length, not a big problem! Case 2: Read length ≅ Repeat length, Assembly problem is NP Hard, (Nagarajan and Pop, 2009) Case 3: Read length < Repeat length, # assemblies exponential in # repeats (Kingsford et al. 2010) 8/23/16 2
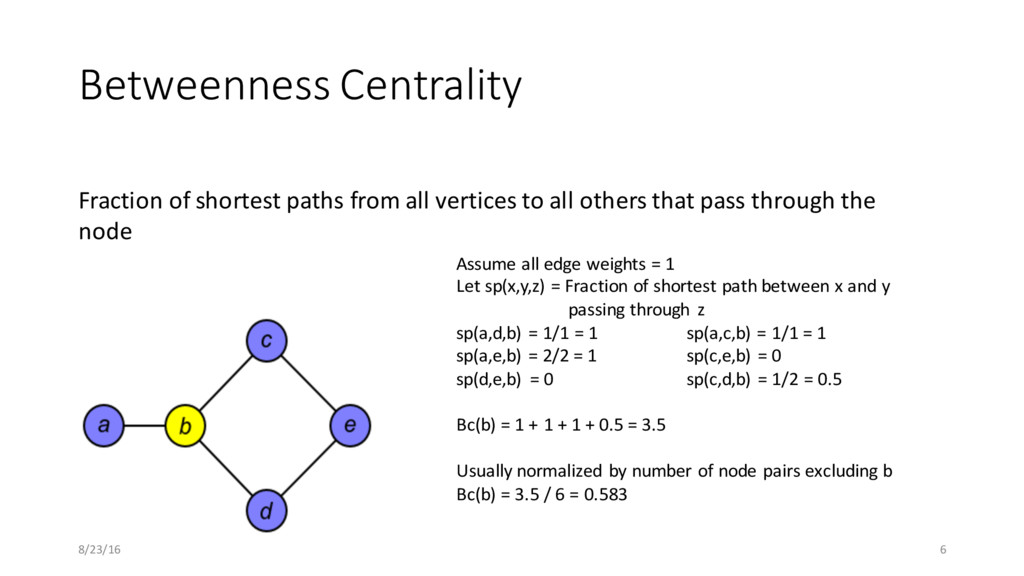
Let sp(x,y,z) = Fraction of shortest path between x and y passing through z sp(a,d,b) = 1/1 = 1 sp(a,c,b) = 1/1 = 1 sp(a,e,b) = 2/2 = 1 sp(c,e,b) = 0 sp(d,e,b) = 0 sp(c,d,b) = 1/2 = 0.5 Bc(b) = 1 + 1 + 1 + 0.5 = 3.5 Usually normalized by number of node pairs excluding b Bc(b) = 3.5 / 6 = 0.583 Fraction of shortest paths from all vertices to all others that pass through the node
