Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
JPX Tokyo Stock Exchange Prediction Award Cere...
Search
tomo
November 09, 2022
Research
2.7k
2
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
JPX Tokyo Stock Exchange Prediction Award Ceremony 解法総評
JPX Tokyo Stock Exchange Prediction Award Ceremonyで発表した解法総評です。
tomo
November 09, 2022
More Decks by tomo
See All by tomo
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
投資戦略を量産せよ 2 - マケデコセミナー(2025/12/26)
gamella
2
1k
マケデコ プログラミングに頼らないExcelシートと生成AIによる日本株データ分析 発表資料
gamella
2
1.5k
株式のシステムトレード初心者の最初の一歩(評価方法を中心に)
gamella
2
1.1k
アドベントカレンダーのお礼とマーケットAI開発プロジェクトにおけるプロジェクトマネジメントのエッセンス 補講
gamella
1
1k
J-Quants表彰会資料 - 上位入賞者解法総評 #JQuants
gamella
1
3.2k
LDAを利用した予測モデル構築 - J-Quants ニュース分析チャレンジ!発表資料
gamella
1
24k
為替短期予測を支える基盤技術 - データエンジニアミーティング資料
gamella
4
4k
Other Decks in Research
See All in Research
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
290
AIで最適化を解けるか?
mickey_kubo
0
140
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
390
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
590
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
700
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
420
Cross-Media Information Spaces and Architectures
signer
PRO
0
320
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
610
「行ける・行けない表」による地域公共交通の性能評価
bansousha
0
170
ScoreMatchingRiesz for Automatic Debiased Machine Learning and Policy Path Estimation with an Application to Japanese Monetary Policy Evaluation
masakat0
0
300
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.4k
Featured
See All Featured
Exploring anti-patterns in Rails
aemeredith
3
450
Leading Effective Engineering Teams in the AI Era
addyosmani
9
2.2k
A designer walks into a library…
pauljervisheath
