When the domain of your data is clearly a graph, why shove it into a relational model? Specialized graph databases like Neo4j have demonstrated that it's easier to "think in graphs", while working with your data. But is Neo4j fast enough for use cases where tight performance is needed?
![Neo4j Magic Adventures Dmitry Vrublevsky @ Neueda [email protected]](https://files.speakerdeck.com/presentations/804a88404ae40132f285624d3aca0ff3/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
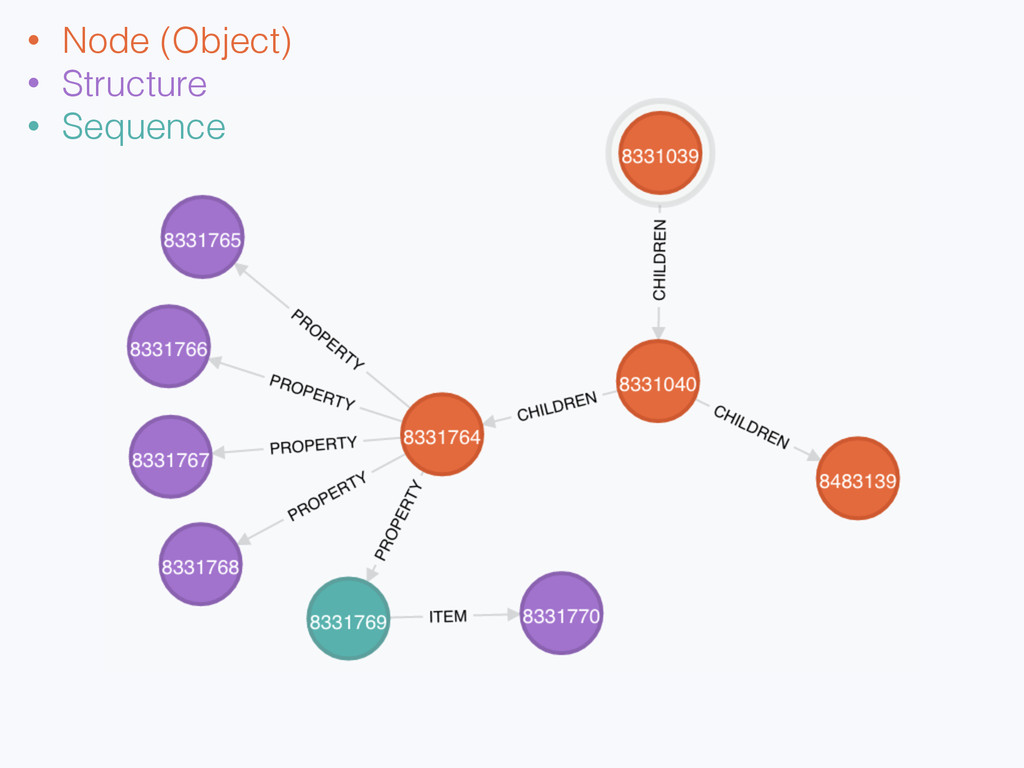{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![MATCH (john {name: ‘John’})-[:friend]->(friends) MATCH (friends)-[:friend]->(fof) RETURN john, fof (](https://files.speakerdeck.com/presentations/804a88404ae40132f285624d3aca0ff3/slide_17.jpg){kind=link}
{kind=link}
![Solution via Cypher query MATCH (root:Object)-[r1:CHILDREN*]->(child:Object) WHERE root.id = {rootNodeId}](https://files.speakerdeck.com/presentations/804a88404ae40132f285624d3aca0ff3/slide_19.jpg){kind=link}
{kind=link}
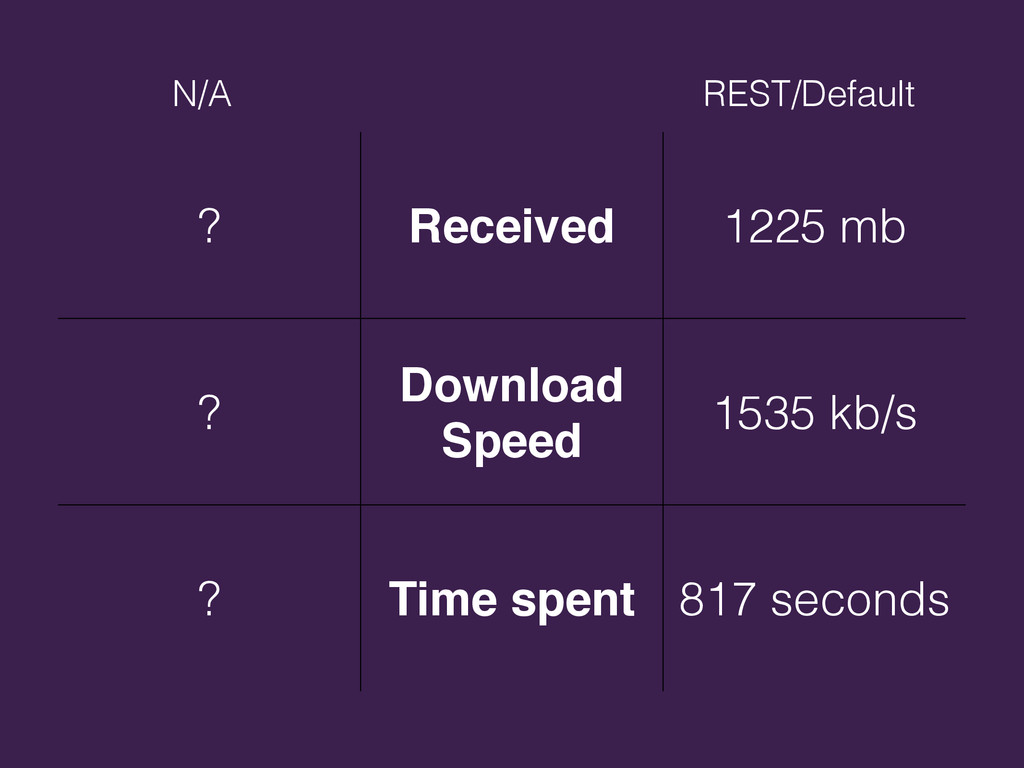{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
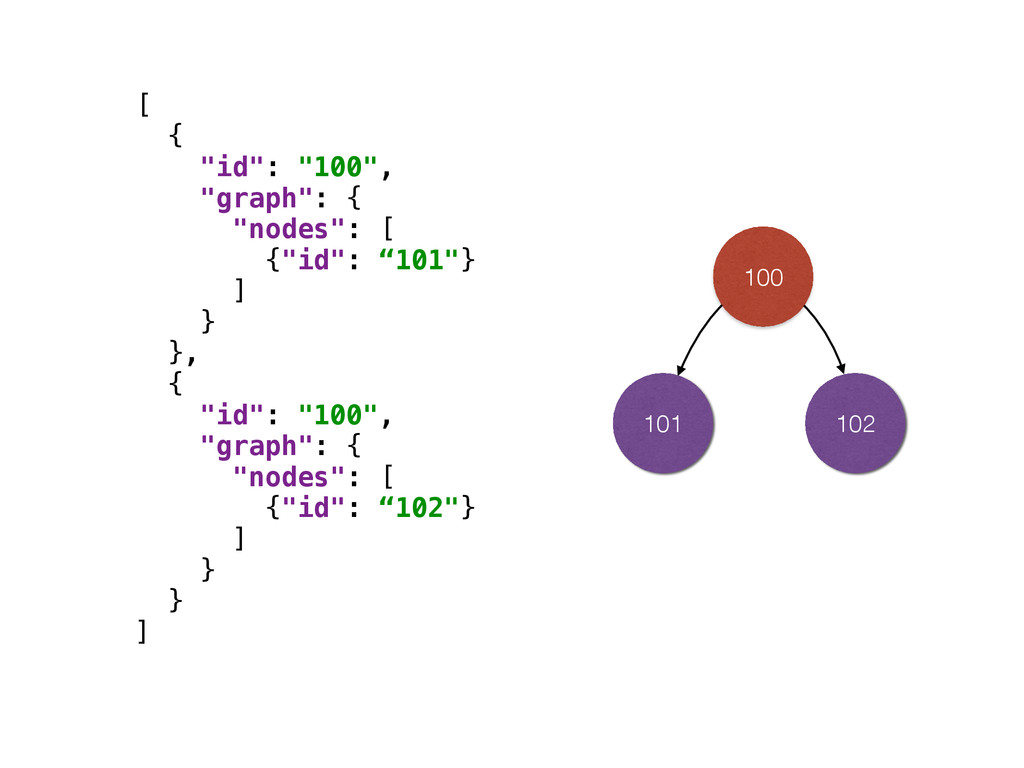{kind=link}
{kind=link}
![Another solution MATCH (root:Object)-[r1:CHILDREN*]->(child:Object) WHERE root.id = {rootNodeId} OPTIONAL