number of nodes and n is number of edges (Brandes) • Sampling algorithm for speed ups • Parallelized algorithm by sampling shortest paths in the graph (Riondato, 2014) • Runs in O(|m| + |n|) for unweighted graphs and in O(|n|+ |m|log(|m|)) on weighted graphs 8/23/16 8
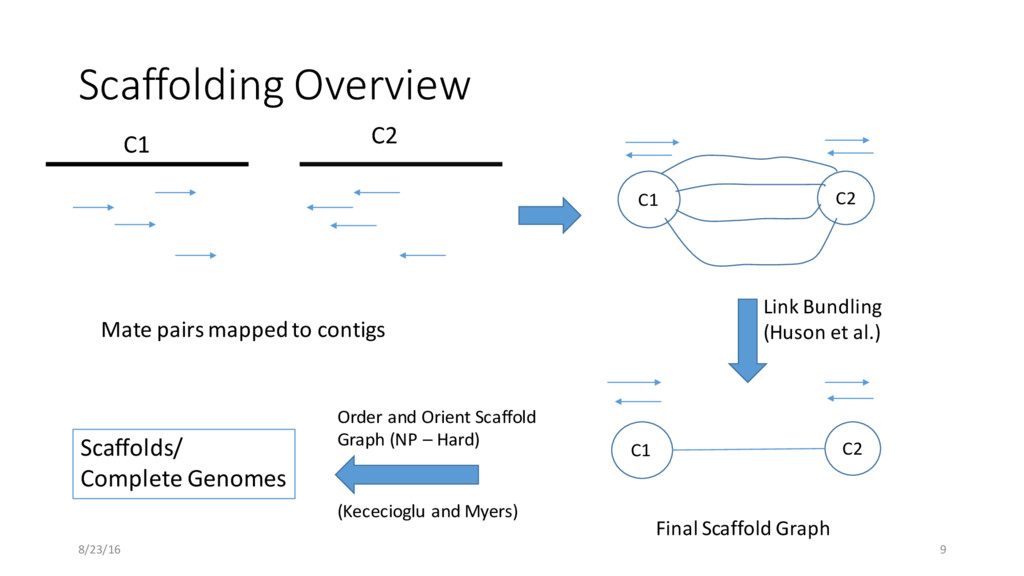
C2 C1 C2 Link Bundling (Huson et al.) Final Scaffold Graph 8/23/16 9 Order and Orient Scaffold Graph (NP – Hard) (Kececioglu and Myers) Scaffolds/ Complete Genomes
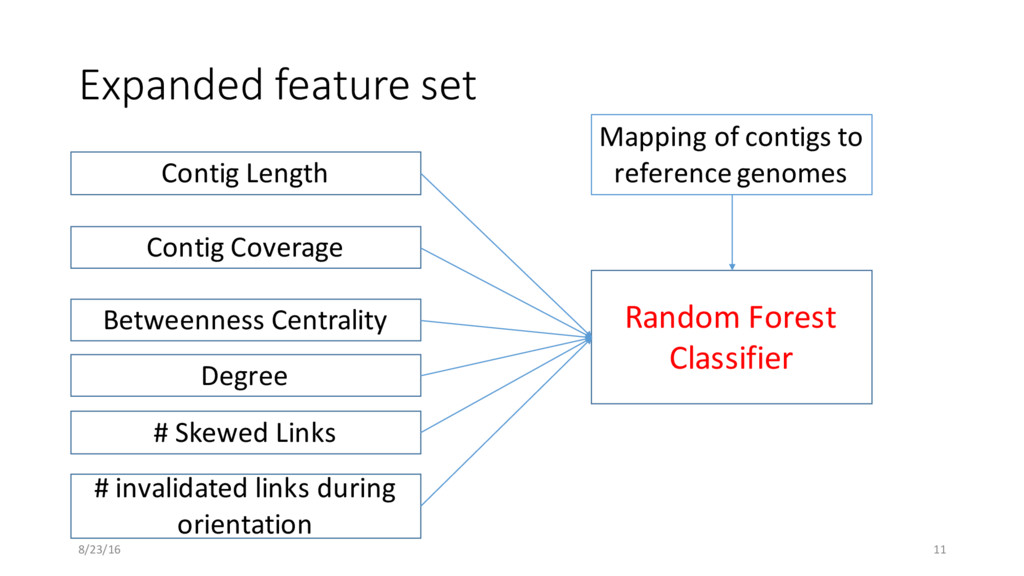
values for all the contigs • Let μ be the mean and be the standard deviation of centrality values • Mark contigs with centrality value greater than μ + 3* as repeats • Same as Bambus2 but much faster centrality detection 8/23/16 10
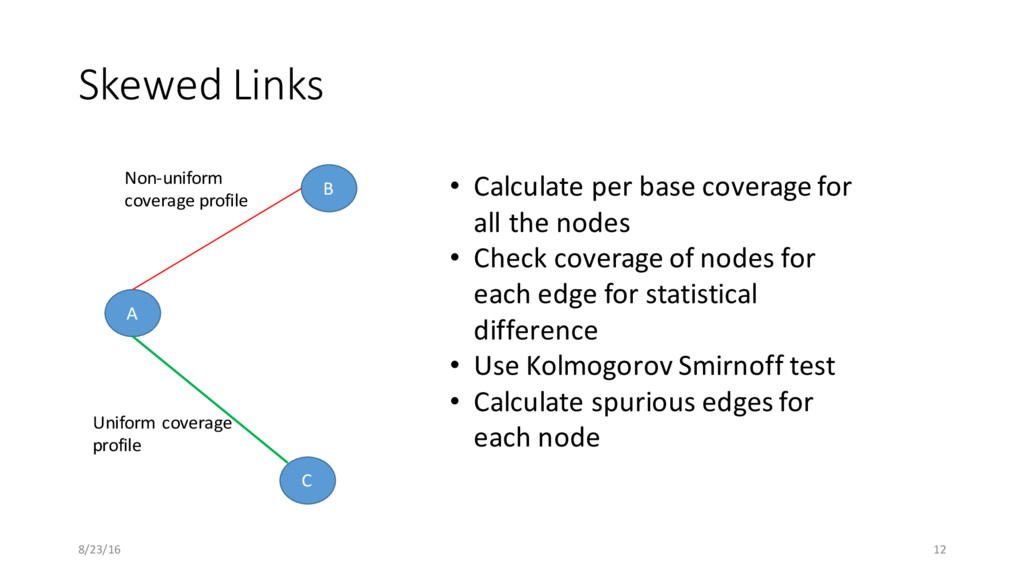
