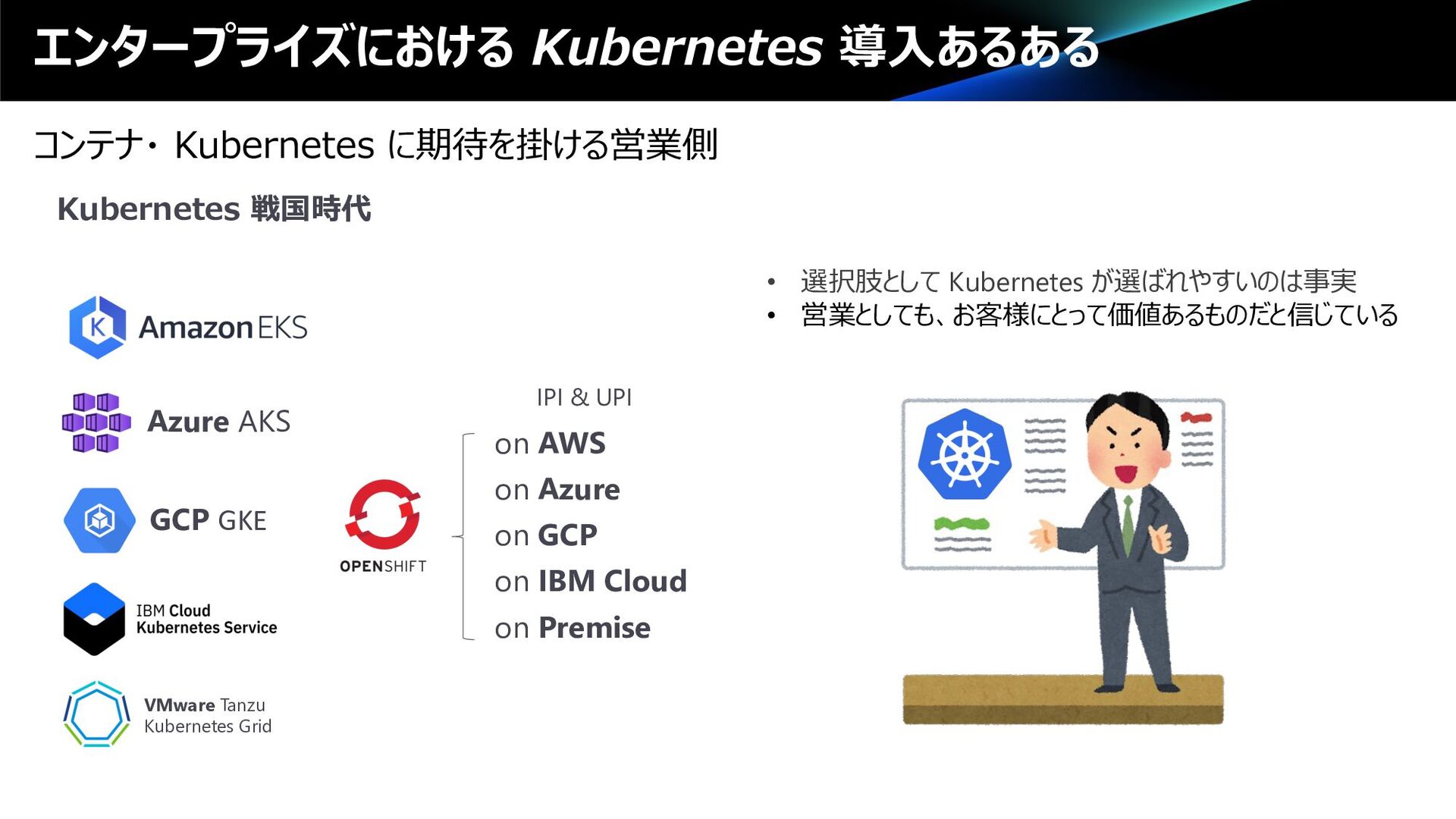
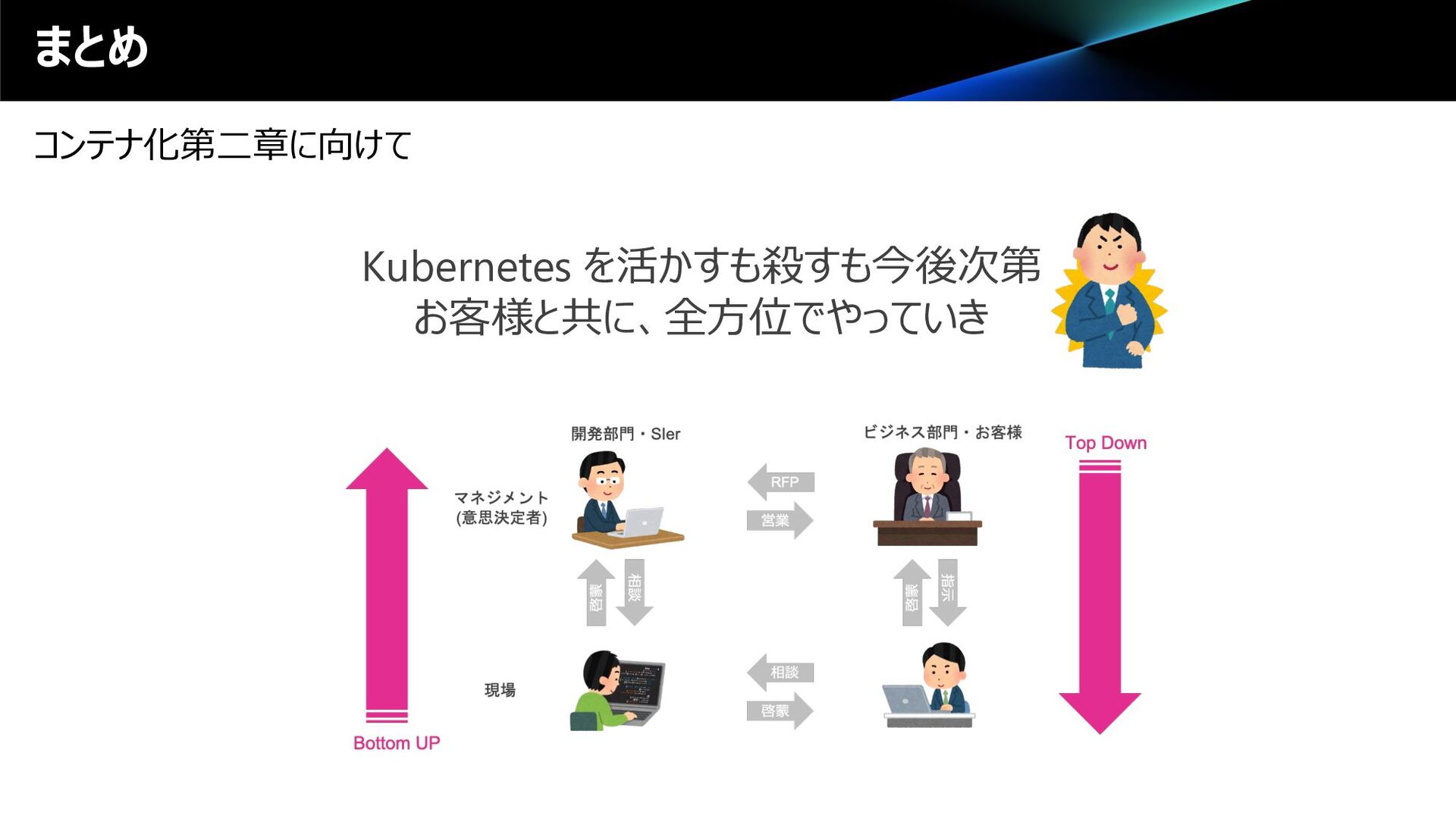
VMware Tanzu Kubernetes Grid on AWS on Azure on GCP on IBM Cloud IPI & UPI Kubernetes 戦国時代 • 