of an idea. Not in the idea. There is not much left just from an idea.” “Real artists ship” –Seth Godin, writer Why Open Source Projects? • Nice way to realize yourself while helping others
speed: storing and processing as much data as possible with your existing resources • Chunked data containers • How machine learning can help compressing better and faster
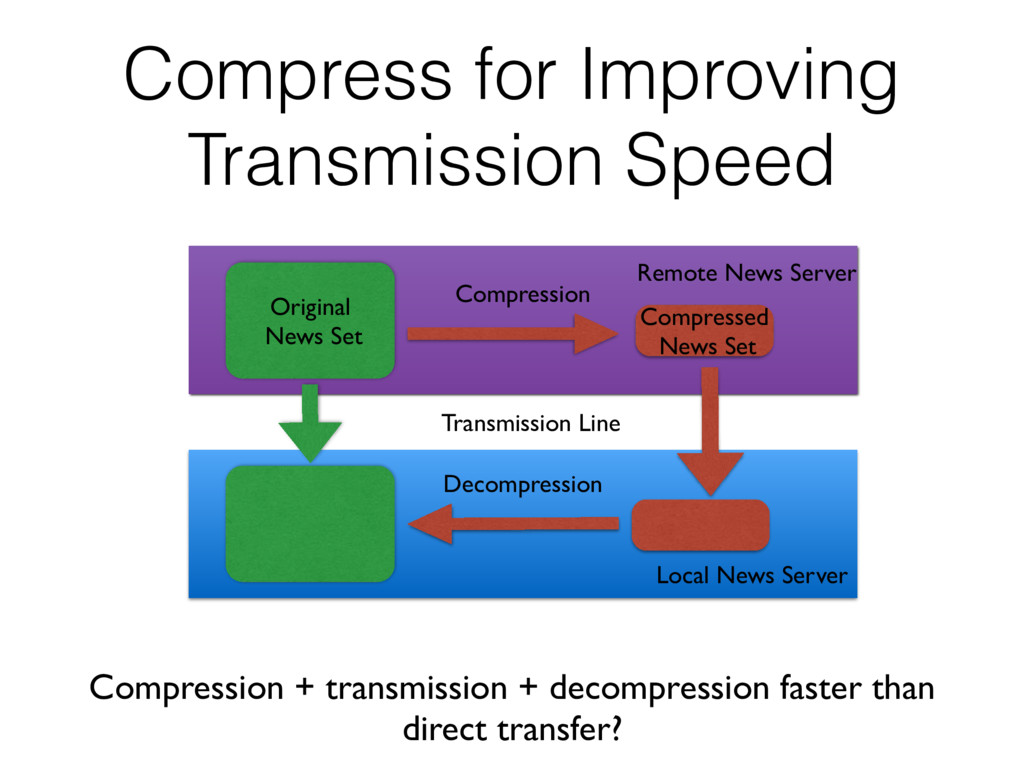
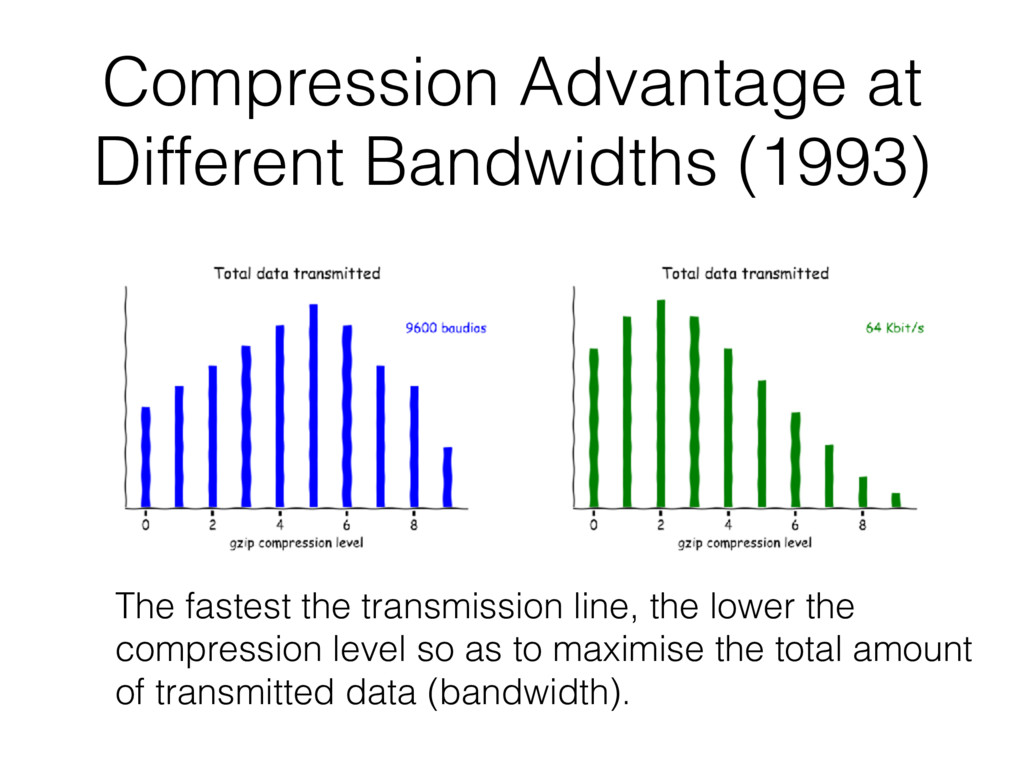
data stream at 9600 bauds and then upgraded to 64 Kbit/s (yeah, that was fast!). • HP 9000-730 with a speedy PA-7000 RISC microprocessor @ 66 MHz, running HP-UX.