211
24k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
Accessibility Awareness
sabderemane
1
160
How to Talk to Developers About Accessibility
jct
2
410
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Ruling the World: When Life Gets Gamed
codingconduct
0
280
Transcript
JPX Tokyo Stock Exchange Prediction Award Ceremony 解法総評 Tomoya Kitayama
STRICTLY CONFIDENTIAL 1
解法総評 Alpacaで入賞者(9位の方は資料が未提出)の手法を確認させていただき、分類を実施致し ました。我々目線で興味深かったアプローチをご紹介させていただきます。 2 解法の種別 該当するユーザー 総評 シンプルなモデル 1位 2位
3位 6位 7位 8位 今回のコンペでもっとも多かった解法。この時期にワー クした特徴量に対して強い相関を持つモデルになって いたと考えております。 完全に問題をハック 4位 Kaggleというプラットフォームの特性を上手く利用した アプローチ。正直、これはやられたと思いました。 クオンツ的なアプローチ 5位 10位 日本株のマーケットに対する新しいアプローチとして評 価できる手法です。今回は重点的に紹介します。また、 今後マケデコのイベントでもとりあげてみたいと考えて おります。
コンペの問題設定 1. モデルは毎営業日(t)に、その営業日までの終値(C_t)等のデータを入力データとして、翌営 業日の終値(C_t+1)から翌々営業日の終値(C_t+2)までの変化率(r_t+1)の上位200銘柄と 下位200銘柄を予測します。 r_t+1 = (C_t+2 - C_t+1)
/ (C_t+1) 2. 予測した上位200銘柄に対して1から200位までにそれぞれ2から1の線形のウェイトをそれ ぞれの変化率に対して掛けたものの総和を計算しこれをS_upとします。 3. 予測した下位200銘柄に対して下位1から200位までにそれぞれ2から1の線形のウェイトを それぞれの変化率に対して掛けたものの総和を計算しこれをS_downとします。 4. S_upからS_downを引いた結果をR_dayとし「デイリースプレッドリターン」と呼ぶことに します。 5. デイリースプレッドリターンをpublic/private期間中、毎営業日計算し、当該期間の時系列 として取得します。デイリースプレッドリターンの時系列の平均/標準偏差をスコアとしま す。 a. スコア計算式(xはpublic/private期間の営業日): Average(R_day1-dayx) / STD(R_day1-dayx) 6. private期間の最大のスコアを獲得したカグラーが勝利となります。 3
シンプルなモデルのアプローチの紹介 今回上位入賞のモデルは総じてシンプルなモデルが多かった。本イベントで紹介されなかったいくつか の解法を紹介します。 7位の方の特徴量 - 33業種ごとにモデルを学習させた - 特徴量は前営業日のOpen/High/Low/Closeのみ 33業種ごとにモデルを作成。特徴量は足元のOHLCのみ。学習するのか興味深いアプローチでちょっと 掘ってみたいと感じました。
8位の方の特徴量 - 前営業日のOpenCloseのリターン - 10/30/50営業日のボラティリティ - 3/5/10営業日のCloseのSMA - 3/5/10/30営業日のReturn Inportanceが高いのは、3/5/10/30営業日のReturnと前営業日のOpenClose Return。 なお、実装は非常にこなれており、かなり試行錯誤の結果、このモデルに到達したことがわかります。 4
