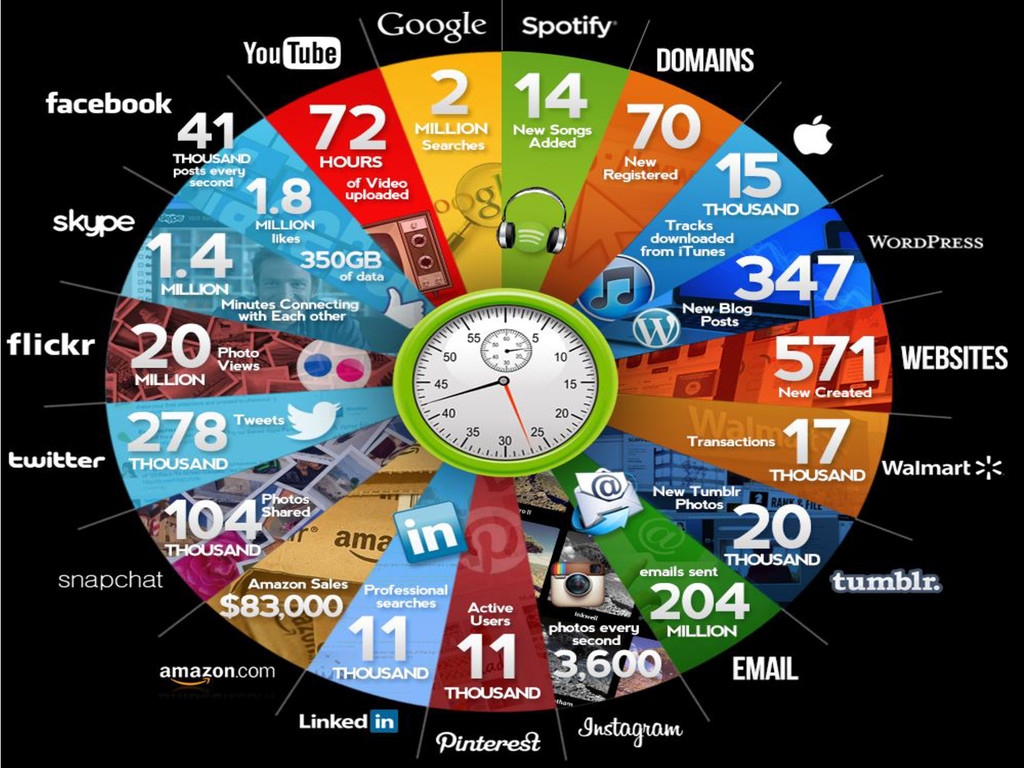
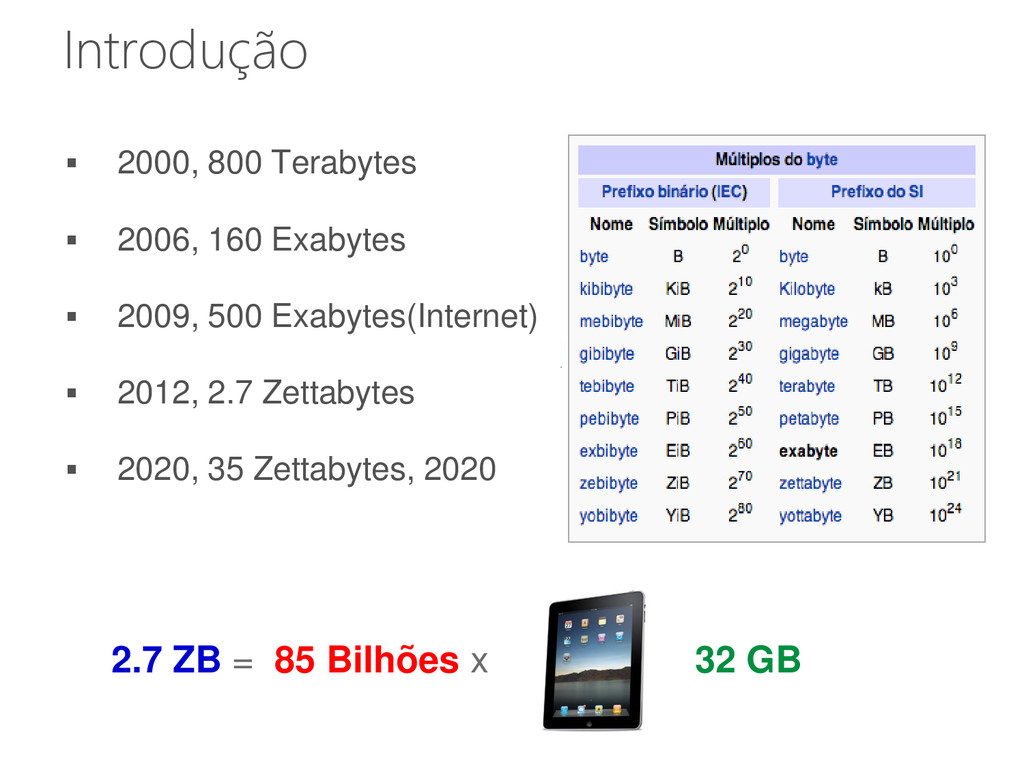
dos dados no mundo hoje foram produzidos nos últimos dois anos 2,7 bilhões de usuários na internet 5 bilhões de celulares 64 Bilhões de mensagens em 24 horas 6 Fonte: IBM/Whatsapp
"likes", 219B de fotos e 140.3B de relacionamentos Youtube • 100 horas de vídeos adicionado a cada minuto Bolsa de valores de Nova Iorque • + 1 TB de dados a cada sessão do pregão Flick • + de 5B de fotos Twitter • 80 TB e 1B de tweets por dia 8
voo transatlântico Wal-Mart • 2,5 PB e 1 milhão de transações/hora LHC CERN • 15 Petabytes por ano Sloan Digital Sky Survey • 14 milhões de estrelas e galáxias • 80 atributos por objeto • 10 Petabytes gerados a cada varredura Google • 24 Petabytes processados por dia
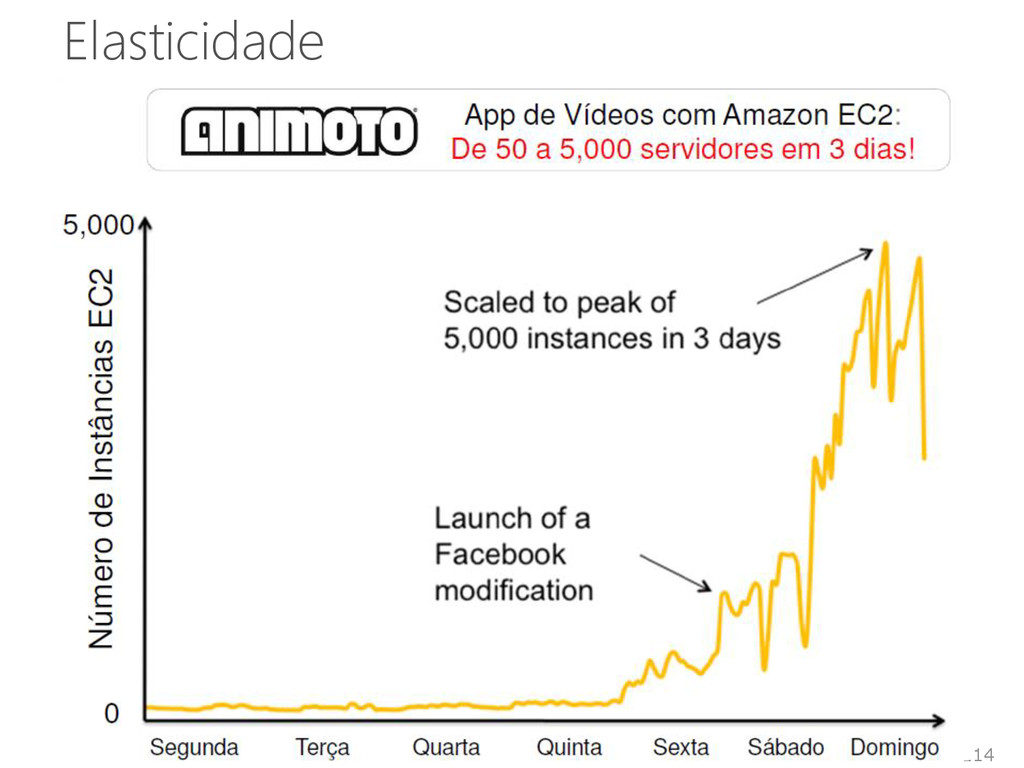
o Facebook Mais de 30 milhões de usuários no iPhone Milhões de usuários em 12 horas no Android 13 funcionários, sendo que 3 cuidam de TI 17 Fonte: Amazon
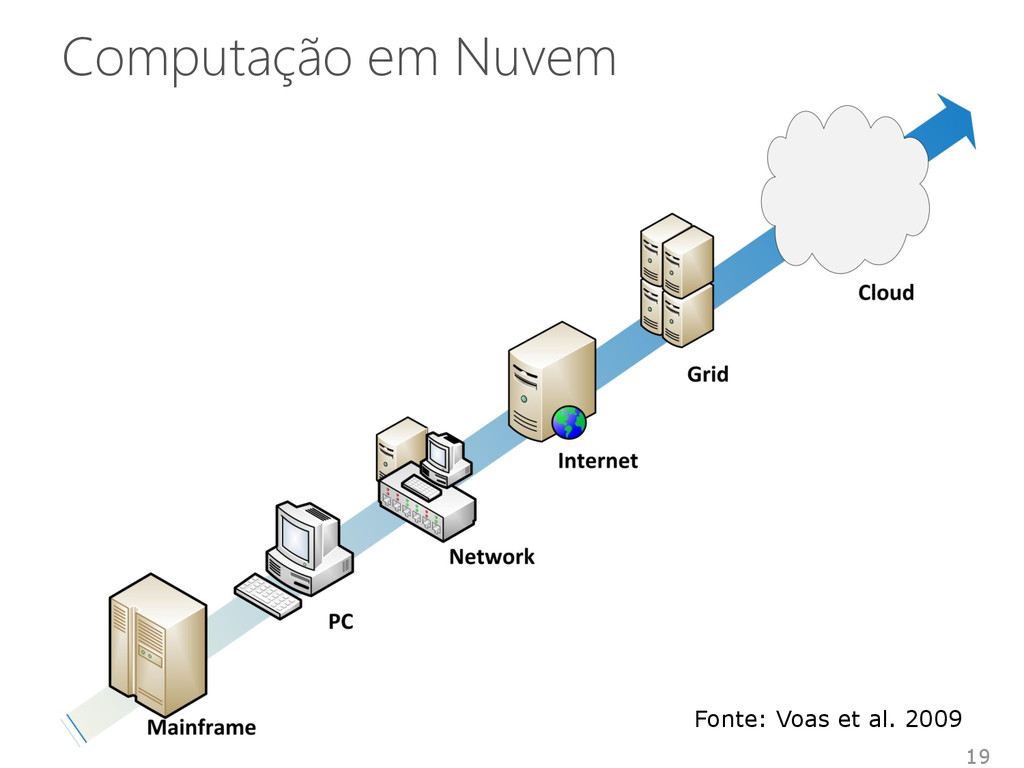
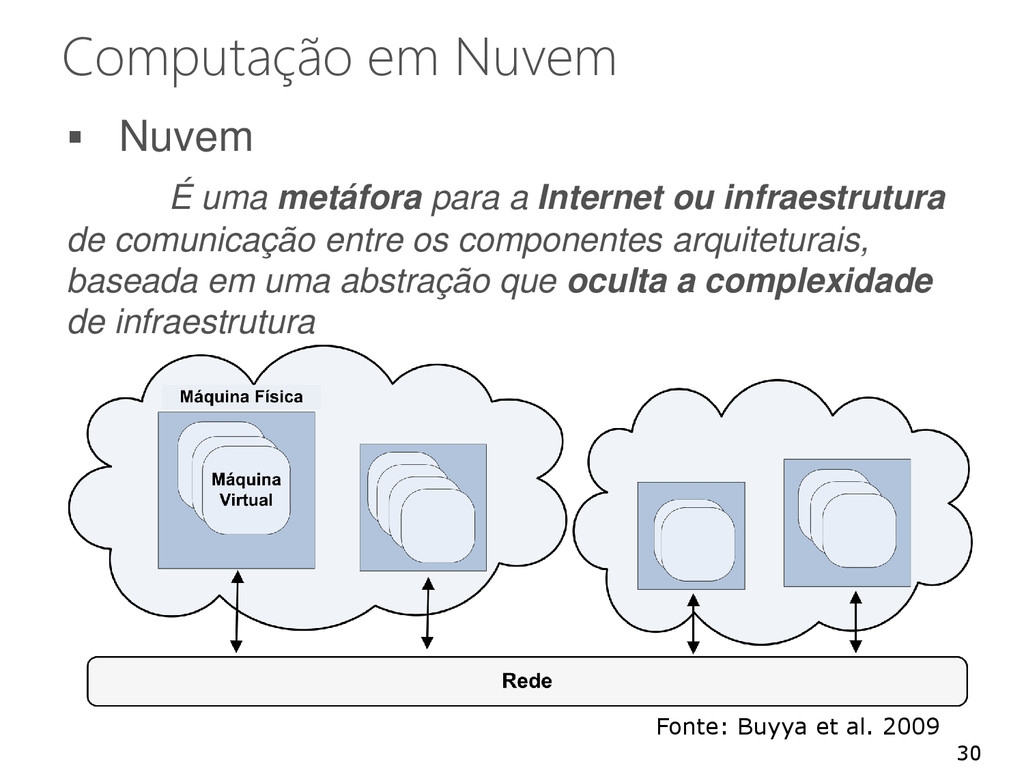
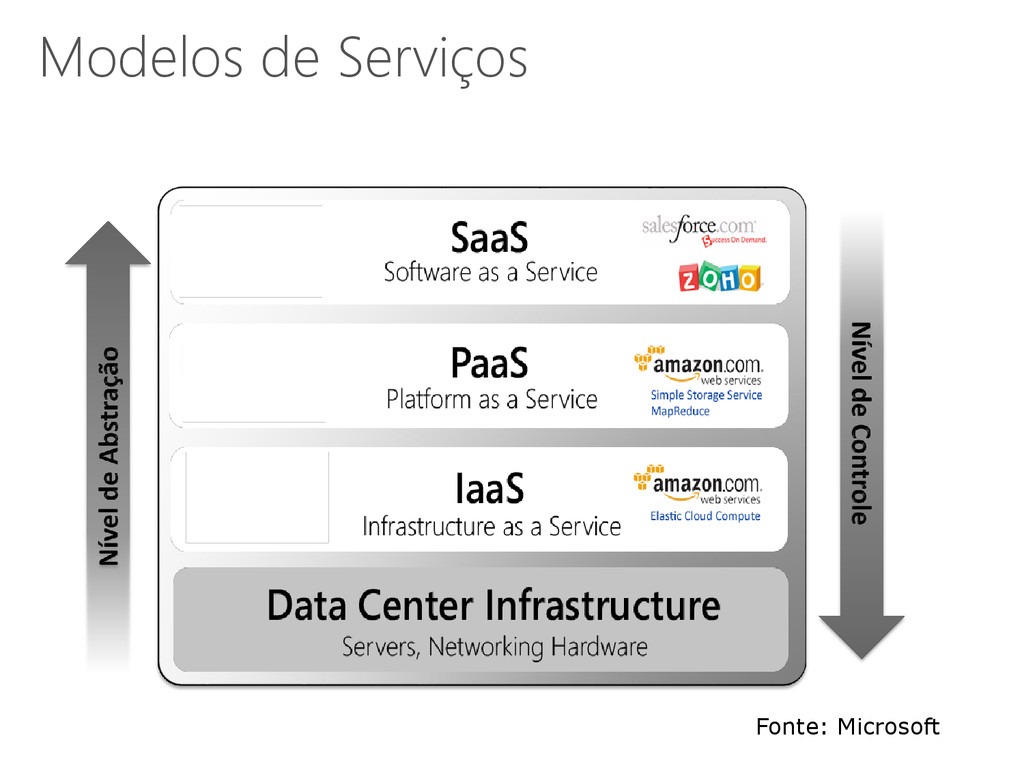
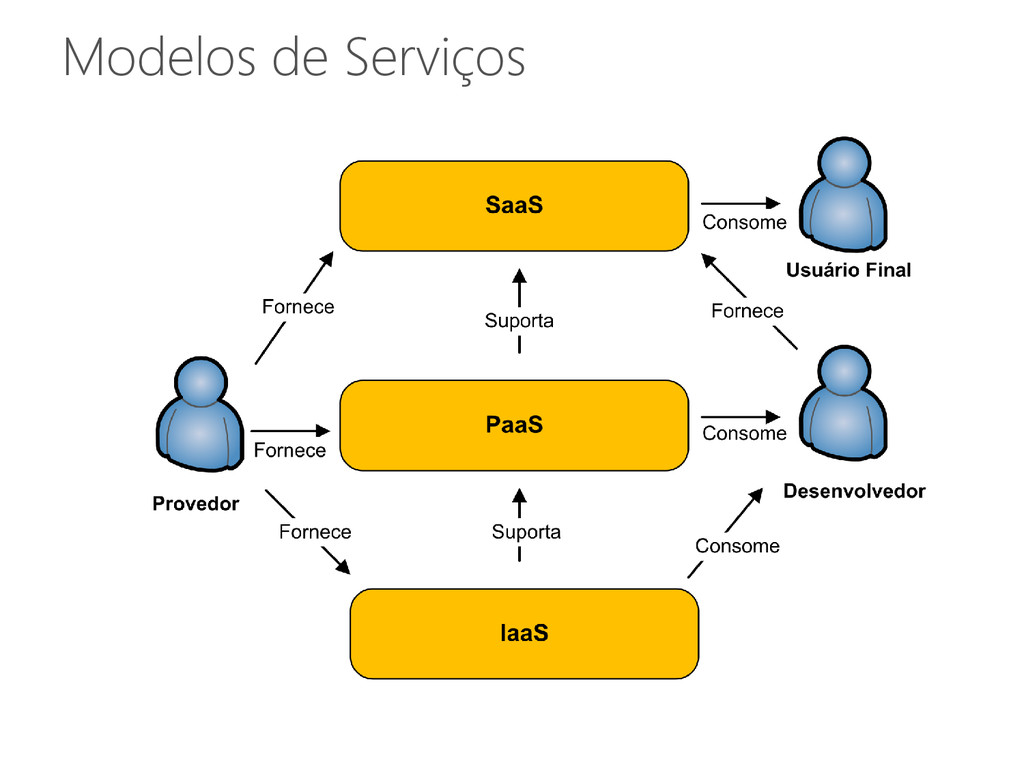
entregues de uma forma transparente A mesma ideia tem sido aplicada no contexto da informática • Cloud Computing ou Computação em Nuvem Computação em Nuvem • Ideia antiga: Software como um Serviço (SaaS) Entrega de aplicações através da Internet • Recentemente: “[Hardware, Infraestrutura, Plataforma] como um serviço” “X como um serviço” 21
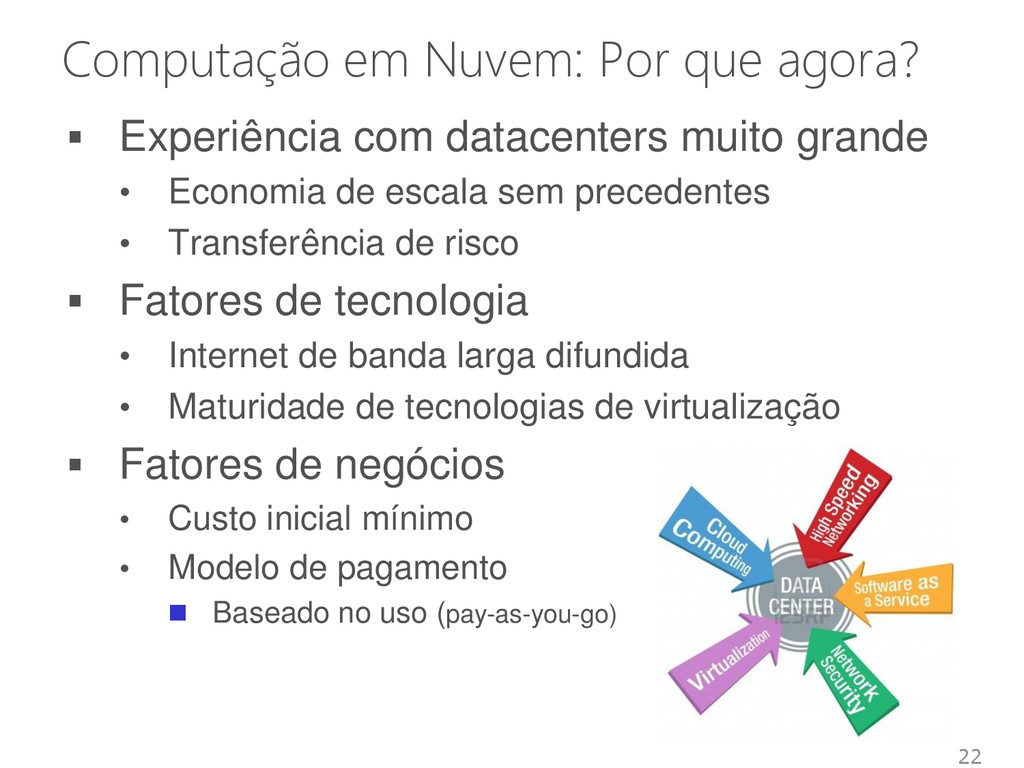
muito grande • Economia de escala sem precedentes • Transferência de risco Fatores de tecnologia • Internet de banda larga difundida • Maturidade de tecnologias de virtualização Fatores de negócios • Custo inicial mínimo • Modelo de pagamento Baseado no uso (pay-as-you-go) 22