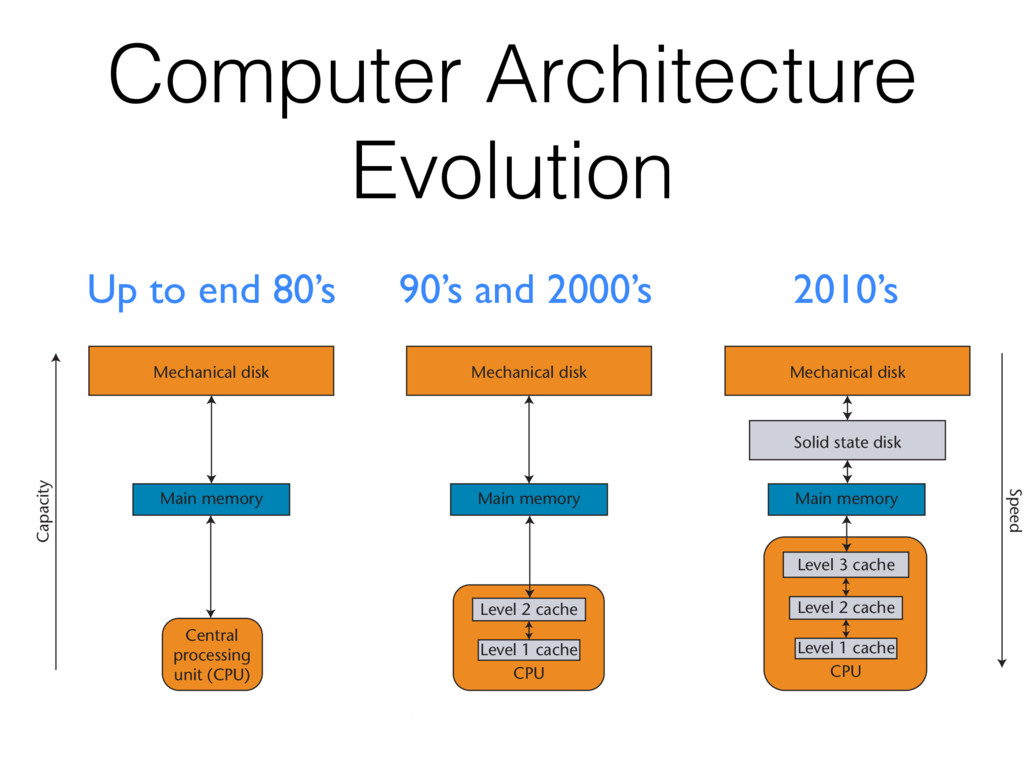
2010’s Figure 1. Evolution of the hierarchical memory model. (a) The primordial (and simplest) model; (b) the most common current Mechanical disk Mechanical disk Mechanical disk Speed Capacity Solid state disk Main memory Level 3 cache Level 2 cache Level 1 cache Level 2 cache Level 1 cache Main memory Main memory CPU CPU (a) (b) (c) Central processing unit (CPU)
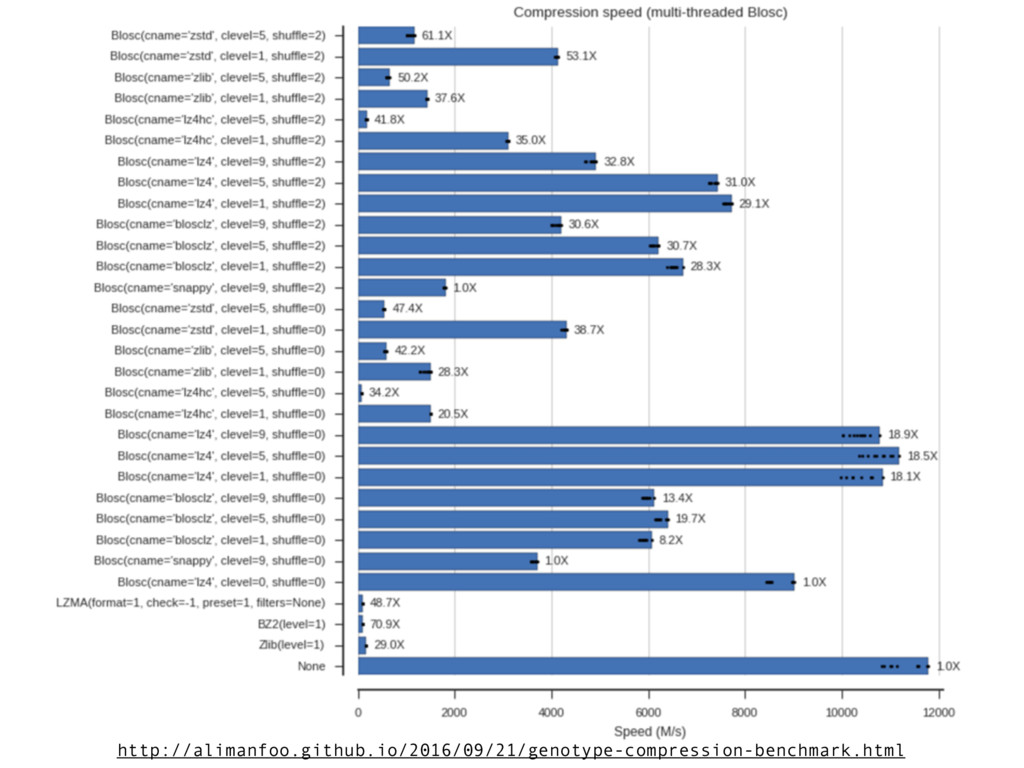
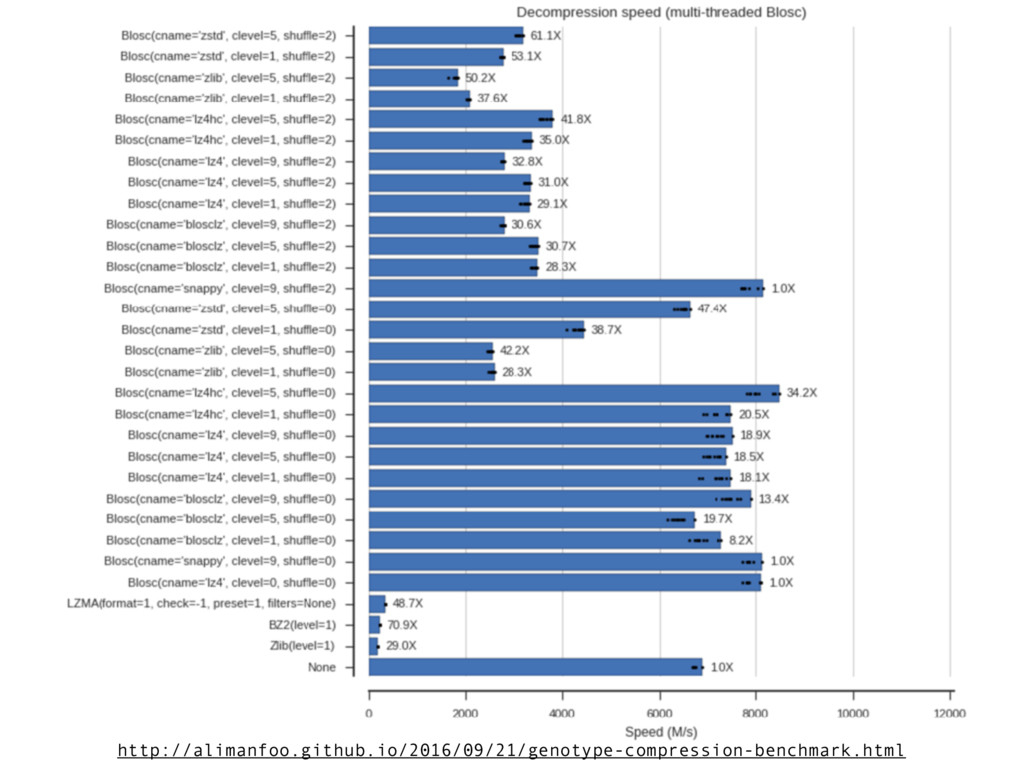
• Compression levels: from 0 to 9 • Codecs: “blosclz”, “lz4”, “lz4hc”, “snappy”, “zlib” and “zstd” • Different filters: “shuffle” and “bitshuffle” • Number of threads • Block sizes (the chunk is split in blocks internally) Nice opportunity for fine tuning for a specific setup!
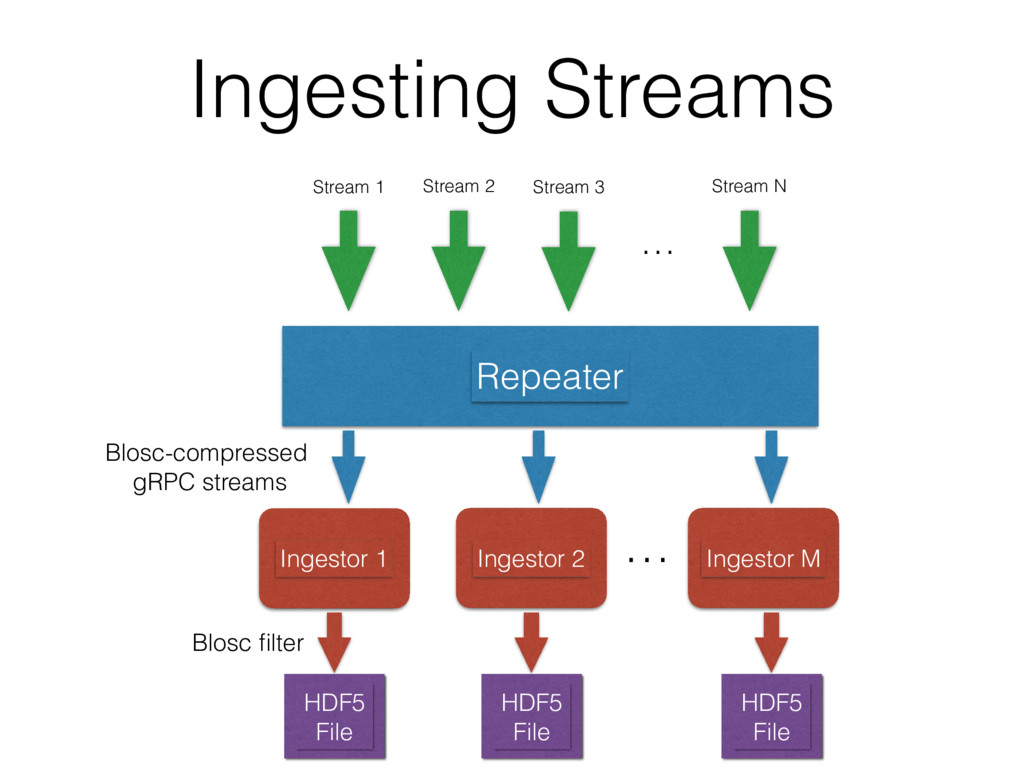
streams simultaneously • Speed for the aggregated streams can be up to 500K messages/sec • Each message can host between 10 and 100 different fields (string, float, int, bool)
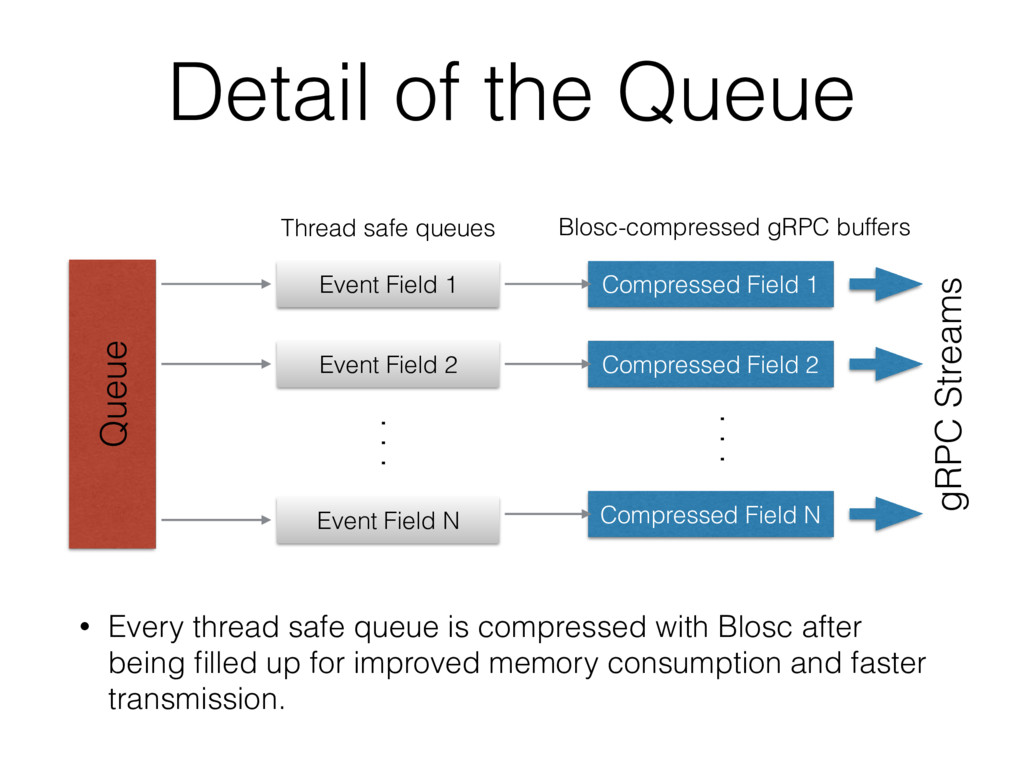
compressed with Blosc after being filled up for improved memory consumption and faster transmission. Event Field 1 Queue Event Field 2 Event Field N . . . Compressed Field 1 Compressed Field 2 Compressed Field N Thread safe queues gRPC Streams . . . Blosc-compressed gRPC buffers
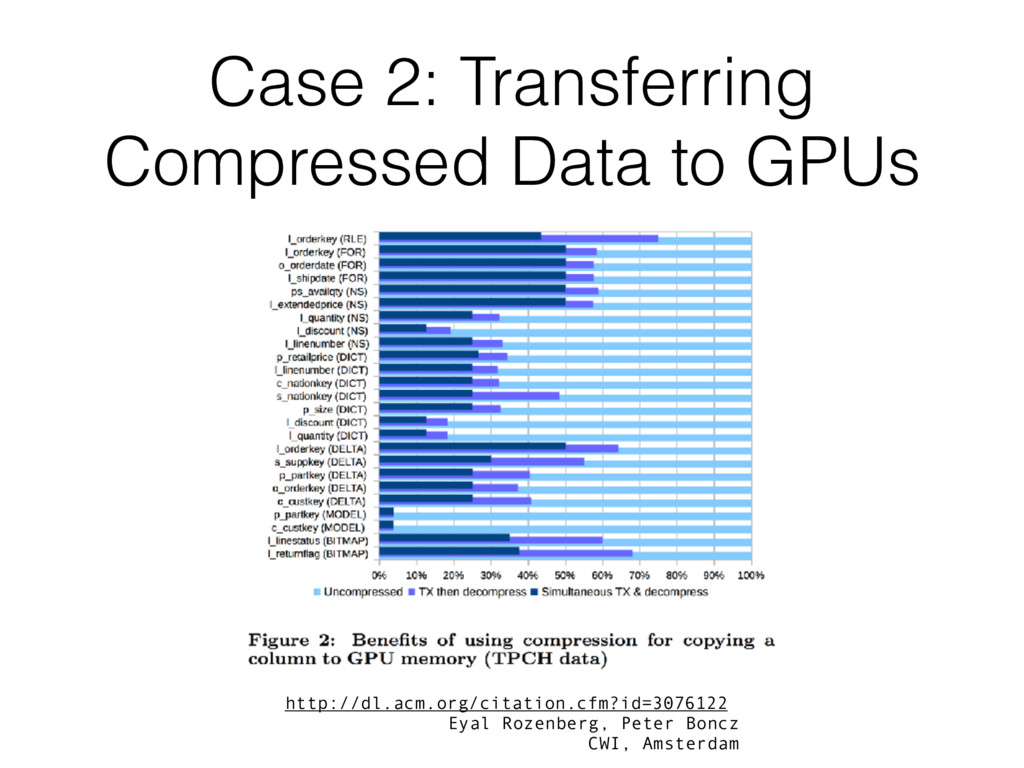
~5x in both transmission and storage. • It was used throughout all the project: • In gRPC buffers, for improved memory consumption in the Repeater queues and faster transmission • In HDF5, so as to greatly reduce the disk usage and ingestion time • The system was able to ingest more than 500K mess/sec (~650K mess/sec in our setup using a single machine with >16 physical cores). Not possible without compression!
