by Stephen Cole Kleen • 1968: “Regular Expression Search Algorithm” - by Ken Thompson. Description of a regular expression compiler. • Regular expressions employed in text editors. Introduction of the grep command.
just the requests to the web app “/PicnicAPI” • Perform LIKE queries on MongoDB • Get the dir and basename of a file path • Get the src attribute of an <img> tag • Read a key-value file having “\” line continuations
test environment, explaining your regex and showing the matches on a text. • http://rubular.com/ - another regex test environment, targeting Ruby's flavour.
string, to check for a match. Both the regex and the string have their own cursor. Which cursor drives the matching process? T h e q u i c k b r q u i Text: Regex:
the regex • Creates a stack of states, and performs backtracking • Supports more language constructs • Imperative regex • Usually returns the first match found • Employed by standard Java, .NET, Python, PHP, Perl, Ruby, …
(, ), [, ], {, }, |, ^, $, #) must be escaped when they are used literally • Escape is performed by prepending “\”. For example: /\?/ to represent a literal “?” • Where raw strings are not supported, a double escape might be required. In Java, the regex /\\\+/ becomes: “\\\\\\+”.
not b here” • [^a-z] = “Something not a, b, c, …, z here” • [^A-Za-c] = “Something not “A, …, Z, a, …, c here” • Negating a character set requires the existence of a character in that position, not belonging to the specified class.
the encoding and on your engine. • In ASCII, usually: – \w = [A-Za-z0-9_] – \s = [\r \n\t\f\v] (includes ASCII-32 common space) • But what about Latin-1 or Unicode? • Know your engine
whose hex value is XXXX • There should also be support for Unicode's categories and scripts, especially via \p • Much more Unicode-related, non-standard features • Know your engine
• Capturing groups are assigned a 1-based index, according to the position of their ( • /(\w+)bet/ tries to match a string and, if successful, creates a capturing group for the text matching \w+, having index 1 • If the above regex is applied to “alphabet”, it matches and its group 1 is “alpha”
precedence: capturing is not always needed • Skipping capturing can save memory and speed up the matching process • To define a non-capturing group, use (?: and ). • Therefore, /(?:\w+)bet/ is just like /\w+bet/, as no capturing is performed and this grouping alters precedence without effects.
that becomes part of the regex • Use \N in your regex, replacing N with the index of the captured group in question • For example: /(['”])\w+\1/ to pair single and double quotes • Some engines support named capturing and backreferences
/alpha|beta/ means “alpha” or “beta” • Alternation has very low precedence; its scope is the current group: use grouping to force precedence. • For example: /A(?:pril|ugust)/ means “A, followed by “pril” or “ugust”.
negated) always matches one and only one character • The branches of an alternation can be strings of any length (at least one character, to be consistent)
animals” It scans the string, starting from P, and, at every character, tries to apply the regex. In a DFA regex, the engine only chooses which regex components remain valid at a given position of the text cursor.
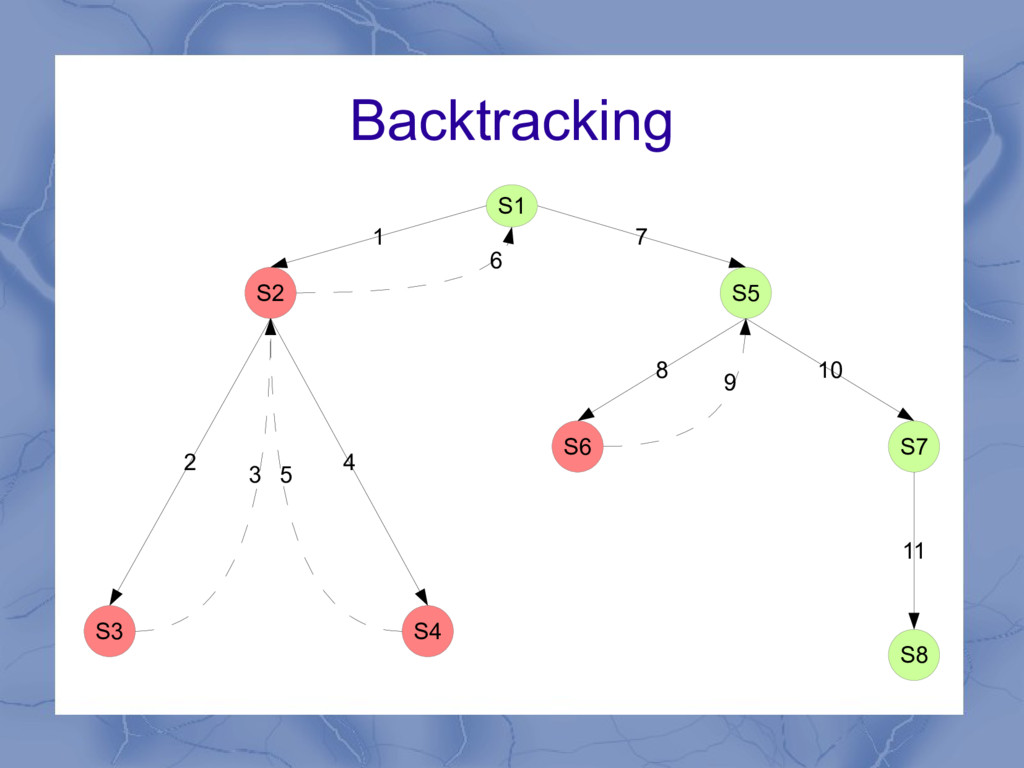
states! • Each decision point saves a state in the stack • State = position of the 2 cursors • If a choice in the regex leads to no match, the engine backtracks (=pops a state from the stack and makes a different choice)
characters, classes or even groups • * = any number of occurrences (even 0) • ? = 0 or 1 occurrencies • + = 1 or infinite occurrencies • {n} = exactly n occurrencies • {m, n} = m to n occurrencies (included) • {m,} = at least m occurrencies
/be?(er|ar)/ • How is it applied to “I'd like a chocolate bar” ? • The regex cursor stays on “b” until the text cursor reaches its “b” too • Then, the following regex paths are tried: – be => b(er) => b(ar)
• Applied to: “Pandas are cute animals” • .* will consume the whole text at first • However, when reaching the end of the text, it stops matching and the regex cursor goes on.
