terpilih mendapatkan Hadiah 1 Unit MOBIL Dri Tri Care Dengan PIN Pemenang: br25h99 info: www.gebeyar-3care.tk Da sebenernya makan sama indomie ge cukup aku mah 😂 RAWIT harganya miring, Internetan makin sering! AYO isi ulang kartu AXIS kamu sekarang, pastikan besok ikut promo Rabu RAWIT. Info838. LD328 Fraud Normal Promo
will need to do the following: • Remove HTML tags • Remove extra whitespaces • Convert accented characters to ASCII characters • Remove special characters, punctuations • Remove numbers • Convert slang words • Replace number with tag • … and many more
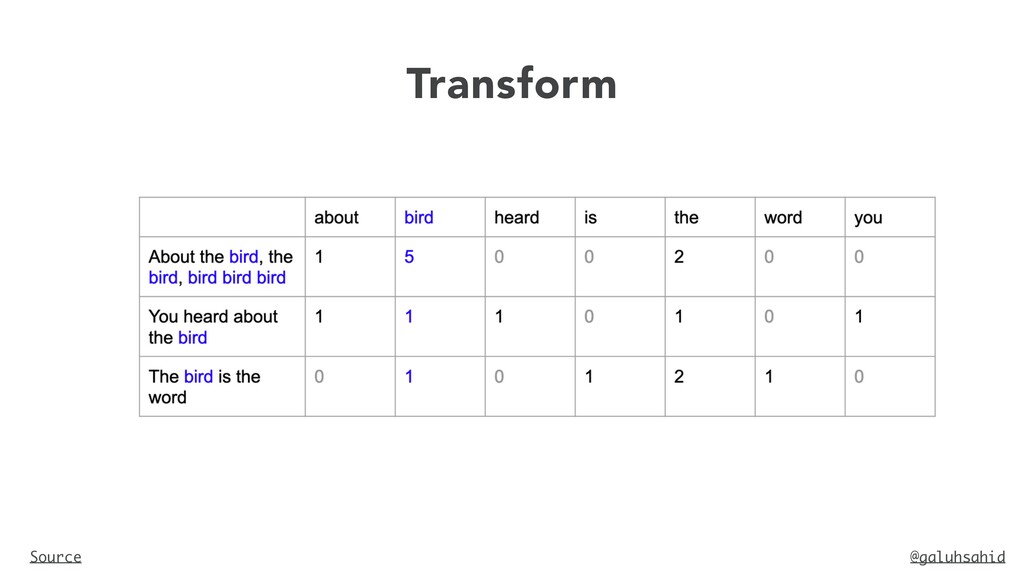
