- 2017 ~ Development and operation of own private cloud • IaaS and PaaS infrastructure • Automation of infrastructure construction - 2021 ~ Camping Helpdesk operation for internal CCoE of AWS • Development and operation of AWS environment provision and security services • Technical support for AWS projects 2
Architecture and design key points 1 3 2 Tips on using RAG to streamline help desk operations Improving the accuracy of RAG responses using Amazon Bedrock 3
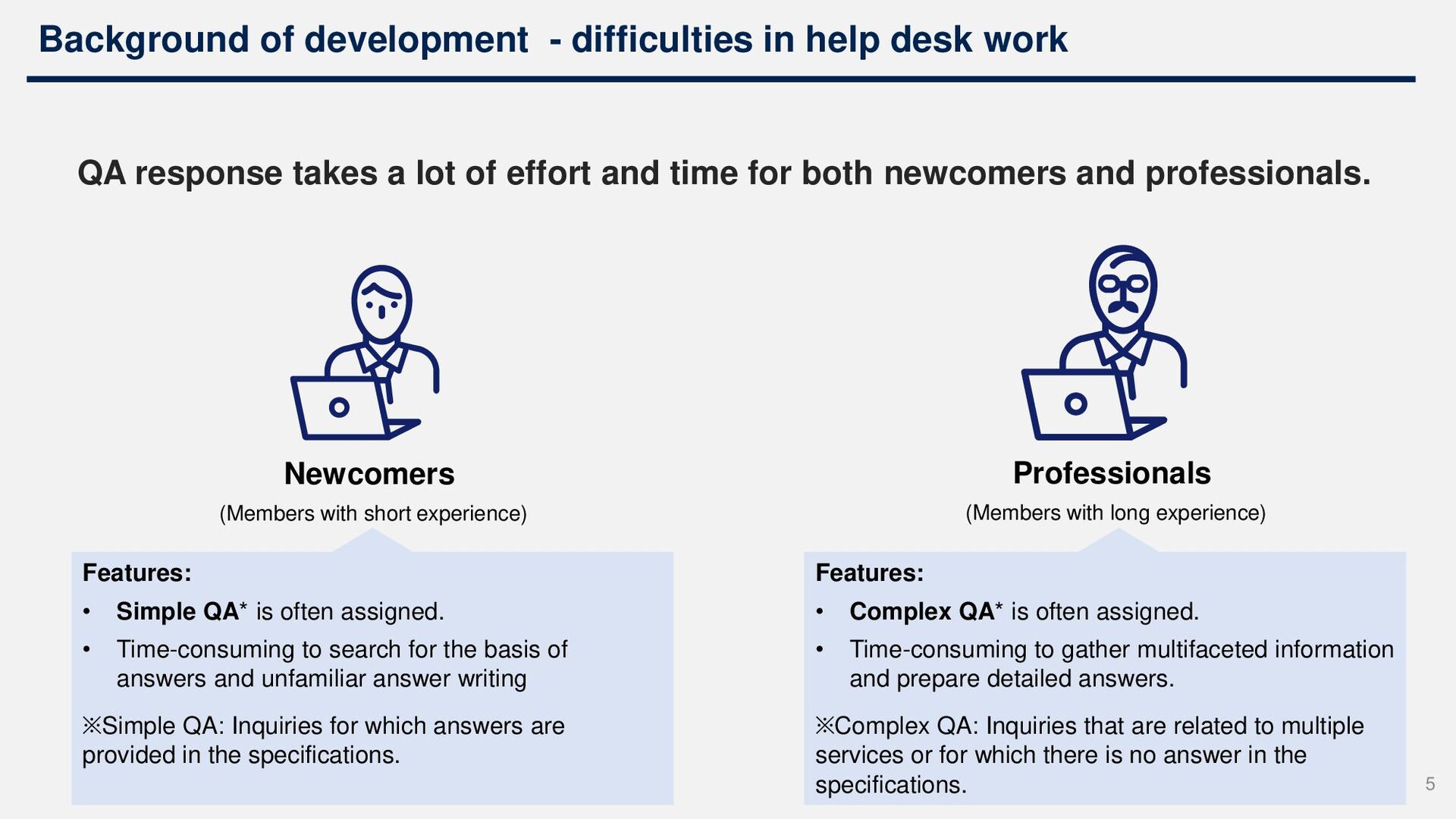
both newcomers and professionals. Professionals (Members with long experience) Features: • Simple QA* is often assigned. • Time-consuming to search for the basis of answers and unfamiliar answer writing ※Simple QA: Inquiries for which answers are provided in the specifications. Features: • Complex QA* is often assigned. • Time-consuming to gather multifaceted information and prepare detailed answers. ※Complex QA: Inquiries that are related to multiple services or for which there is no answer in the specifications. Newcomers (Members with short experience) Background of development - difficulties in help desk work 5
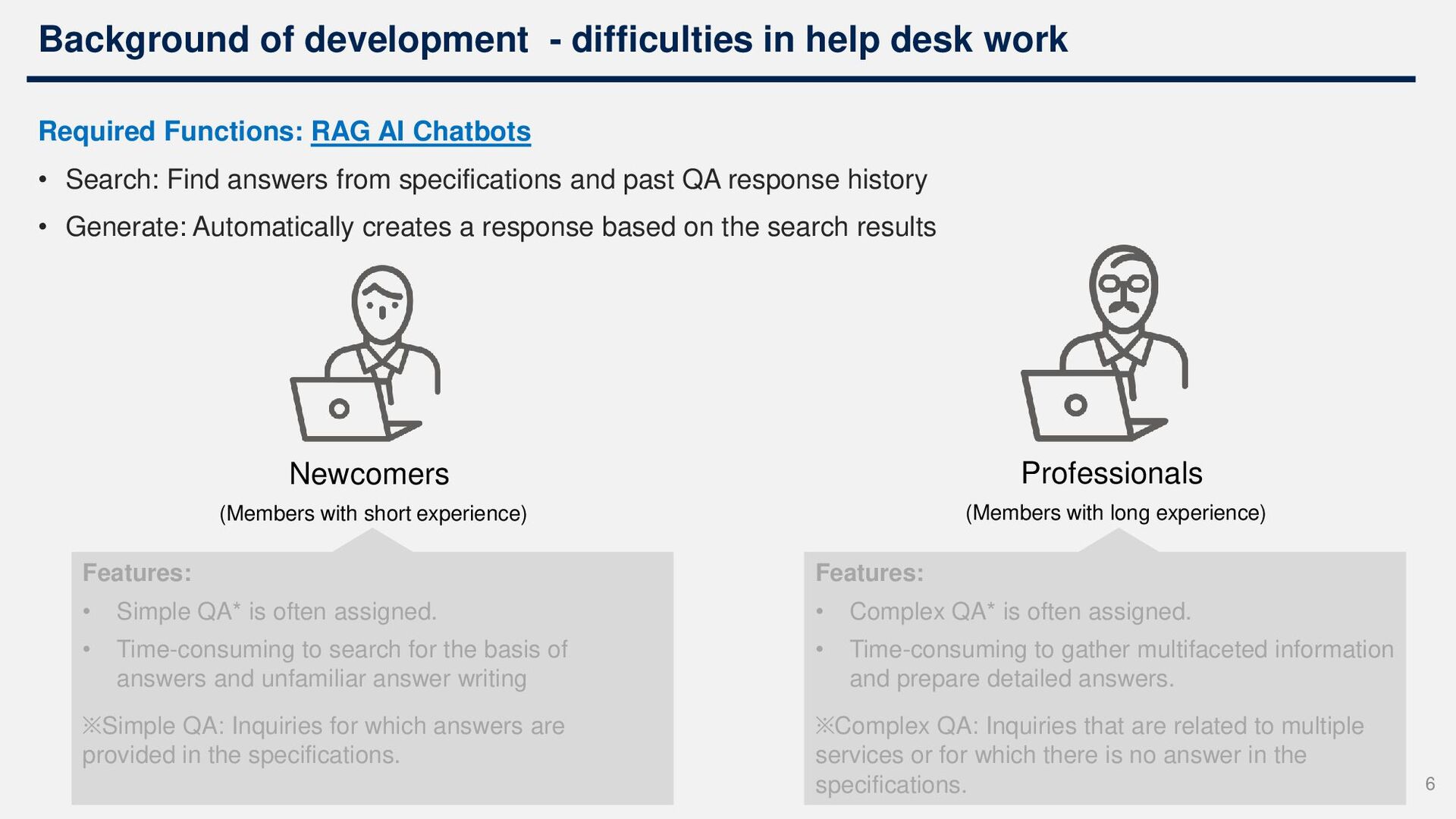
specifications and past QA response history • Generate: Automatically creates a response based on the search results Professionals (Members with long experience) Features: • Simple QA* is often assigned. • Time-consuming