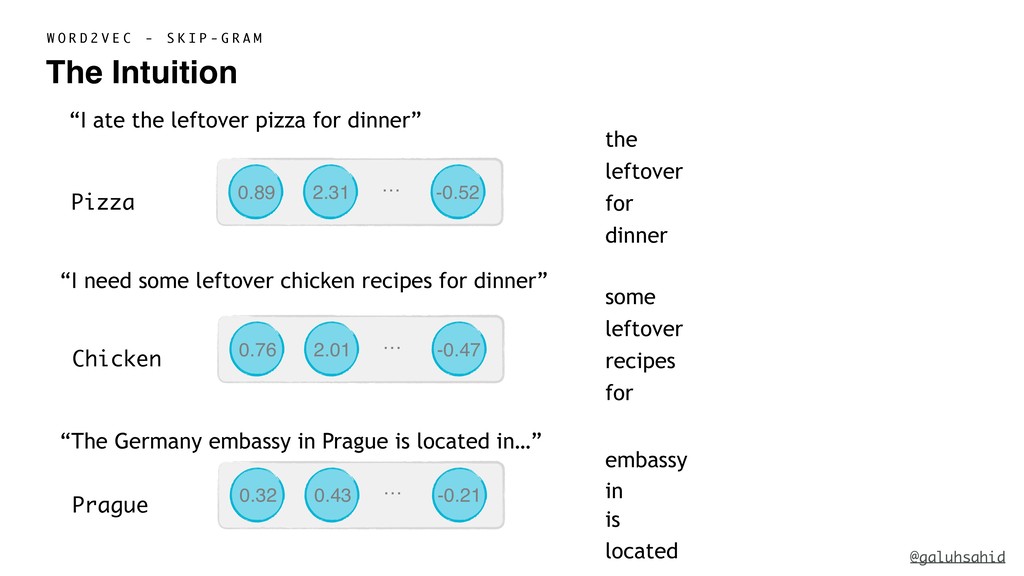
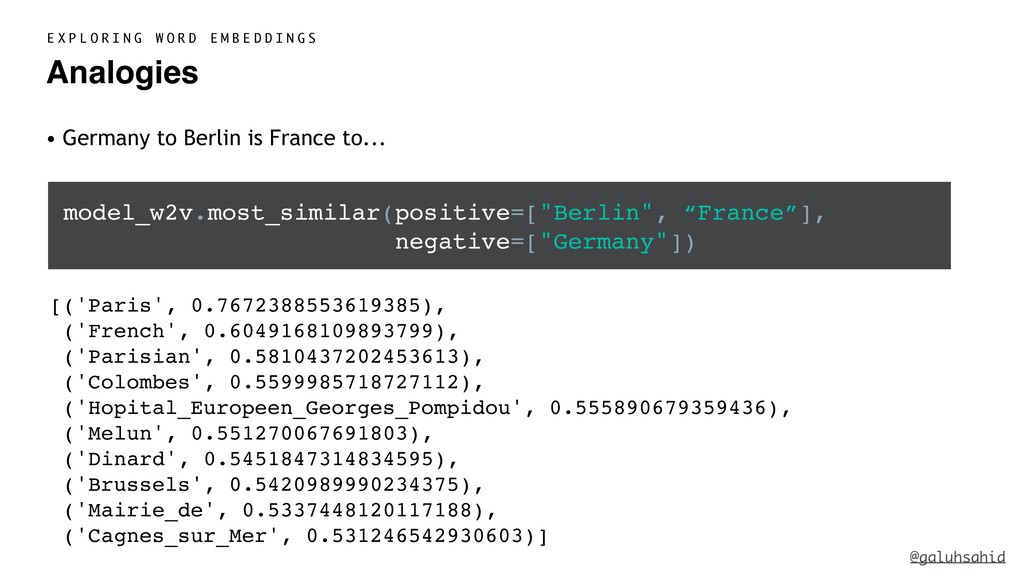
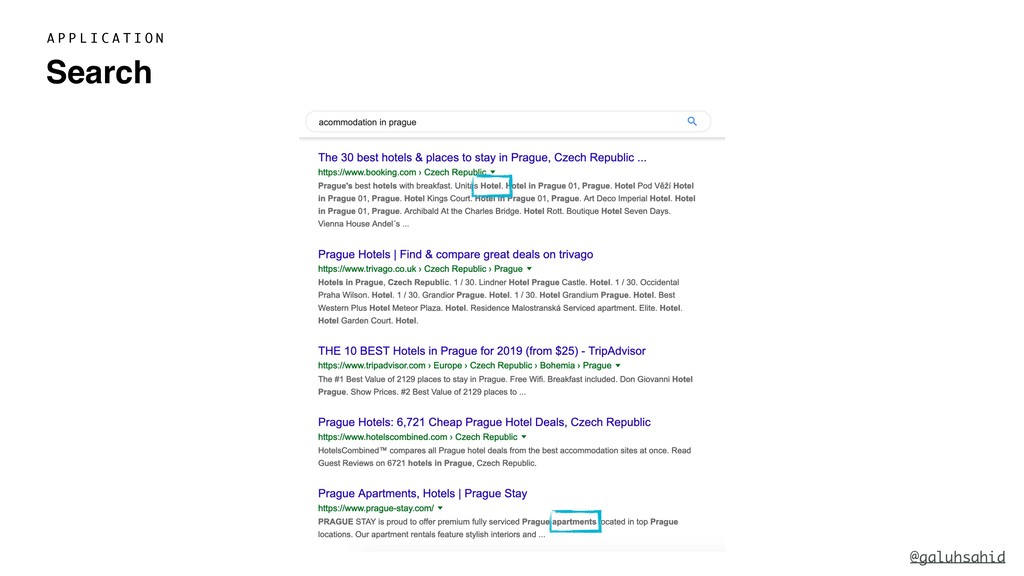
France is to Paris like Czechia is to _______. If I ask you to fill the blank, you would answer "Prague" right away even without me giving a clue such as "the answer is a capital city". Our existing knowledge enables us to determine that France and Paris has a Country - Capital City connection and Czechia's capital city of Prague, so that must be the answer.
