Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Matrix Multiplication
Search
Moro
November 14, 2018
Programming
14
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Matrix Multiplication
Parallel Computing in Shared Memory using OpenMP - Matrix Multiplication problem.
Moro
November 14, 2018
More Decks by Moro
See All by Moro
MockK and Truth - Unit Tests - Android
gabrielbmoro
0
150
More Accessible Apps - Android
gabrielbmoro
0
12
Variables and Tips - Android
gabrielbmoro
0
14
Migrating an Existing App to Compose - Android
gabrielbmoro
0
16
Recycler View and Performance - Android
gabrielbmoro
0
15
Repository Pattern and Productivity - Android
gabrielbmoro
0
16
What is new in Android Jetpack?
gabrielbmoro
0
24
List Users - Android
gabrielbmoro
0
10
Working with Collections - Kotlin
gabrielbmoro
0
18
Other Decks in Programming
See All in Programming
任せる範囲はこう広がった / How the Scope of AI Delegation Has Expanded
nrslib
1
260
ルールを書いて終わらせないハーネスエンジニアリング
yug1224
2
1.5k
エンジニア向け会社紹介/Findy Company Profile
findyinc
6
360k
えっ!!コードを読まずに開発を!?
hananouchi
0
210
Performance Engineering for Everyone
elenatanasoiu
0
270
才能?センス?知らん、 続けたもん勝ちだ。-- 結婚・出産・癌を越えてなお、私がプロダクトを創り続ける理由
16bitidol
2
860
【やさしく解説 設計編・中級 #6】良いアーキテクチャとは ~ 一本の登り道の、行き先 ~
panda728
PRO
0
160
ローカルLLMでどこまでコードが書けるか -拡張版 / How much code can be written on a local LLM Extended
kishida
12
4.8k
SREの積み重ねがAI駆動開発のガードレールになった ― 7つの実践/SRE Guardrails The 7
tomoyakitaura
8
4.3k