to search for the basis of answers and unfamiliar answer writing ※Simple QA: Inquiries for which answers are provided in the specifications. Features: • Complex QA* is often assigned. • Time-consuming to gather multifaceted information and prepare detailed answers. ※Complex QA: Inquiries that are related to multiple services or for which there is no answer in the specifications. Newcomers (Members with short experience) Background of development - difficulties in help desk work 6
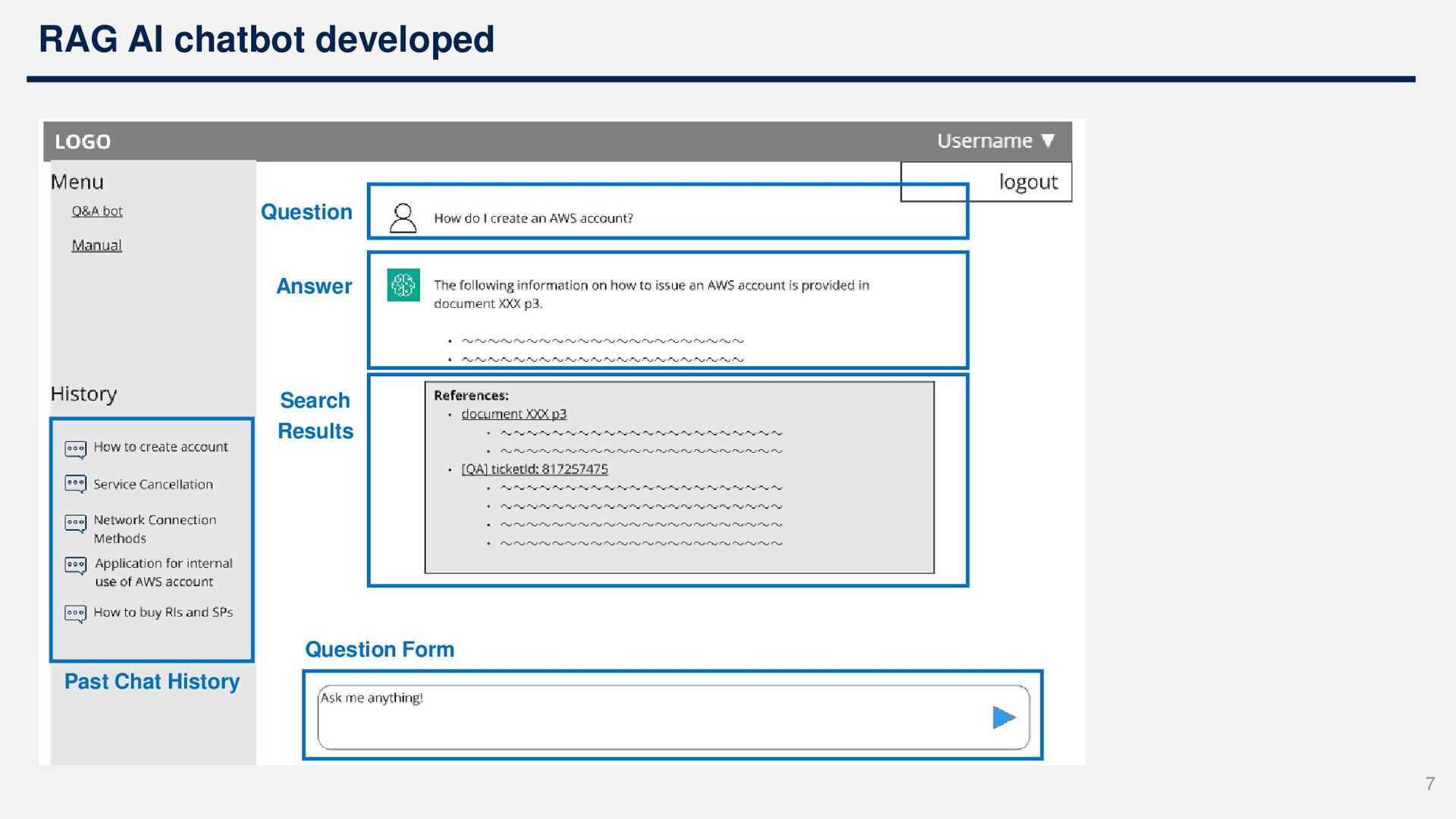
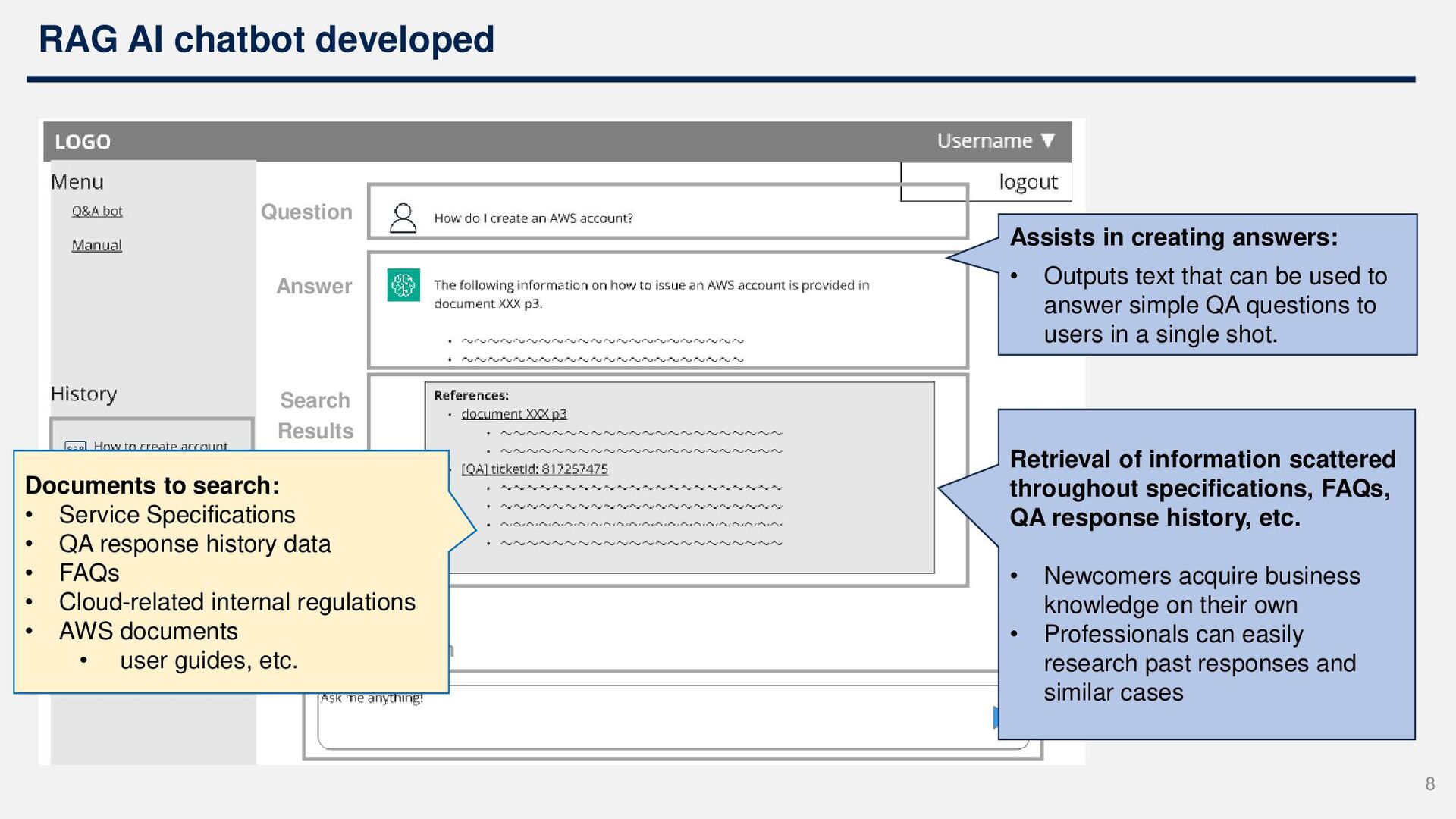
History Question Form 8 Documents to search: • Service Specifications • QA response history data • FAQs • Cloud-related internal regulations • AWS documents • user guides, etc. Assists in creating answers: • Outputs text that can be used to answer simple QA questions to users in a single shot. Retrieval of information scattered throughout specifications, FAQs, QA response history, etc. • Newcomers acquire business knowledge on their own • Professionals can easily research past responses and similar cases
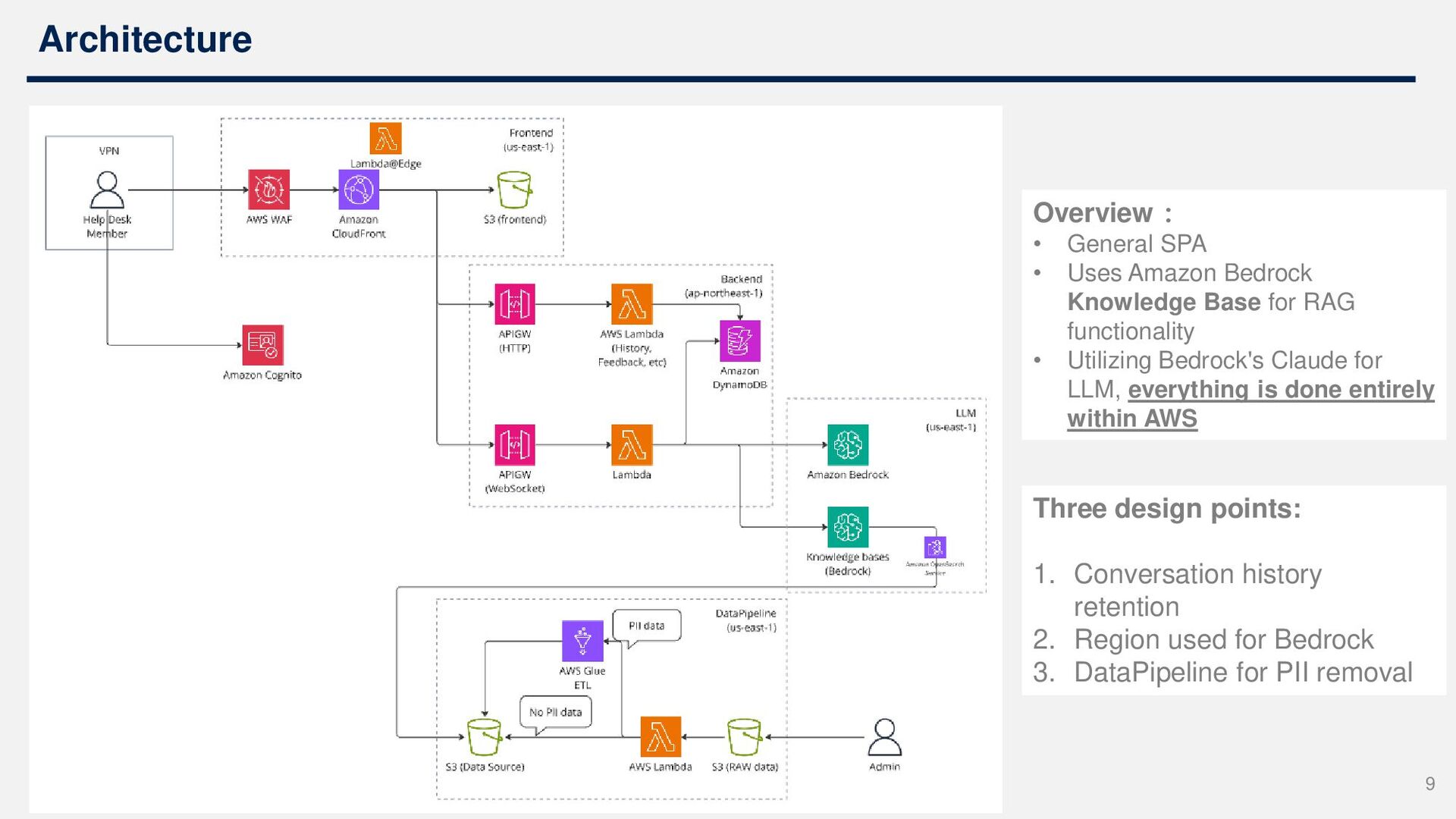
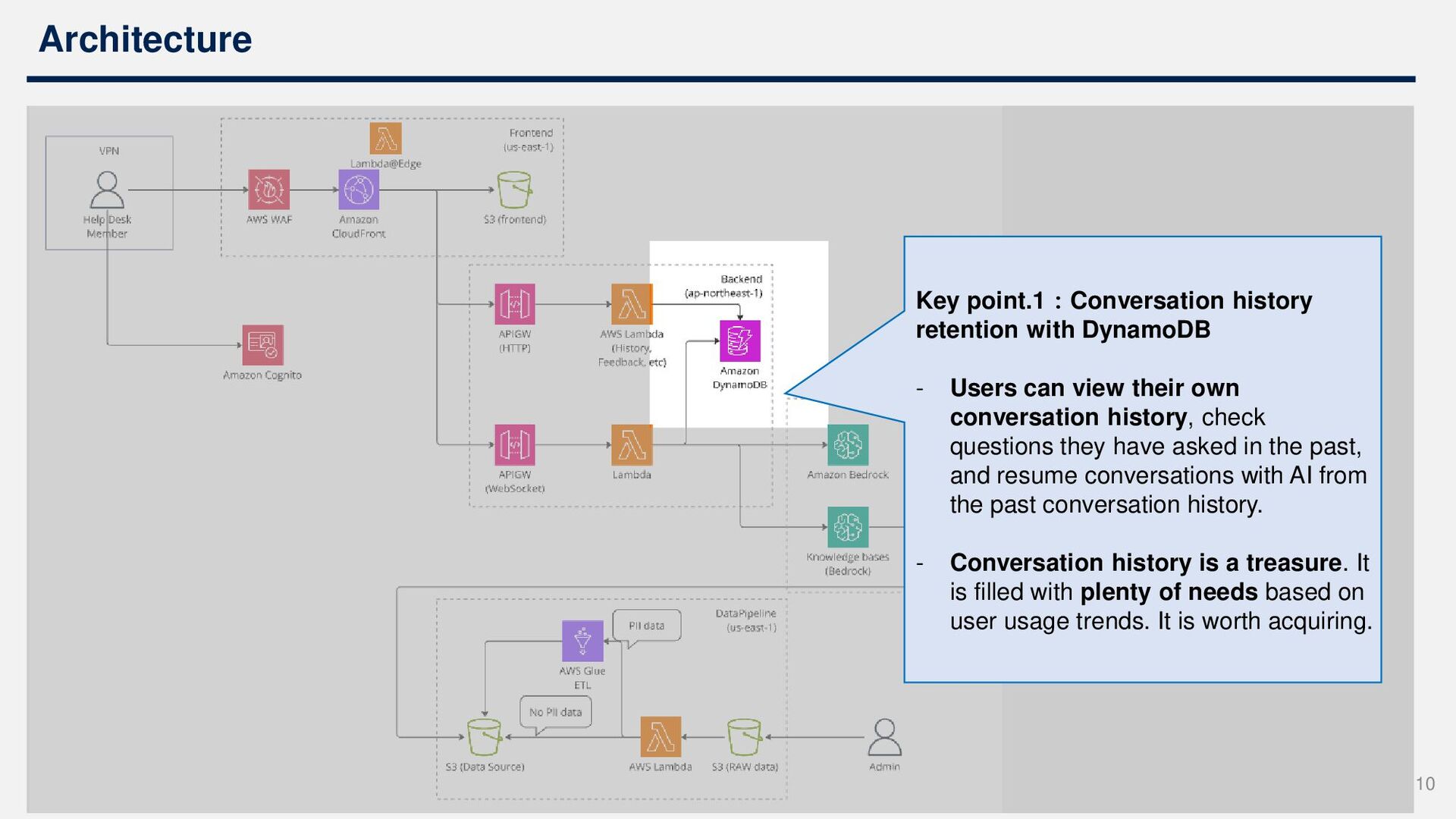
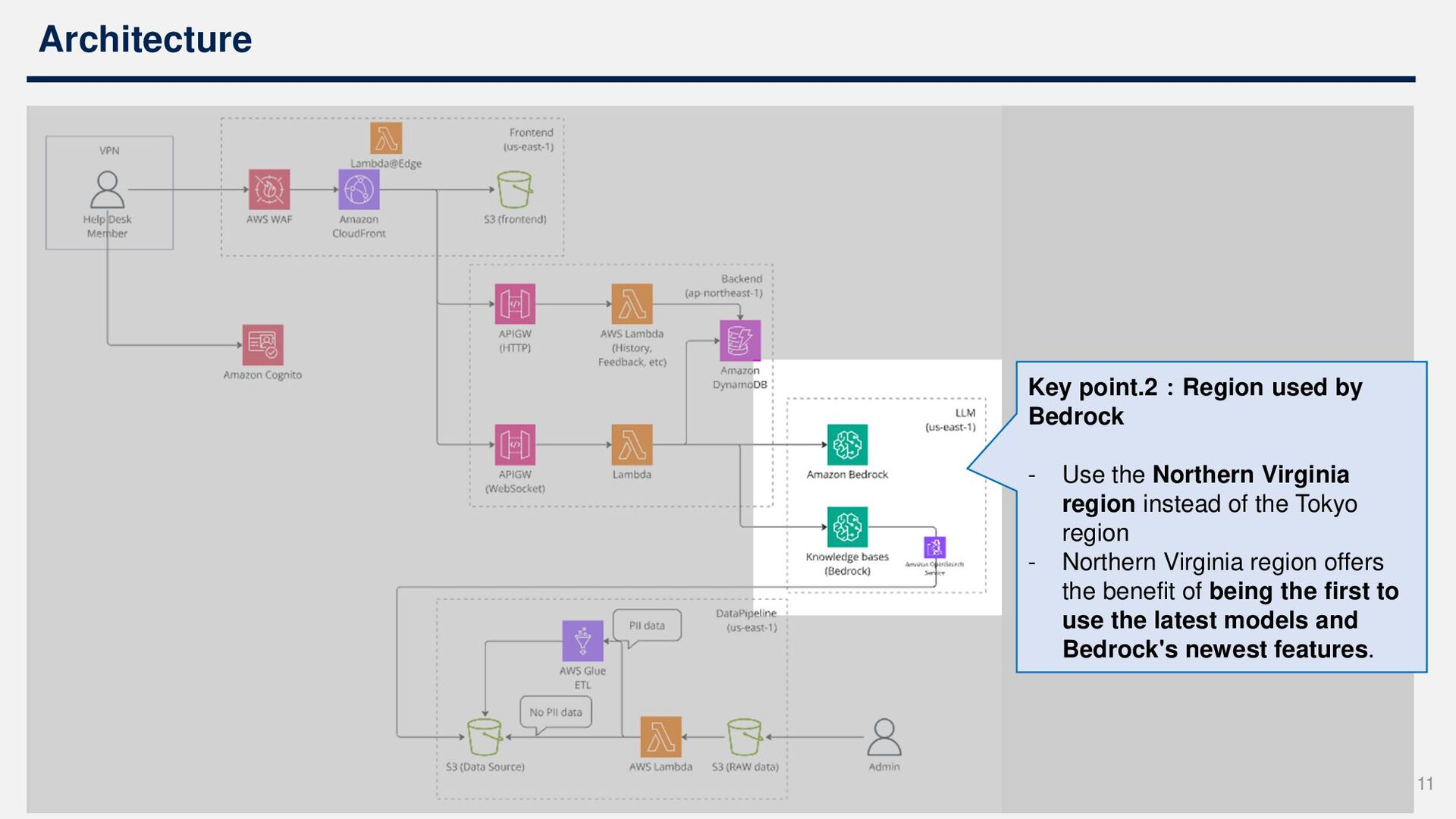
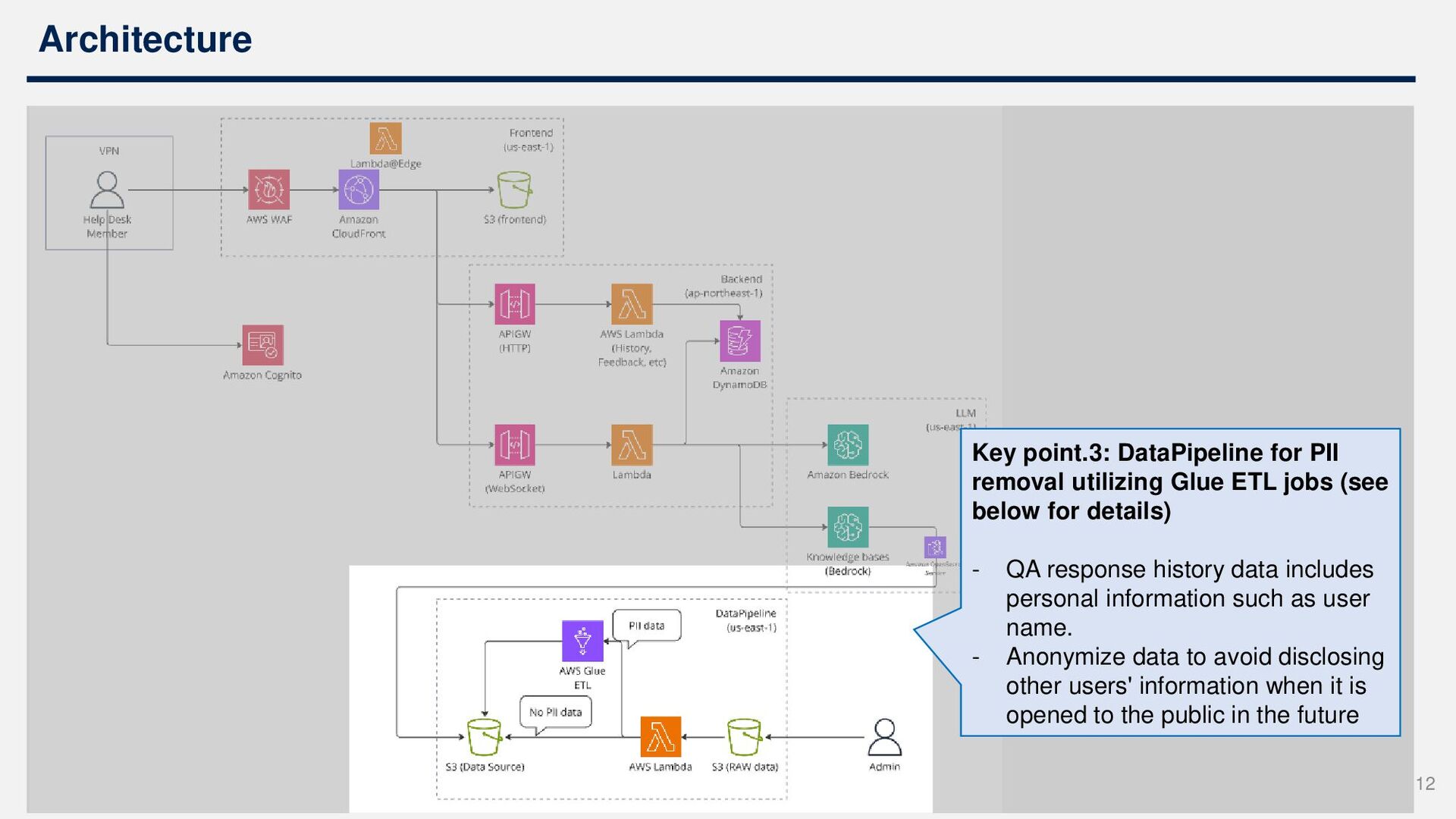
Base for RAG functionality • Utilizing Bedrock's Claude for LLM, everything is done entirely within AWS Three design points: 1. Conversation history retention 2. Region used for Bedrock 3. DataPipeline for PII removal 9
