Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Glueで作るセキュリティ分析基盤 / jawsug_bgnr46lt
Search
KoheiGamo
February 23, 2022
Technology
910
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Glueで作るセキュリティ分析基盤 / jawsug_bgnr46lt
KoheiGamo
February 23, 2022
More Decks by KoheiGamo
See All by KoheiGamo
AWS re:Invent2025最新動向まとめ(NRIグループre:Cap 2025)
gamogamo
0
270
20240825_bedrock_helpdesk_jp.pdf
gamogamo
0
290
How to Streamline Help Desk Operations and Improve RAG Response Accuracy with Amazon Bedrock
gamogamo
0
180
LT_AWSConsoleToCode.pdf
gamogamo
0
110
Other Decks in Technology
See All in Technology
2026 TECHFRESH 畢業分享會 - 開發日常大解密!從領域驅動到企業級上線
line_developers_tw
PRO
0
610
AIを「創る」と「使う」の循環 — HRテックが実践するリアルなAI組織実装
taketo957
0
1.9k
2026TECHFRESH畢業分享會 - AI 時代的人生存檔點
line_developers_tw
PRO
0
620
Building applications in the Gemini API family.
line_developers_tw
PRO
0
2.7k
やさしいA2A入門
minorun365
PRO
10
1.6k
脆弱性対応、どこで線を引くか
rymiyamoto
0
330
個人最適 から 全体最適 へ AI情報共有会・AIギルド・AI-DLC で進める カンリーの組織展開
rfdnxbro
0
2.1k
AI駆動開発が変える、大規模開発の前提 ーHuman in the Loop から Human on the Loop へ / AIE2026
visional_engineering_and_design
30
23k
ルールやカスタム機能、どう活かす?ハンズオンで体感するIBM Bobの出力コントロール
muehara
1
110
手塩にかけりゃいいってもんじゃない
ming_ayami
0
190
Microsoft Build Keynoteふりかえり
tomokusaba
0
120
Socrates × Looker 〜セマンティックレイヤーで進化するデータ分析エージェント〜
