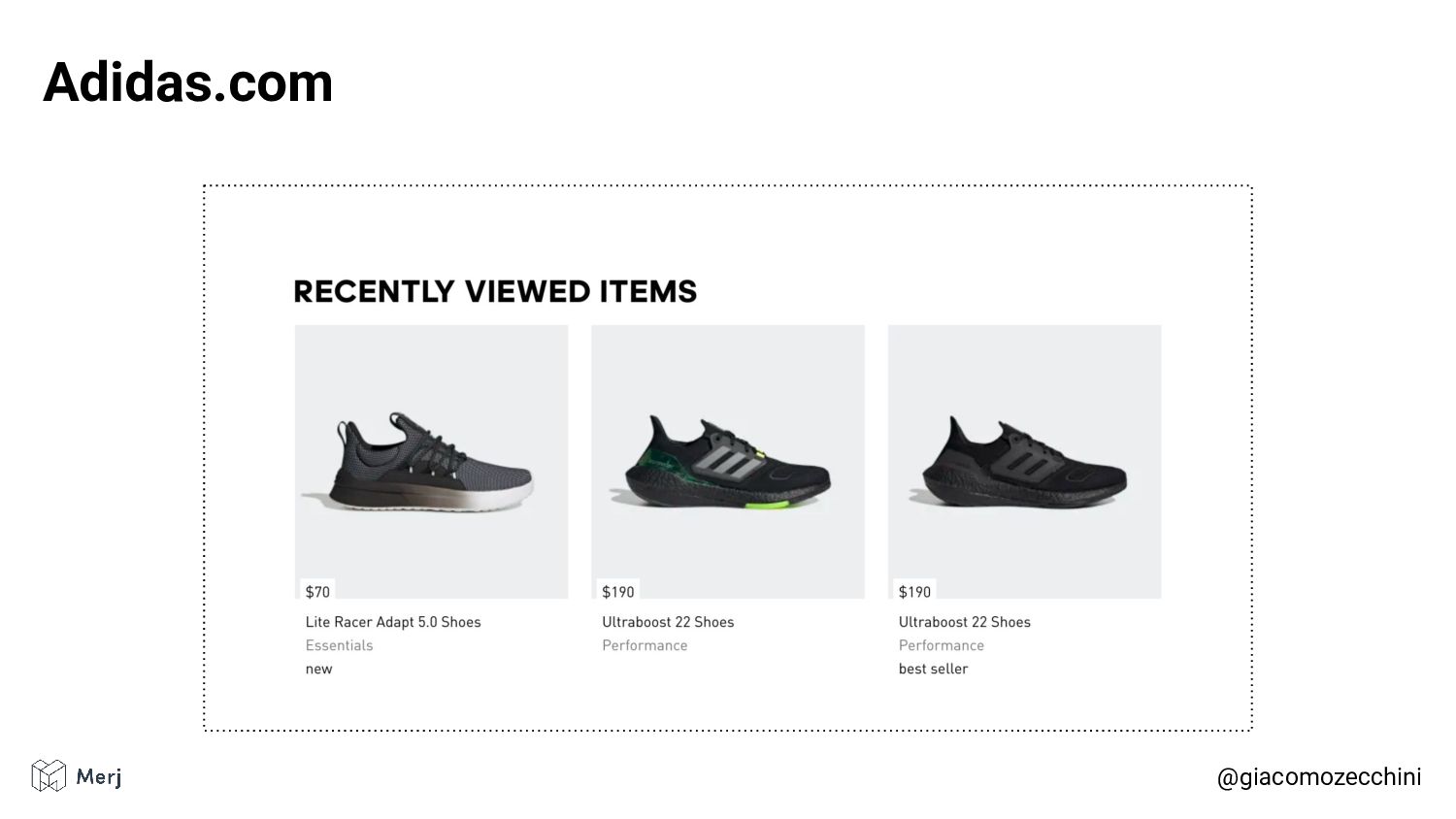
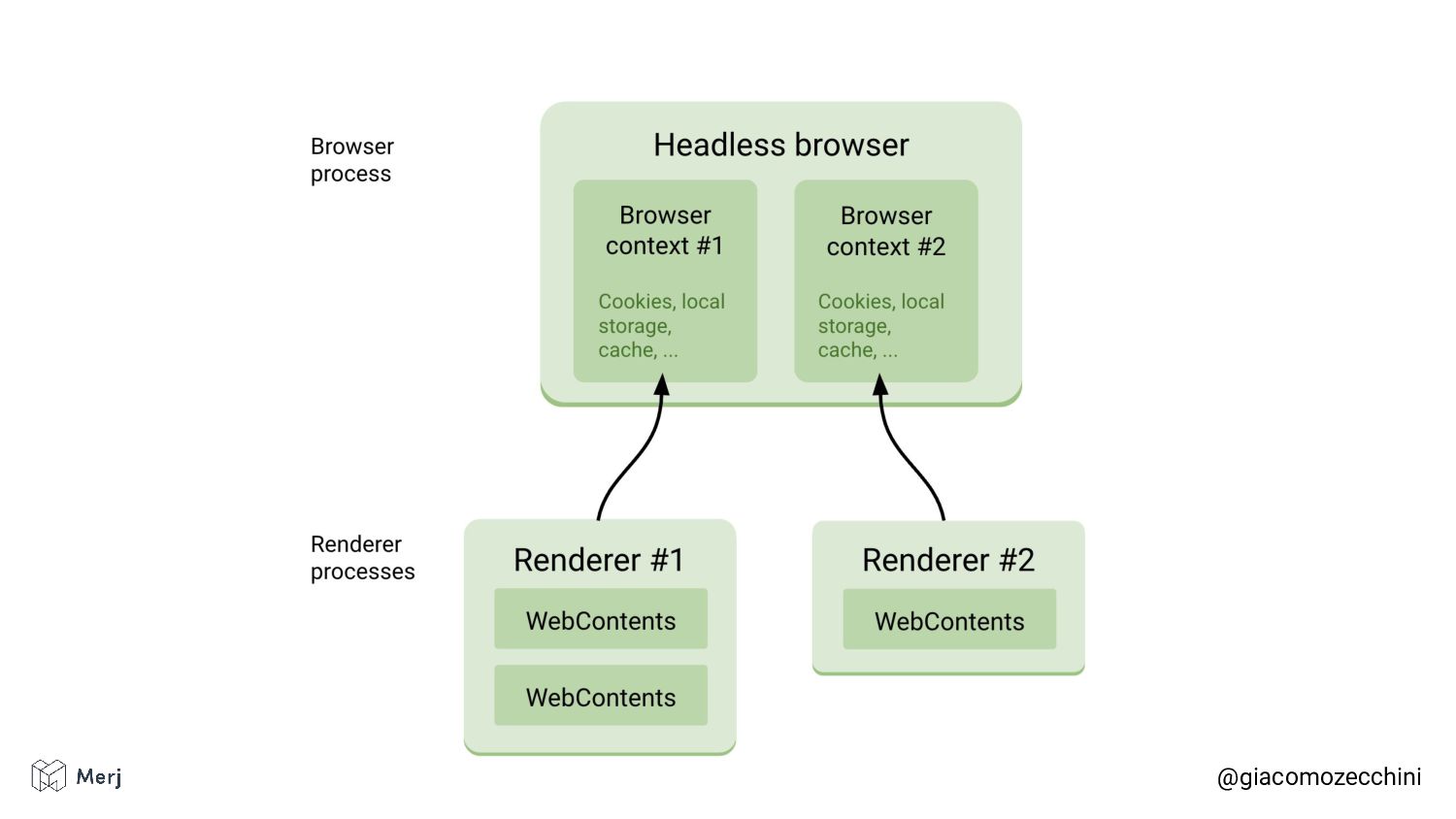
Deep dive into session isolation and why search engines render pages in isolated rendering sessions to avoid having the rendering of one web page affect the functionality or the content of another.
Web crawling tools aim to replicate search engines' crawling and rendering behaviours by implementing and using web rendering systems. This offers insights into what search engines might see when they are crawling and rendering web pages.