view their own conversation history, check questions they have asked in the past, and resume conversations with AI from the past conversation history. - Conversation history is a treasure. It is filled with plenty of needs based on user usage trends. It is worth acquiring. 10
Virginia region instead of the Tokyo region - Northern Virginia region offers the benefit of being the first to use the latest models and Bedrock's newest features. 11
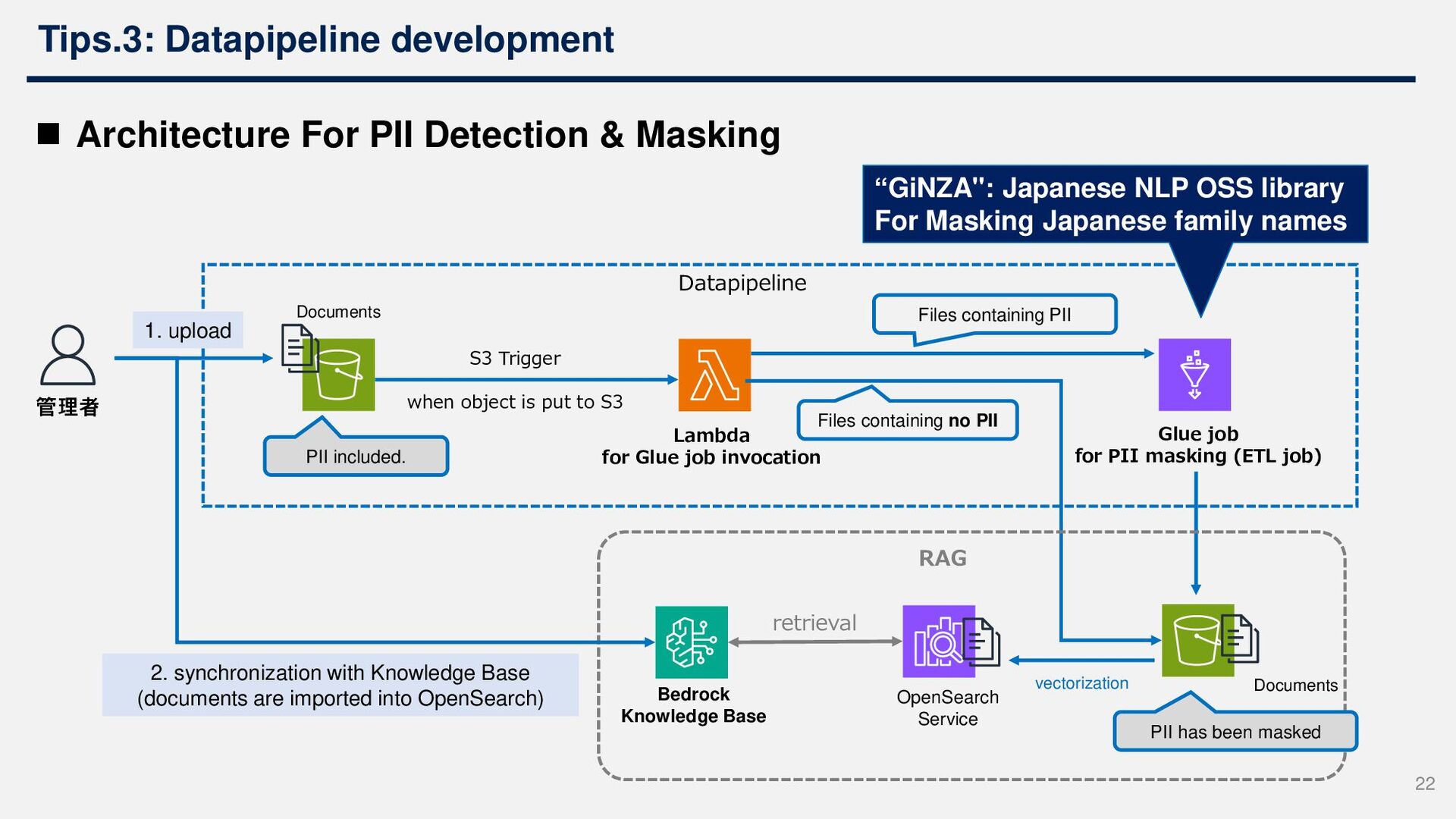
jobs (see below for details) - QA response history data includes personal information such as user name. - Anonymize data to avoid disclosing other users' information when it is opened to the public in the future 12
with a “top-down approach” (getting feedback from domain experts) Move to a “bottom-up approach” (getting feedback from end-users) • Prepare a pair of assumed questions and ideal model answers (data for quantitative evaluation) • Develop an initial prototype to generate content similar to the model answers • Have help desk members and test users actively use the application to collect feedback. • Modify functionality based on user feedback to continually improve the accuracy of responses. After prototype release Engage domain experts early in prototype development to: • Create a comprehensive dataset of assumed questions and ideal model answers • Shape the solution's direction through envisioned user interactions 15
