в MySQL/Postgres/Mongo/MyMegaDatabase чота встроенное типа есть и агонь • Взять Sphinx, C++ не подведёт • Взять Lucene/Solr/Elastic, Java не подведёт • Самим всё написать, мы ж мужики • Купить крутейший коммерческий, например
varchar(255) not null, docid integer primary key not null ); insert into X values (“hello”, 123), (“world”,123); select * from X a, X b where a.keyword=“hello” and b.keyword=“world” and a.docid=b.docid
• На самом деле, Неизбежно Будет Говнецо * • Все базы в первую очередь про OLAP, ох • Великие Древние ещё также умеют транзакции, ууух • Типично муторно масштабировать • Синтаксис, ранжирование, эффективность? Не, не слышали (*) Разумеется, именно Ваш Любимый Вендор не такой!
надо • Core product (Google, Yandex, Bing…) • Спецтребования (“хочу взлетать в 16 KB памяти…”) • Ключевое, осознавать масштаб бедствия • У нас вот получается довольно компактно • Sphinx 0.1 = ~1K LOC, Sphinx 2.x = ~120K LOC • Больше фичей и-или “сопливый” код = ~1..10M+ LOC
не надо • Мало усилий => так себе и получится • Много усилий => это зачем? • Берите базу, берите Sphinx, берите Lucene & spawn • Бегите от “заказчиков”, у которых нету $10 на VPS!!!
форматы индекса; скорость индексации; размеры индекса; требования к RAM; механизмы масштабирования; API доступа; функционал текстового поиска; скорость текстового поиска, причем от вида запроса; скорость НЕтекстового поиска; добавочные функции (геопоиск, фасеты, подсказки, сниппеты); ранжирование; расширяемость…
только лишь все • Мало кто может это делать • У каждого свои требования, и они ортогональны • Качество поиска VS супербыстрый булев поиск? • Текстовый поиск VS атрибутивка? • Масштабирование на терабайты VS индекс на 1 GB?
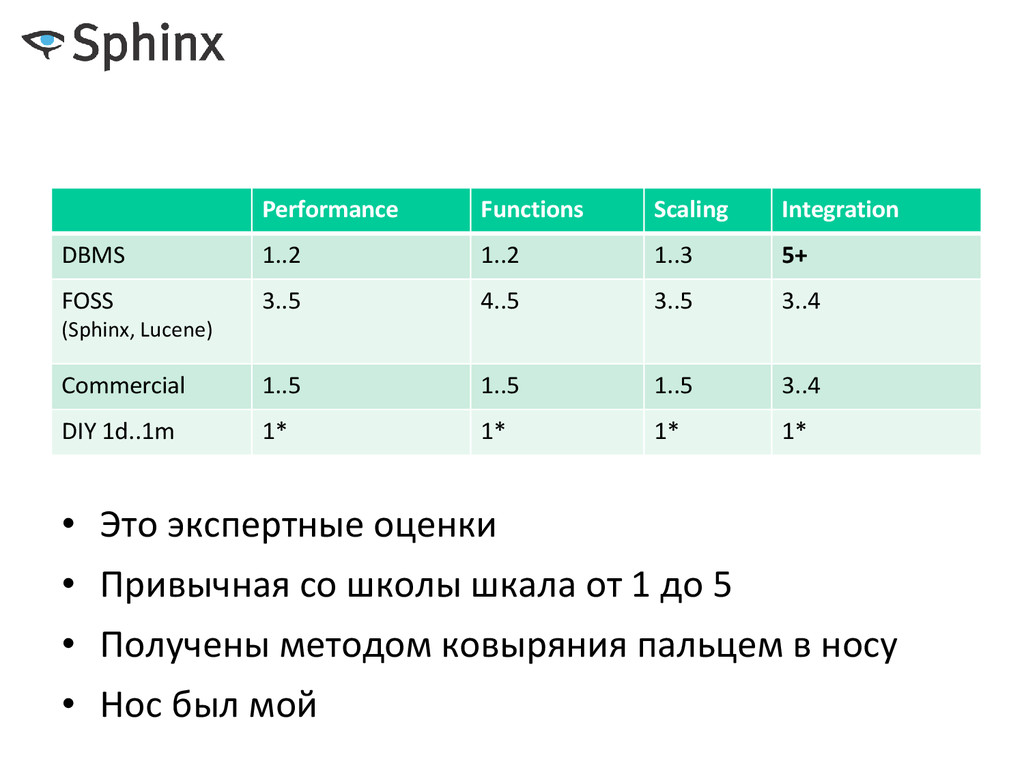
(Sphinx, Lucene) 3..5 4..5 3..5 3..4 Commercial 1..5 1..5 1..5 3..4 DIY 1d..1m 1* 1* 1* 1* • Это экспертные оценки • Привычная со школы шкала от 1 до 5 • Получены методом ковыряния пальцем в носу • Нос был мой
любому параметру – это за свои же деньги • в целом не впечатляет • DIY • в общем (для всех задач) будет очень плохо • но в частностях, возможно, невероятно хорошо • хочешь круто угореть – спроси меня как!
