= User::insert(&pool, &UserInput{ first_name: "Taro".to_string(), last_name: "Yamada".to_string(), email: "
[email protected]".to_string(), } ).await?; let user_id2 = User::insert(&pool, &UserInput{ first_name: "Jane".to_string(), last_name: "Conley".to_string(), email: "
[email protected]".to_string(), } ).await?; let user_id3 = User::insert(&pool, &UserInput{ first_name: "Jack".to_string(), last_name: "Johnson".to_string(), email: "
[email protected]".to_string(), } ).await?; let user_id3 = User::insert(&pool, &UserInput{ first_name: "Foo".to_string(), last_name: "Bar".to_string(), email: "
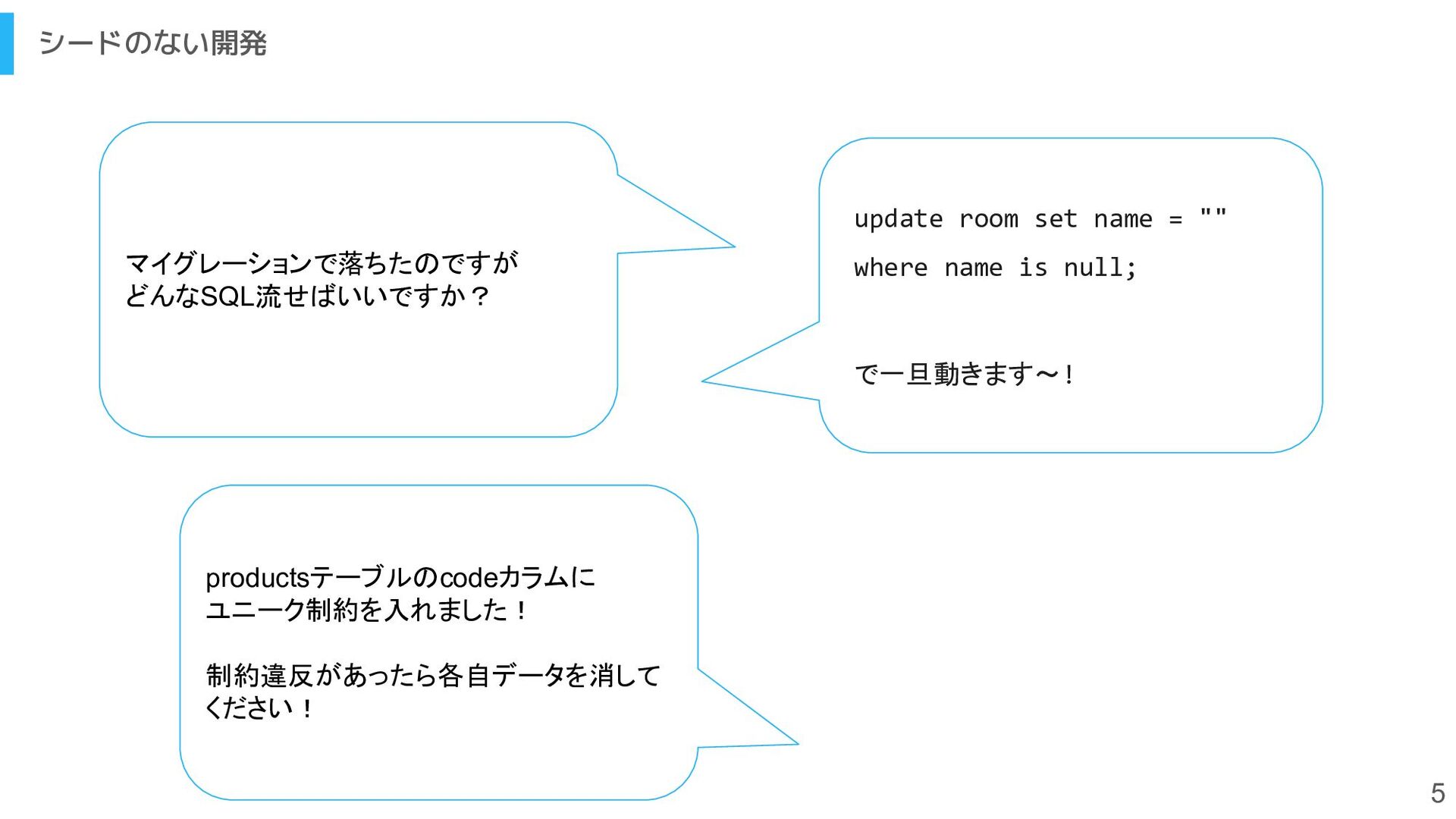
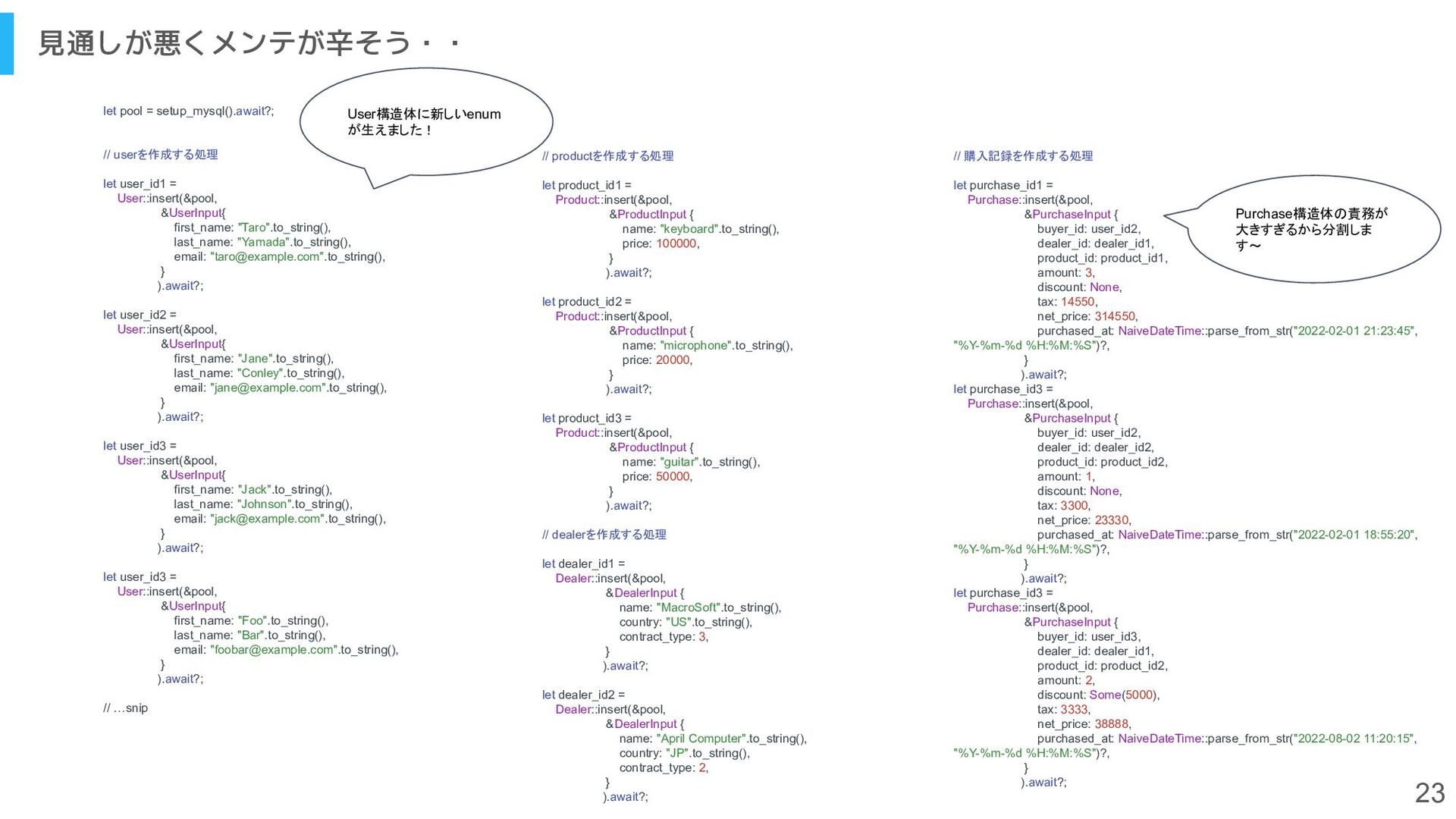
[email protected]".to_string(), } ).await?; // …snip // productを作成する処理 let product_id1 = Product::insert(&pool, &ProductInput { name: "keyboard".to_string(), price: 100000, } ).await?; let product_id2 = Product::insert(&pool, &ProductInput { name: "microphone".to_string(), price: 20000, } ).await?; let product_id3 = Product::insert(&pool, &ProductInput { name: "guitar".to_string(), price: 50000, } ).await?; // dealerを作成する処理 let dealer_id1 = Dealer::insert(&pool, &DealerInput { name: "MacroSoft".to_string(), country: "US".to_string(), contract_type: 3, } ).await?; let dealer_id2 = Dealer::insert(&pool, &DealerInput { name: "April Computer".to_string(), country: "JP".to_string(), contract_type: 2, } ).await?; // 購入記録を作成する処理 let purchase_id1 = Purchase::insert(&pool, &PurchaseInput { buyer_id: user_id2, dealer_id: dealer_id1, product_id: product_id1, amount: 3, discount: None, tax: 14550, net_price: 314550, purchased_at: NaiveDateTime::parse_from_str("2022-02-01 21:23:45", "%Y-%m-%d %H:%M:%S")?, } ).await?; let purchase_id3 = Purchase::insert(&pool, &PurchaseInput { buyer_id: user_id2, dealer_id: dealer_id2, product_id: product_id2, amount: 1, discount: None, tax: 3300, net_price: 23330, purchased_at: NaiveDateTime::parse_from_str("2022-02-01 18:55:20", "%Y-%m-%d %H:%M:%S")?, } ).await?; let purchase_id3 = Purchase::insert(&pool, &PurchaseInput { buyer_id: user_id3, dealer_id: dealer_id1, product_id: product_id2, amount: 2, discount: Some(5000), tax: 3333, net_price: 38888, purchased_at: NaiveDateTime::parse_from_str("2022-08-02 