hanon52_
3
2k
Featured
See All Featured
Conquering PDFs: document understanding beyond plain text
inesmontani
PRO
4
2.8k
It's Worth the Effort
3n
188
29k
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
The AI Search Optimization Roadmap by Aleyda Solis
aleyda
1
5.9k
HDC tutorial
michielstock
2
700
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
140
Embracing the Ebb and Flow
colly
88
5.1k
Optimizing for Happiness
mojombo
378
71k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
How to build a perfect <img>
jonoalderson
1
5.6k
Automating Front-end Workflow
addyosmani
1370
210k
Transcript
Glueで作るセキュリティ分析基盤 〜セキュリティ診断レポートを作ってみた話〜 株式会社野村総合研究所 蒲 晃平 JAWS-UG 初心者支部#46 AWS Builders Online
Series recap4
1 自己紹介 蒲 晃平 ガモウ コウヘイ 野村総合研究所所属 新卒入社5年目/AWS歴10か月 Career Private
- 2017年 プライベートクラウドの運営/開発 ✓ IaaS・PaaS (OracleDB) ✓ SRE ✓ 自動化 (仮想マシンやストレージボリューム作成) - 2021年 AWS活用推進 ✓ AWS案件の技術支援 ✓ セキュリティ対策サービスの運営/開発 (本日のトピック) #キャンプ初心者 #密回避
2 今日のお話 • 大量のAWSアカウントのセキュリティ設定状況を診断し、 その結果を定期的にレポートとして出力する機能をGlueを使って実装 • 上記の機能をサービスとして社内に展開 • このサービスにより、レポートを受け取ったアカウント管理者は セキュリティ設定状況を俯瞰でき、セキュリティ対策をより計画的に実施出来るようになった
Glueを使った一つの事例として上記の話を紹介します 業務で取り組んだこと
3 アジェンダ なぜ作ったか? 作ったもの Glueの使用感 まとめ
事業内容やニーズから、定期レポート機能を 作った理由を説明 アーキテクチャや用いたGlueサービスの説明や サービスの選択理由を説明 使ってみてわかったGlueの実践知を共有 本日の内容のまとめと振り返り
