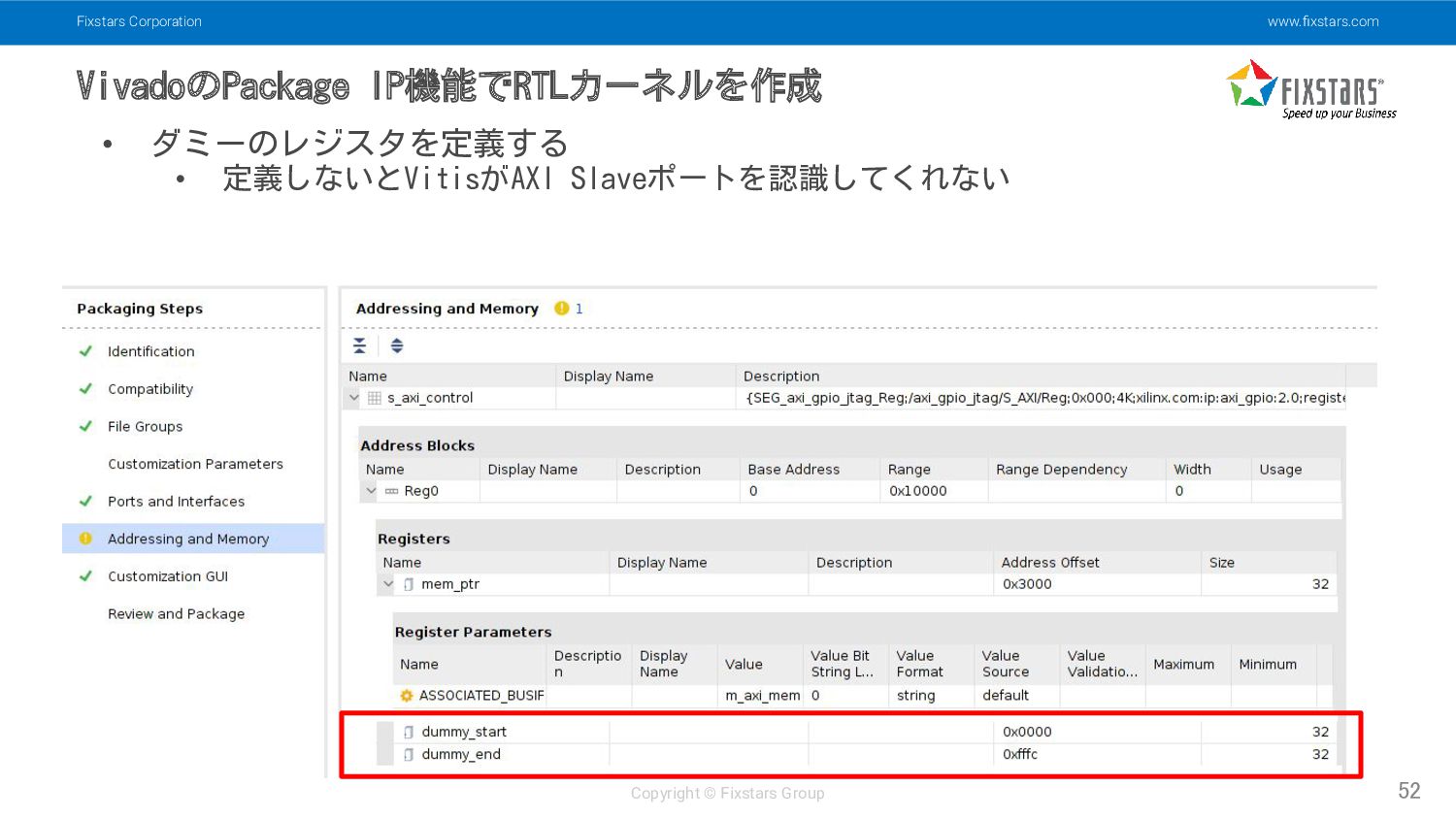
• ダミーのレジスタを定義する • 定義しないとVitisがAXI Slaveポートを認識してくれない
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group できあがり!? 53 •
クロック、リセット、レジスタアクセス、メモリアクセスを持つカーネルが完成 • vexriscv_vitis.xo という名前で保存 と思ったら罠が待っていた
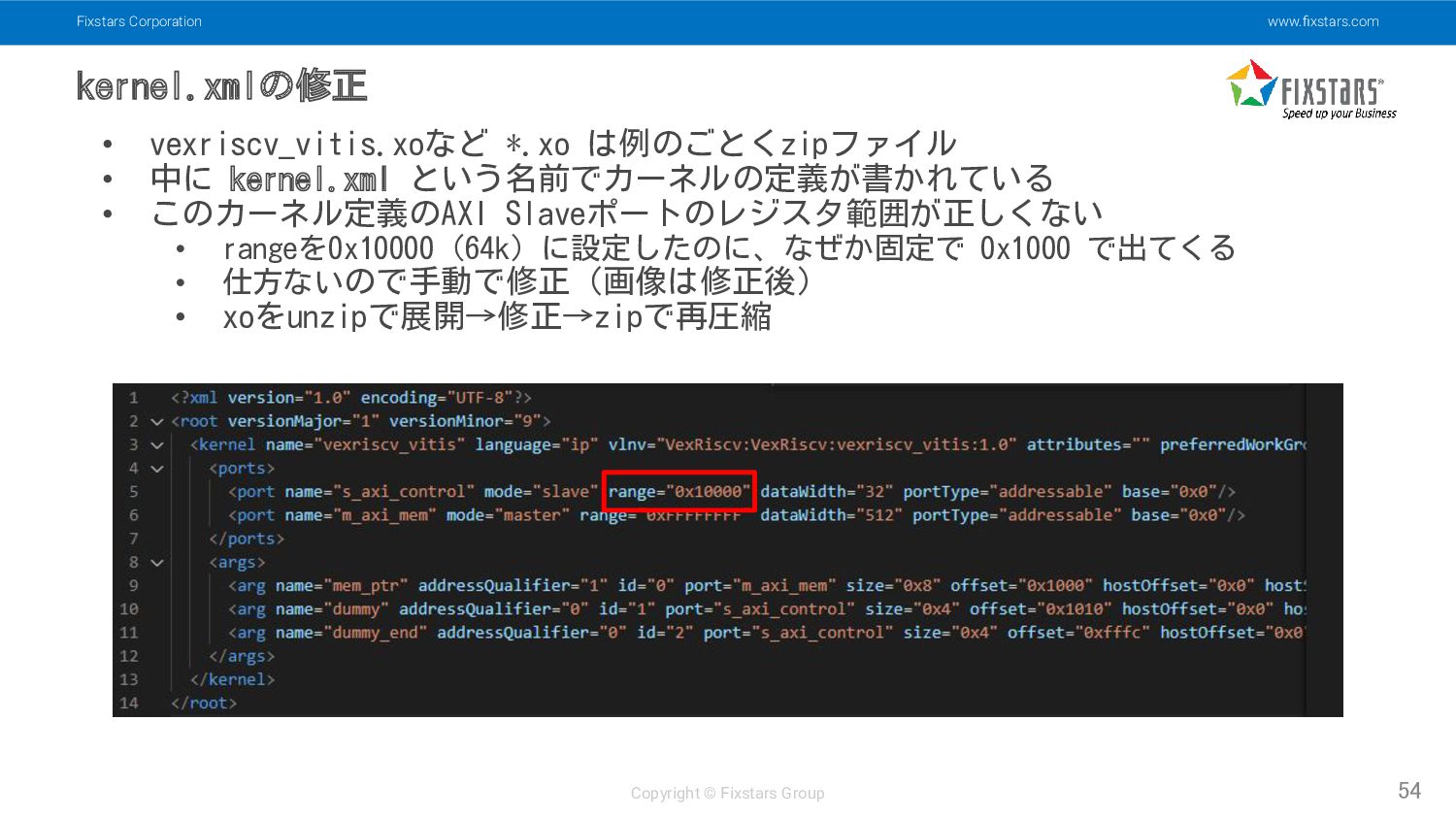
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group kernel.xmlの修正 54 •