However, computers don't know that Prague belongs to the same "category" as Paris and other capital cities unless we tell them so. If we want to get computers to understand human language as well as we do, there are way too many things that we need to teach computers explicitly. Is there a better way?
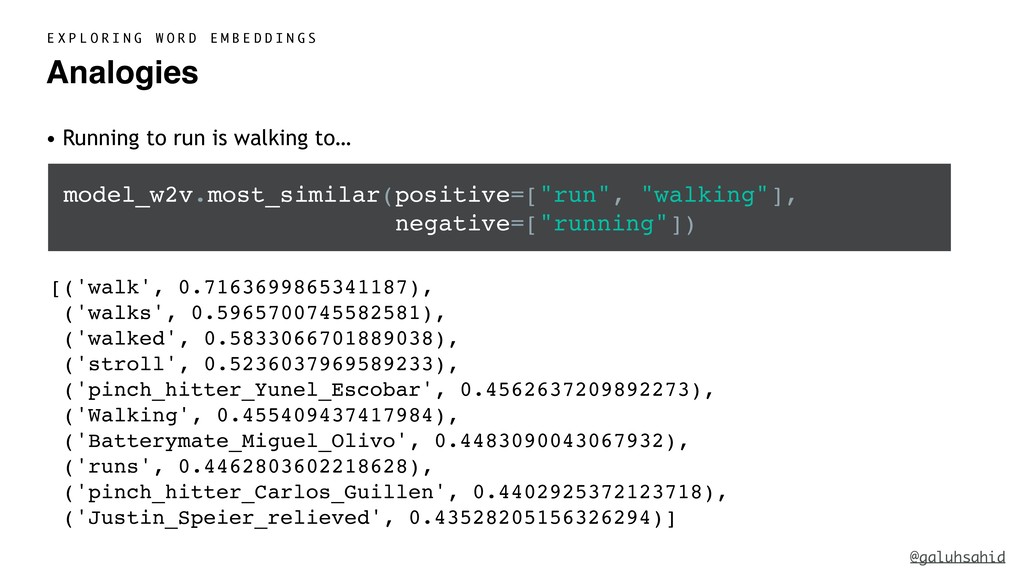
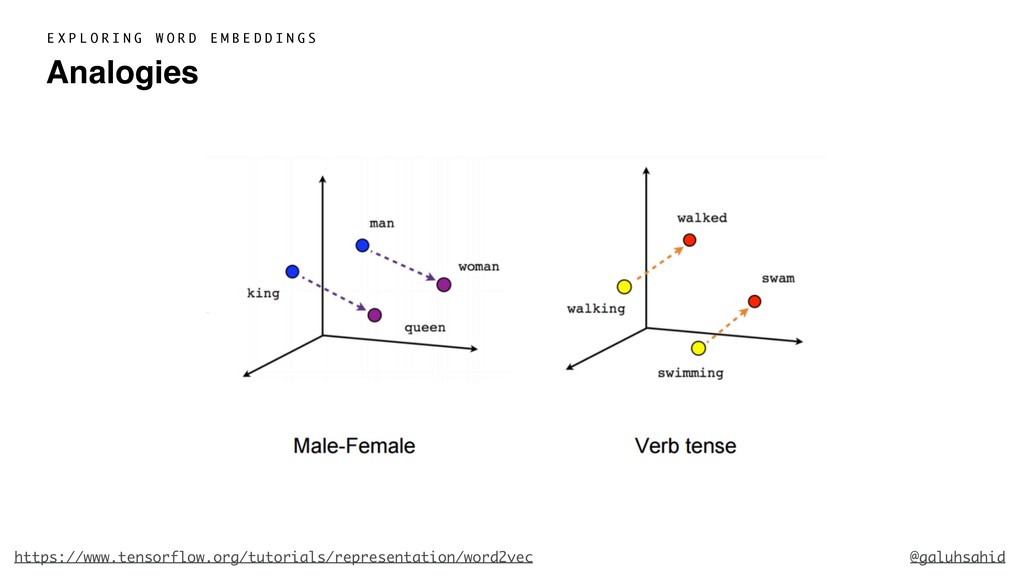
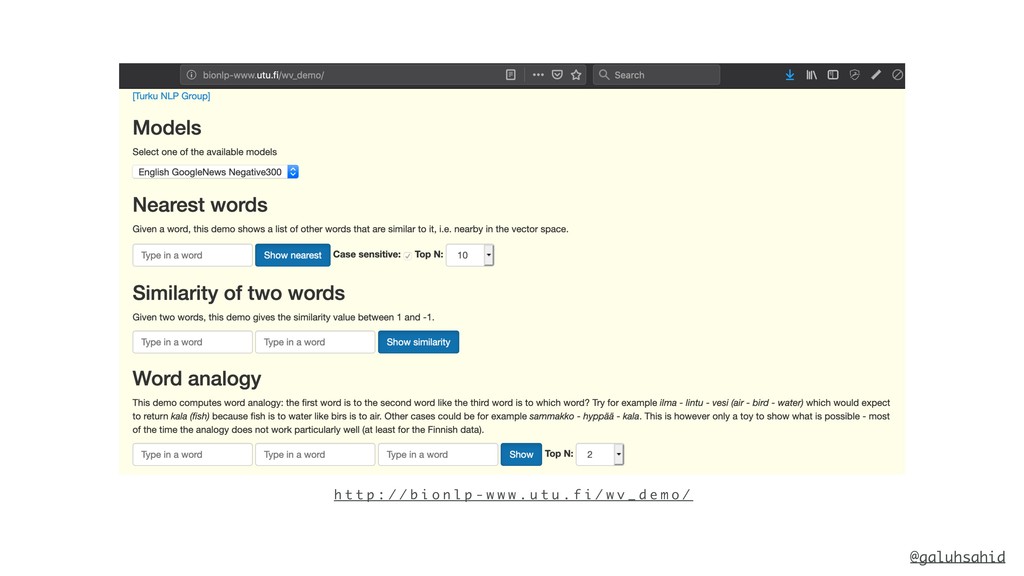
With word embeddings, we represent words by a series of numbers. This opens up a whole new world for computers because now they can understand the context of a word and infer relationships between words using numbers and maths—the language they are proficient in. We'll delve into the details of what word embeddings actually are and why we need them, popular word embedding models, what problems you can solve using word embeddings, and how you can use word embeddings with Python.