4 なぜ作ったか?
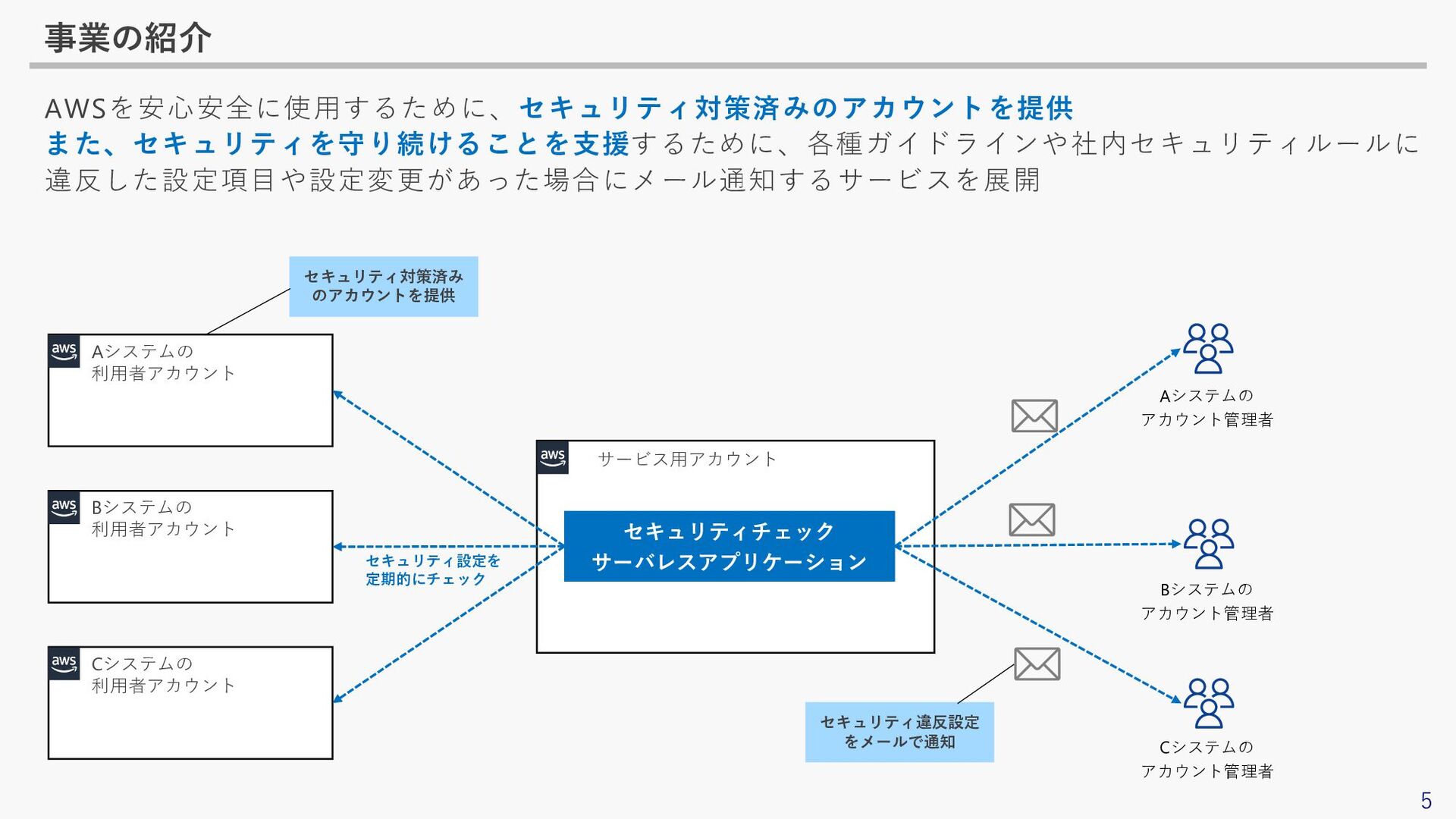
5 事業の紹介 AWSを安心安全に使用するために、セキュリティ対策済みのアカウントを提供 また、セキュリティを守り続けることを支援するために、各種ガイドラインや社内セキュリティルールに 違反した設定項目や設定変更があった場合にメール通知するサービスを展開 サービス用アカウント Aシステムの 利用者アカウント Bシステムの 利用者アカウント
Cシステムの 利用者アカウント セキュリティ設定を 定期的にチェック セキュリティチェック サーバレスアプリケーション セキュリティ対策済み のアカウントを提供 セキュリティ違反設定 をメールで通知 Aシステムの アカウント管理者 Bシステムの アカウント管理者 Cシステムの アカウント管理者
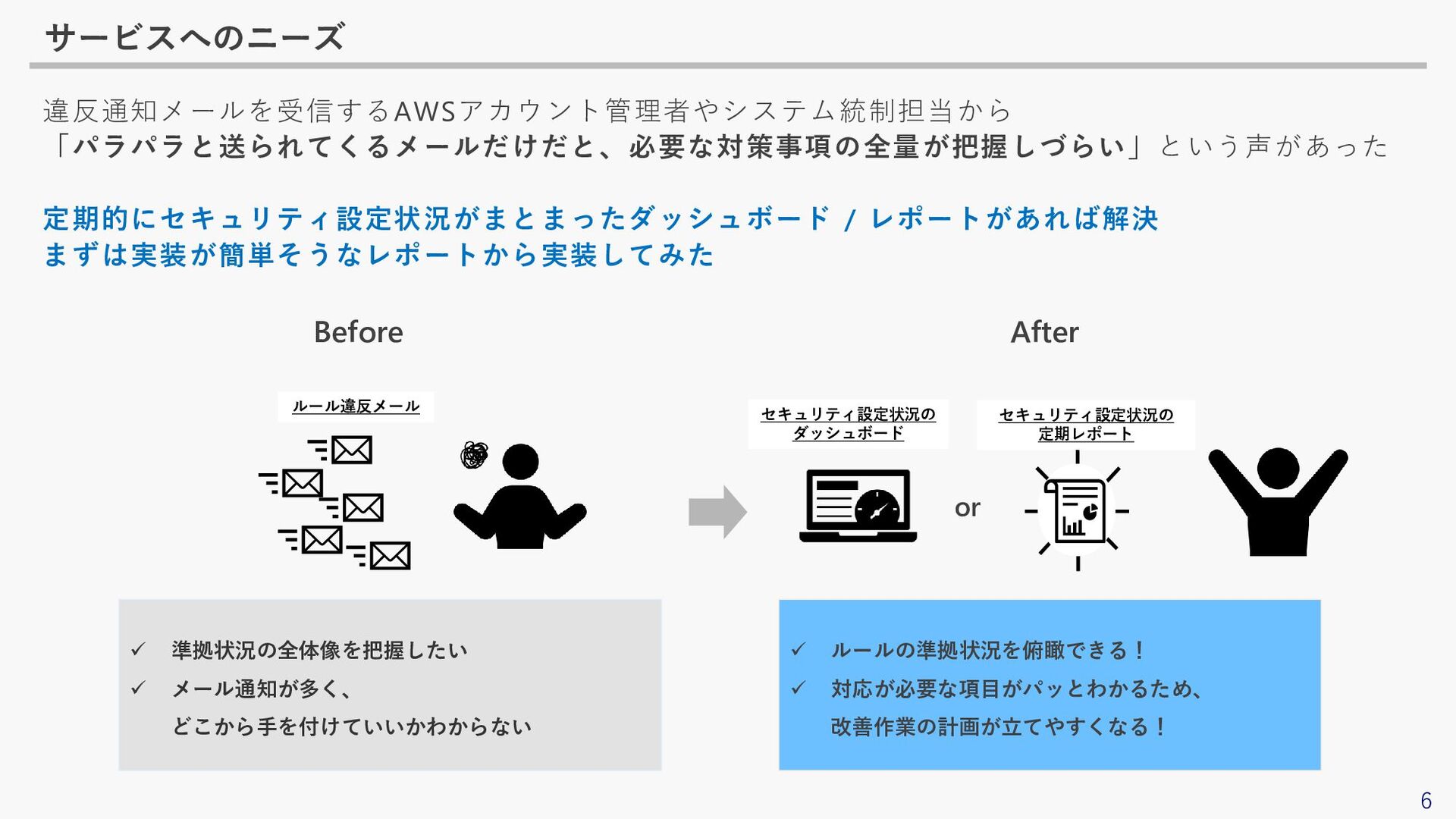
6 サービスへのニーズ 違反通知メールを受信するAWSアカウント管理者やシステム統制担当から 「パラパラと送られてくるメールだけだと、必要な対策事項の全量が把握しづらい」という声があった 定期的にセキュリティ設定状況がまとまったダッシュボード / レポートがあれば解決 まずは実装が簡単そうなレポートから実装してみた ✓ 準拠状況の全体像を把握したい
✓ メール通知が多く、 どこから手を付けていいかわからない ✓ ルールの準拠状況を俯瞰できる! ✓ 対応が必要な項目がパッとわかるため、 改善作業の計画が立てやすくなる! セキュリティ設定状況の 定期レポート ルール違反メール Before After セキュリティ設定状況の ダッシュボード or
7 作ったもの
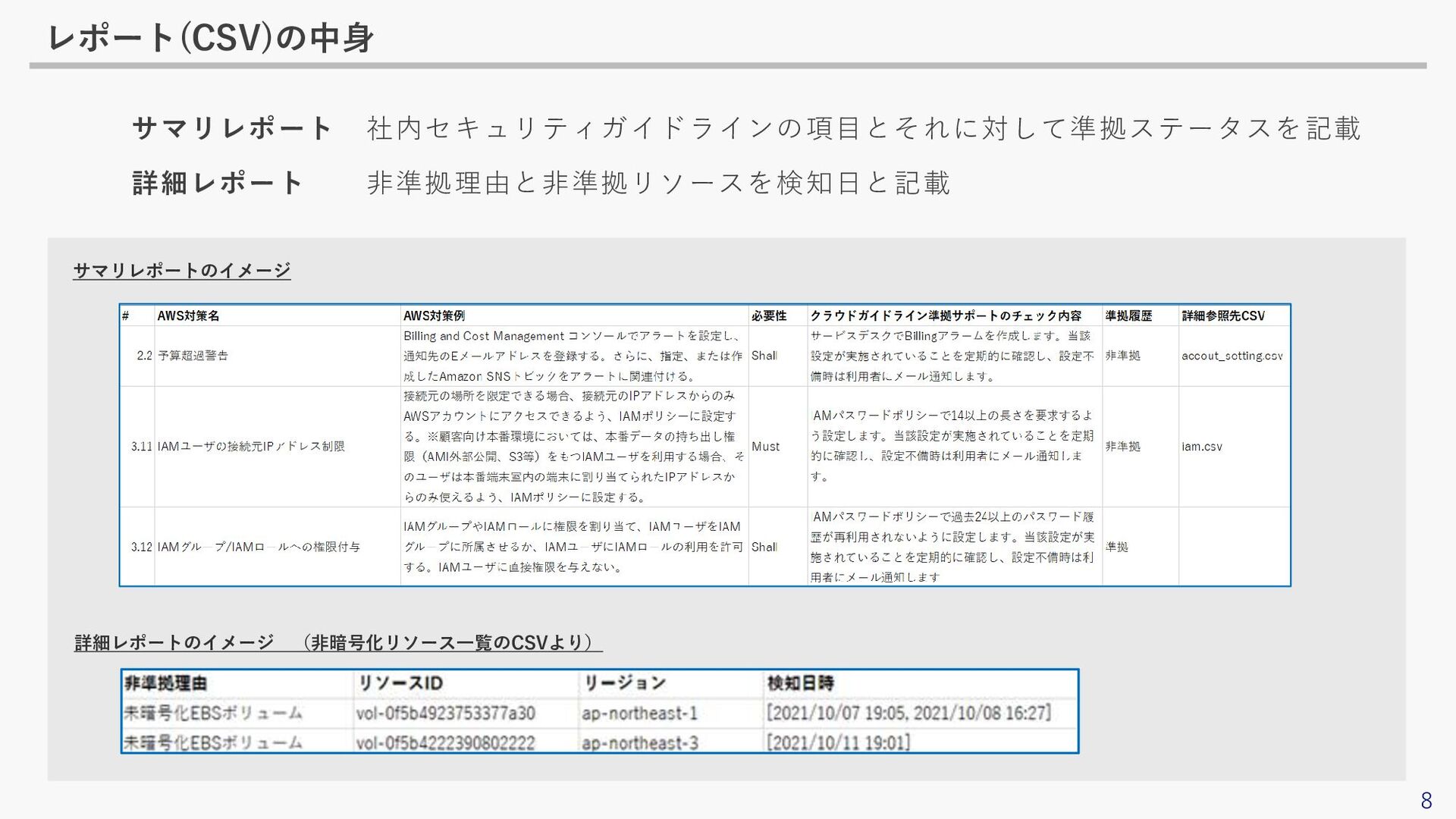
8 レポート(CSV)の中身 サマリレポート 社内セキュリティガイドラインの項目とそれに対して準拠ステータスを記載 詳細レポート 非準拠理由と非準拠リソースを検知日と記載 サマリレポートのイメージ 詳細レポートのイメージ (非暗号化リソース一覧のCSVより)
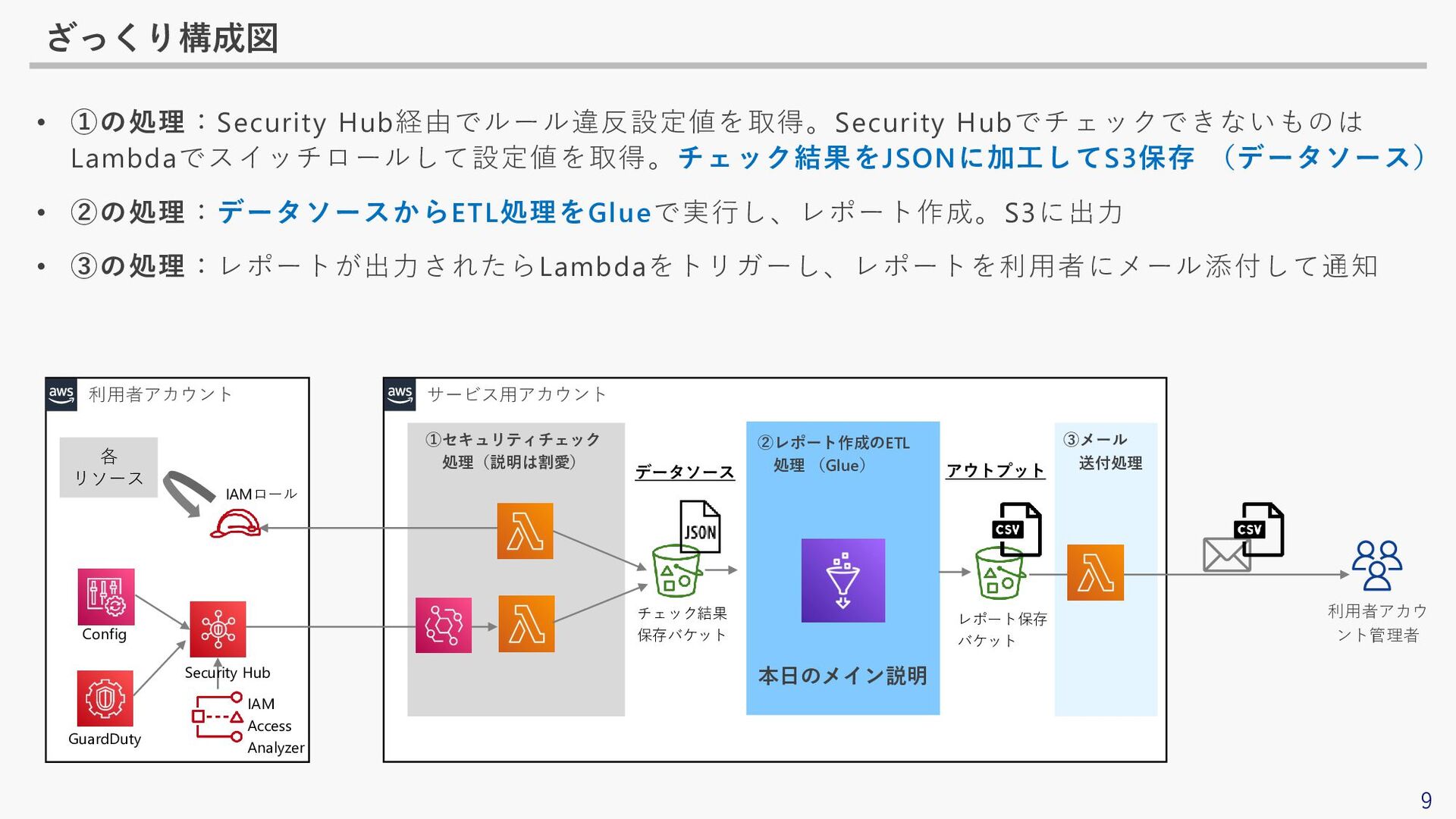
9 サービス用アカウント ざっくり構成図 利用者アカウント 利用者アカウ ント管理者 各 リソース GuardDuty IAM
Access Analyzer Security Hub Config IAMロール ①セキュリティチェック 処理(説明は割愛) ②レポート作成のETL 処理 (Glue) 本日のメイン説明 ③メール 送付処理 チェック結果 保存バケット レポート保存 バケット データソース アウトプット • ①の処理:Security Hub経由でルール違反設定値を取得。Security Hubでチェックできないものは Lambdaでスイッチロールして設定値を取得。チェック結果をJSONに加工してS3保存 (データソース) • ②の処理:データソースからETL処理をGlueで実行し、レポート作成。S3に出力 • ③の処理:レポートが出力されたらLambdaをトリガーし、レポートを利用者にメール添付して通知