vexriscv_vitis.xoなど *.xo は例のごとくzipファイル • 中に kernel.xml という名前でカーネルの定義が書かれている • このカーネル定義のAXI Slaveポートのレジスタ範囲が正しくない • rangeを0x10000 (64k) に設定したのに、なぜか固定で 0x1000 で出てくる • 仕方ないので手動で修正 (画像は修正後) • xoをunzipで展開→修正→zipで再圧縮
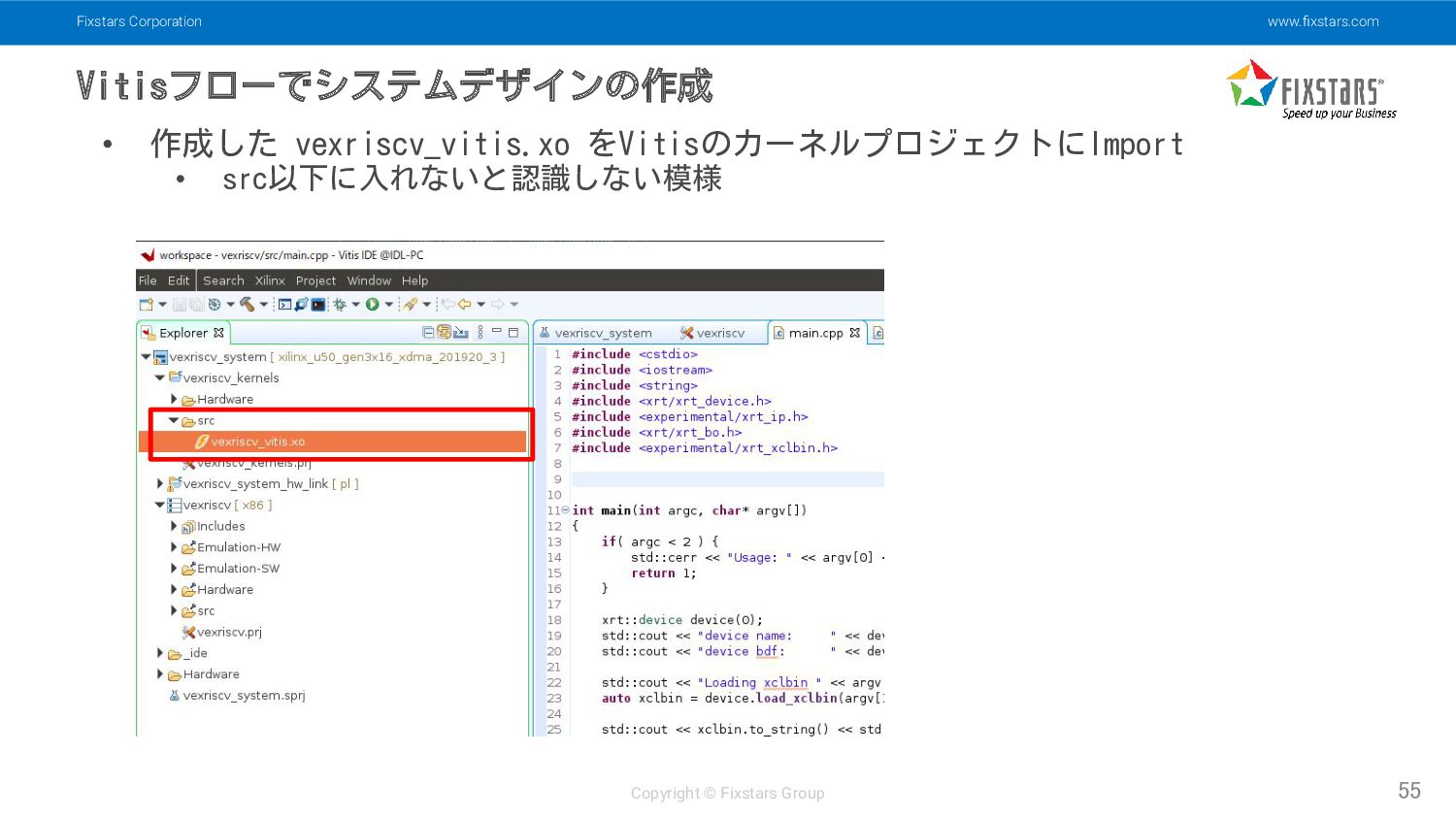
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Vitisフローでシステムデザインの作成 55 •
作成した vexriscv_vitis.xo をVitisのカーネルプロジェクトにImport • src以下に入れないと認識しない模様
