of code. KerasCV & KerasNLP Unlock the power of data and model parallelism together, so you can scale up with confidence. DTensor Cross-framework compatibility that’s simple and easy. JAX2TF Flexible, fine-grained control over model size like never before for ML development that’s cheaper and faster. TF Quantization API (preview) Building for a changing landscape.
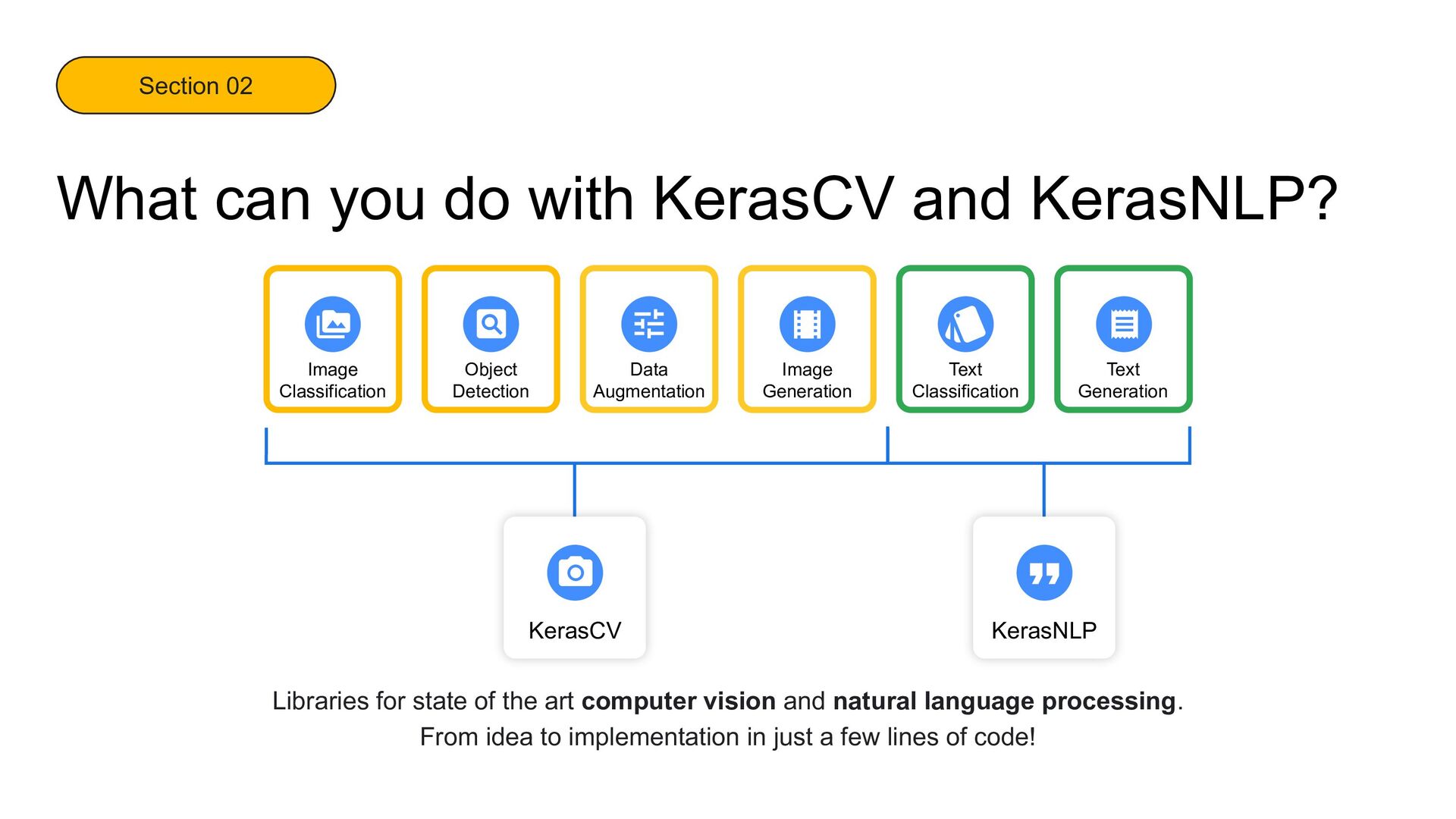
Image Generation KerasCV KerasNLP Libraries for state of the art computer vision and natural language processing. From idea to implementation in just a few lines of code! Section 02 What can you do with KerasCV and KerasNLP?
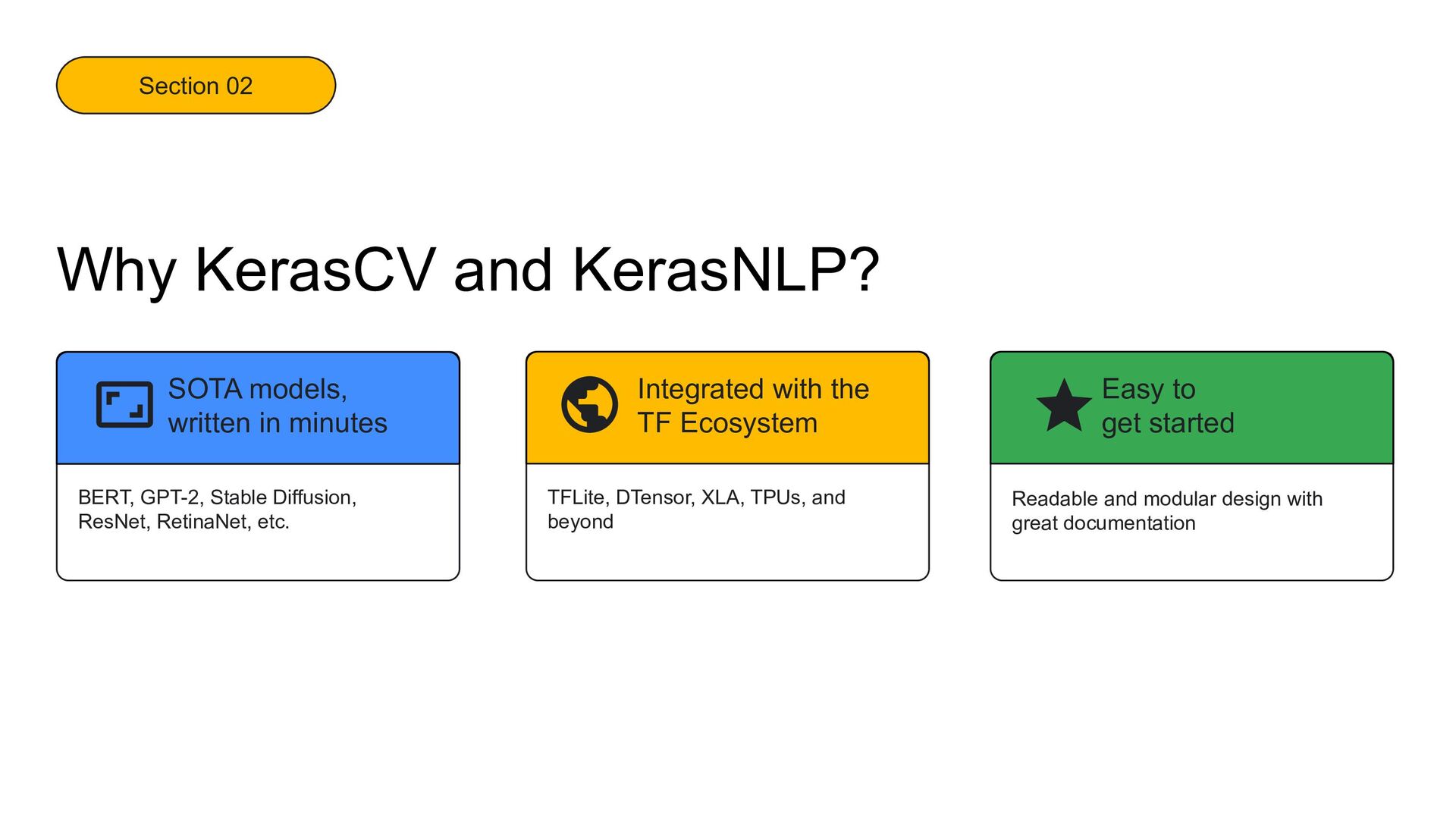
models, written in minutes TFLite, DTensor, XLA, TPUs, and beyond Integrated with the TF Ecosystem Readable and modular design with great documentation Easy to get started Why KerasCV and KerasNLP?