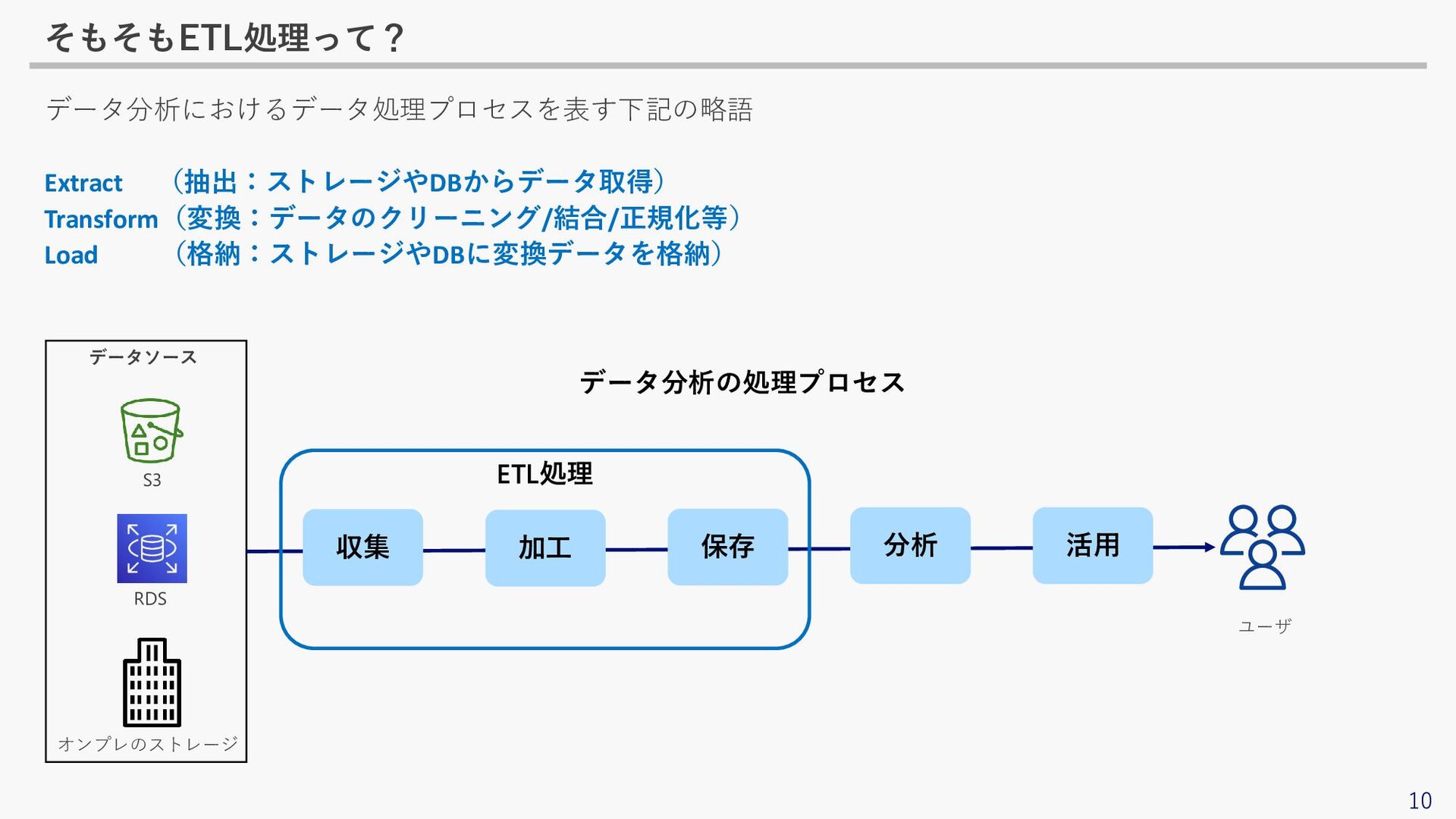
10 そもそもETL処理って? データ分析におけるデータ処理プロセスを表す下記の略語 Extract (抽出:ストレージやDBからデータ取得) Transform(変換:データのクリーニング/結合/正規化等) Load (格納:ストレージやDBに変換データを格納) データソース 収集
加工 保存 分析 活用 ETL処理 データ分析の処理プロセス ユーザ S3 RDS オンプレのストレージ
11 AWSのETLサービス 多すぎる! AWS Batch AWS Lambda Amazon Athena Amazon
Redshift (ETL) Amazon EMR AWS Glue Amazon ECS Amazon EKS 等々
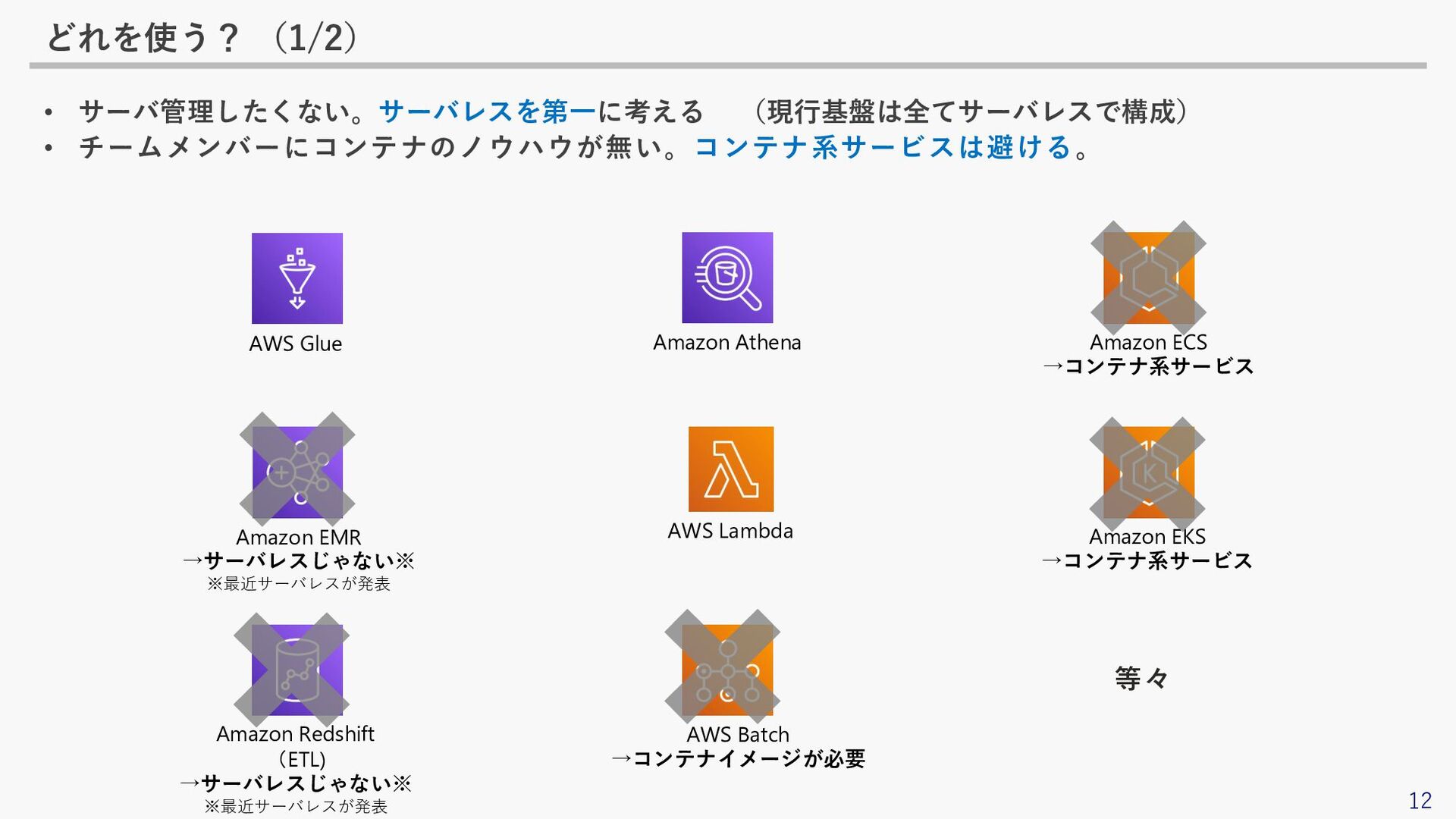
12 どれを使う? (1/2) • サーバ管理したくない。サーバレスを第一に考える (現行基盤は全てサーバレスで構成) • チームメンバーにコンテナのノウハウが無い。コンテナ系サービスは避ける。 AWS Batch
→コンテナイメージが必要 AWS Lambda Amazon Athena Amazon Redshift (ETL) →サーバレスじゃない※ ※最近サーバレスが発表 Amazon EMR →サーバレスじゃない※ ※最近サーバレスが発表 AWS Glue Amazon ECS →コンテナ系サービス Amazon EKS →コンテナ系サービス 等々
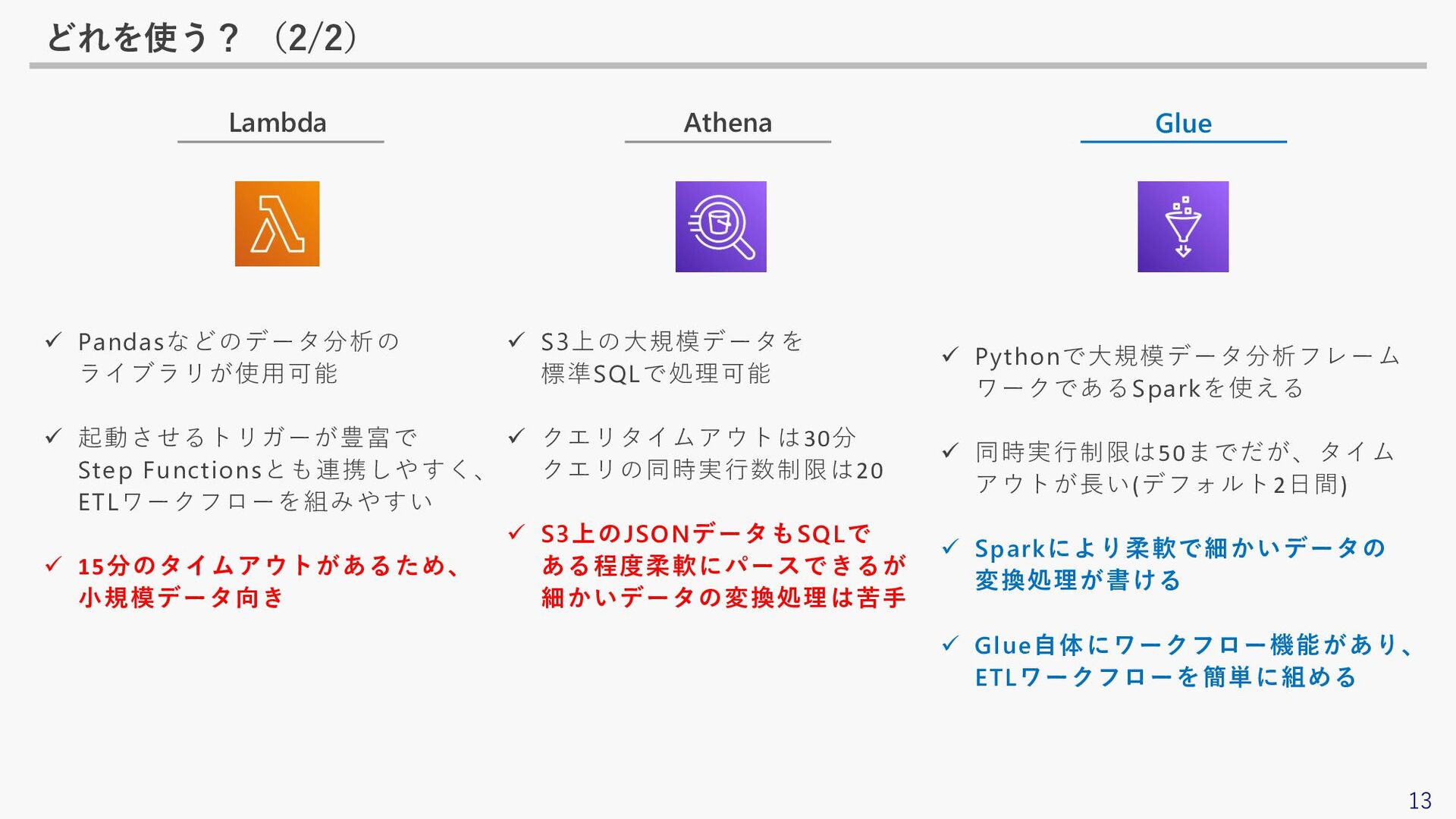
13 どれを使う? (2/2) Lambda Athena Glue ✓ Pandasなどのデータ分析の ライブラリが使用可能 ✓
起動させるトリガーが豊富で Step Functionsとも連携しやすく、 ETLワークフローを組みやすい ✓ 15分のタイムアウトがあるため、 小規模データ向き ✓ S3上の大規模データを 標準SQLで処理可能 ✓ クエリタイムアウトは30分 クエリの同時実行数制限は20 ✓ S3上のJSONデータもSQLで ある程度柔軟にパースできるが 細かいデータの変換処理は苦手 ✓ Pythonで大規模データ分析フレーム ワークであるSparkを使える ✓ 同時実行制限は50までだが、タイム アウトが長い(デフォルト2日間) ✓ Sparkにより柔軟で細かいデータの 変換処理が書ける ✓ Glue自体にワークフロー機能があり、 ETLワークフローを簡単に組める
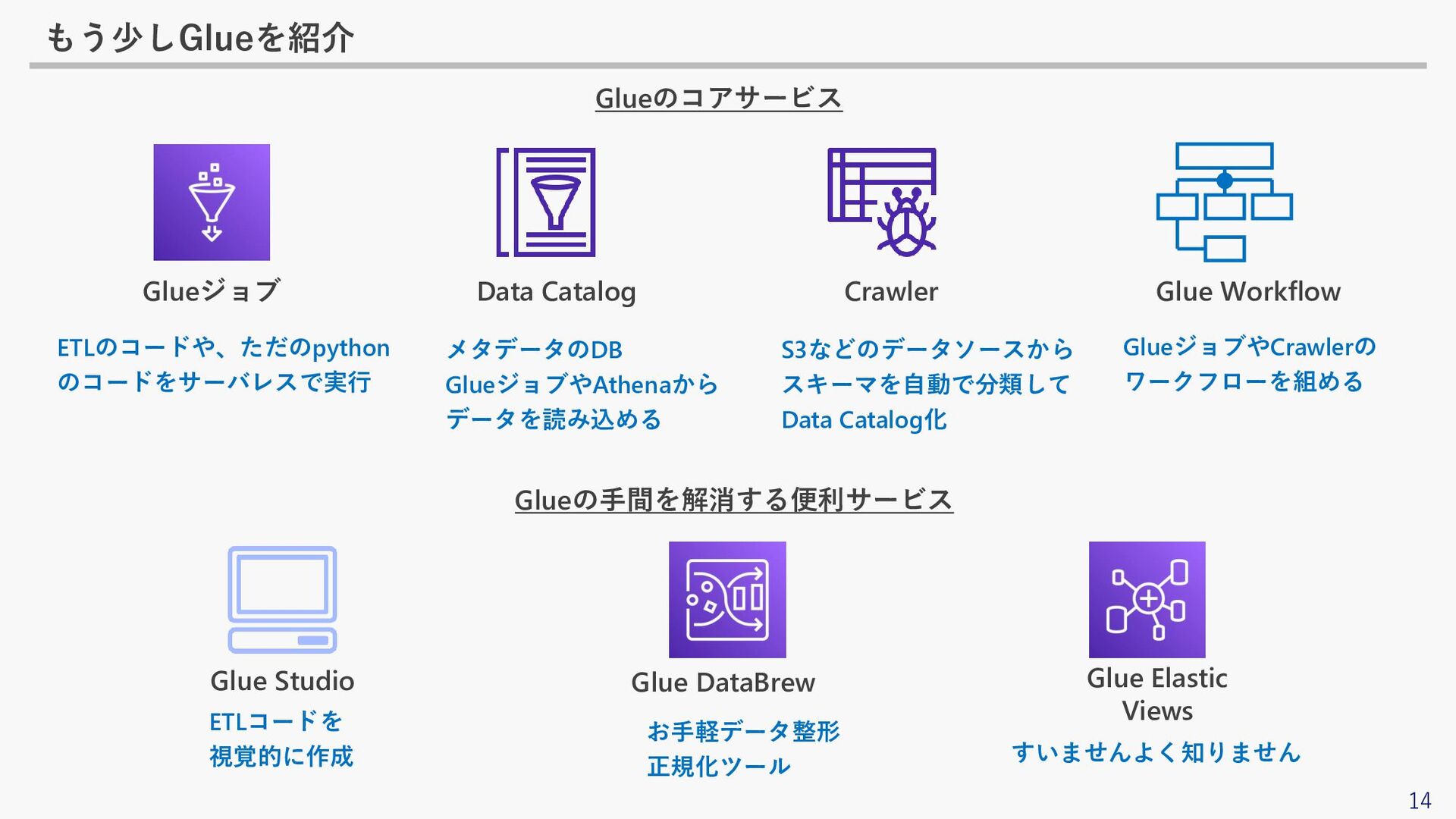
14 もう少しGlueを紹介 Data Catalog Crawler Glue Workflow Glue Studio Glue
