It’s easy to find generic performance and tuning tips for MySQL, valid for many versions. However, if you are using MySQL 8, you would probably like to know and use the latest features that will optimize your environments.
Join this webinar to discover the MySQL 8 specific features that will help you improve your performance and tuning specific to MySQL 8 (Histograms, Resource Groups, Options for Document Store/JSON, and many others). We will also add some suggestions on how to improve specific workloads (e.g. write intensive, read intensive, asynchronous replicas, InnoDB Cluster).
Take this opportunity to learn directly from MySQL experts and have your questions answered by them!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
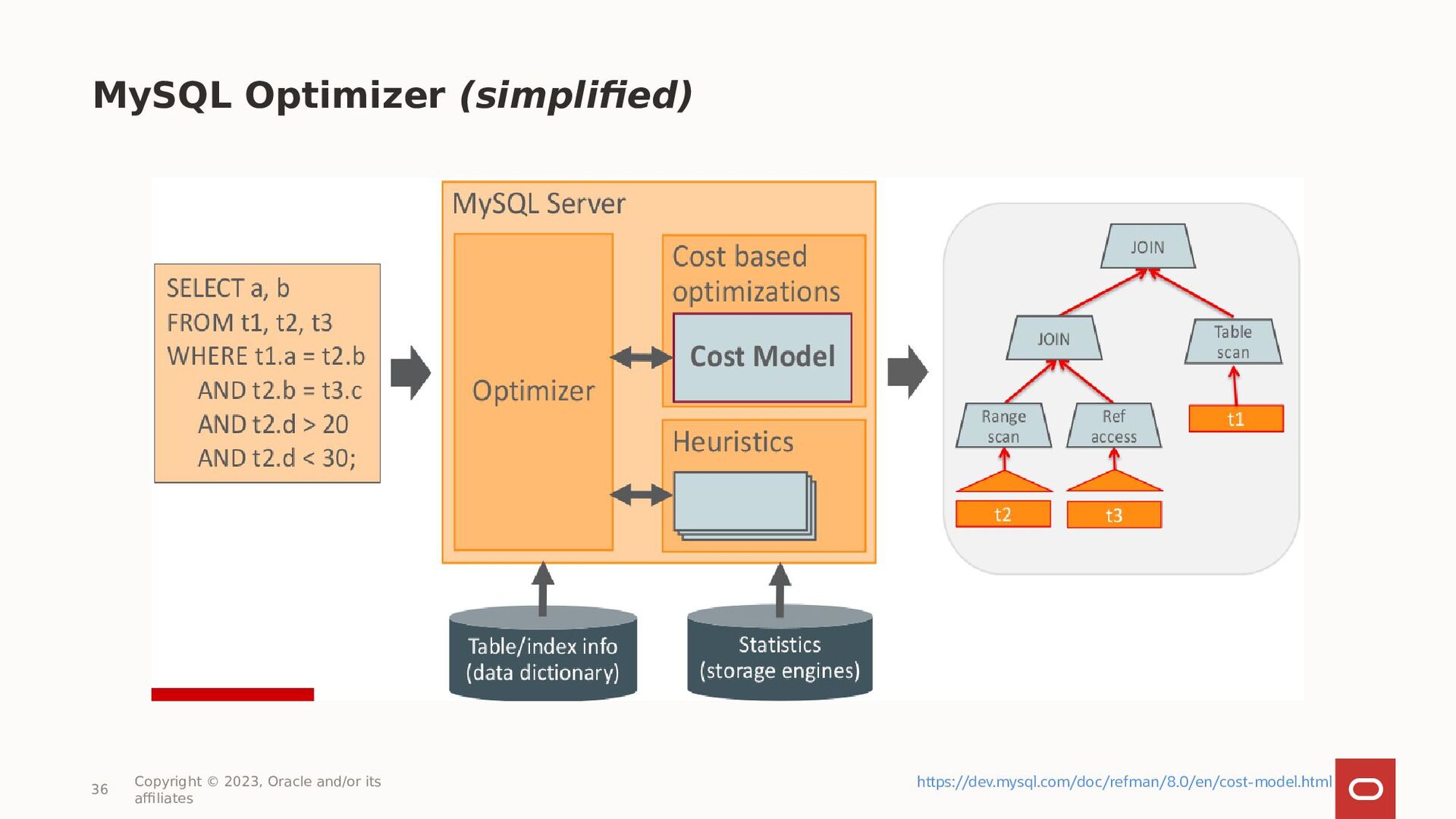{