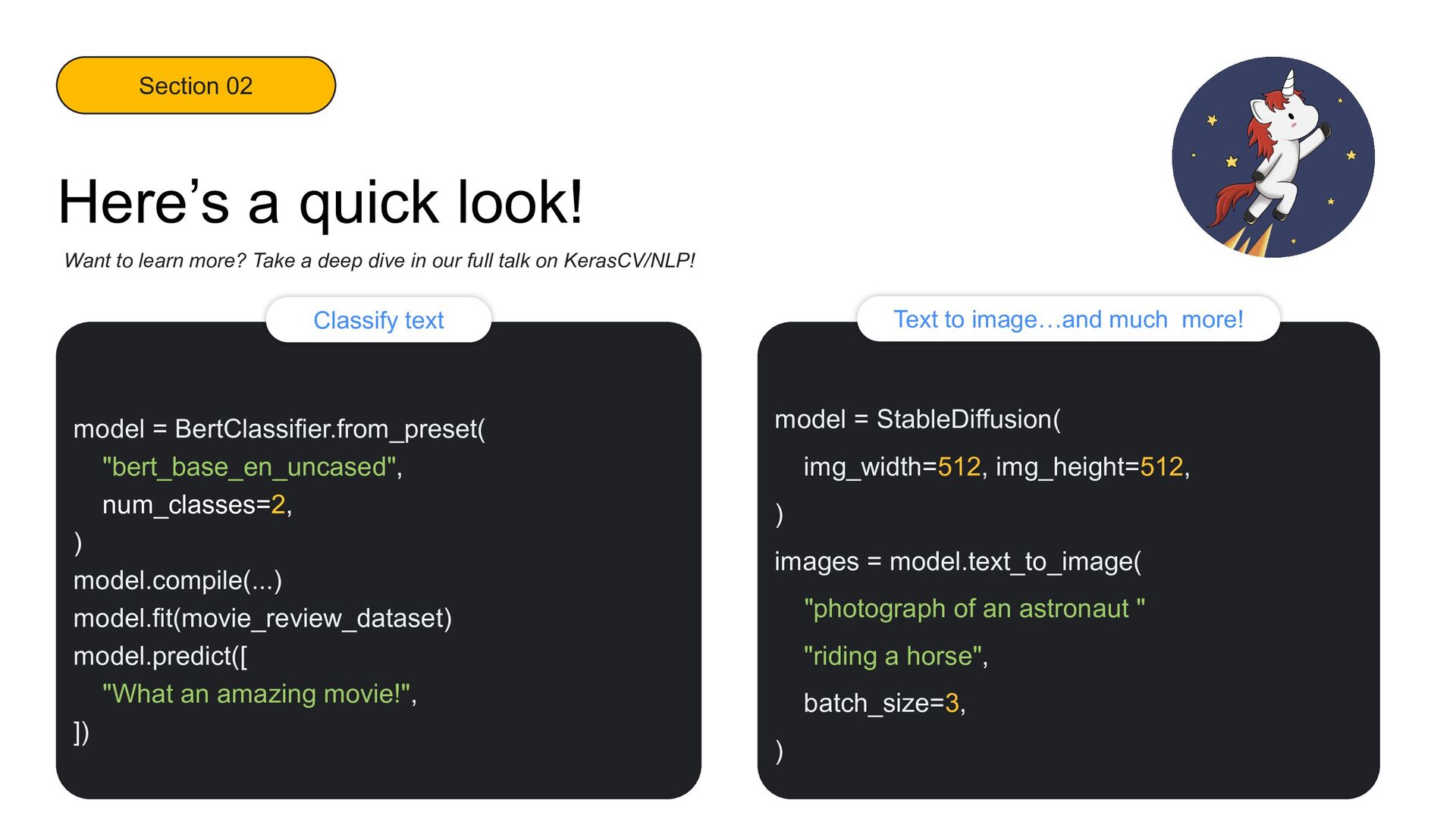
of an astronaut " "riding a horse", batch_size=3, ) model = BertClassifier.from_preset( "bert_base_en_uncased", num_classes=2, ) model.compile(...) model.fit(movie_review_dataset) model.predict([ "What an amazing movie!", ]) Here’s a quick look! Want to learn more? Take a deep dive in our full talk on KerasCV/NLP! Classify text Text to image…and much more! Section 02