DataBrew Glue Elastic Views Glueジョブ Glueのコアサービス Glueの手間を解消する便利サービス ETLのコードや、ただのpython のコードをサーバレスで実行 メタデータのDB GlueジョブやAthenaから データを読み込める ETLコードを 視覚的に作成 お手軽データ整形 正規化ツール すいませんよく知りません S3などのデータソースから スキーマを自動で分類して Data Catalog化 GlueジョブやCrawlerの ワークフローを組める
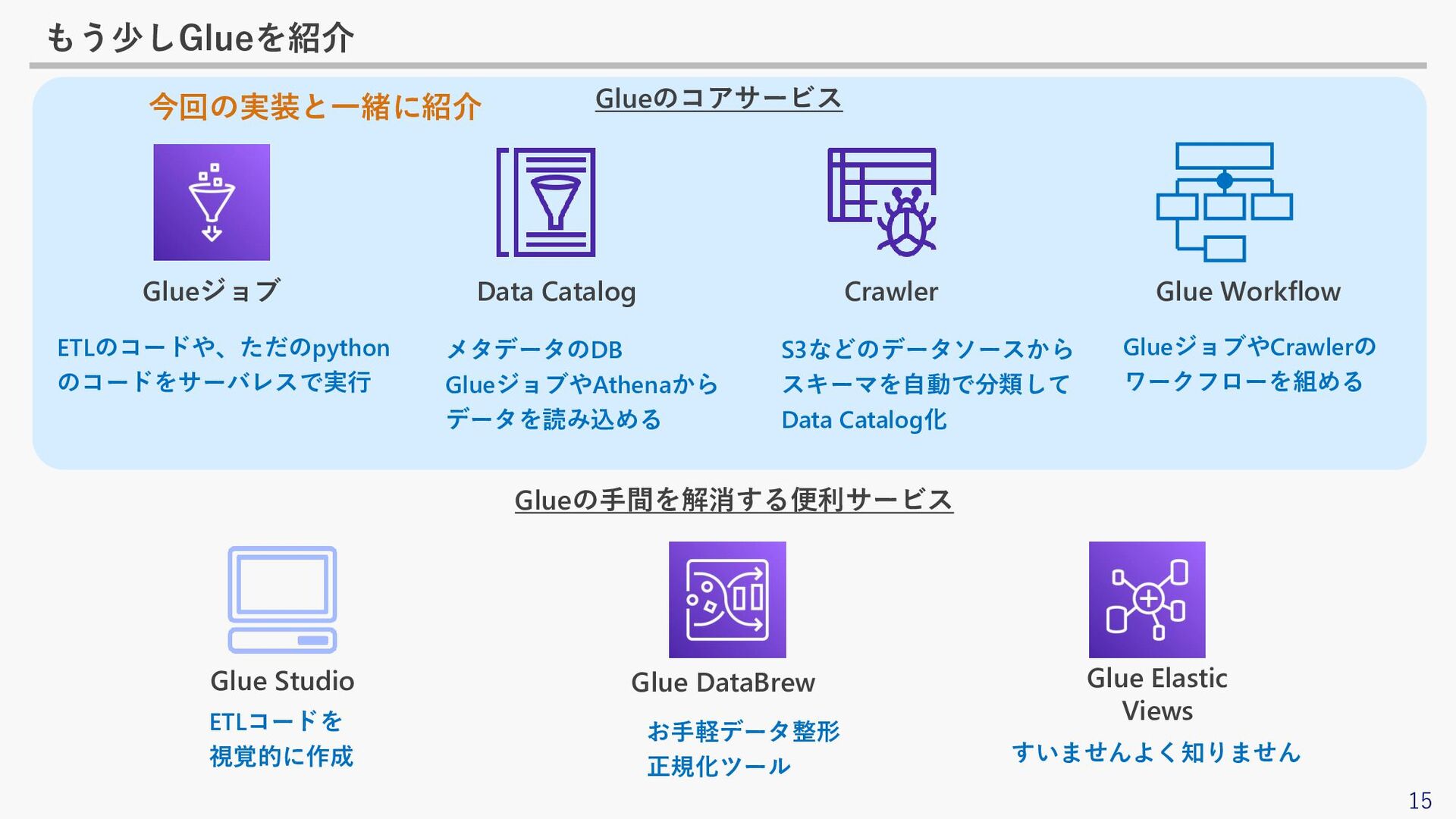
15 もう少しGlueを紹介 Data Catalog Crawler Glue Workflow Glue Studio Glue
DataBrew Glue Elastic Views Glueジョブ ETLのコードや、ただのpython のコードをサーバレスで実行 メタデータのDB GlueジョブやAthenaから データを読み込める ETLコードを 視覚的に作成 お手軽データ整形 正規化ツール すいませんよく知りません S3などのデータソースから スキーマを自動で分類して Data Catalog化 GlueジョブやCrawlerの ワークフローを組める Glueのコアサービス Glueの手間を解消する便利サービス 今回の実装と一緒に紹介
16 ETLアーキテクチャ [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後 [トリガー] Crawler
正常終了後 [トリガー] スケジューラ 日次起動 Glue Workflow 月初判定 Python Shell CSV作成 Sparkジョブ Data Catalog 出力 日次稼働 月次稼働 クローラ データ 取得 CSV加工 Glue Workflowを使って、月初に先月分のセキュリティレポートをバッチ処理的に作成 [出力先] レポート保存バケット
17 ETLアーキテクチャ・クローラ [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後 [トリガー] Crawler
正常終了後 [トリガー] スケジューラ 日次起動 Glue Workflow 月初判定 Python Shell CSV作成 Sparkジョブ Data Catalog 出力 日次稼働 月次稼働 クローラ データ 取得 CSV加工 • クローラにより、S3上のセキュリティチェック結果のJSONファイルのスキーマを自動で識別し、 Sparkジョブが読み込めるデータベース(Data Catalog)として出力 • Data CatalogはAthena/EMR等でも読み込める。将来、Data Catalogのデータを使って、 Athena + QuickSightでダッシュボード化を見越して、クローラは細かい間隔で実行 (毎日稼働) [出力先] レポート保存バケット