11:20:15", "%Y-%m-%d %H:%M:%S")?, } ).await?; User構造体に新しいenum が生えました! Purchase構造体の責務が 大きすぎるから分割しま す〜
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
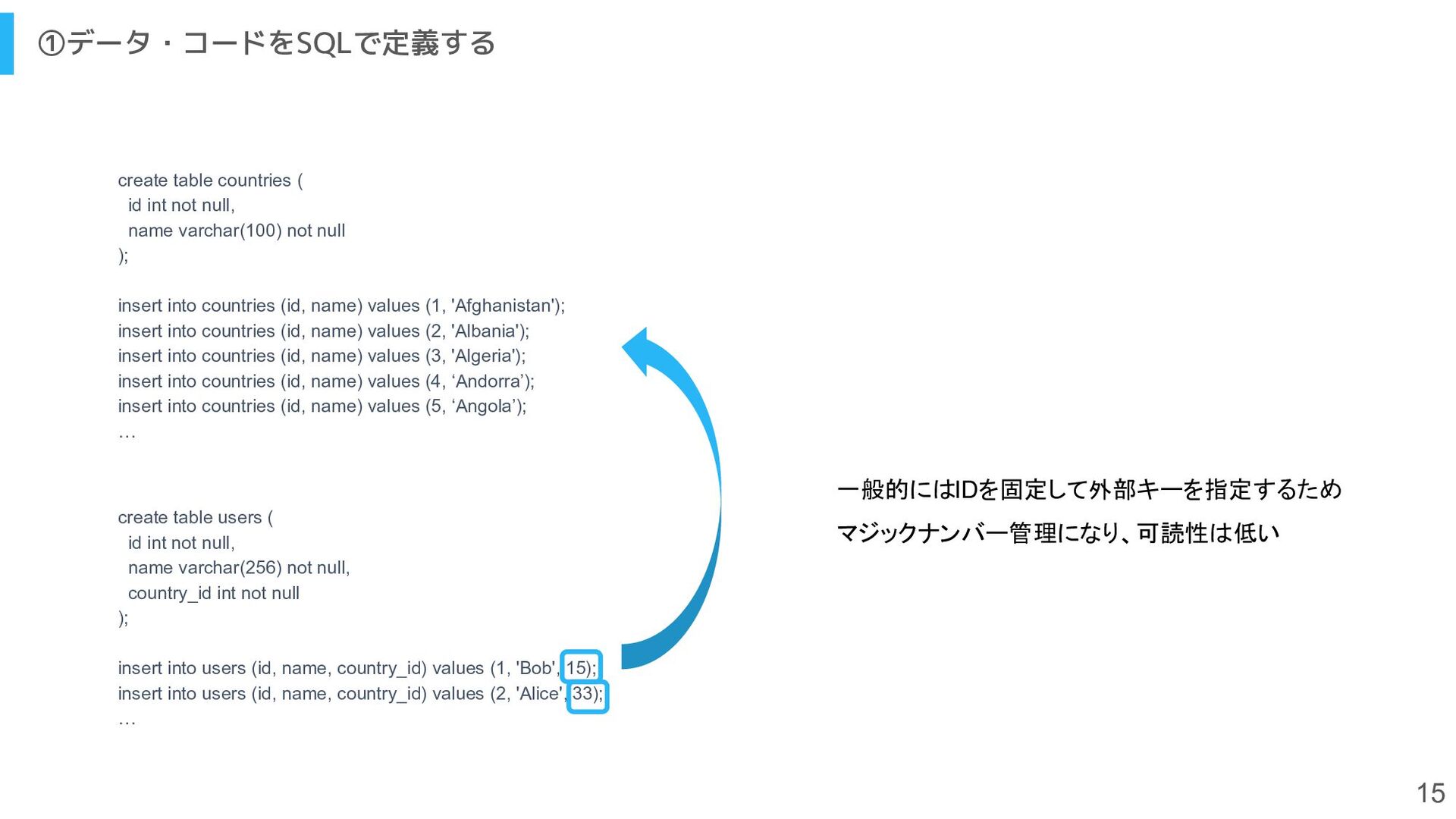{kind=link}
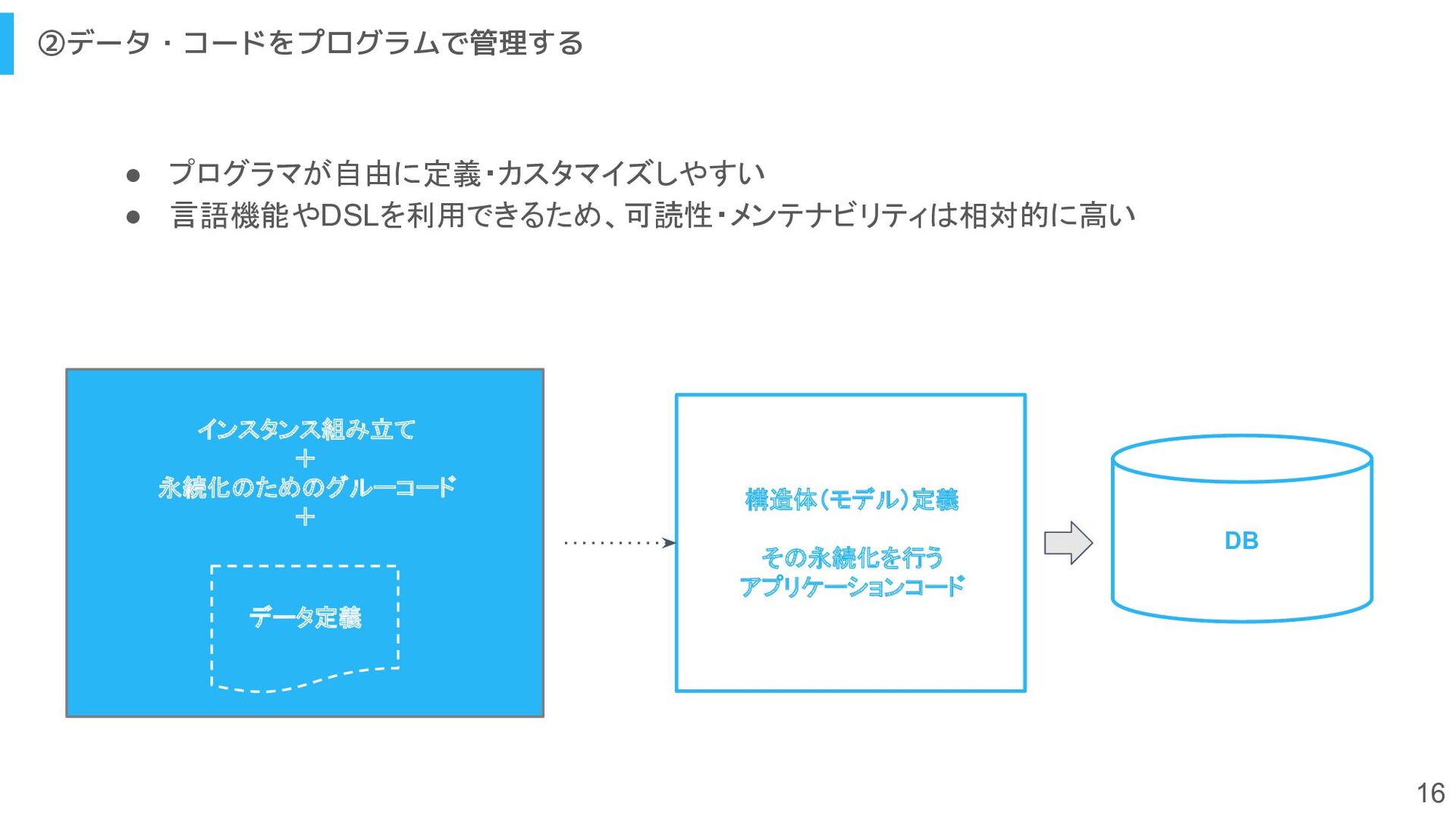{kind=link}
{kind=link}
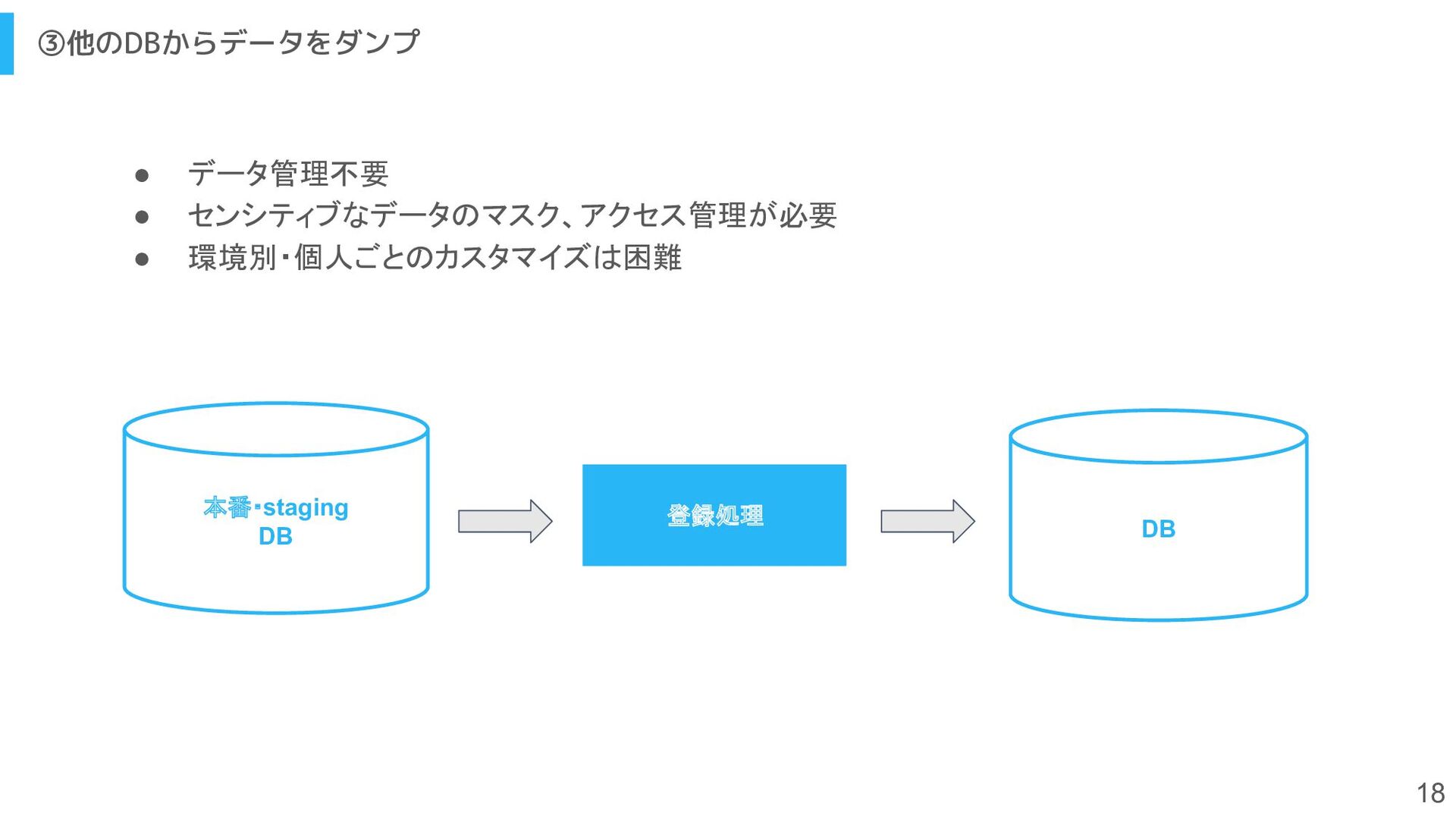{kind=link}
{kind=link}
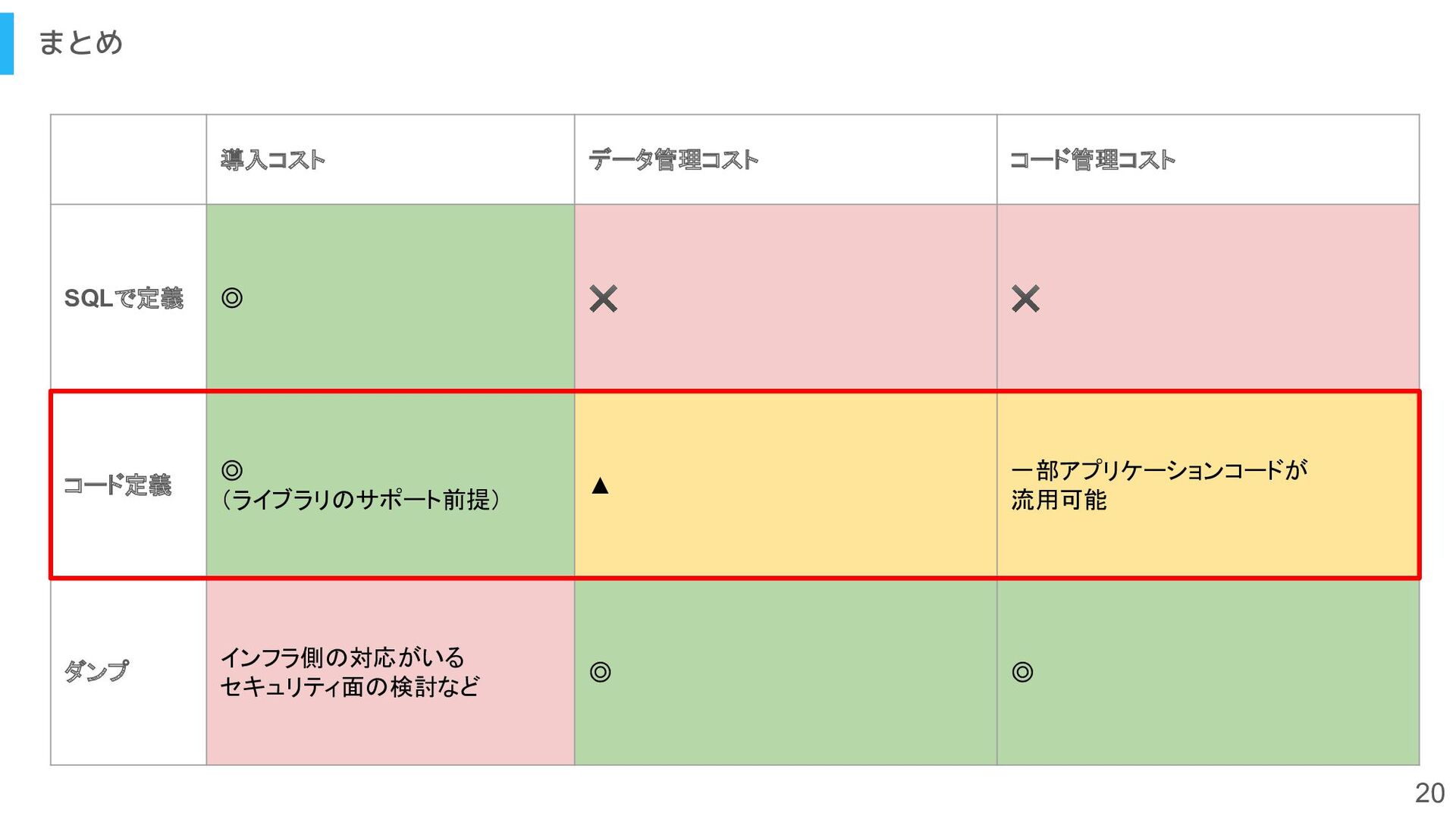{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}