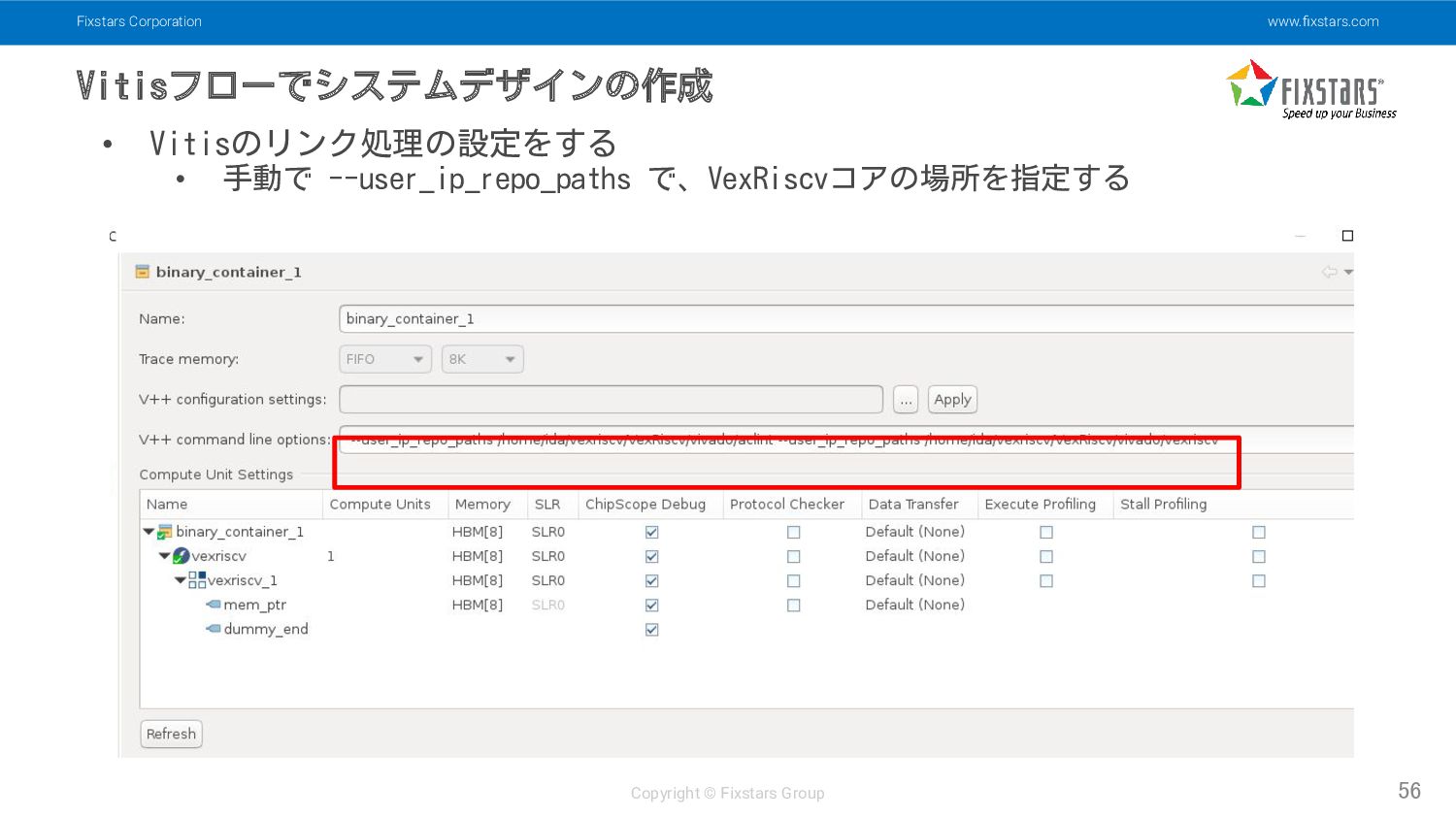
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Vitisフローでシステムデザインの作成 56 •
Vitisのリンク処理の設定をする • 手動で --user_ip_repo_paths で、VexRiscvコアの場所を指定する
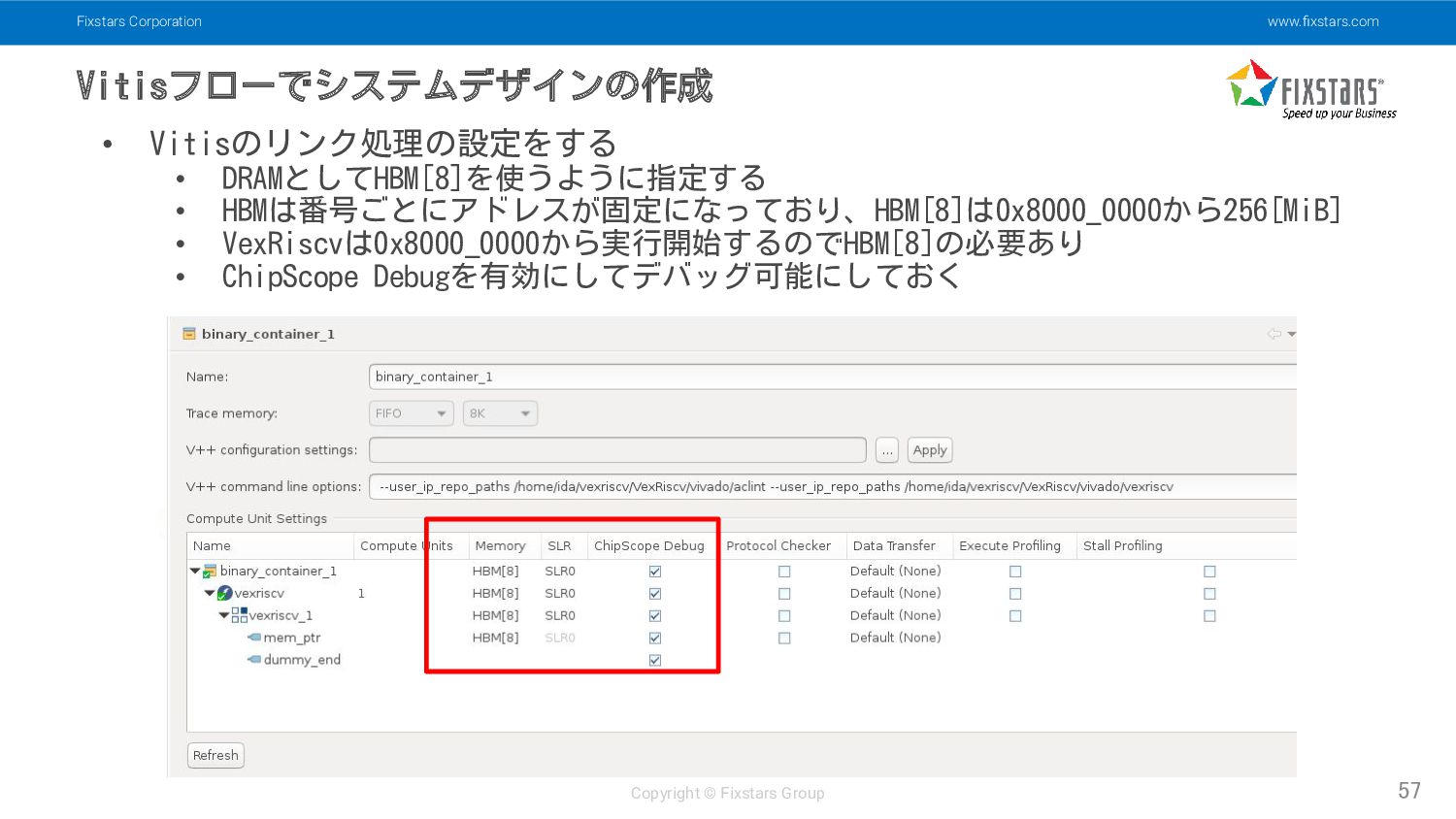
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Vitisフローでシステムデザインの作成 57 •
