Blosc/bcolz: Comprimiendo mas allá de los límites de la memoria
Blosc es un compresor extremadamente rápido, mientras que bcolz es un contenedor de datos columnares que soporta compresión. Juntos pueden cambiar las reglas del juego actuales en almacenamiento y procesamiento de datos.
Mantengo Numexpr desde hace años. • Desarrollador y enseñante en áreas como: • Python (casi 15 años de experiencia) • Computación y almacenamiento de altas prestaciones. • Consultor en proyectos de procesamiento de datos.
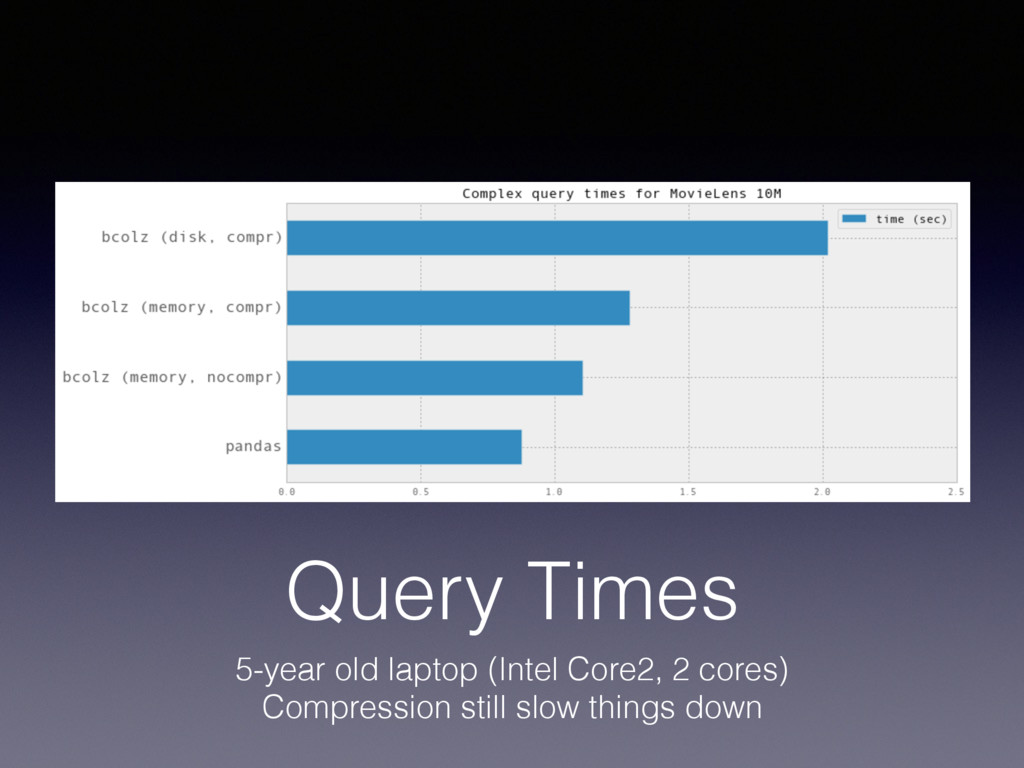
# Parse and load CSV files using pandas # Merge some files in a single dataframe lens = pd.merge(movies, ratings) # The pandas way of querying result = lens.query("(title == 'Tom and Huck (1995)') & (rating == 5)”)['user_id'] zlens = bcolz.ctable.fromdataframe(lens) # The bcolz way of querying (notice