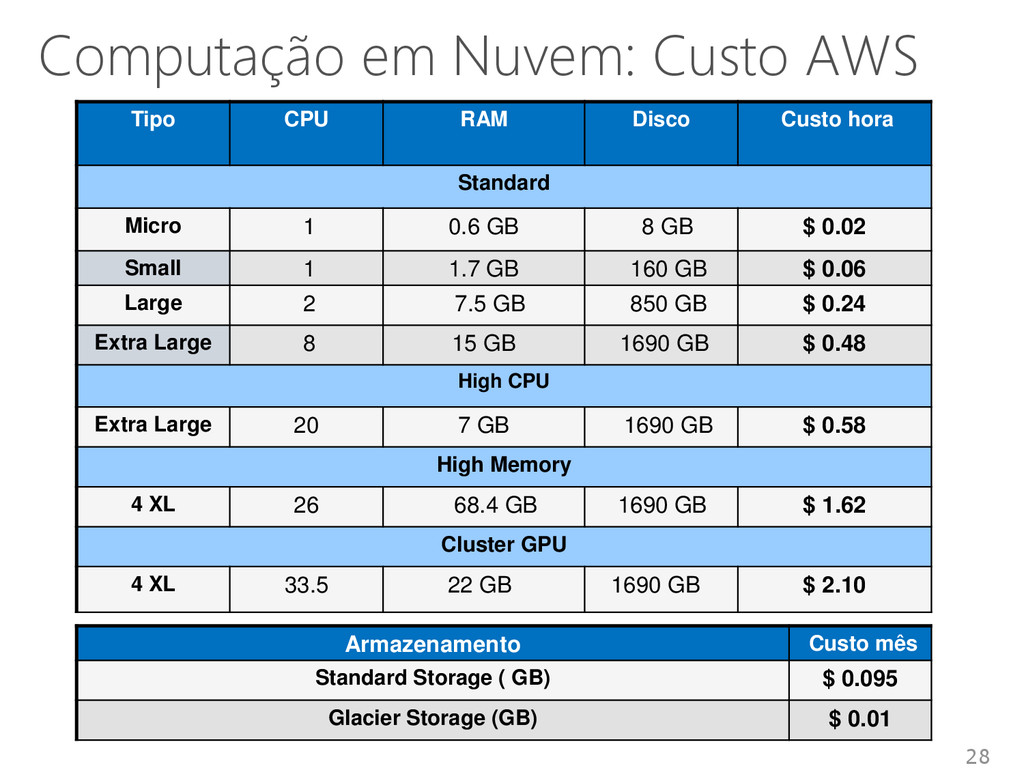
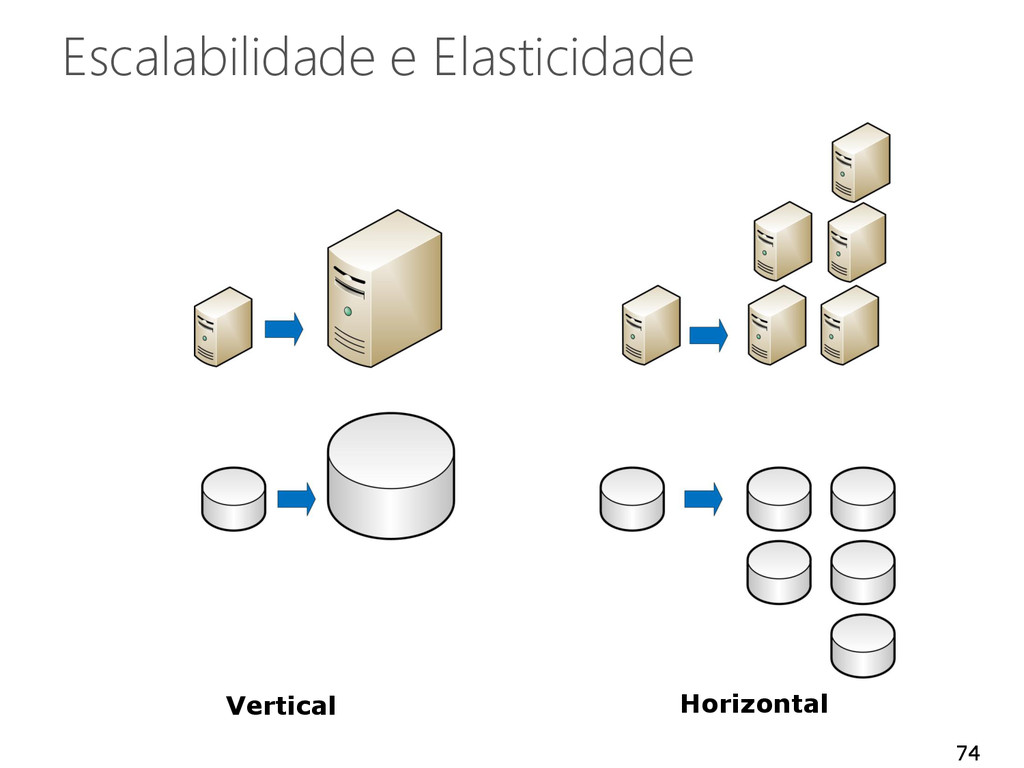
de manutenção Quant. fixa de recursos Dificuldade de escalabilidade Pagamento pelo uso Menor custo de manutenção Escalabilidade linear Tolerância a falhas Sob demanda 26 Fonte: Forrester Research
500 supercomputadores mais rápidos do mundo 1.064 instâncias do EC2 foram usadas para criar um supercomputador com 17.024 cores 240 teraflops de velocidade • 240 trilhões de operações por segundo Esse supercomputador é o 72º computador mais rápido do mundo • Lista do Top 500 (jun/2012) Você pode alugá-lo por menos de US$ 1.000/h 29 Fonte: Daniel Cordeiro
Internet ou infraestrutura de comunicação entre os componentes arquiteturais, baseada em uma abstração que oculta a complexidade de infraestrutura 30 Fonte: Buyya et al. 2009
que possibilita acesso, de modo conveniente e sob demanda, a um conjunto de recursos computacionais configuráveis que podem ser rapidamente adquiridos e liberados com mínimo esforço gerencial ou interação com o provedor de serviços” 31 Fonte: NIST
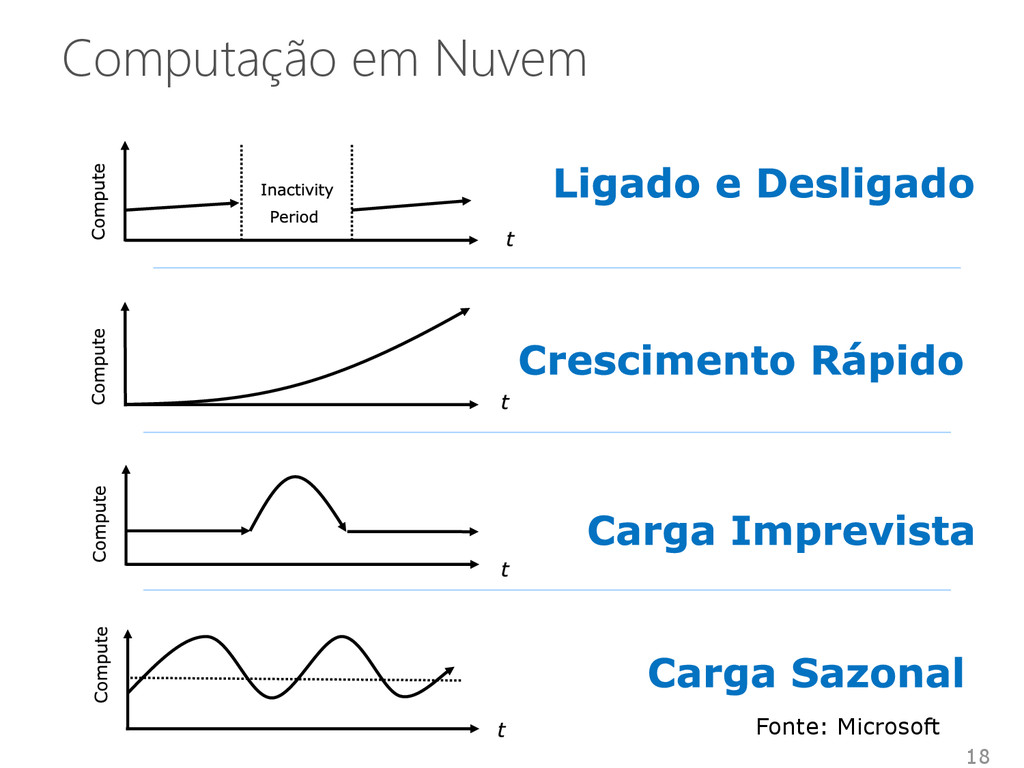
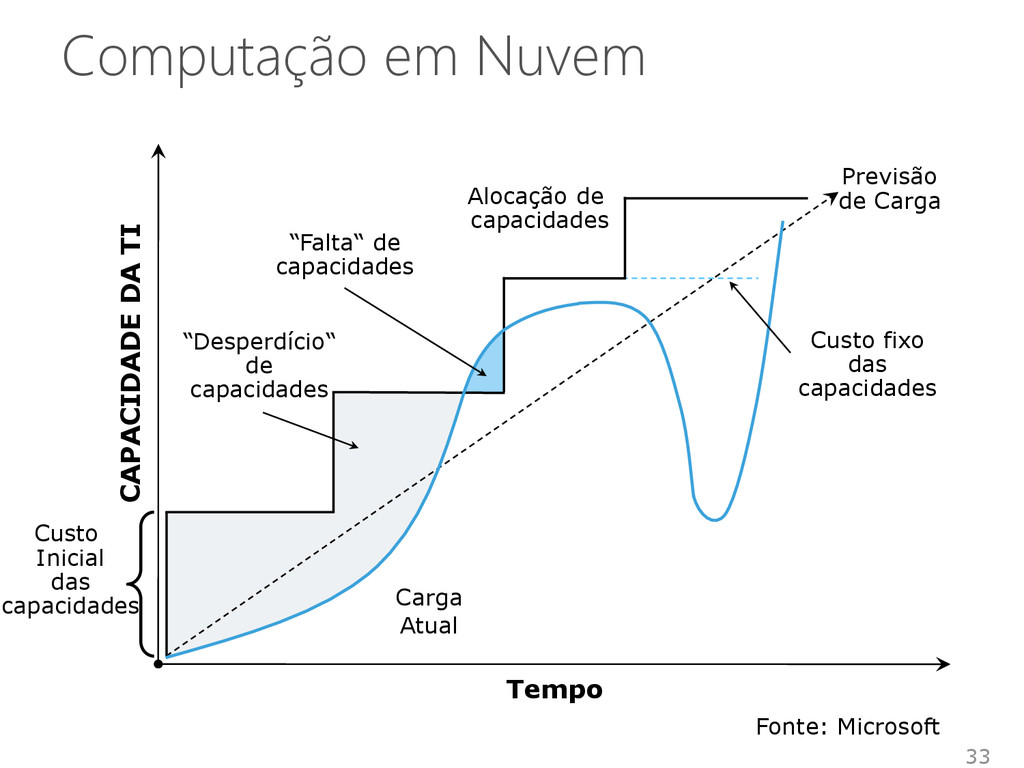
Alocação de capacidades “Desperdício“ de capacidades “Falta“ de capacidades Custo fixo das capacidades Previsão de Carga Custo Inicial das capacidades Fonte: Microsoft
Redução dos investimentos iniciais Redução do “excesso de TI“ Sem “falta“ de capacidades É possível a redução das capacidades no caso da redução da carga Tempo CAPACIDADE DA TI Previsão de Carga Fonte: Microsoft
de seus cliente são armazenados no provedor Dependência de provedor de nuvem • Sem controle físico sobre o hardware • E se governo decide encerrar a “nuvem”? ou obrigar o provedor a fornece informações? • E se o datacenter “quebra”? Limitado ao provedor (lock-in) • Adaptando soluções para serviços específicos (não-padrão) 39