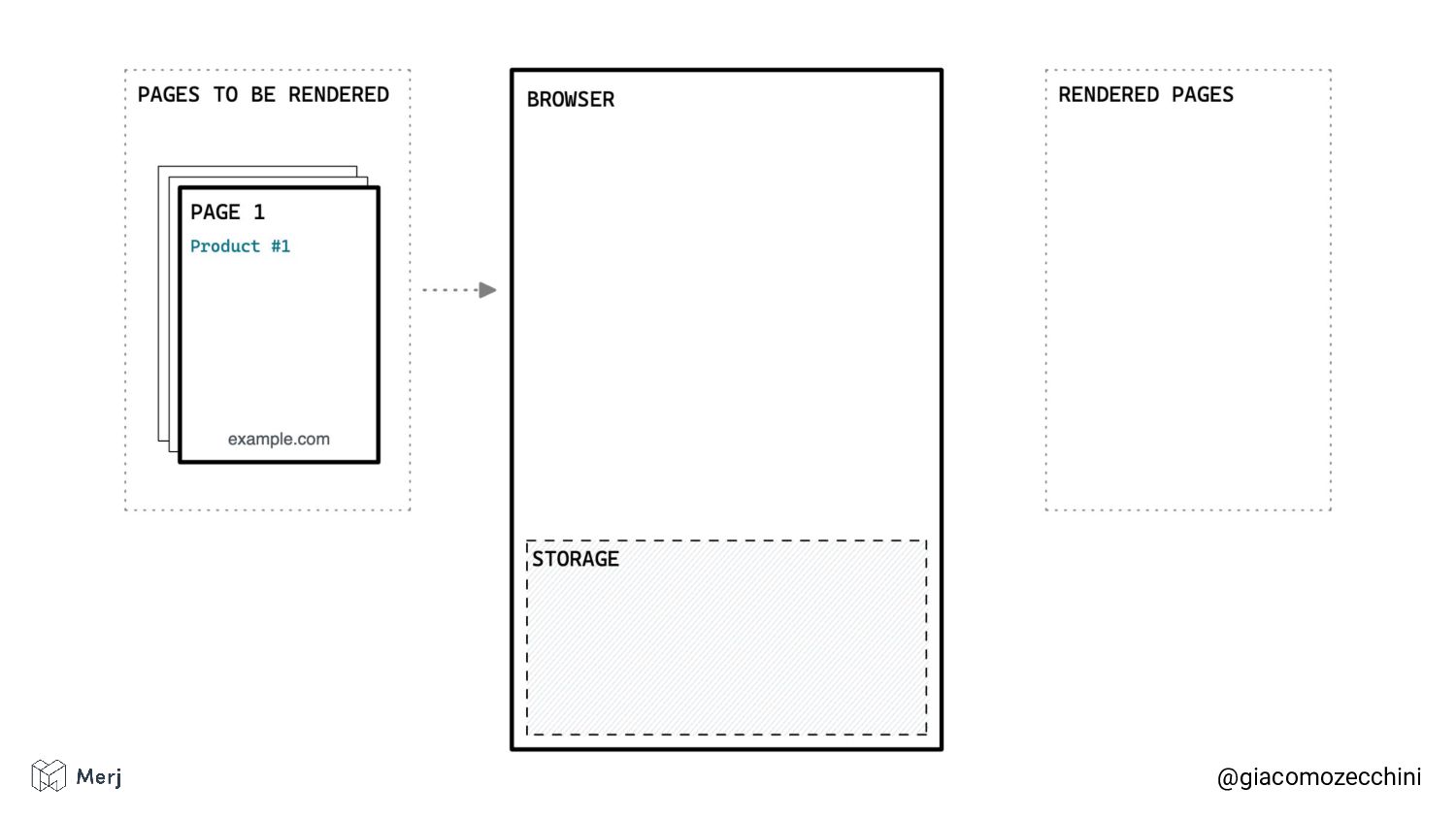
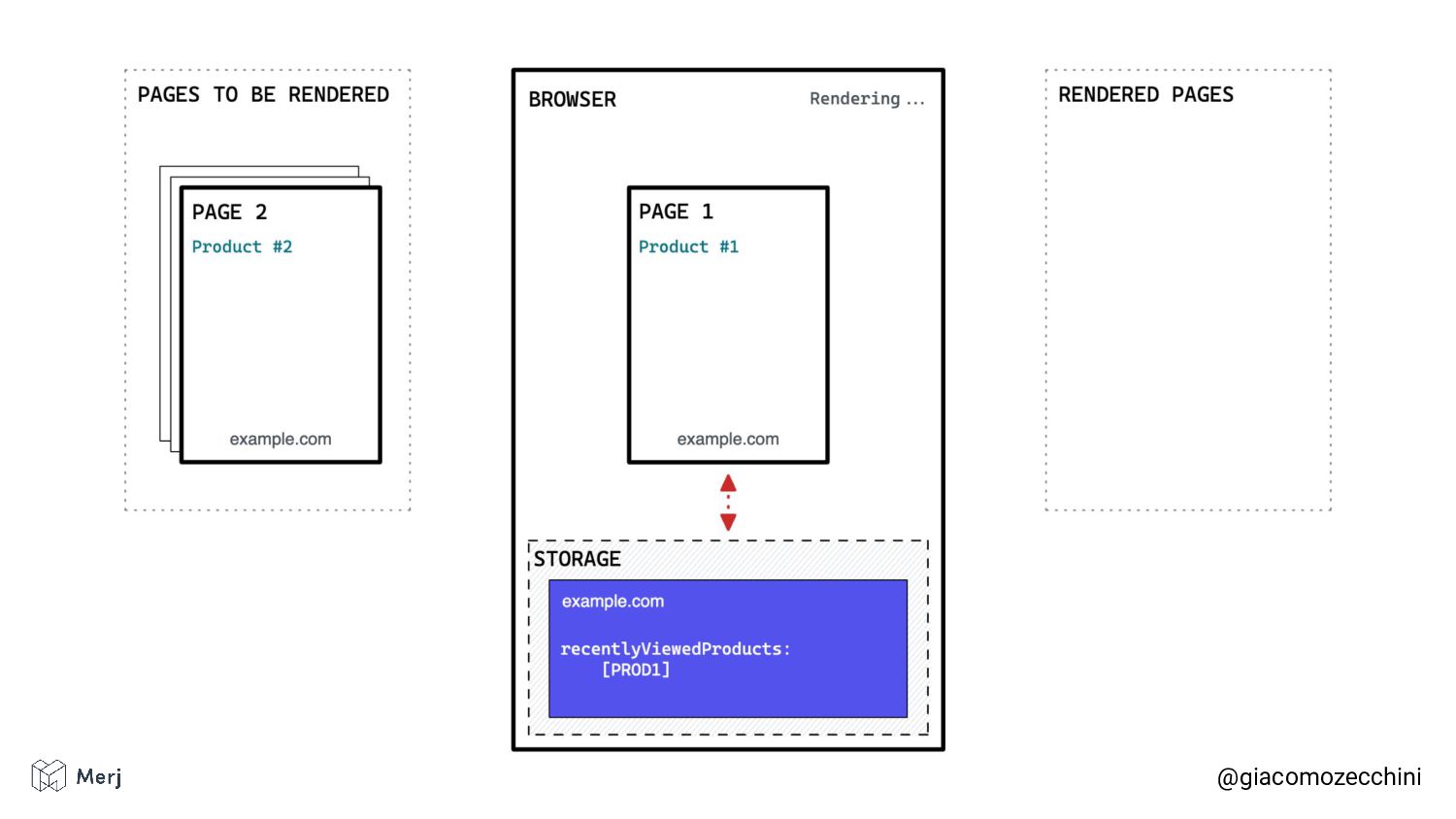
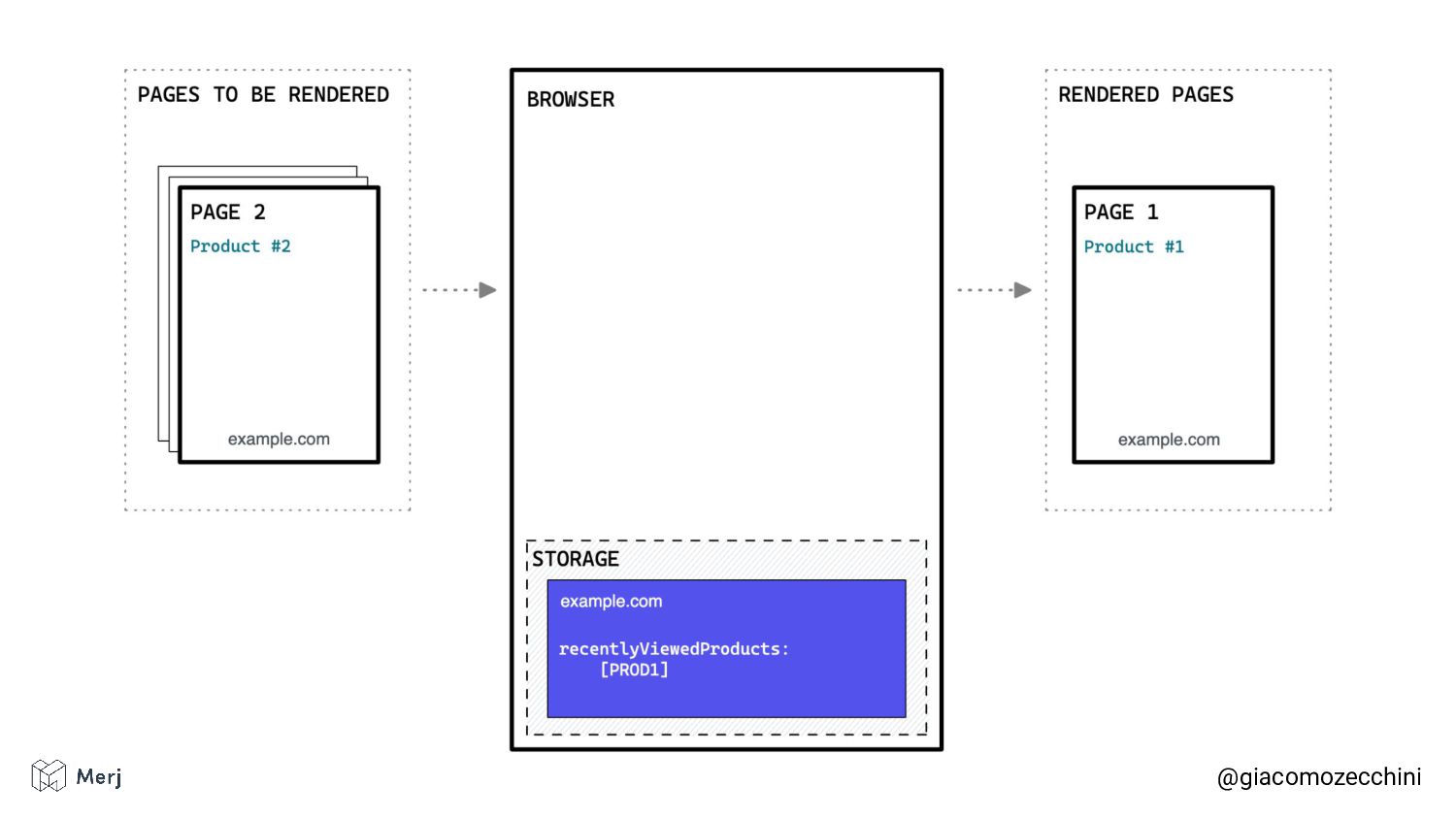
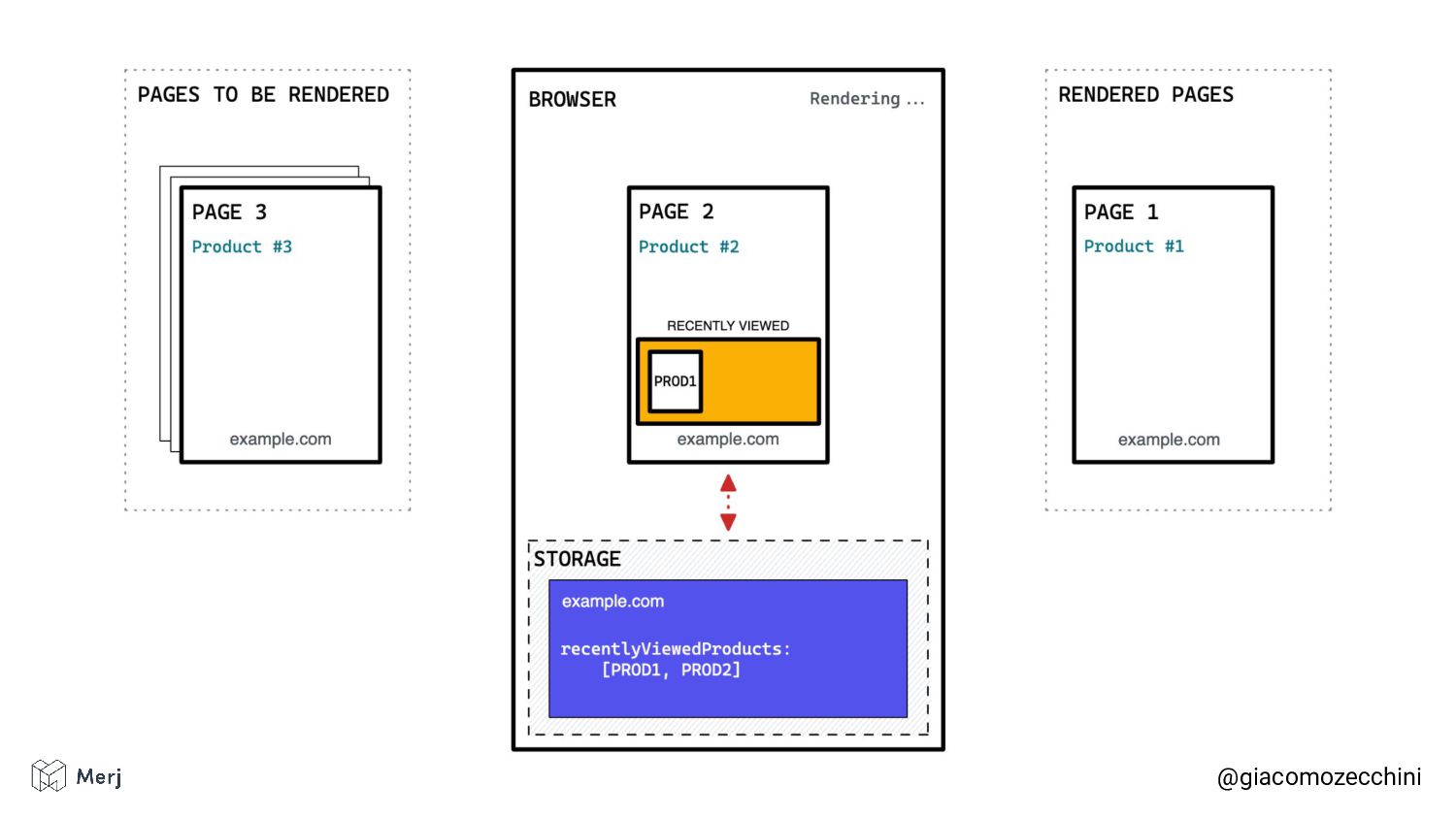