Vitisのリンク処理の設定をする • DRAMとしてHBM[8]を使うように指定する • HBMは番号ごとにアドレスが固定になっており、HBM[8]は0x8000_0000から256[MiB] • VexRiscvは0x8000_0000から実行開始するのでHBM[8]の必要あり • ChipScope Debugを有効にしてデバッグ可能にしておく
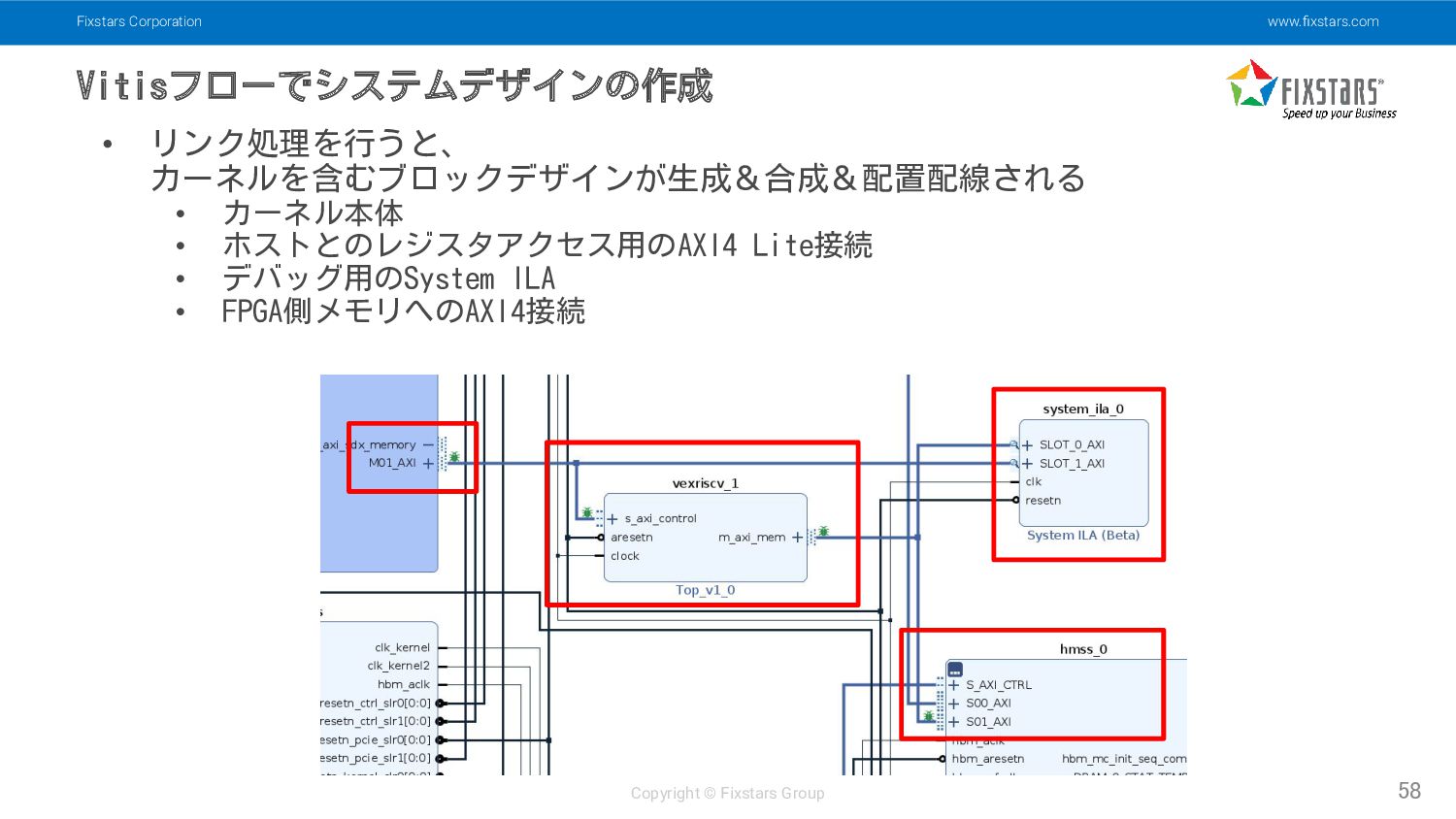
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Vitisフローでシステムデザインの作成 58 •
リンク処理を行うと、 カーネルを含むブロックデザインが生成&合成&配置配線される • カーネル本体 • ホストとのレジスタアクセス用のAXI4 Lite接続 • デバッグ用のSystem ILA • FPGA側メモリへのAXI4接続