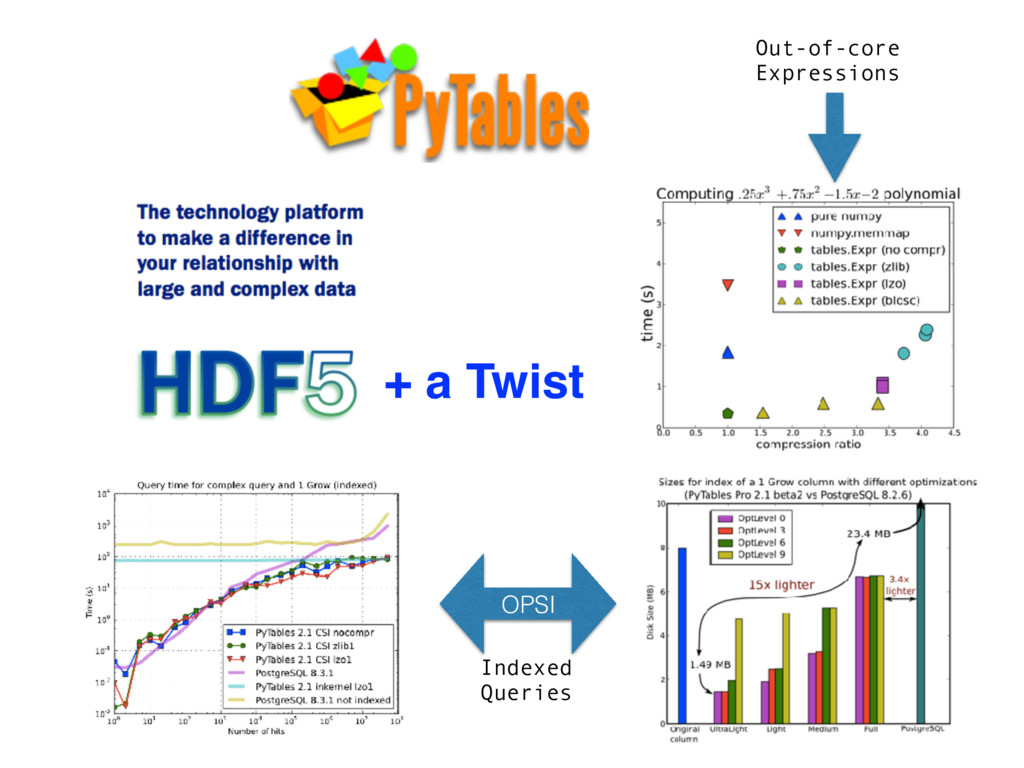
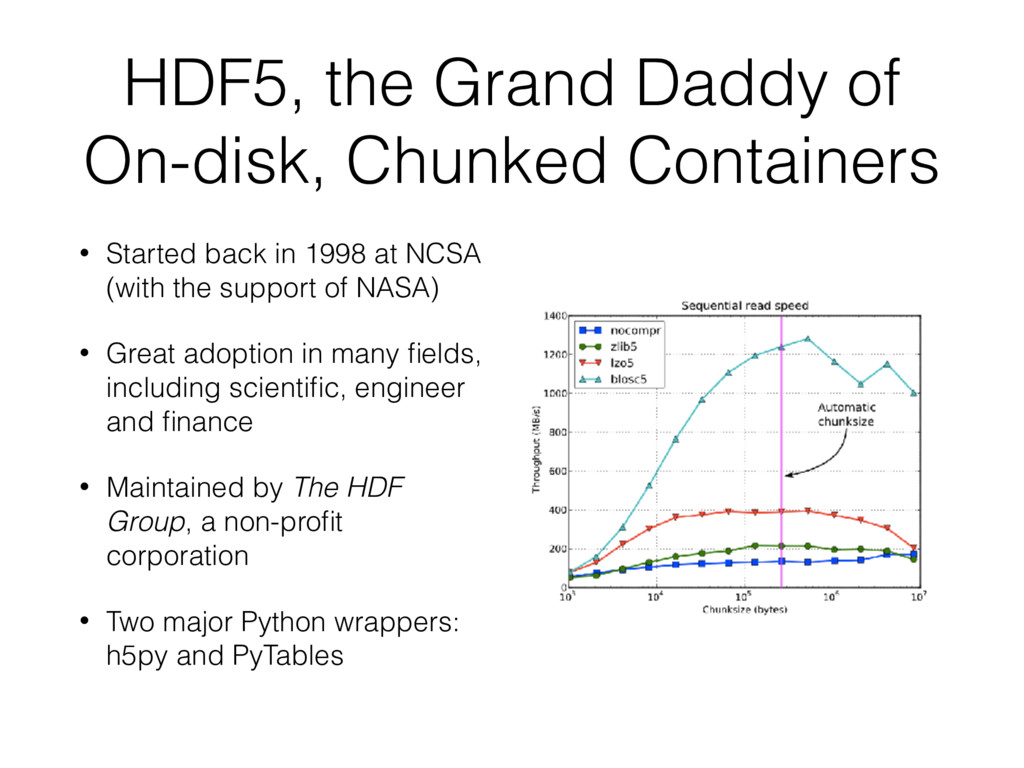
back in 1998 at NCSA (with the support of NASA) • Great adoption in many fields, including scientific, engineer and finance • Maintained by The HDF Group, a non-profit corporation • Two major Python wrappers: h5py and PyTables
the data arranged column-wise. Better performance for big tables, as well as for improving the compression ratio. • Efficient shrinks and appends: you can shrink or append more data at the end of the objects very efficiently.