18 ETLアーキテクチャ・Python Shell (Glueジョブ) [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後
[トリガー] Crawler 正常終了後 [トリガー] スケジューラ 日次起動 Glue Workflow 月初判定 Python Shell CSV作成 Sparkジョブ Data Catalog 出力 日次稼働 月次稼働 クローラ データ 取得 CSV加工 • Glueジョブにはデータ分析フレームワークのSpark以外にも、素のPythonスクリプトも実行できる。 これをPython Shellといい、Lambdaのタイムアウトがない版のようなもの。 トリガーはLambdaほど充実してないが、Glue Workflowの中で様々な処理を実装可能 (SDKであるboto3も使える) • Python Shellは日付判定して、月初のみ正常終了させる。月初のみ後続のCSV作成Sparkジョブを動かす [出力先] レポート保存バケット
19 ETLアーキテクチャ・ Sparkジョブ (Glueジョブ) [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後
[トリガー] Crawler 正常終了後 [トリガー] スケジューラ 日次起動 Glue Workflow 月初判定 Python Shell CSV作成 Sparkジョブ Data Catalog 出力 日次稼働 月次稼働 クローラ データ 取得 CSV加工 • 大規模データのETL処理をサーバレスで実装 • Data Catalog上からデータを取得 (実データはS3上)して、Sparkの各種データ変換メソッドを使い、 データをいい感じに整形し、CSVファイルとしてS3に出力 (Sparkは力技で柔軟な変換処理が書ける) [出力先] レポート保存バケット
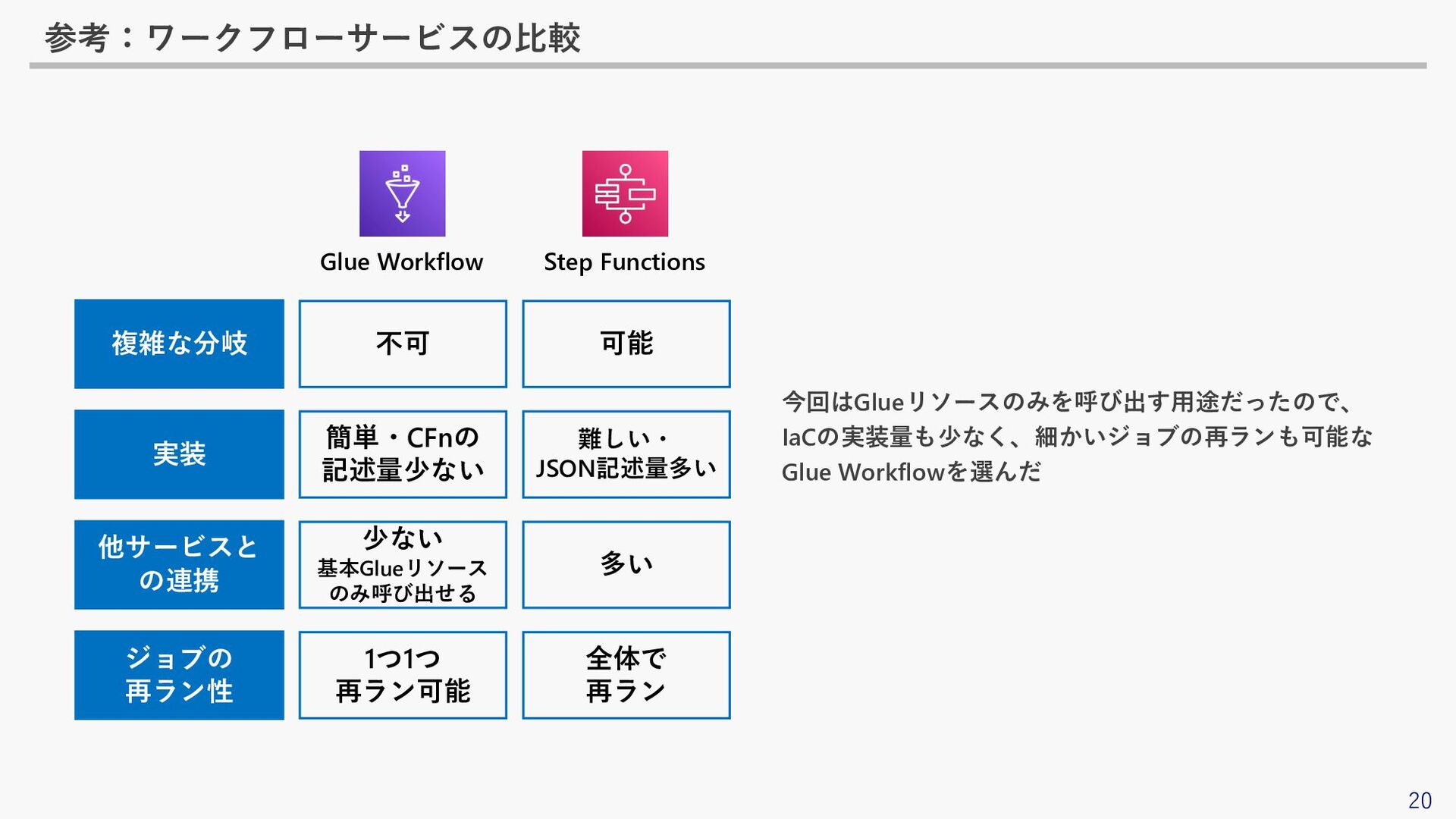
20 参考:ワークフローサービスの比較 複雑な分岐 実装 他サービスと の連携 不可 簡単・CFnの 記述量少ない 少ない
基本Glueリソース のみ呼び出せる 可能 難しい・ JSON記述量多い 多い Glue Workflow Step Functions 今回はGlueリソースのみを呼び出す用途だったので、 IaCの実装量も少なく、細かいジョブの再ランも可能な Glue Workflowを選んだ ジョブの 再ラン性 1つ1つ 再ラン可能 全体で 再ラン
21 Glueの使用感
22 Glueの素晴らしいところ 圧倒的に安い Glueで現在かかっている月額:2ドル • サーバレスなので使った分だけしか料金がかからない。 Sparkの豊富なデータ変換メソッド • インプットデータが多少複雑でも、柔軟にデータを作りたい形に整形できる 痒いところに手が届く