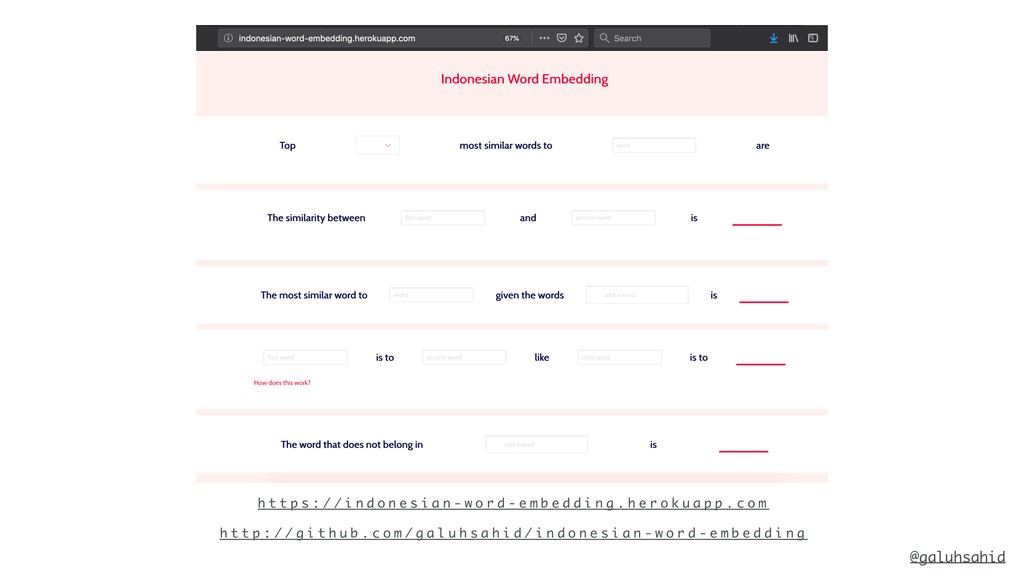
Jupyter Notebook is available here: https://github.com/galuhsahid/intro-to-word-embeddings
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
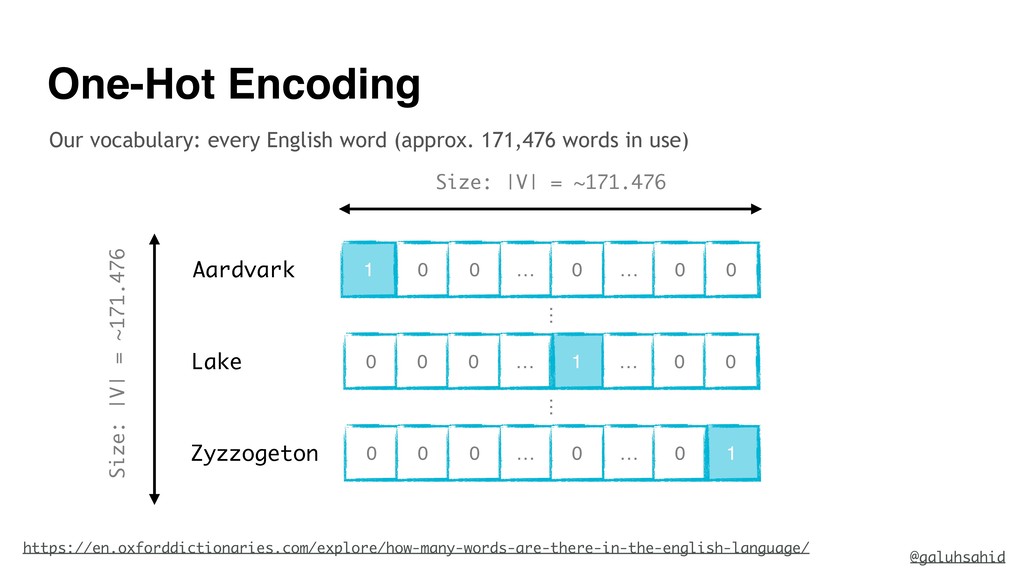