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group 合成したデザインの書き込み 59 •
通常の演算カーネルは、XRTを用いてホスト側のソフトウェアを作成する • 今回は勝手に動いているCPUコアなのでホスト側ソフトウェア不要 • 代わりにXRTに付属する xbutil プログラムを使ってデザインを書き込む • xbutil reset –device (デバイス) でターゲットをリセット
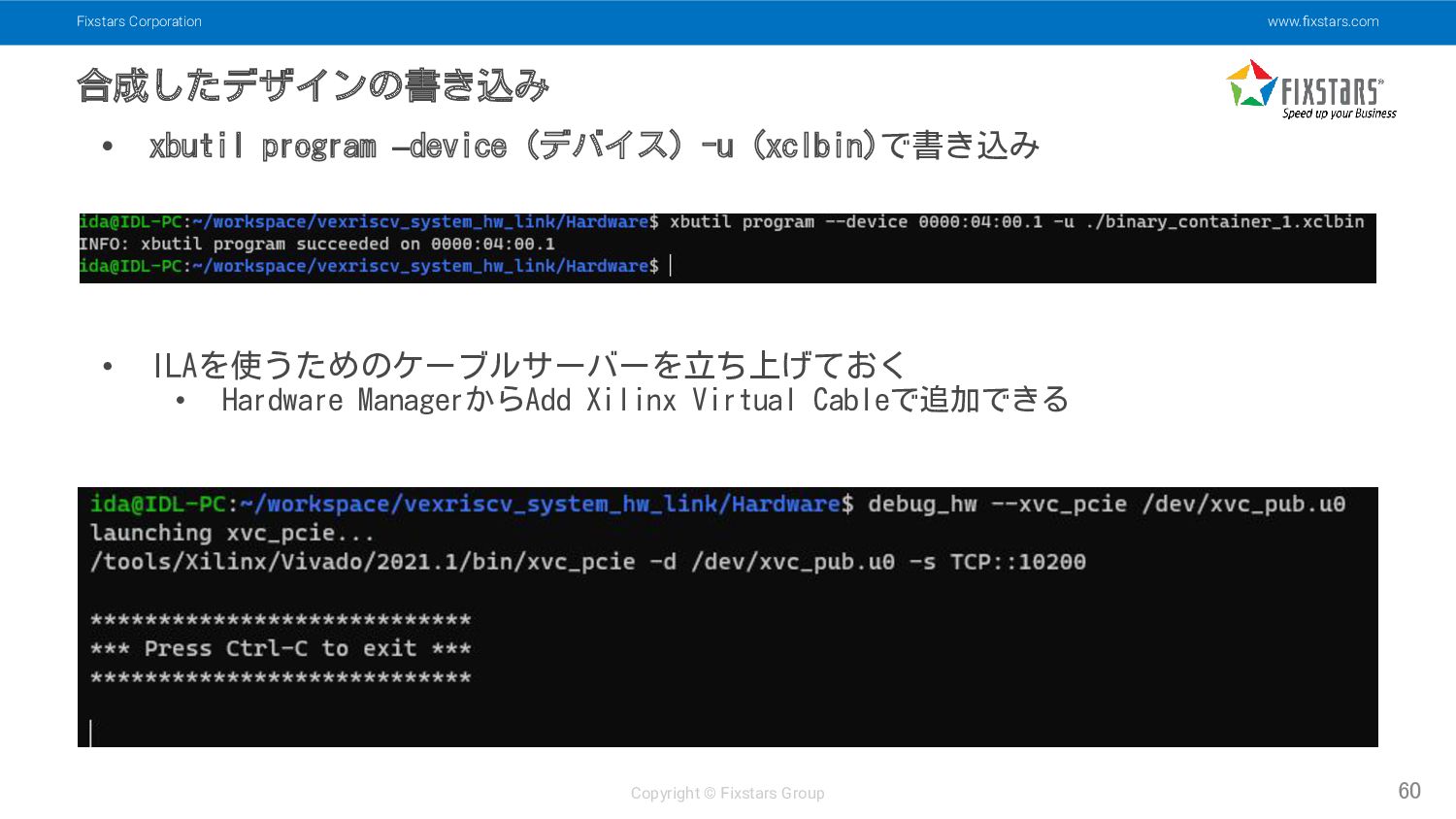
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group 合成したデザインの書き込み 60 •