• Python Shellを使って、Workflowの途中で柔軟な処理を差し込んだり • Workflowの途中から再ランしたり • ジョブのロングラン時に、EventBridgeに連携して通知したり • 読み込んだデータを再処理しないようにできたり (ジョブ ブックマークという便利機能) 頻繁にサービスアップデートされていて、どんどん便利になる • Glueバージョンが上がり、Sparkクラスタ起動時間が短くなった。また、処理自体も高速に • データ加工やETLのコーディングがどんどん楽に。(StudioやBrew等)
23 Glueのつらいところ Sparkには慣れが必要 • 日本語ドキュメントが少ない。 • 文法が似ているpandas(軽量なデータ分析ライブラリ)ばっかりヒットする。 Glueジョブの性能分析が難しい CloudWatchのメトリクスや、性能分析ツール(SparkUI:データ変換処理に沿って行数と列名の変化を ビジュアル表示してくれるツール)があるものの、Sparkに詳しくないと分析が難しい
→性能問題が起きたらサポートに聞きましょう。ジョブIDを伝えたらある程度原因分析もしてくれます。 クローラがマネージドすぎてブラックボックスな箇所が多い • ファイルフォーマットが揃ってないと、クローラが作るData Catalogのテーブル数が不定 • スペックが選べない。データ量に応じて自動的にスケールアップする仕様っぽい? • タイムアウト値が24時間で変更できない • ログがあまり出ない。(ERRORは原因が出るが、通常はStartとENDくらい) 性能問題の調査が難しい
24 Glueの注意点 Glueジョブの同実行数の上限には注意 • 「1ジョブあたりの最大同時実行数:1,000」 vs 「1アカウントあたりの最大同時実行数:50」(こっちが適用) Glueジョブは処理を細かく分割して、ジョブの並列度を上げるような用途には向かない Glueジョブ(Spark)のログが大量に出る •
CloudWatch Logsにデフォルトでログ出力されるが、Sparkのシステムログが大量に勝手に出力され、 見たいログが埋もがち。コード内でloggerするときに接頭辞を工夫する必要がある データソースの設計がSparkジョブの実装の複雑さと性能を左右 (S3ならファイル構造/フォルダ構成) • シンプルなファイル構造にする JSONならネストが深いとクローラがうまくスキーマ解釈できない(カスタム分類子を上手って回避できるかも) Sparkジョブで頑張ってパースできるけど、実装が複雑になる • S3のフォルダ構成はSparkジョブの性能に大きく関わる。 (例) s3://aaaa/bbbb/ccc/file.txt →aaa、bbb、cccがそれぞれパーティションになり、ジョブ内でパーティションを指定してデータをロードする。 いい感じにフォルダ分割してないと、データロード時に無駄なものを読み込むことになる。