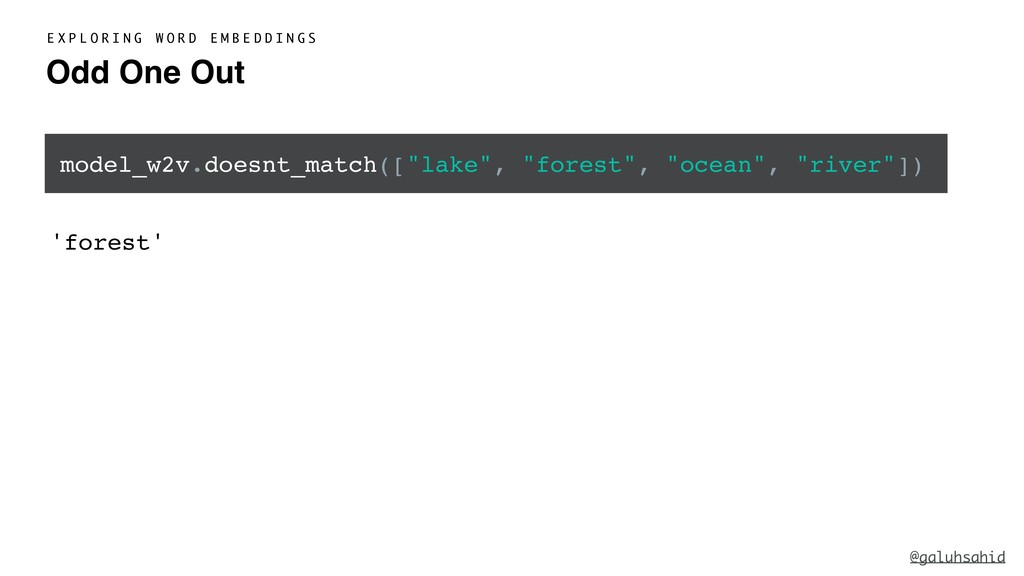
![Lake Ocean River Forest Pizza [large, body, water] [large, area,](https://files.speakerdeck.com/presentations/f7c674d6fbe342b7a599fdded39ab5fc/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
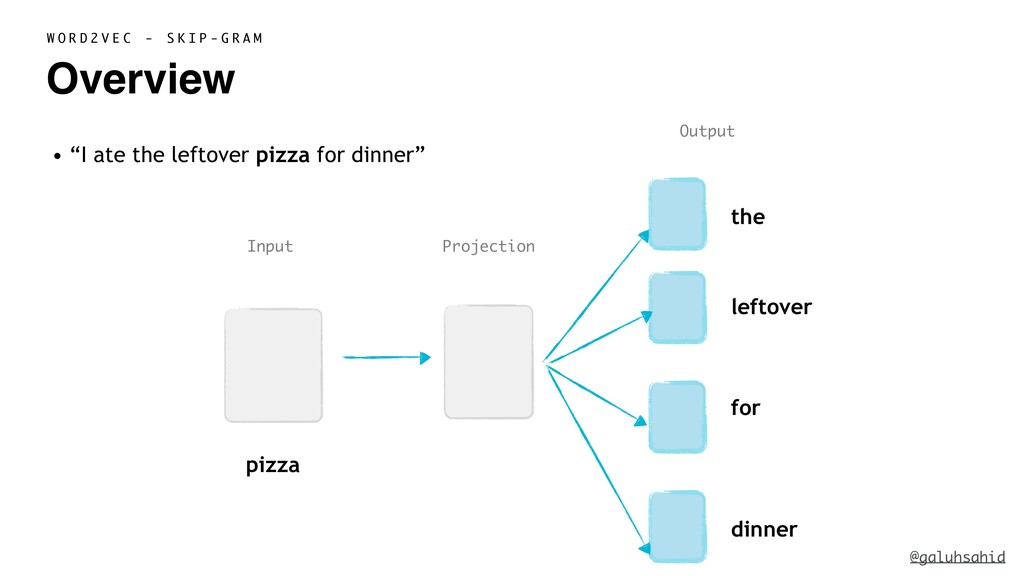{kind=link}