選択肢として Kubernetes が選ばれやすいのは事実 • 営業としても、お客様にとって価値あるものだと信じている on Premise
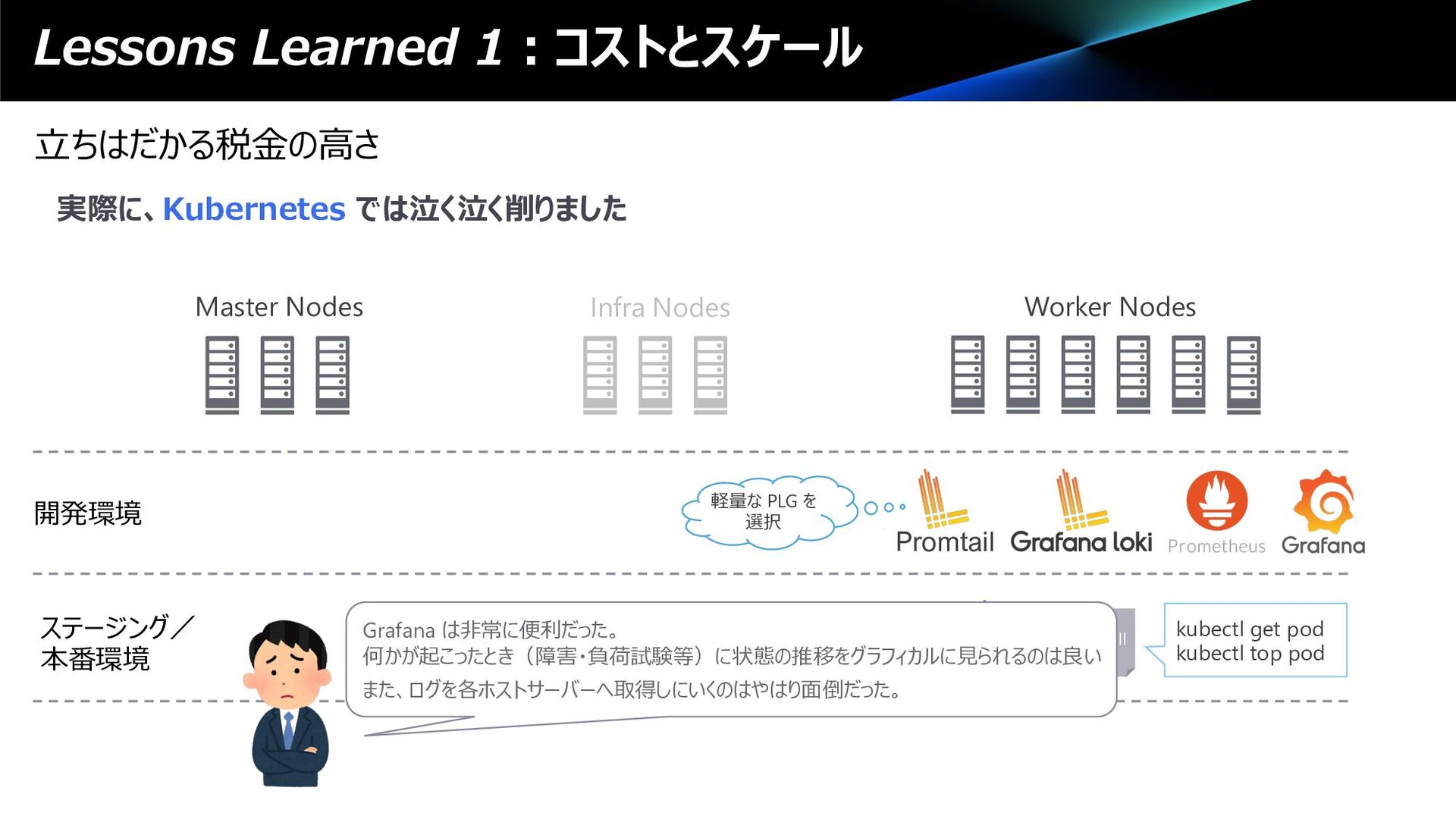
Worker Nodes Promtail 開発環境 ステージング/ 本番環境 Shell kubectl get pod kubectl top pod Local PV 軽量な PLG を 選択 Grafana は⾮常に便利だった。 何かが起こったとき(障害・負荷試験等)に状態の推移をグラフィカルに⾒られるのは良い また、ログを各ホストサーバーへ取得しにいくのはやはり⾯倒だった。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}