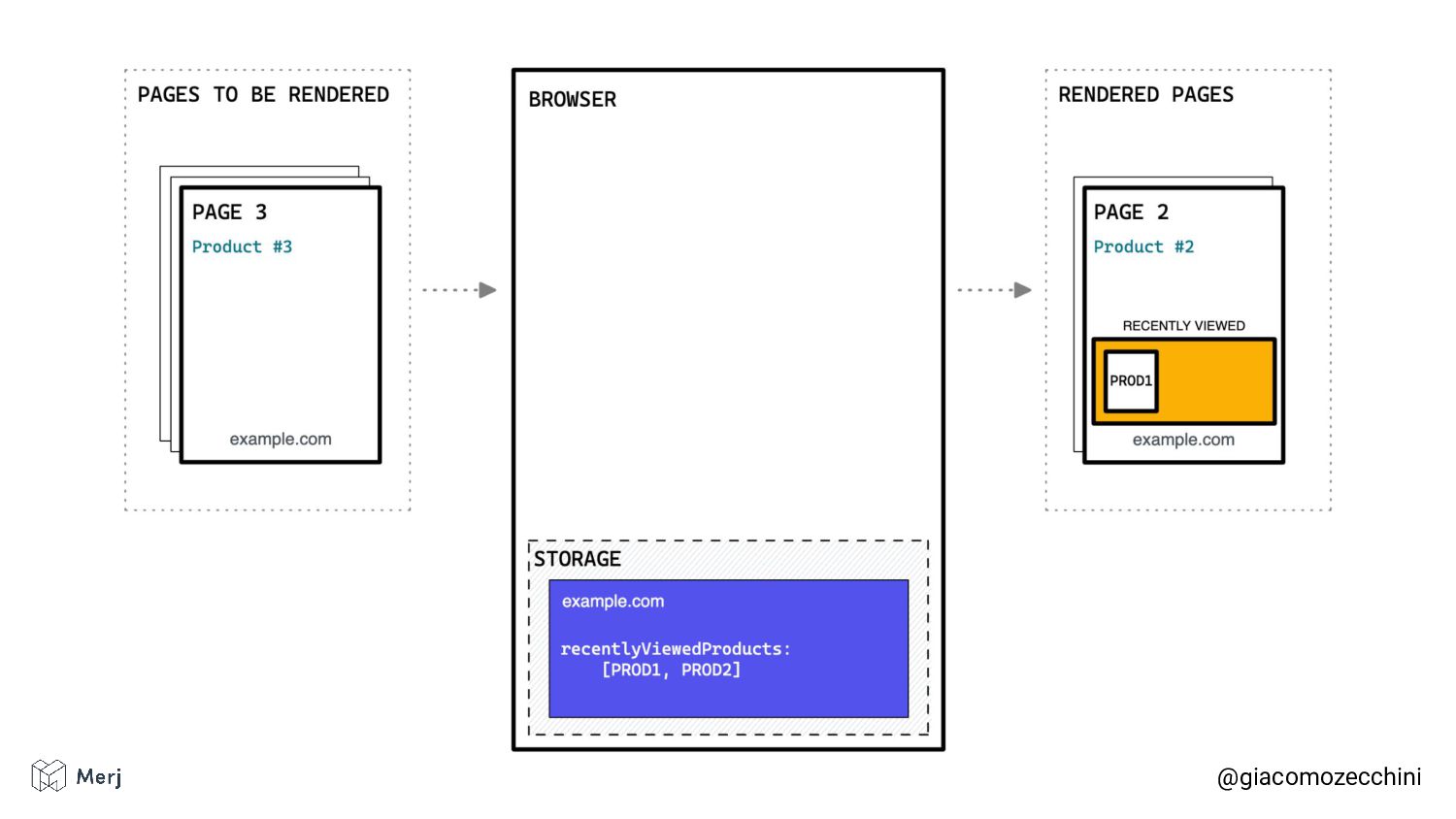
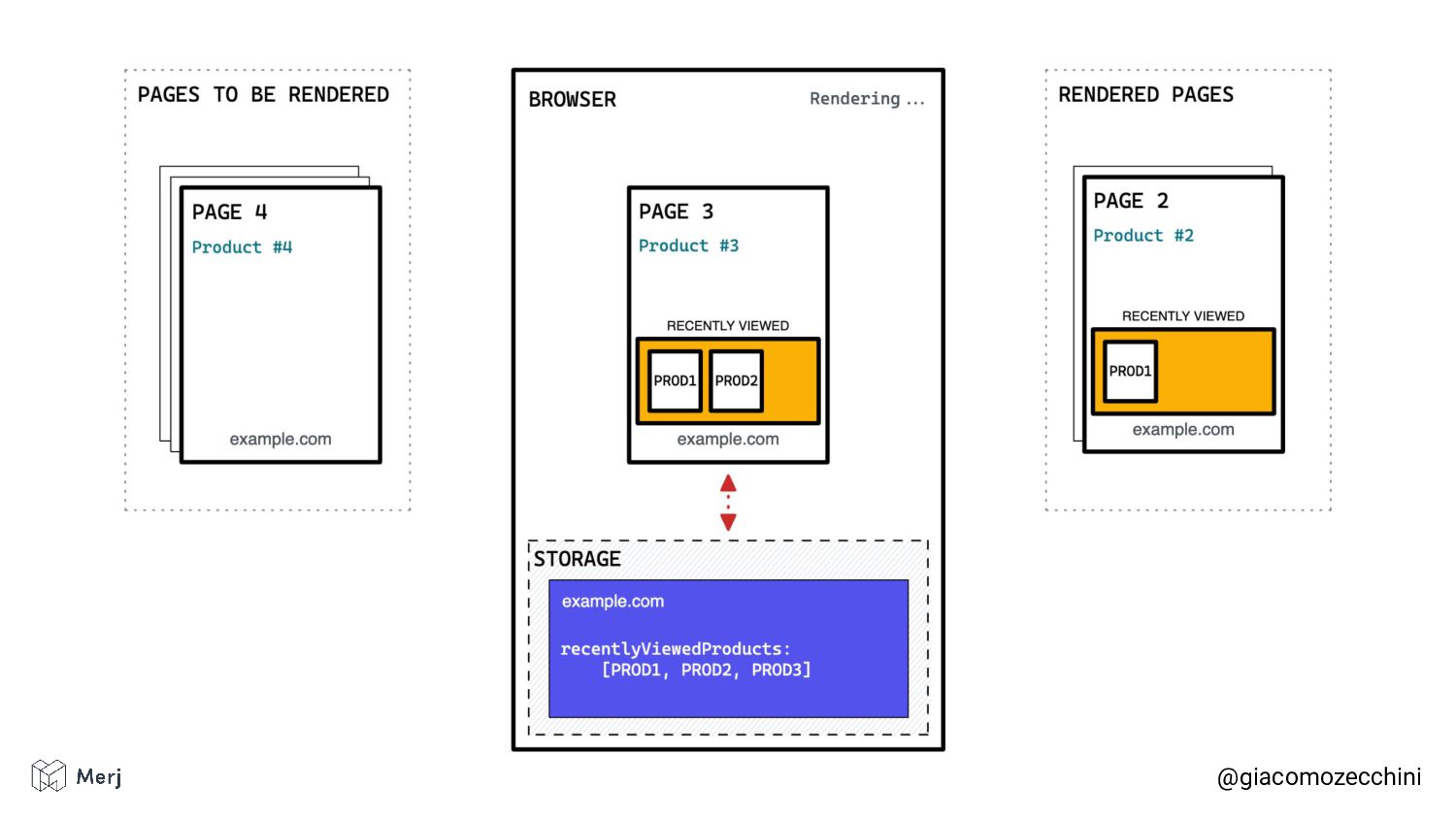
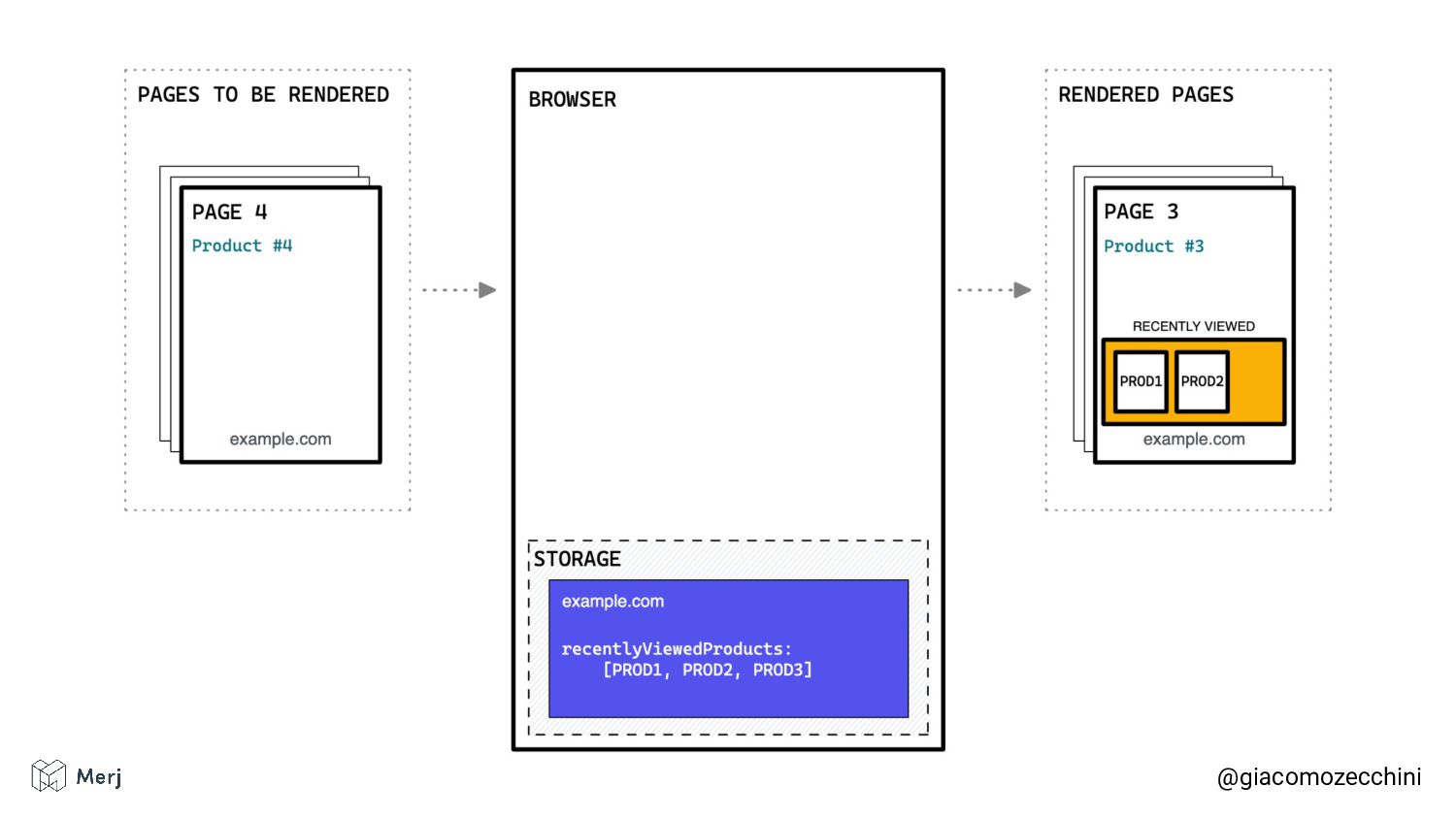