25 まとめ・振り返り Glueを活用してセキュリティ診断レポートを定期的に作成する機能を実装 • レポートにより設定状況を俯瞰でき、セキュリティ対策をより計画的に立てることができる • 環境の一時的なアセスメントにも活用可能 Glueの使い勝手の良さ • サーバレスのため稼働コストが格安(月額2ドルほど)
• SparkジョブでAthenaよりも柔軟(力技とも言う)にデータを整形 • タイムアウトも気にしなくてもほど長い。(デフォルト2日間。Lambdaだと15分) • WorkflowもGlueの機能だけで簡単に組める Glueのつらいところ/注意点 • ジョブの同時実行数が50と少ない。処理を細かく分けて並列化する構成には不向き • 性能分析の難易度が高い。サポートを上手く活用しよう • データソースのファイル/フォルダ設計が、Sparkジョブ(ETL)の実装の複雑さ・性能を決める肝 Glueは使いこなすまで時間がかかるが、安くて機能も豊富な凄いヤツ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![16 ETLアーキテクチャ [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後 [トリガー] Crawler](https://files.speakerdeck.com/presentations/c4e23bd4be05473b8f1259601de11507/slide_16.jpg){kind=link}
![17 ETLアーキテクチャ・クローラ [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後 [トリガー] Crawler](https://files.speakerdeck.com/presentations/c4e23bd4be05473b8f1259601de11507/slide_17.jpg){kind=link}
![18 ETLアーキテクチャ・Python Shell (Glueジョブ) [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後](https://files.speakerdeck.com/presentations/c4e23bd4be05473b8f1259601de11507/slide_18.jpg){kind=link}
![19 ETLアーキテクチャ・ Sparkジョブ (Glueジョブ) [データソース] セキュリティチェック 結果保存バケット [トリガー] ジョブ 正常終了後](https://files.speakerdeck.com/presentations/c4e23bd4be05473b8f1259601de11507/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}