• Всё начинается от текстового поиска • Отдельно довески про атрибутивку • Что это значит? • “Тупо поиск” работает принципально одинаково • Детали реализации, однако, могут Менять Всё
• Sphinx 1.x, преиндексируем всё • Sphinx 2.0, expansion с индексами • Sphinx 3.0, думаем про гибрид • Lucene ?.?, expansion без индексов • Lucene 4.?, expansion с индексами • Разница в скорости в 100 (сто) раз? Легко • Разница в памяти? Привет, “Журавлёв”
table • Lucene = on-disk, row-based docstore + кеш • Доступ в Sphinx = in-memory hash lookup • Доступ в Lucene = как бы disk read, поэтому кеш • Sphinx = можно мешать schemaful/schemaless • Lucene = полный schemaless, поэтому кеш • Зато в 2.x дурные legacy ограничения • Зато у нас возможен UPDATE
Sphinx 2.x = хранилки документов нет • Sphinx 3.x = хранилка документов тоже есть • Тоже перерастаем в странную СУБД • Тоже disk based, тоже LZ4 • Принципиально улучшить не удалось
• Sphinx = внутренних кешей почитай нет • Lucene = скорость пох, всё закешируем! • Lucene = кешируется ВСЁ, хрен отключишь • Делать адекватные бенчмарки это АД • Xapian (внезапно) = мега оптимизация под дефолтный, никому не нужный юзкейс
фиксированный бюджет памяти! • Lucene = не-не-не, булев матчинг и может BM25; памяти побольше тупо ставь • Sphinx 2.x = неидеально c булевым поиском • Sphinx 3.x = думаем про отдельный lightweight path… и убрать бюджетирование, муахахаха • Lucene = неидеально с ранкингом, позициями
• Везде некий API (SphinxQL, REST/XML или JSON) • Везде завелись RT индексы, schemaless/JSON • Везде агрегация результатов с кластера • Везде поддержка атрибутивки, допфункций • Везде, что странно, “просто поиск” сегодня как- то работает!!! • Коммодитизация…
системы, делаем к ним одинаковый запрос, сравниваем время • На оценку 4 = повторяем запрос N раз, считаем среднее время, чтобы кеш прогрело и не дрожало • На оценку 5 = выкидываем 1й прогон всегда и даже выкидываем outliers, считаем среднее без них
считаем всё заново, кешируется только read(), и тот внутриOS • Lucene = на всех уровнях внутренние кеши, некоторые не отключить никак – Нужна долбежка многими разными запросами – Повтор 1 запроса подряд = обмеряем кеш – Повтор 10-20 запросов = в общем-то тоже
у вас в N раз медленнее, чем Solr?” – Sphinx, поддержка синтаксиса / Solr, тупорылый bag-of-words – Sphinx, произвольный текст / Solr, только преиндексированный – И ключевая “оптимизация” Solr... – Зачем честно подсвечивать всё, если можно быстро первые 64 KB?!
сравниваемые системы (увы!) • Делаем действительно сходные запросы • Моделируем боевую нагрузку, помним про внутренние и внешние кеши • Смотрим функционал (что реально критично?) • Прикидываем на пальцах TCO
сравниваемые системы (увы!) • Делаем действительно сходные запросы • Моделируем боевую нагрузку, помним про внутренние и внешние кеши • Смотрим функционал (что реально критично?) • Прикидываем на пальцах TCO
– Зато удобно (ничего не надо делать!!!) • Sphinx, Lucene et al = – Ср. быстро и функционально – Разные виды запросов могут сильно отличаться – Разный функционал и, похоже, “фокус” – Мерить нужное, иначе (уже+пока) никак
годы – Результат может быть любой • Коммерческие = – Неожиданные подвохи везде – Хтоническая интеграция и поддержка – Шмотка +X к TCO, но зато +Y к откату • Дефолтные настройки могут удивить, везде
Друг Вася пользуется и Петя ещё хвалил! – На Хабре чота писали вроде крутое! – Есть интерн с опытом! (homepage) • Выбираем систему Y, т.к. – Она дорогая от известного мега-производителя – И деньги очень нужны имеет убедительные плюсы
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Вопросы? Для стеснительных: [email protected]](https://files.speakerdeck.com/presentations/00724990514d013239f51ed527c22d35/slide_58.jpg){kind=link}