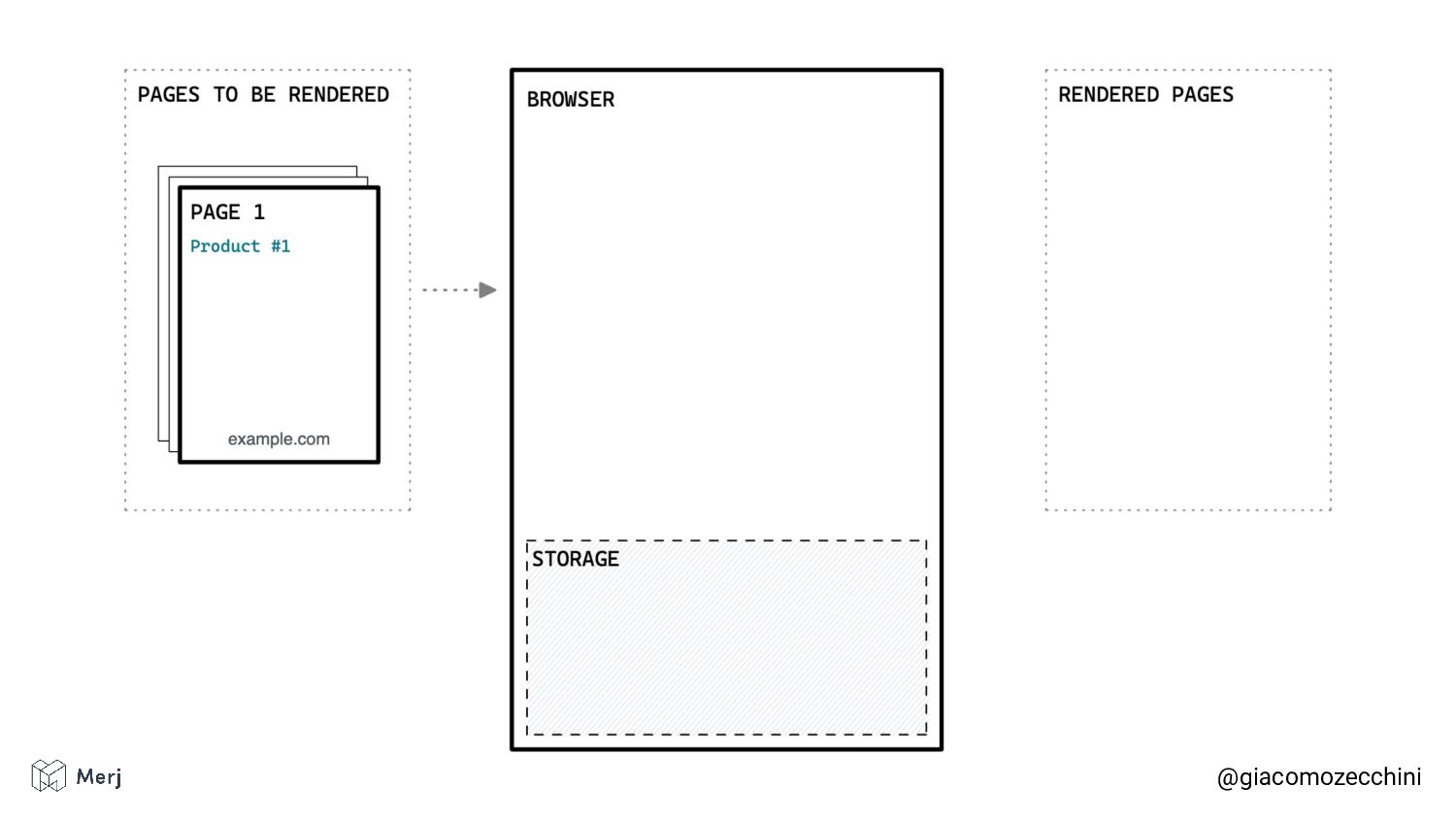
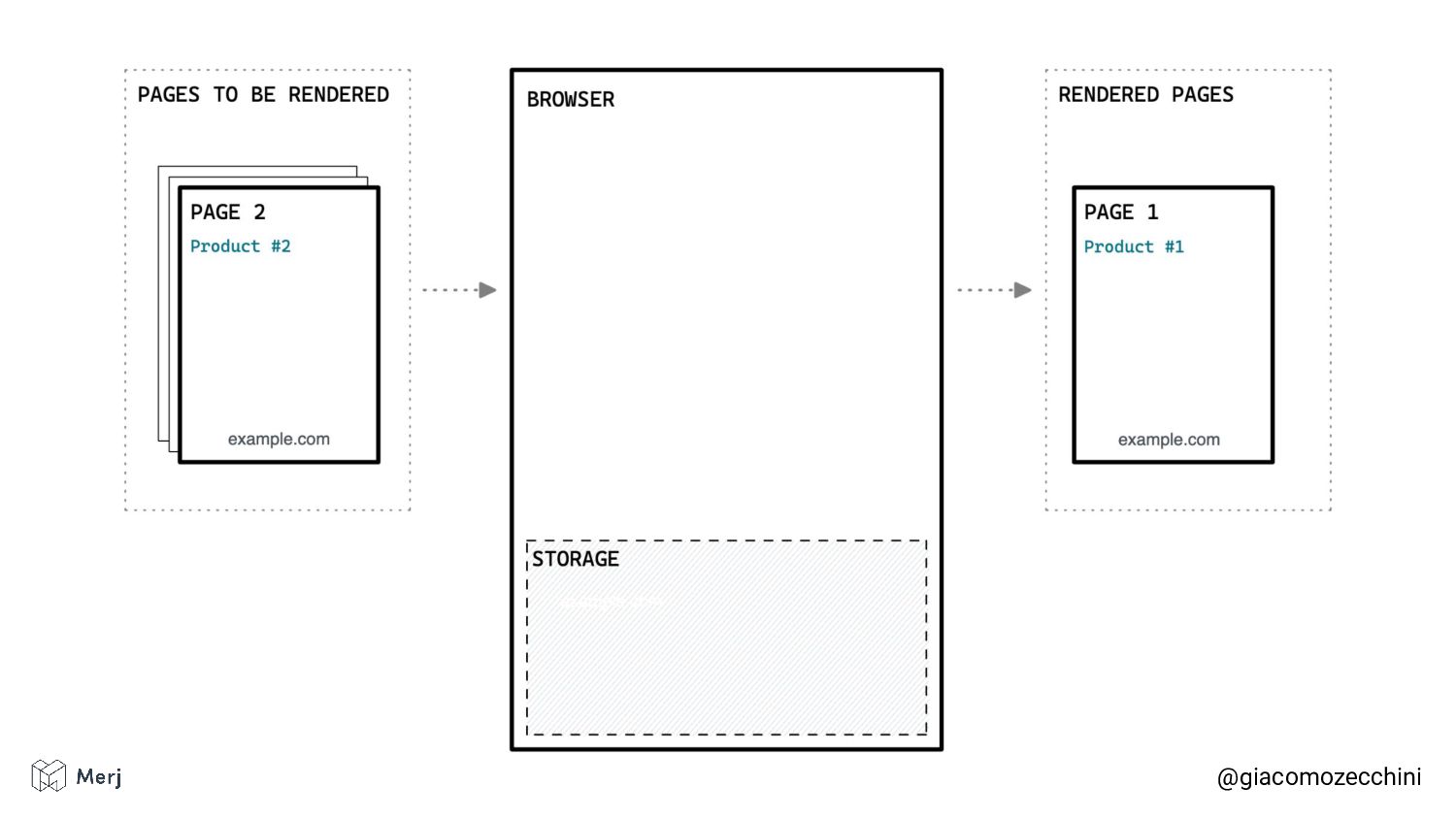
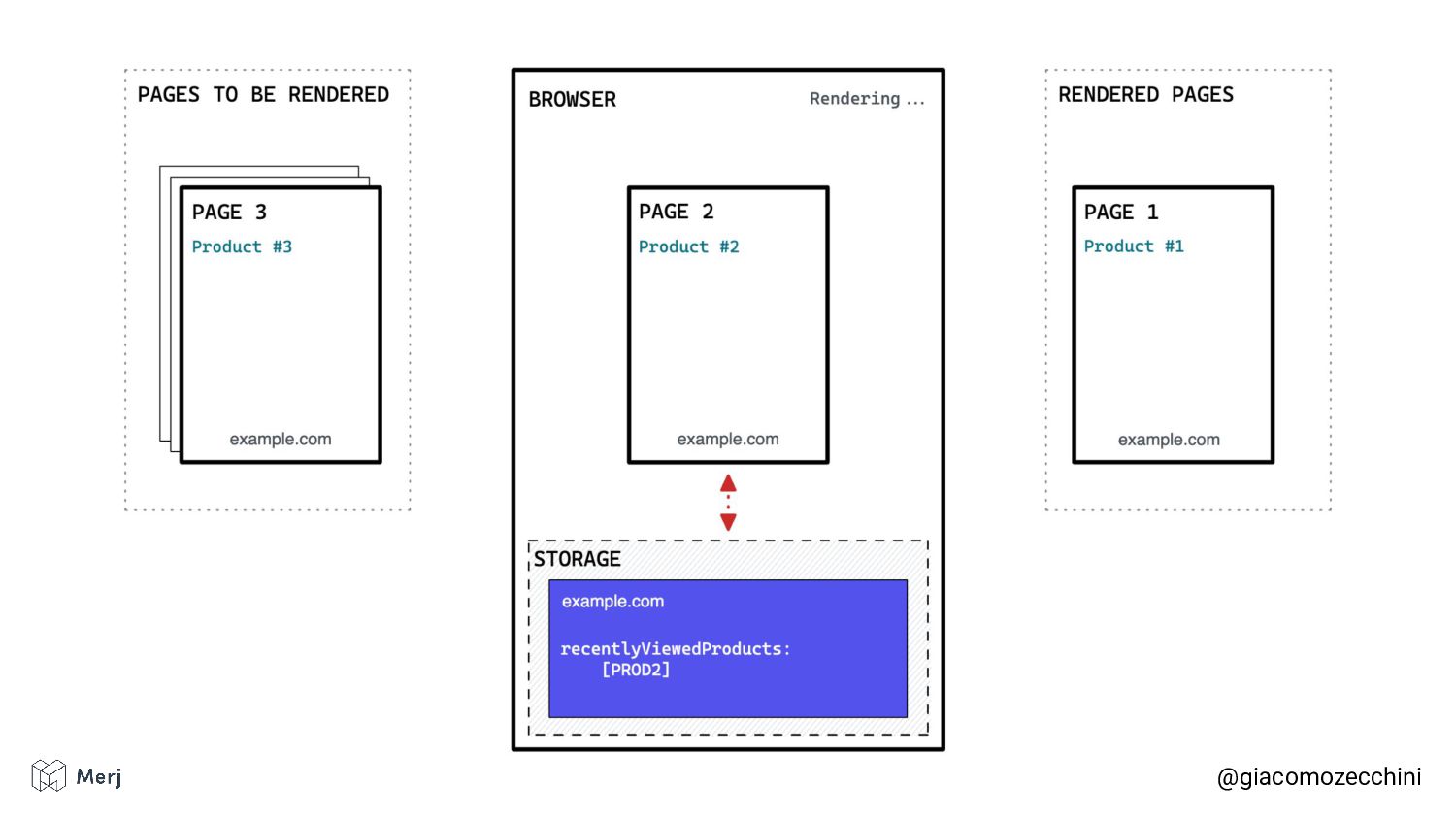
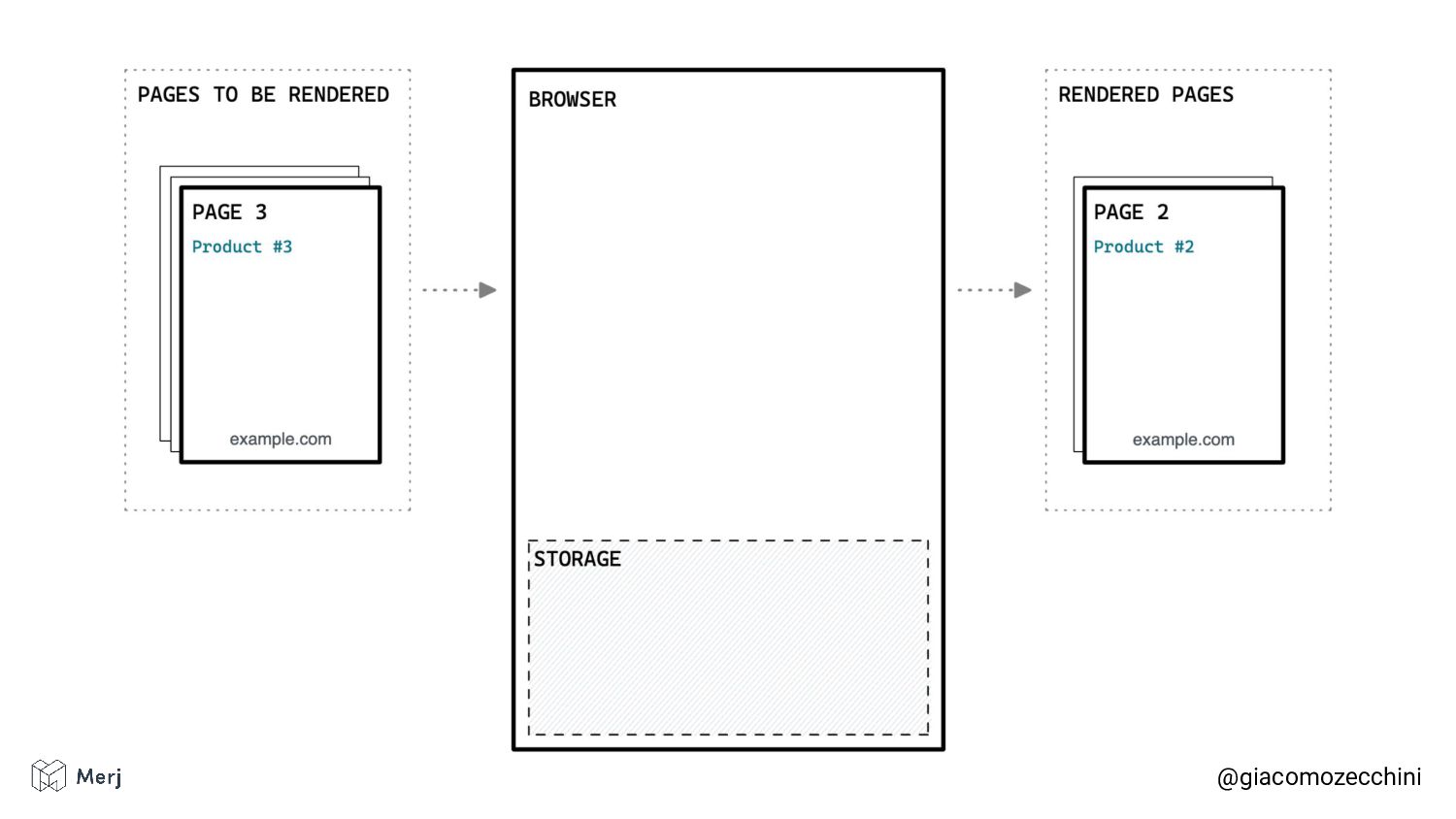