match (no more text is available), so the engine backtracks! • Some backtracking is performed, until the first available space is reached (between “cute” and “animals”) • The regex cursor moves on to “a”, that matches the “a” in “animals”. But “r” doesn't match “n” => more backtracking!
go on until the space between “are” and “cute”... “a” doesn't match the “c” in “cute” => backtracking, again! • The next space is ok: it is followed by “are”, that matches the rest of the regex.
“Pandas are cute animals”, what happens? • The engine must choose whether to apply .*? to “P”. But it's lazy, so the engine chooses to move the regex cursor forward • The regex cursor goes on to “ “, but it doesn't match “P” so the engine backtracks • The engine must now take the remaining path – applying .*? to “P”, which is viable
the first space in the text is reached: it matches the space in the regex, so the regex cursor can go on • The matching process continues until the regex ends • In this case, the match of greedy and lazy evaluation was the same – but the lazy quantifiers required less backtracking
is encountered, the regex engine must choose whether to apply its element to the text or not • Greedy quantifiers prefer the “apply” path whenever possible • Lazy quantifiers prefer the “skip” path whenever possible • Choosing greedy VS lazy quantifiers can impact performances and what is matched, but not the presence/absence of a match.
– /\d{1,3}/ matches the whole “987”: the greedy quantifier tries to consume as much as possible – /\d{1,3}?/ matches just “9”: the lazy quantifier must honour the constraints (at least 1 match), but chooses to skip application whenever possible
• All the states created within an atomic group are removed from the engine's stack as soon as the group closes • Atomic groups are non-capturing, but can have capturing groups • Atomic grouping can alter the match/failure result of a regex, as well as affecting performances
customized behaviour • Enabling and disabling flags usually affects the whole regex, but some engines support flags on just regions. • Flag manipulation is engine- and API- dependent • Every engine has its own flags, but some are definitely common.
matches any character, including \n • Multiline anchors: ^ and $ (see later) work on lines instead of the whole text • Extended: spaces – including newlines - are ignored unless escaped or within a character class; lines starting with # are comments. More readable regexes.
of the text (of a line, in multiline mode) • $: the cursor is at the end of the text (of a line, in multiline mode. And before or after \n? Know your engine). • \A: the cursor is at the beginning of the text • \Z: the cursor is at the end of the text • \b: the cursor is at a word boundary (what's a word boundary? Know your engine)
cursor. Can be positive (the regex must match) or negative (the regex must fail). • Lookahead = a lookaround on the text following the cursor • Lookbehind = a lookaround on the text preceding the cursor.
the other characters in the regex consume the text and make the text cursor shift forward. • On the other hand, lookarounds do not consume text • Juxtaposed lookarounds all apply, bound by a logic and, to the position marked by the text cursor
own stack • They are also called zero-length assertions • Lookahead can be full-fledged regexes • Lookbehinds are usually much more restricted, depending on the engine
stack, that gets deleted at the end of the lookaround. • An important detail: capturing groups within lookarounds are considered capturing groups of the whole regex => their result is saved.
regexes with their own stack, which is thrown away. • This is exactly like an atomic group, but the lookahead does not consume text • However, capturing groups in a lookahead are stored by the regex => use a backreference to capture that text • Therefore, for example: /(?=(\d+))\1/ = /(?>\d+)/
System.Text.RegularExpressions.Regex • Its constructor accepts the regex and, optionally, global flags • C# supports raw strings (preceded by @), to avoid over-escaping, that can be found in Java.
In lieu of a constructor, it's a static method, Pattern.compile(), that creates a regex • It takes the regex and, optionally, the global flags • In Java, the regex /\\test/ becomes “\\\\test”, because each “\” in the regex must be escaped in Java, too, for a total of 4 “\”.
/regex/ (with slashes and without double quotes) as the right side of an equality assertion in your query • Important: a regex could hit indexes on a field, but the best results are achieved when the regex starts with ^
use this notation to create a regex object: var regex = /regexPattern/ var regexWithFlags = /regexPattern/flags • Alternatively, the RegExp class can be used
simple, just like any other construct • To achieve this result, a good knowledge of the text, as well as of the requirements, is needed. • Write tests for your regexes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Character classes • [abc] = “a, b or c in](https://files.speakerdeck.com/presentations/06d183ba030545d5b939b2f26101fda8/slide_22.jpg){kind=link}
![Negated character classes • [^ab] = “Something not a and](https://files.speakerdeck.com/presentations/06d183ba030545d5b939b2f26101fda8/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}