- No retry mechanism - No error reporting - Does not scale out easily - No X - No Y - No Z - No A - No B - etc... SIMPLE IS GOOD, BUT THIS IS TOO SIMPLE
is the default, # but you can lay foundation somewhere else if you prefer # (optional) export AIRFLOW_HOME=~/airflow # install from pypi using pip pip install airflow # initialize the database airflow initdb # start the web server, default port is 8080 airflow webserver -p 8080
can be re-run - Airflow may re-run steps, so this needs to be taken into account - Idempotent operations batch_id id name surname 1 1 John Smith 1 2 Mark Shuttleworth 1 3 Luke Walker 1 4 Beth Simmons 1 5 Liz Taylor 2 1 John Smith 2 2 Mark Shuttleworth 2 3 Luke Walker 2 4 Beth Simmons 2 5 Liz Taylor 3 1 John Smith 3 2 Mark Shuttleworth 3 3 Luke Walker 3 4 Beth Simmons 3 5 Liz Taylor
Avro - Very simple - Everyone knows what it is - Order dependent - Hard to extend - Flat - No types - Very simple - Everyone knows what it is - Easy to extend - Verbose - Poor types - Not so common - Easy to extend - Space efficient - Smaller ecosystem - Rich types
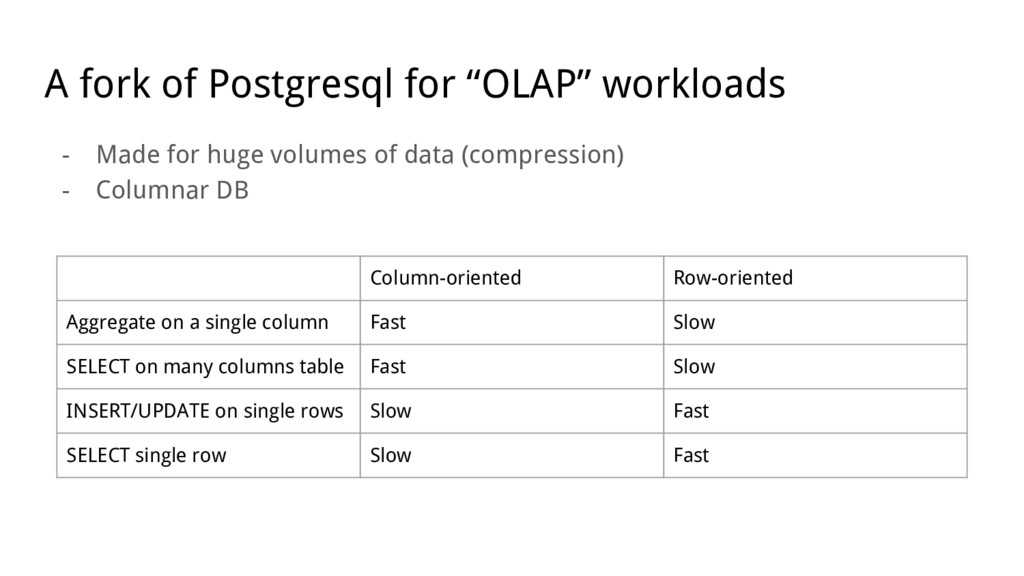
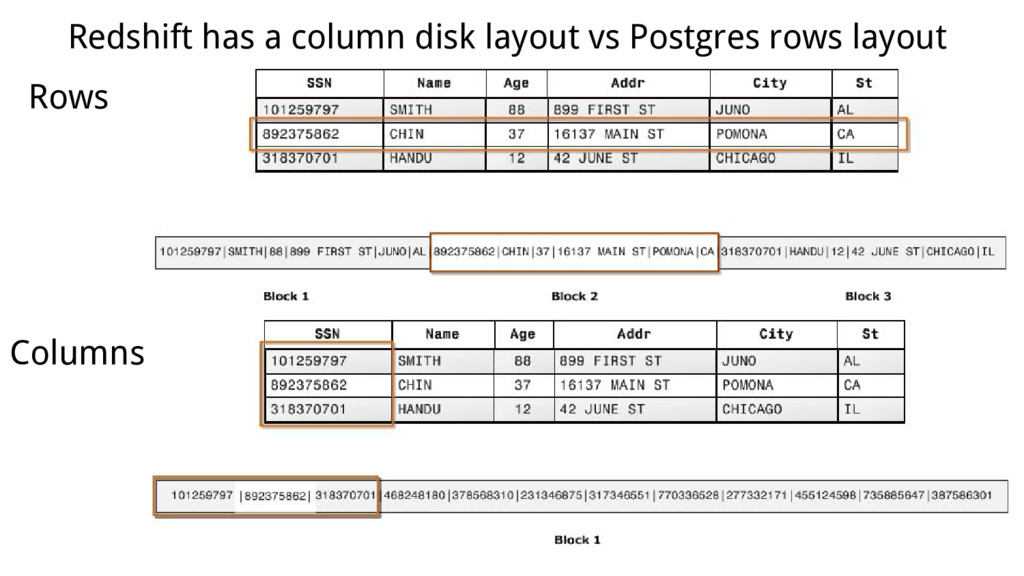