MATCH](https://files.speakerdeck.com/presentations/804a88404ae40132f285624d3aca0ff3/slide_29.jpg){kind=link}
{kind=link}
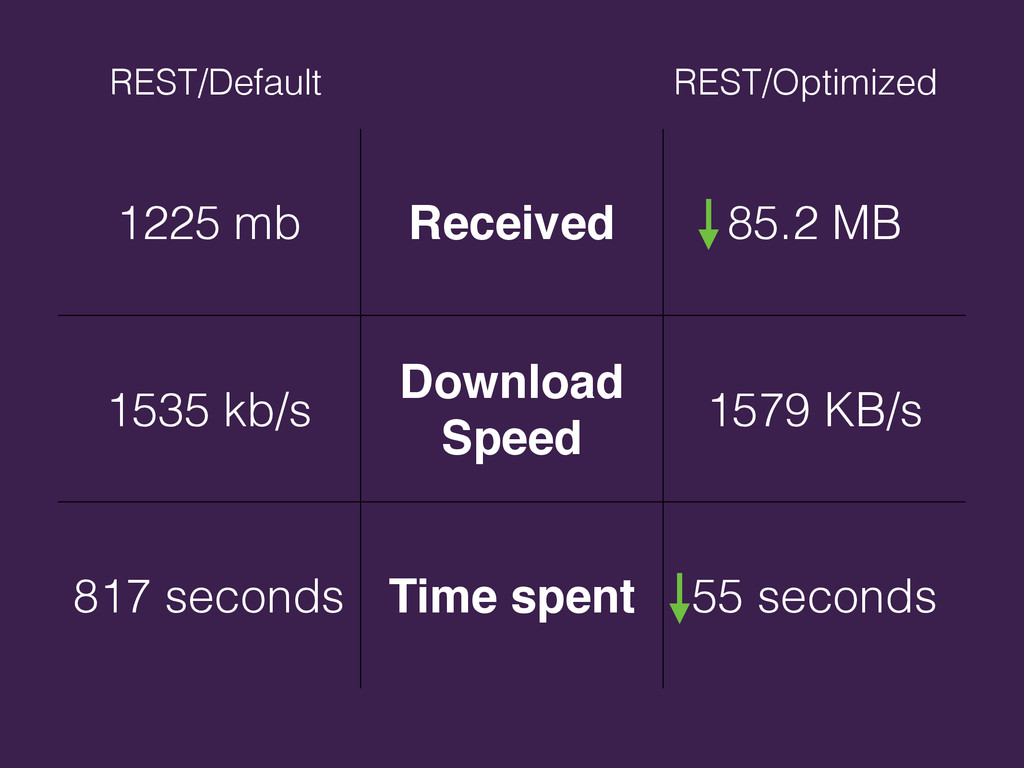{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
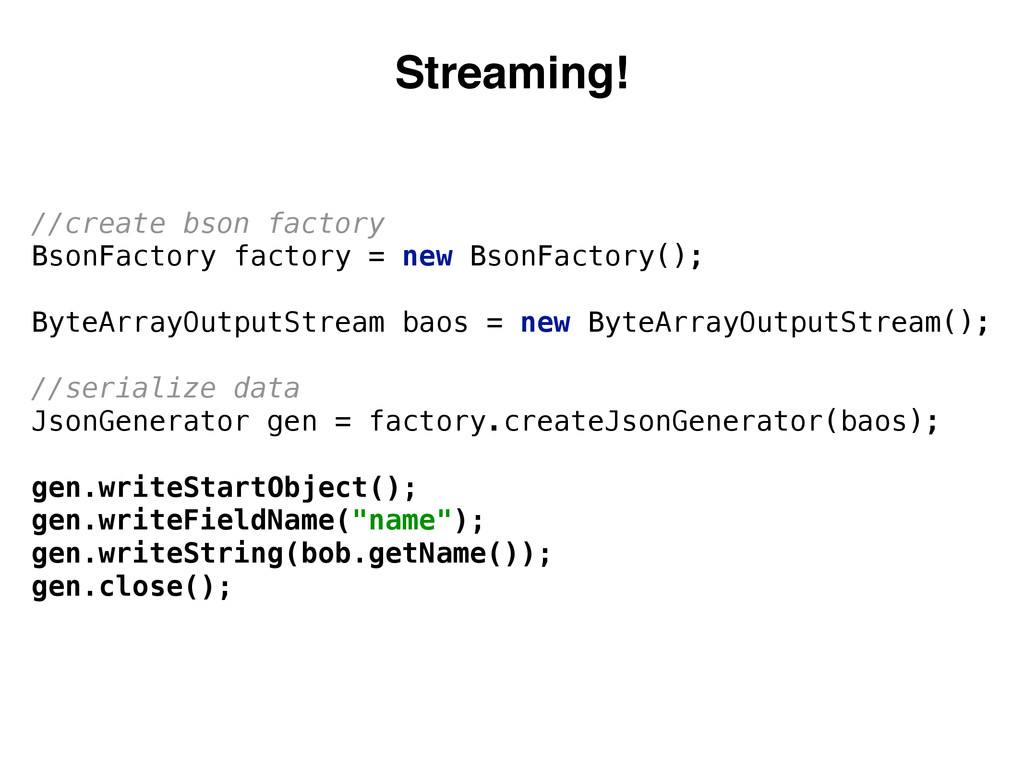{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![New cypher