evaluation dataset will also be used as a benchmark for quantitative evaluation, so it is important to prepare a large number of good questions. Engage domain experts early! Sample data set for evaluation: 16
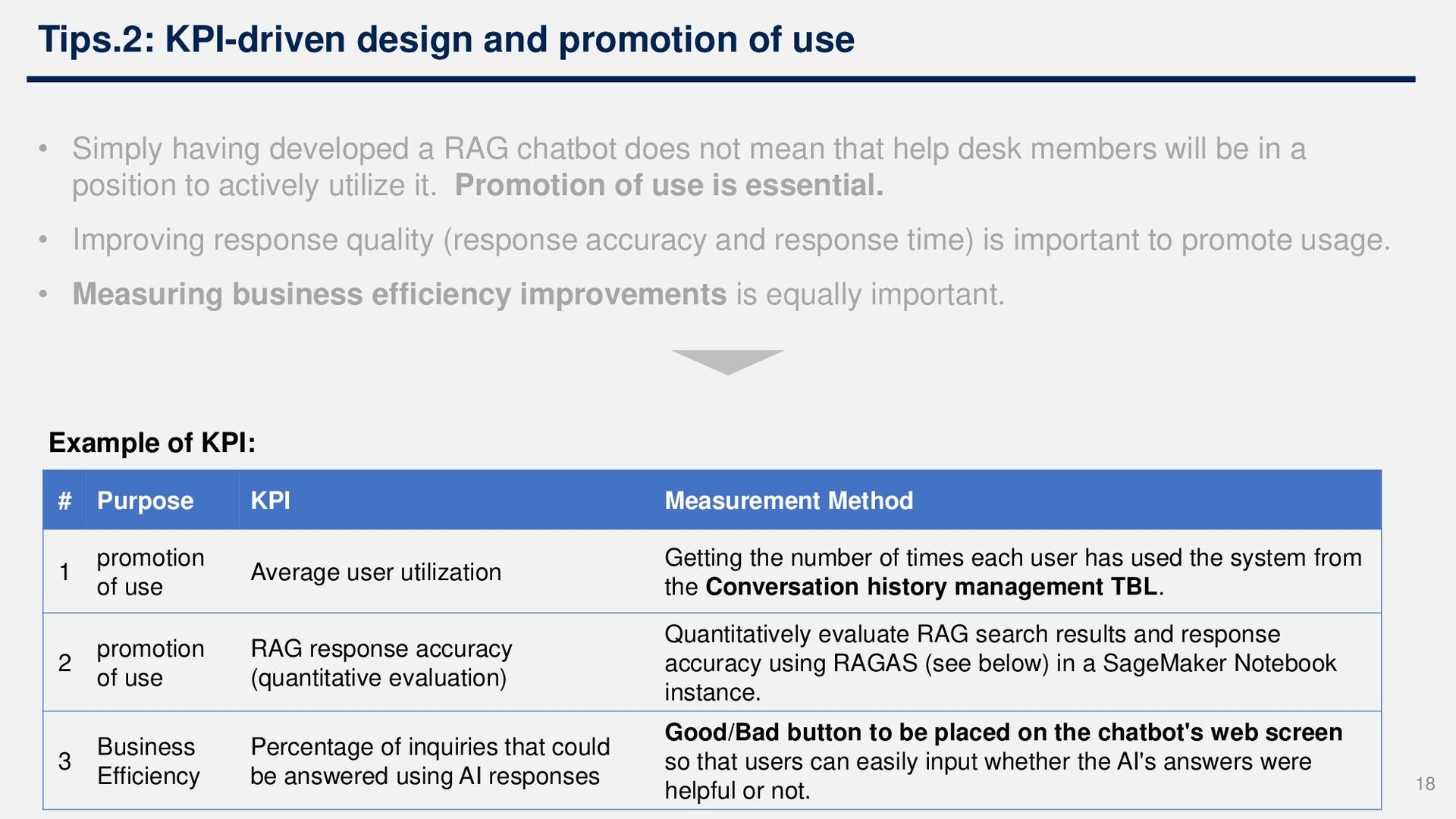
developed a RAG chatbot does not mean that help desk members will be in a position to actively utilize it. Promotion of use is essential. • Improving response quality (response accuracy and response time) is important to promote usage. • Measuring business efficiency improvements is equally important. 17
developed a RAG chatbot does not mean that help desk members will be in a position to actively utilize it. Promotion of use is essential. • Improving response quality (response accuracy and response time) is important to promote usage. • Measuring business efficiency improvements is equally important. # Purpose KPI Measurement Method 1 promotion of use Average user utilization Getting the number of times each user has used the system from the Conversation history management TBL. 2 promotion of use RAG response accuracy (quantitative evaluation) Quantitatively evaluate RAG search results and response accuracy using RAGAS (see below) in a SageMaker Notebook instance. 