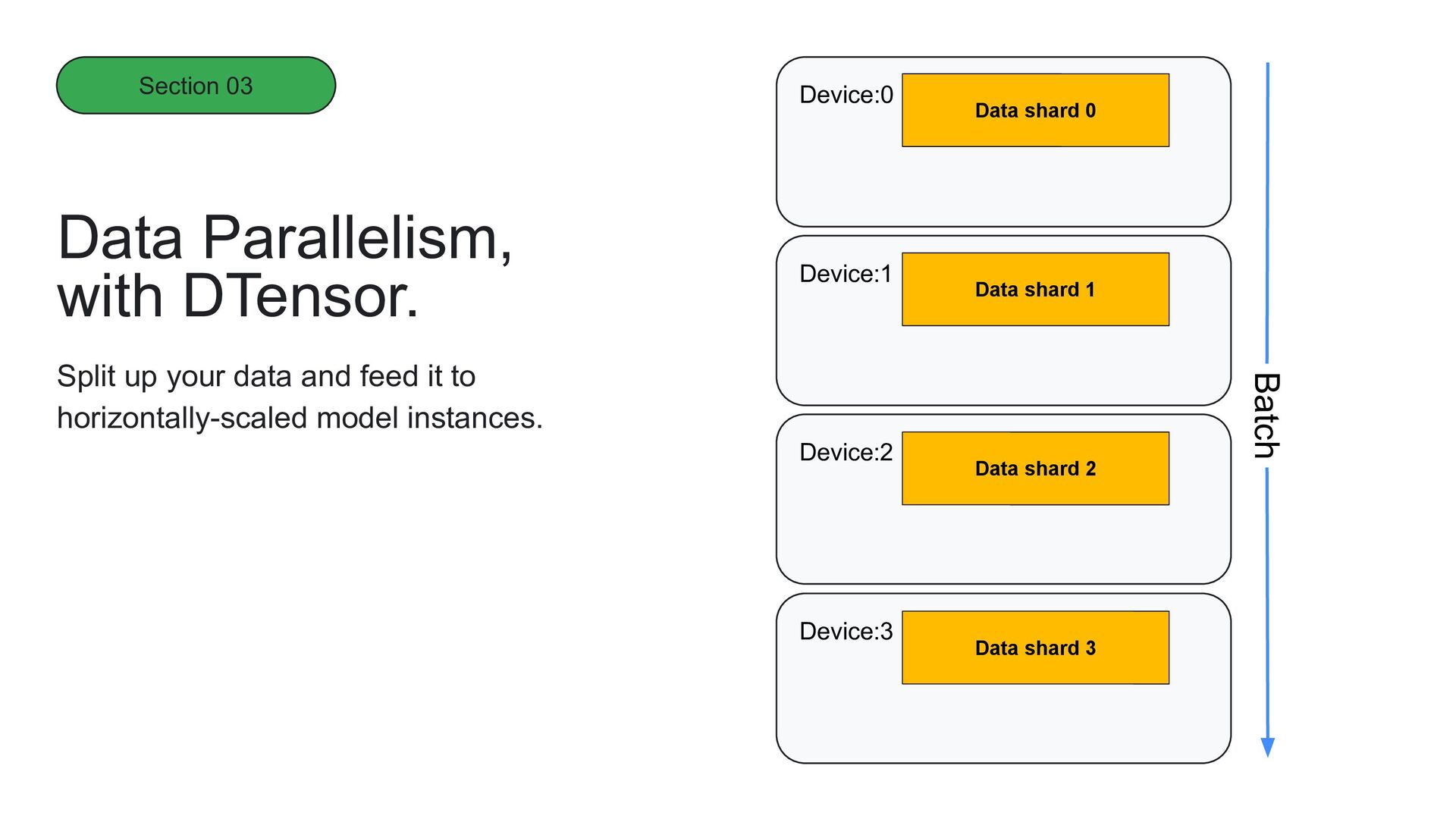
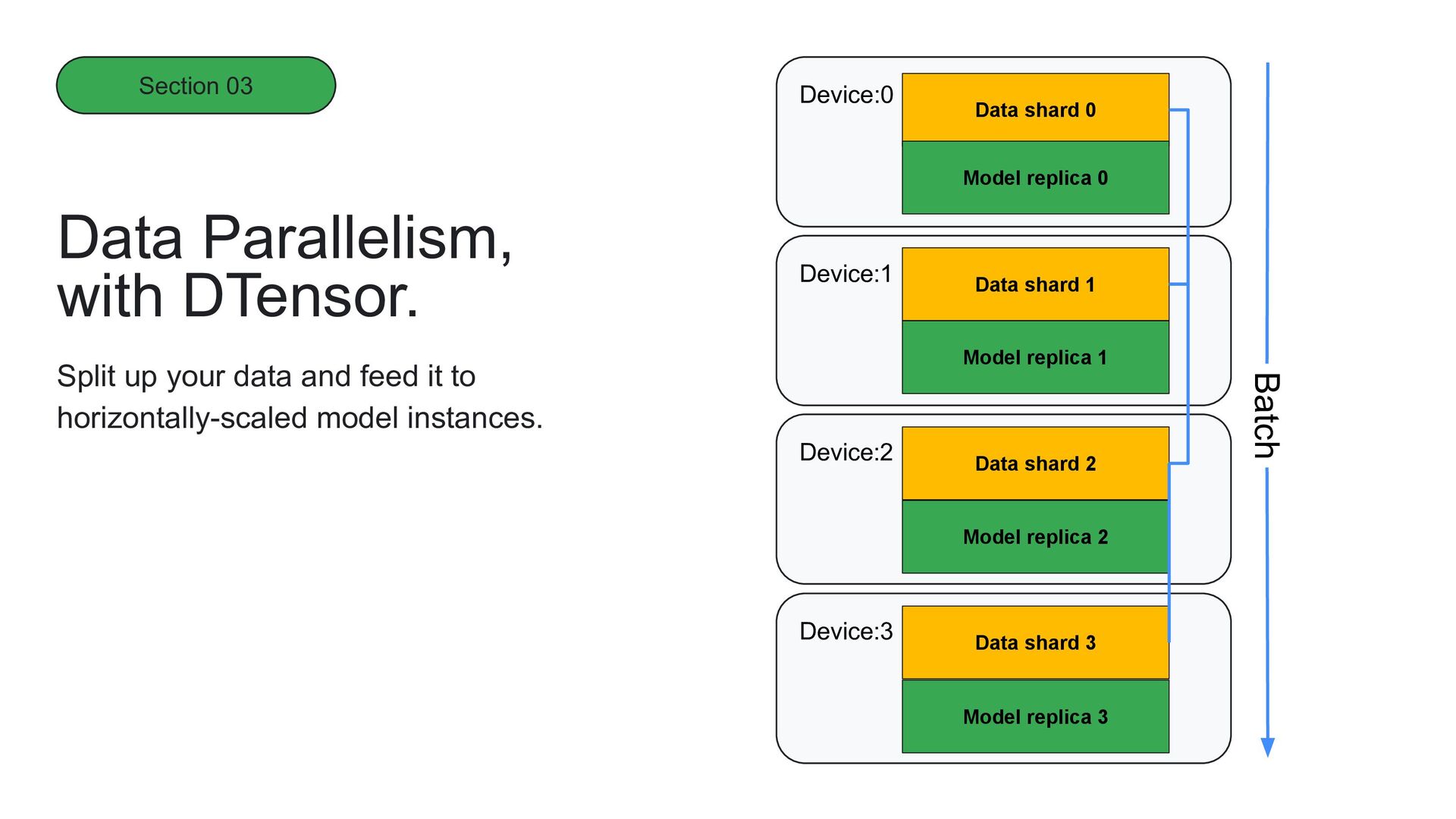
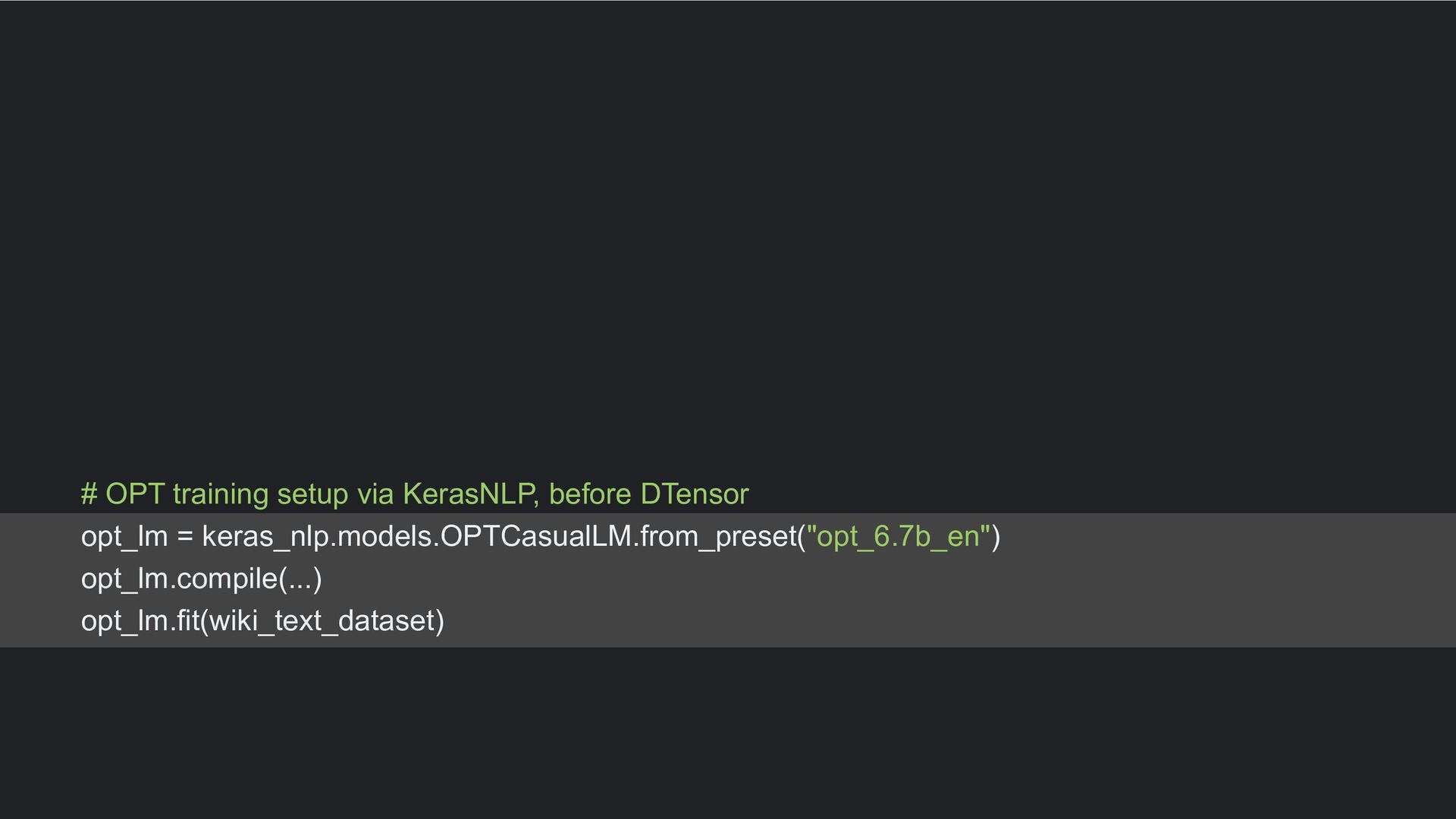
through data parallelism, which splits up your data and feeds it to horizontally-scaled model instances. But it requires that the model fits within a single hardware device. • Across the device: developers need to be able to scale their models across hardware devices. Dtensor