solution MATCH (root:Object)-[:CHILDREN*]->(child:Object) WHERE root.id = {rootNodeId} RETURN](https://files.speakerdeck.com/presentations/804a88404ae40132f285624d3aca0ff3/slide_47.jpg){kind=link}
{kind=link}
{kind=link}
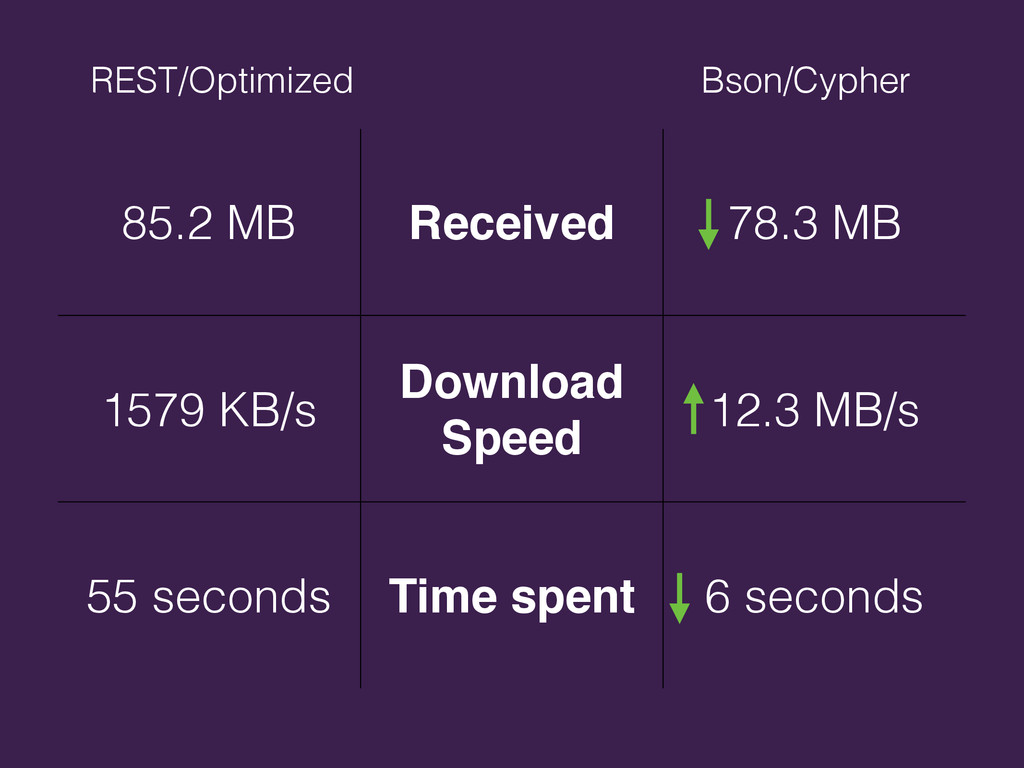{kind=link}
{kind=link}
{kind=link}
{kind=link}