3 Business Efficiency Percentage of inquiries that could be answered using AI responses Good/Bad button to be placed on the chatbot's web screen so that users can easily input whether the AI's answers were helpful or not. Example of KPI: 18
user utilization Getting the number of times each user has used the system from the Conversation history management TBL. 2 promotion of use RAG response accuracy (quantitative evaluation) Quantitatively evaluate RAG search results and response accuracy using RAGAS (see below) in a SageMaker Notebook instance. 3 Business Efficiency Percentage of inquiries that could be answered using AI responses Good/Bad button to be placed on the chatbot's web screen so that users can easily input whether the AI's answers were helpful or not. Tips.2: KPI-driven design and promotion of use • Simply having developed a RAG chatbot does not mean that help desk members will be in a position to actively utilize it. Promotion of use is essential. • Improving response quality (response accuracy and response time) is important to promote usage. • Measuring business efficiency improvements is equally important. “KPI-driven design": KPIs are defined from the system design stage, and the data and acquisition functions required for measurement are determined in advance. 19
source for RAG is very important for helpdesk operations. • The total amount of QA response history is often much larger than the amount of text in specifications and manuals. • QA response history is essential for AI to answer questions that are not in the manual, and also essential for automated FAQ creation. • QA response history almost always includes PII (name and email address) that identifies the inquirer 20
source for RAG is very important for helpdesk operations. • The total amount of QA response history is often much larger than the amount of text in specifications and manuals. • QA response history is essential for AI to answer questions that are not in the manual, and also essential for automated FAQ creation. • QA response history almost always includes PII (name and email address) that identifies the inquirer 21 If privacy restrictions are in place, it is essential that data be anonymized and PII removed prior to vectorization of the RAG chatbot. (ex. internal regulations prohibit entering personal information into LLMs, or the chatbot is publicly accessible)
for PII masking (ETL job) Files containing PII Files containing no PII 管理者 Documents 1. upload Bedrock Knowledge Base OpenSearch Service RAG Documents vectorization retrieval 2. synchronization with Knowledge Base (documents are imported into OpenSearch) S3 Trigger when object is put to S3 ◼ Architecture For PII Detection & Masking “GiNZA": Japanese NLP OSS library For Masking Japanese family names PII included. PII has been masked Datapipeline 22
