«In the end, what's the difference between any passionate software engineer and an artist?»
I firmly believe that creativity is the very heart of excellent engineering: for example, the gradual refinement steps to achieve beautiful code are conceptually similar to the process of creating an exquisite painting or sculpting a statue out of marble...
In my personal, endless pursuit of Knowledge, I've noticed that even different domains can actually influence each other - and natural languages are by far one of my favorite inspiration sources when developing software.
In this presentation we're going to unfold - with technology and fun! - the story of the software architecture that I created to savor the nuances of the Spanish language.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
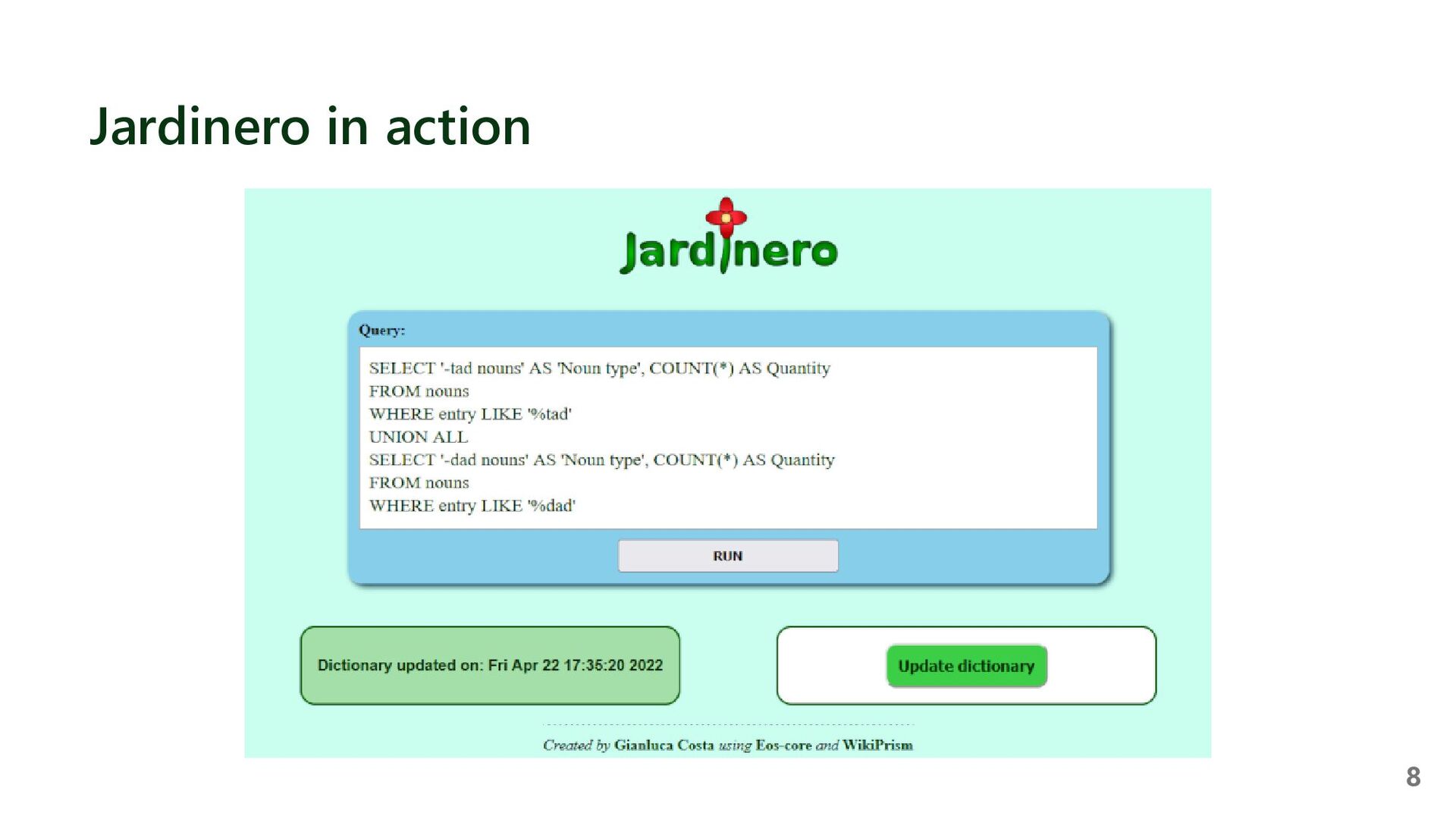{kind=link}
{kind=link}
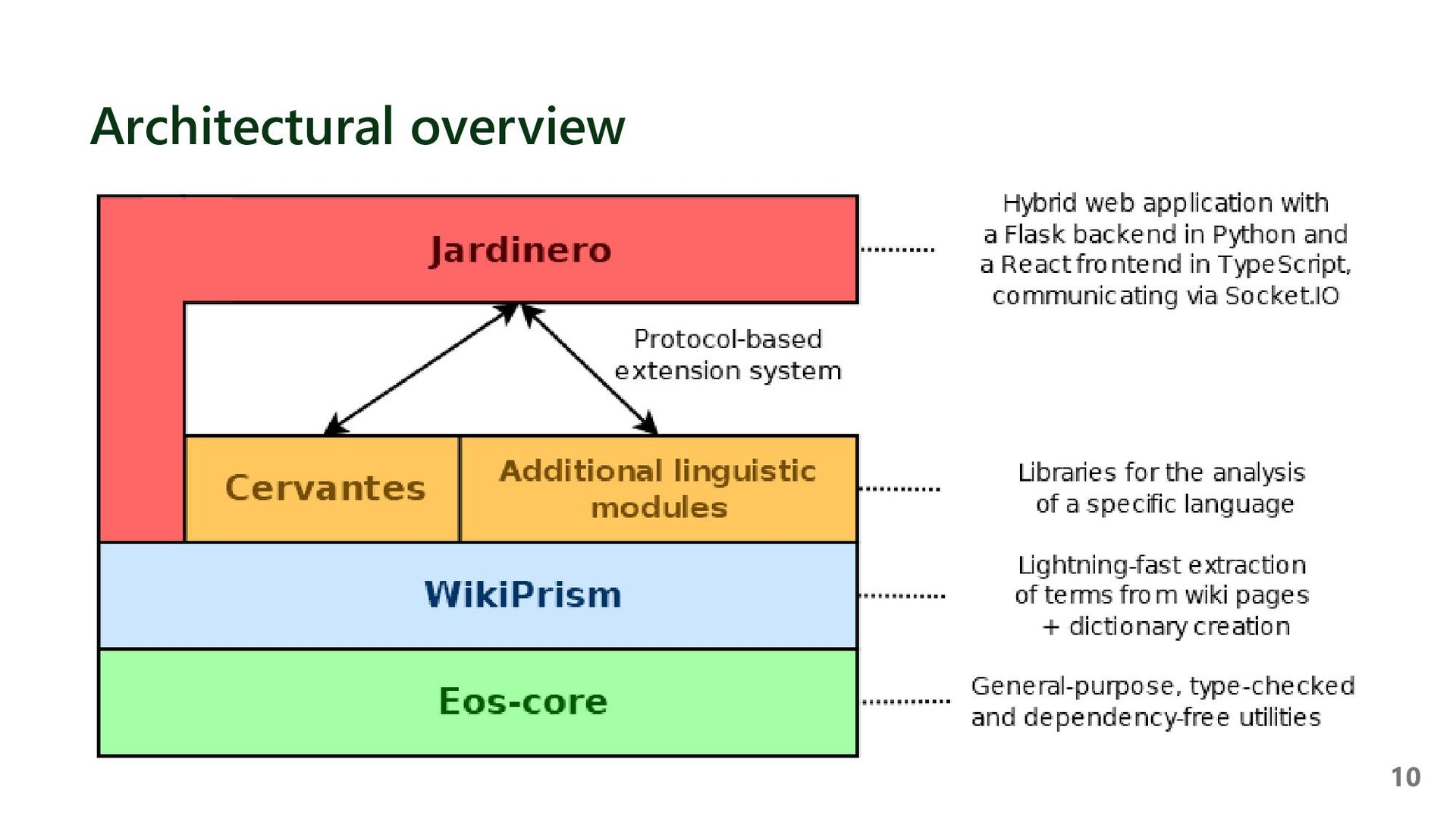{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
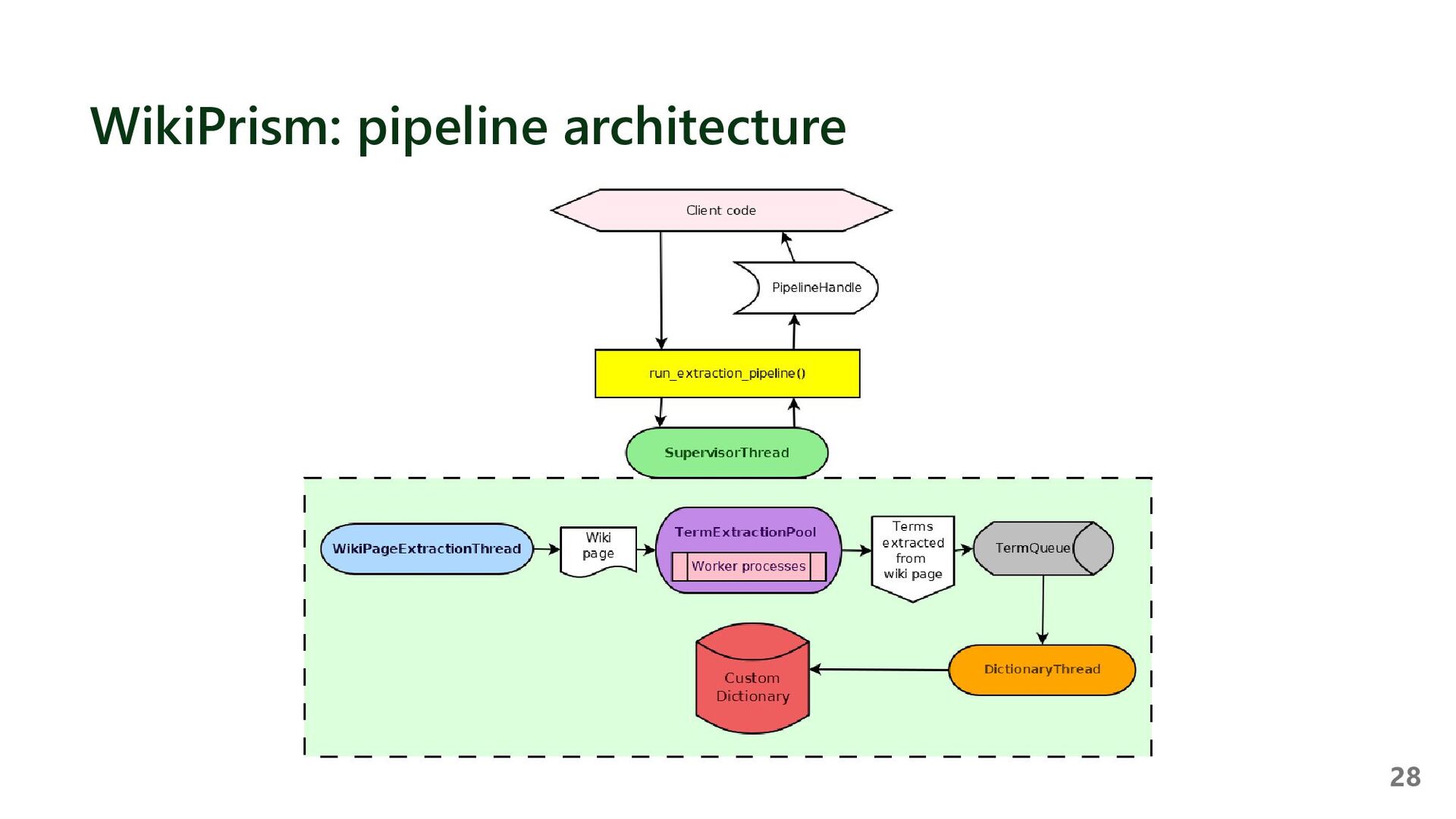{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}