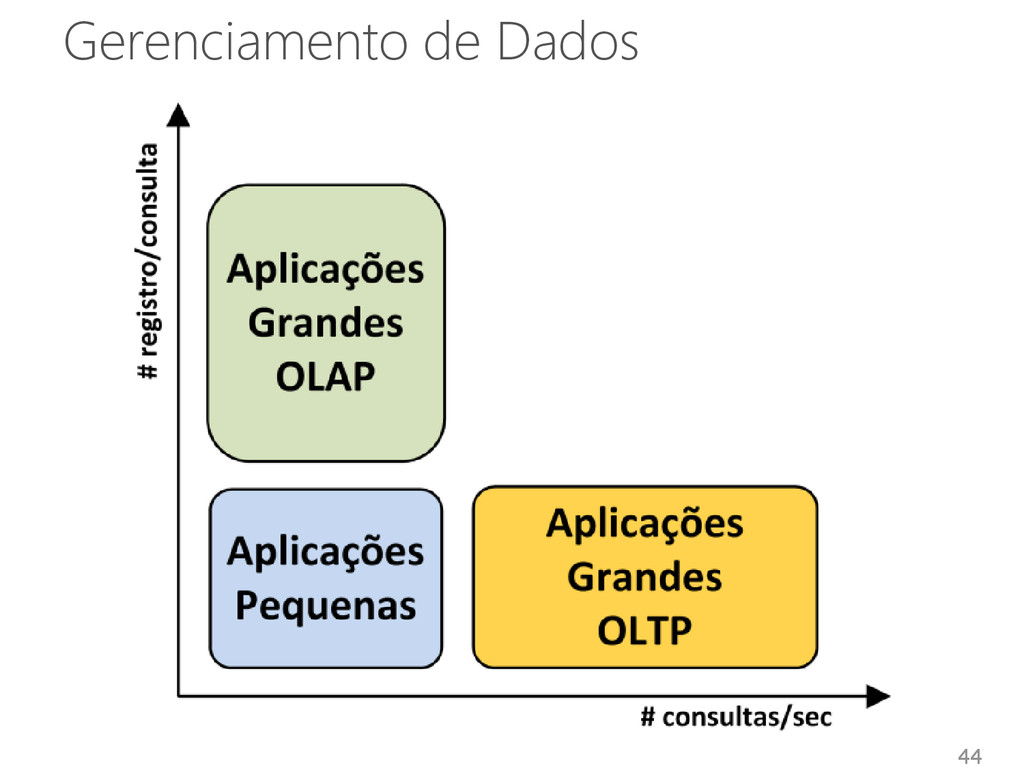
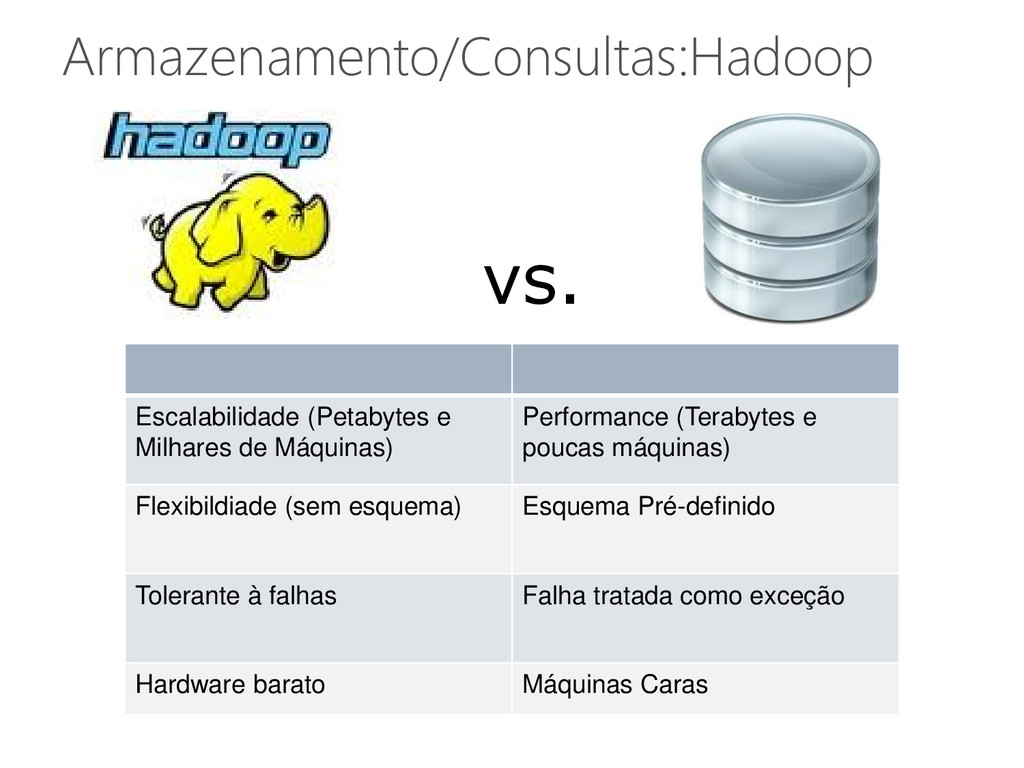
Analytical Processing) • OLTP (Online Transaction Processing) Características das aplicações • Grandes quantidades de dados Banco de dados único Foco na escalabilidade do banco de dados • Pequenas quantidades de dados Múltiplos bancos de dados Foco na escalabilidade da infraestrutura 43
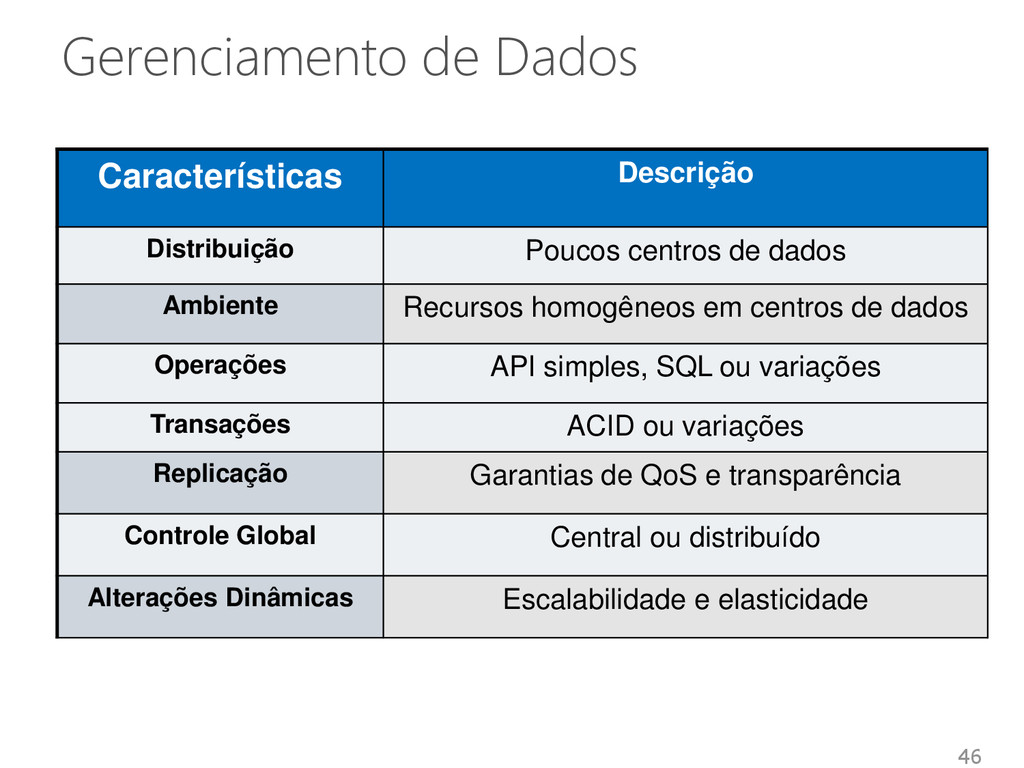
dados Ambiente Recursos homogêneos em centros de dados Operações API simples, SQL ou variações Transações ACID ou variações Replicação Garantias de QoS e transparência Controle Global Central ou distribuído Alterações Dinâmicas Escalabilidade e elasticidade
humana limitada • Alta alternância na carga de processamento • Variedade de infraestruturas compartilhadas • Mais recursos disponíveis para administração • Atualizações de software mais frequentes 47
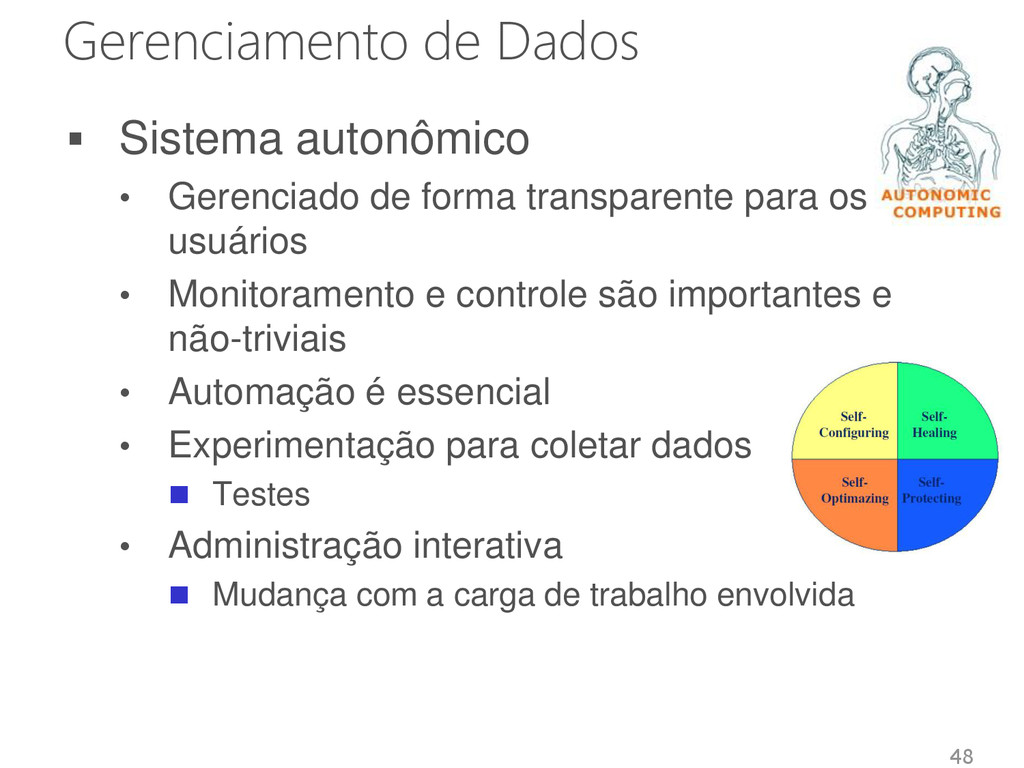
transparente para os usuários • Monitoramento e controle são importantes e não-triviais • Automação é essencial • Experimentação para coletar dados Testes • Administração interativa Mudança com a carga de trabalho envolvida 48
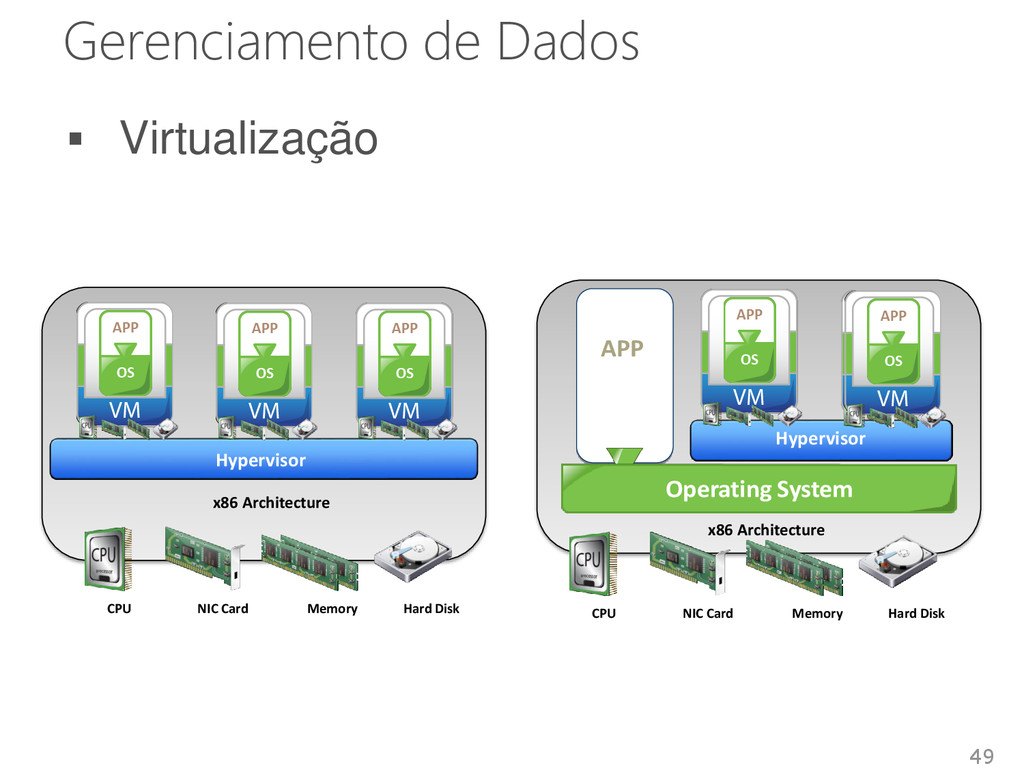
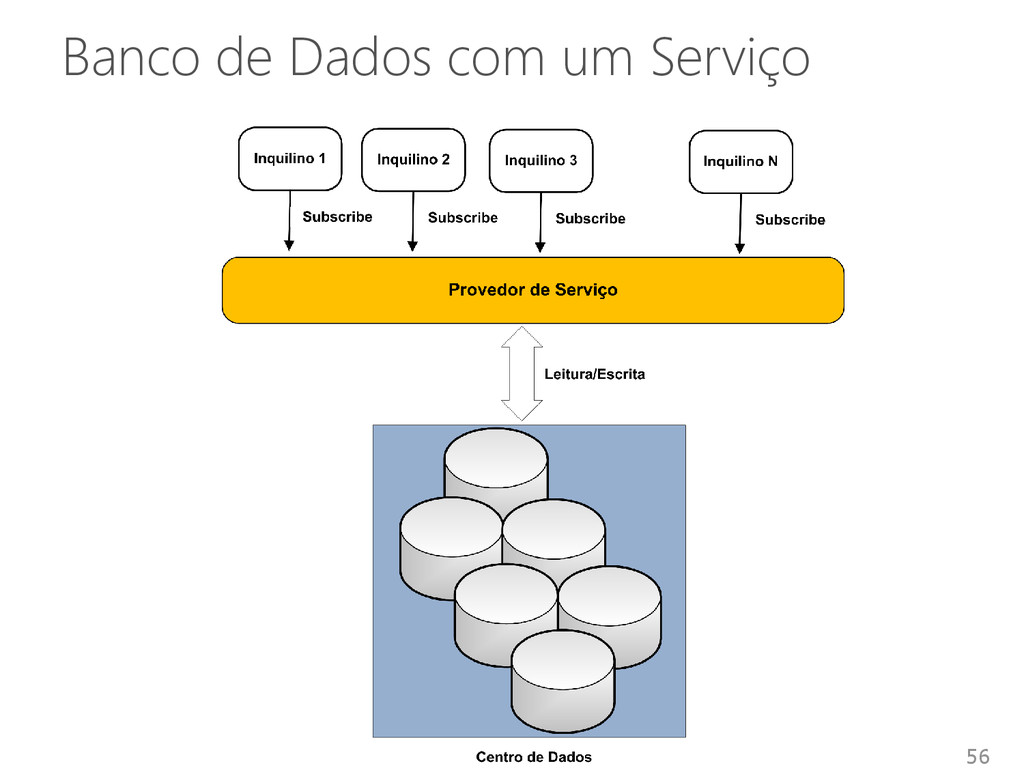
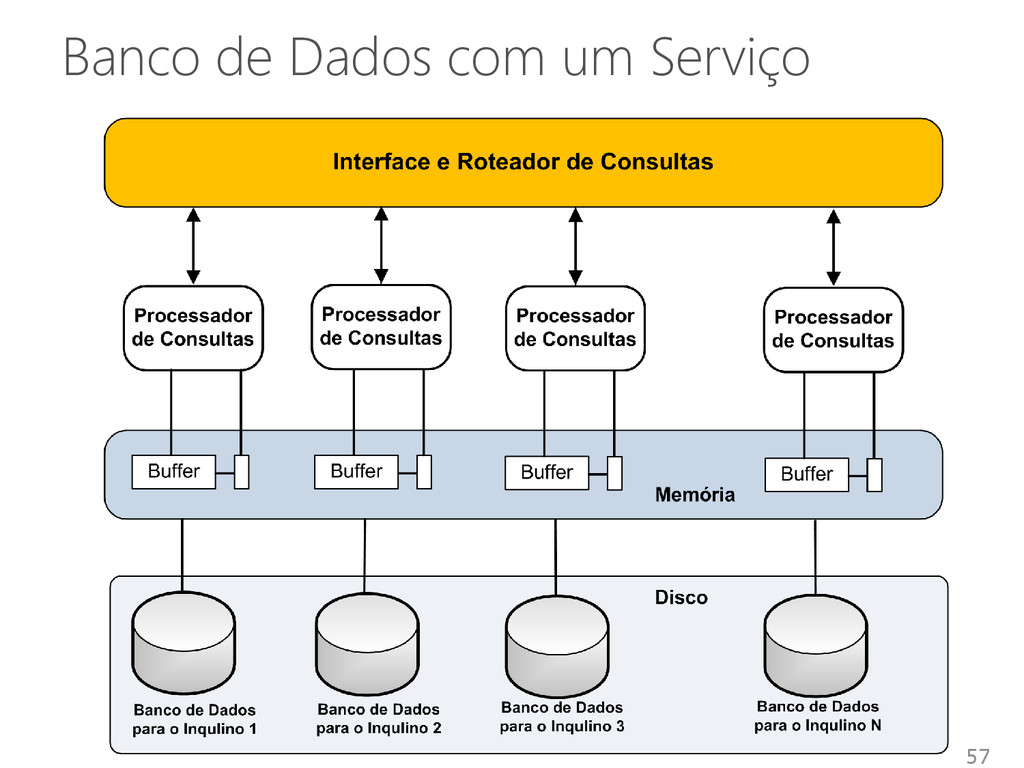
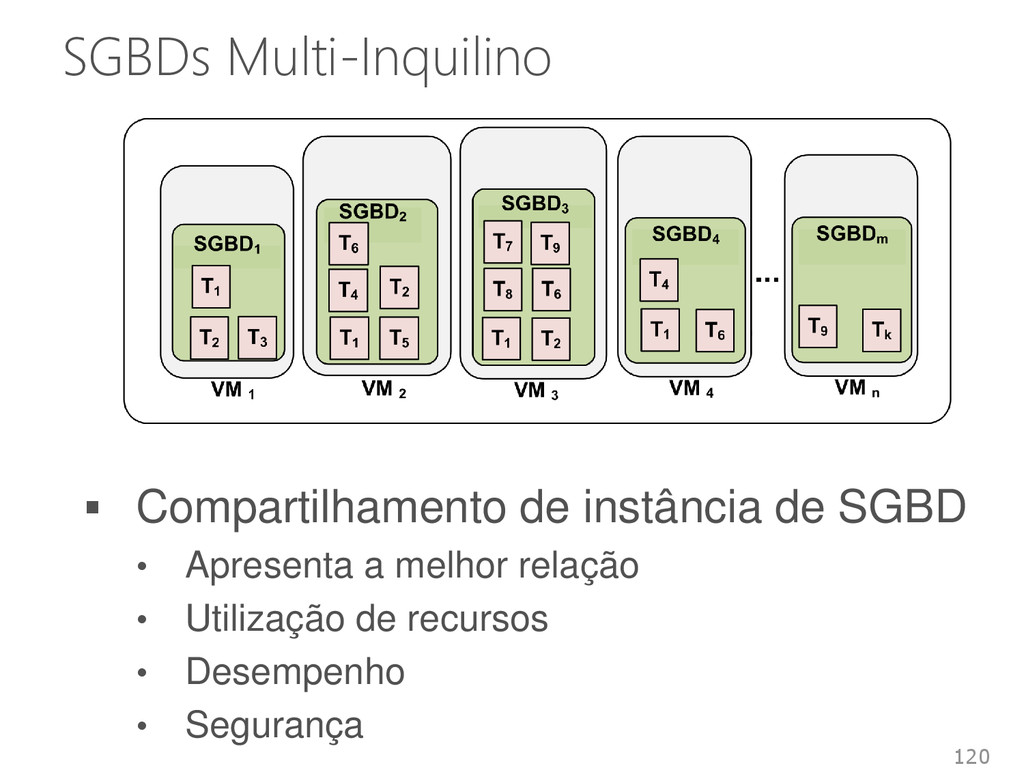
e provisionamento flexível de SGBDs • Recursos dedicados recursos compartilhados Melhorar a utilização de recursos Simplificar a administração Reduzir custos • Introduz pouco overhead no sistema Aproximadamente 10% 50
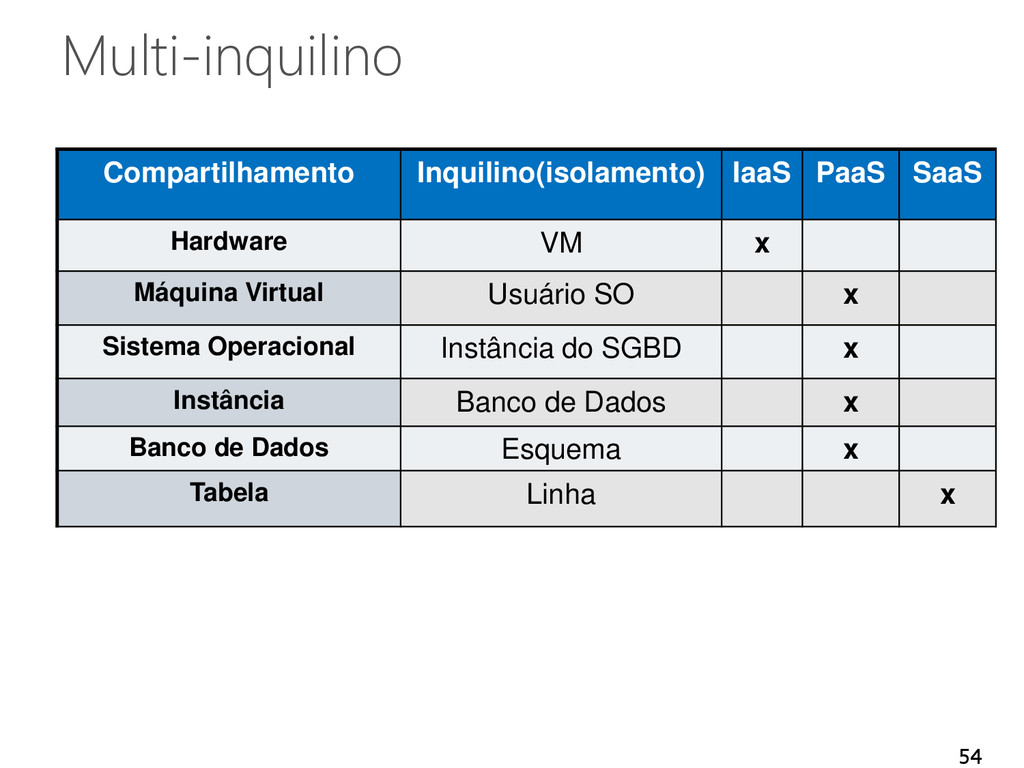
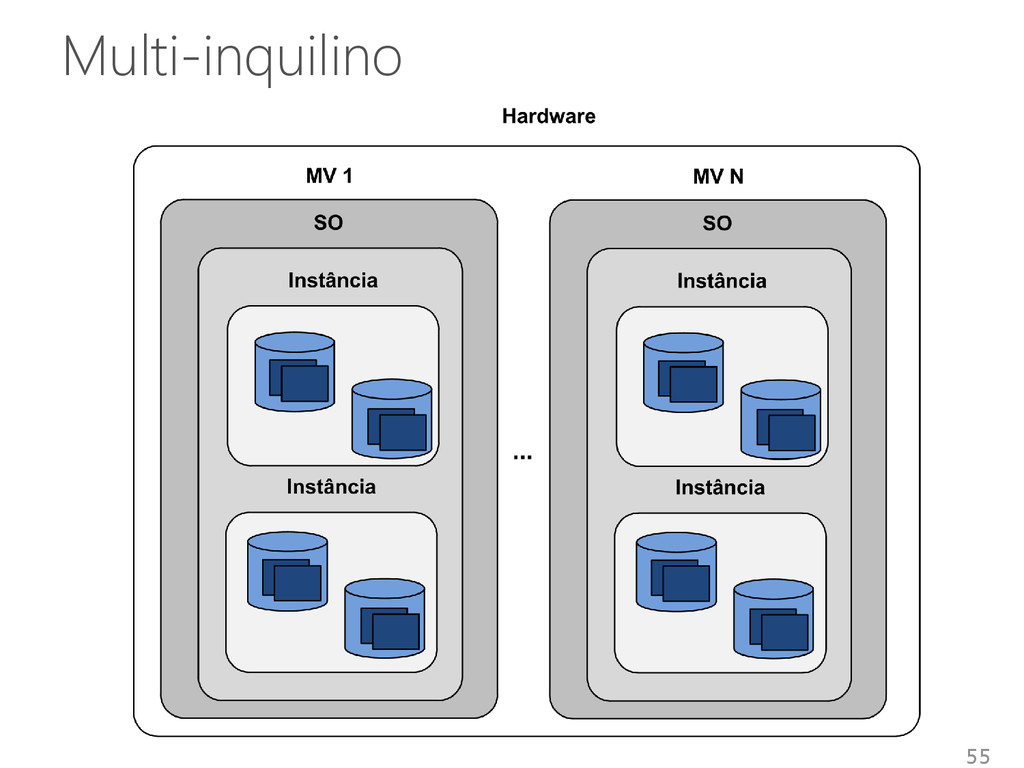
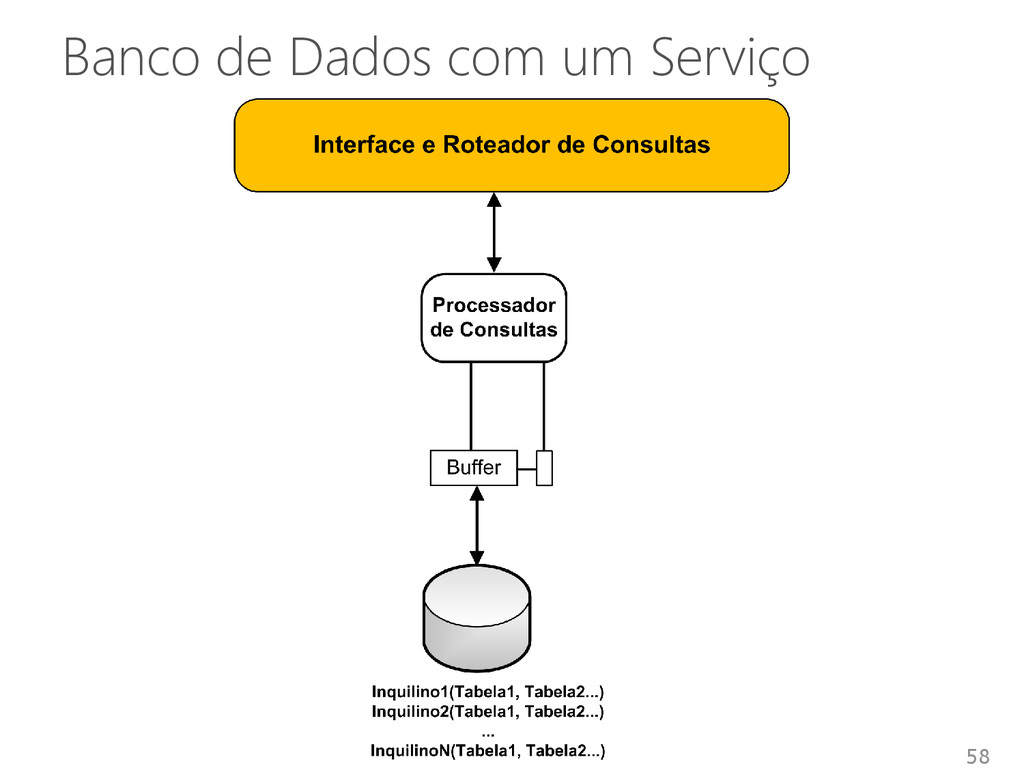