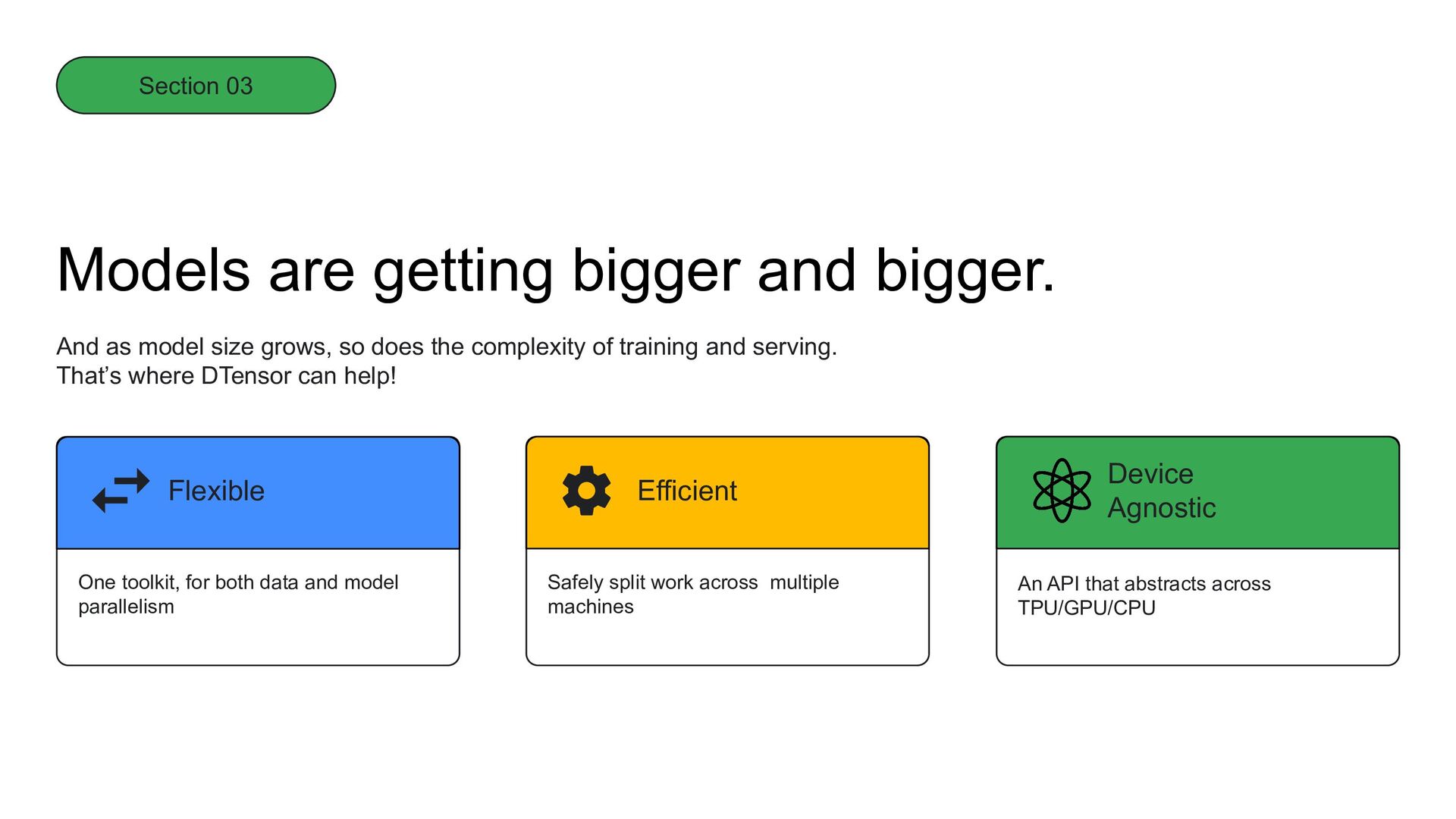
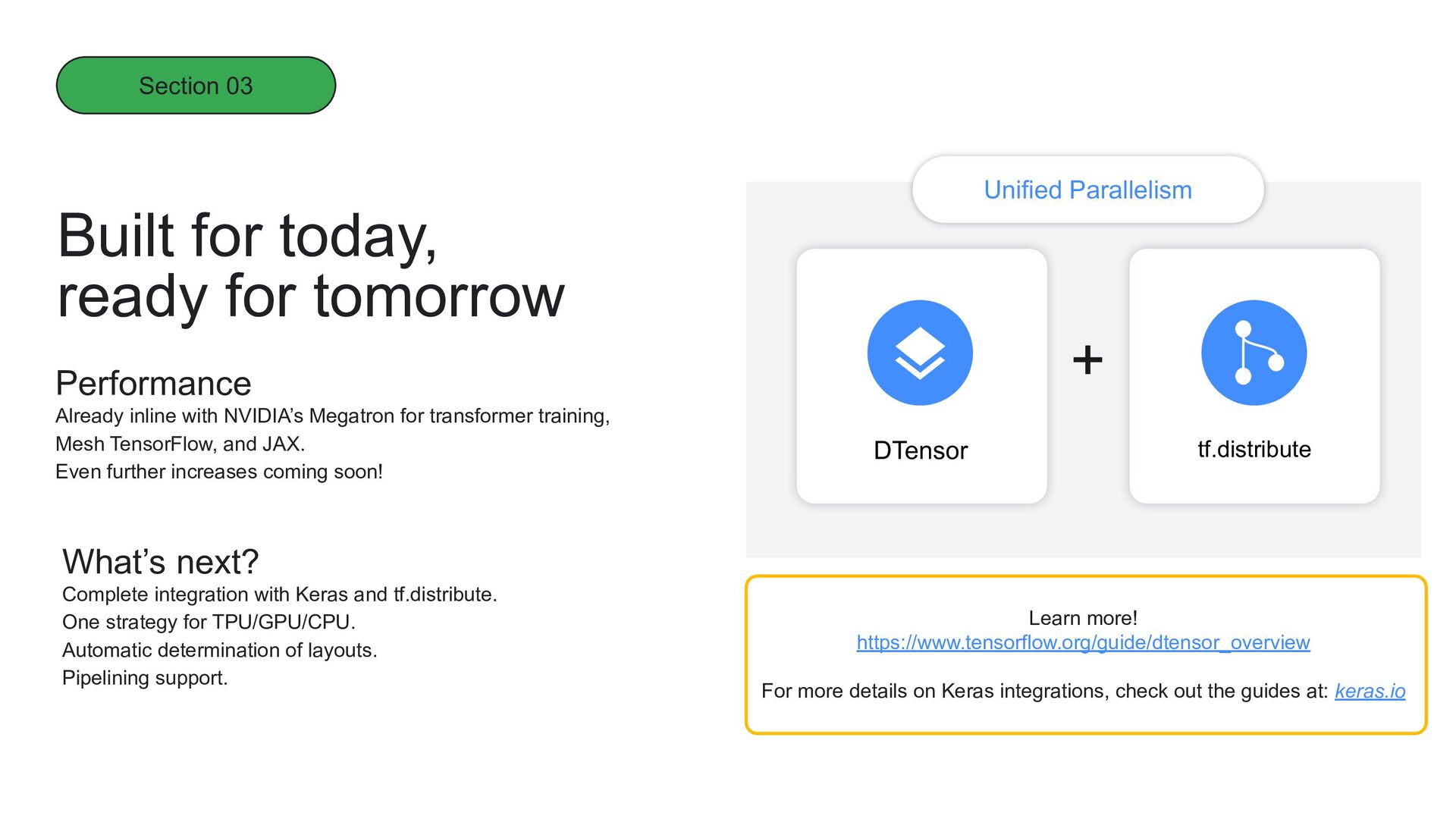
split work across multiple machines Efficient An API that abstracts across TPU/GPU/CPU Device Agnostic Models are getting bigger and bigger. And as model size grows, so does the complexity of training and serving. That’s where DTensor can help! Section 03
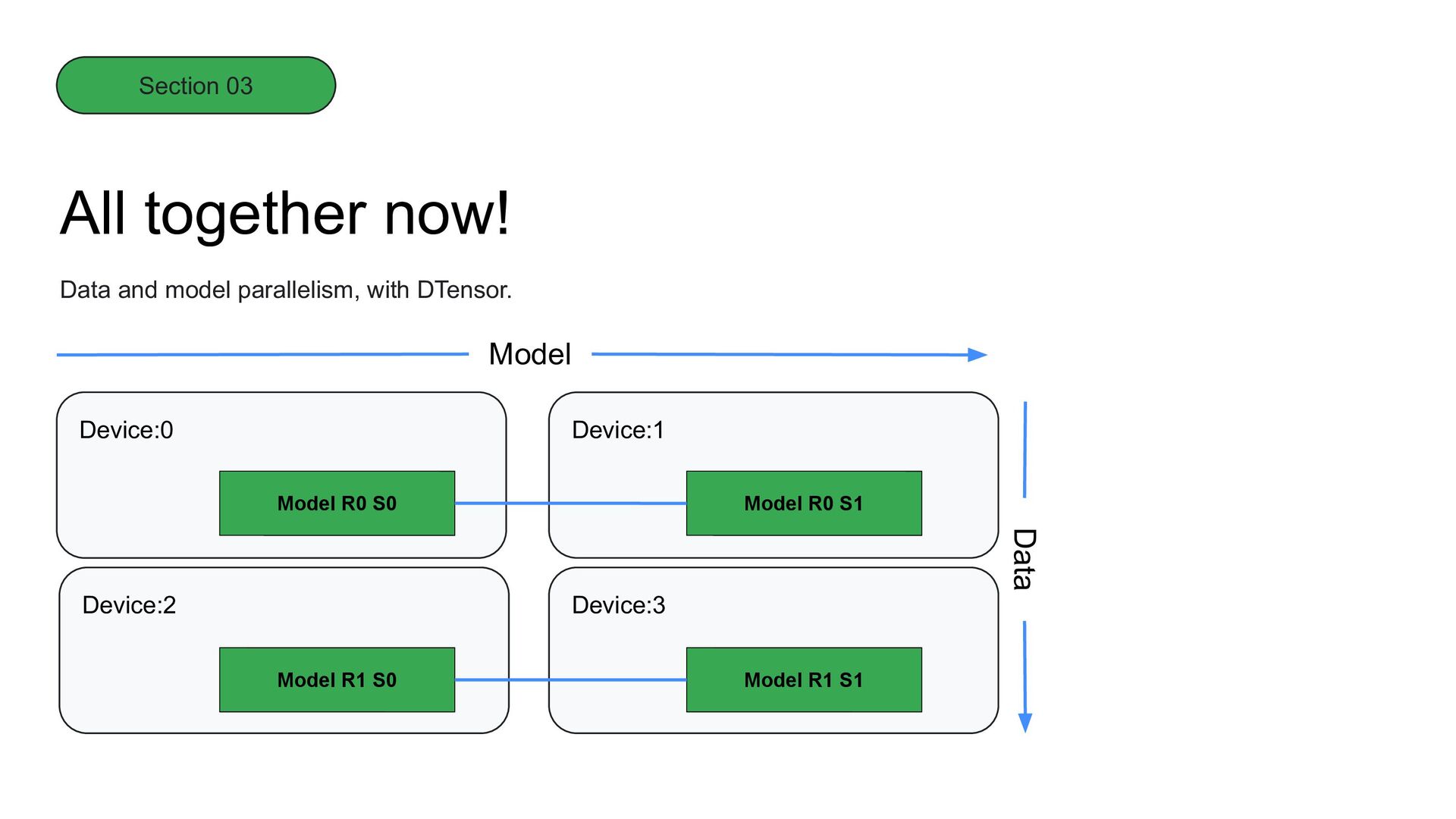