問題をハックするアプローチ 本日も発表のあった4位のddmチームの 解き方 メトリクスに対してもっとも周期性が安 定している特徴量を選択し、モデルを2 つ提出できるというルールから、その特 徴量の昇順と降順を提出するというアプ ローチは、説明を聞いたときに完全に問 題をハックされたと感心しました。 また、配当のデータの重要性に気づくな
ど、問題としても重要なポイントを認識 しておりました(問題作成時に、配当調 整済みリターンはあまりにも複雑になる ので生成をあきらめました) 5
クオンツ的に問題を理解するアプローチの紹介 金融クオンツとして25年のキャリアを 持ち、多くのKaggleの金融コンペで入 賞を果たす モデルは極めてシンプルながらも深い考 察によって構築されており、どのような 局面においてもワークするように設計さ れている(詳細は次ページ) なぜこのモデルがワークするかのロジッ クが明確に構築されており、オプション
データの貢献の可能性も指摘するなど、 入賞後に提出された資料の完成度が非常 に高い 6
クオンツモデルの概要 モデル: 勾配ブースト決定木 目的関数: 数式1のスコアを数式2に改変して利用することが最も最適なスコアとなることを発見 特徴量 - 銘柄コード - 株価自体のクロスセクションなランキング
- 各銘柄の前2日間のリターン(これがもっとも優位な特徴量)、そのユニバースの平均 - 長期のリターン・ラグ(131取引日のヒストリカル価格リターン、25日ラグ)、そのユニバースの平均 - 過去11取引日の一日平均出来高をクロスセクションでランキング - 過去231取引日の日次リターンの標準偏差 トレーニング方法 - 1年分の学習データで次の1ヶ月を予測この1ヶ月のデータを可能な 限り多く作り、各月のコンペのスコアを計測 - 特徴量をパラメータにして、もっとも安定的に高い平均スコアを出 すモデルを選択。アンサンブルは顕著な効果は観測されなかった モデルの特徴 - 学習時にスコアの両端(top250/bottom250)のみを利用、これがもっとも効果が高いトリックになった - オプションデータのインプライド・ボラティリティは市場の平均だったため上手く特徴量として活用できなかっ たが、ここがまさに掘る価値があるところだった 7 数式1 数式2
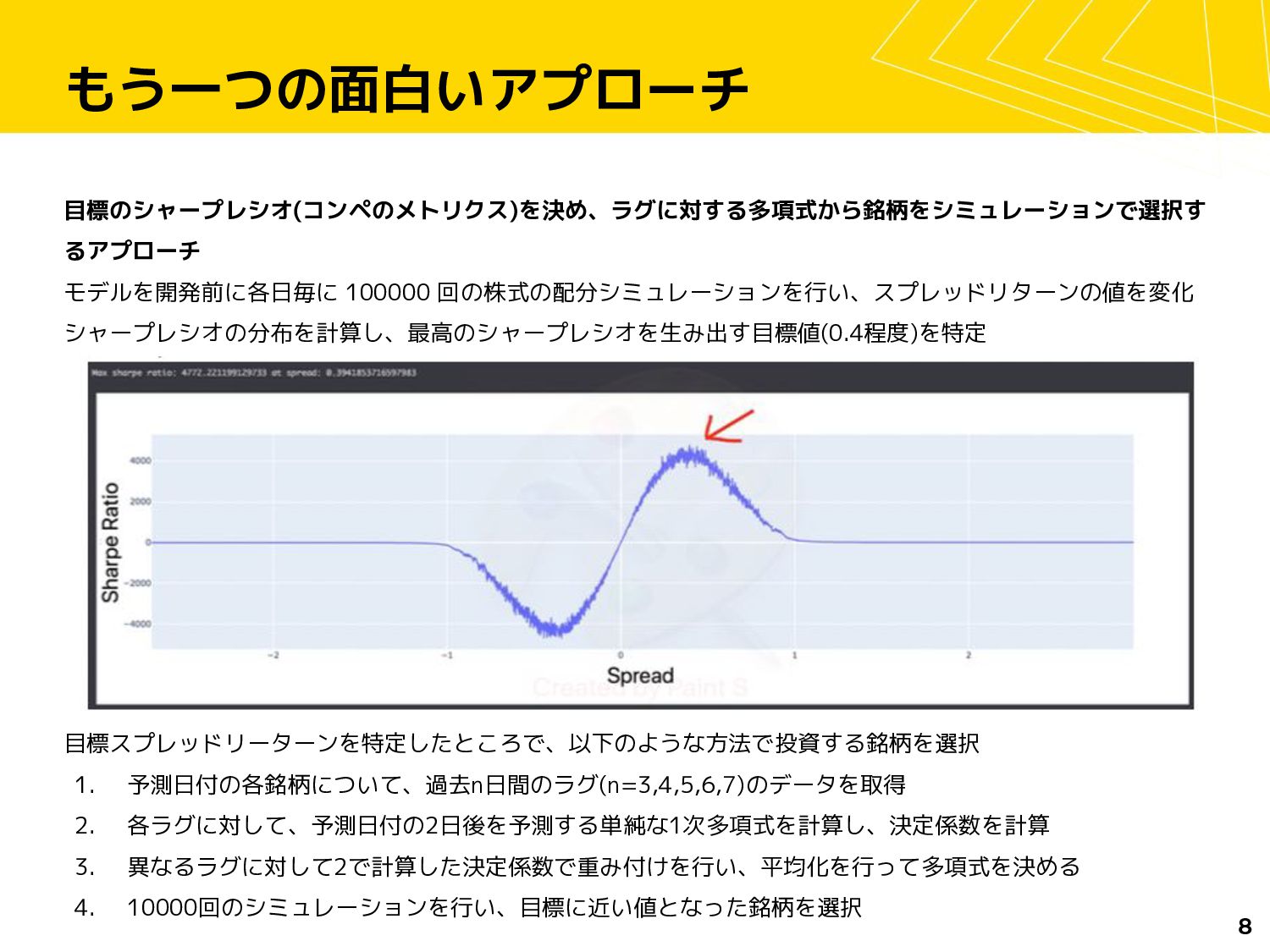
もう一つの面白いアプローチ 目標のシャープレシオ(コンペのメトリクス)を決め、ラグに対する多項式から銘柄をシミュレーションで選択す るアプローチ モデルを開発前に各日毎に 100000 回の株式の配分シミュレーションを行い、スプレッドリターンの値を変化 シャープレシオの分布を計算し、最高のシャープレシオを生み出す目標値(0.4程度)を特定 8 目標スプレッドリーターンを特定したところで、以下のような方法で投資する銘柄を選択 1.
予測日付の各銘柄について、過去n日間のラグ(n=3,4,5,6,7)のデータを取得 2. 各ラグに対して、予測日付の2日後を予測する単純な1次多項式を計算し、決定係数を計算 3. 異なるラグに対して2で計算した決定係数で重み付けを行い、平均化を行って多項式を決める 4. 10000回のシミュレーションを行い、目標に近い値となった銘柄を選択
最後に 今回の問題はトレードに限りなく近い条件、かつ再現性のある問題を設定することに苦心 しました。 結果として、多様なアプローチで問題を解くことが確認できて非常に有意義なコンペとな りました。 また、Late Submissionが開放されており、他のテクニックなどを駆使して、問題を改め て解いてみることも出来ます。ぜひ、すでに解法が公開されているものもありますので、 そちらをご覧になりつつ、最後に改めてチャレンジしていただければ幸いです。 今後もJ-Qunatsを何卒よろしくおねがいします!
9
Thank You! STRICTLY CONFIDENTIAL 10
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}