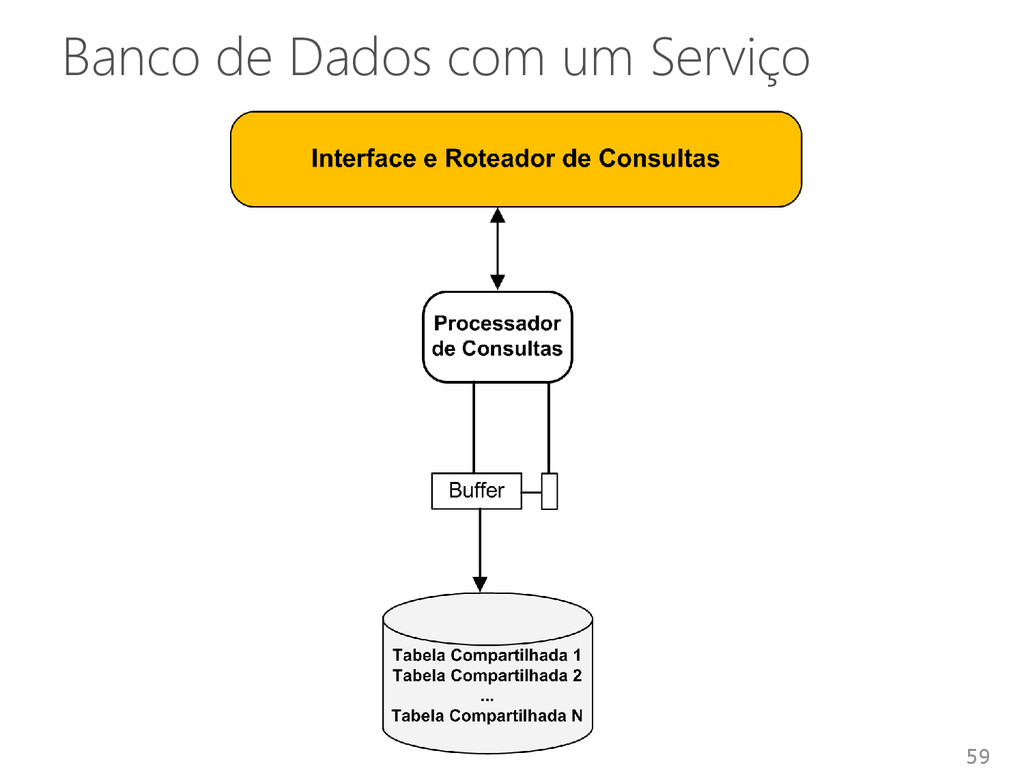
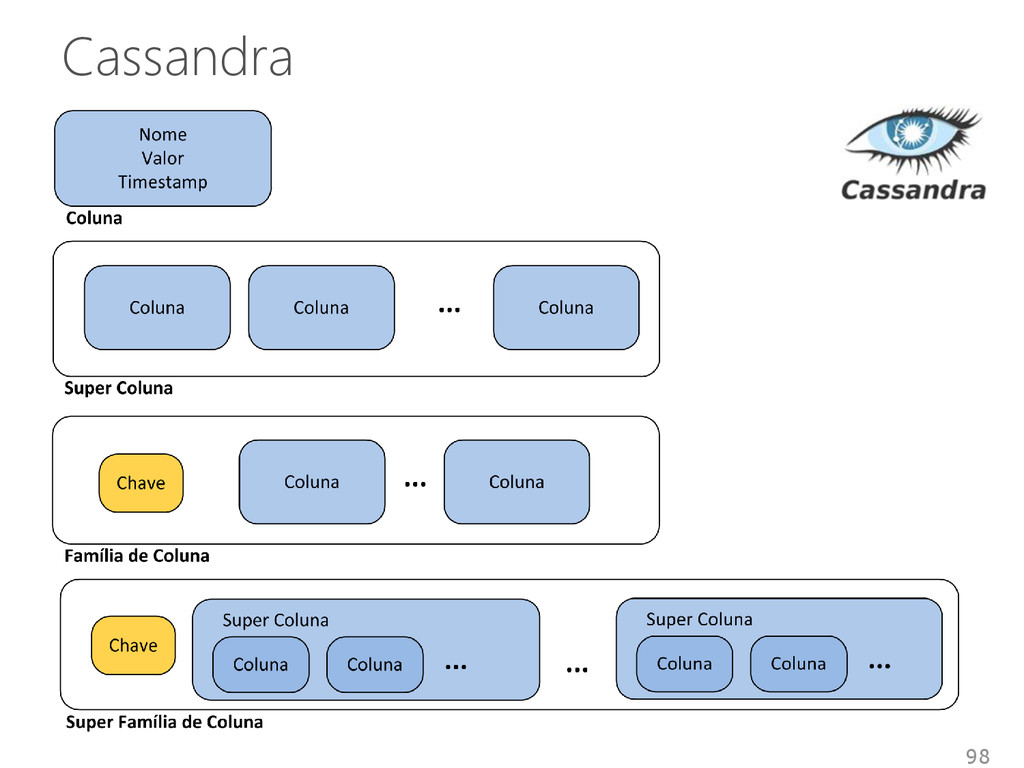
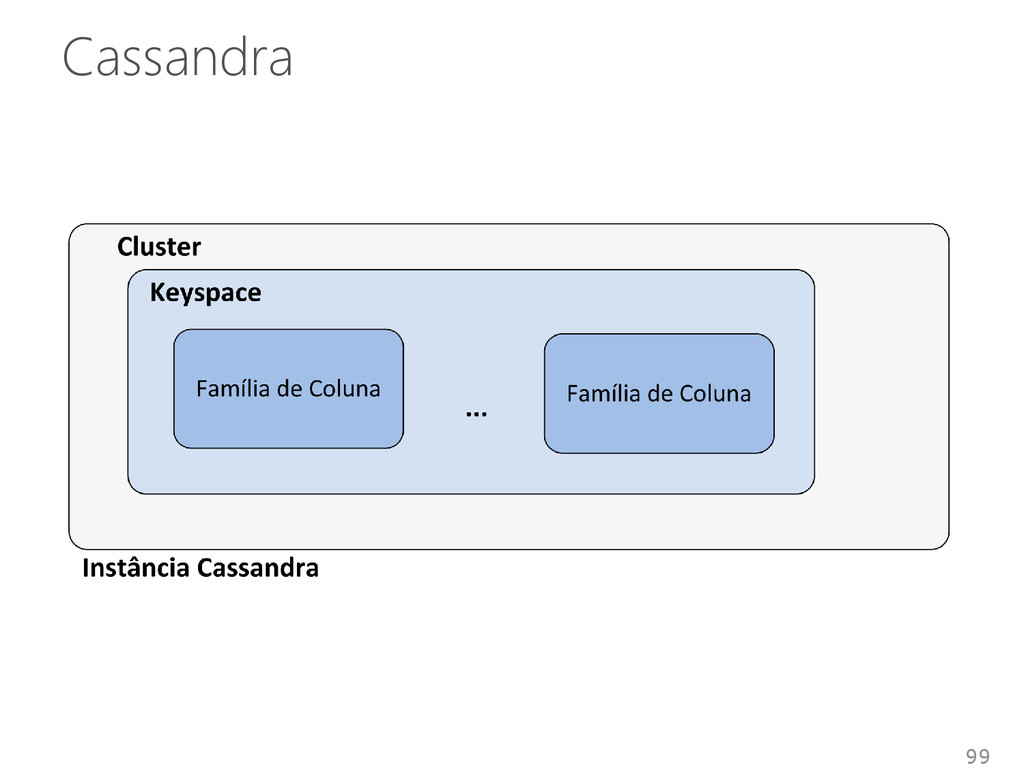
de múltiplos inquilinos em um único sistema Inquilino • SGBD • Banco de dados • Inquilino Compartilhamento de infraestruturas entre inquilinos • Diferentes níveis de abstração e isolamento 53
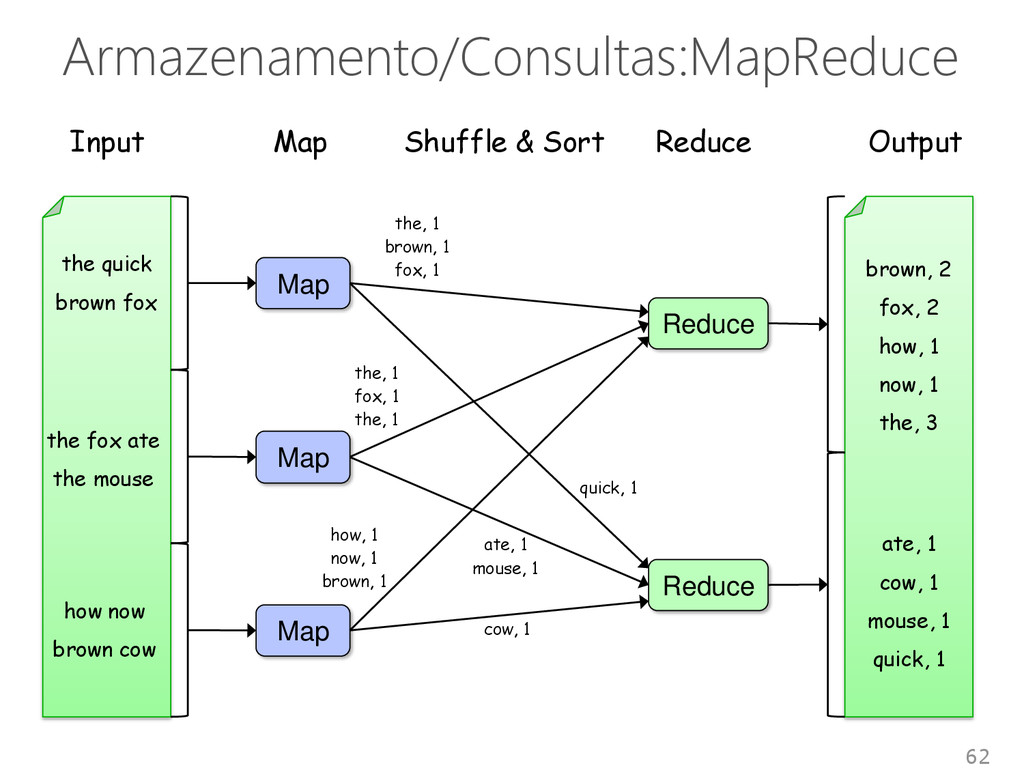
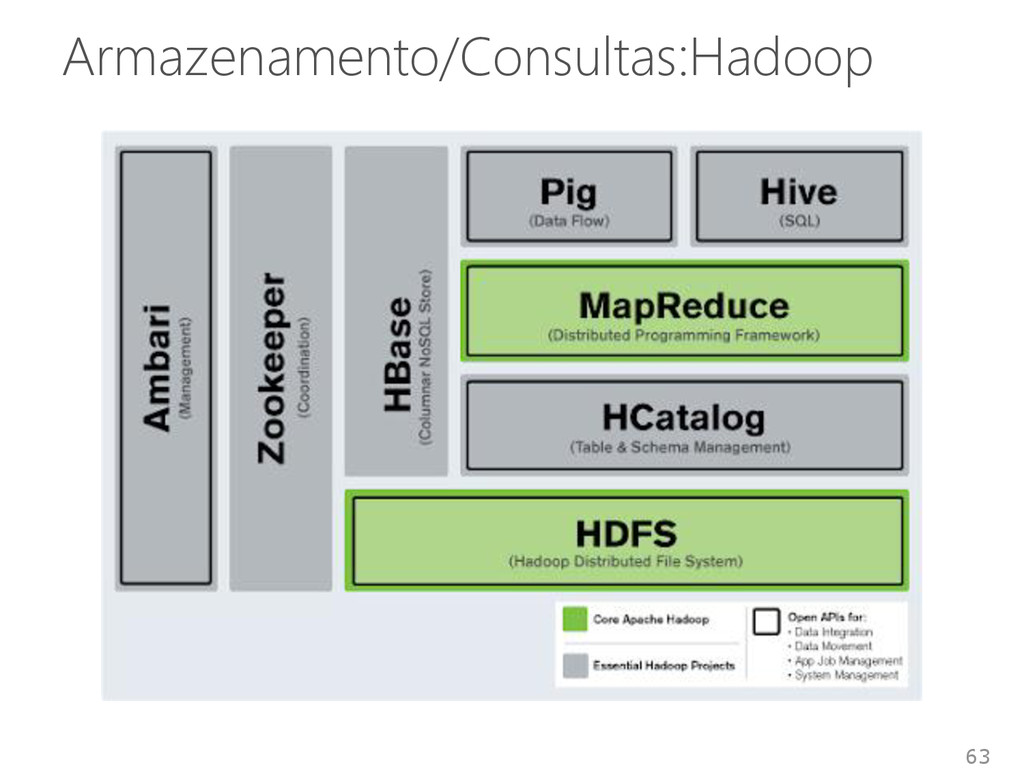
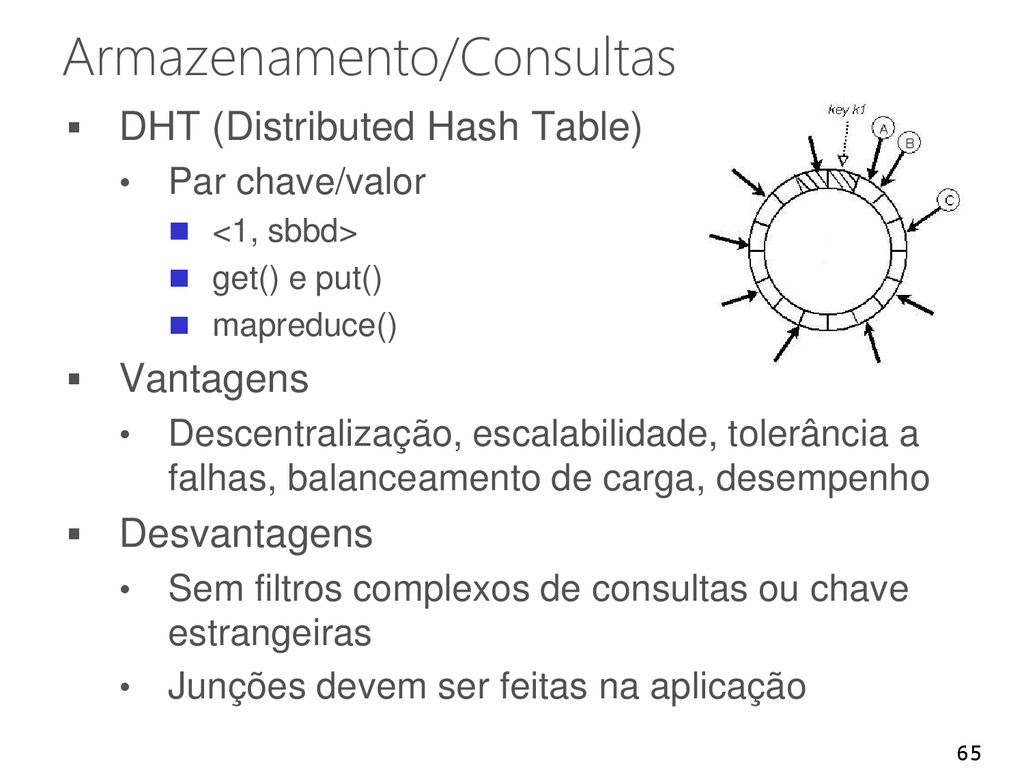
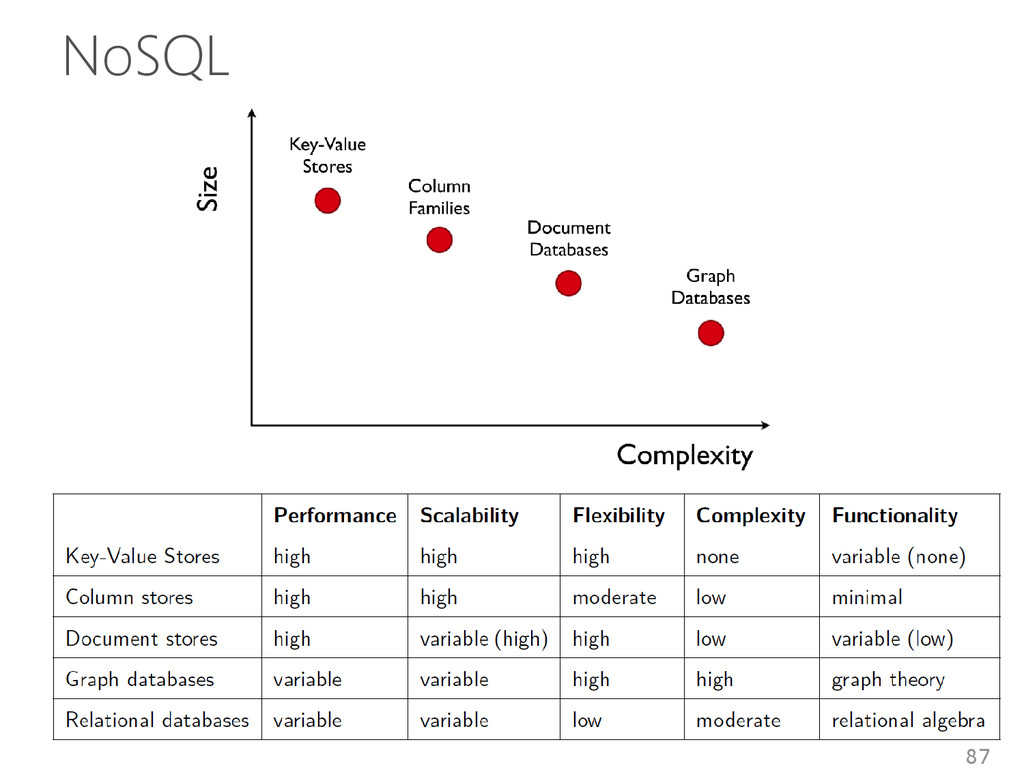
<1, sbbd> get() e put() mapreduce() Vantagens • Descentralização, escalabilidade, tolerância a falhas, balanceamento de carga, desempenho Desvantagens • Sem filtros complexos de consultas ou chave estrangeiras • Junções devem ser feitas na aplicação 65
documento Coleção de pares chave-valor • Esquema flexível • Diferentes formatos: JSON, XML, outros. Grafo • Vértices, arestas e propriedades • Gerenciamento de dados com estruturas diferenciadas e consultas complexas. 67
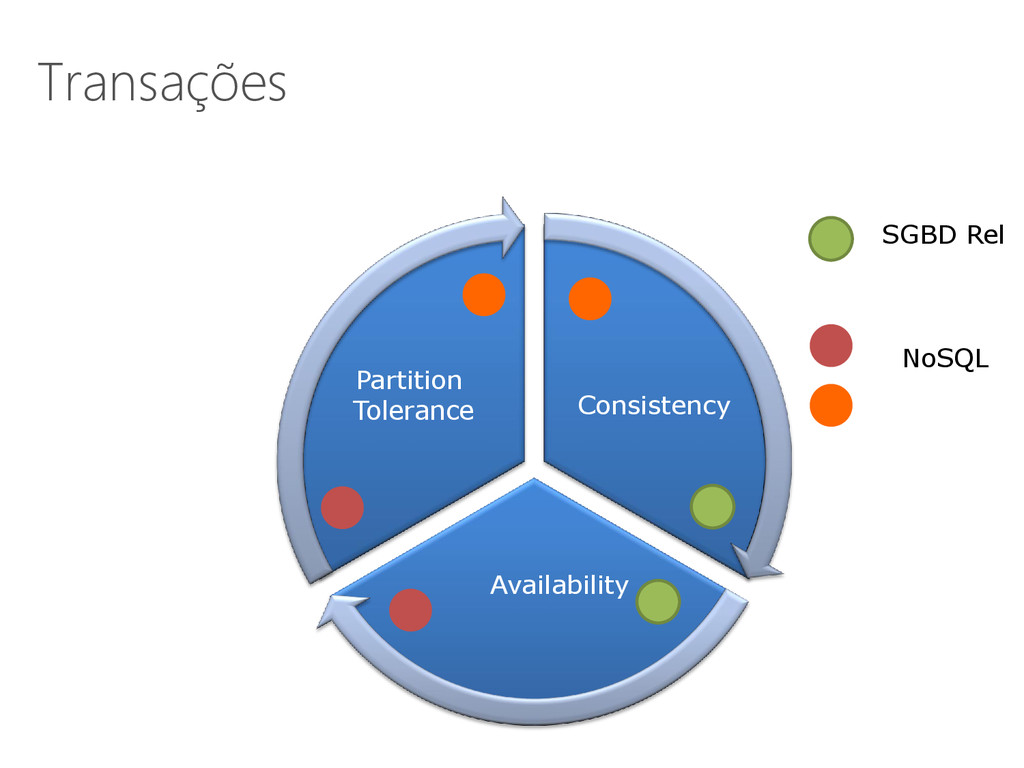
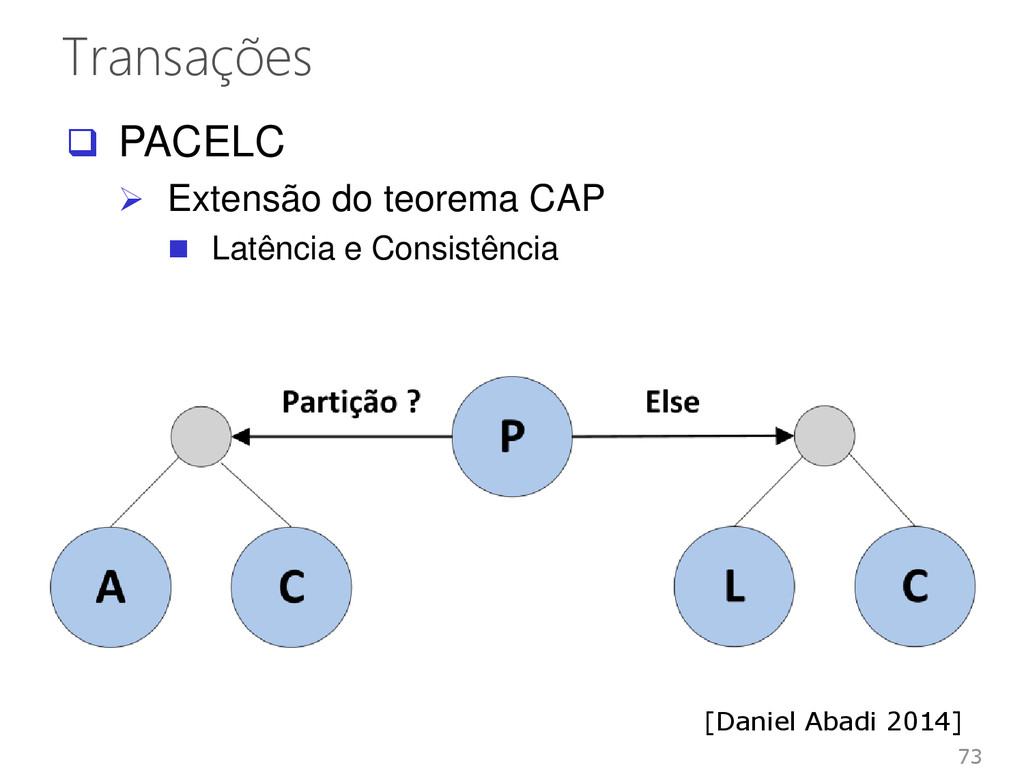
[Gilbert & Lynch, 2002] • Um sistema distribuído não pode assegurar as seguintes propriedades de um vez: Consistência Disponibilidade Tolerância a partições 68
consistent) BASE • Basicamente disponível • Estado leve • Eventualmente consistente Consistência eventual • O sistema garante que, se nenhuma atualização for feita ao dado, todos os acessos irão devolver o último valor atualizado 72
desenvolvimento de soluções eficazes Pode comprometer o desempenho no processamento de consultas executadas de forma paralela Garantias de QoS • De acordo com o SLA definido Tempo de resposta Disponibilidade Penalidades para o provedor 75
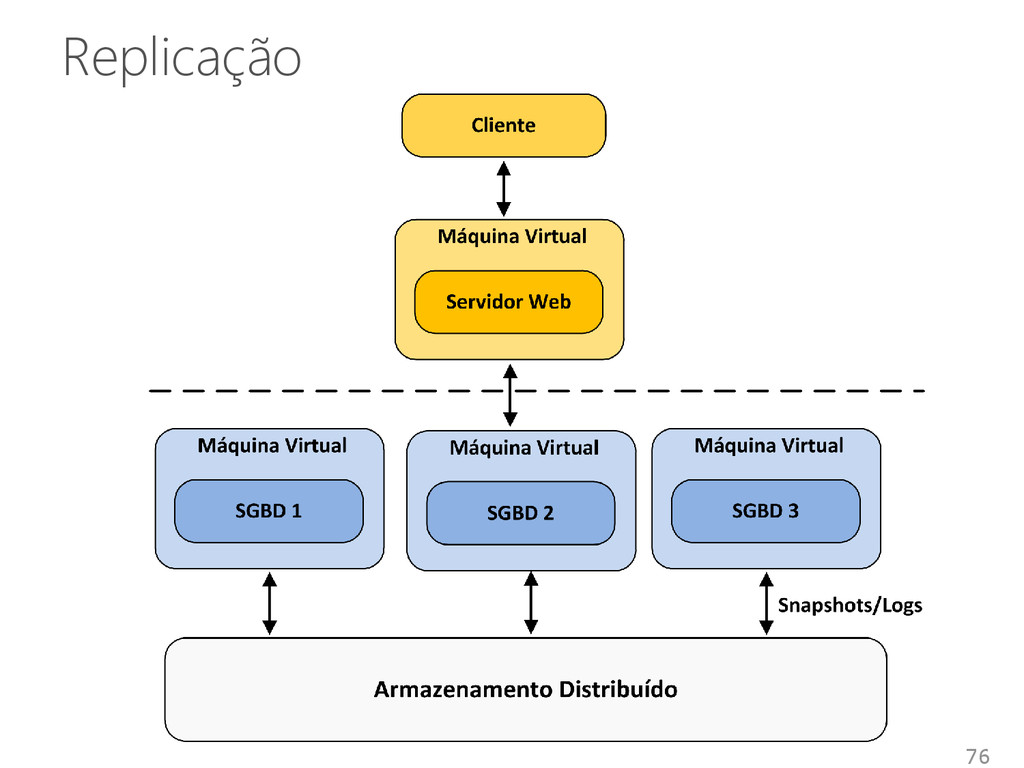
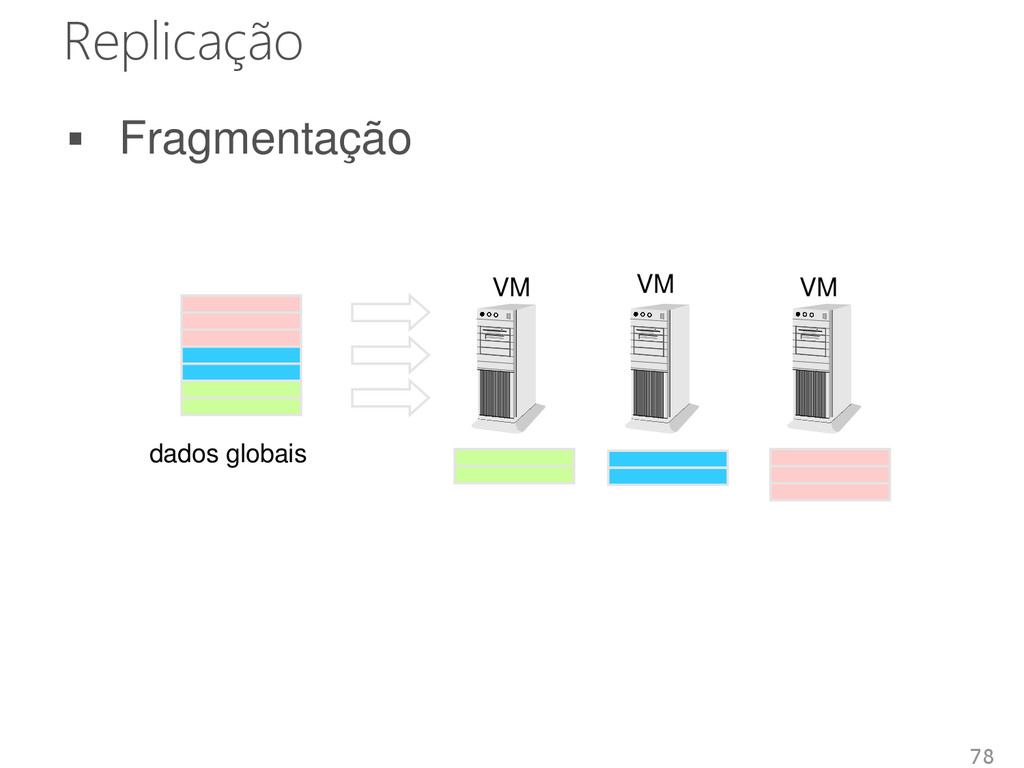