型も通る、synthも通る、それでも危ない 〜AIのCDKの権限とコストを機械で検証する〜 / It Passes Type Checks, It Passes Synth Checks, but It’s Still Risky — Automatically Verifying Permissions and Costs in AI’s CDK —
seike460
PRO
1
320
コーディングルールの鮮度を保ちたい for SRE NEXT 2026 / keep-fresh-go-internal-conventions-sre-next-2026
handlename
0
140
5分で問診!Composer セキュリティ健康診断
codmoninc
0
270
Featured
See All Featured
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2.1k
Navigating Team Friction
lara
192
16k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
The Illustrated Children's Guide to Kubernetes
chrisshort
51
53k
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
The SEO identity crisis: Don't let AI make you average
varn
0
510
Leveraging Curiosity to Care for An Aging Population
cassininazir
1
390
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.9k
Making Projects Easy
brettharned
120
6.7k
<Decoding/> the Language of Devs - We Love SEO 2024
nikkihalliwell
1
270
Transcript
Matrix Multiplication Parallel Computing in Shared Memory using OpenMP Gabriel
Moro - KNOWLEDGE TRANSFER - KT, Porto Alegre - November 2018
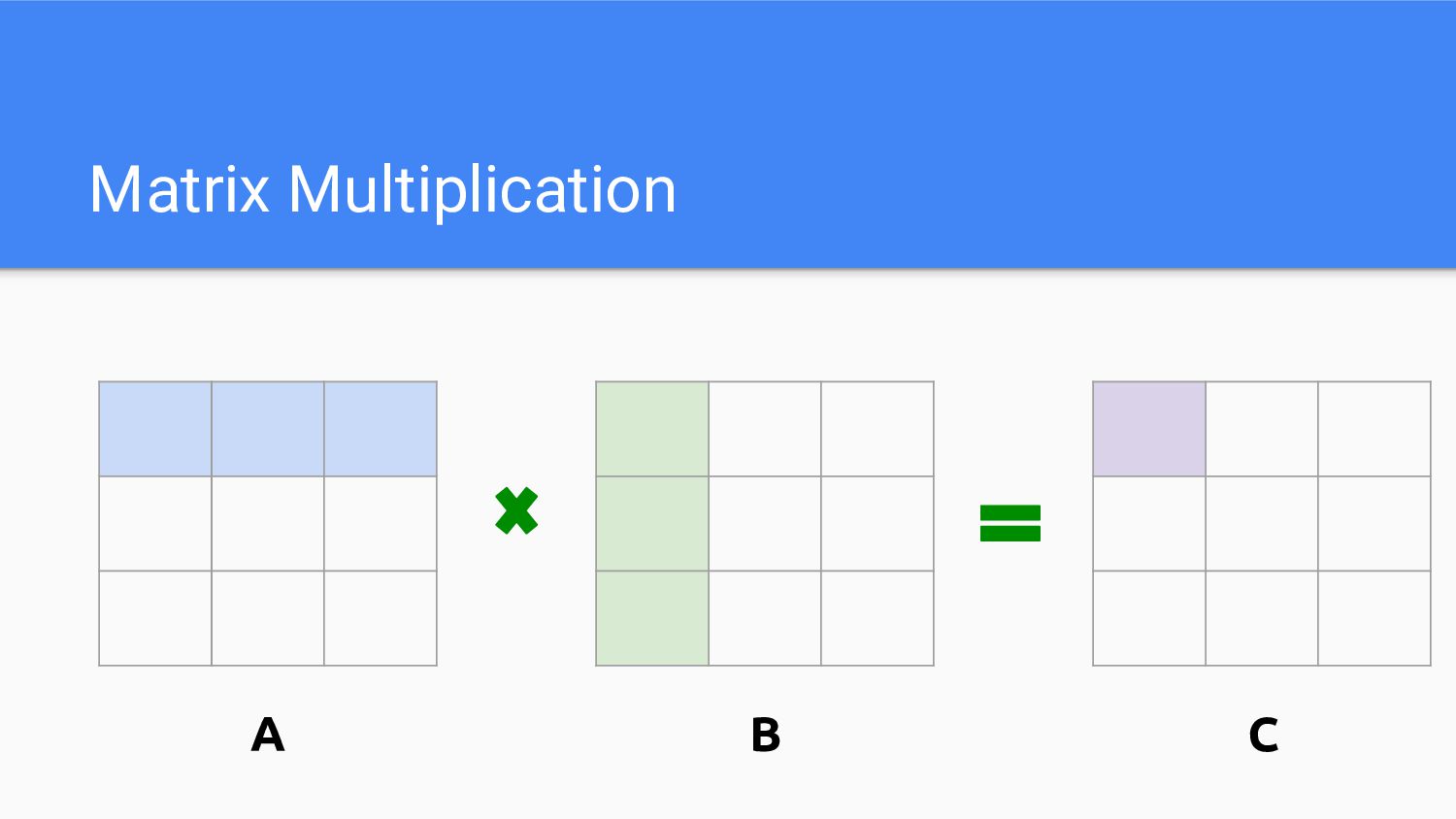
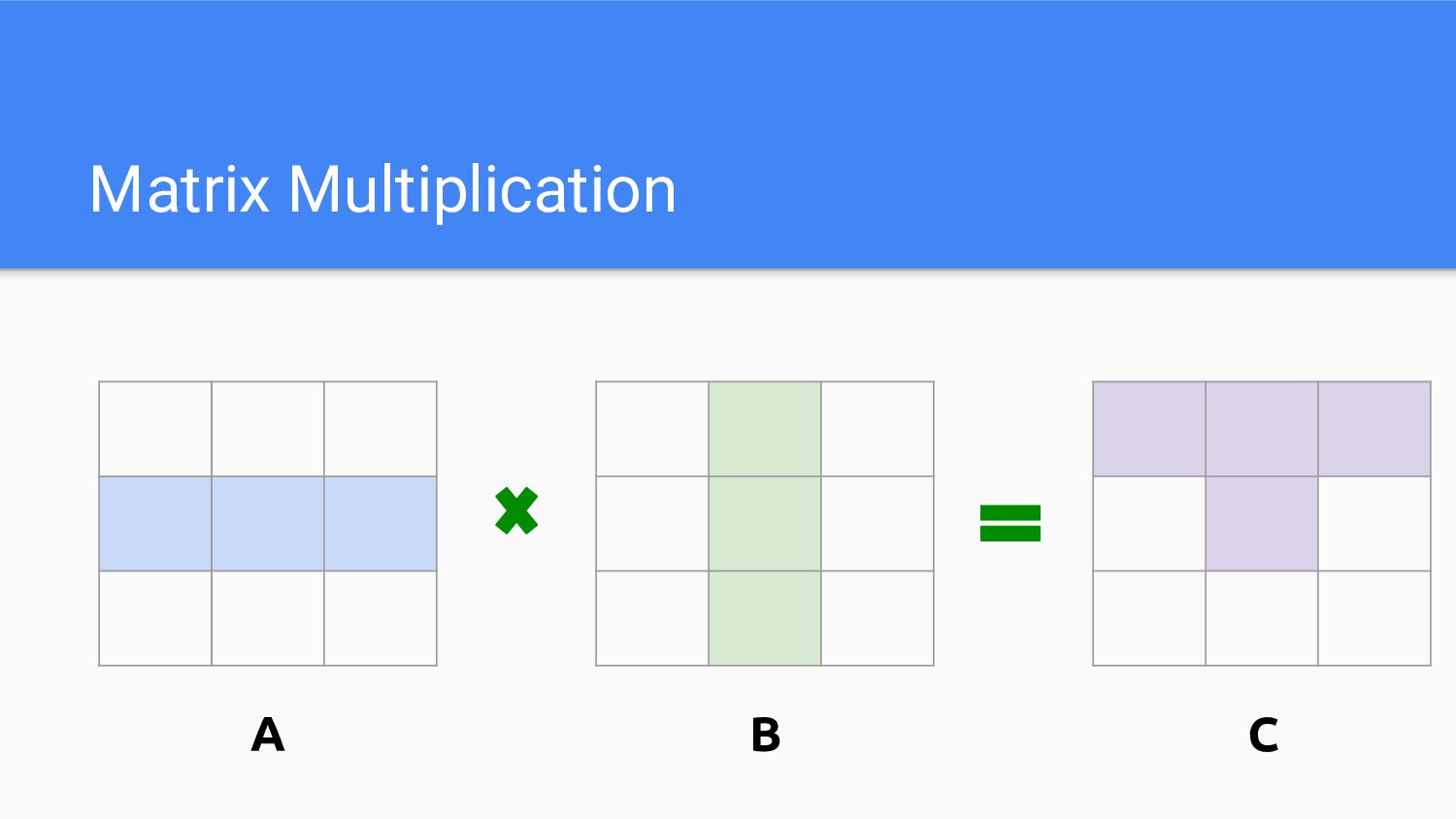
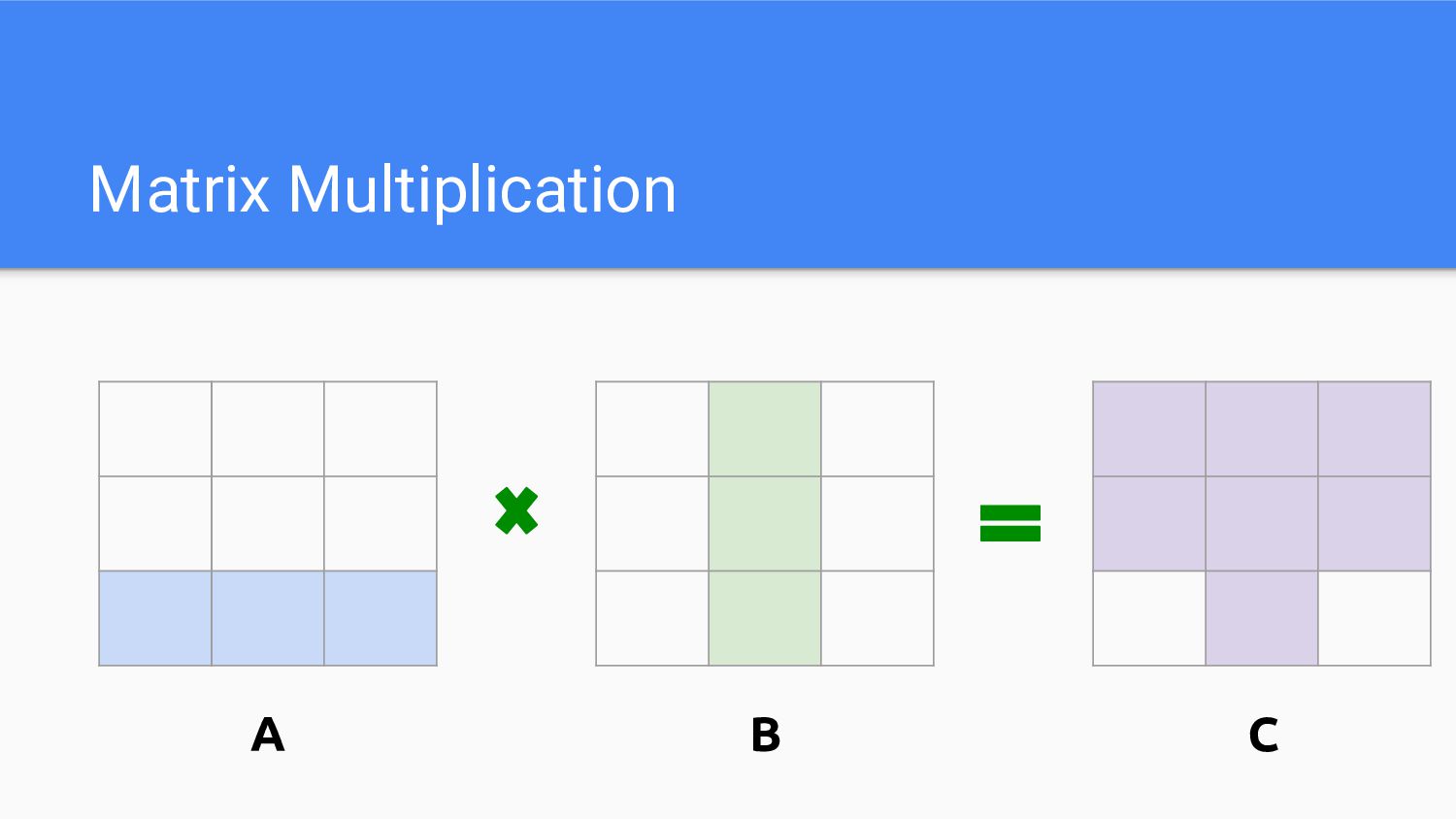
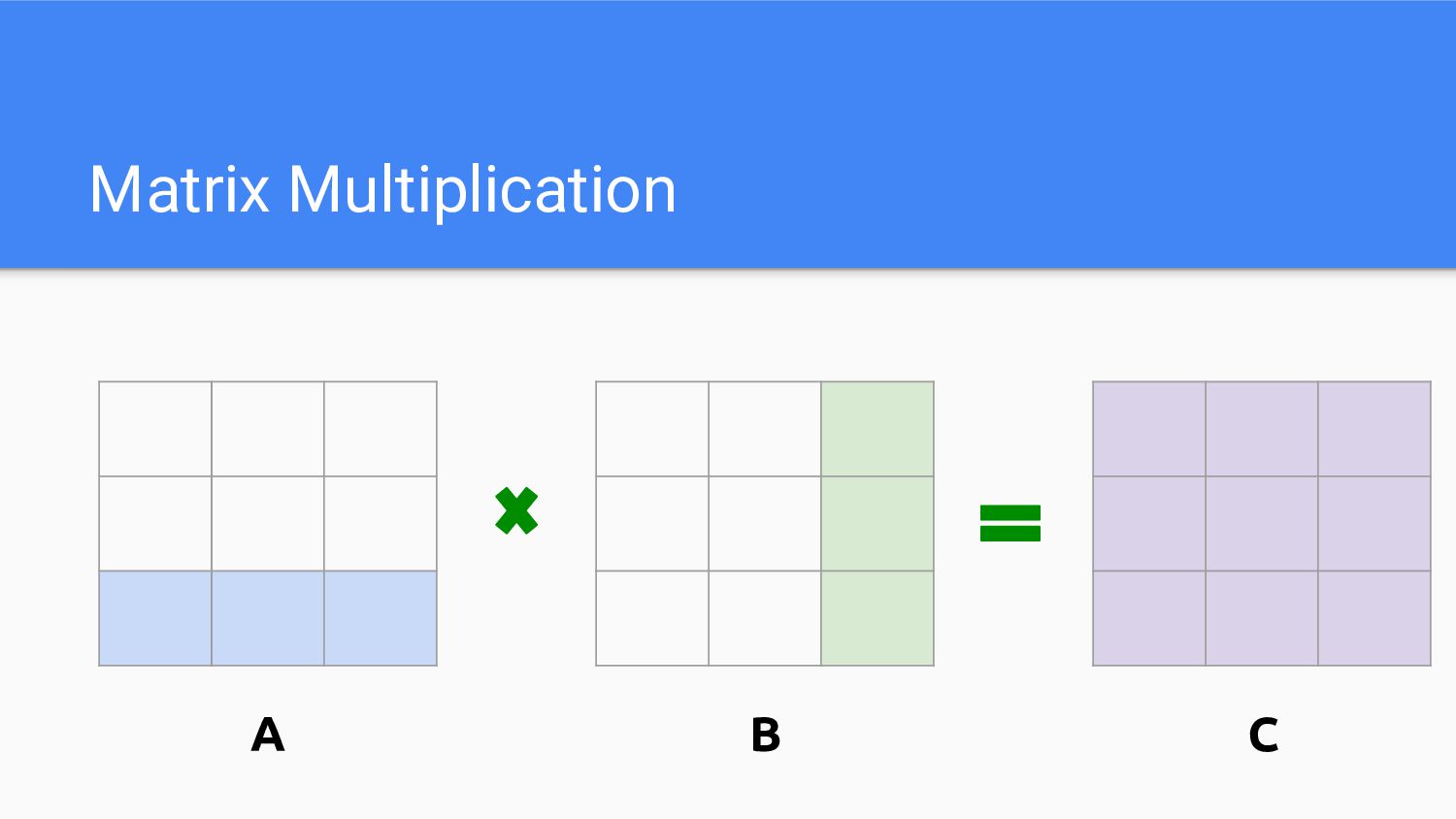
Matrix Multiplication A B C
Matrix Multiplication A B C
Matrix Multiplication A B C
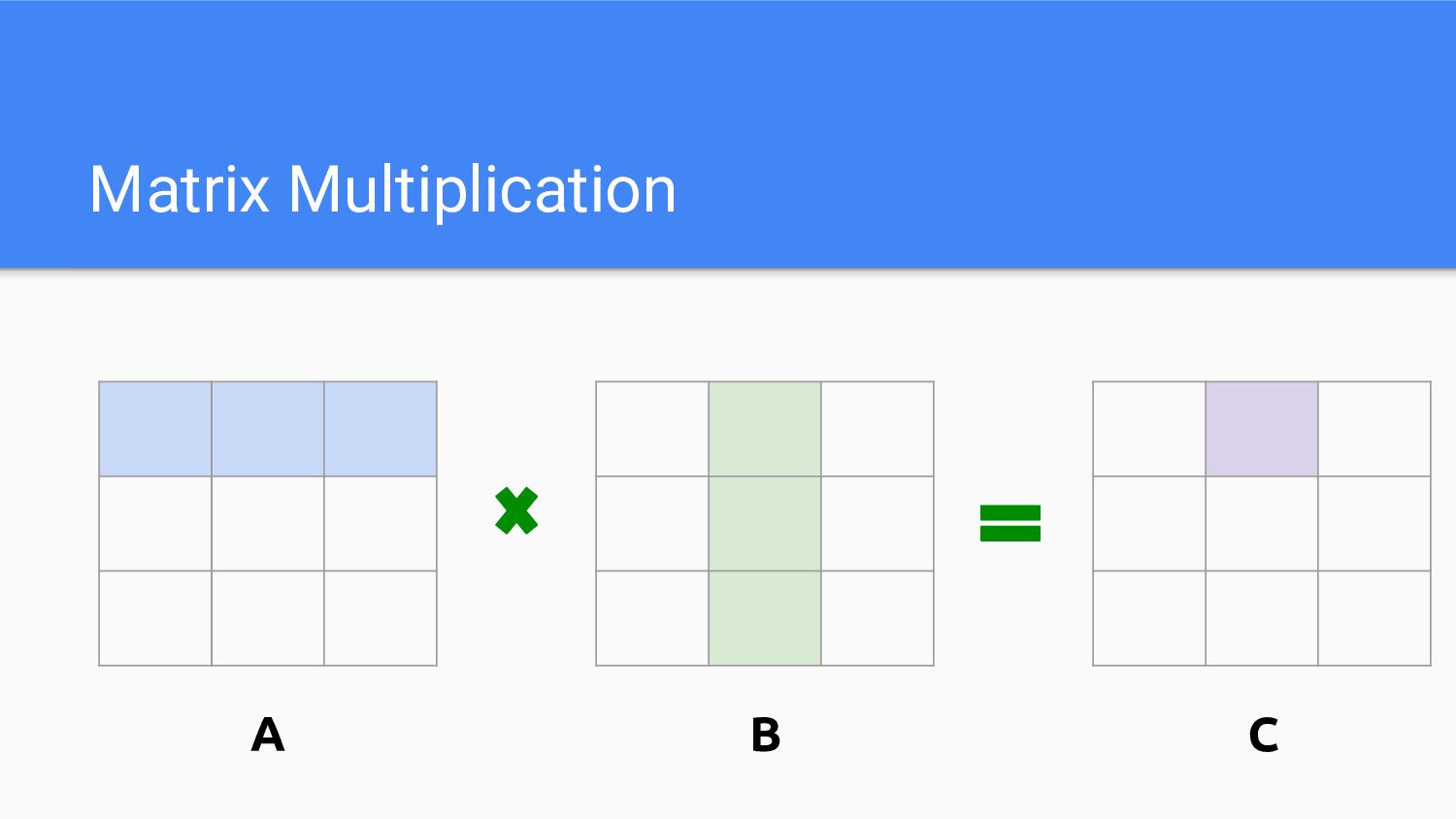
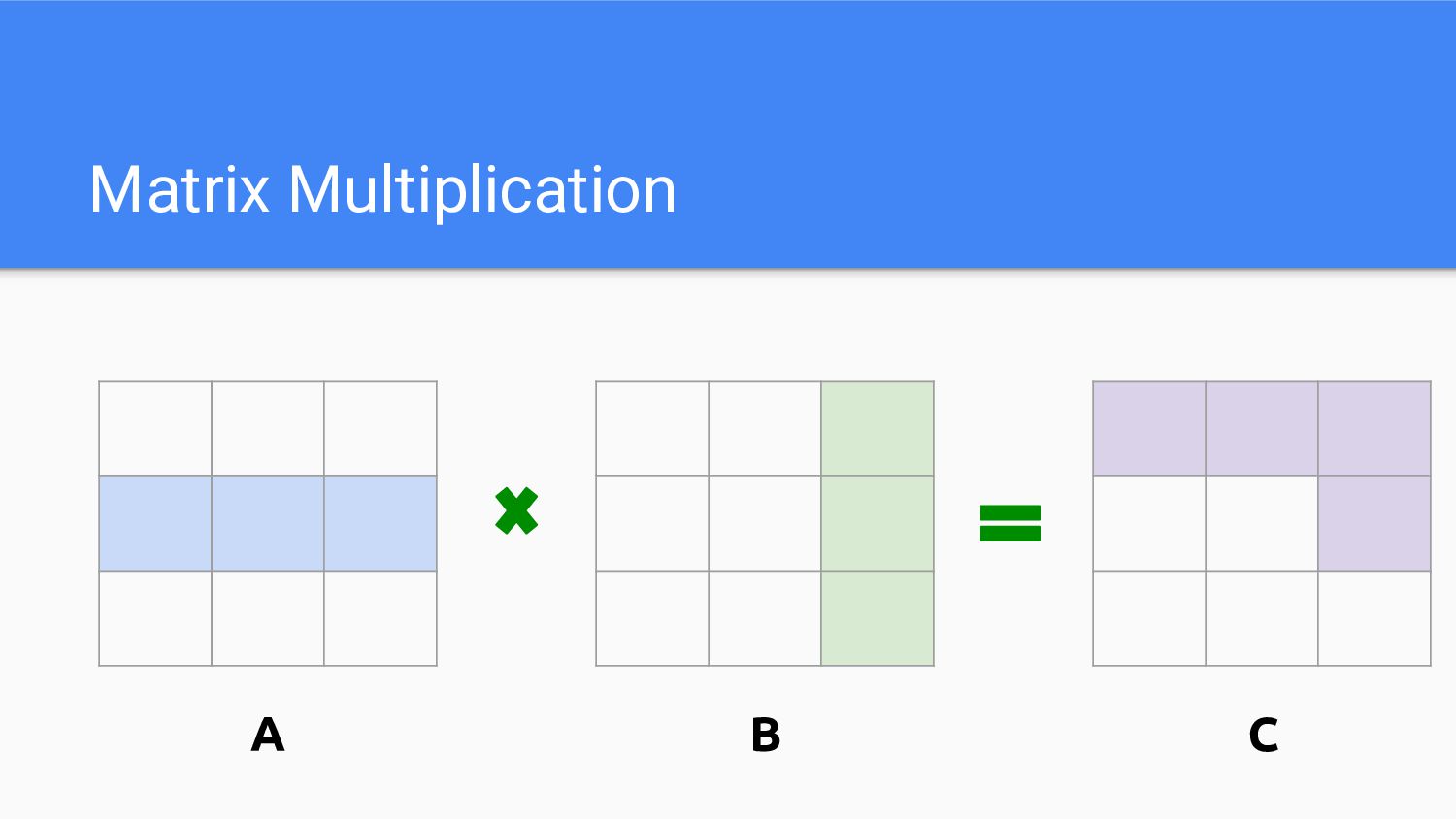
Matrix Multiplication A B C