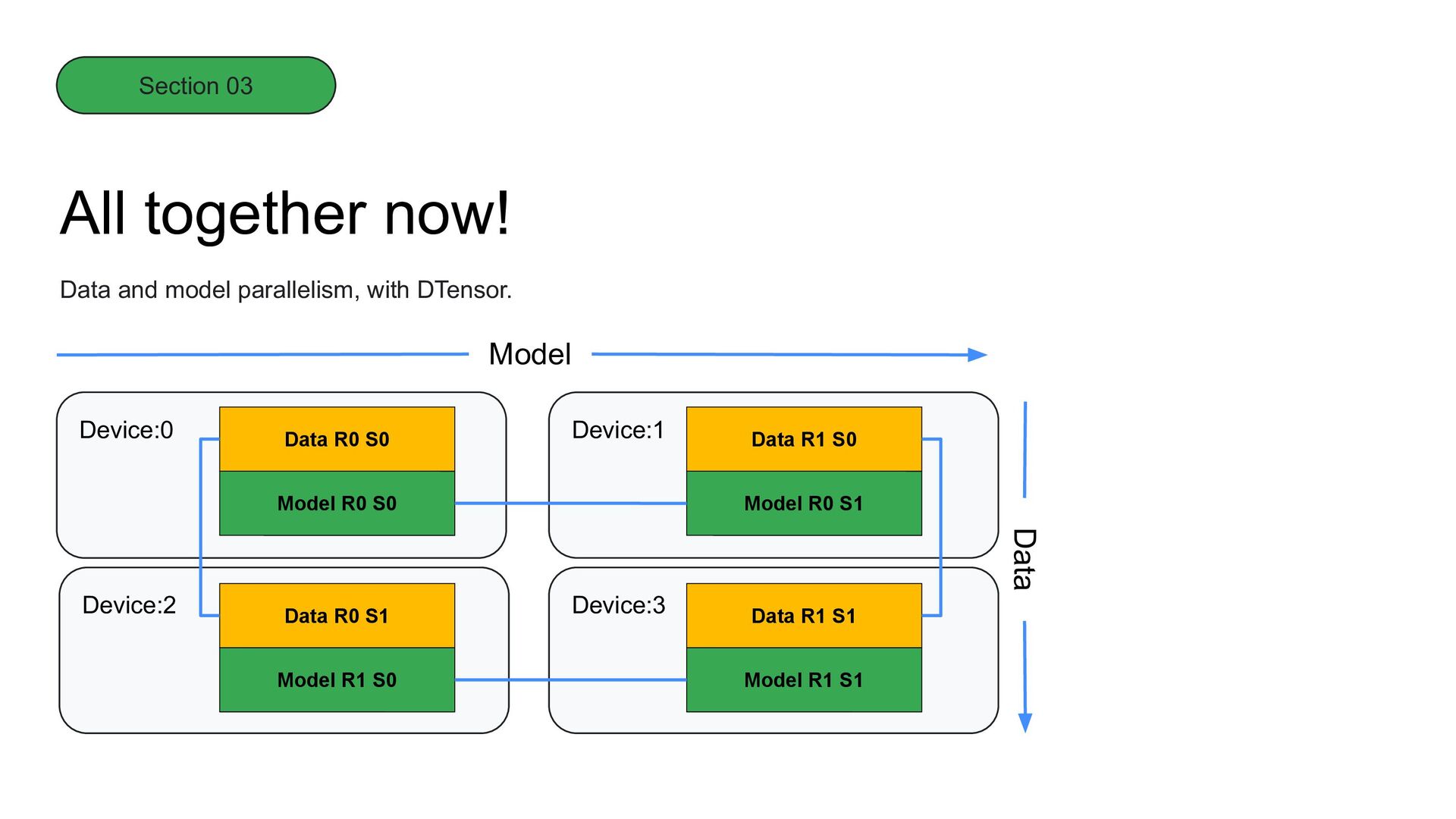
instances. Data Parallelism, with DTensor. Device:0 Device:2 Device:1 Device:3 Data shard 0 Data shard 1 Data shard 3 Data shard 2 Model replica 0 Model replica 1 Model replica 3 Model replica 2 Batch Section 03
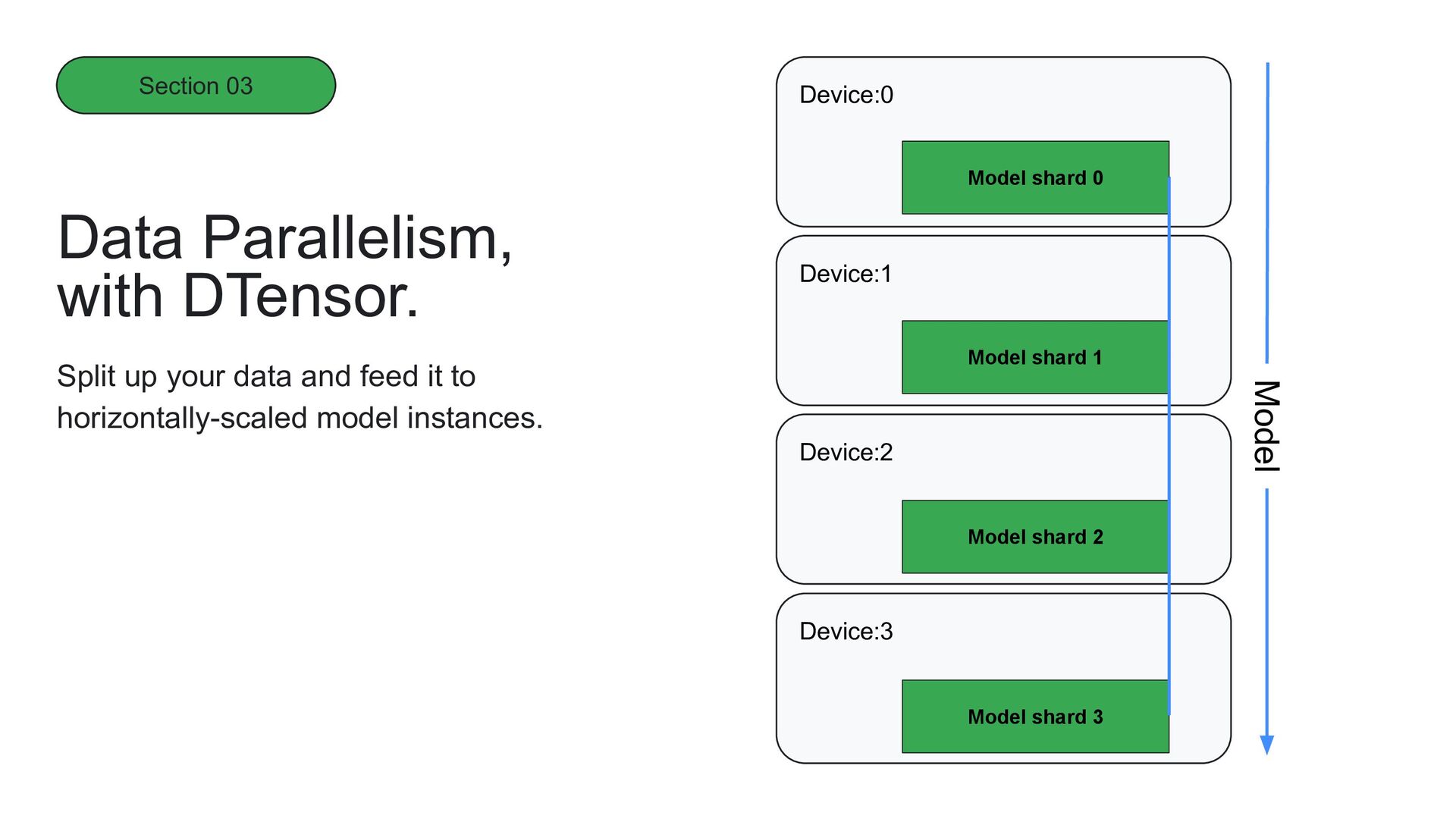
it to horizontally-scaled model instances. Data Parallelism, with DTensor. Model shard 0 Model shard 1 Model