base coverage for all the nodes • Check coverage of nodes for each edge for statistical difference • Use Kolmogorov Smirnoff test • Calculate spurious edges for each node Non-uniform coverage profile Uniform coverage profile
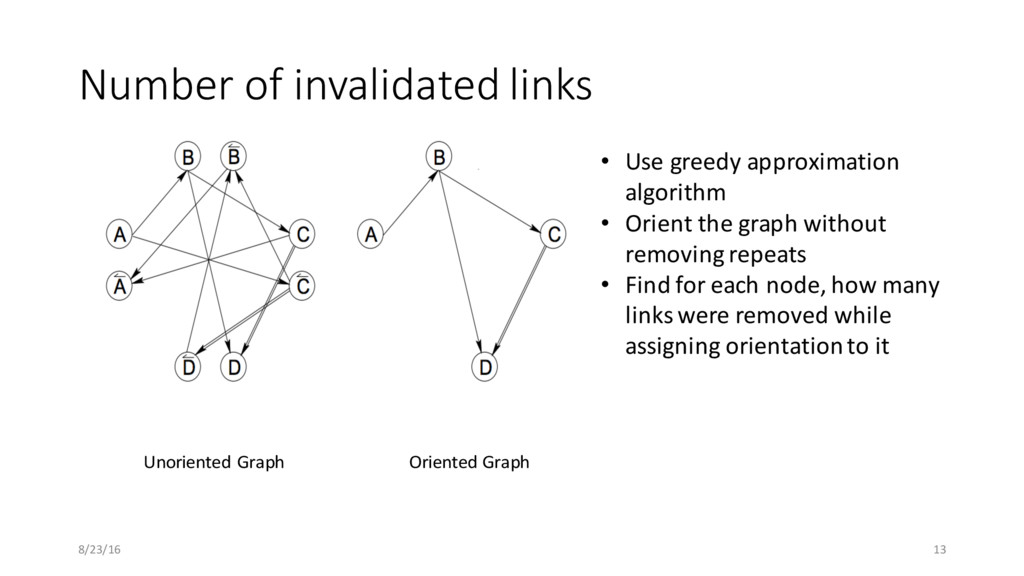
• Use greedy approximation algorithm • Orient the graph without removing repeats • Find for each node, how many links were removed while assigning orientation to it
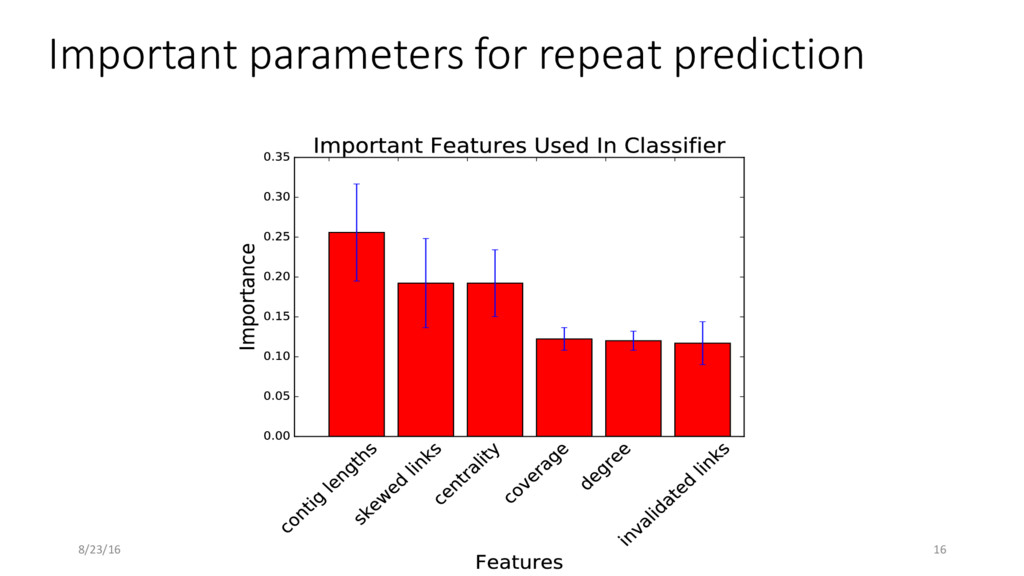
organisms with known genomes (Shakya et al.) • Used IDBA-UD with default parameters for assembly resulting in 47,767 contigs • For training classifier, used simulated data for the set 40 genomes • Trained a random forest classifier on the features obtained from simulated data 8/23/16 14
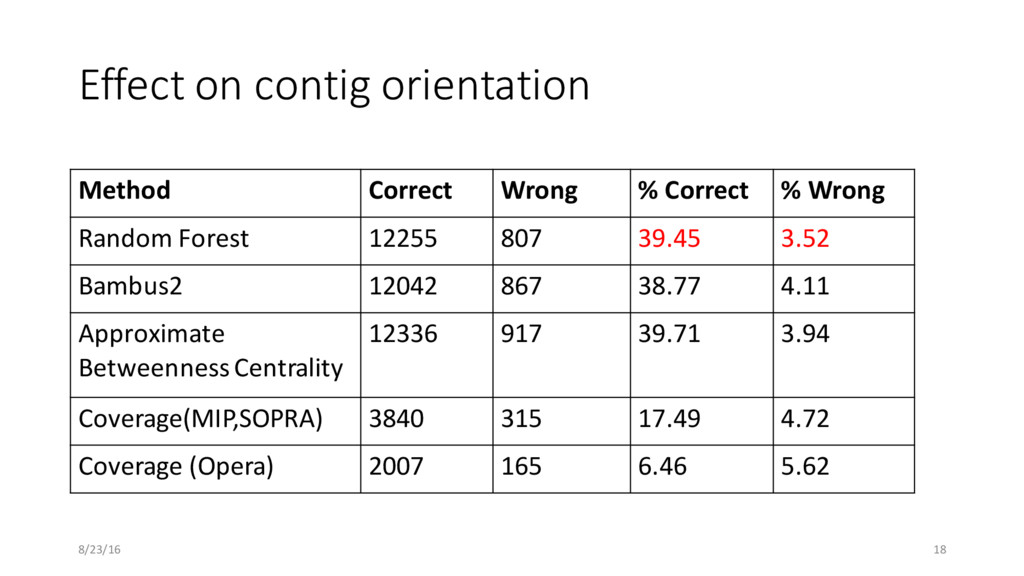