Matrix Multiplication A B C
Matrix Multiplication A B C
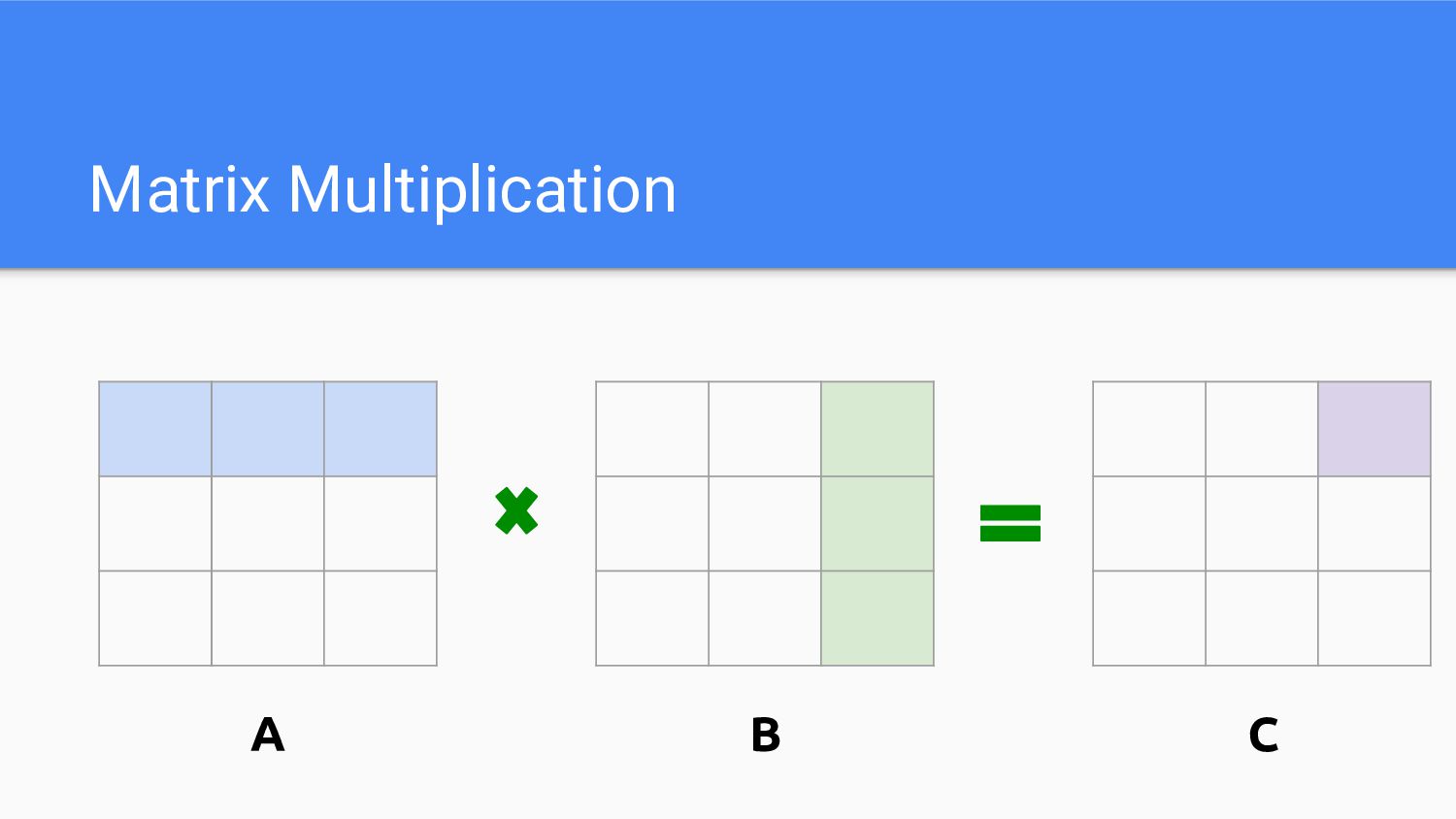
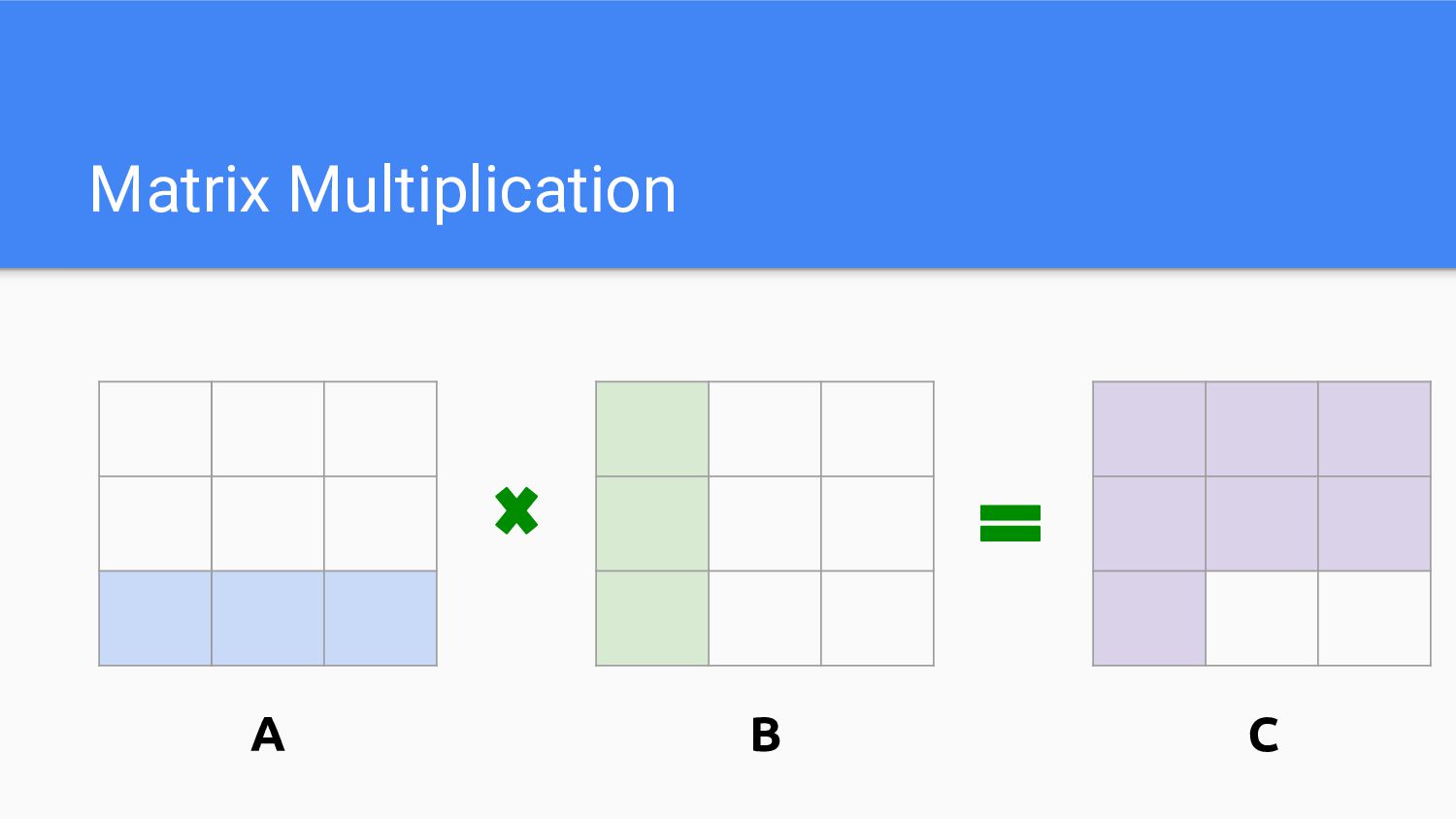
Matrix Multiplication A B C
Matrix Multiplication A B C
Matrix Multiplication A B C
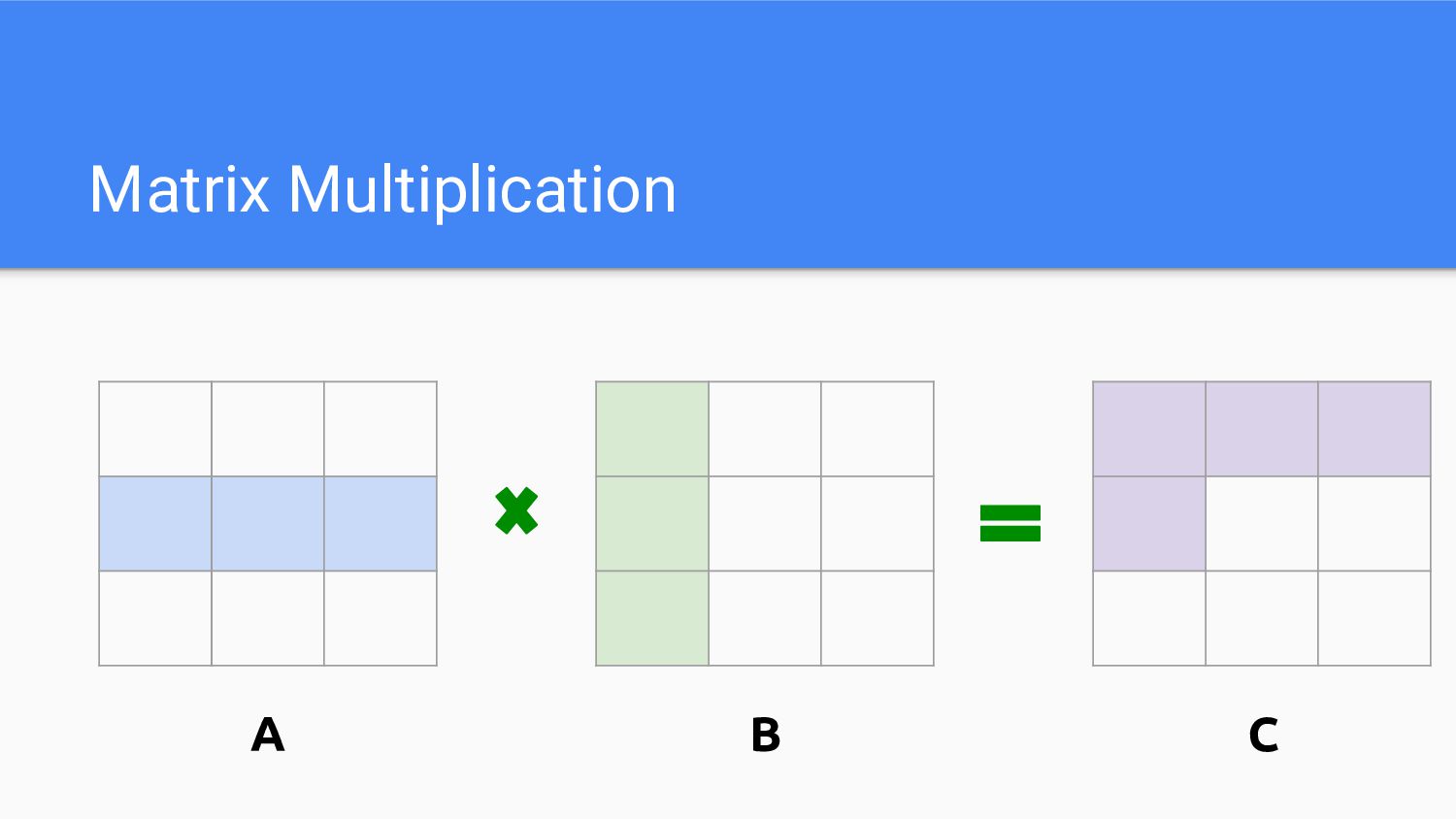
Ways to improve the performance to this algorithm - Algorithm
complexity - Parallelism
Ways to improve the performance to this algorithm - Algorithm
complexity - Parallelism
Ways to improve the performance to this algorithm - Algorithm
complexity - Parallelism - Shared Memory - Distributed Memory
Ways to improve the performance to this algorithm - Algorithm
complexity - Parallelism - Shared Memory - Distributed Memory
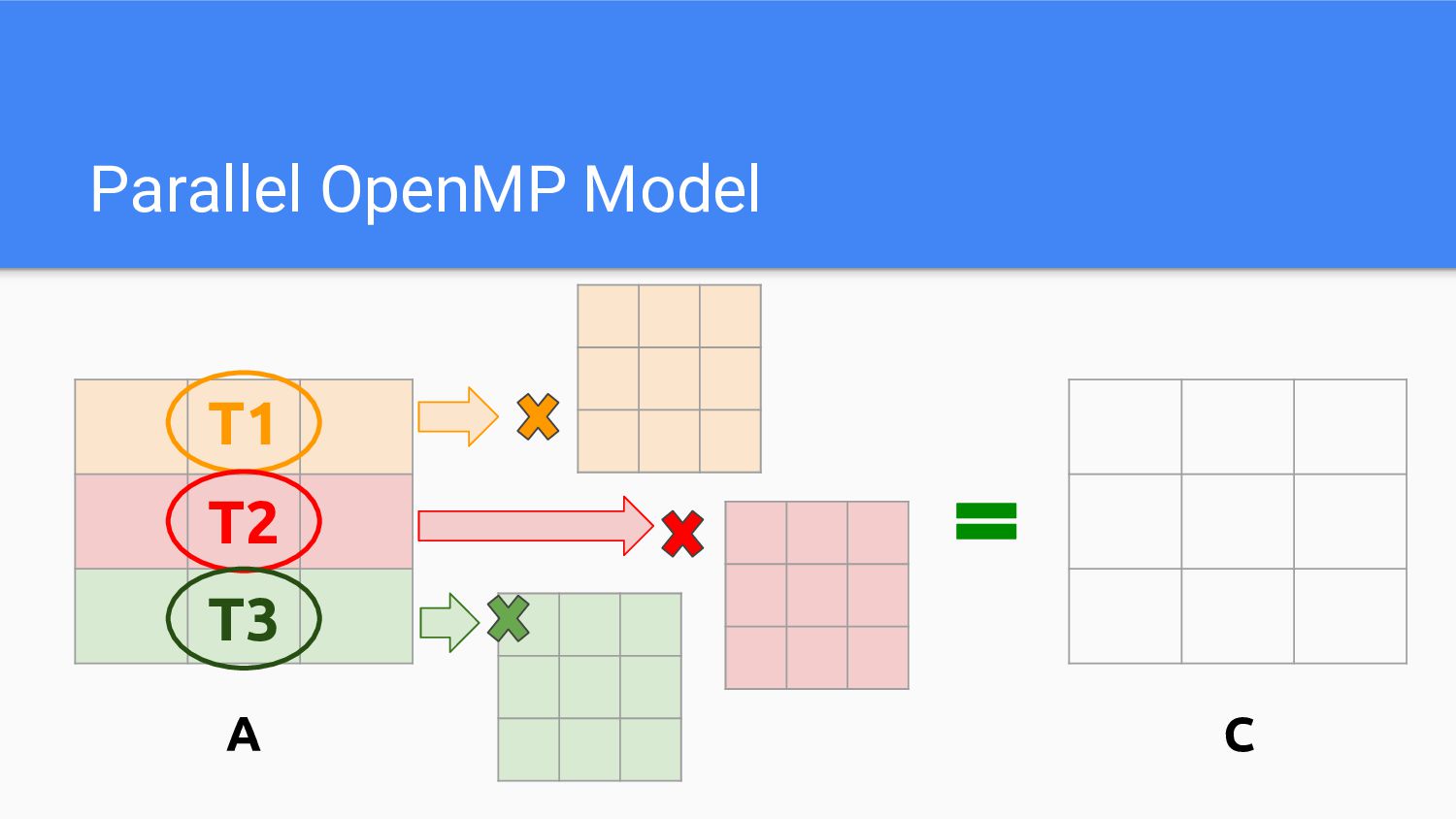