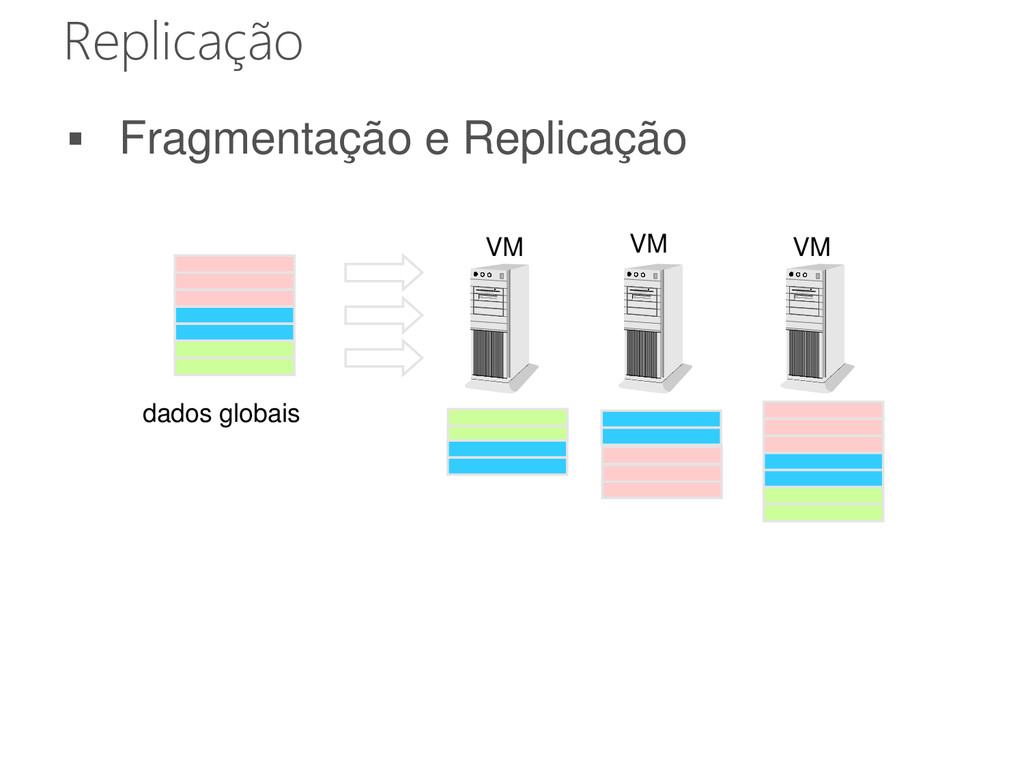
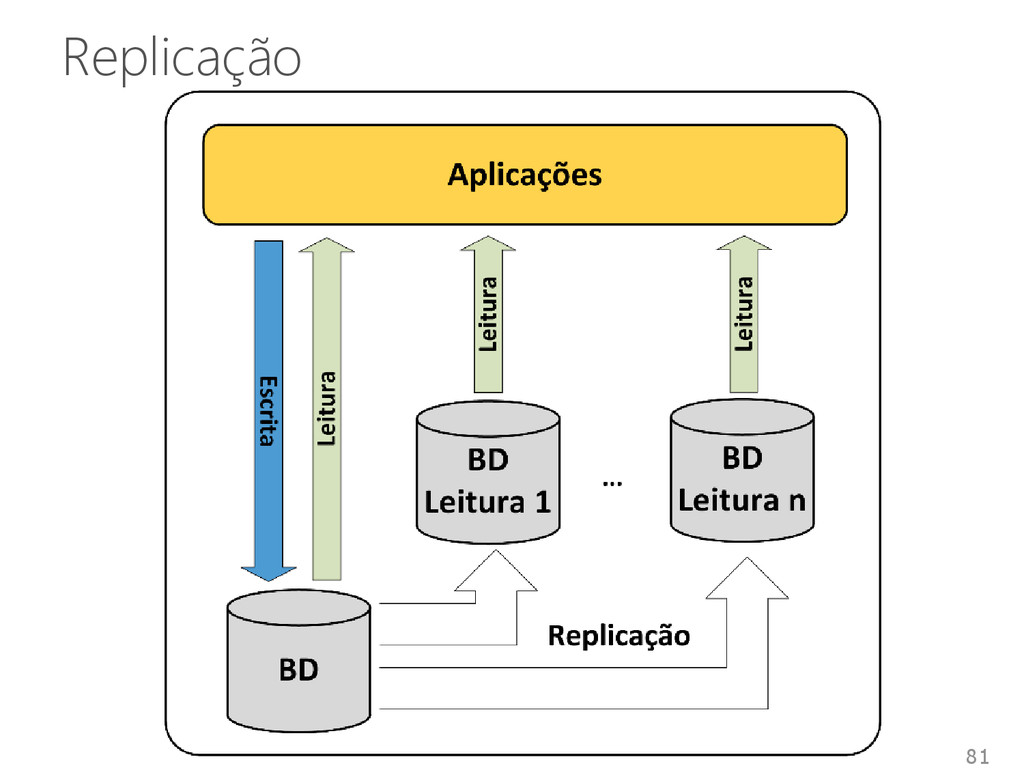
• Máquinas e redes podem falhar As soluções para gerenciamento de dados • Devem ser construídas para tratar falhas Técnicas de distribuição • Replicação • Fragmentação 77
da rede • Diferentes protocolos Cópia primária, Réplica ativa, Paxos, Gossip • Técnicas para trabalhar com máquinas virtuais Fragmentação • Estruturas: DHT e orientada a coluna • Facilita a distribuição dos dados 80
• API simples • Escalabilidade • Consistência eventual O desempenho depende da remoção das sobrecargas [Stonebraker 2010] • Logging, bloqueio, gerenc. de buffer, entre outras Tem pouco a ver com o SQL 84
• Baseado no Amazon Dynamo • Modelo chave valor DHT • Escalabilidade, disponibilidade, balanceamento de carga e heterogeneidade Linguagem • get() e put() Ausência de transações Consistência eventual 91
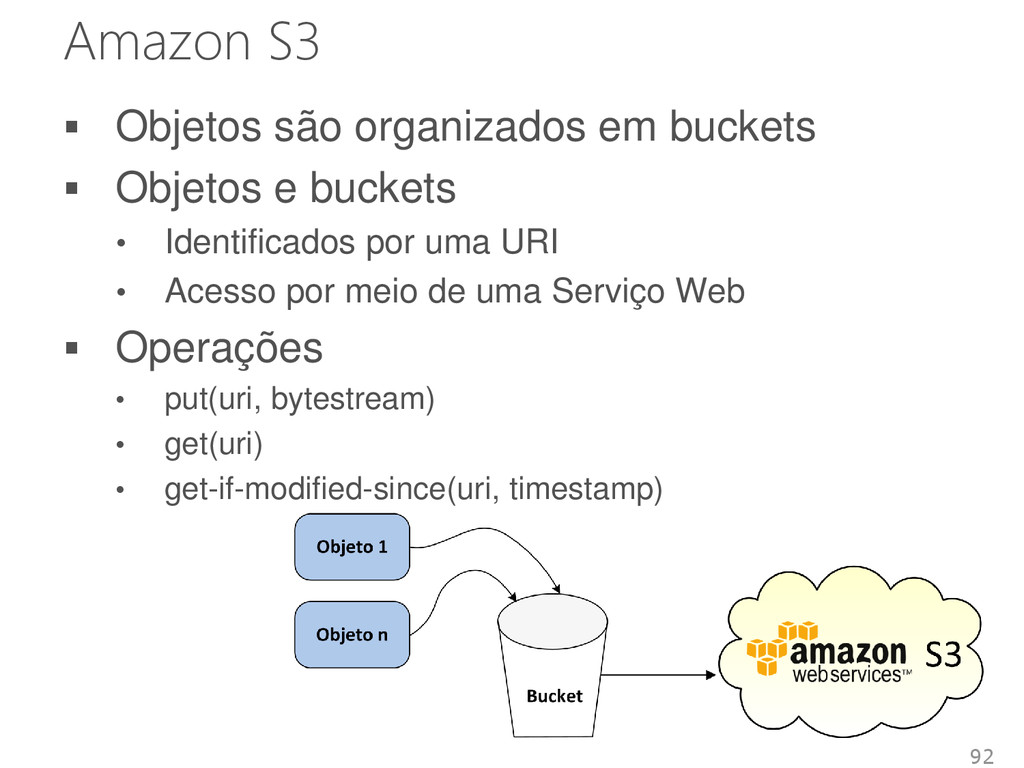
Objetos e buckets • Identificados por uma URI • Acesso por meio de uma Serviço Web Operações • put(uri, bytestream) • get(uri) • get-if-modified-since(uri, timestamp)
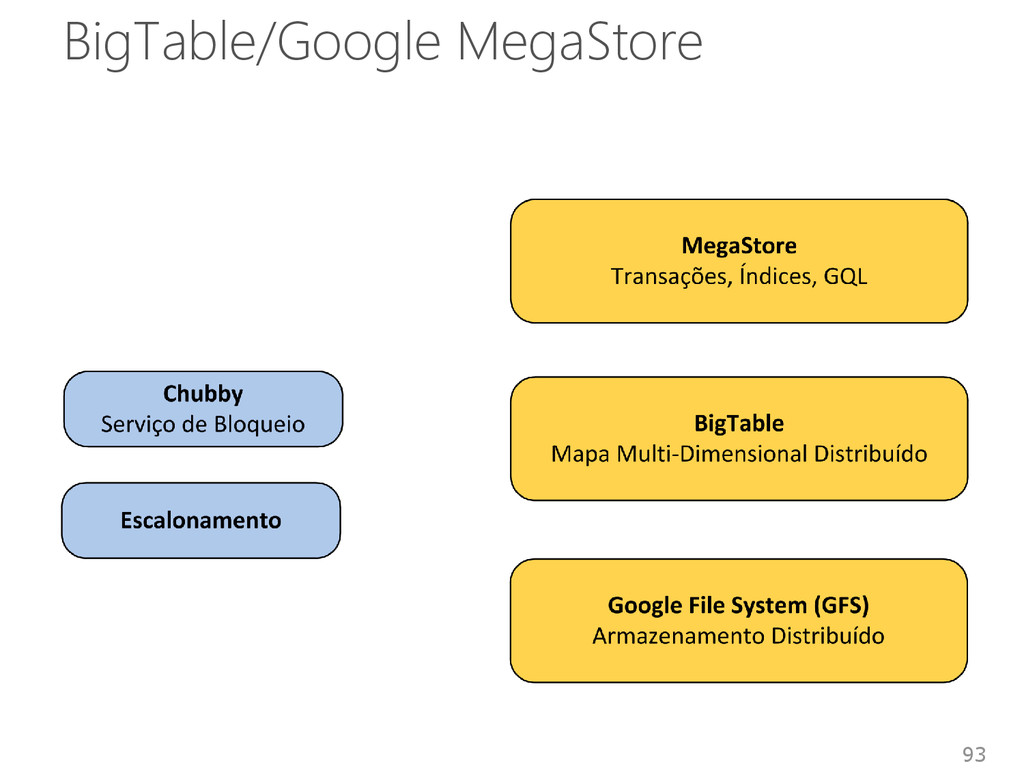
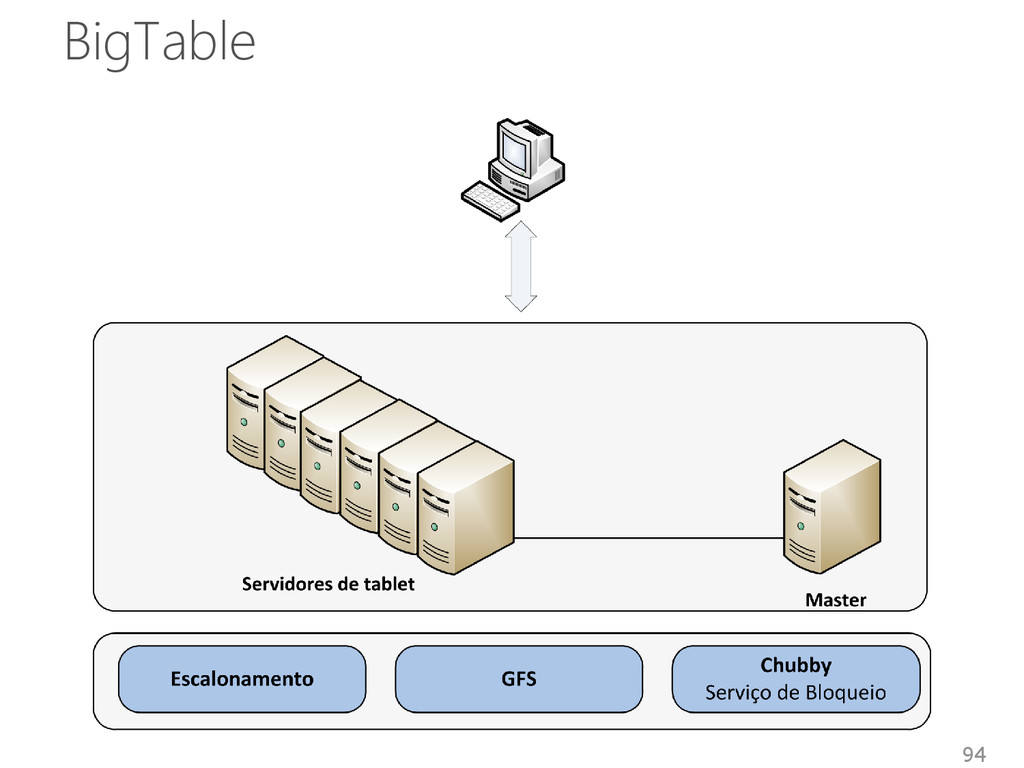
Acesso: API Python e Java • GQL (Google Query Language) Select, Where Order By, Limit e In. Transação • Suporte a transações por meio das APIs • Transações aplicadas a entidades Unidade de consistência, escalabilidade, replicação 96
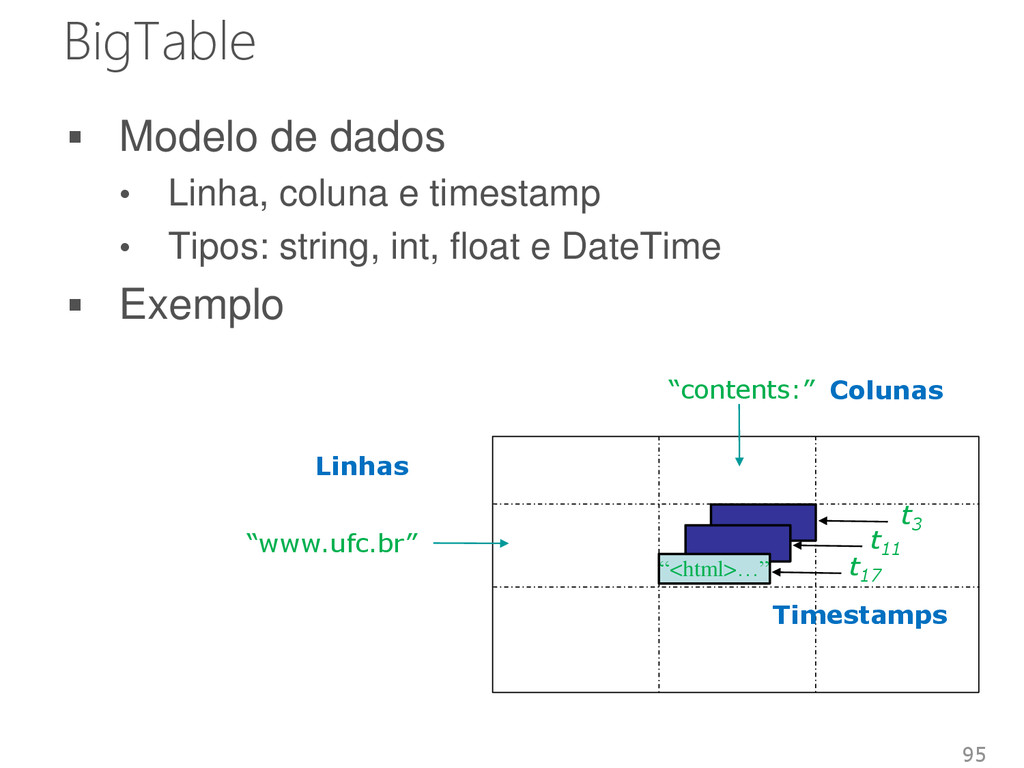
Características de 2 sistemas • Arquitetura descentraliza do Dynamo • Modelo de dados do BigTable Armazenamento • Baseado em índices Linguagem • API Simples Instruções de seleção, inserção, atualização e remoção de dados 97
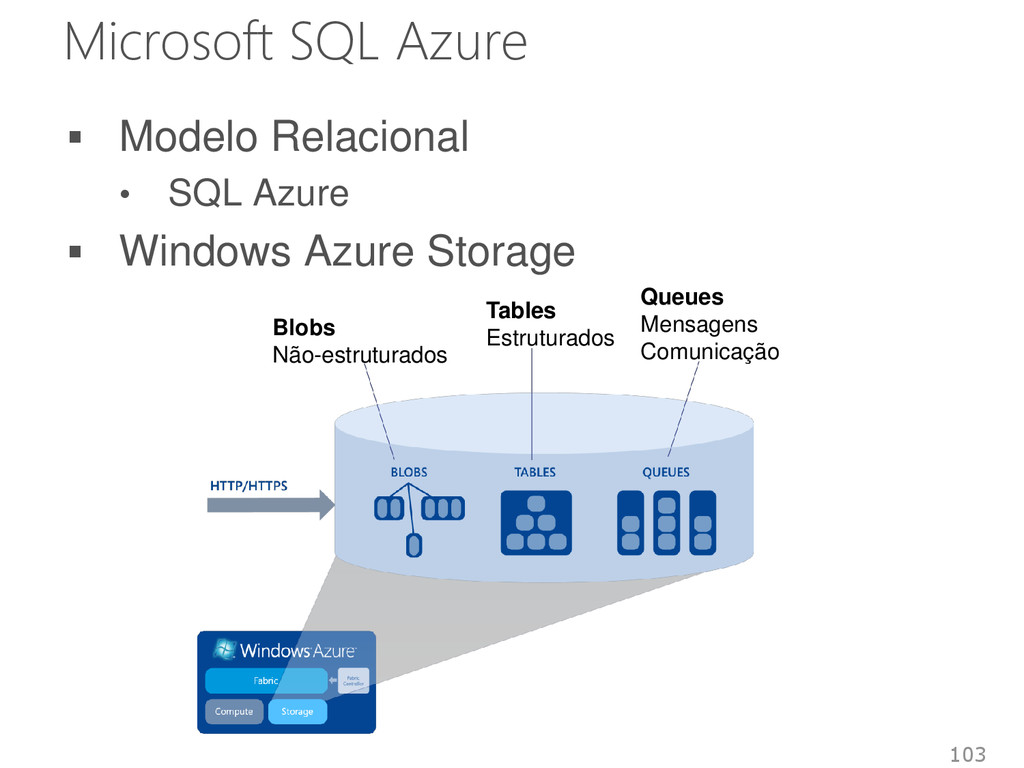
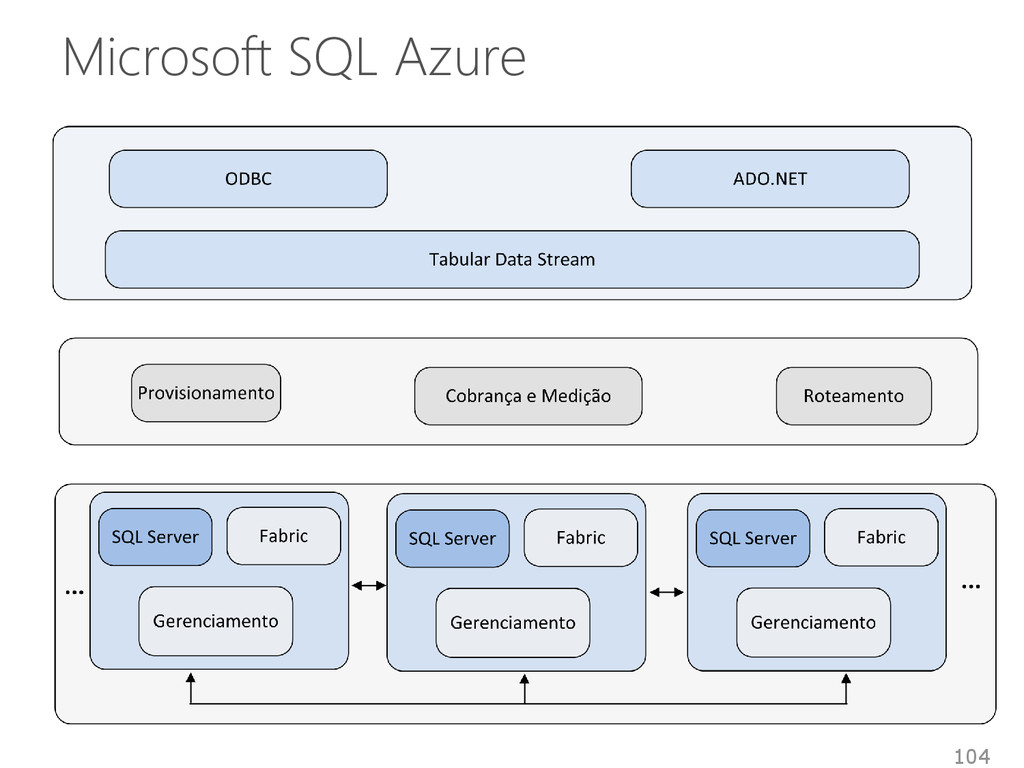