the use of the `where` iterator) result = [r.user_id for r in dblens.where( "(title == 'Tom and Huck (1995)') & (rating == 5)", outcols=['user_id'])]
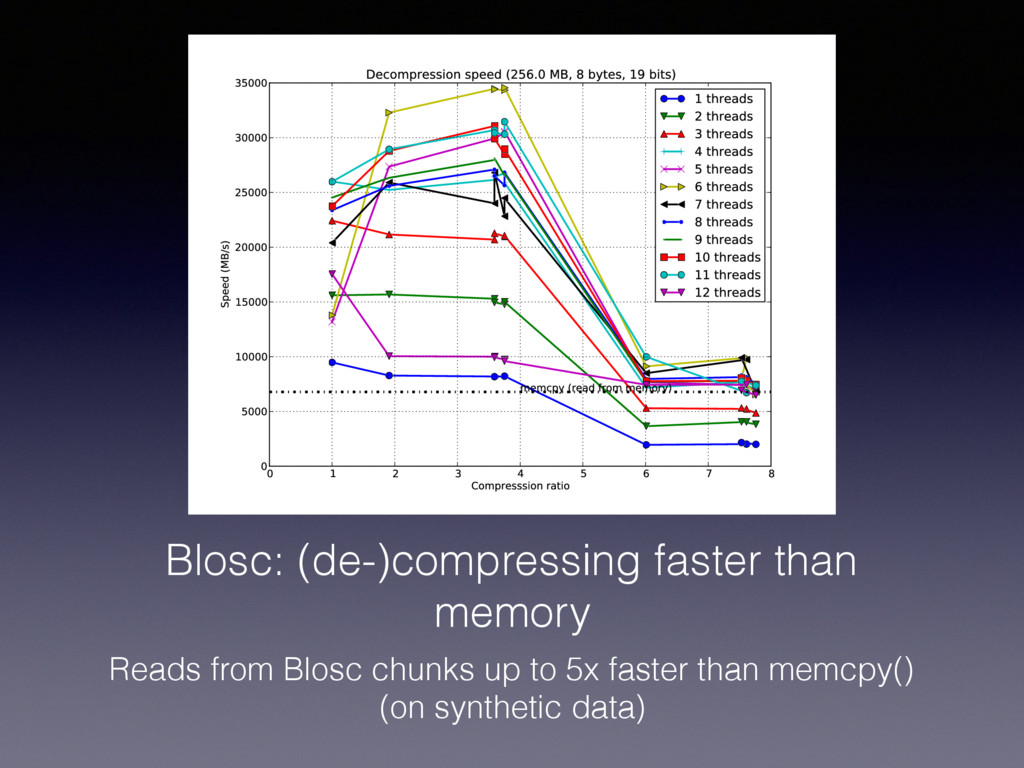
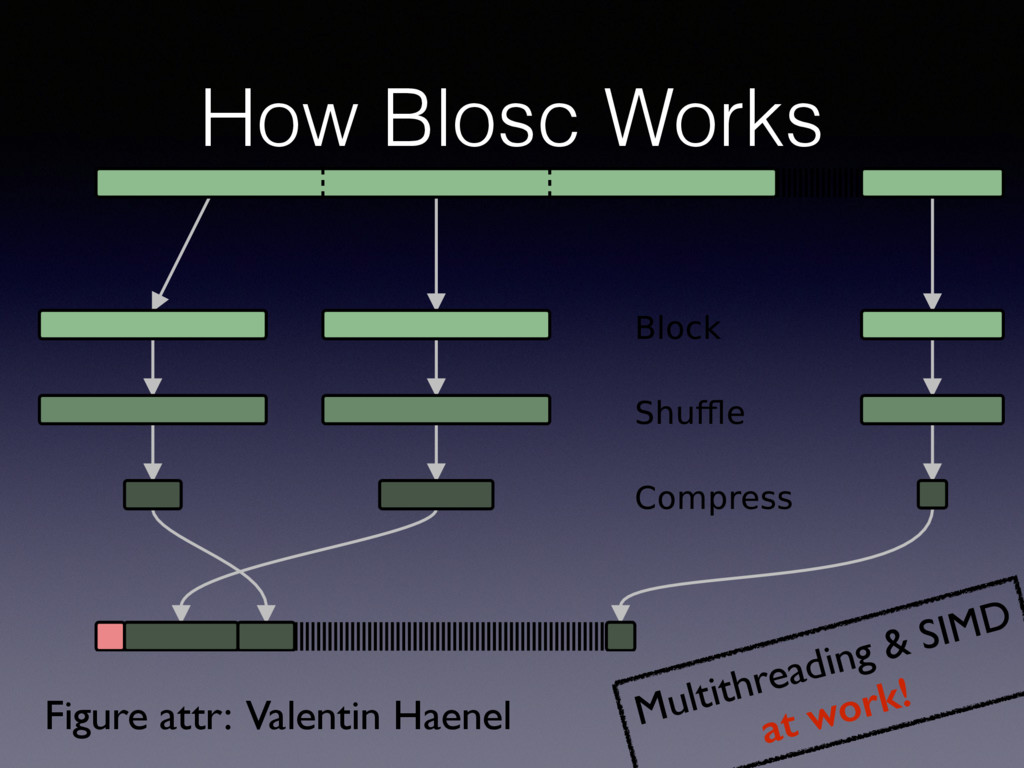
is accelerated using SSE2 and AVX2 (if available) • Supports different compressor backends: blosclz, lz4, snappy and zlib • Fine-tuned for using internal caches (mainly L1 and L2)