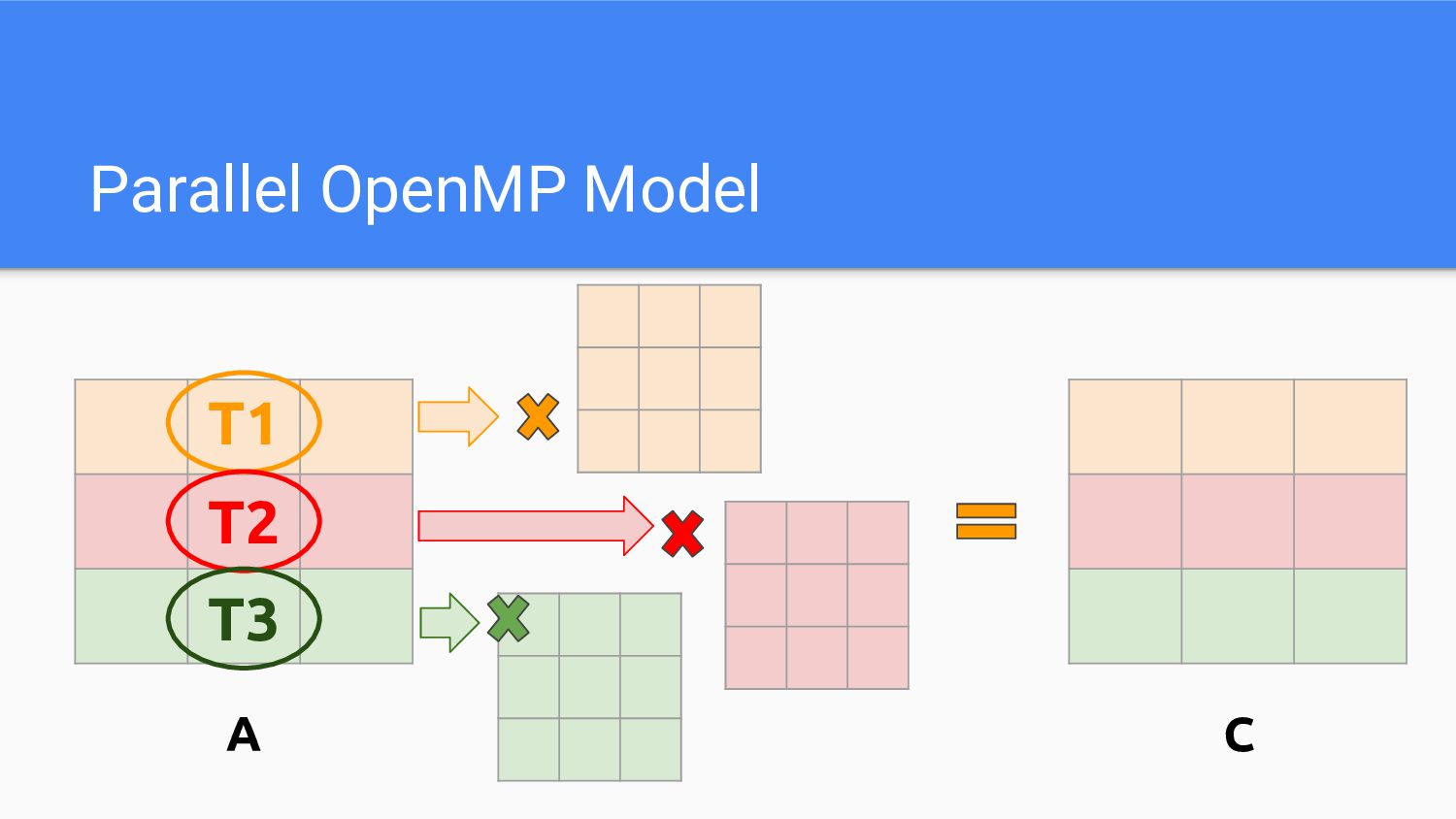
Parallel OpenMP Model A C T1 T2 T3
Parallel OpenMP Model A C T1 T2 T3
Turing - Processor - 4 x Intel Xeon X7550 Nehalem
- 32 physical cores - HyperThreading - Memory - 128GB DDR3 - GPPD-UFRGS
Version: normal_seq for(i=0;i < size; i++) { for(j=0;j < size;
j++) { tmp=0; for(k=0; k < size; k++) tmp = tmp + A[i][k] * B[k][j]; C[i][j] = tmp; } }
Version: normal_par #pragma omp parallel for private(i,j,k,tmp) for(i=0;i < size;
i++) { for(j=0;j < size; j++) { tmp=0; for(k=0; k < size; k++) tmp = tmp + A[i][k] * B[k][j]; C[i][j] = tmp; } }
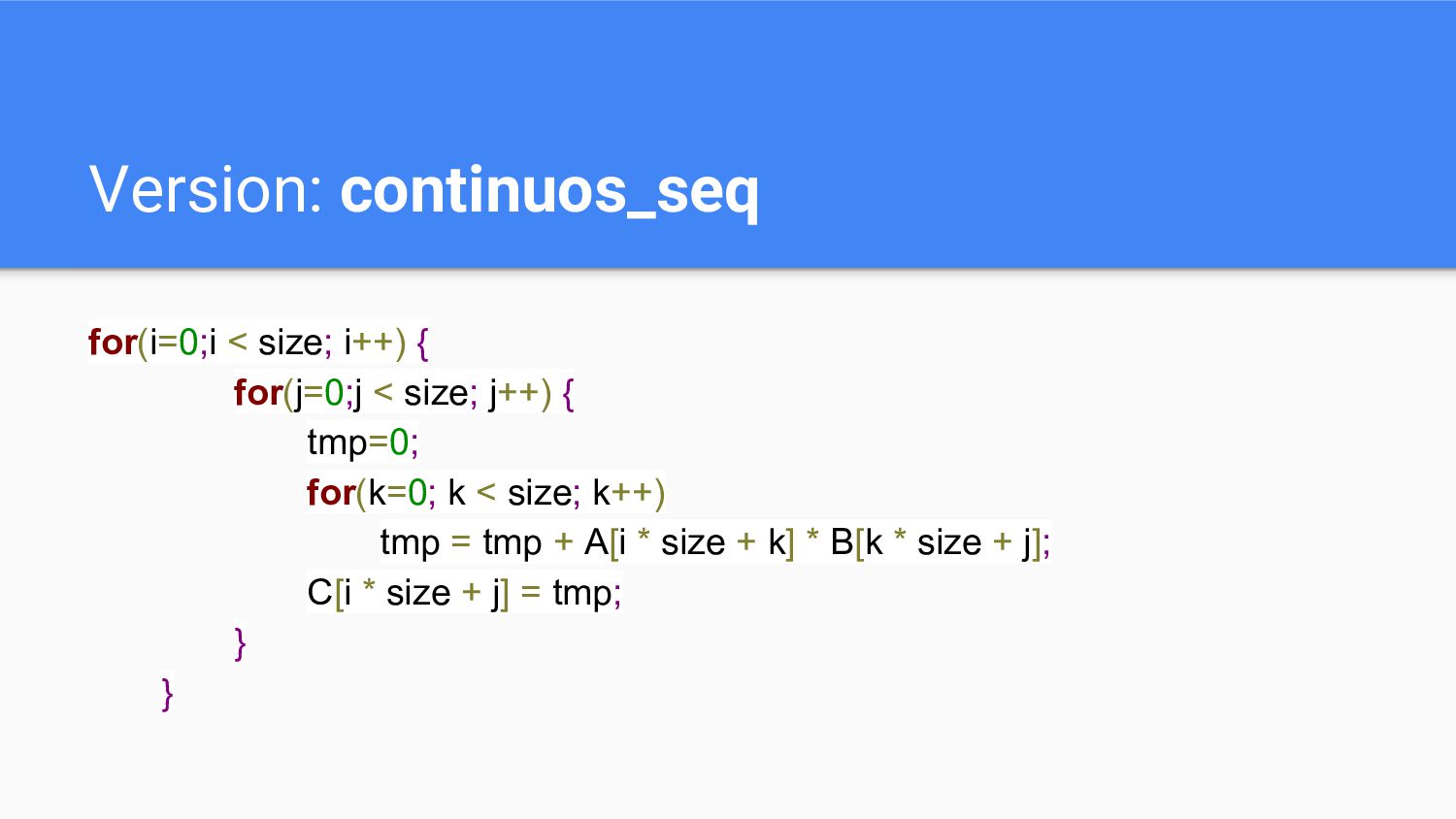
Version: continuos_seq for(i=0;i < size; i++) { for(j=0;j < size;