shard 3 Model shard 2 Data replica 0 Data replica 1 Data replica 3 Data replica 2 Model Section 03
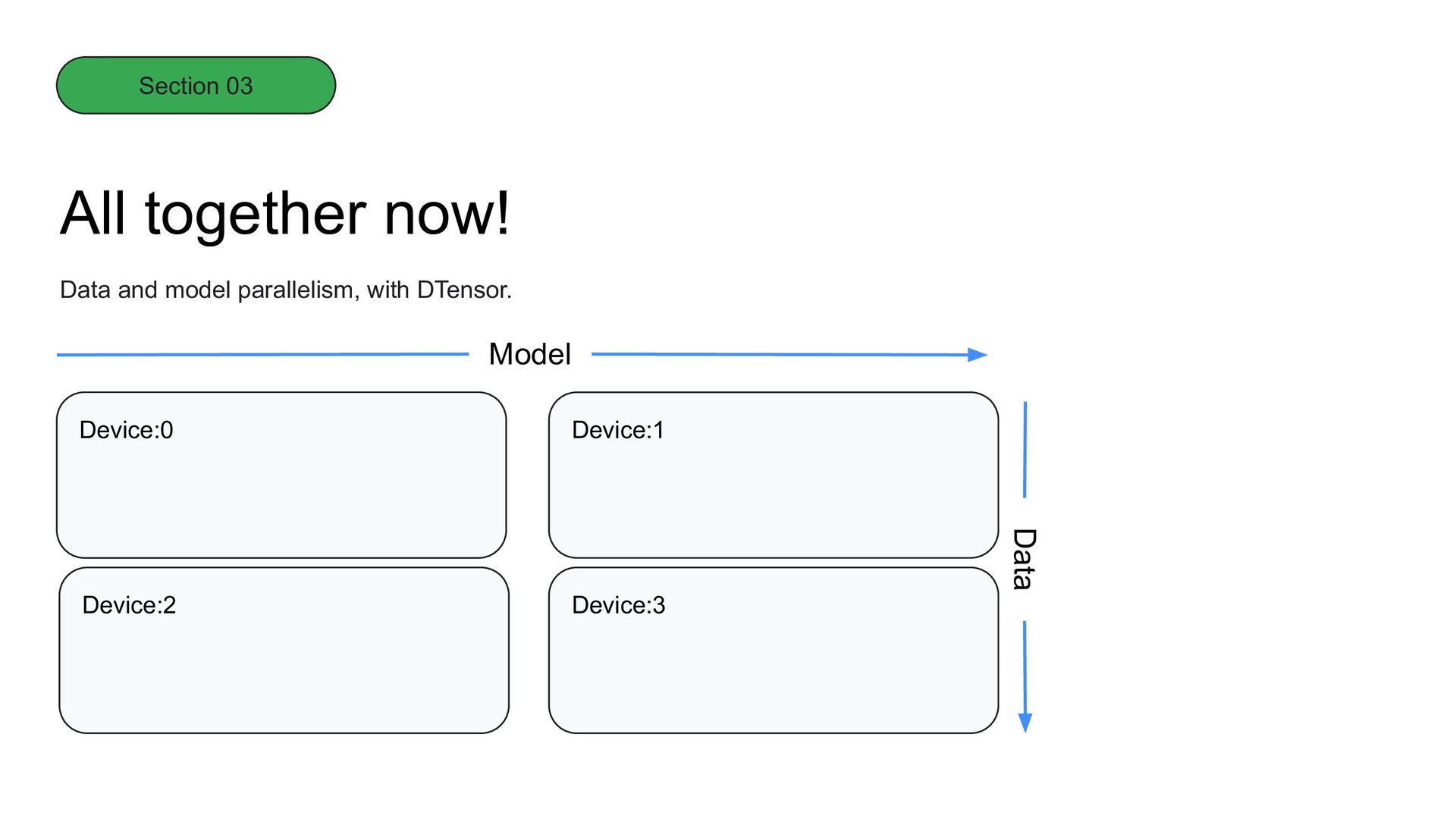
TensorFlow, and JAX. Even further increases coming soon! Learn more! https://www.tensorflow.org/guide/dtensor_overview For more details on Keras integrations, check out the guides at: keras.io What’s next? Complete integration with Keras and tf.distribute. One