at this point; there is no better publicly available option that I'm aware of. That's not just ‘yet another compressor library’ case.” — Ivan Smirnov (advocating for Blosc inclusion in h5py)
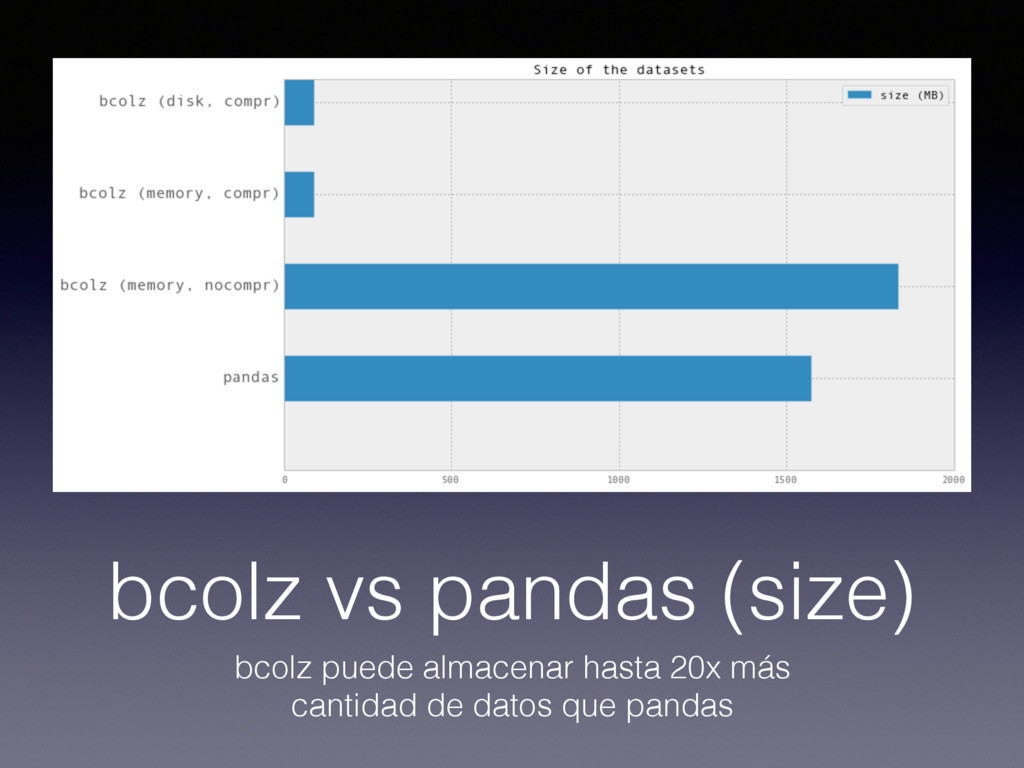
both chunked and is compressible • It is meant for both memory and persistent storage (disk) • Containers come with two flavors: carray (multidimensional, homogeneous arrays) and ctable (tabular data, made of carrays)