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
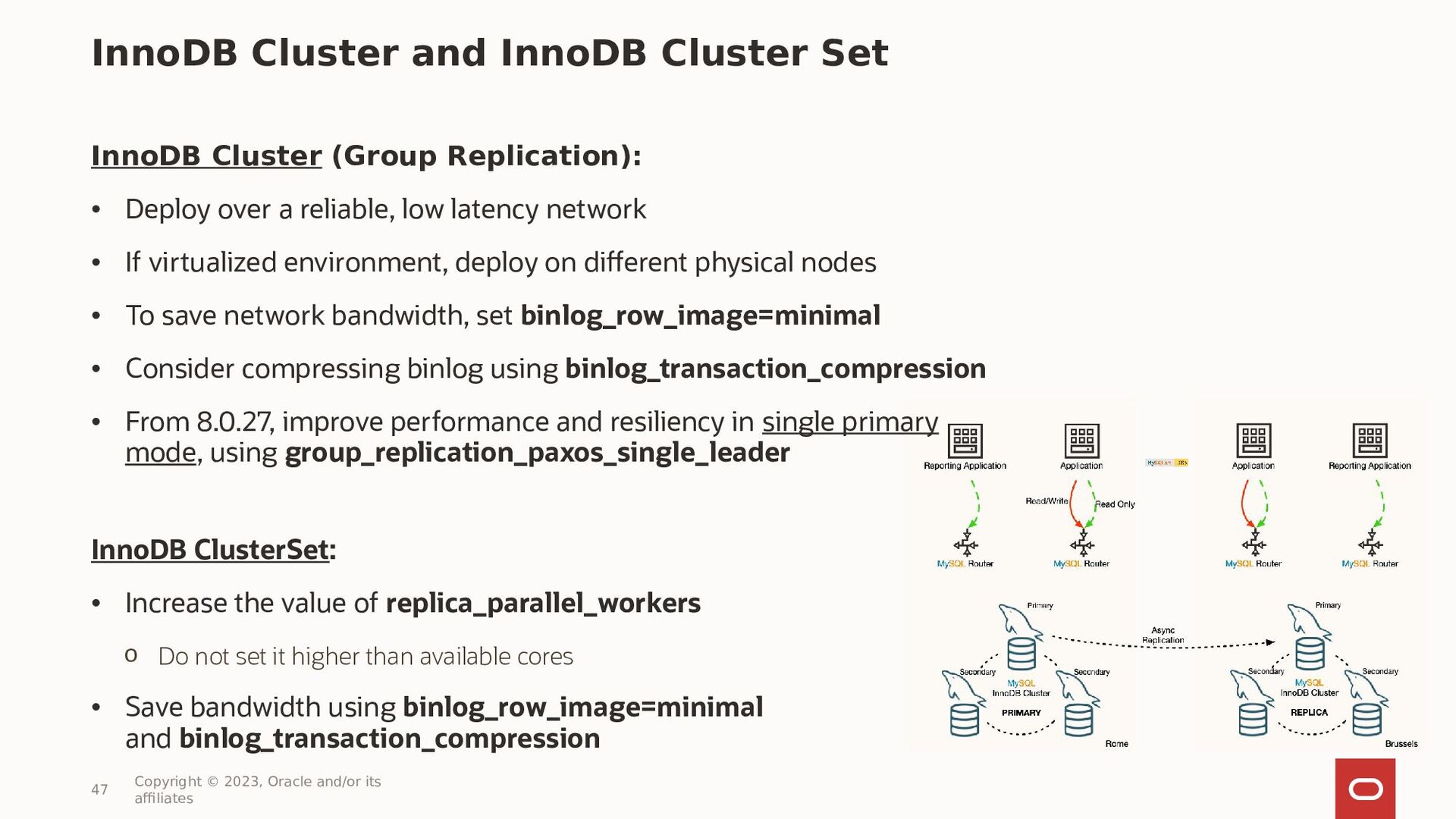{kind=link}
{kind=link}
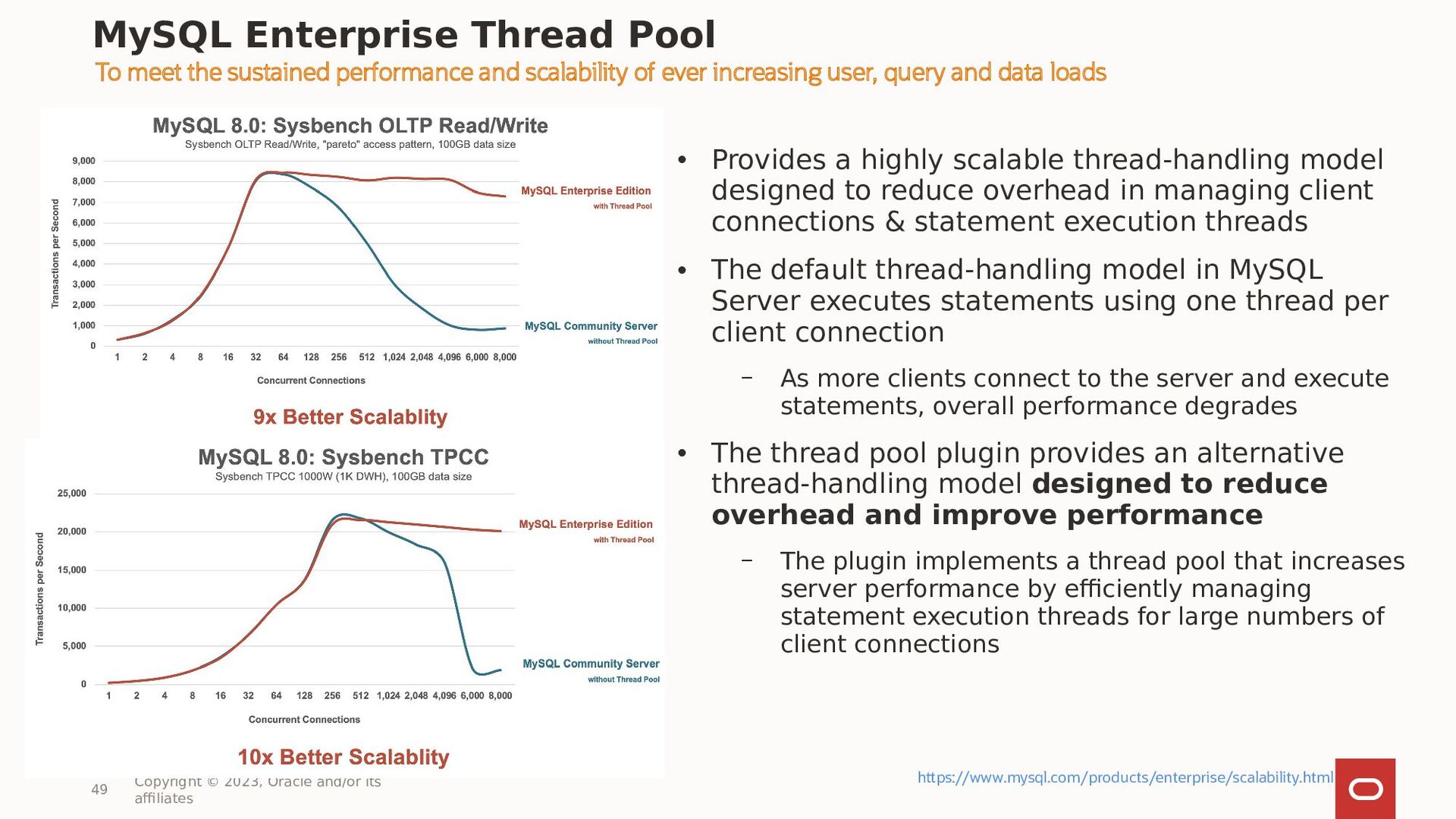{kind=link}
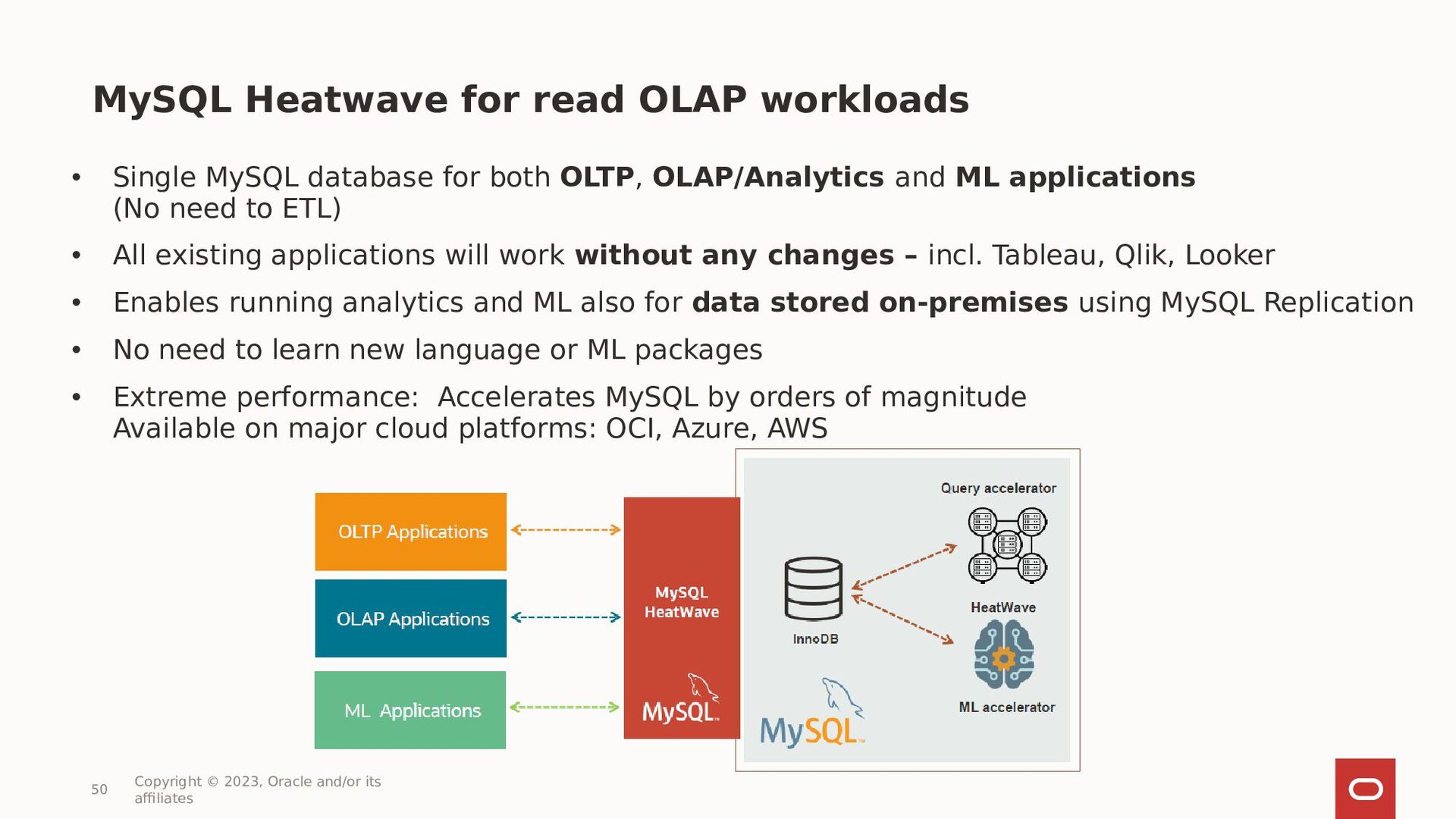{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}