scaffolding process? • Removed repeats from the scaffold graph and oriented it • Evaluated using two metrics: • % correct = # links with right orientation / # links in the original graph • % wrong = # links with wrong orientation / # links in repeat removed graph 8/23/16 17
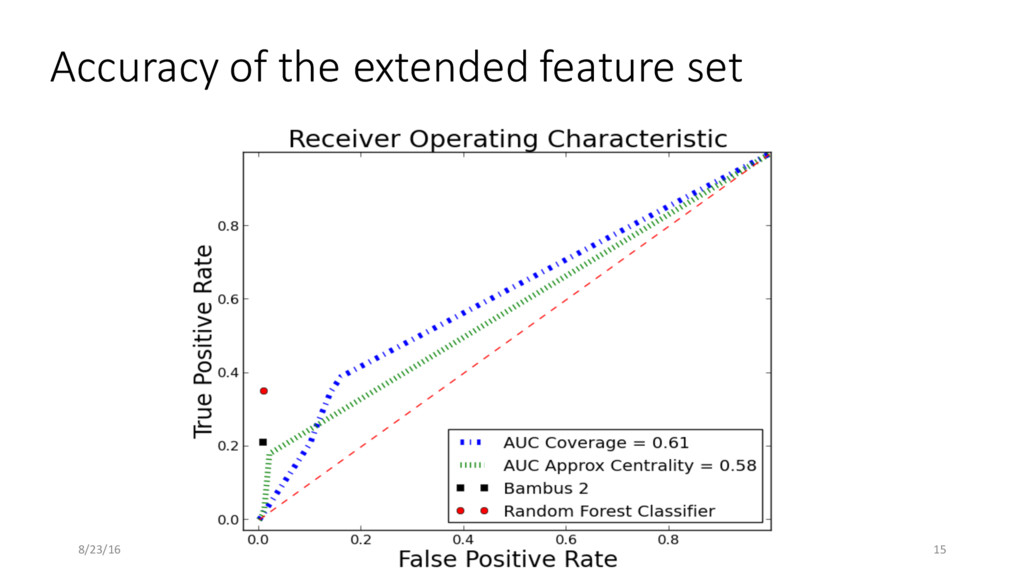
extended feature set • Used approximate betweenness centrality for speedups • Achieved accuracy and efficiency over previous methods • Plan to incorporate repeat detection in MetAMOS pipeline 8/23/16 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![8/23/16 20 Thank you [email protected] [email protected]](https://files.speakerdeck.com/presentations/106223751b0e4bc9840ac2c9ec49131e/slide_19.jpg){kind=link}