j++) { tmp=0; for(k=0; k < size; k++) tmp = tmp + A[i * size + k] * B[k * size + j]; C[i * size + j] = tmp; } }
Version: continuos_par #pragma omp parallel for private(i,j,k,tmp) for(i=0;i < size;
i++) { for(j=0;j < size; j++) { tmp=0; for(k=0; k < size; k++) tmp = tmp + A[i * size + k] * B[k * size + j]; C[i * size + j] = tmp; } }
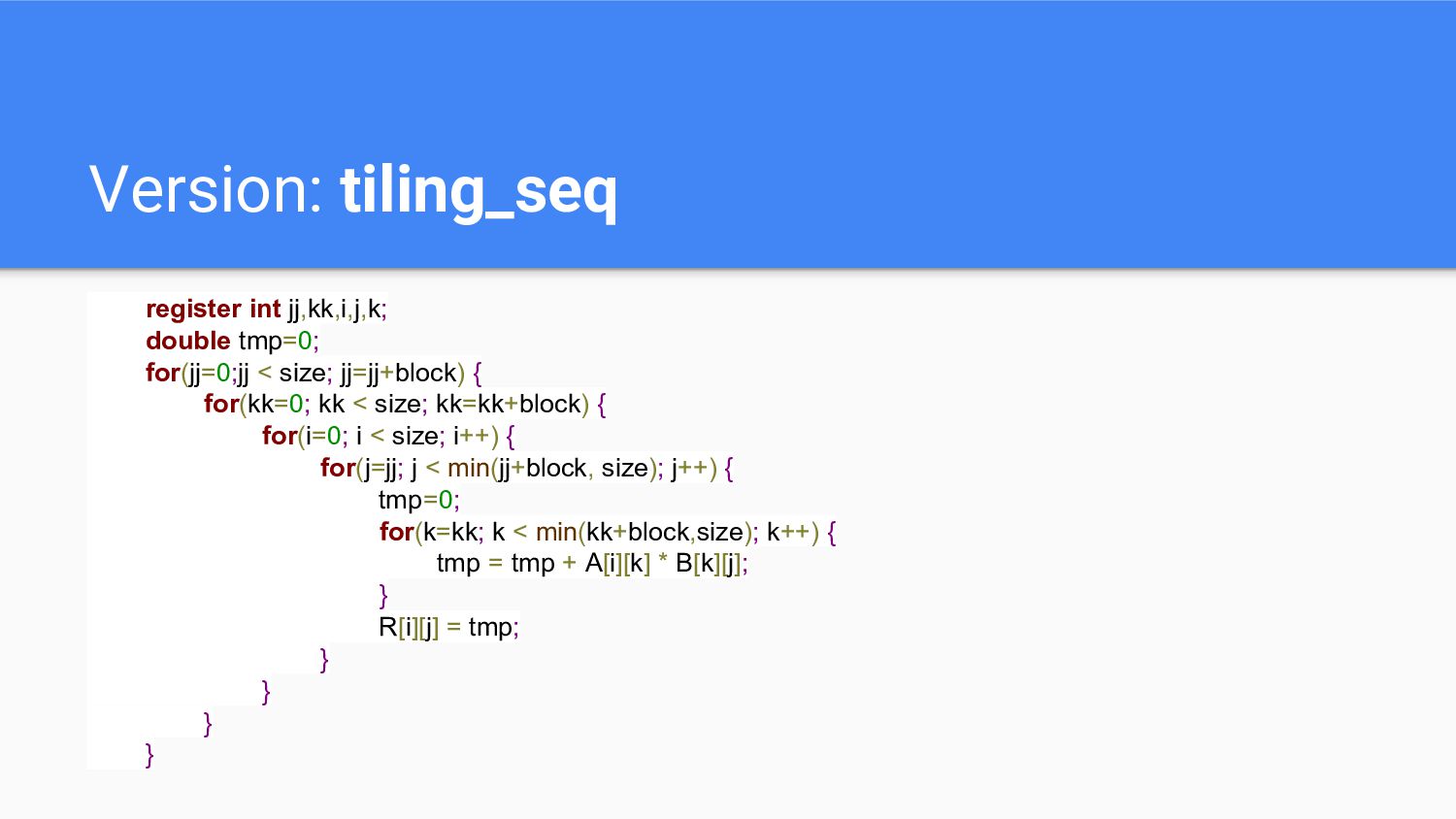
Version: tiling_seq register int jj,kk,i,j,k; double tmp=0; for(jj=0;jj < size;
jj=jj+block) { for(kk=0; kk < size; kk=kk+block) { for(i=0; i < size; i++) { for(j=jj; j < min(jj+block, size); j++) { tmp=0; for(k=kk; k < min(kk+block,size); k++) { tmp = tmp + A[i][k] * B[k][j]; } R[i][j] = tmp; } } } }
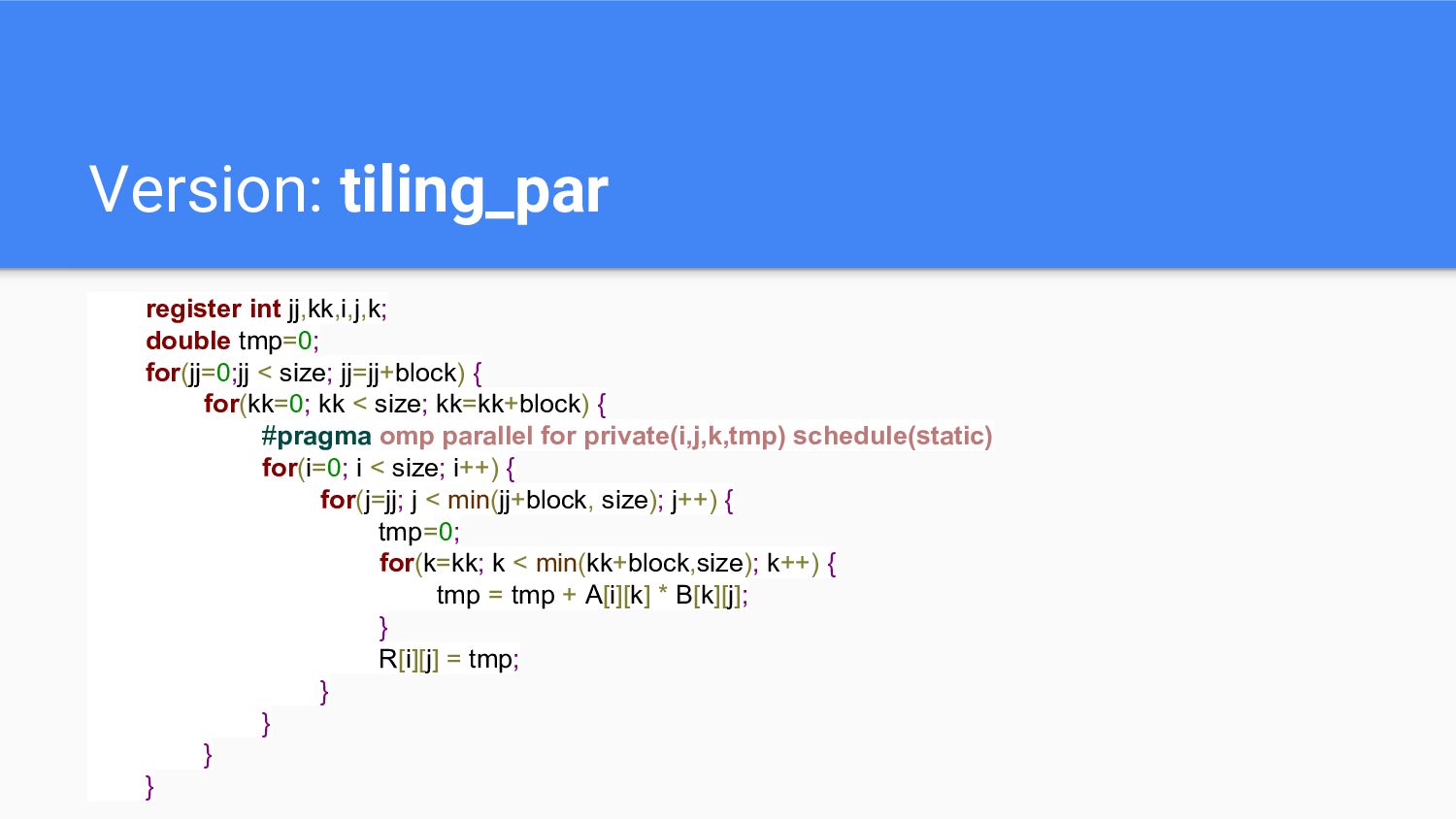
Version: tiling_par register int jj,kk,i,j,k; double tmp=0; for(jj=0;jj < size;
jj=jj+block) { for(kk=0; kk < size; kk=kk+block) { #pragma omp parallel for private(i,j,k,tmp) schedule(static) for(i=0; i < size; i++) { for(j=jj; j < min(jj+block, size); j++) { tmp=0; for(k=kk; k < min(kk+block,size); k++) { tmp = tmp + A[i][k] * B[k][j]; } R[i][j] = tmp; } } } }
Links - Top 500: https://www.top500.org/lists/2018/11/ - Green 500: https://www.top500.org/green500/lists/2018/11/ -
NAS Parallel Benchmark: https://www.nas.nasa.gov/publications/npb.html
Thanks! https://github.com/tido4410/knowledge-transfer-gbmoro.git Gabriel Moro - Matrix Multiplication - OpenMP -
KT, Porto Alegre - November 2018
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}