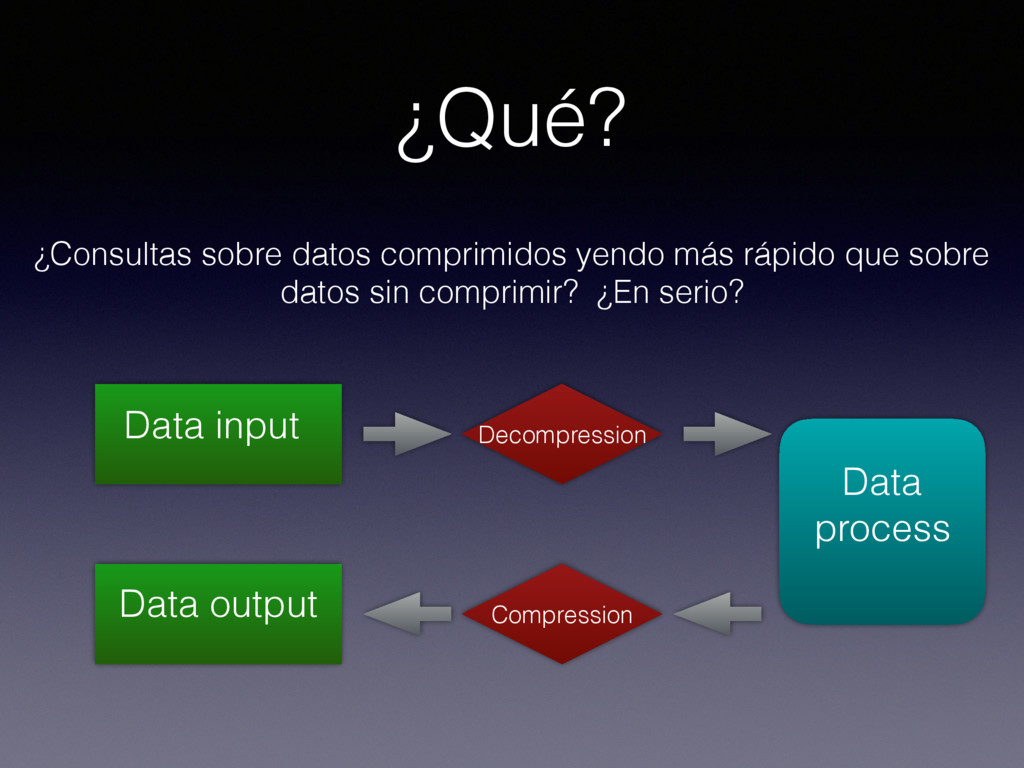
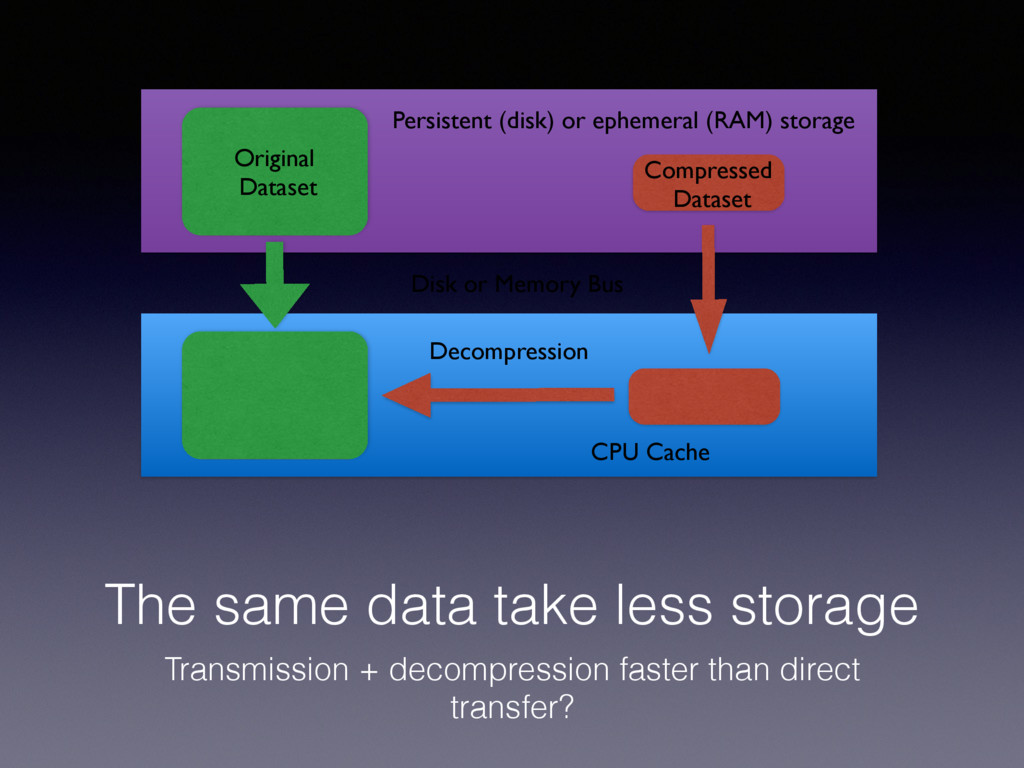
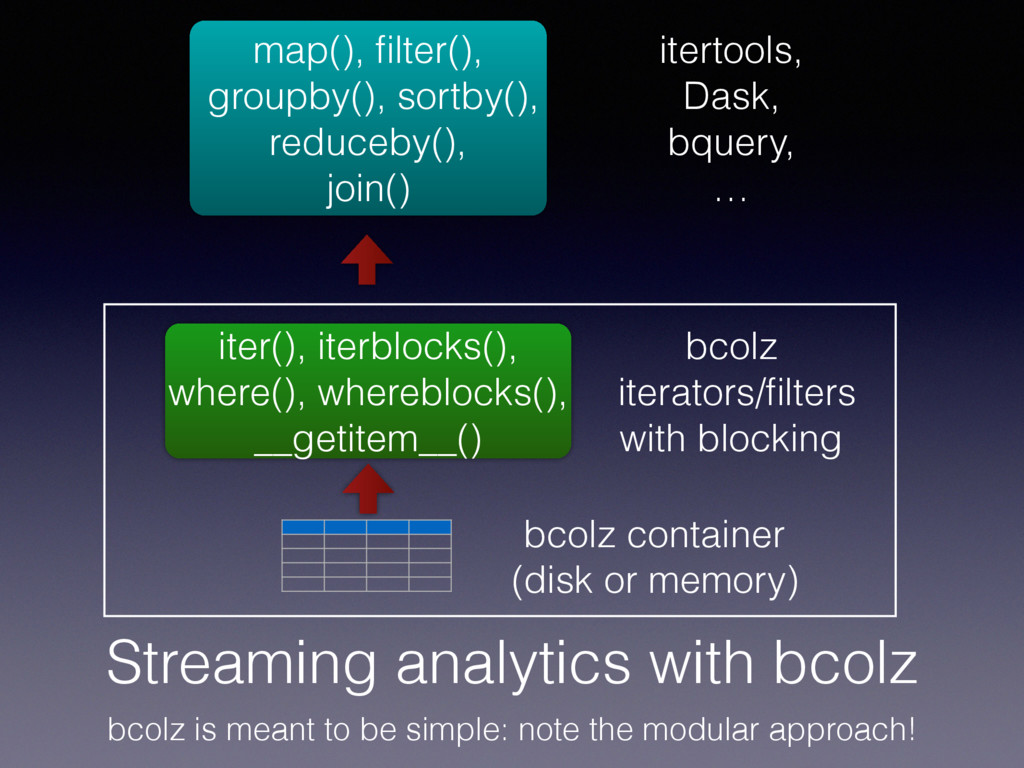
not only in memory • bcolz allows every operation to be executed either in-memory or on-disk (out-of-core operations) • The recipe is to provide high performance iterators for carray and ctable, and then implement operations with these iterators
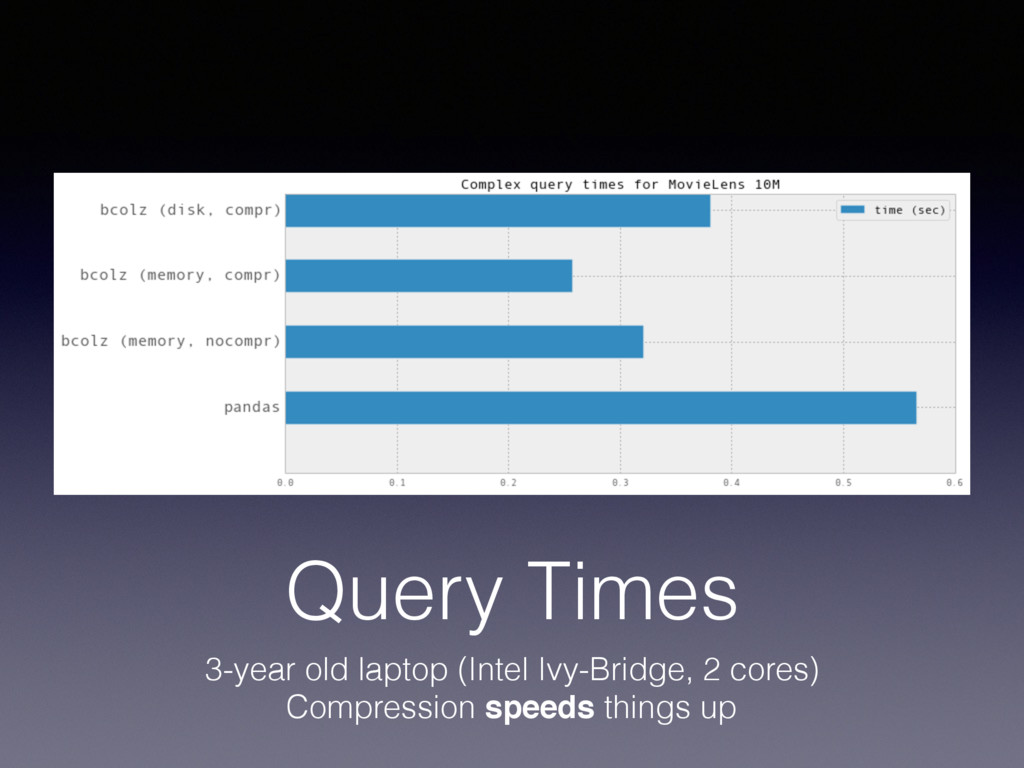