Não suporta transações distribuídas • Consistência forte Alta disponibilidade e tolerância a falhas • Azure Data Center Implementa o modelo multi-inquilino 105
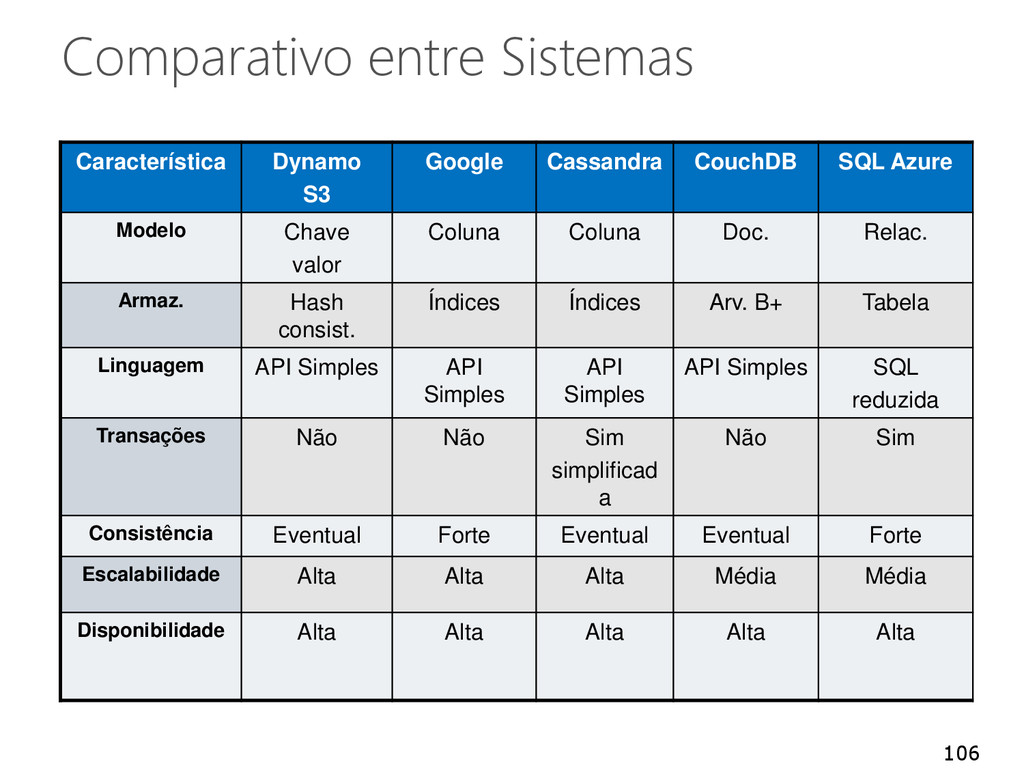
Azure Modelo Chave valor Coluna Coluna Doc. Relac. Armaz. Hash consist. Índices Índices Arv. B+ Tabela Linguagem API Simples API Simples API Simples API Simples SQL reduzida Transações Não Não Sim simplificad a Não Sim Consistência Eventual Forte Eventual Eventual Forte Escalabilidade Alta Alta Alta Média Média Disponibilidade Alta Alta Alta Alta Alta 106
Consistência SGBDs Virtualizados Qualidade dos Serviços de Dados SGBDs Multi-Inquilino Segurança e Privacidade dos Dados Avaliação de Serviços de Dados em Nuvem Computação em Nuvem para Big Data 109
dados e necessidade de gerenciar e analisar • Novas arquiteturas para paralelizar o processamento OLAP • Desenvolver sistemas que combinem as abordagens OLAP e OLTP • Interação com novos sistemas de arquivos e sistemas legados Linguagens com restrições • Novas linguagens de consultas • API comum para vários serviços 110
diferentes • Desenvolver técnicas para prover escalabilidade e elasticidade • Construir soluções com suporte a consistência forte • Desenvolver soluções para garantir escalabilidade, disponibilidade e consistência 111
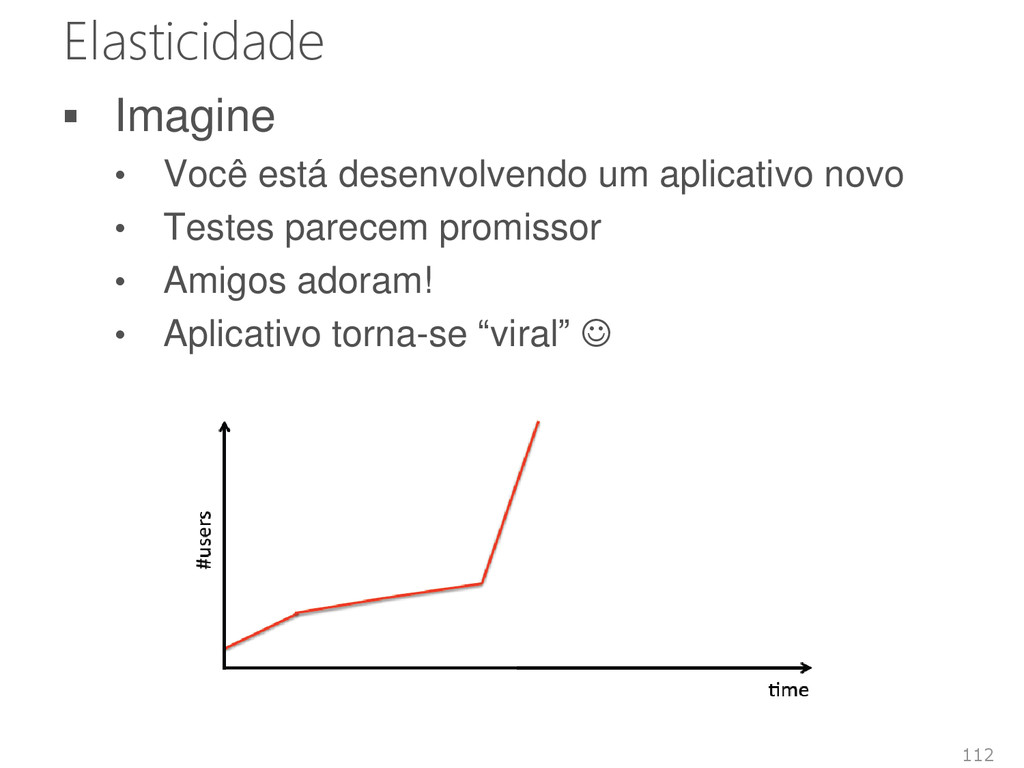
Replicação Redimensionamento Migração Como medir a elasticidade? Novas métricas Novas ferramentas Demand Capacity Time Resources Demand Capacity Time Resources
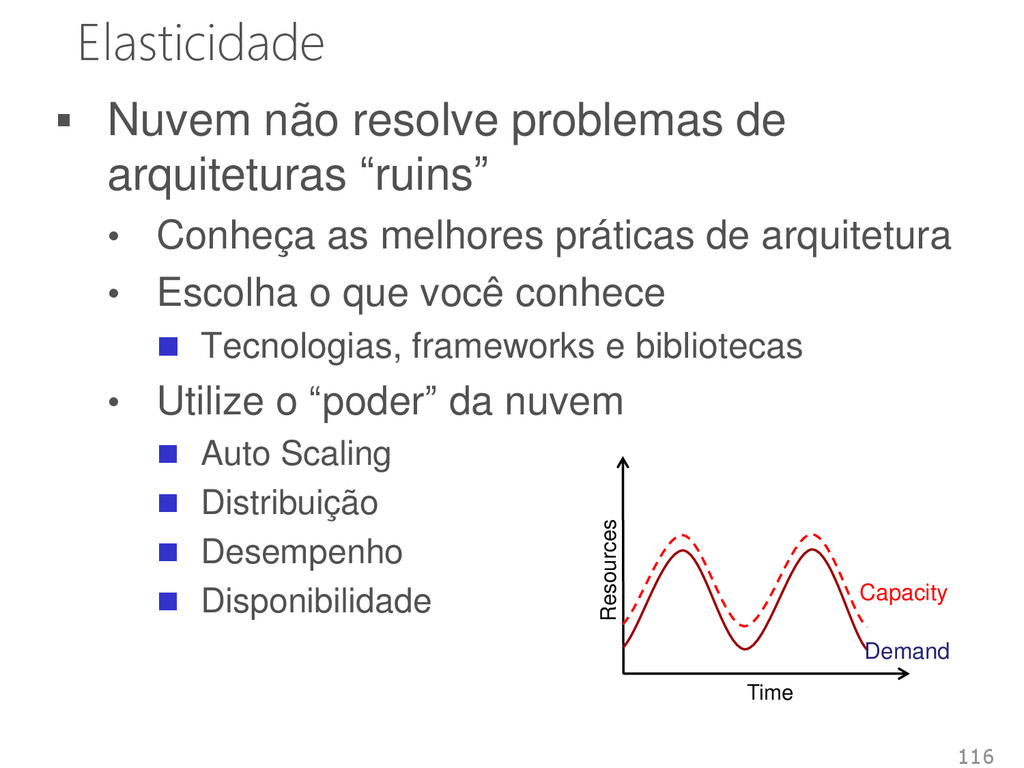
Conheça as melhores práticas de arquitetura • Escolha o que você conhece Tecnologias, frameworks e bibliotecas • Utilize o “poder” da nuvem Auto Scaling Distribuição Desempenho Disponibilidade 116 Demand Capacity Time Resources