xbutil program –device (デバイス) -u (xclbin)で書き込み • ILAを使うためのケーブルサーバーを立ち上げておく • Hardware ManagerからAdd Xilinx Virtual Cableで追加できる
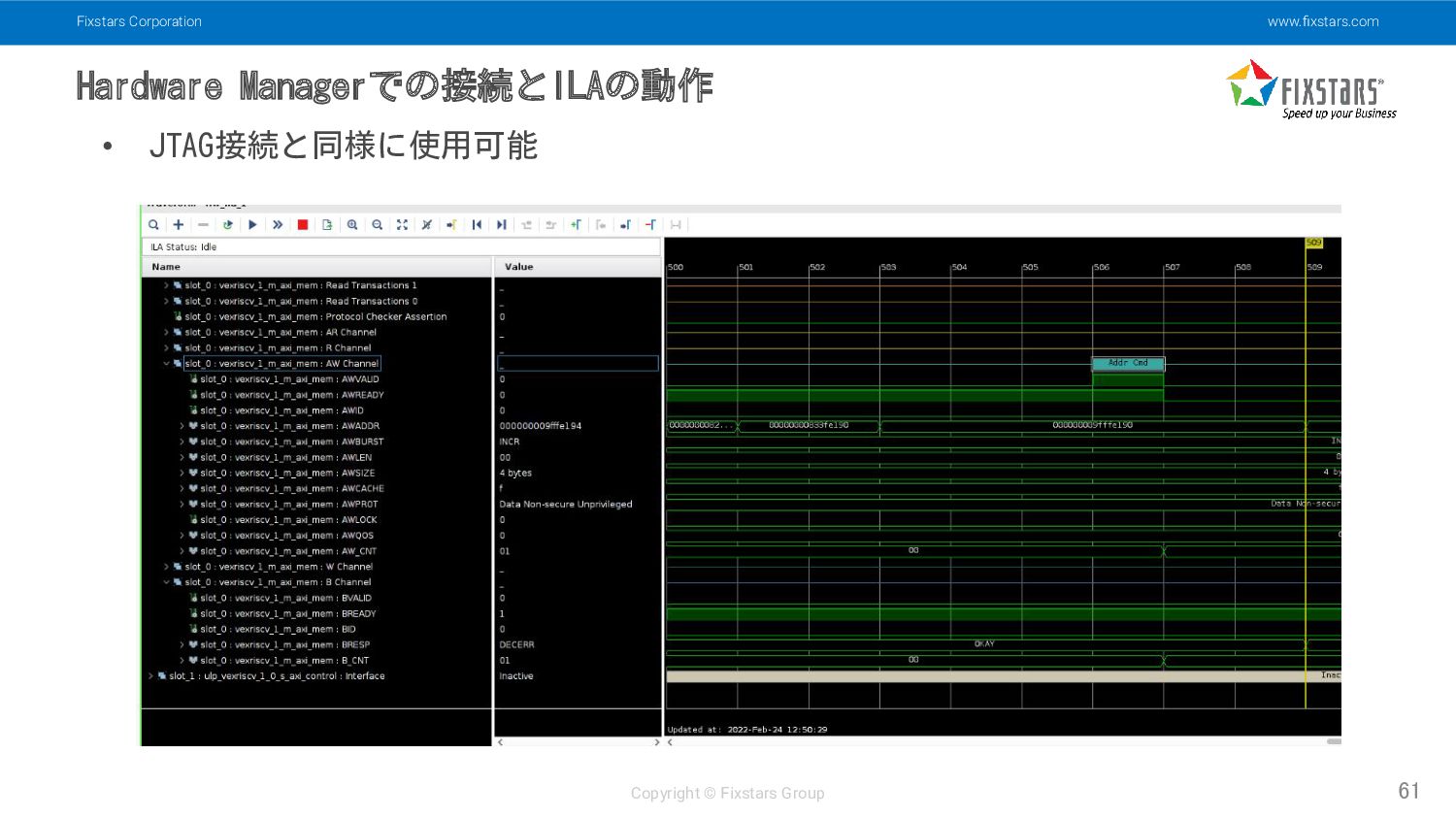
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Hardware Managerでの接続とILAの動作 61
• JTAG接続と同様に使用可能
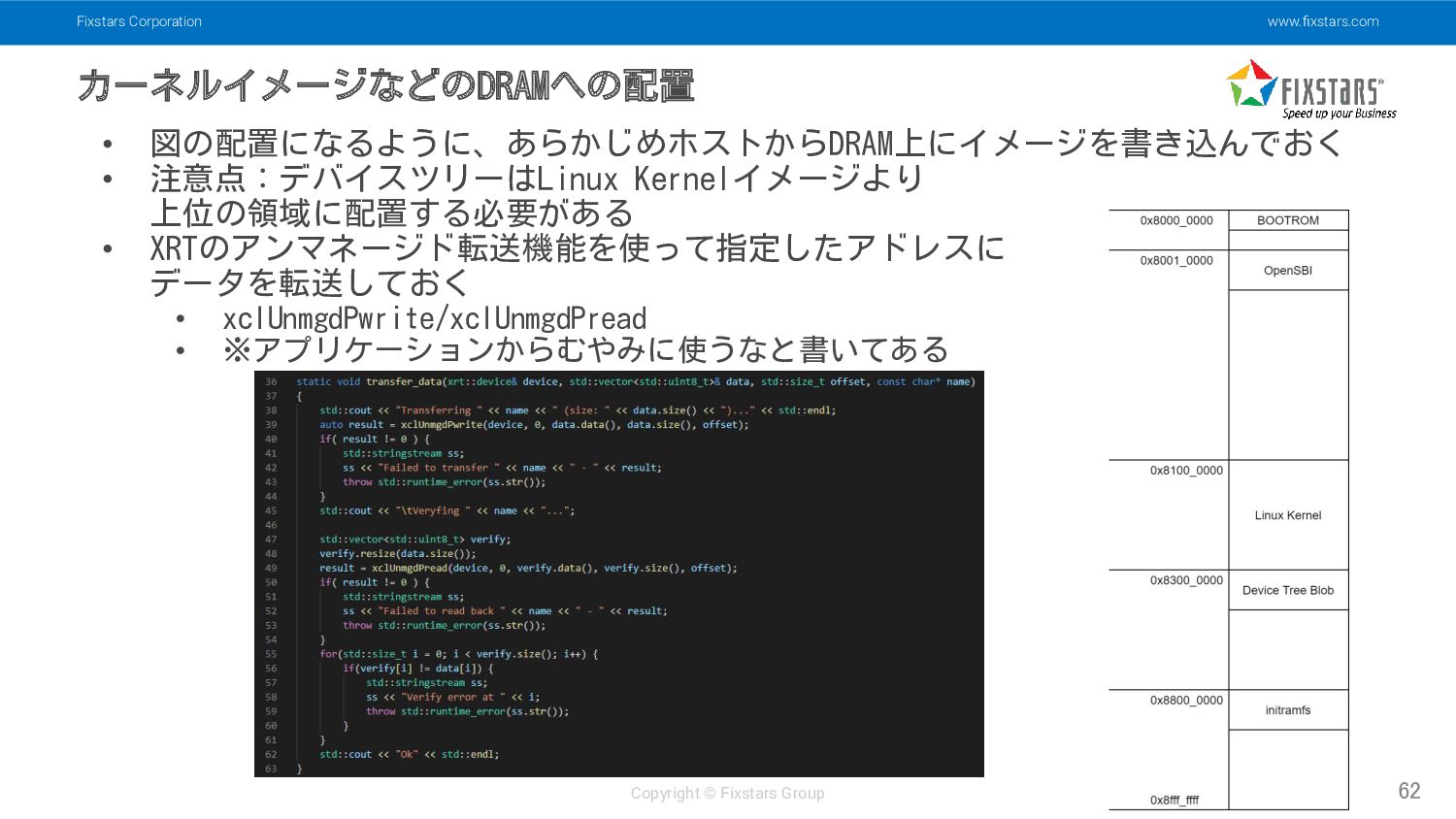
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group カーネルイメージなどのDRAMへの配置 62 •