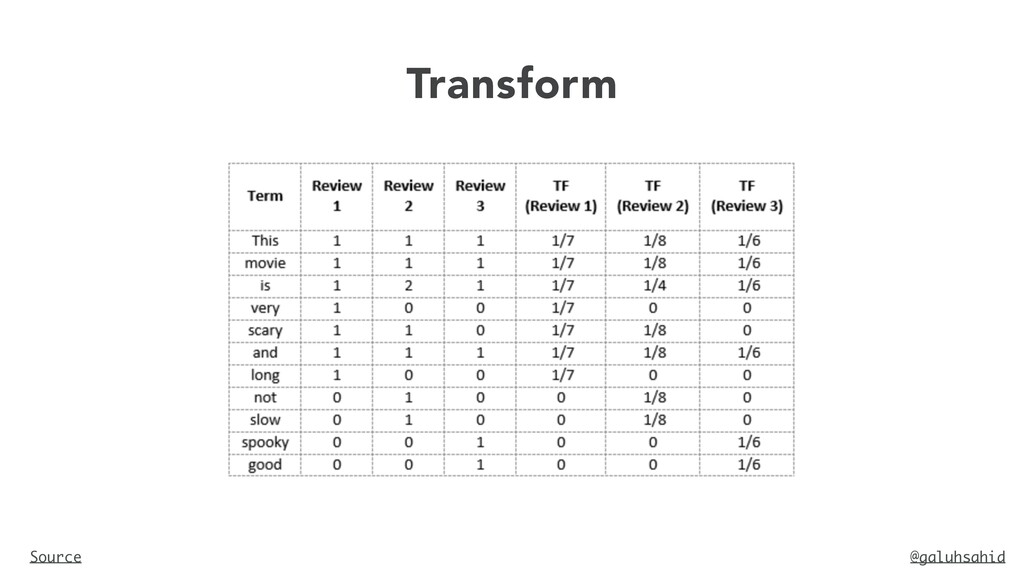
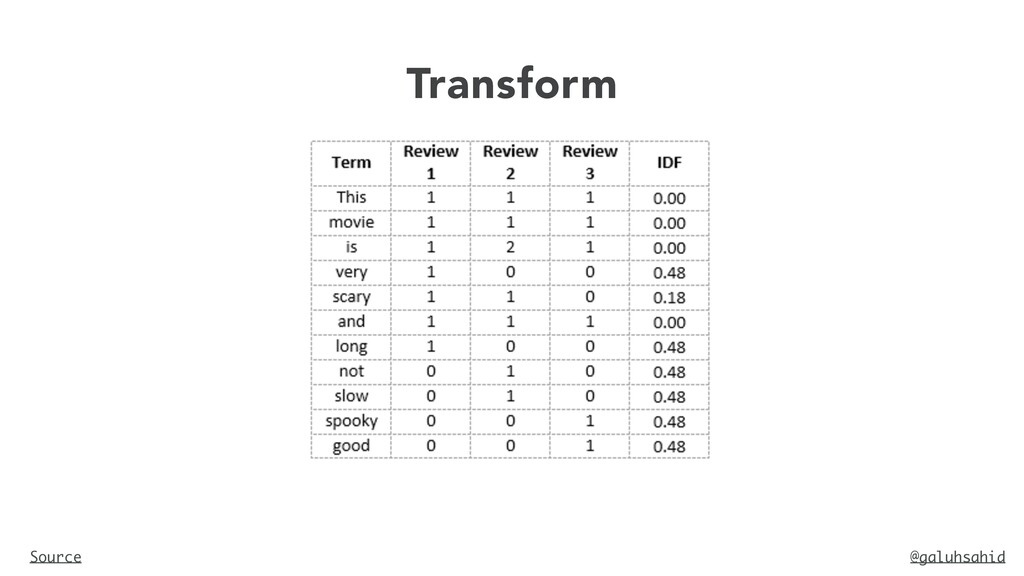
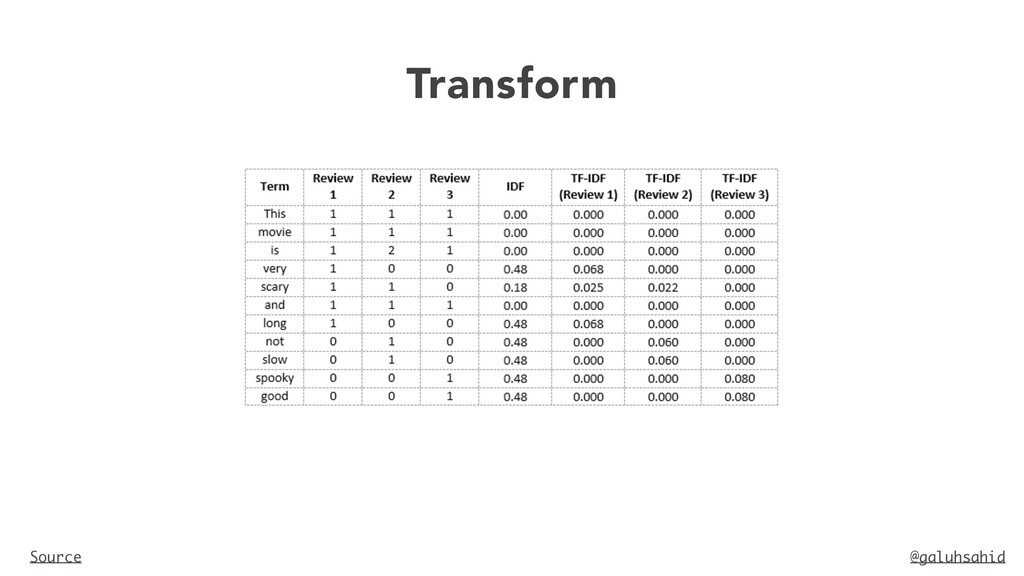
and is slow Vocabulary: ‘This’, ‘movie’, ‘is’, ‘very’, ‘scary’, ‘and’, ‘long’, ‘not’, ‘slow’, ‘spooky’, ‘good’ Number of words in Review 2 = 8 TF for the word ‘this’ = (number of times ‘this’ appears in review 2)/ (number of terms in review 2) = 1/8
large text corpus (like Wikipedia), and then use that model for downstream NLP tasks that we care about (like question answering)” https://github.com/google-research/bert
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}