utilização dos SGBDs em nuvem • Integração das tecnologias de virtualização com SGBDs Tratar cargas de trabalho inesperadas • Replicação e fragmentação • Provisionar e alocar recursos 117
nuvem devem fornecer alta disponibilidade Diferentes abordagens para melhorar a disponibilidade • Redundância • Nuvens híbridas • Balanceamento dinâmico de carga 118
mesmo em condições extremas Técnicas adaptativas e dinâmicas Auto sintonia de parâmetros baseada na carga de trabalho Compreensão automática da carga de trabalho Experimentação 119
modelos de dados Interoperabilidade entre provedores Questões de contrato, SLA e governança Soluções de segurança no acesso e ataques Privacidade, integridade e auditoria Técnicas de criptografia Novas estratégias para garantir a segurança
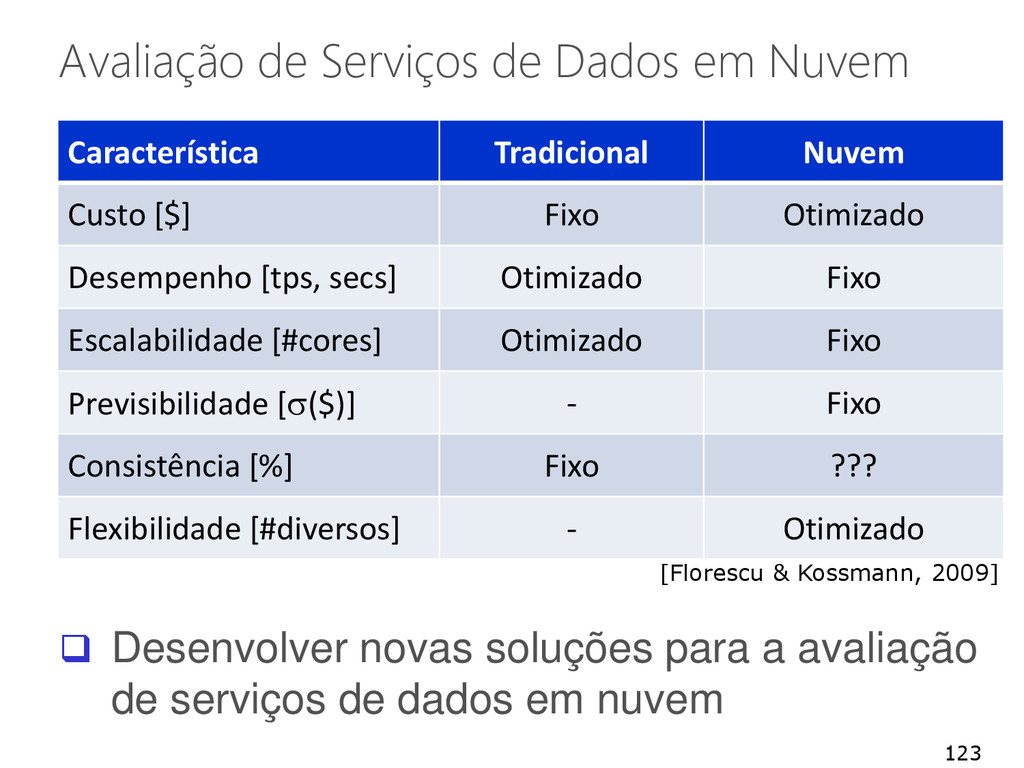
novas soluções para a avaliação de serviços de dados em nuvem Característica Tradicional Nuvem Custo [$] Fixo Otimizado Desempenho [tps, secs] Otimizado Fixo Escalabilidade [#cores] Otimizado Fixo Previsibilidade [s($)] - Fixo Consistência [%] Fixo ??? Flexibilidade [#diversos] - Otimizado Desenvolver novas soluções para a avaliação de serviços de dados em nuvem [Florescu & Kossmann, 2009]
de serviços em nuvem • Qual o melhor serviço para um determinado propósito? Necessidade de serviços de benchmarks • Avaliar diferentes tipos de serviços • Ferramentas para gerar cargas de trabalho, monitorar o desempenho • Métricas para calcular o custo por usuário em uma determinada unidade de tempo • Desenvolvimento de sistemas de simulação Ex. CloudSim
• Qual é o impacto no trânsito e no preços das casas com construção de uma nova ponte? Perguntas em tempo real • Existe um ataque cibernético acontecendo? Perguntas em abertas • Quantos supernovas aconteceram no ano passado?