{kind=link}
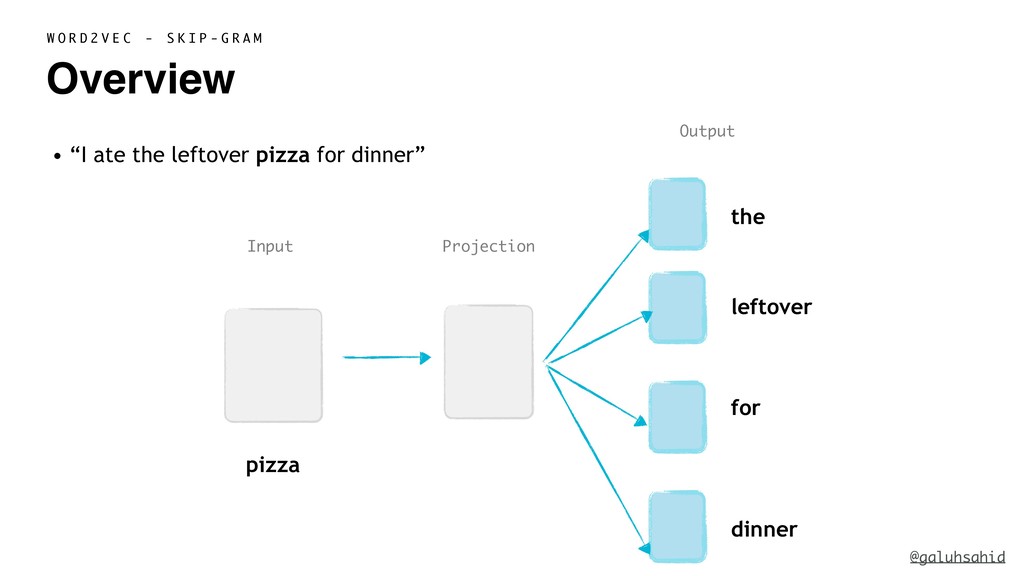{kind=link}
{kind=link}
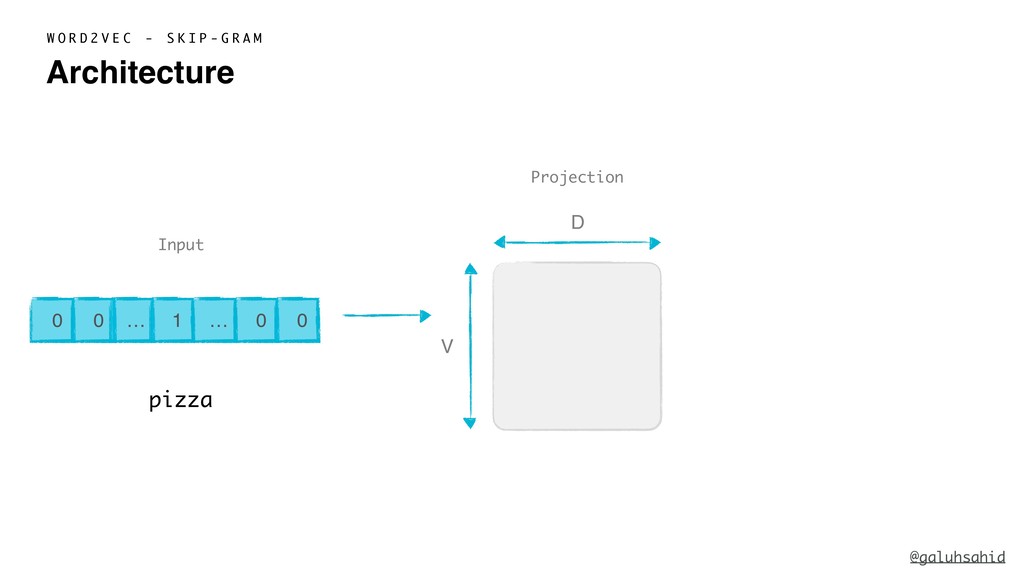{kind=link}
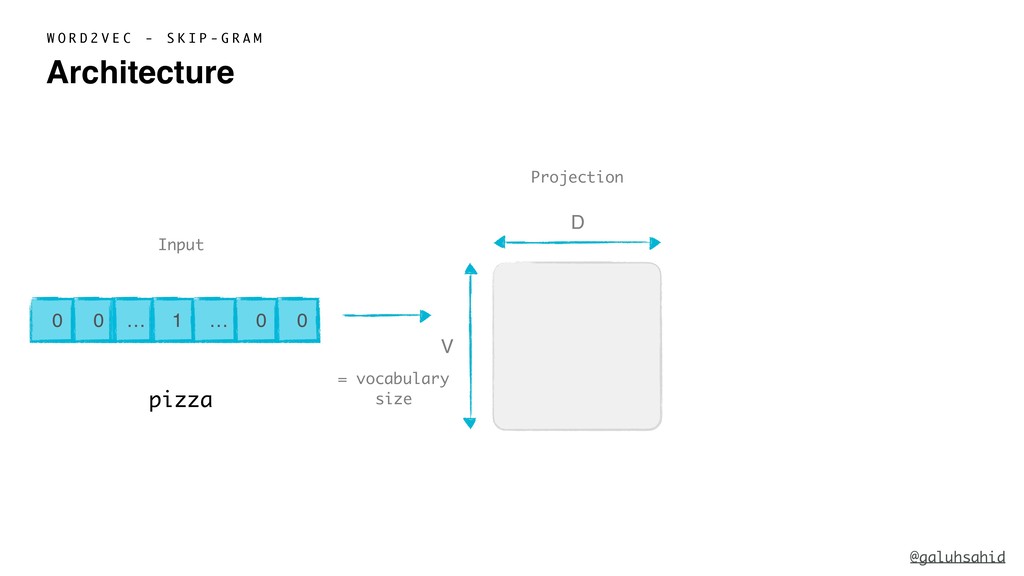{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}