huge volumes of data (compression) - Columnar DB Column-oriented Row-oriented Aggregate on a single column Fast Slow SELECT on many columns table Fast Slow INSERT/UPDATE on single rows Slow Fast SELECT single row Slow Fast
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
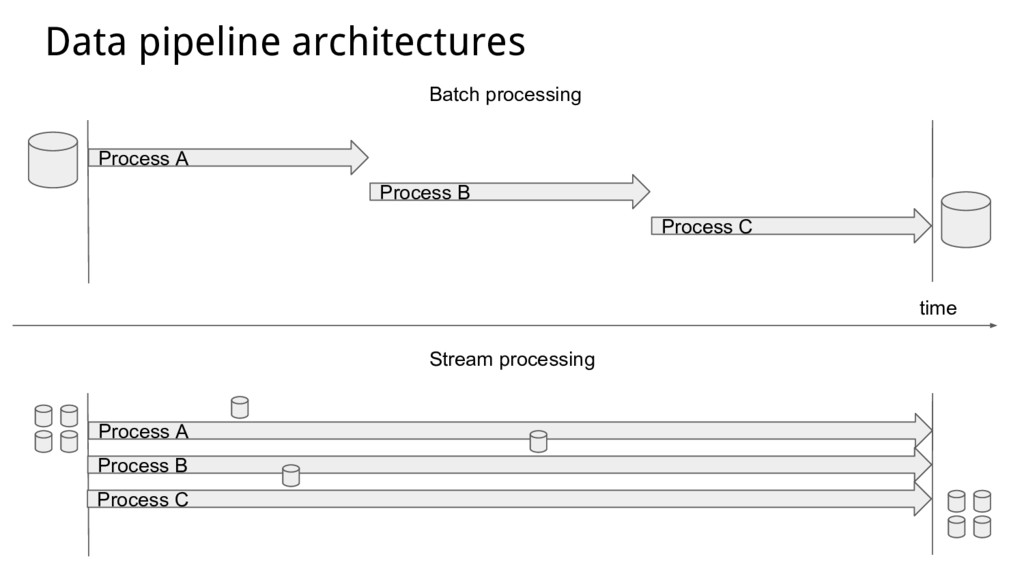{kind=link}
{kind=link}
{kind=link}
{kind=link}
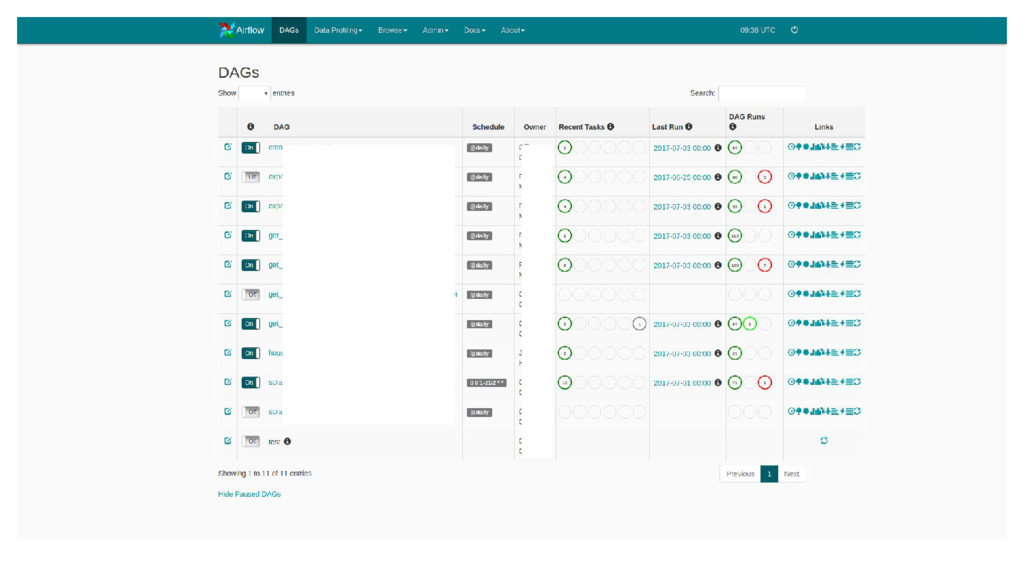{kind=link}
{kind=link}
{kind=link}
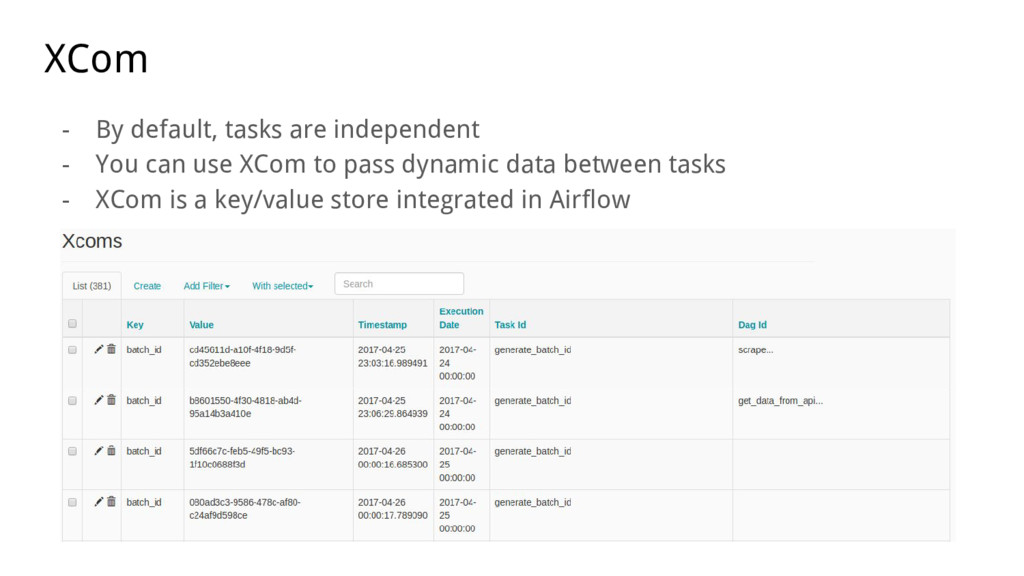{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
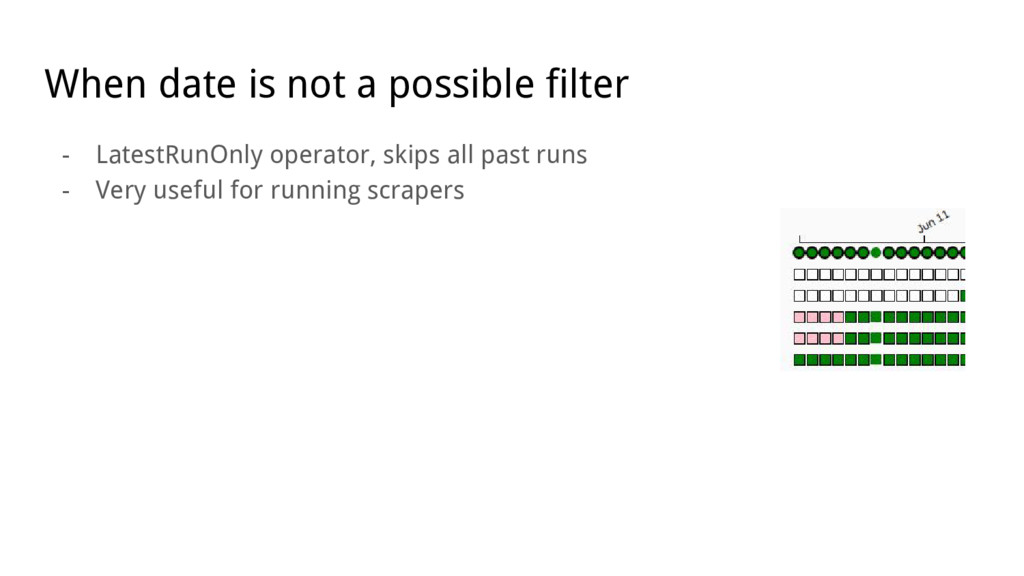{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}