図の配置になるように、あらかじめホストからDRAM上にイメージを書き込んでおく • 注意点:デバイスツリーはLinux Kernelイメージより 上位の領域に配置する必要がある • XRTのアンマネージド転送機能を使って指定したアドレスに データを転送しておく • xclUnmgdPwrite/xclUnmgdPread • ※アプリケーションからむやみに使うなと書いてある
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group カーネルイメージなどのDRAMへの配置 63 •
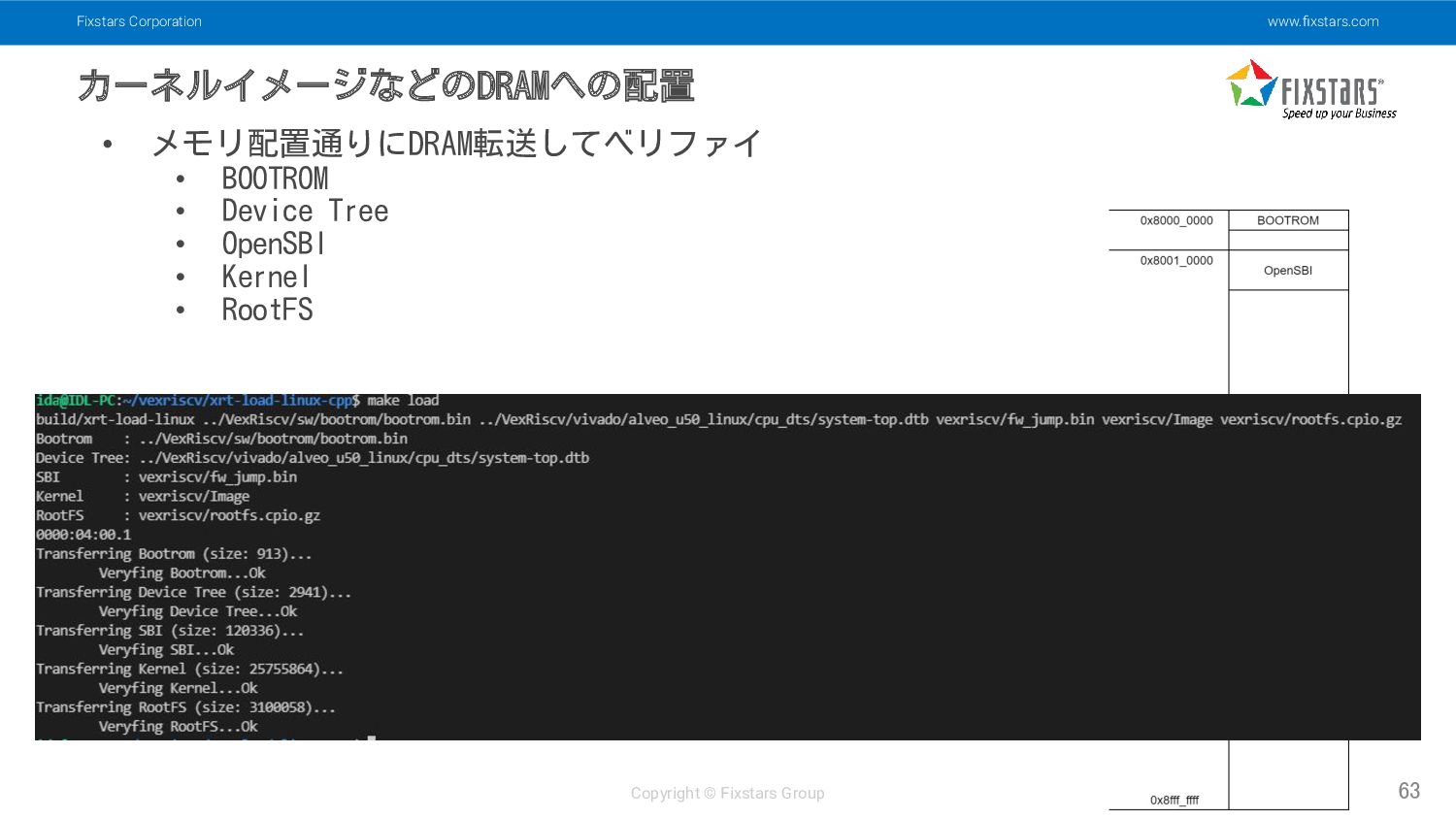
メモリ配置通りにDRAM転送してベリファイ • BOOTROM • Device Tree • OpenSBI • Kernel • RootFS
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group 動作確認結果 64 •
カーネル起動中にpanicとなり、正常動作は確認できなかった • 前回Device Treeの配置を間違ったときの現象に似ているが… • CPUからみた構成はLiteFuryで動作したものと変わっていないはず… • 今後の検証課題として継続調査予定
Fixstars Corporation www.fixstars.com Copyright © Fixstars Group Copyright © Fixstars
Group Thank You お問い合わせ窓口 :
[email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}