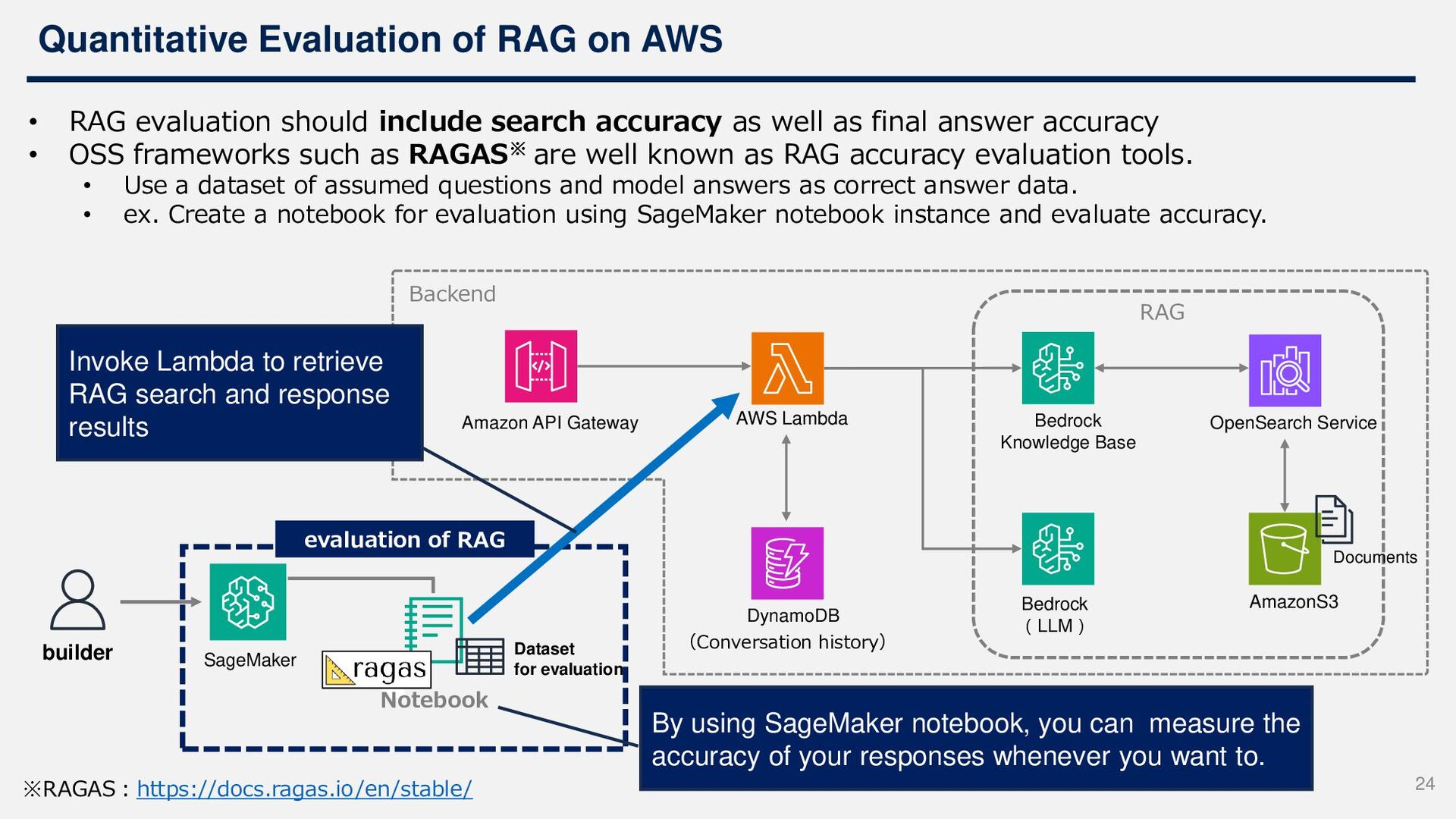
include search accuracy as well as final answer accuracy • OSS frameworks such as RAGAS※ are well known as RAG accuracy evaluation tools. • Use a dataset of assumed questions and model answers as correct answer data. • ex. Create a notebook for evaluation using SageMaker notebook instance and evaluate accuracy. ※RAGAS:https://docs.ragas.io/en/stable/ Amazon API Gateway AWS Lambda Bedrock (LLM) Bedrock Knowledge Base AmazonS3 OpenSearch Service Backend RAG DynamoDB Documents (Conversation history) Notebook SageMaker evaluation of RAG builder By using SageMaker notebook, you can measure the accuracy of your responses whenever you want to. Dataset for evaluation Invoke Lambda to retrieve RAG search and response results 24
input to output has a problem using the following information • Results of quantitative evaluation: Search and answer accuracy obtained from RAGAS • Usage data recorded in the Conversation History TBL: actual question of the user and the content of the LLM answers Make improvements according to bottleneck processes (Advanced tuning with Knowledge Base) 2 # Process Cause Examples of Improvement Actions 1 Question Question text does not include information or keywords necessary for the search • Publish usage guidelines to users, and provide samples prompts. • Review search queries (give the information it needs to search) 2 Question Question text includes many questions. • Enable Knowledge Base’s Query reformulation options (break many questions into multiple sub-queries) 2 Retrieval Diagrams in the document are not legible. • Enable Knowledge Base’s parsing options (have Claude output figures and tables in natural language before vectorizing) 3 Retrieval Search accuracy is poor. • Change search algorithms (ex. OpenSearch's hybrid search with Knowledge Base) • Review your chunking strategy (ex. Knowledge Base's customized chunking) 4 Generate Failure to respond to the intent of the searched document • Prompt tuning • Review document structure 2 1 25
to start by creating a good evaluation dataset and involve domain experts early in the project to do so. • KPI-driven design and promotion is good practice. • To utilize RAG chatbots for help desk operations, it is important to utilize the history of past QA responses, which requires the construction of a data pipeline that includes the anonymization of personal information (PII). • To improve the accuracy of RAG responses, it is necessary to identify bottlenecks and take countermeasures according to the bottlenecks. • Bedrock Knowledge Base features recently allow for advanced tuning, which should be utilized. 27
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}