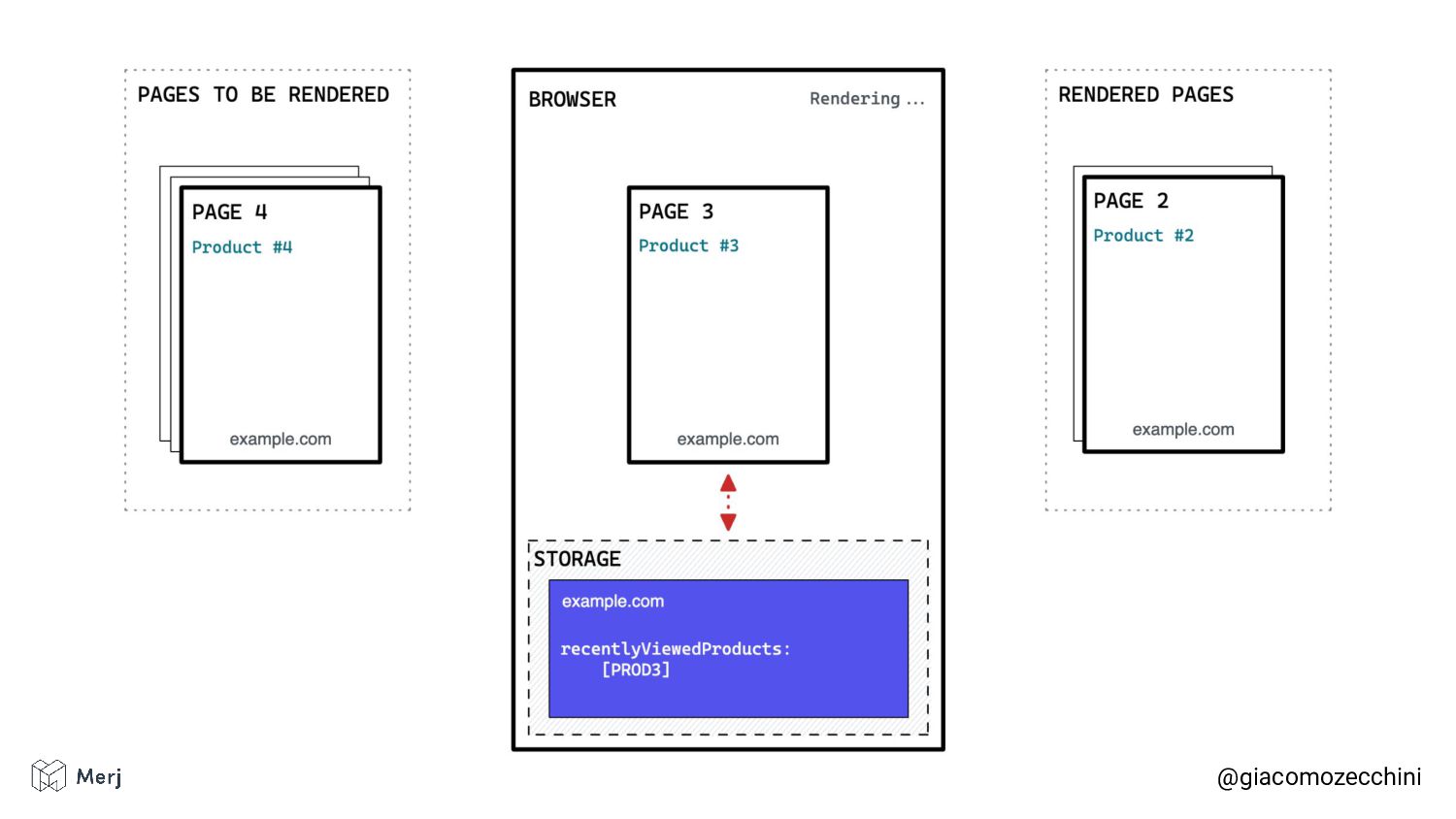
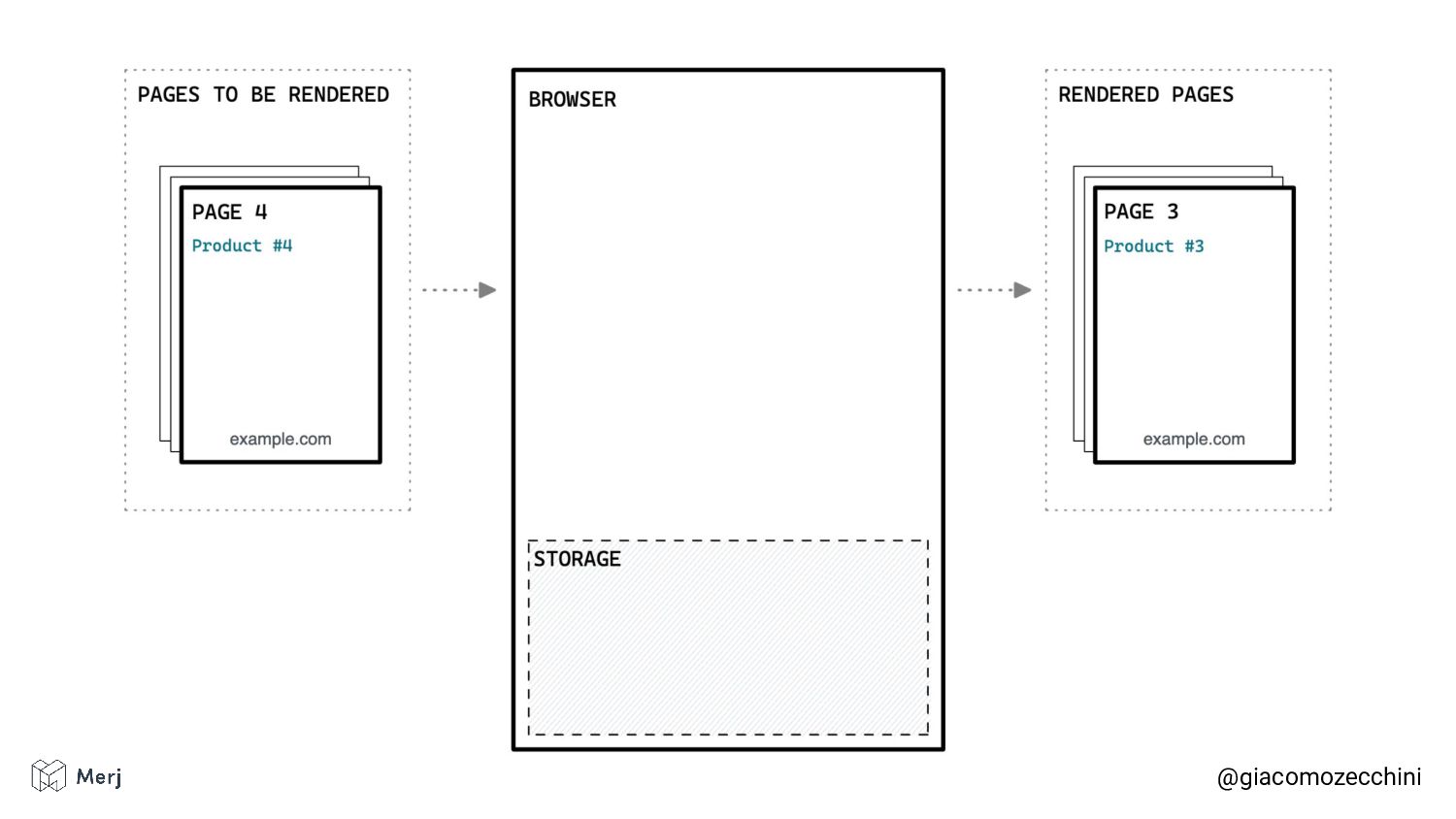
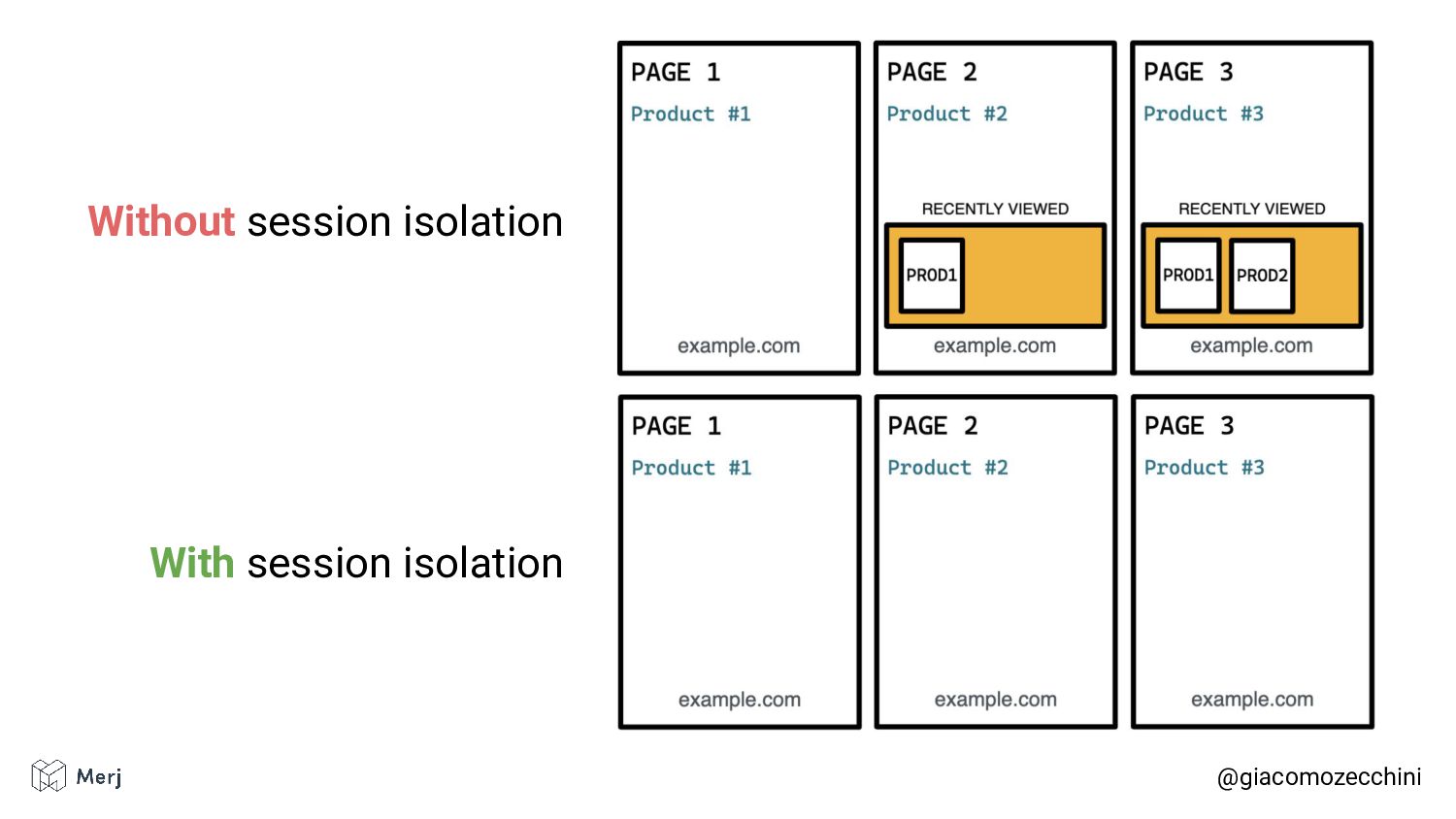