any NumPy dtype. • Chunk arrays along any dimension. • Compress chunks using Blosc or alternatively zlib, BZ2 or LZMA. • Created by Alistair Miles from MRC Centre for Genomics and Global Health for handling genomic data in-memory.
0 to 9 • Codecs: “blosclz”, “lz4”, “lz4hc”, “snappy”, “zlib” and “zstd” • Different filters: “shuffle” and “bitshuffle” • Number of threads • Block sizes (the chunk is split in blocks internally) Question: how to choose the best candidates for maximum speed? Or for maximum compression? Or for a right balance?
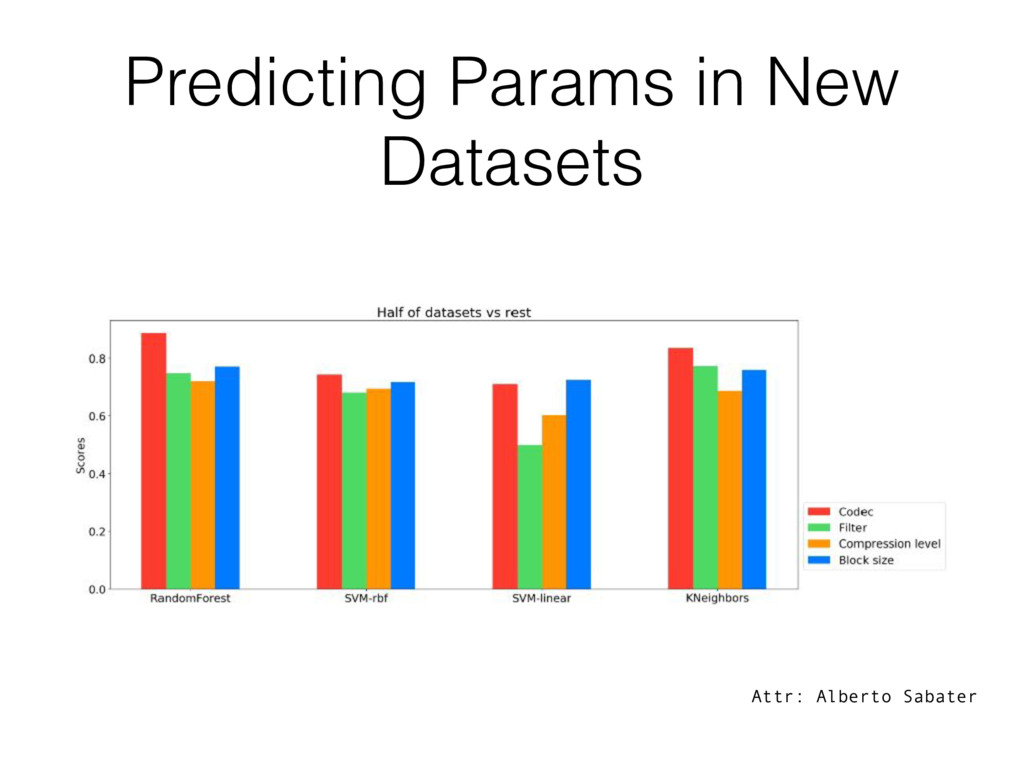
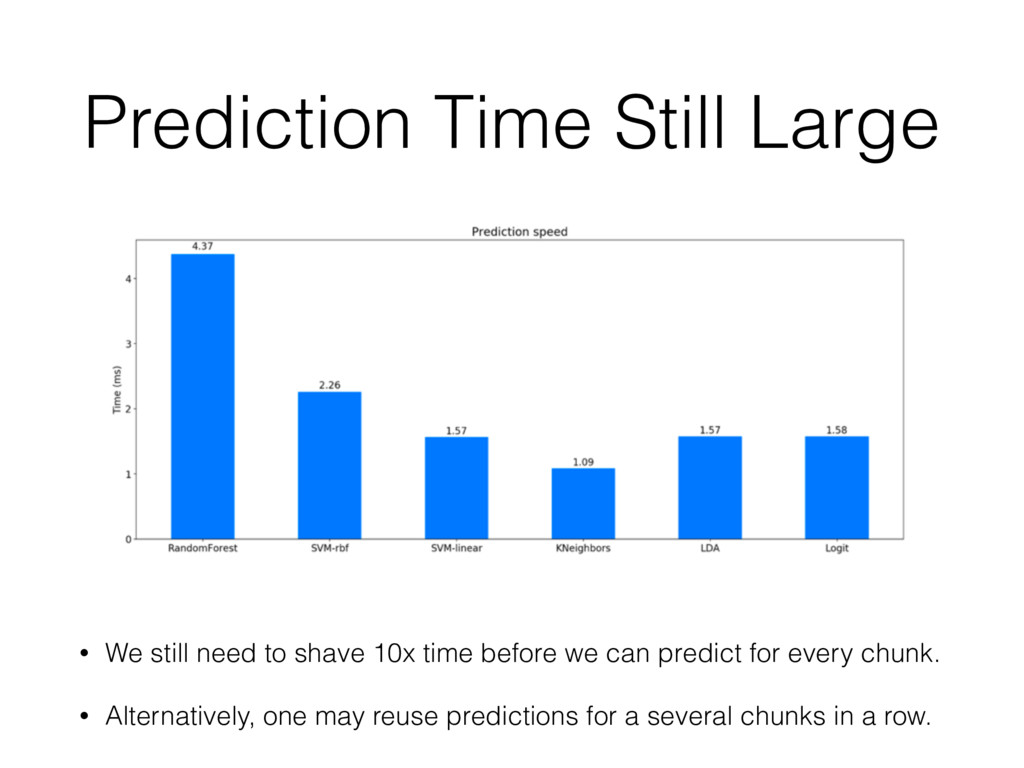