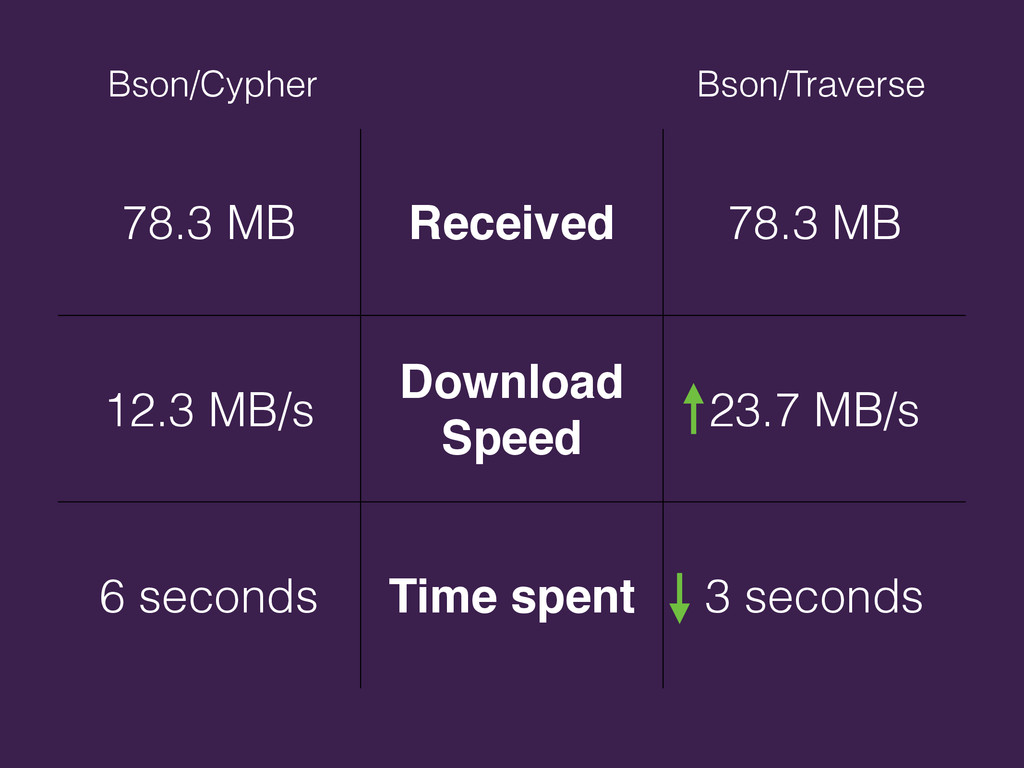{kind=link}
{kind=link}
{kind=link}
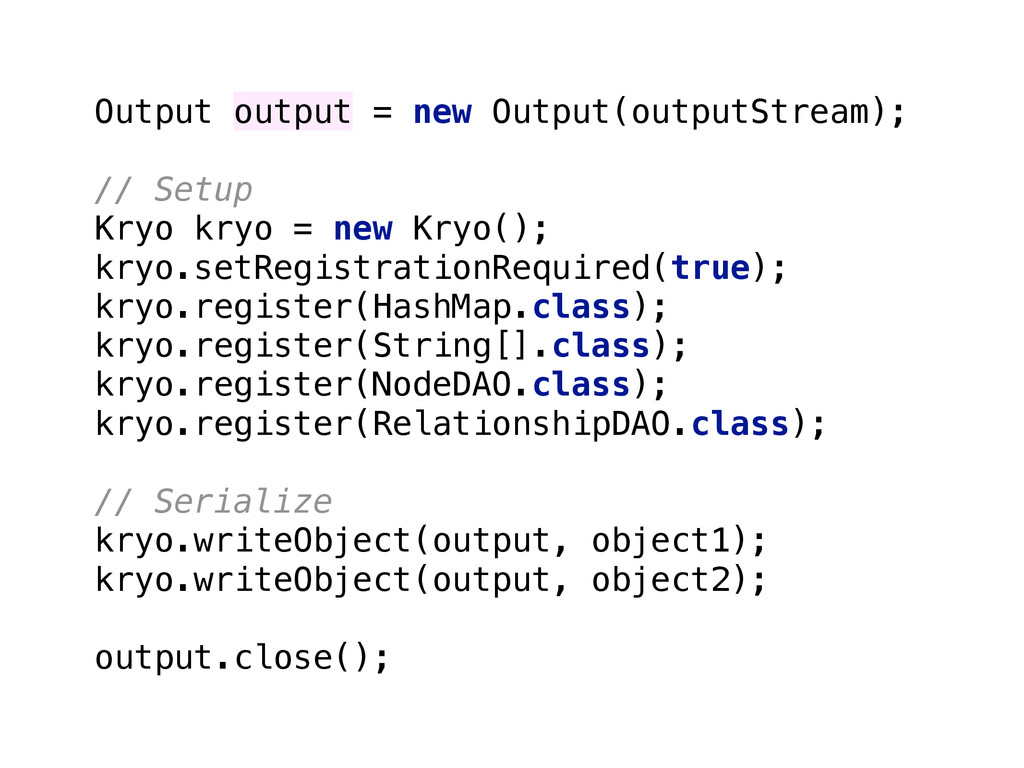{kind=link}
{kind=link}
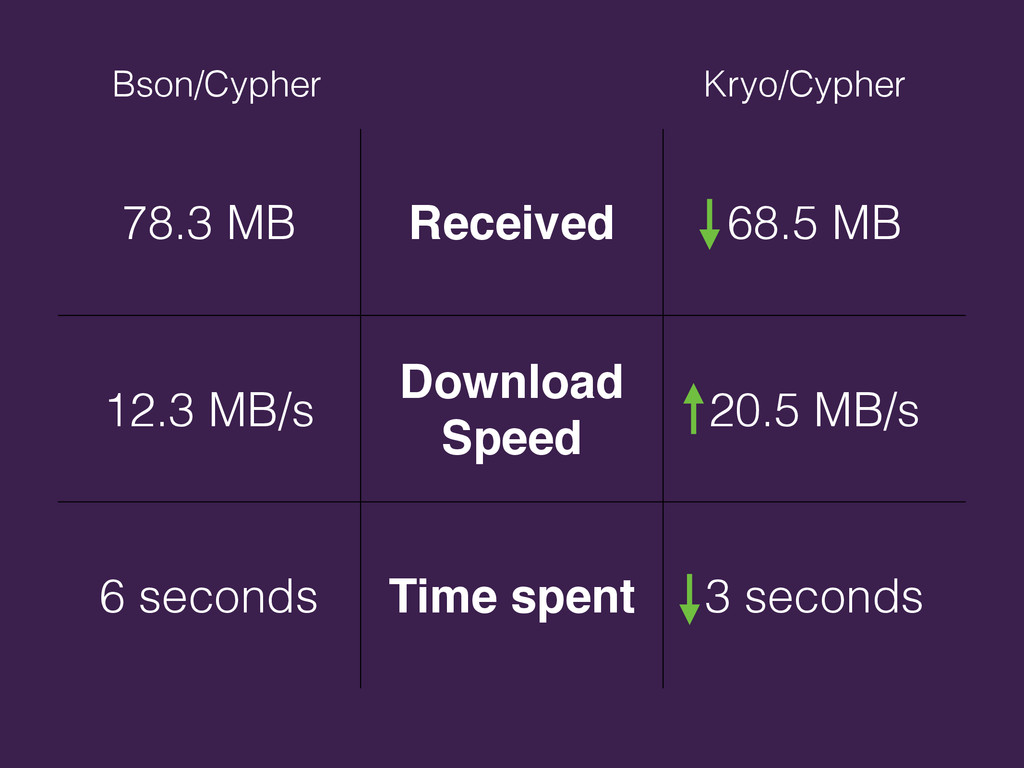{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
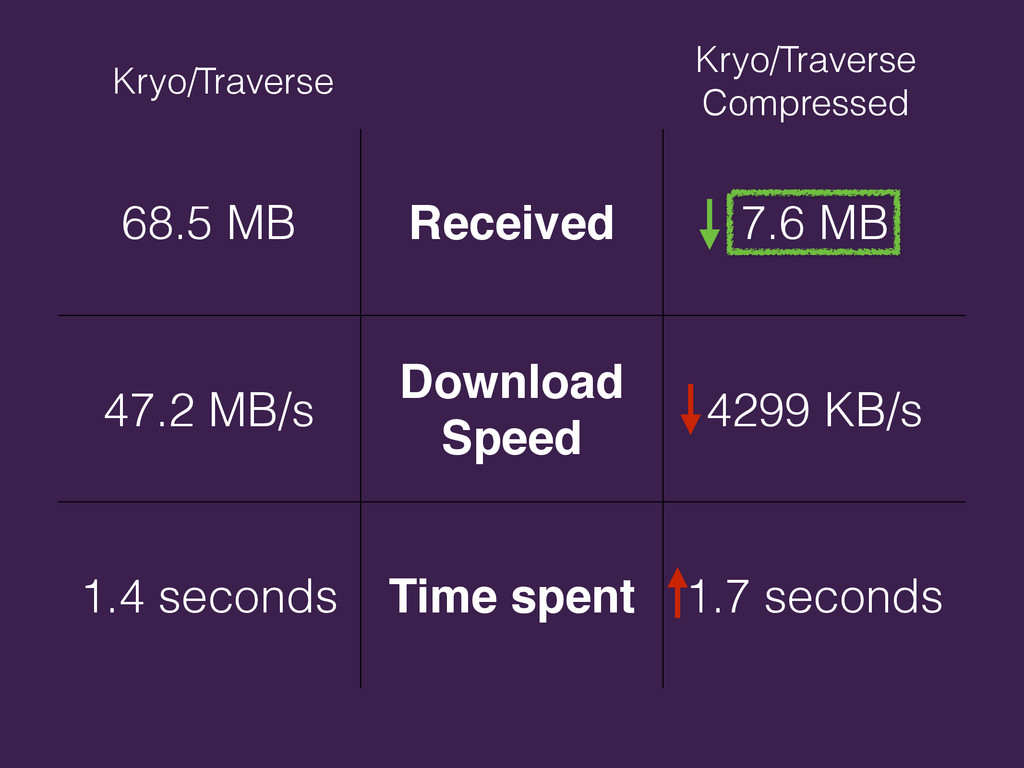{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