strategy for TPU/GPU/CPU. Automatic determination of layouts. Pipelining support. DTensor tf.distribute + Unified Parallelism Section 03 Built for today, ready for tomorrow
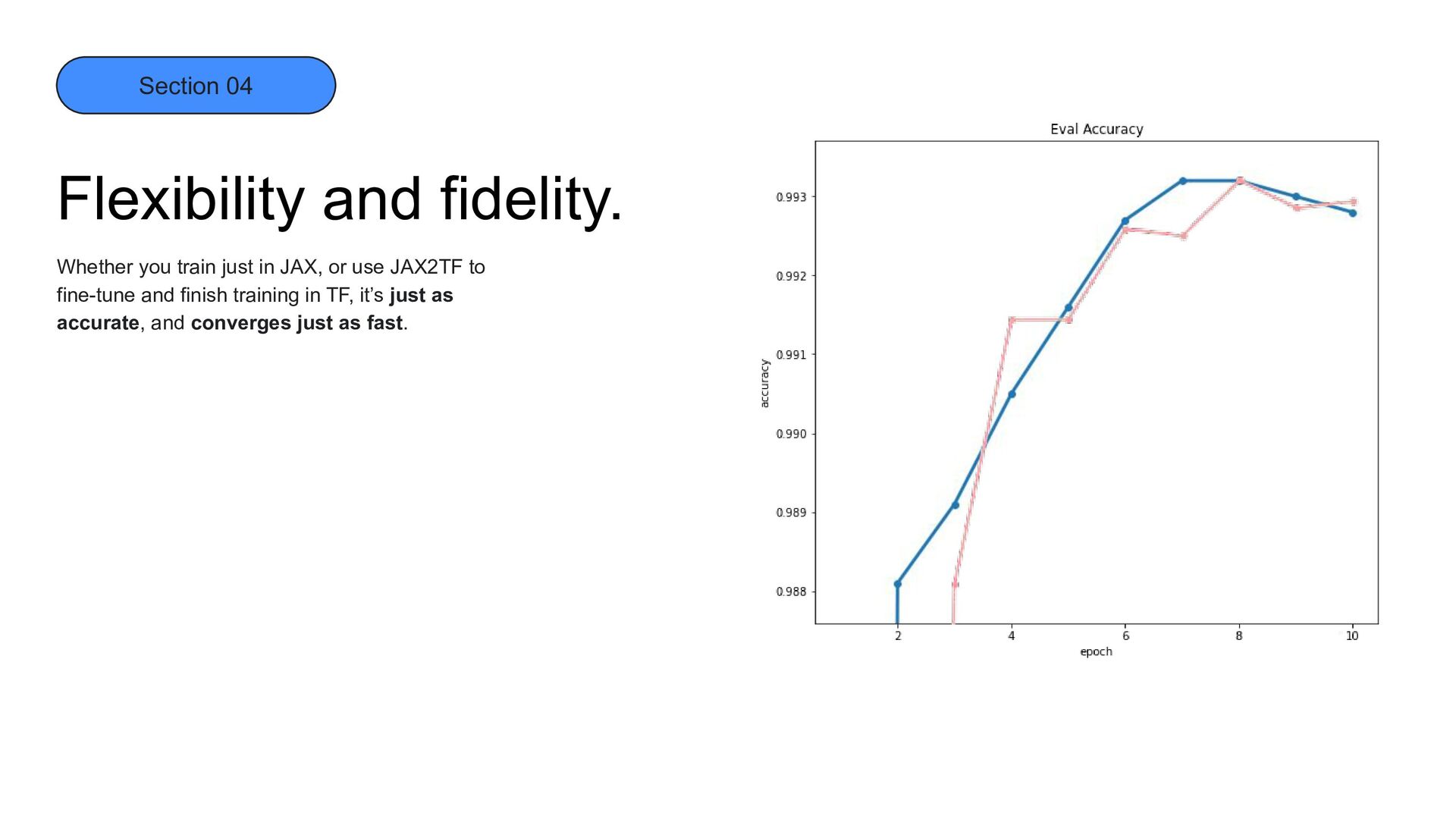
download growth (3 months) Section 04 What’s JAX? An open-source framework for high-performance, ML research. Bringing JAX’s development power into production has been hard – until now.