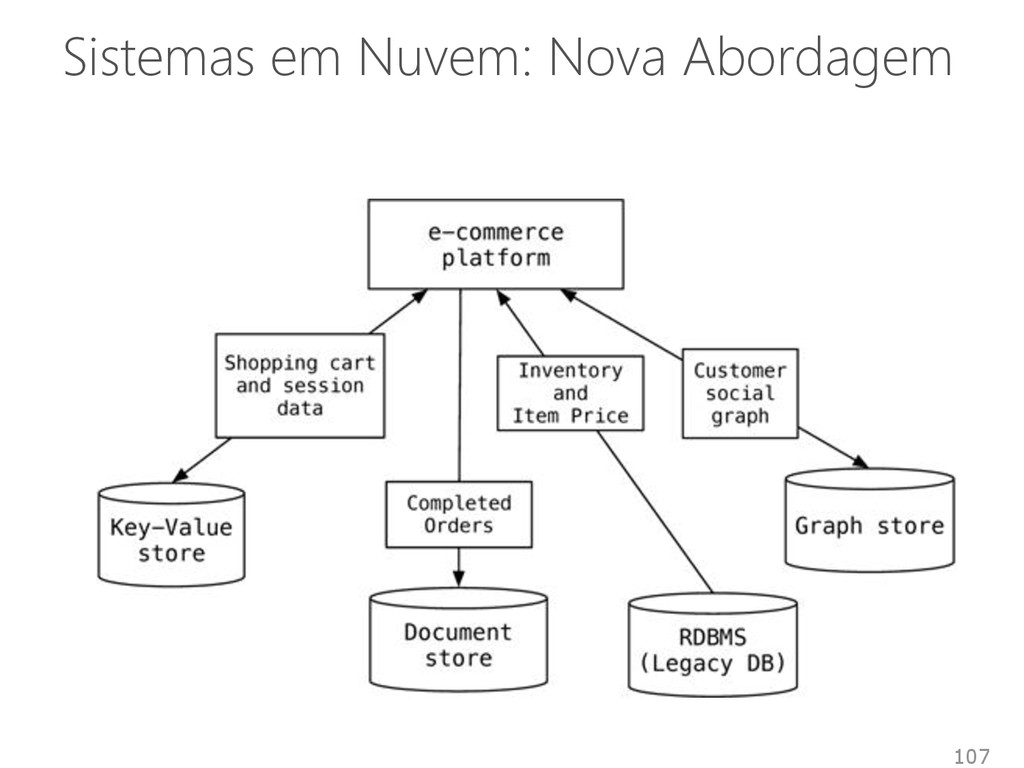
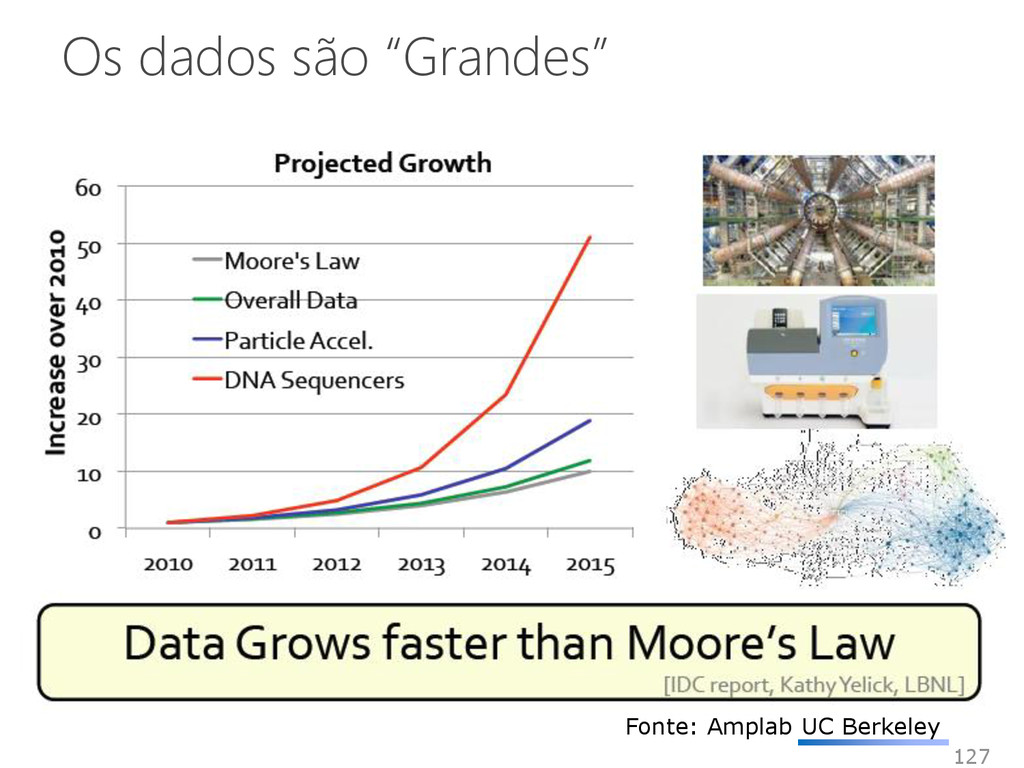
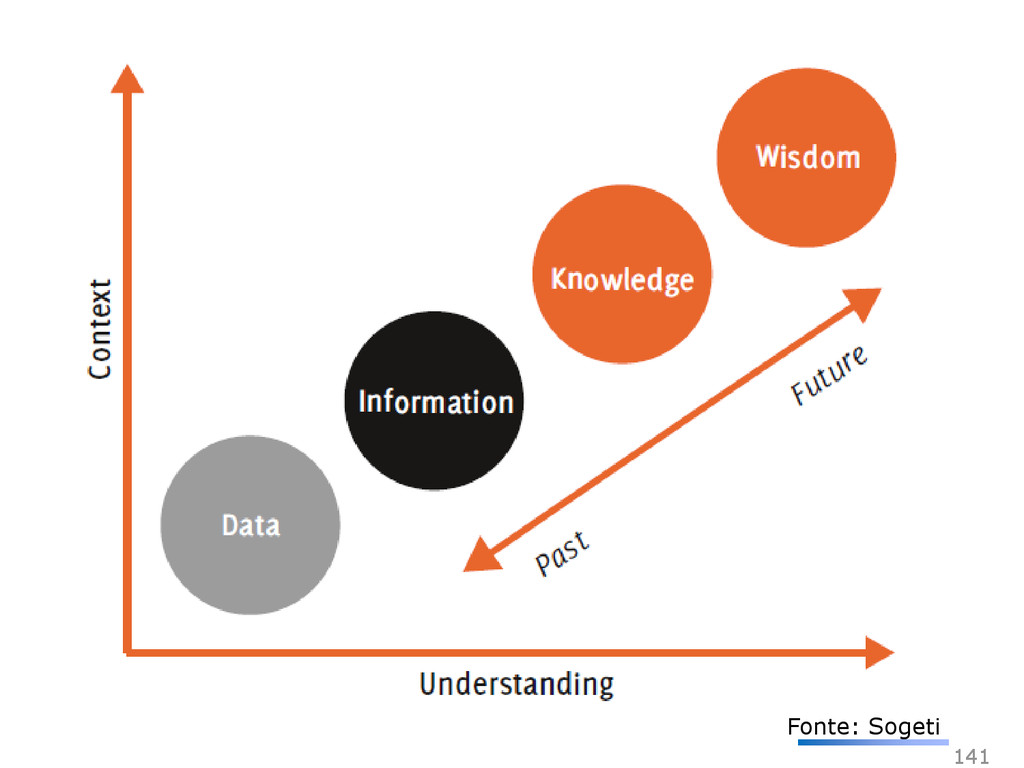
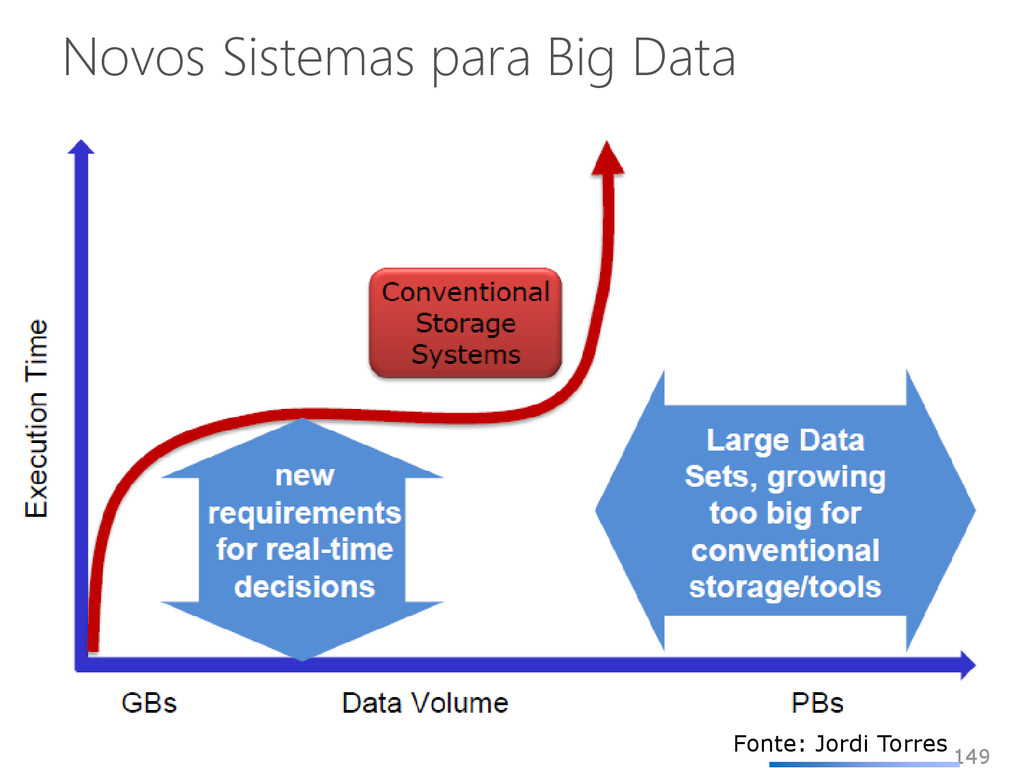
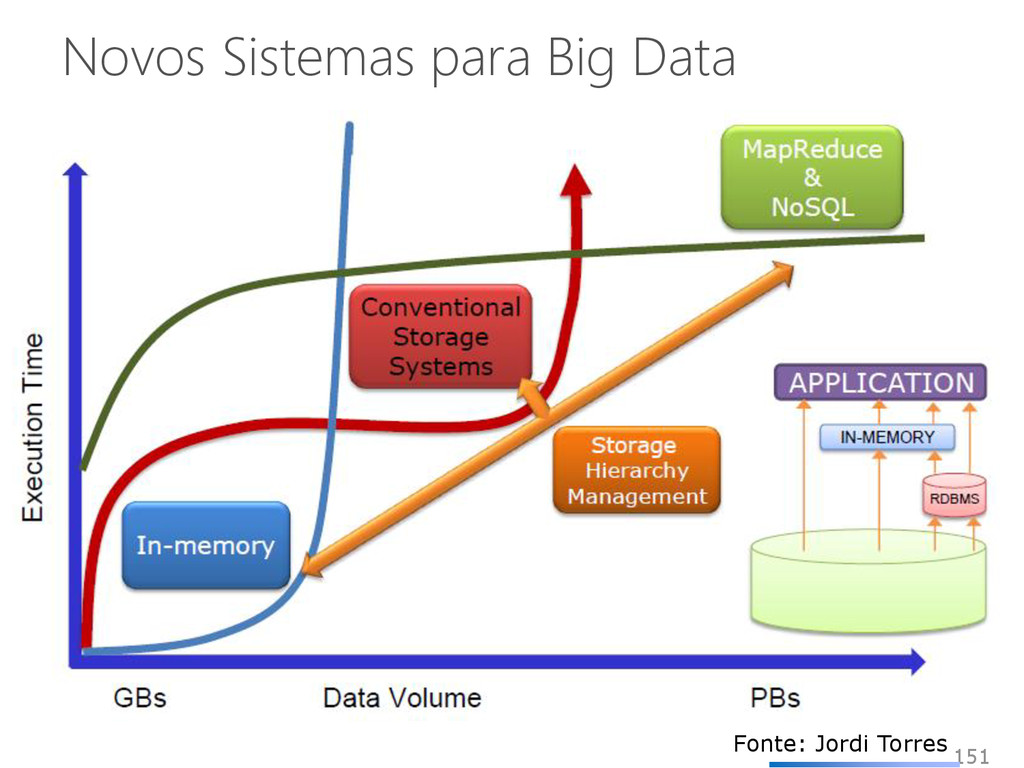
armazenamento, o processamento e a capacidade dos sistemas convencionais • Volume de dados muito grande • Dados são gerados rapidamente • Dados não se encaixam nas estruturas de arquiteturas de sistemas atuais Além disso, para obter valor a partir desses dados, é preciso mudar a forma de analisá-los 131 Fonte: Jordi Torres
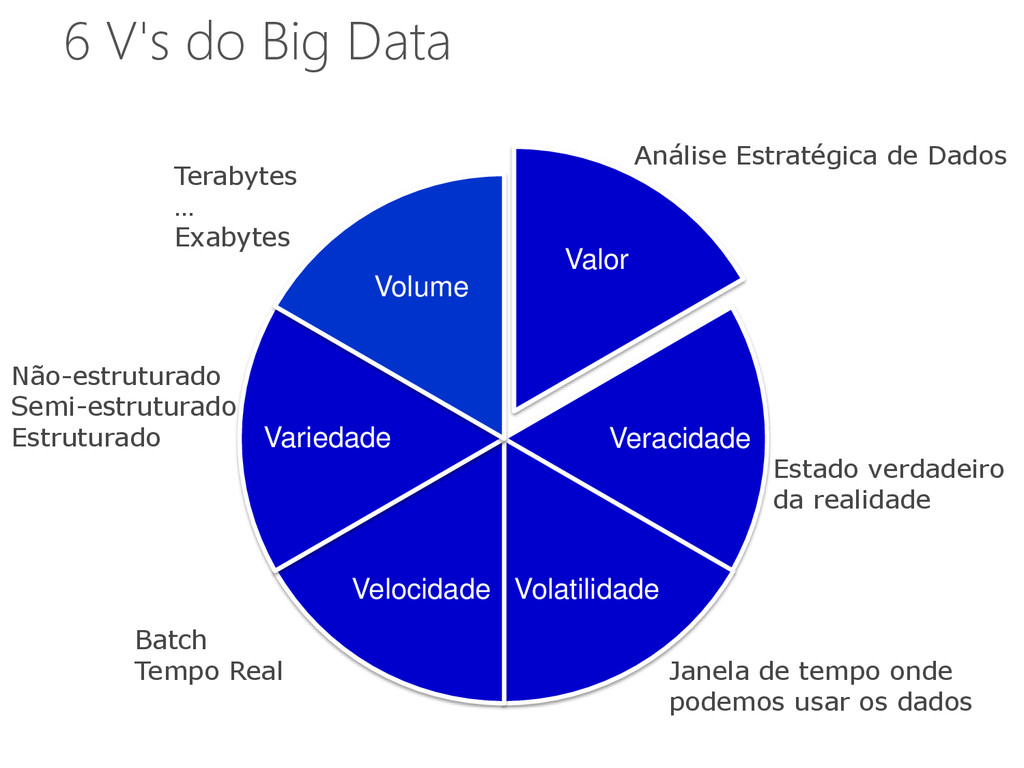
Volume Não-estruturado Semi-estruturado Estruturado Terabytes … Exabytes Batch Tempo Real Janela de tempo onde podemos usar os dados Estado verdadeiro da realidade Análise Estratégica de Dados
analytic applications will use predictive capabilities. Gartner Business Intelligence Summit 2012 If you can predict it, you can own it… • Forecasting • Targeting • Fraud detection • Risk • Customer churn, conversion • Propensity • Price Elasticity 138
é explorar os grandes volumes de dados e extrair informações úteis ou conhecimento para futuras ações” Fonte: Rajaraman and Ullman 2012 Análise para Big Data
clientes e quais produtos eles estão comprando? Quais clientes são mais propoensos a comprar no concorrente? Qual impacto da venda de novos produtos nos lucros? Quais promoções geram mais lucros? Qual a distribuição mais eficiente? Análise para Big Data Fonte: VLDB 2010
pessoas, processos e tecnologias. Todas as três devem marchar em sincronia, caso contrário o projeto falhará.” O que precisamos ? Fonte: Big Data, Big Analytics; Minelli, Chamber, Dhira; Wiley CIO Series, 2013
do Big Data • Heterogeneidade • Análise de padrões temporais • Processamento em tempo real • Incerteza • Subjetividade • Ambiguidade Novas tecnologias • Big Data + Cloud Segurança dos dados • Privacidade
• Alta dimensionalidade dos dados • Acúmulo de outliers • Correlação incorreta dos dados • Alto custo computacional • Necessidade de algoritmos complexos 157
são flexíveis para garantir a escalabilidade • Permite construir serviços com garantias de SLA • Trade-off entre funcionalidades e custos operacionais Os serviços em nuvem para dados oferecem: APIs mais restritas do que os SGBDs tradicionais Uma linguagem minimalista de consulta Possuem garantia de consistência limitada • Mais esforço no desenvolvimento das aplicações 159
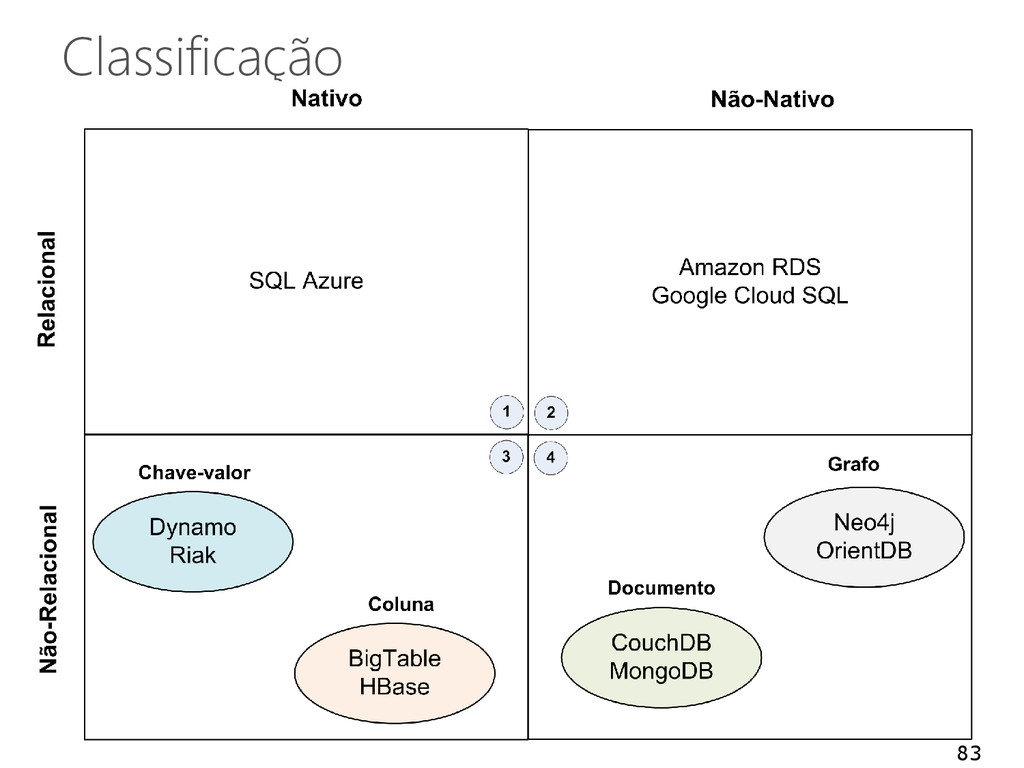
ponto fundamental • Existe uma grande quantidade de sistemas para o gerenciamento de dados em nuvem • Vários desafios Elasticidade Escalabilidade Privacidade Consistência 160
estes desafios • Necessidade de compreender as características das novas aplicações Infraestruturas terão suporte a vários modelos • Relacional, chave-valor, entre outros. Comunidade científica e indústria devem interagir • Consolidação e ampla utilização de sistemas de gerenciamento de dados em nuvem 161
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Transações Teorema CAP (Consistency, Availability, Partition Tolerance) [Brewer, 2000]](https://files.speakerdeck.com/presentations/cbedea3001680132ae422a25e2af3406/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
![Transações 71 [MongoDB 2014]](https://files.speakerdeck.com/presentations/cbedea3001680132ae422a25e2af3406/slide_70.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Obrigado! Flávio R. C. Sousa [email protected] @flaviosousa www.lia.ufc.br/~flavio](https://files.speakerdeck.com/presentations/cbedea3001680132ae422a25e2af3406/slide_161.jpg){kind=link}
![Obrigado! Flávio R. C. Sousa [email protected] @flaviosousa www.lia.ufc.br/~flavio](https://files.speakerdeck.com/presentations/cbedea3001680132ae422a25e2af3406/slide_162.jpg){kind=link}