of bcolz (including Blosc) are designed with the memory hierarchy in mind to get the best performance • Basically, bcolz uses the blocking technique extensively so as to leverage the temporal and spatial localities all along the hierarchy
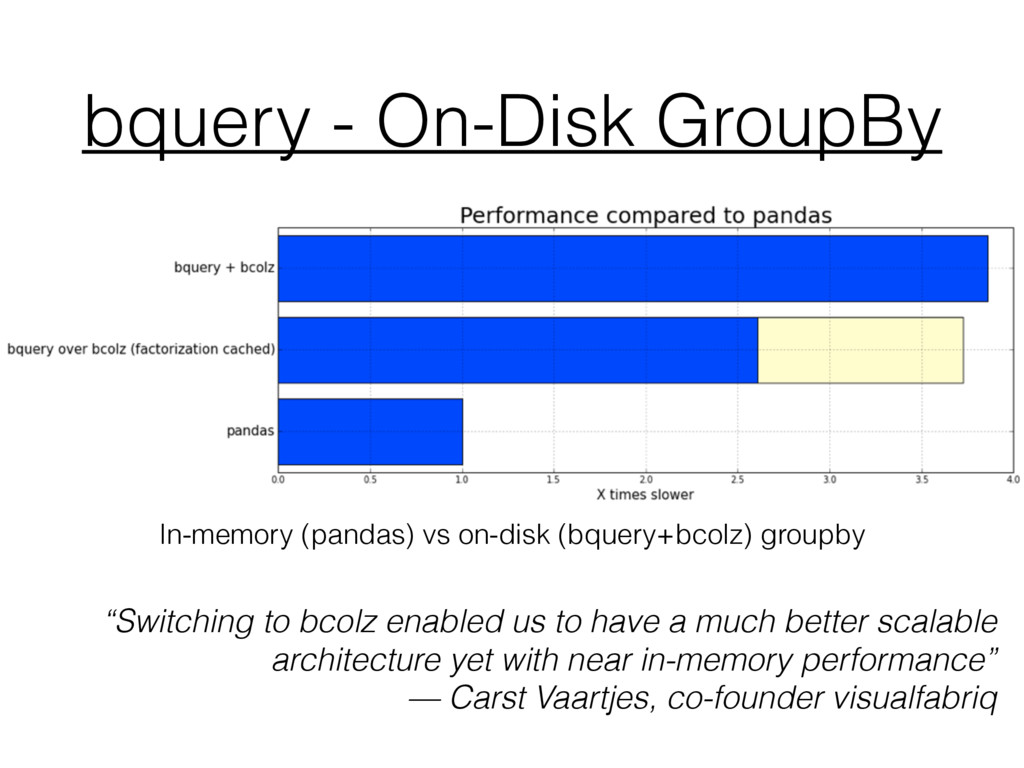
“Switching to bcolz enabled us to have a much better scalable architecture yet with near in-memory performance” — Carst Vaartjes, co-founder visualfabriq