what she prefer: • Maximum compression ratio • Maximum compression speed • Maximum decompression speed • A balance between all the above • Based on that, and the characteristics of the data to be compressed, the training step gives hints on the optimal Blosc parameters to be used in new datasets.
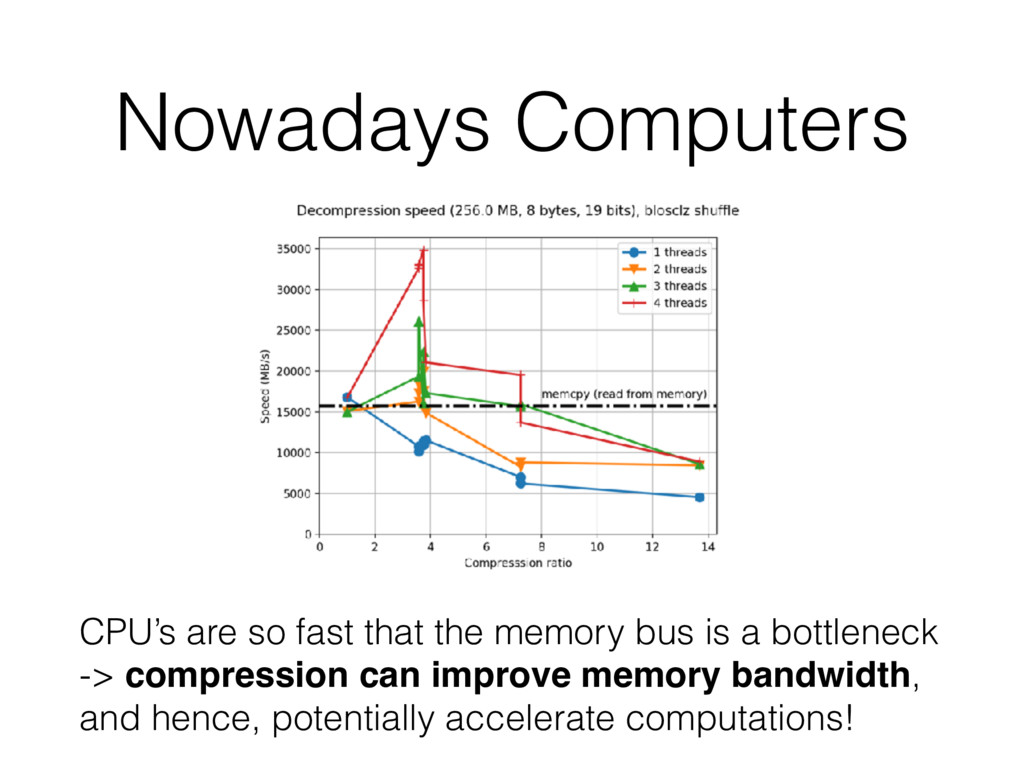
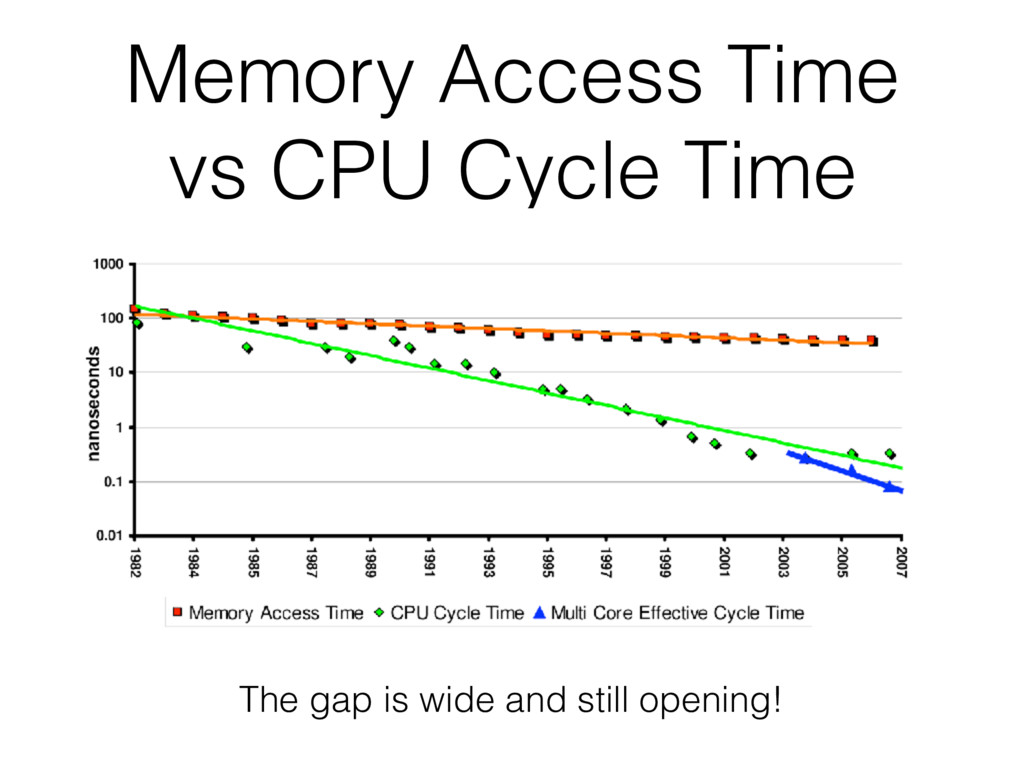
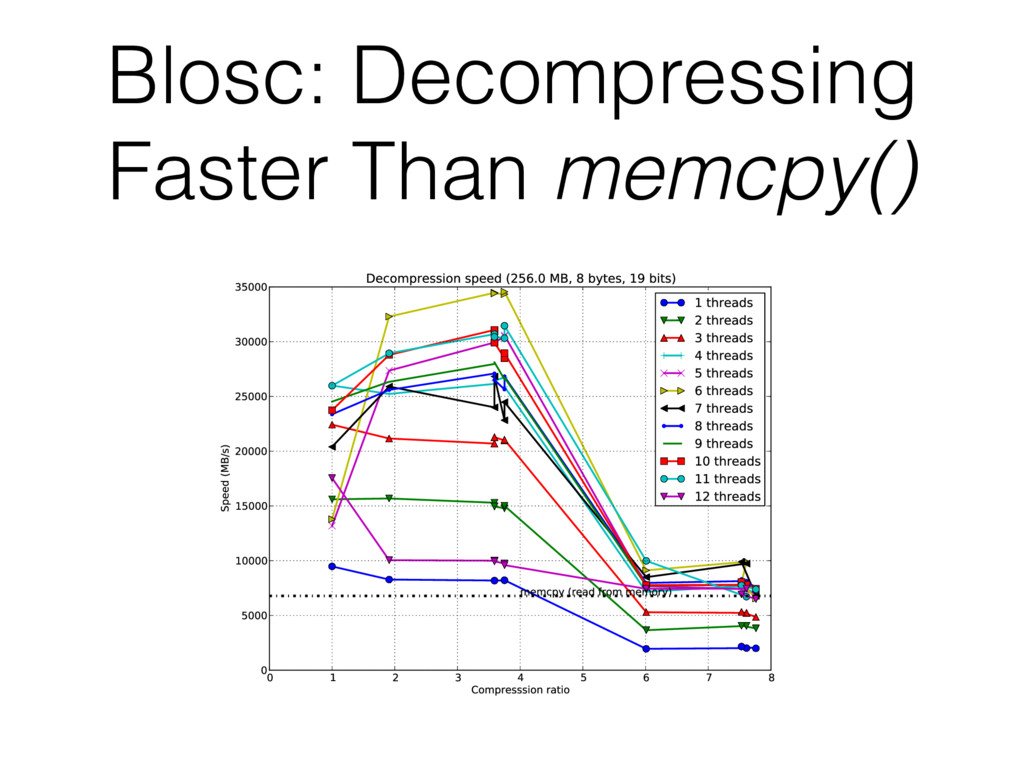
evolution in computer architecture, the compression can be effective for two reasons: • We can work with more data using the same resources. • We can reduce the overhead of compression to near zero, and even beyond that! We are definitely entering in an age where compression will be used much more ubiquitously.
• Not many data libraries focus on chunked data containers nowadays. • No silver bullet: we won’t be able to find a single container that makes everybody happy; it’s all about tradeoffs. • With chunked containers we can use persistent media (disk) as if it is ephemeral (memory) and the other way around -> independency of media!
to use different nodes in parallel: First give compression an opportunity to squeeze all the capabilities out of your single box. (You are always in time to parallelise later on ;)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}