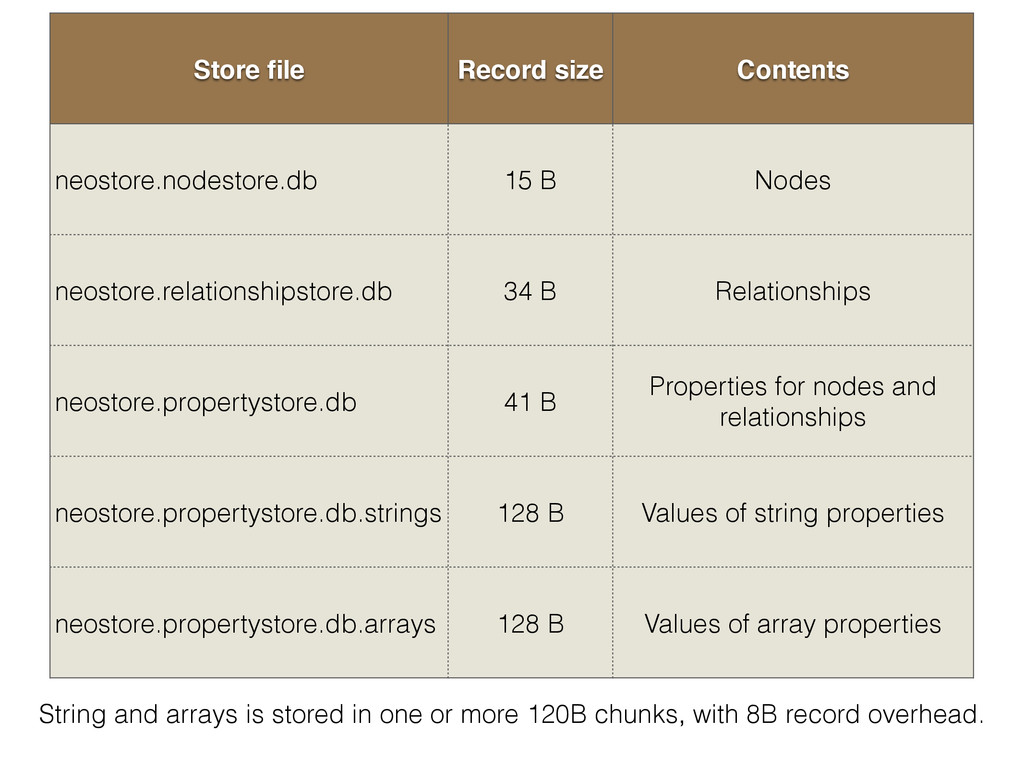{kind=link}
{kind=link}
{kind=link}
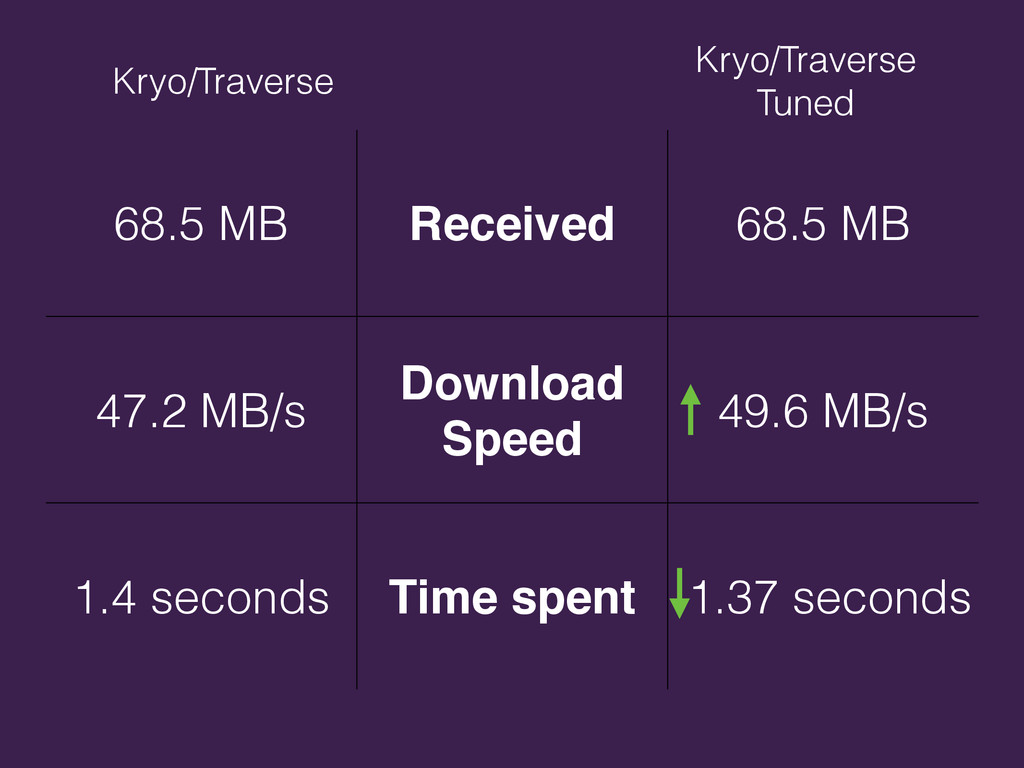{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
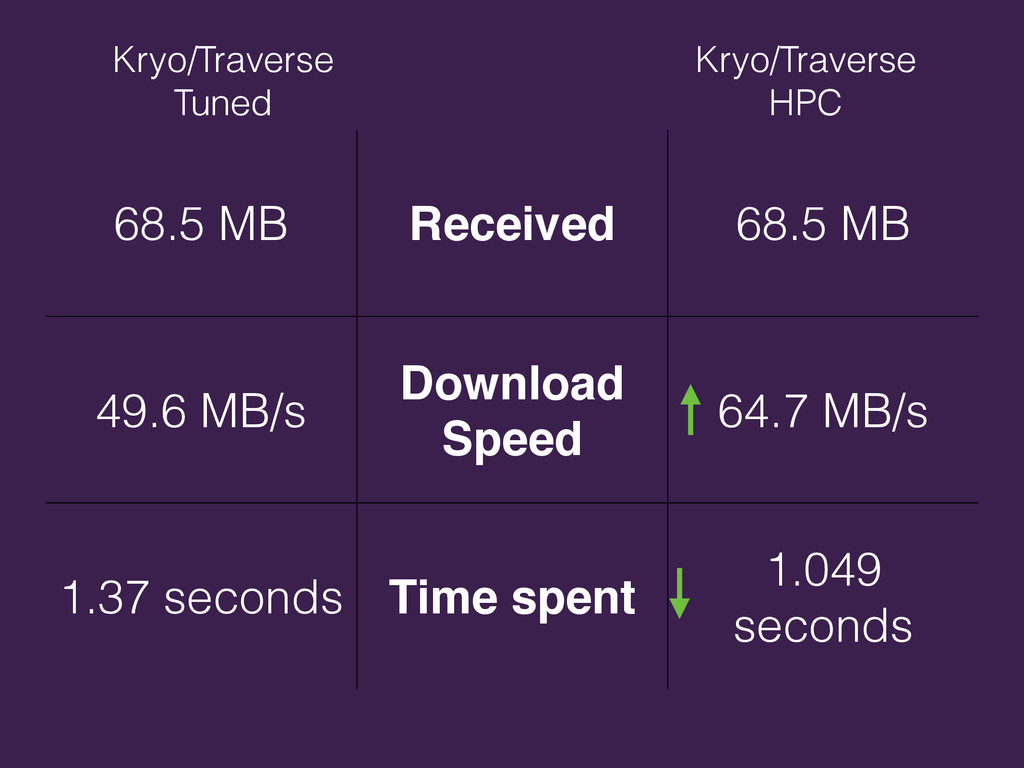{kind=link}
{kind=link}
{kind=link}
{kind=link}
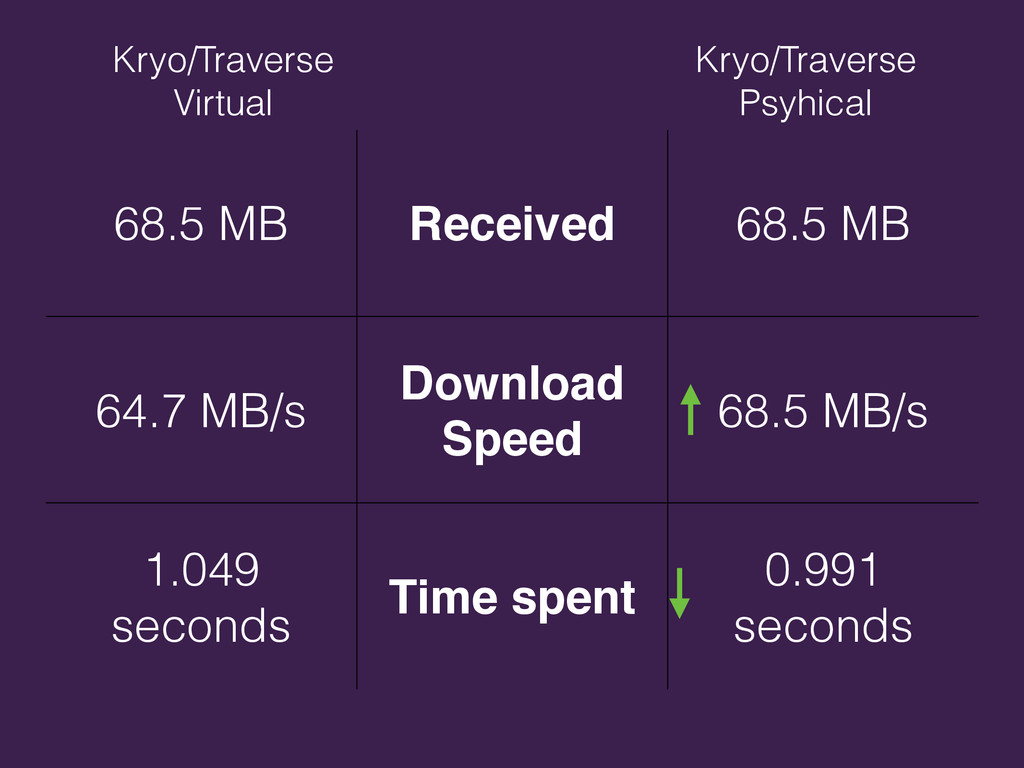{kind=link}
{kind=link}
{kind=link}