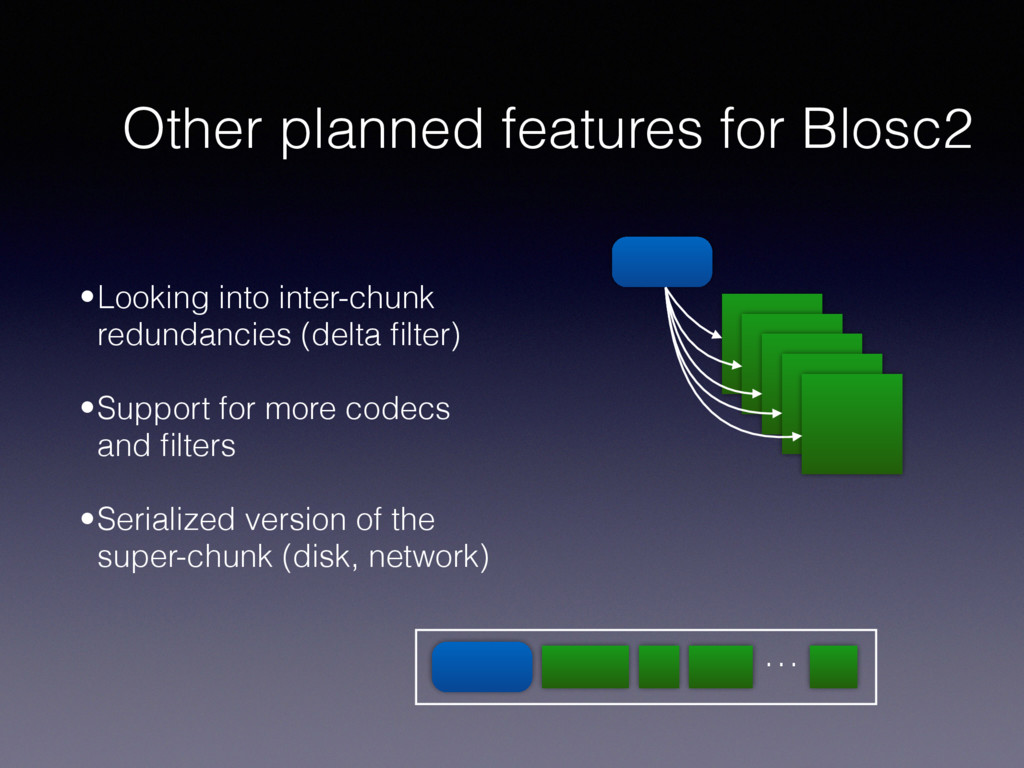
• This can lead to a poor use of space to accommodate variable-length data (potentially large zero-paddings) • Blosc2 addresses this shortcoming by using superchunks of variable-length chunks
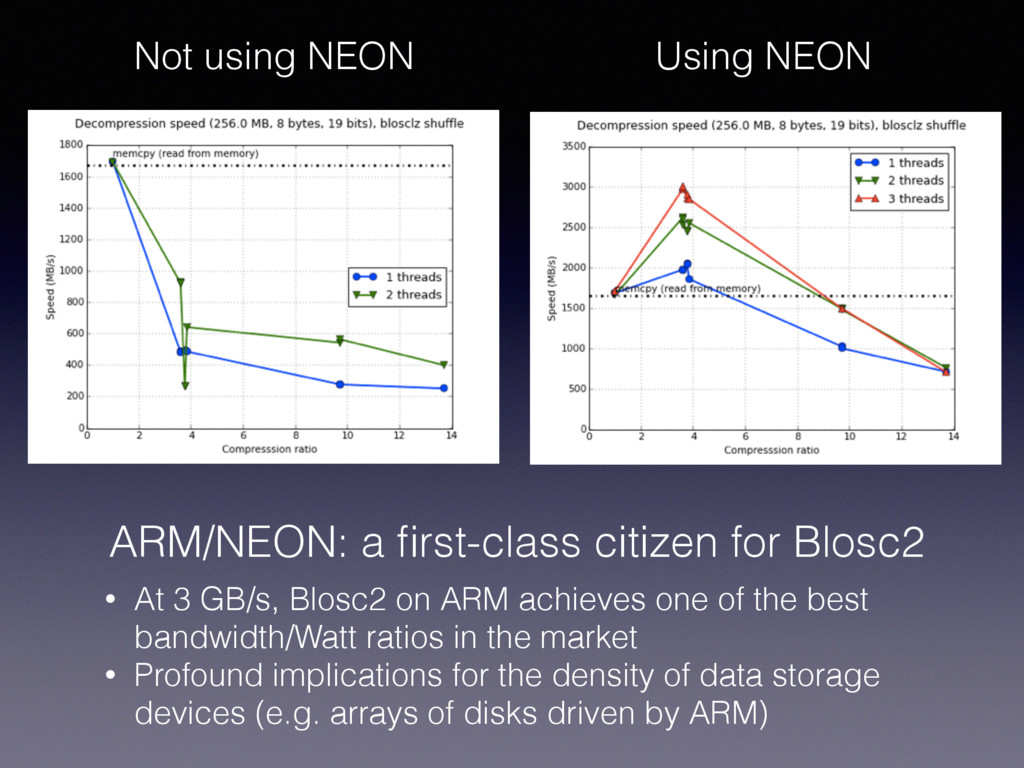
Blosc2 on ARM achieves one of the best bandwidth/Watt ratios in the market • Profound implications for the density of data storage devices (e.g. arrays of disks driven by ARM) Not using NEON Using NEON
la compresión puede ser efectiva por dos razones: • Se puede trabajar con más datos usando los mismos recursos • Se puede llegar a reducir el coste de la compresión a cero, e incluso más allá!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![¿Preguntas? [email protected]](https://files.speakerdeck.com/presentations/6a780f1529e248fcb61f2dcc533d2a85/slide_35.jpg){kind=link}