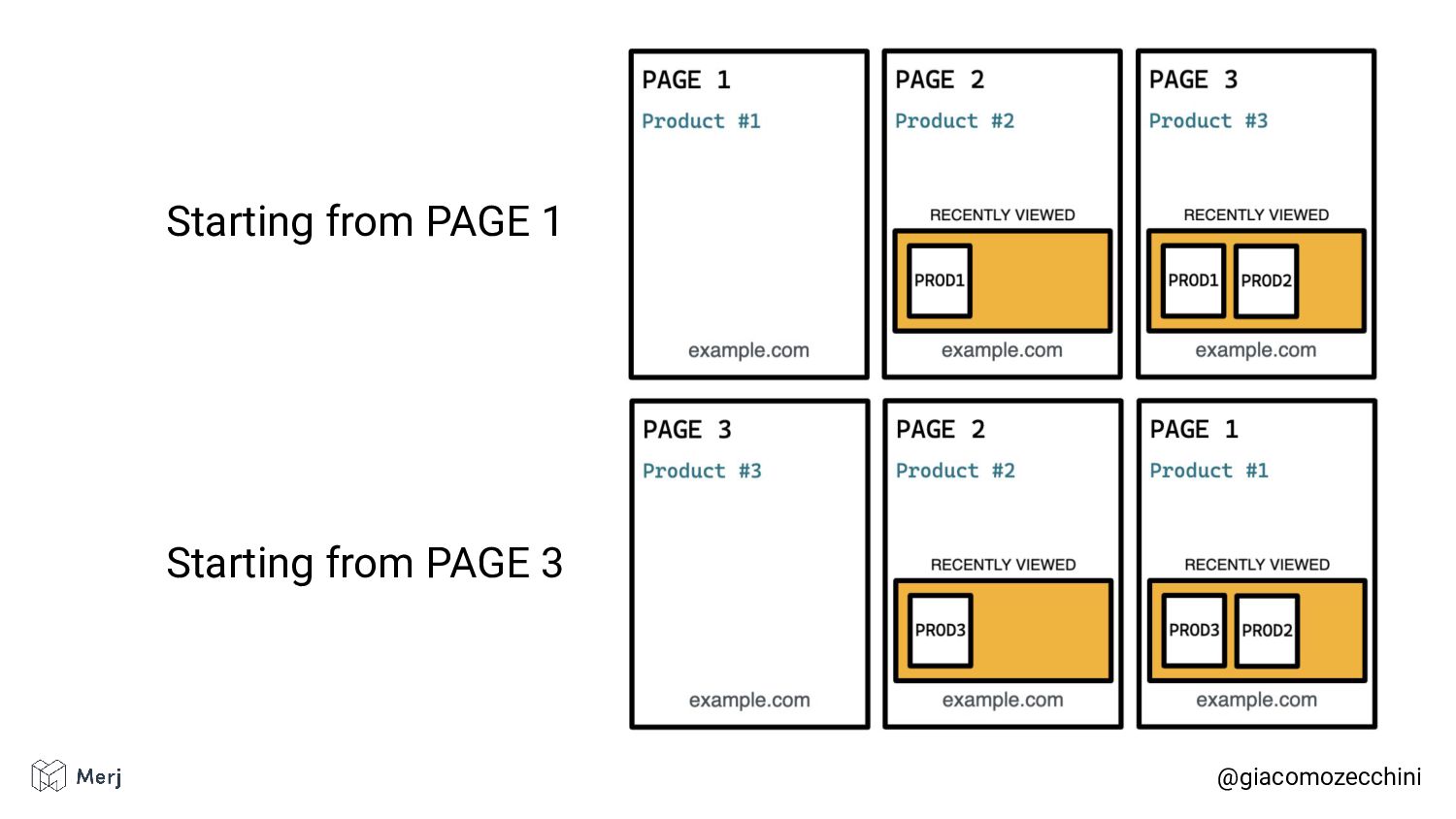
While there is no defined standard for an automated rendering process, search engines (e.g. Google, Bing, Yandex) render pages in isolated rendering sessions. This way, they avoid having the rendering of one web page affect the functionality or the content of another. Isolated rendering sessions should have isolated storage and avoid cross-tab talking.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}