Quantization API Adjust model size, easily. Smaller models are faster to run and require fewer resources Reduces memory, latency, compute and battery costs Section 05
work, without model rewrites. Easy Introducing the TF Quantization API Adjust model size, easily. Smaller models are faster to run and require fewer resources Reduces memory, latency, compute and battery costs Section 05
Flexible Tools that just work, without model rewrites. Easy Reduced memory, latency, compute and battery costs Efficient Introducing the TF Quantization API Adjust model size, easily. Smaller models are faster to run and require fewer resources Reduces memory, latency, compute and battery costs Section 05
model! tf.quantization.apply_quantization_on_model(model, config_map, …) # From here, you can train and save just as always. model.fit() model.save() # You can also export to TFLite, without any changes! converter = tf.lite.TFLiteConverter.from_keras_model(model) converter.optimizations = [tf.lite.Optimize.DEFAULT] tflite_model = converter.convert()
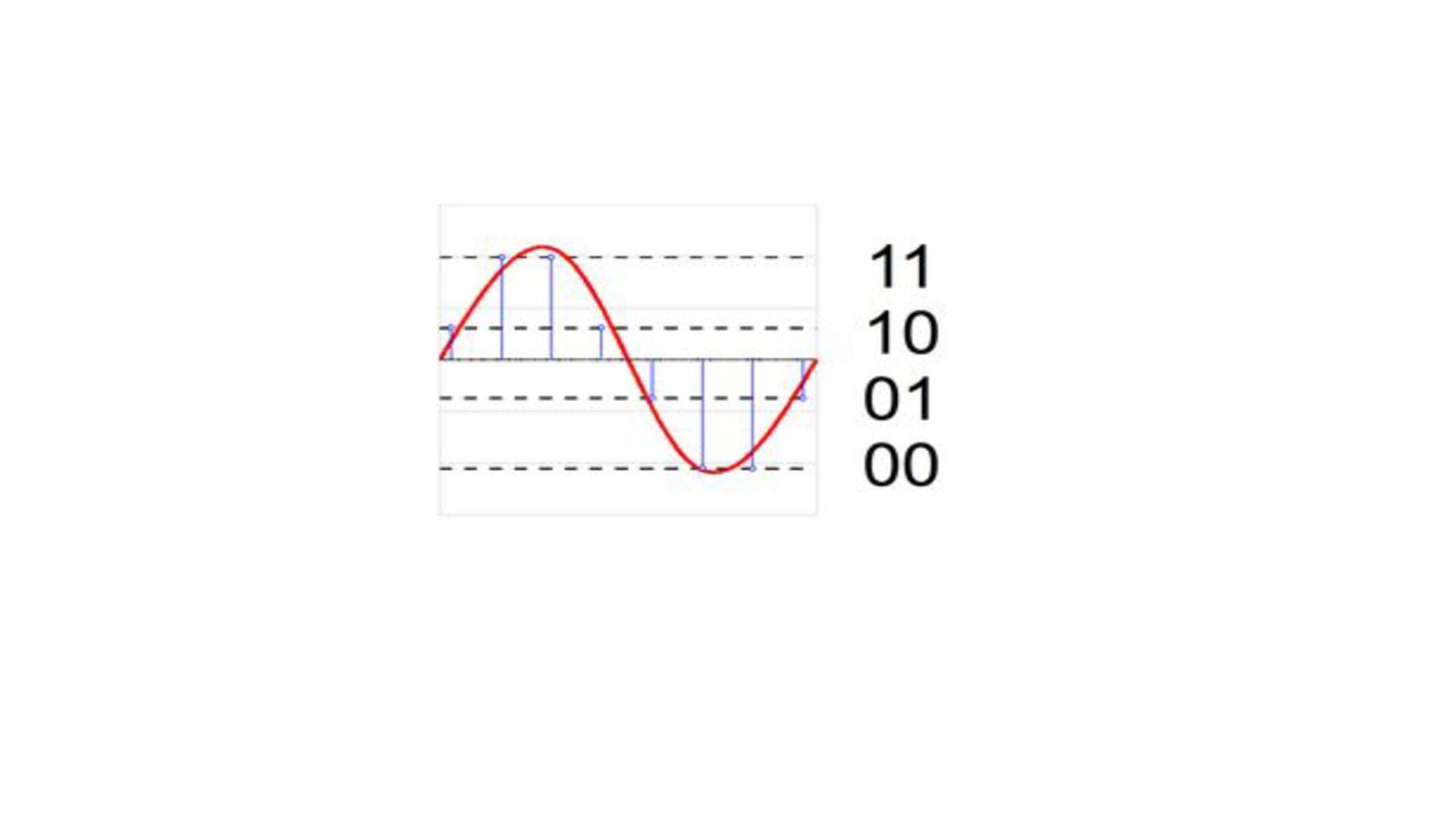
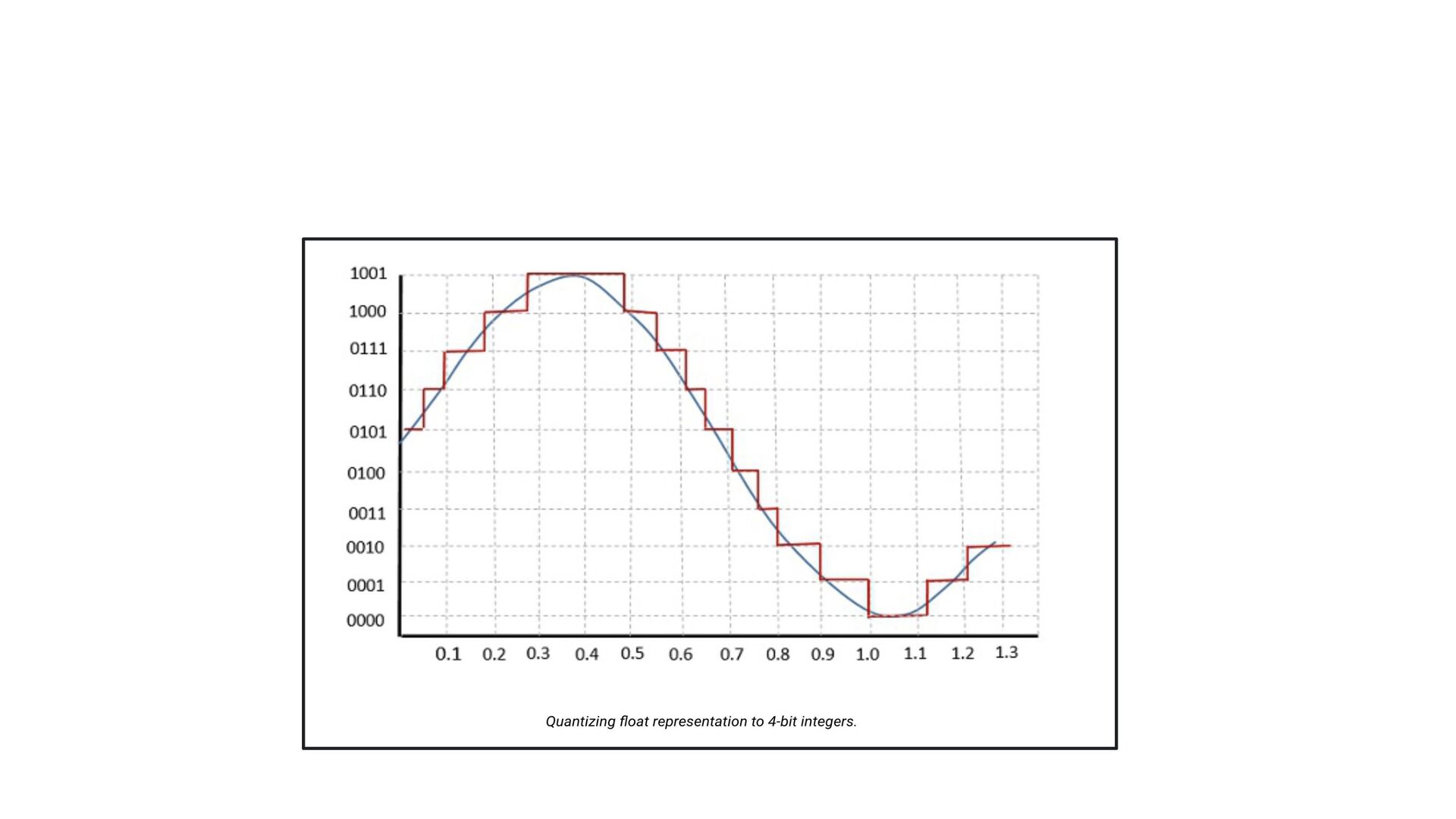
training. This is as simple as it gets and most readily accessible, but there can be a small quality drop. • Quantization-Aware Training (QAT): Simulate quantization during just the forward pass, providing for maximal flexibility with a minimal quality tradeoff. • Quantized Training: Quantize all computations while training. This is still nascent, and needs a lot more testing, but is a powerful tool we want to make sure TensorFlow users have access to. Quantization
MobileNetV2. Model: MobileNetV2 Device: Pixel 7 Serving throughput vs. float32 CPU baseline: CPU with XNNPack (1 thread): 2.24x Edge-TPU: 16.56x Performance and quality Section 05
MobileNetV2. Model: MobileNetV2 Device: Pixel 7 Serving throughput vs. float32 CPU baseline: CPU with XNNPack (1 thread): 2.24x Edge-TPU: 16.56x All without noticeable detriment to accuracy. float32: 73% int8: Still 73%! Performance and quality. Section 05
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![# DTensor-enabled training! mesh_dims = [("batch", 2), ("model", 4)] mesh](https://files.speakerdeck.com/presentations/968a983614c14c849b208c90f7931415/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}